

So erstellen Sie einen Redis-Cluster unter Centos

Must-have-Tools:
redis-3.0.0.tar
redis-3.0.0.gem (Ruby und Redis-Schnittstelle)
Analyse:
Zuallererst erfordert die Anzahl der Cluster eine Basis Instanzen für Clustering).
Wird auf einem Server betrieben, sodass nur 6 verschiedene Portnummern erforderlich sind. Dies sind: 7001, 7002, 7003, 7004, 7005, 7006.
Schritte:
1. Laden Sie redis-3.0.0.tar auf den Server hoch (geben Sie Ihr eigenes Softwareverzeichnis an), entpacken Sie redis- 3.0.0.tar.
2. Installieren Sie die C-Sprachumgebung (nach der Installation von Centos wird sie mit der C-Sprachumgebung geliefert)
yum install gcc-c++
3. Geben Sie das Redis-3.0.0-Verzeichnis ein #🎜🎜 #
make
make install prefix=/usr/local/redis
5. Überprüfen Sie, ob die Installation erfolgreich ist (das bin-Verzeichnis wird angezeigt)
#🎜🎜 ## 🎜🎜#
6. Starten Sie Redis im Frontend (geben Sie das Bin-Verzeichnis im Bild oben ein) ./redis-server (offen) #🎜🎜 #
./redis-server (offen) #🎜🎜 #
 Ändern Sie die Datei redis.conf und ändern Sie daemonize auf „yes“. Verwenden Sie zuerst vim redis.conf
Ändern Sie die Datei redis.conf und ändern Sie daemonize auf „yes“. Verwenden Sie zuerst vim redis.conf
#. 🎜 🎜#
Verwenden Sie den Befehl Backend, um Redis zu starten Start ist erfolgreich#🎜 🎜#
So deaktivieren Sie den Backend-Start: 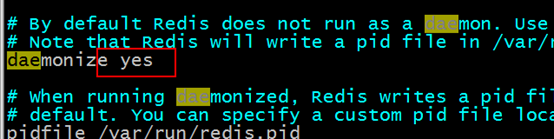
./redis-cli shutdown
Ruby installieren
yum install ruby yum install rubygems
Laden Sie die folgenden Dateien auf das Linux-System hoch
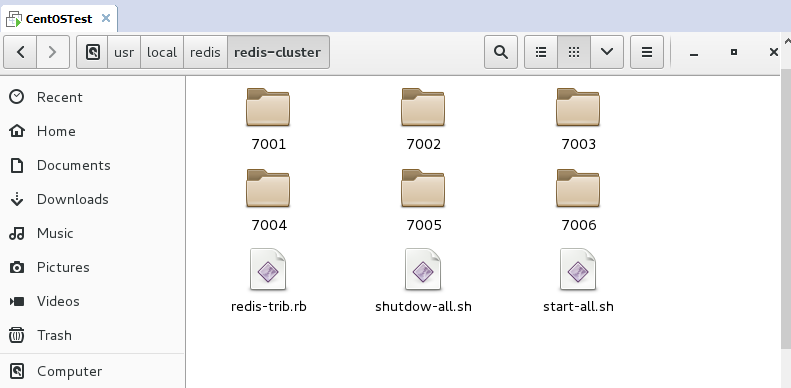
Voraussetzung: Erstellen Sie zunächst ein neues Redis-Cluster-Verzeichnis
#🎜🎜 ## 🎜🎜#Zum Aufbau eines Clusters sind mindestens 3 Hosts erforderlich. Wenn jeder Host mit einer Slave-Maschine konfiguriert ist, sind mindestens 6 Maschinen erforderlich. Das Portdesign ist wie folgt: 7001-7006
Schritt 1: Kopieren Sie eine 7001-Maschine
Geben Sie /usr/local/redis/ ein. Verzeichnis und führen Sie cp bin ./redis-cluster/7001 –r
Schritt 2: Wenn persistente Dateien vorhanden sind, löschen Sie sie aus
rm -rf appendonly.aof dump.rdb
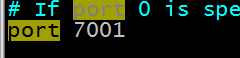
Schritt 3: Cluster-Parameter festlegen#🎜🎜 #

Schritt 5: 7002 kopieren - 7006-Maschine
gibt die Verzeichnisstruktur unter meinem Desktop-System an:
Als nächstes richten Sie den Ein-Klick-Start aller Redis ein oder Schließen Sie die Redis-Gruppe: Erstellen Sie zunächst eine neue Datei. Sie können vim verwenden, um eine Datei zu öffnen, die nicht vorhanden ist, und diese dann speichern. (Start-all.sh und Shutdown-all.sh im Bild oben sind die, die ich erstellt habe)
Erstellen Sie zunächst eine neue Datei. Sie können vim verwenden, um eine Datei zu öffnen, die nicht vorhanden ist, und diese dann speichern. (Start-all.sh und Shutdown-all.sh im Bild oben sind die, die ich erstellt habe)
start-all.sh:
cd 7001 ./redis-server redis.conf cd .. cd 7002 ./redis-server redis.conf cd .. cd 7003 ./redis-server redis.conf cd .. cd 7004 ./redis-server redis.conf cd .. cd 7005 ./redis-server redis.conf cd .. cd 7006 ./redis-server redis.conf cd ..
shutdow-all. sh:# 🎜🎜#
cd 7001 ./redis-cli -p 7001 shutdown cd .. cd 7002 ./redis-cli -p 7002 shutdown cd .. cd 7003 ./redis-cli -p 7003 shutdown cd .. cd 7004 ./redis-cli -p 7004 shutdown cd .. cd 7005 ./redis-cli -p 7005 shutdown cd .. cd 7006 ./redis-cli -p 7006 shutdown cd ..
 Als nächstes ändern Sie die Berechtigungen dieser beiden Dateien und legen sie als startbare Skriptdateien fest
Als nächstes ändern Sie die Berechtigungen dieser beiden Dateien und legen sie als startbare Skriptdateien festchmod u+x start-all.sh chmod u+x shutdown-all.sh
Als nächstes verwenden Sie Ruby, um diese Cluster zu verbinden und zu verwalten# 🎜🎜#
/redis-trib.rb create --replicas 1 192.168.78.133:7001 192.168.78.133:7002 192.168.78.133:7003 192.168.78.133:7004 192. 168.78.133:7005 192.168.78.133:7006#🎜 🎜## 🎜🎜# erscheint:connecting to node 192.168.242.137:7001: ok connecting to node 192.168.242.137:7002: ok connecting to node 192.168.242.137:7003: ok connecting to node 192.168.242.137:7004: ok connecting to node 192.168.242.137:7005: ok connecting to node 192.168.242.137:7006: ok >>> performing hash slots allocation on 6 nodes... using 3 masters: 192.168.242.137:7001 192.168.242.137:7002 192.168.242.137:7003 adding replica 192.168.242.137:7004 to 192.168.242.137:7001 adding replica 192.168.242.137:7005 to 192.168.242.137:7002 adding replica 192.168.242.137:7006 to 192.168.242.137:7003 m: 8240cd0fe6d6f842faa42b0174fe7c5ddcf7ae24 192.168.242.137:7001 slots:0-5460 (5461 slots) master m: 4f52a974f64343fd9f1ee0388490b3c0647a4db7 192.168.242.137:7002 slots:5461-10922 (5462 slots) master m: cb7c5def8f61df2016b38972396a8d1f349208c2 192.168.242.137:7003 slots:10923-16383 (5461 slots) master s: 66adf006fed43b3b5e499ce2ff1949a756504a16 192.168.242.137:7004 replicates 8240cd0fe6d6f842faa42b0174fe7c5ddcf7ae24 s: cbb0c9bc4b27dd85511a7ef2d01bec90e692793b 192.168.242.137:7005 replicates 4f52a974f64343fd9f1ee0388490b3c0647a4db7 s: a908736eadd1cd06e86fdff8b2749a6f46b38c00 192.168.242.137:7006 replicates cb7c5def8f61df2016b38972396a8d1f349208c2 can i set the above configuration? (type 'yes' to accept): yes >>> nodes configuration updated >>> assign a different config epoch to each node >>> sending cluster meet messages to join the cluster waiting for the cluster to join.. >>> performing cluster check (using node 192.168.242.137:7001) m: 8240cd0fe6d6f842faa42b0174fe7c5ddcf7ae24 192.168.242.137:7001 slots:0-5460 (5461 slots) master m: 4f52a974f64343fd9f1ee0388490b3c0647a4db7 192.168.242.137:7002 slots:5461-10922 (5462 slots) master m: cb7c5def8f61df2016b38972396a8d1f349208c2 192.168.242.137:7003 slots:10923-16383 (5461 slots) master m: 66adf006fed43b3b5e499ce2ff1949a756504a16 192.168.242.137:7004 slots: (0 slots) master replicates 8240cd0fe6d6f842faa42b0174fe7c5ddcf7ae24 m: cbb0c9bc4b27dd85511a7ef2d01bec90e692793b 192.168.242.137:7005 slots: (0 slots) master replicates 4f52a974f64343fd9f1ee0388490b3c0647a4db7 m: a908736eadd1cd06e86fdff8b2749a6f46b38c00 192.168.242.137:7006 slots: (0 slots) master replicates cb7c5def8f61df2016b38972396a8d1f349208c2 [ok] all nodes agree about slots configuration. >>> check for open slots... >>> check slots coverage... [ok] all 16384 slots covered.
 Testen Sie es, geben Sie das Verzeichnis 7001 ein und führen Sie Folgendes aus: ./redis-cli -h 192.168.242.137 -p 7001 –c
Testen Sie es, geben Sie das Verzeichnis 7001 ein und führen Sie Folgendes aus: ./redis-cli -h 192.168.242.137 -p 7001 –c
Das obige ist der detaillierte Inhalt vonSo erstellen Sie einen Redis-Cluster unter Centos. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1389
1389
 52
52

 So optimieren Sie die CentOS -HDFS -Konfiguration
Apr 14, 2025 pm 07:15 PM
So optimieren Sie die CentOS -HDFS -Konfiguration
Apr 14, 2025 pm 07:15 PM
Verbesserung der HDFS -Leistung bei CentOS: Ein umfassender Optimierungshandbuch zur Optimierung von HDFs (Hadoop Distributed Dateisystem) auf CentOS erfordert eine umfassende Berücksichtigung der Hardware-, Systemkonfigurations- und Netzwerkeinstellungen. Dieser Artikel enthält eine Reihe von Optimierungsstrategien, mit denen Sie die HDFS -Leistung verbessern können. 1. Hardware -Upgrade und Auswahlressourcenerweiterung: Erhöhen Sie die CPU-, Speicher- und Speicherkapazität des Servers so weit wie möglich. Hochleistungs-Hardware: Übernimmt Hochleistungs-Netzwerkkarten und -Schalter, um den Netzwerkdurchsatz zu verbessern. 2. Systemkonfiguration Fine-Tuning-Kernel-Parameteranpassung: Modify /etc/sysctl.conf Datei, um die Kernelparameter wie TCP-Verbindungsnummer, Dateihandelsnummer und Speicherverwaltung zu optimieren. Passen Sie beispielsweise den TCP -Verbindungsstatus und die Puffergröße an
 CentOS stoppt die Wartung 2024
Apr 14, 2025 pm 08:39 PM
CentOS stoppt die Wartung 2024
Apr 14, 2025 pm 08:39 PM
CentOS wird 2024 geschlossen, da seine stromaufwärts gelegene Verteilung RHEL 8 geschlossen wurde. Diese Abschaltung wirkt sich auf das CentOS 8 -System aus und verhindert, dass es weiterhin Aktualisierungen erhalten. Benutzer sollten eine Migration planen, und empfohlene Optionen umfassen CentOS Stream, Almalinux und Rocky Linux, um das System sicher und stabil zu halten.
 So überprüfen Sie die CentOS -HDFS -Konfiguration
Apr 14, 2025 pm 07:21 PM
So überprüfen Sie die CentOS -HDFS -Konfiguration
Apr 14, 2025 pm 07:21 PM
Vollständige Anleitung zur Überprüfung der HDFS -Konfiguration in CentOS -Systemen In diesem Artikel wird die Konfiguration und den laufenden Status von HDFS auf CentOS -Systemen effektiv überprüft. Die folgenden Schritte helfen Ihnen dabei, das Setup und den Betrieb von HDFs vollständig zu verstehen. Überprüfen Sie die Hadoop -Umgebungsvariable: Stellen Sie zunächst sicher, dass die Hadoop -Umgebungsvariable korrekt eingestellt ist. Führen Sie im Terminal den folgenden Befehl aus, um zu überprüfen, ob Hadoop ordnungsgemäß installiert und konfiguriert ist: Hadoopsion-Check HDFS-Konfigurationsdatei: Die Kernkonfigurationsdatei von HDFS befindet sich im/etc/hadoop/conf/verzeichnis, wobei core-site.xml und hdfs-site.xml von entscheidender Bedeutung sind. verwenden
 CentOS -Konfiguration IP -Adresse
Apr 14, 2025 pm 09:06 PM
CentOS -Konfiguration IP -Adresse
Apr 14, 2025 pm 09:06 PM
Steps to configure IP address in CentOS: View the current network configuration: ip addr Edit the network configuration file: sudo vi /etc/sysconfig/network-scripts/ifcfg-eth0 Change IP address: Edit IPADDR= Line changes the subnet mask and gateway (optional): Edit NETMASK= and GATEWAY= Lines Restart the network service: sudo systemctl restart network verification IP address: ip addr
 CentOS Shutdown -Befehlszeile
Apr 14, 2025 pm 09:12 PM
CentOS Shutdown -Befehlszeile
Apr 14, 2025 pm 09:12 PM
Der Befehl centOS stilldown wird heruntergefahren und die Syntax wird von [Optionen] ausgeführt [Informationen]. Zu den Optionen gehören: -h das System sofort stoppen; -P schalten Sie die Leistung nach dem Herunterfahren aus; -r neu starten; -t Wartezeit. Zeiten können als unmittelbar (jetzt), Minuten (Minuten) oder als bestimmte Zeit (HH: MM) angegeben werden. Hinzugefügten Informationen können in Systemmeldungen angezeigt werden.
 CentOS installieren MySQL
Apr 14, 2025 pm 08:09 PM
CentOS installieren MySQL
Apr 14, 2025 pm 08:09 PM
Die Installation von MySQL auf CentOS umfasst die folgenden Schritte: Hinzufügen der entsprechenden MySQL Yum -Quelle. Führen Sie den Befehl mySQL-server aus, um den MySQL-Server zu installieren. Verwenden Sie den Befehl mySQL_SECURE_INSTALLATION, um Sicherheitseinstellungen vorzunehmen, z. B. das Festlegen des Stammbenutzerkennworts. Passen Sie die MySQL -Konfigurationsdatei nach Bedarf an. Tune MySQL -Parameter und optimieren Sie Datenbanken für die Leistung.
 Welche Schritte sind erforderlich, um CentOs in HDFs zu konfigurieren
Apr 14, 2025 pm 06:42 PM
Welche Schritte sind erforderlich, um CentOs in HDFs zu konfigurieren
Apr 14, 2025 pm 06:42 PM
Das Erstellen eines Hadoop -verteilten Dateisystems (HDFS) auf einem CentOS -System erfordert mehrere Schritte. Dieser Artikel enthält einen kurzen Konfigurationshandbuch. 1. Bereiten Sie sich auf die Installation von JDK in der frühen Stufe vor: Installieren Sie JavadevelopmentKit (JDK) auf allen Knoten, und die Version muss mit Hadoop kompatibel sein. Das Installationspaket kann von der offiziellen Oracle -Website heruntergeladen werden. Konfiguration der Umgebungsvariablen: Bearbeiten /etc /Profildatei, setzen Sie Java- und Hadoop -Umgebungsvariablen, damit das System den Installationspfad von JDK und Hadoop ermittelt. 2. Sicherheitskonfiguration: SSH-Kennwortfreie Anmeldung zum Generieren von SSH-Schlüssel: Verwenden Sie den Befehl ssh-keygen auf jedem Knoten
 So installieren Sie Redis in CentOS7
Apr 14, 2025 pm 08:21 PM
So installieren Sie Redis in CentOS7
Apr 14, 2025 pm 08:21 PM
Laden Sie das Quellcodepaket von der offiziellen Redis -Quelle herunter, um es zu kompilieren und zu installieren, um die neueste und stabile Version zu gewährleisten, und kann auf personalisierte Weise angepasst werden. Die spezifischen Schritte sind wie folgt: Aktualisieren Sie die Liste der Softwarepakets und erstellen
