

Welche Einschränkungen gibt es bei MySQL?

1. Überblick
Konzept: Einschränkungen sind Regeln, die auf Felder in einer Tabelle einwirken, um die in der Tabelle gespeicherten Daten einzuschränken.
Zweck: Gewährleistung der Genauigkeit, Gültigkeit und Integrität der Daten in der Datenbank.
Kategorie:

Hinweis: Einschränkungen werden auf die Felder in der Tabelle angewendet und Einschränkungen können beim Erstellen/Ändern der Tabelle hinzugefügt werden.
2. Einschränkungsdemonstration
Wir haben die allgemeinen Einschränkungen in der Datenbank und die in den Einschränkungen enthaltenen Schlüsselwörter eingeführt. Wie geben wir diese Einschränkungen beim Erstellen und Ändern von Tabellen an? Lassen Sie uns dies anhand eines Falls demonstrieren .
Fallanforderungen: Schließen Sie die Erstellung der Tabellenstruktur gemäß den Anforderungen ab. Die Anforderungen lauten wie folgt:
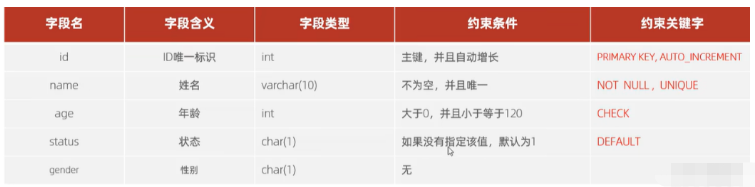
Die entsprechende Anweisung zur Tabellenerstellung lautet:
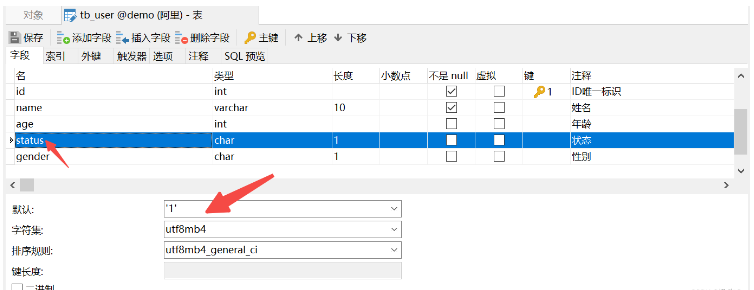
CREATE TABLE tb_user ( id INT AUTO_INCREMENT PRIMARY KEY COMMENT 'ID唯一标识', NAME VARCHAR ( 10 ) NOT NULL UNIQUE COMMENT '姓名', age INT CHECK ( age > 0 && age <= 120 ) COMMENT '年龄', STATUS CHAR ( 1 ) DEFAULT '1' COMMENT '状态', gender CHAR ( 1 ) COMMENT '性别' );
Beim Hinzufügen von Einschränkungen zu Feldern müssen wir nach dem Feld nur das Schlüsselwort der Einschränkung hinzufügen und darauf achten zu seiner Syntax.
Wir führen die obige SQL aus, um die Tabellenstruktur zu erstellen, und können sie dann anhand eines Datensatzes testen, um zu überprüfen, ob die Einschränkungen wirksam werden können.
(1) Zuerst wurden drei Datenelemente hinzugefügt
insert into tb_user(name,age,status,gender) values ('Tom1',19,'1','男'),('Tom2',25,'0','男'); insert into tb_user(name,age,status,gender) values ('Tom3',19,'1','男');
Es dauerte 21 Sekunden, um drei Datenelemente hinzuzufügen. Was ist los?
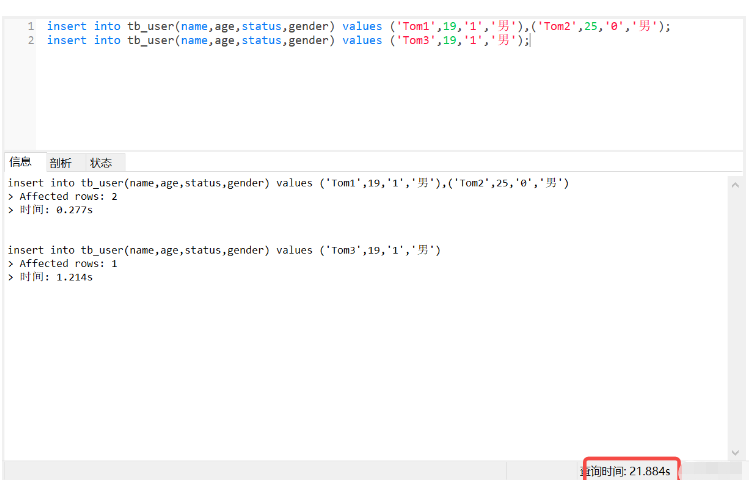
Ursprünglich dachte ich, dass das Hinzufügen dieser Einschränkungen dazu führt, dass das Hinzufügen von Daten langsamer wird, aber das war nicht der Fall, da dies der Linux-Server von Alibaba ist, und dann habe ich MySQL über den Client unter Linux verbunden, um das neue Hinzufügen auszuführen betrug 0,01 Sekunden, was darauf hinweist, dass dies die Zeit ist, die Navicat benötigt, um eine Verbindung zum Remote-Host herzustellen.
Selbst wenn diese neuen Einschränkungen hinzugefügt werden, führt dies dazu, dass die neuen Daten langsam sind, was nur in Stapeln deutlich erkennbar ist. Es ist im Grunde für ein einzelnes Datenelement unsichtbar. (2) Testname NICHT NULL .
insert into tb_user(name,age,status,gender) values (null,19,'1','男');
Obwohl ein Fehler gemeldet wird, werden wir ein Phänomen feststellen, wenn wir zu diesem Zeitpunkt weitere Daten hinzufügen.
insert into tb_user(name,age,status,gender) values ('Tom3',19,'1','男');
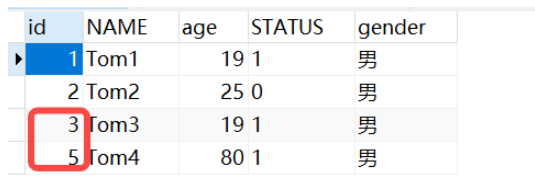
 Es handelt sich offensichtlich um eine sich selbst erhöhende ID, aber es gibt keine 4. Der Grund dafür ist, dass UNIQUE nach der Beantragung der sich selbst erhöhenden ID bereit ist, in die Datenbank aufgenommen zu werden. Dann wird zu diesem Zeitpunkt zunächst geprüft, ob Es gibt einen Wert mit demselben Namen. Wenn einer vorhanden ist, schlägt das neue Hinzufügen fehl. Die automatische Inkrementierung der ID wurde jedoch beantragt.
Es handelt sich offensichtlich um eine sich selbst erhöhende ID, aber es gibt keine 4. Der Grund dafür ist, dass UNIQUE nach der Beantragung der sich selbst erhöhenden ID bereit ist, in die Datenbank aufgenommen zu werden. Dann wird zu diesem Zeitpunkt zunächst geprüft, ob Es gibt einen Wert mit demselben Namen. Wenn einer vorhanden ist, schlägt das neue Hinzufügen fehl. Die automatische Inkrementierung der ID wurde jedoch beantragt. Im Gegenteil, als wir gerade den Nullnamen getestet haben, hat er keinen Ausweis beantragt, weil er ihn bereits zu Beginn als leer beurteilt hatte und noch nicht den Schritt der Ausweisbeantragung erreicht hatte.
Bestimmen Sie, ob er leer ist. -》 Beantragen Sie eine automatische Inkrementierungs-ID. -》 Bestimmen Sie, ob bereits ein vorhandener Wert vorhanden ist.
Zusammenfassung: Wenn der neu hinzugefügte Name nicht leer ist, sondern dieselben Daten wie der hat Im vorherigen Fall schlägt das neue Hinzufügen zu diesem Zeitpunkt fehl, gilt jedoch für die Primärschlüssel-ID.
(4) Test CHECKWas wir festlegen, ist, dass das Alter größer als 0 und kleiner oder gleich 120 sein muss, sonst schlägt das Speichern fehl! insert into tb_user(name,age,status,gender) values ('Tom4',80,'1','男');
age int check (age > 0 && age <= 120) COMMENT '年龄' ,
insert into tb_user(name,age,status,gender) values ('Tom5',-1,'1','男'); insert into tb_user(name,age,status,gender) values ('Tom5',121,'1','男');
STATUS CHAR ( 1 ) DEFAULT '1' COMMENT '状态',
(6) Oben vervollständigen wir die Spezifikation der Einschränkungen, indem wir SQL-Anweisungen schreiben.
Auto-Inkrementierung des Primärschlüssels
Eindeutigkeitsbeschränkung des Namens
Status ist standardmäßig 1
3. Fremdschlüsseleinschränkungen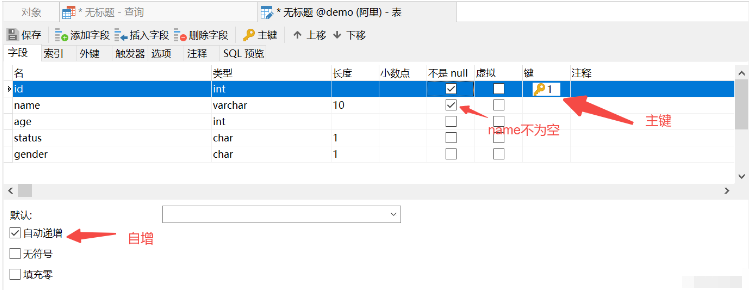
Fremdschlüssel:
Verwendung: Stellen Sie eine Verbindung zwischen den Daten der beiden Tabellen her, um die Konsistenz und Integrität der Daten sicherzustellen.
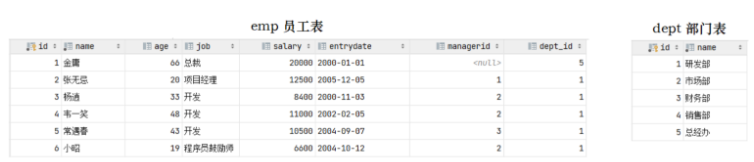
Die Emp-Tabelle auf der linken Seite ist die Mitarbeitertabelle, in der die grundlegenden Informationen der Mitarbeiter gespeichert sind, einschließlich Mitarbeiter-ID, Name, Alter, Position, Gehalt und Beitritt In den Mitarbeiterinformationen wird die Abteilungs-ID dept_id gespeichert, und die ID dieser Abteilung ist die Primärschlüssel-ID der zugeordneten Abteilungstabelle dept. Dann ist die dept_id der emp-Tabelle der Fremdschlüssel , und es ist mit dem Primärschlüssel einer anderen Tabelle verknüpft.
2、 不使用外键有什么影响
通过上面的示例,我们分别来演示 添加外键 和不添加外键的区别,首先来看不添加 外键 对数据有什么影响:
准备数据:
CREATE TABLE dept ( id INT auto_increment COMMENT 'ID' PRIMARY KEY, NAME VARCHAR ( 50 ) NOT NULL COMMENT '部门名称' ) COMMENT '部门表'; INSERT INTO dept (id, name) VALUES (1, '研发部'), (2, '市场部'),(3, '财务部'), (4, '销售部'), (5, '总经办'); CREATE TABLE emp ( id INT auto_increment COMMENT 'ID' PRIMARY KEY, NAME VARCHAR ( 50 ) NOT NULL COMMENT '姓名', age INT COMMENT '年龄', job VARCHAR ( 20 ) COMMENT '职位', salary INT COMMENT '薪资', entrydate date COMMENT '入职时间', managerid INT COMMENT '直属领导ID', dept_id INT COMMENT '部门ID' ) COMMENT '员工表'; INSERT INTO emp (id, name, age, job,salary, entrydate, managerid, dept_id) VALUES (1, '金庸', 66, '总裁',20000, '2000-01-01', null,5), (2, '张无忌', 20, '项目经理',12500, '2005-12-05', 1,1), (3, '杨逍', 33, '开发', 8400,'2000-11-03', 2,1), (4, '韦一笑', 48, '开 发',11000, '2002-02-05', 2,1), (5, '常遇春', 43, '开发',10500, '2004-09-07', 3,1), (6, '小昭', 19, '程 序员鼓励师',6600, '2004-10-12', 2,1);
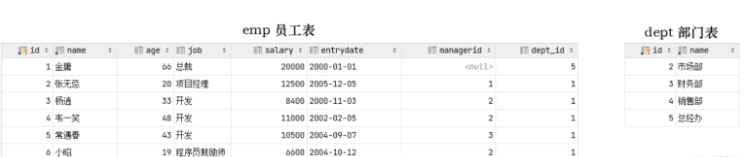
接下来,我们可以做一个测试,删除id为1的部门信息。
结果,我们看到删除成功,而删除成功之后,部门表不存在id为1的部门,而在emp表中还有很多的员工,关联的为id为1的部门,此时就出现了数据的不完整性。 而要想解决这个问题就得通过数据库的外键约束。
正常开发当中有时候会通过业务代码来控制数据的不完整性,例如删除部门的时候会先根据部门id去查看一下有没有对应的员工表,如果有则删除失败,没有则删除成功。
3、 添加外键的语法
可以在创建表的时候直接添加外键,也可以对现已存在的表添加外键。
(1)方式一
CREATE TABLE 表名( 字段名 数据类型, ... [CONSTRAINT] [外键名称] FOREIGN KEY (外键字段名) REFERENCES 主表 (主表列名) );
使用示例:
CREATE TABLE emp ( id INT auto_increment COMMENT 'ID' PRIMARY KEY, NAME VARCHAR ( 50 ) NOT NULL COMMENT '姓名', age INT COMMENT '年龄', job VARCHAR ( 20 ) COMMENT '职位', salary INT COMMENT '薪资', entrydate date COMMENT '入职时间', managerid INT COMMENT '直属领导ID', dept_id INT COMMENT '部门ID', CONSTRAINT fk_emp_dept_id FOREIGN KEY (dept_id) REFERENCES dept (id) ) COMMENT '员工表';
也可以省略掉CONSTRAINT fk_emp_dept_id 这样mysql就会自动给我们起外键名称。
方式二:对现存在的表添加外键
ALTER TABLE 表名 ADD CONSTRAINT 外键名称 FOREIGN KEY (外键字段名) REFERENCES 主表 (主表列名) ;
使用示例:
alter table emp add constraint fk_emp_dept_id FOREIGN KEY (dept_id) REFERENCES dept(id);
方式三:Navicat添加外键

删除外键:
ALTER TABLE 表名 DROP FOREIGN KEY 外键名称;
使用示例:
alter table emp drop foreign key fk_emp_dept_id;
4、 删除/更新行为
我们将在父表数据删除时发生的限制行为称为删除/更新行为,此行为是在添加外键之后发生的。具体的删除/更新行为有以下几种:

默认的MySQL 8.0.27版本中,RESTRICT是用于删除和更新行的行为!但是,不同的版本可能会有不同的行为

具体语法为:
ALTER TABLE 表名 ADD CONSTRAINT 外键名称 FOREIGN KEY (外键字段) REFERENCES 主表名 (主表字段名) ON UPDATE CASCADE ON DELETE CASCADE;
就是比原先添加外键后面多了这些ON UPDATE CASCADE ON DELETE CASCADE,代表的是更新时采用CASCADE ,删除时也采用CASCADE
5、 演示删除/更新行为
(1)演示RESTRICT
在对父表中的记录进行删除或更新操作时,需要先检查该记录是否存在关联的外键,如果存在,则不允许执行删除或更新操作。 (与 NO ACTION 一致) 默认行为
首先要添加外键,默认是RESTRICT行为!
alter table emp add constraint fk_emp_dept_id FOREIGN KEY (dept_id) REFERENCES dept(id);
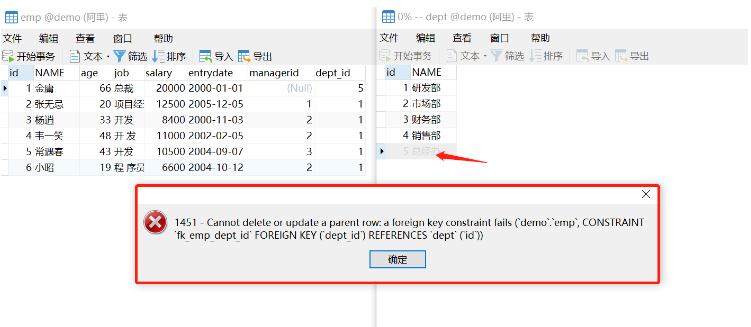
删除父表中id为5的记录时,会因为emp表中的dept_id存在5而报错。假如要更新id也同样会报错的!
(2)演示CASCADE
当在父表中删除/更新对应记录时,首先检查该记录是否有对应外键,如果有,则
也删除/更新外键在子表中的记录。
删除外键的语法:
ALTER TABLE 表名 DROP FOREIGN KEY 外键约束名;
删除外键的示例:
alter table emp drop foreign key fk_emp_dept_id;
指定外键的删除更新行为为cascade
alter table emp add constraint fk_emp_dept_id foreign key (dept_id) references dept(id) on update cascade on delete cascade ;
修改父表id为1的记录,将id修改为6

我们发现,原来在子表中dept_id值为1的记录,现在也变为6了,这就是cascade级联的效果。
在一般的业务系统中,不会修改一张表的主键值。
删除父表id为6的记录

我们发现,父表的数据删除成功了,但是子表中关联的记录也被级联删除了。
(3)演示SET NULL
当在父表中删除对应记录时,首先检查该记录是否有对应外键,如果有则设置子表中该外键值为null(这就要求该外键允许取null)。
alter table emp add constraint fk_emp_dept_id foreign key (dept_id) references dept(id) on update set null on delete set null ;
在执行测试之前,我们需要先移除已创建的外键 fk_emp_dept_id。然后再通过数据脚本,将emp、dept表的数据恢复了。
接下来,我们删除id为1的数据,看看会发生什么样的现象。
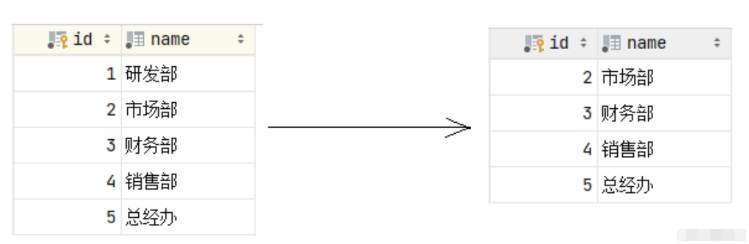
我们发现父表的记录是可以正常的删除的,父表的数据删除之后,再打开子表 emp,我们发现子表emp的dept_id字段,原来dept_id为1的数据,现在都被置为NULL了。
Dies ist die Auswirkung des Lösch-/Aktualisierungsverhaltens von SET NULL.
4. Ist es besser, Auto-Inkrementierung oder UUID als Primärschlüssel-ID zu verwenden?
Beim Entwerfen von Tabellen in MySQL empfiehlt MySQL offiziell, keine UUID oder diskontinuierliche und sich nicht wiederholende Schneeflocken-IDs (lange Form und eindeutig) zu verwenden. , empfiehlt jedoch eine kontinuierliche automatische Inkrementierung. Die offizielle Empfehlung zum Erhöhen der Primärschlüssel-ID lautet auto_increment. Warum wird die Verwendung von uuid nicht empfohlen?
1. Testen Sie die Effizienz der automatischen Inkrementierung von IDs und Zufallszahlen. Erstellen Sie zunächst drei Tabellen: user_auto_key stellt die automatische Inkrementierungstabelle dar, user_uuid stellt die UUID des ID-Speichers dar und random_key stellt die Tabellen-ID dar ist die Schneeflocken-ID. Dann lauten die Testergebnisse des Batch-Einfügens von Daten durch Herstellen einer Verbindung mit JDBC wie folgt:
Wenn das vorhandene Datenvolumen 130 W beträgt: Testen wir das Einfügen von 10-W-Daten erneut, um zu sehen, wie die Ergebnisse aussehen werden: 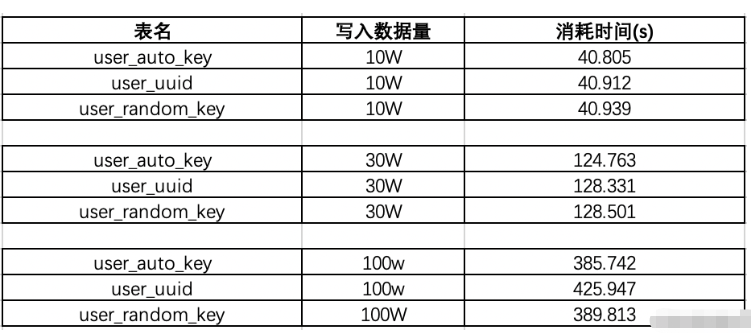
Das ist möglich Wenn die Datenmenge etwa 100 W beträgt, ist die Einfügungseffizienz von UUID am niedrigsten, und wenn in der Folgesequenz 130 W Daten hinzugefügt werden, sinkt die Zeit von Uudi erneut. Die allgemeine Effizienzbewertung der Zeitnutzung ist:  , UUID hat die niedrigste Effizienz
, UUID hat die niedrigste Effizienz
auto_key>random_key>uuid2 Nachteile der Verwendung von sich selbst erhöhenden IDs
1 Sobald andere Ihre Datenbank durchsuchen, können sie sie anhand der sich selbst erhöhenden ID abrufen der Datenbank Mit Ihren Geschäftswachstumsinformationen ist es einfach, Ihre Betriebssituation zu analysieren Konkurrenz-Hotspot, da alle Einfügungen hier stattfinden, führt die gleichzeitige Einfügung zu einer Lückensperrenkonkurrenz. Die Erhöhung der ID erfordert eine Datenmigration. Das ist ziemlich mühsam!
5. Und wenn es um Unterdatenbanken und Untertabellen geht, ist es ziemlich mühsam, IDs automatisch zu erhöhen!3. Nachteile der Verwendung von uuid
Da uuid im Vergleich zur sequentiellen automatisch inkrementierenden ID unregelmäßig ist, ist der Wert der neuen Zeile nicht unbedingt größer als der Wert des vorherigen Primärschlüssels, sodass innodb dies nicht tun kann Um immer neue Zeilen am Ende des Index einzufügen, müssen Sie einen neuen geeigneten Ort für die neue Zeile finden, um neuen Platz zuzuweisen. Dieser Vorgang erfordert die Durchführung mehrerer zusätzlicher Vorgänge, und die Unordnung der Daten kann dazu führen, dass Daten verstreut werden, was zu den folgenden Problemen führt: 1 Die geschriebene Zielseite wurde wahrscheinlich auf die Festplatte geleert und aus dem Cache entfernt. oder wurde auch nicht in den Cache geladen, muss innodb die Zielseite vor dem Einfügen finden und von der Festplatte in den Speicher lesen, was zu vielen zufälligen IO-Vorgängen führt2 Da die Schreibvorgänge nicht in der richtigen Reihenfolge sind, muss innodb dies tun Führen Sie häufig Seitenaufteilungsvorgänge durch, um Platz für neue Zeilen zuzuweisen. Mindestens drei Seiten müssen für eine Einfügung geändert werden.3 Aufgrund der häufigen Seitenaufteilung werden die Seiten spärlich und unregelmäßig . Das Füllen führt letztendlich zu Datenfragmentierung und Fragmentierungsproblemen, aber Snowflake kann dieses Problem natürlich lösen. Die neu eingefügte ID muss meiner Meinung nach die größte sein Die Verwendung des Schneeflocken-Algorithmus ist eine sehr gute Wahl!
5. Verwenden Sie in der tatsächlichen Entwicklung so wenig Fremdschlüssel wie möglich. Primärschlüssel und Indizes können nicht nur die Geschwindigkeit des Datenabrufs optimieren, sondern Entwickler können auch andere Arbeit sparen.
Konfliktschwerpunkt: Ob das Datenbankdesign Fremdschlüssel erfordert. Hier gibt es zwei Fragen:
Eine ist, wie die Integrität und Konsistenz von Datenbankdaten sichergestellt werden kann.
Die zweite ist die Auswirkung der ersten auf die Leistung.
Hier sind zwei Standpunkte unterteilt, Pro und Contra, als Referenz!
1. Positiver Standpunkt
1. Die Datenbank selbst gewährleistet Datenkonsistenz und -integrität und ist zuverlässiger, da es für das Programm schwierig ist, 100 % Datenintegrität zu gewährleisten, und selbst wenn der Datenbankserver Fremdschlüssel verwendet Bei auftretenden Problemen kann die Datenkonsistenz und -integrität weitestgehend gewährleistet werden.
2. Das Datenbankdesign mit Primär- und Fremdschlüsseln kann die Lesbarkeit des ER-Diagramms verbessern, was beim Datenbankdesign sehr wichtig ist.
3. Die bis zu einem gewissen Grad durch Fremdschlüssel erläuterte Geschäftslogik macht das Design durchdacht, spezifisch und umfassend.
Es besteht eine Eins-zu-Viele-Beziehung zwischen Datenbank und Anwendung. Wenn das System größer wird, werden Anwendungen A und B möglicherweise durch unterschiedliche Entwicklungen entwickelt Mannschaften. Wie kann man koordinieren, um die Datenintegrität sicherzustellen, und wie geht man damit um, wenn nach einem Jahr eine neue C-Anwendung hinzugefügt wird?
2. Gegensätzliche Ansichten1. Eine Überbetonung oder Verwendung von Primärschlüsseln/Fremdschlüsseln erhöht die Entwicklungsschwierigkeiten und führt zu Problemen wie zu vielen Tabellen
3. Wenn keine Fremdschlüssel verwendet werden, ist die Datenverwaltung einfach, die Bedienung bequem und die Leistung hoch (Vorgänge wie Import und Export sind beim Einfügen, Aktualisieren und Löschen von Daten schneller)
Denken Sie nicht einmal an Fremdschlüssel in einer riesigen Datenbank. Stellen Sie sich vor, dass ein Programm jeden Tag Millionen von Datensätzen einfügen muss ist mehr als ein Feld. Bei Fremdschlüsseln erhöht sich die Anzahl der Scans exponentiell! Eines meiner Programme war in 3 Stunden abgeschlossen, wenn Fremdschlüssel hinzugefügt würden, würde es 28 Stunden dauern!
3. Fazit: In großen Systemen (geringe Leistungsanforderungen, hohe Sicherheitsanforderungen) sind in kleinen Systemen keine Fremdschlüssel erforderlich. was auch immer Es ist besser, Fremdschlüssel zu verwenden.
2. Verwenden Sie Fremdschlüssel angemessen und übertreiben Sie es nicht.
Um die Konsistenz und Integrität der Daten sicherzustellen, können Sie diese durch Programme steuern, ohne Fremdschlüssel zu verwenden. Zu diesem Zeitpunkt sollte eine Schicht geschrieben werden, um den Datenschutz zu implementieren, und dann kann über diese Schicht auf verschiedene Anwendungen der Datenbank zugegriffen werden.
Hinweis:
MySQL erlaubt die Verwendung von Fremdschlüsseln, aber aus Gründen der Integritätsprüfung wird diese Funktion in allen Tabellentypen außer dem InnoDB-Tabellentyp ignoriert. Das mag seltsam erscheinen, ist aber eigentlich ganz normal: Die Durchführung einer Integritätsprüfung nach jedem Einfügen, Aktualisieren und Löschen aller Fremdschlüssel in einer Datenbank ist ein zeit- und ressourcenintensiver Prozess, der sich auf die Leistung auswirken kann, insbesondere bei der Verarbeitung komplexer oder die Anzahl der Wicklungsanschlüsse. Daher können Benutzer anhand der Tabelle diejenige auswählen, die ihren spezifischen Anforderungen entspricht.
Wenn Sie also eine bessere Leistung benötigen und keine Integritätsprüfung benötigen, können Sie den Tabellentyp MyISAM verwenden. Wenn Sie eine Tabelle basierend auf referenzieller Integrität in MySQL erstellen und auf dieser Grundlage eine gute Leistung aufrechterhalten möchten, ist dies der Fall Die beste Wahl für die Tabellenstruktur ist der Typ innoDB
Das obige ist der detaillierte Inhalt vonWelche Einschränkungen gibt es bei MySQL?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 PHPs Fähigkeiten zur Verarbeitung von Big-Data-Strukturen
May 08, 2024 am 10:24 AM
PHPs Fähigkeiten zur Verarbeitung von Big-Data-Strukturen
May 08, 2024 am 10:24 AM
Fähigkeiten zur Verarbeitung von Big-Data-Strukturen: Chunking: Teilen Sie den Datensatz auf und verarbeiten Sie ihn in Blöcken, um den Speicherverbrauch zu reduzieren. Generator: Generieren Sie Datenelemente einzeln, ohne den gesamten Datensatz zu laden, geeignet für unbegrenzte Datensätze. Streaming: Lesen Sie Dateien oder fragen Sie Ergebnisse Zeile für Zeile ab, geeignet für große Dateien oder Remote-Daten. Externer Speicher: Speichern Sie die Daten bei sehr großen Datensätzen in einer Datenbank oder NoSQL.
 Wie optimiert man die MySQL-Abfrageleistung in PHP?
Jun 03, 2024 pm 08:11 PM
Wie optimiert man die MySQL-Abfrageleistung in PHP?
Jun 03, 2024 pm 08:11 PM
Die MySQL-Abfrageleistung kann durch die Erstellung von Indizes optimiert werden, die die Suchzeit von linearer Komplexität auf logarithmische Komplexität reduzieren. Verwenden Sie PreparedStatements, um SQL-Injection zu verhindern und die Abfrageleistung zu verbessern. Begrenzen Sie die Abfrageergebnisse und reduzieren Sie die vom Server verarbeitete Datenmenge. Optimieren Sie Join-Abfragen, einschließlich der Verwendung geeigneter Join-Typen, der Erstellung von Indizes und der Berücksichtigung der Verwendung von Unterabfragen. Analysieren Sie Abfragen, um Engpässe zu identifizieren. Verwenden Sie Caching, um die Datenbanklast zu reduzieren. Optimieren Sie den PHP-Code, um den Overhead zu minimieren.
 Wie verwende ich MySQL-Backup und -Wiederherstellung in PHP?
Jun 03, 2024 pm 12:19 PM
Wie verwende ich MySQL-Backup und -Wiederherstellung in PHP?
Jun 03, 2024 pm 12:19 PM
Das Sichern und Wiederherstellen einer MySQL-Datenbank in PHP kann durch Befolgen dieser Schritte erreicht werden: Sichern Sie die Datenbank: Verwenden Sie den Befehl mysqldump, um die Datenbank in eine SQL-Datei zu sichern. Datenbank wiederherstellen: Verwenden Sie den Befehl mysql, um die Datenbank aus SQL-Dateien wiederherzustellen.
 Wie füge ich mit PHP Daten in eine MySQL-Tabelle ein?
Jun 02, 2024 pm 02:26 PM
Wie füge ich mit PHP Daten in eine MySQL-Tabelle ein?
Jun 02, 2024 pm 02:26 PM
Wie füge ich Daten in eine MySQL-Tabelle ein? Mit der Datenbank verbinden: Stellen Sie mit mysqli eine Verbindung zur Datenbank her. Bereiten Sie die SQL-Abfrage vor: Schreiben Sie eine INSERT-Anweisung, um die einzufügenden Spalten und Werte anzugeben. Abfrage ausführen: Verwenden Sie die Methode query(), um die Einfügungsabfrage auszuführen. Bei Erfolg wird eine Bestätigungsmeldung ausgegeben.
 So beheben Sie den Fehler „mysql_native_password nicht geladen' unter MySQL 8.4
Dec 09, 2024 am 11:42 AM
So beheben Sie den Fehler „mysql_native_password nicht geladen' unter MySQL 8.4
Dec 09, 2024 am 11:42 AM
Eine der wichtigsten Änderungen, die in MySQL 8.4 (der neuesten LTS-Version von 2024) eingeführt wurden, besteht darin, dass das Plugin „MySQL Native Password“ nicht mehr standardmäßig aktiviert ist. Darüber hinaus entfernt MySQL 9.0 dieses Plugin vollständig. Diese Änderung betrifft PHP und andere Apps
 Wie verwende ich gespeicherte MySQL-Prozeduren in PHP?
Jun 02, 2024 pm 02:13 PM
Wie verwende ich gespeicherte MySQL-Prozeduren in PHP?
Jun 02, 2024 pm 02:13 PM
So verwenden Sie gespeicherte MySQL-Prozeduren in PHP: Verwenden Sie PDO oder die MySQLi-Erweiterung, um eine Verbindung zu einer MySQL-Datenbank herzustellen. Bereiten Sie die Anweisung zum Aufrufen der gespeicherten Prozedur vor. Führen Sie die gespeicherte Prozedur aus. Verarbeiten Sie die Ergebnismenge (wenn die gespeicherte Prozedur Ergebnisse zurückgibt). Schließen Sie die Datenbankverbindung.
 Wie erstelle ich eine MySQL-Tabelle mit PHP?
Jun 04, 2024 pm 01:57 PM
Wie erstelle ich eine MySQL-Tabelle mit PHP?
Jun 04, 2024 pm 01:57 PM
Das Erstellen einer MySQL-Tabelle mit PHP erfordert die folgenden Schritte: Stellen Sie eine Verbindung zur Datenbank her. Erstellen Sie die Datenbank, falls sie nicht vorhanden ist. Wählen Sie eine Datenbank aus. Tabelle erstellen. Führen Sie die Abfrage aus. Schließen Sie die Verbindung.
 Der Unterschied zwischen Oracle-Datenbank und MySQL
May 10, 2024 am 01:54 AM
Der Unterschied zwischen Oracle-Datenbank und MySQL
May 10, 2024 am 01:54 AM
Oracle-Datenbank und MySQL sind beide Datenbanken, die auf dem relationalen Modell basieren, aber Oracle ist in Bezug auf Kompatibilität, Skalierbarkeit, Datentypen und Sicherheit überlegen, während MySQL auf Geschwindigkeit und Flexibilität setzt und eher für kleine bis mittlere Datensätze geeignet ist. ① Oracle bietet eine breite Palette von Datentypen, ② bietet erweiterte Sicherheitsfunktionen, ③ ist für Anwendungen auf Unternehmensebene geeignet; ① MySQL unterstützt NoSQL-Datentypen, ② verfügt über weniger Sicherheitsmaßnahmen und ③ ist für kleine bis mittlere Anwendungen geeignet.
