

Was passiert, wenn der Redis-Speicher zu groß ist?

1 Die Hauptdatenbank ist ausgefallen
Werfen wir einen Blick auf den Notfallwiederherstellungsprozess nach einem Ausfall der Hauptdatenbank: wie unten gezeigt
# 🎜🎜 #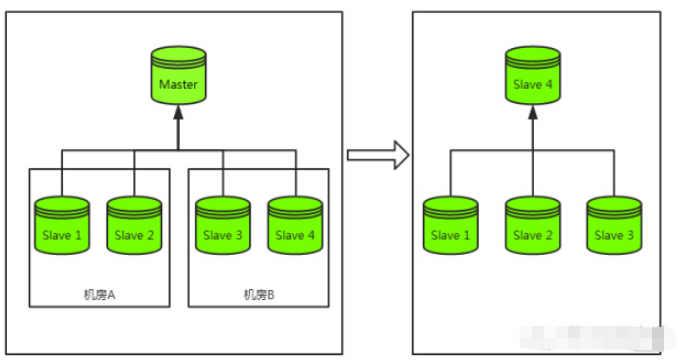
- Die Hauptdatenbank speichert ihre eigenen Daten auf der Festplatte
#🎜🎜 ## 🎜🎜#
Die Hauptbibliothek sendet die RDB-Datei an die Slave-Bibliothek - Laden aus der Bibliothek starten
- # 🎜🎜##🎜🎜 #Starten Sie den Download nach dem Laden fort und beginnen Sie gleichzeitig mit der Bereitstellung von Diensten
- Offensichtlich ist das Speichervolumen von Redis in diesem Prozess umso größer Je länger die einzelnen oben genannten Schritte dauern, desto höher sind die tatsächlichen Testdaten (wir glauben, dass unsere Maschinenleistung besser ist):
Sie Wenn die Daten 20 G erreichen, wurde die Wiederherstellungszeit der Slave-Bibliothek auf fast 20 Minuten verlängert. Wenn 10 Slave-Bibliotheken vorhanden sind, dauert die Wiederherstellung nacheinander insgesamt 200 Minuten Die Bibliothek ist derzeit für eine große Anzahl von Leseanfragen verantwortlich. Können Sie eine so lange Wiederherstellungszeit ertragen? gleichzeitig wiederholt werden? Dies liegt daran, dass, wenn alle Slave-Bibliotheken gleichzeitig RDB-Dateien von der Master-Bibliothek anfordern, die Netzwerkkarte der Master-Bibliothek sofort nach dem Volllaufen in einen Zustand übergeht, in dem sie keine Dienste mehr normal bereitstellen kann. Zu diesem Zeitpunkt stürzt die Hauptdatenbank erneut ab, was die Sache nur noch schlimmer macht.
Natürlich können wir die Slave-Datenbanken stapelweise wiederherstellen, beispielsweise in Zweiergruppen, sodass sich die Wiederherstellungszeit aller Slave-Datenbanken nur von 200 Minuten auf 100 Minuten verkürzt Eine fünfzigstufige Lösung zu hundert Schritten? 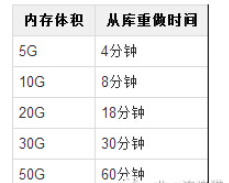
2 Kapazitätserweiterungsproblem
Normalerweise kommt es zu einem plötzlichen Anstieg des Verkehrsaufkommens, bevor die Ursache gefunden wird um die Kapazität zu erweitern. Laut der Tabelle in Szenario 1 dauert die Erweiterung einer 20G-Redis-Slave-Datenbank in diesem kritischen Moment möglicherweise . .3 Ein schlechtes Netzwerk führt zur Neuerstellung der Slave-Bibliothek und löst schließlich eine Lawine aus
Das größte Problem in diesem Szenario ist der Unterschied zwischen den Die Synchronisation der Hauptbibliothek und der Slave-Bibliothek ist unterbrochen, und zu diesem Zeitpunkt ist es wahrscheinlich, dass die Slave-Bibliothek noch Schreibanforderungen akzeptiert. Wenn die Unterbrechungszeit also zu lang ist, wird der Synchronisationspuffer wahrscheinlich überschrieben. Zu diesem Zeitpunkt ist die letzte Synchronisationsposition der Slave-Bibliothek verloren gegangen, obwohl sich die Master-Bibliothek nicht geändert hat, da die Synchronisationsposition der Slave-Bibliothek verloren gegangen ist 1, 2 und 3 in Frage 1. 4 Schritte. Wenn die Speichergröße der Hauptbibliothek zu diesem Zeitpunkt zu groß ist, ist die Redo-Geschwindigkeit der Slave-Bibliothek sehr langsam und die an die Slave-Bibliothek gesendeten Leseanforderungen werden gleichzeitig stark beeinträchtigt Die übertragene RDB-Datei ist zu groß und die Netzwerkkarte der Hauptbibliothek wird für lange Zeit stark beeinträchtigt.4 Je größer der Speicher, desto länger blockiert der Vorgang, der die Persistenz auslöst, den Hauptthread
Redis ist ein Single-Threaded-In-Memory Wenn Redis zeitaufwändige Vorgänge ausführen muss, wird dafür ein neuer Prozess erstellt, z. B. bgsave und bgrewriteaof. Beim Forken eines neuen Prozesses muss der gemeinsam nutzbare Dateninhalt zwar nicht kopiert werden, die Speicherseitentabelle des vorherigen Prozessbereichs wird jedoch vom Hauptthread kopiert und blockiert alle Lese- und Schreibvorgänge Je länger es dauert, desto höher ist die Speichernutzung. Beispiel: Bei Redis mit 20 GB Speicher benötigt bgsave etwa 750 ms, um die Speicherseitentabelle zu kopieren, und der Redis-Hauptthread wird ebenfalls 750 ms lang blockiert.
Lösung
Die Lösung besteht natürlich darin, den Speicherverbrauch zu reduzieren. Unter normalen Umständen tun wir Folgendes: #🎜 🎜 #
1 Legen Sie die Ablaufzeit festLegen Sie die Ablaufzeit für zeitkritische Schlüssel fest und reduzieren Sie die Speicherauswirkung abgelaufener Schlüssel durch die Redis-eigene Reinigung abgelaufener Schlüssel Strategie Gleichzeitig kann es auch geschäftliche Probleme reduzieren und muss nicht regelmäßig gereinigt werden.
Das ist einfach Unsinn, aber gibt es jemanden, dem es genauso geht wie uns?
3 Unnötige Daten rechtzeitig bereinigen
Zum Beispiel überträgt ein Redis die Daten von 3 Unternehmen und nach einer gewissen Zeit von 2 Unternehmen gehen offline und bereinigen dann einfach die relevanten Daten dieser beiden Unternehmen.
4 Versuchen Sie, die Daten so weit wie möglich zu komprimieren Achten Sie auf das Speicherwachstum und suchen Sie nach großen Kapazitätsschlüsseln
Ob Sie ein DBA oder ein Entwickler sind, wenn Sie Redis verwenden, müssen Sie auf den Speicher achten, sonst sind Sie tatsächlich inkompetent. Hier können Sie analysieren, welche Schlüssel in Redis vorhanden sind Beispiele sind relativ groß, um dem Unternehmen dabei zu helfen, abnormale Schlüssel schnell zu finden (nicht). Schlüssel, von denen erwartet wird, dass sie wachsen, sind oft die Ursache von Problemen)
6 pika
Wenn Sie wirklich nicht so müde sein wollen, dann Migrieren Sie das Unternehmen auf das neue Open-Source-Pika, damit Sie dem Speicher nicht zu viel Aufmerksamkeit schenken müssen. Redis-Speicher ist auch vorhanden Die dadurch verursachten Probleme sind kein Problem mehr.
Das obige ist der detaillierte Inhalt vonWas passiert, wenn der Redis-Speicher zu groß ist?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 So erstellen Sie den Redis -Clustermodus
Apr 10, 2025 pm 10:15 PM
So erstellen Sie den Redis -Clustermodus
Apr 10, 2025 pm 10:15 PM
Der Redis -Cluster -Modus bietet Redis -Instanzen durch Sharding, die Skalierbarkeit und Verfügbarkeit verbessert. Die Bauschritte sind wie folgt: Erstellen Sie ungerade Redis -Instanzen mit verschiedenen Ports; Erstellen Sie 3 Sentinel -Instanzen, Monitor -Redis -Instanzen und Failover; Konfigurieren von Sentinel -Konfigurationsdateien, Informationen zur Überwachung von Redis -Instanzinformationen und Failover -Einstellungen hinzufügen. Konfigurieren von Redis -Instanzkonfigurationsdateien, aktivieren Sie den Cluster -Modus und geben Sie den Cluster -Informationsdateipfad an. Erstellen Sie die Datei nodes.conf, die Informationen zu jeder Redis -Instanz enthält. Starten Sie den Cluster, führen Sie den Befehl erstellen aus, um einen Cluster zu erstellen und die Anzahl der Replikate anzugeben. Melden Sie sich im Cluster an, um den Befehl cluster info auszuführen, um den Clusterstatus zu überprüfen. machen
 So löschen Sie Redis -Daten
Apr 10, 2025 pm 10:06 PM
So löschen Sie Redis -Daten
Apr 10, 2025 pm 10:06 PM
So löschen Sie Redis -Daten: Verwenden Sie den Befehl Flushall, um alle Schlüsselwerte zu löschen. Verwenden Sie den Befehl flushdb, um den Schlüsselwert der aktuell ausgewählten Datenbank zu löschen. Verwenden Sie SELECT, um Datenbanken zu wechseln, und löschen Sie dann FlushDB, um mehrere Datenbanken zu löschen. Verwenden Sie den Befehl del, um einen bestimmten Schlüssel zu löschen. Verwenden Sie das Redis-Cli-Tool, um die Daten zu löschen.
 So lesen Sie Redis -Warteschlange
Apr 10, 2025 pm 10:12 PM
So lesen Sie Redis -Warteschlange
Apr 10, 2025 pm 10:12 PM
Um eine Warteschlange aus Redis zu lesen, müssen Sie den Warteschlangenname erhalten, die Elemente mit dem Befehl LPOP lesen und die leere Warteschlange verarbeiten. Die spezifischen Schritte sind wie folgt: Holen Sie sich den Warteschlangenname: Nennen Sie ihn mit dem Präfix von "Warteschlange:" wie "Warteschlangen: My-Queue". Verwenden Sie den Befehl LPOP: Wischen Sie das Element aus dem Kopf der Warteschlange aus und geben Sie seinen Wert zurück, z. B. die LPOP-Warteschlange: my-queue. Verarbeitung leerer Warteschlangen: Wenn die Warteschlange leer ist, gibt LPOP NIL zurück, und Sie können überprüfen, ob die Warteschlange existiert, bevor Sie das Element lesen.
 So verwenden Sie den Befehl Redis
Apr 10, 2025 pm 08:45 PM
So verwenden Sie den Befehl Redis
Apr 10, 2025 pm 08:45 PM
Die Verwendung der REDIS -Anweisung erfordert die folgenden Schritte: Öffnen Sie den Redis -Client. Geben Sie den Befehl ein (Verbschlüsselwert). Bietet die erforderlichen Parameter (variiert von der Anweisung bis zur Anweisung). Drücken Sie die Eingabetaste, um den Befehl auszuführen. Redis gibt eine Antwort zurück, die das Ergebnis der Operation anzeigt (normalerweise in Ordnung oder -err).
 So verwenden Sie Redis Lock
Apr 10, 2025 pm 08:39 PM
So verwenden Sie Redis Lock
Apr 10, 2025 pm 08:39 PM
Um die Operationen zu sperren, muss die Sperre durch den Befehl setNX erfasst werden und dann den Befehl Ablauf verwenden, um die Ablaufzeit festzulegen. Die spezifischen Schritte sind: (1) Verwenden Sie den Befehl setNX, um zu versuchen, ein Schlüsselwertpaar festzulegen; (2) Verwenden Sie den Befehl Ablauf, um die Ablaufzeit für die Sperre festzulegen. (3) Verwenden Sie den Befehl Del, um die Sperre zu löschen, wenn die Sperre nicht mehr benötigt wird.
 So lesen Sie den Quellcode von Redis
Apr 10, 2025 pm 08:27 PM
So lesen Sie den Quellcode von Redis
Apr 10, 2025 pm 08:27 PM
Der beste Weg, um Redis -Quellcode zu verstehen, besteht darin, Schritt für Schritt zu gehen: Machen Sie sich mit den Grundlagen von Redis vertraut. Wählen Sie ein bestimmtes Modul oder eine bestimmte Funktion als Ausgangspunkt. Beginnen Sie mit dem Einstiegspunkt des Moduls oder der Funktion und sehen Sie sich die Codezeile nach Zeile an. Zeigen Sie den Code über die Funktionsaufrufkette an. Kennen Sie die von Redis verwendeten Datenstrukturen. Identifizieren Sie den von Redis verwendeten Algorithmus.
 So verwenden Sie die Befehlszeile der Redis
Apr 10, 2025 pm 10:18 PM
So verwenden Sie die Befehlszeile der Redis
Apr 10, 2025 pm 10:18 PM
Verwenden Sie das Redis-Befehlszeilen-Tool (REDIS-CLI), um Redis in folgenden Schritten zu verwalten und zu betreiben: Stellen Sie die Adresse und den Port an, um die Adresse und den Port zu stellen. Senden Sie Befehle mit dem Befehlsnamen und den Parametern an den Server. Verwenden Sie den Befehl Hilfe, um Hilfeinformationen für einen bestimmten Befehl anzuzeigen. Verwenden Sie den Befehl zum Beenden, um das Befehlszeilenwerkzeug zu beenden.
 So konfigurieren Sie die Ausführungszeit der Lua -Skript in CentOS Redis
Apr 14, 2025 pm 02:12 PM
So konfigurieren Sie die Ausführungszeit der Lua -Skript in CentOS Redis
Apr 14, 2025 pm 02:12 PM
Auf CentOS -Systemen können Sie die Ausführungszeit von LuA -Skripten einschränken, indem Sie Redis -Konfigurationsdateien ändern oder Befehle mit Redis verwenden, um zu verhindern, dass bösartige Skripte zu viele Ressourcen konsumieren. Methode 1: Ändern Sie die Redis -Konfigurationsdatei und suchen Sie die Redis -Konfigurationsdatei: Die Redis -Konfigurationsdatei befindet sich normalerweise in /etc/redis/redis.conf. Konfigurationsdatei bearbeiten: Öffnen Sie die Konfigurationsdatei mit einem Texteditor (z. B. VI oder Nano): Sudovi/etc/redis/redis.conf Setzen Sie die LUA -Skriptausführungszeit.
