
 Technologie-Peripheriegeräte
KI
Die LLM-Inferenz ist dreimal schneller! Microsoft veröffentlicht LLM Accelerator: Verwendung von Referenztext zur Erzielung verlustfreier Beschleunigung
Technologie-Peripheriegeräte
KI
Die LLM-Inferenz ist dreimal schneller! Microsoft veröffentlicht LLM Accelerator: Verwendung von Referenztext zur Erzielung verlustfreier Beschleunigung
Die LLM-Inferenz ist dreimal schneller! Microsoft veröffentlicht LLM Accelerator: Verwendung von Referenztext zur Erzielung verlustfreier Beschleunigung

Mit der rasanten Entwicklung der Technologie der künstlichen Intelligenz werden nach und nach neue Produkte und Technologien wie ChatGPT, New Bing und GPT-4 veröffentlicht. Grundlegende große Modelle werden in vielen Anwendungen eine immer wichtigere Rolle spielen.
Die meisten aktuellen großen Sprachmodelle sind autoregressive Modelle. Autoregression bedeutet, dass das Modell bei der Ausgabe häufig eine wortweise Ausgabe verwendet, dh bei der Ausgabe jedes Wortes muss das Modell die zuvor ausgegebenen Wörter als Eingabe verwenden. Dieser autoregressive Modus schränkt normalerweise die volle Nutzung paralleler Beschleuniger während der Ausgabe ein.
In vielen Anwendungsszenarien weist die Ausgabe eines großen Modells häufig große Ähnlichkeit mit einigen Referenztexten auf, beispielsweise in den folgenden drei häufigen Szenarien:
1. Retrieval-Enhanced-Generierung
Wenn Suchanwendungen wie New Bing reagieren auf Benutzereingaben. Sie geben zunächst einige Informationen im Zusammenhang mit der Benutzereingabe zurück, fassen dann die abgerufenen Informationen mithilfe eines Sprachmodells zusammen und beantworten dann die Benutzereingaben. In diesem Szenario enthält die Ausgabe des Modells häufig eine große Anzahl von Textfragmenten aus den Suchergebnissen.
2. Zwischengespeicherte Generierung verwenden
Beim groß angelegten Einsatz von Sprachmodellen werden historische Eingaben und Ausgaben zwischengespeichert. Bei der Verarbeitung neuer Eingaben sucht die Abrufanwendung im Cache nach ähnlichen Eingaben. Daher ist die Ausgabe des Modells häufig der entsprechenden Ausgabe im Cache sehr ähnlich.
3. Generierung in Multi-Turn-Konversationen
Bei der Verwendung von Anwendungen wie ChatGPT stellen Benutzer häufig wiederholte Änderungsanfragen basierend auf der Ausgabe des Modells. In diesem Dialogszenario mit mehreren Runden weisen die mehreren Ausgaben des Modells häufig nur geringe Änderungen und einen hohen Wiederholungsgrad auf.
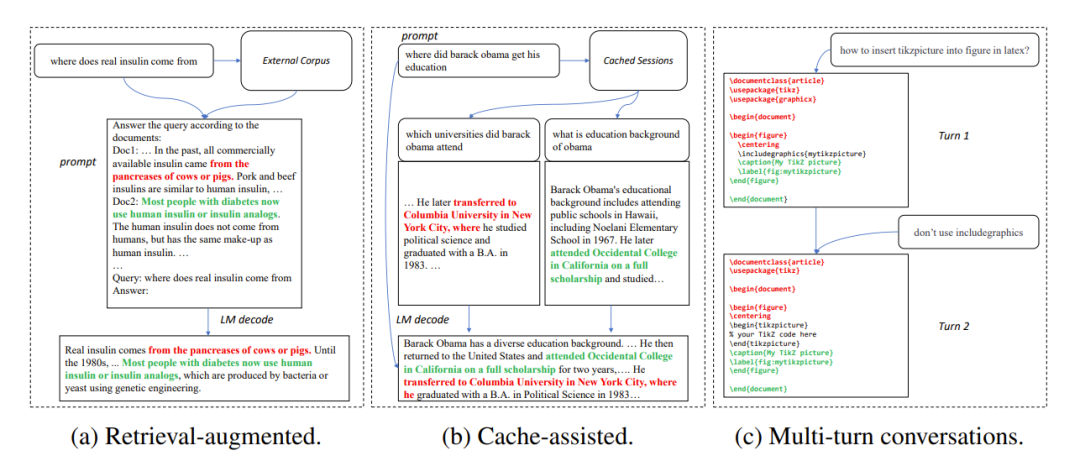
Abbildung 1: Häufige Szenarien, in denen die Ausgabe eines großen Modells dem Referenztext ähnelt
Basierend auf den obigen Beobachtungen verwendeten die Forscher die Wiederholbarkeit des Referenztextes und des Referenzmodells Ausgabe als Durchbruch in der Autoregression Wir konzentrieren uns auf den Engpass und hoffen, die Nutzung paralleler Beschleuniger zu verbessern und das Denken großer Sprachmodelle zu beschleunigen. Anschließend schlagen wir eine LLM Accelerator-Methode vor, die die Wiederholung von Ausgabe und Referenztext verwendet, um mehrere Wörter in einem Schritt auszugeben .
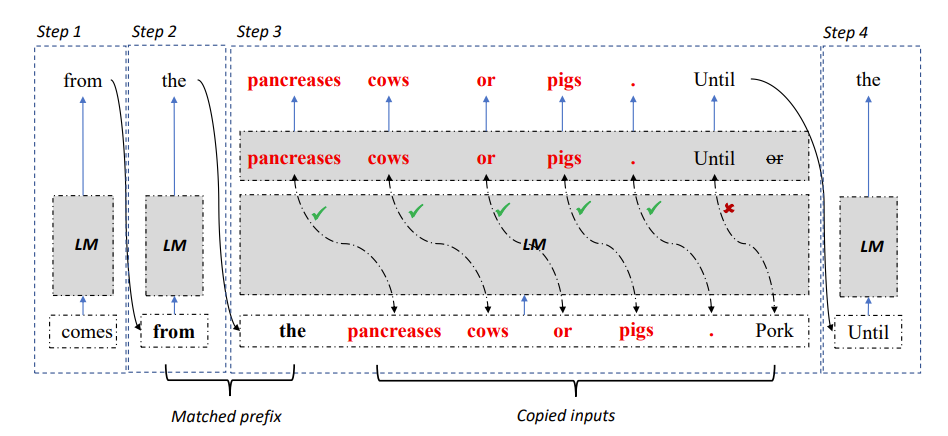
Abbildung 2: LLM Accelerator-Dekodierungsalgorithmus
Konkret muss das Modell bei jedem Dekodierungsschritt zunächst mit den vorhandenen Ausgabeergebnissen und dem Referenztext abgeglichen werden, wenn eine Referenz im Text gefunden wird Wenn der Wert mit der vorhandenen Ausgabe übereinstimmt, wird das Modell wahrscheinlich weiterhin den vorhandenen Referenztext ausgeben.
Daher fügten die Forscher nachfolgende Wörter des Referenztextes als Eingabe in das Modell hinzu, sodass ein Dekodierungsschritt mehrere Wörter ausgeben kann.
Um sicherzustellen, dass die Eingabe und Ausgabe korrekt sind, verglichen die Forscher die vom Modell ausgegebenen Wörter weiter mit den eingegebenen Wörtern aus dem Referenzdokument. Wenn die beiden inkonsistent sind, werden die falschen Eingabe- und Ausgabeergebnisse verworfen.
Die obige Methode kann sicherstellen, dass die Dekodierungsergebnisse vollständig mit der Basismethode übereinstimmen, und kann die Anzahl der Ausgabewörter in jedem Dekodierungsschritt erhöhen, wodurch eine verlustfreie Beschleunigung großer Modellinferenzen erreicht wird.
LLM Accelerator erfordert keine zusätzlichen Hilfsmodelle, ist einfach zu verwenden und kann problemlos in verschiedenen Anwendungsszenarien eingesetzt werden.
Papierlink: https://arxiv.org/pdf/2304.04487.pdf
Projektlink: https://github.com/microsoft/LMOps
Mit LLM Accelerator, Es gibt zwei Hyperparameter, die angepasst werden müssen.
Erstens die Anzahl der übereinstimmenden Wörter zwischen der Ausgabe, die zum Auslösen des Übereinstimmungsmechanismus und dem Referenztext erforderlich ist: Je länger die Anzahl der übereinstimmenden Wörter ist, desto genauer ist sie, wodurch besser sichergestellt werden kann, dass die Wörter aus dem Referenztext kopiert werden korrekte Ausgabe, Reduzierung unnötiger Trigger und Berechnungen; kürzere Übereinstimmungen, weniger Decodierungsschritte, möglicherweise schnellere Beschleunigung.
Das zweite ist die Anzahl der jedes Mal kopierten Wörter: Je mehr Wörter kopiert werden, desto größer ist das Beschleunigungspotenzial, aber es kann auch dazu führen, dass mehr falsche Ausgaben verworfen werden, was Rechenressourcen verschwendet. Forscher haben durch Experimente herausgefunden, dass aggressivere Strategien (Abgleich einzelner Wortauslöser, gleichzeitiges Kopieren von 15 bis 20 Wörtern) häufig bessere Beschleunigungsverhältnisse erzielen können.
Um die Wirksamkeit des LLM Accelerator zu überprüfen, führten die Forscher Experimente zur Abrufverbesserung und Cache-unterstützten Generierung durch und erstellten experimentelle Proben unter Verwendung des MS-MARCO-Absatzabrufdatensatzes.
Im Experiment zur Abrufverbesserung verwendeten die Forscher das Abrufmodell, um die 10 relevantesten Dokumente für jede Abfrage zurückzugeben, und fügten sie dann als Eingabe für das Modell in die Abfrage ein, wobei sie diese 10 Dokumente als Referenztext verwendeten.
Im Experiment zur Cache-unterstützten Generierung generiert jede Abfrage vier ähnliche Abfragen und verwendet dann das Modell, um die entsprechende Abfrage als Referenztext auszugeben.
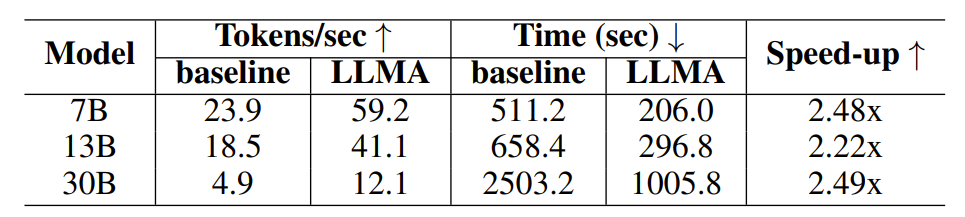
Tabelle 1: Zeitvergleich im Szenario der Retrieval-Enhanced-Generierung
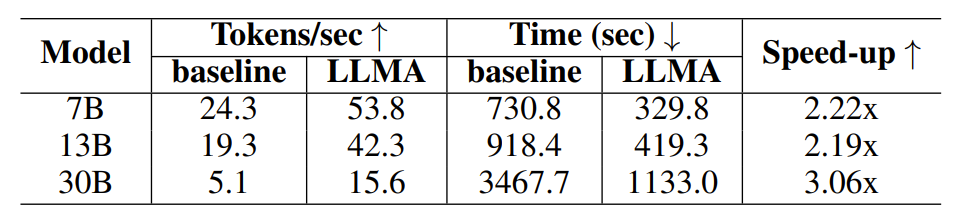
Tabelle 2: Zeitvergleich im Szenario der Generierung mit Cache
Die Die Forscher verwendeten die über die OpenAI-Schnittstelle erhaltene Ausgabe des Davinci-003-Modells als Zielausgabe, um eine qualitativ hochwertige Ausgabe zu erhalten. Nachdem die Forscher den erforderlichen Eingabe-, Ausgabe- und Referenztext erhalten hatten, führten sie Experimente mit dem Open-Source-Sprachmodell LLaMA durch.
Da die Ausgabe des LLaMA-Modells nicht mit der Davinci-003-Ausgabe übereinstimmt, verwendeten die Forscher eine zielorientierte Dekodierungsmethode, um das Beschleunigungsverhältnis unter der idealen Ausgabe (Davinci-003-Modellergebnis) zu testen.
Die Forscher verwendeten Algorithmus 2, um die Dekodierungsschritte zu erhalten, die zum Generieren der Zielausgabe während der gierigen Dekodierung erforderlich sind, und zwangen das LLaMA-Modell, gemäß den erhaltenen Dekodierungsschritten zu dekodieren.

Abbildung 3: Verwendung von Algorithmus 2, um die Dekodierungsschritte zu erhalten, die zum Generieren der Zielausgabe während der gierigen Dekodierung erforderlich sind
Für Modelle mit Parametermengen von 7B und 13B verwendeten die Forscher einen einzigen 32G NVIDIA-Experimente werden auf einer V100-GPU durchgeführt; für ein Modell mit 30B-Parametern werden Experimente auf vier identischen GPUs durchgeführt. Alle Experimente verwenden Gleitkommazahlen mit halber Genauigkeit, die Dekodierung ist eine gierige Dekodierung und die Stapelgröße beträgt 1.
Experimentelle Ergebnisse zeigen, dass LLM Accelerator in verschiedenen Modellgrößen (7B, 13B, 30B) und verschiedenen Anwendungsszenarien (Abrufverbesserung, Cache-Unterstützung) das zwei- bis dreifache Beschleunigungsverhältnis erreicht hat.
Weitere experimentelle Analysen ergaben, dass LLM Accelertator die erforderlichen Decodierungsschritte erheblich reduzieren kann und das Beschleunigungsverhältnis positiv mit dem Reduktionsverhältnis der Decodierungsschritte korreliert.
Einerseits bedeuten weniger Decodierungsschritte, dass jeder Decodierungsschritt mehr Ausgabewörter generiert, was die Recheneffizienz von GPU-Berechnungen verbessern kann; andererseits bedeutet dies für das 30B-Modell, das Multikartenparallelität erfordert mehr Weniger Synchronisierung mehrerer Karten, wodurch eine schnellere Geschwindigkeitsverbesserung erreicht wird.
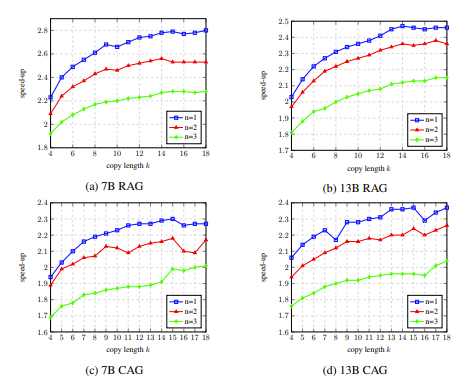
Im Ablationsexperiment zeigten die Ergebnisse der Analyse der Hyperparameter von LLM Accelertator am Entwicklungssatz, dass beim Abgleichen eines einzelnen Wortes (d. h. Auslösen des Kopiermechanismus) das Beschleunigungsverhältnis beim Kopieren 15 bis maximal erreichen kann 20 Wörter gleichzeitig (dargestellt in Abbildung 4).
In Abbildung 5 können wir sehen, dass die Anzahl der übereinstimmenden Wörter 1 beträgt, was den Kopiermechanismus stärker auslösen kann. Mit zunehmender Kopierlänge nehmen die von jedem Decodierungsschritt akzeptierten Ausgabewörter zu und die Decodierungsschritte nehmen somit ab Erreichen eines höheren Beschleunigungsverhältnisses. Abbildung 4: Im Ablationsexperiment die Analyseergebnisse der Hyperparameter des LLM Accelertator am Entwicklungssatz. Abbildung 5: Am Entwicklungssatz , mit statistischen Daten der Dekodierungsschritte für unterschiedliche Anzahl übereinstimmender Wörter n und Anzahl kopierter Wörter k
 LLM Accelertator ist Teil der Arbeitsreihe der Microsoft Research Asia Natural Language Computing Group zur Beschleunigung großer Sprachmodelle. Forscher werden sich weiterhin mit verwandten Themen befassen und diese tiefer erforschen.
LLM Accelertator ist Teil der Arbeitsreihe der Microsoft Research Asia Natural Language Computing Group zur Beschleunigung großer Sprachmodelle. Forscher werden sich weiterhin mit verwandten Themen befassen und diese tiefer erforschen.
Das obige ist der detaillierte Inhalt vonDie LLM-Inferenz ist dreimal schneller! Microsoft veröffentlicht LLM Accelerator: Verwendung von Referenztext zur Erzielung verlustfreier Beschleunigung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1386
1386
 52
52

 Einstiegsadresse für die internationale Bing-Version von Microsoft (Einstieg in die Bing-Suchmaschine)
Mar 14, 2024 pm 01:37 PM
Einstiegsadresse für die internationale Bing-Version von Microsoft (Einstieg in die Bing-Suchmaschine)
Mar 14, 2024 pm 01:37 PM
Bing ist eine von Microsoft eingeführte Online-Suchmaschine. Die Suchfunktion ist sehr leistungsfähig und verfügt über zwei Eingänge: die inländische Version und die internationale Version. Wo sind die Eingänge zu diesen beiden Versionen? Wie greife ich auf die internationale Version zu? Werfen wir einen Blick auf die Details unten. Zugang zur Website der chinesischen Version von Bing: https://cn.bing.com/ Zugang zur Website der internationalen Version von Bing: https://global.bing.com/ Wie greife ich auf die internationale Version von Bing zu? 1. Geben Sie zunächst die URL ein, um Bing zu öffnen: https://www.bing.com/ 2. Sie sehen, dass es Optionen für nationale und internationale Versionen gibt. Wir müssen nur die internationale Version auswählen und die Schlüsselwörter eingeben.
 Microsoft veröffentlicht das kumulative August-Update für Win11: Verbesserung der Sicherheit, Optimierung des Sperrbildschirms usw.
Aug 14, 2024 am 10:39 AM
Microsoft veröffentlicht das kumulative August-Update für Win11: Verbesserung der Sicherheit, Optimierung des Sperrbildschirms usw.
Aug 14, 2024 am 10:39 AM
Laut Nachrichten dieser Website vom 14. August veröffentlichte Microsoft während des heutigen August-Patch-Dienstags kumulative Updates für Windows 11-Systeme, darunter das Update KB5041585 für 22H2 und 23H2 sowie das Update KB5041592 für 21H2. Nachdem das oben genannte Gerät mit dem kumulativen Update vom August installiert wurde, sind die mit dieser Site verbundenen Versionsnummernänderungen wie folgt: Nach der Installation des 21H2-Geräts wurde die Versionsnummer auf Build22000.314722H2 erhöht. Die Versionsnummer wurde auf Build22621.403723H2 erhöht. Nach der Installation des Geräts wurde die Versionsnummer auf Build22631.4037 erhöht. Die Hauptinhalte des KB5041585-Updates für Windows 1121H2 sind wie folgt: Verbesserung: Verbessert
 Microsoft Edge-Upgrade: Funktion zum automatischen Speichern von Passwörtern verboten? ! Die Benutzer waren schockiert!
Apr 19, 2024 am 08:13 AM
Microsoft Edge-Upgrade: Funktion zum automatischen Speichern von Passwörtern verboten? ! Die Benutzer waren schockiert!
Apr 19, 2024 am 08:13 AM
Neuigkeiten vom 18. April: Kürzlich berichteten einige Benutzer des Microsoft Edge-Browsers, die den Canary-Kanal nutzten, dass sie nach dem Upgrade auf die neueste Version festgestellt hätten, dass die Option zum automatischen Speichern von Passwörtern deaktiviert sei. Nach einer Untersuchung stellte sich heraus, dass es sich hierbei um eine geringfügige Anpassung nach dem Browser-Upgrade und nicht um eine Aufhebung der Funktionalität handelte. Vor der Verwendung des Edge-Browsers für den Zugriff auf eine Website berichteten Benutzer, dass der Browser ein Fenster öffnete, in dem sie gefragt wurden, ob sie das Anmeldekennwort für die Website speichern wollten. Nachdem Sie sich zum Speichern entschieden haben, gibt Edge bei der nächsten Anmeldung automatisch die gespeicherte Kontonummer und das gespeicherte Passwort ein, was den Benutzern großen Komfort bietet. Aber das neueste Update ähnelt einer Optimierung, bei der die Standardeinstellungen geändert werden. Benutzer müssen das Speichern des Passworts auswählen und dann in den Einstellungen das automatische Ausfüllen des gespeicherten Kontos und Passworts manuell aktivieren.
 Das Vollbild-Popup von Microsoft fordert Benutzer von Windows 10 auf, sich zu beeilen und auf Windows 11 zu aktualisieren
Jun 06, 2024 am 11:35 AM
Das Vollbild-Popup von Microsoft fordert Benutzer von Windows 10 auf, sich zu beeilen und auf Windows 11 zu aktualisieren
Jun 06, 2024 am 11:35 AM
Laut Nachrichten vom 3. Juni sendet Microsoft aktiv Vollbildbenachrichtigungen an alle Windows 10-Benutzer, um sie zu einem Upgrade auf das Betriebssystem Windows 11 zu ermutigen. Dabei handelt es sich um Geräte, deren Hardwarekonfigurationen das neue System nicht unterstützen. Seit 2015 hat Windows 10 fast 70 % des Marktanteils eingenommen und seine Dominanz als Windows-Betriebssystem fest etabliert. Der Marktanteil liegt jedoch weit über dem Marktanteil von 82 %, und der Marktanteil übersteigt den von Windows 11, das 2021 erscheinen wird, bei weitem. Obwohl Windows 11 seit fast drei Jahren auf dem Markt ist, ist die Marktdurchdringung immer noch langsam. Microsoft hat angekündigt, den technischen Support für Windows 10 nach dem 14. Oktober 2025 einzustellen, um sich stärker darauf zu konzentrieren
 Die Funktion von Microsoft Win11 zum Komprimieren von 7z- und TAR-Dateien wurde von den Versionen 24H2 auf 23H2/22H2 herabgestuft
Apr 28, 2024 am 09:19 AM
Die Funktion von Microsoft Win11 zum Komprimieren von 7z- und TAR-Dateien wurde von den Versionen 24H2 auf 23H2/22H2 herabgestuft
Apr 28, 2024 am 09:19 AM
Laut Nachrichten dieser Website vom 27. April hat Microsoft Anfang dieses Monats das Vorschauversionsupdate für Windows 11 Build 26100 auf den Canary- und Dev-Kanälen veröffentlicht, das voraussichtlich eine mögliche RTM-Version des Windows 1124H2-Updates werden wird. Die wichtigsten Änderungen in der neuen Version sind der Datei-Explorer, die Integration von Copilot, die Bearbeitung von PNG-Dateimetadaten, die Erstellung von TAR- und 7z-komprimierten Dateien usw. @PhantomOfEarth hat herausgefunden, dass Microsoft einige Funktionen der 24H2-Version (Germanium) auf die 23H2/22H2-Version (Nickel) übertragen hat, beispielsweise die Erstellung von TAR- und 7z-komprimierten Dateien. Wie im Diagramm gezeigt, unterstützt Windows 11 die native Erstellung von TAR
 Microsoft Edge-Browser-Update: Funktion „Bild vergrößern' hinzugefügt, um die Benutzererfahrung zu verbessern
Mar 21, 2024 pm 01:40 PM
Microsoft Edge-Browser-Update: Funktion „Bild vergrößern' hinzugefügt, um die Benutzererfahrung zu verbessern
Mar 21, 2024 pm 01:40 PM
Einer Nachricht vom 21. März zufolge hat Microsoft kürzlich seinen Microsoft Edge-Browser aktualisiert und eine praktische „Bild vergrößern“-Funktion hinzugefügt. Wenn Benutzer den Edge-Browser verwenden, können Benutzer diese neue Funktion jetzt ganz einfach im Popup-Menü finden, indem sie einfach mit der rechten Maustaste auf das Bild klicken. Noch praktischer ist, dass Benutzer auch mit der Maus über das Bild fahren und dann die Strg-Taste doppelklicken können, um schnell die Funktion zum Vergrößern des Bildes aufzurufen. Nach Angaben des Herausgebers wurde der neueste veröffentlichte Microsoft Edge-Browser im kanarischen Kanal auf neue Funktionen getestet. Die stabile Version des Browsers hat außerdem offiziell die praktische Funktion „Bild vergrößern“ eingeführt, die Benutzern ein komfortableres Durchsuchen von Bildern ermöglicht. Darauf haben auch ausländische Wissenschafts- und Technologiemedien geachtet
 Microsoft plant, NTLM in Windows 11 in der zweiten Jahreshälfte 2024 auslaufen zu lassen und vollständig auf Kerberos-Authentifizierung umzustellen
Jun 09, 2024 pm 04:17 PM
Microsoft plant, NTLM in Windows 11 in der zweiten Jahreshälfte 2024 auslaufen zu lassen und vollständig auf Kerberos-Authentifizierung umzustellen
Jun 09, 2024 pm 04:17 PM
In der zweiten Hälfte des Jahres 2024 veröffentlichte der offizielle Microsoft-Sicherheitsblog eine Nachricht als Reaktion auf den Aufruf der Sicherheits-Community. Das Unternehmen plant, das in der zweiten Jahreshälfte 2024 veröffentlichte NTLAN Manager (NTLM)-Authentifizierungsprotokoll in Windows 11 zu eliminieren, um die Sicherheit zu verbessern. Nach bisherigen Erläuterungen hat Microsoft bereits zuvor ähnliche Schritte unternommen. Am 12. Oktober letzten Jahres schlug Microsoft in einer offiziellen Pressemitteilung einen Übergangsplan vor, der darauf abzielt, NTLM-Authentifizierungsmethoden auslaufen zu lassen und mehr Unternehmen und Benutzer dazu zu bewegen, auf Kerberos umzusteigen. Um Unternehmen zu helfen, die möglicherweise Probleme mit fest verdrahteten Anwendungen und Diensten haben, nachdem sie die NTLM-Authentifizierung deaktiviert haben, stellt Microsoft IAKerb und zur Verfügung
 Microsoft bringt neue Version von Outlook für Windows auf den Markt: umfassende Aktualisierung der Kalenderfunktionen
Apr 27, 2024 pm 03:44 PM
Microsoft bringt neue Version von Outlook für Windows auf den Markt: umfassende Aktualisierung der Kalenderfunktionen
Apr 27, 2024 pm 03:44 PM
In den Nachrichten vom 27. April gab Microsoft bekannt, dass es bald einen Test einer neuen Version des Outlook für Windows-Clients veröffentlichen wird. Dieses Update konzentriert sich hauptsächlich auf die Optimierung der Kalenderfunktion mit dem Ziel, die Arbeitseffizienz der Benutzer zu verbessern und den täglichen Arbeitsablauf weiter zu vereinfachen. Die Verbesserung der neuen Version des Outlook für Windows-Clients liegt in seiner leistungsfähigeren Kalenderverwaltungsfunktion. Jetzt können Benutzer persönliche Arbeitszeit- und Standortinformationen einfacher teilen und so die Besprechungsplanung effizienter gestalten. Darüber hinaus verfügt Outlook über benutzerfreundliche Einstellungen, die es Benutzern ermöglichen, Besprechungen so einzustellen, dass sie automatisch früher enden oder später beginnen. Dies bietet Benutzern mehr Flexibilität, unabhängig davon, ob sie Besprechungsräume wechseln, eine Pause einlegen oder eine Tasse Kaffee vereinbaren möchten . entsprechend
