

Ein Clustered Index erstellt einen B+-Baum basierend auf dem Primärschlüssel jeder Tabelle, und die Zeilendatensatzdaten der gesamten Tabelle werden in den Blattknoten gespeichert.
Lassen Sie uns zum Beispiel den Clustered-Index intuitiv spüren.
Erstellen Sie Tabelle t und lassen Sie künstlich zu, dass jede Seite nur zwei Zeilendatensätze speichert (ich weiß nicht, wie ich künstlich nur zwei Zeilendatensätze pro Seite steuern kann):
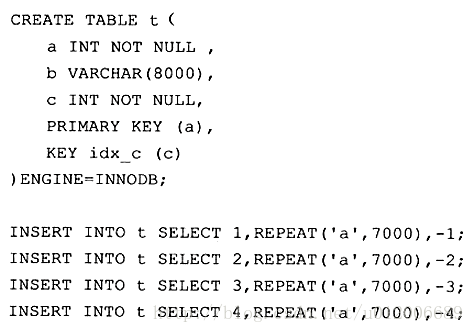
Schließlich „MySQL Technology Insider“ Der Autor erhalten Die grobe Struktur dieses Clustered-Index-Baums mithilfe von Analysetools wie folgt:
Die Blattknoten eines Clustered-Index werden als Datenseiten bezeichnet, die jeweils durch eine doppelt verknüpfte Liste verknüpft sind und die Datenseiten angeordnet sind in der Reihenfolge der Primärschlüssel.
Wie in der Abbildung gezeigt, speichert jede Datenseite einen vollständigen Zeilendatensatz, während auf der Indexseite der Nicht-Datenseite nur der Schlüsselwert und der Offset, der auf die Datenseite zeigt, und kein vollständiger Zeilendatensatz gespeichert werden .
Wenn ein Primärschlüssel definiert ist, verwendet InnoDB automatisch den Primärschlüssel, um einen Clustered-Index zu erstellen. Wenn kein Primärschlüssel definiert ist, wählt InnoDB einen eindeutigen und nicht leeren Index als Primärschlüssel. InnoDB definiert einen Primärschlüssel implizit als Clustered-Index, wenn es keinen eindeutigen Nicht-Null-Index gibt.
Hilfsindex, auch nicht gruppierter Index genannt. Im Vergleich zum Clustered-Index enthalten die Blattknoten nicht alle Daten des Zeilendatensatzes. Zusätzlich zum Schlüsselwert enthält die Indexzeile des Blattknotens auch ein Lesezeichen (Lesezeichen), mit dem InnoDB mitgeteilt wird, wo die dem Index entsprechenden Zeilendaten zu finden sind.
Lassen Sie uns das Beispiel in „MySQL Technology Insider“ verwenden, um intuitiv zu spüren, wie der Hilfsindex aussieht.
Erstellen Sie am Beispiel der obigen Tabelle t einen nicht gruppierten Index für Spalte c:
Dann erhielt der Autor durch Analysearbeiten das Beziehungsdiagramm zwischen dem Hilfsindex und dem gruppierten Index:
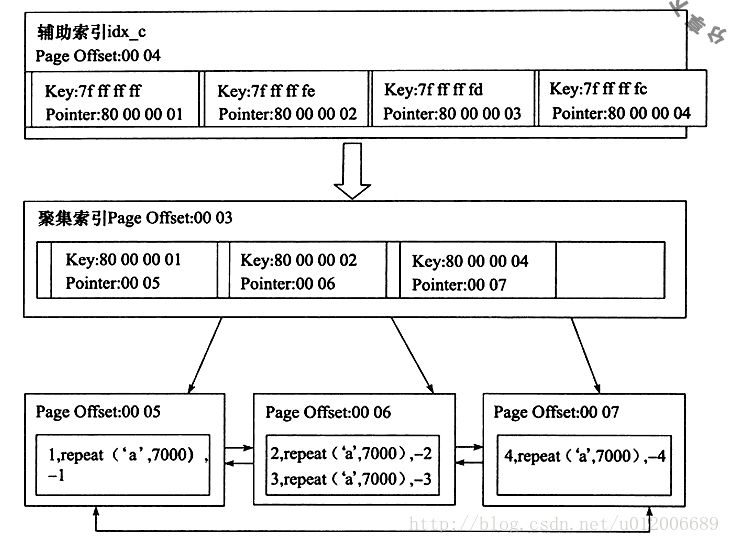
Sie können den Hilfsindex sehen. Der Blattknoten von idx_c enthält den Wert von Spalte c und den Wert des Primärschlüssels.
Angenommen, der Wert von Key ist 0x7ffffffff, wobei die binäre Darstellung von 7 0111 ist und 0 eine negative Zahl ist. Der tatsächliche ganzzahlige Wert sollte invertiert plus 1 sein, sodass das Ergebnis -1 ist und dies der Wert in Spalte c ist. Der Primärschlüsselwert ist eine positive Zahl 1, dargestellt durch den Zeigerwert 80000001, wobei 8 Bits die Binärzahl 1000 darstellen.
Mit der InnoDB-Speicher-Engine können Sie den Index über den Hilfsindex abdecken und die Abfragedatensätze direkt abrufen, ohne die Datensätze im Clustered-Index abzufragen.
Welche Vorteile bietet die Verwendung eines Deckungsindex?
kann viele E/A-Vorgänge reduzieren
Im obigen Bild wissen wir, dass Sie, wenn Sie Felder abfragen möchten, die nicht im Hilfsindex enthalten sind, zuerst den Hilfsindex und dann den Clustered-Index durchlaufen müssen . Wenn sich der abzufragende Feldwert bereits im Hilfsindex befindet, besteht keine Notwendigkeit, den Clustered-Index zu überprüfen, wodurch die E/A-Vorgänge offensichtlich reduziert werden.
Im Bild oben kann beispielsweise die folgende SQL den Hilfsindex direkt verwenden.
select a from where c = -2;
ist hilfreich für Statistiken.
Angenommen, die folgende Tabelle existiert:
CREATE TABLE `student` ( `id` bigint(20) NOT NULL, `name` varchar(255) NOT NULL, `age` varchar(255) NOT NULL, `school` varchar(255) NOT NULL, PRIMARY KEY (`id`), KEY `idx_name` (`name`), KEY `idx_school_age` (`school`,`age`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
Bei Ausführung in dieser Tabelle:
select count(*) from student
Was passiert mit dem Optimierer?
Der Optimierer wählt den Hilfsindex für die Statistik aus, denn obwohl Ergebnisse durch Durchlaufen sowohl des Clustered-Index als auch des Hilfsindex erzielt werden können, ist die Größe des Hilfsindex viel kleiner als die des Clustered-Index. Führen Sie den Befehl EXPLAIN aus:

key und Extra zeigen an, dass der Hilfsindex idx_name verwendet wird.
Nehmen Sie außerdem an, dass die folgende SQL ausgeführt wird:
select * from student where age > 10 and age < 15
Da die Feldreihenfolge des gemeinsamen Index idx_school_age zuerst Schule und dann Alter ist, wird eine bedingte Abfrage entsprechend dem Alter durchgeführt, normalerweise ohne Verwendung des Index:

Wenn die Bedingungen jedoch unverändert bleiben, fragen Sie alle Felder ab, anstatt die Anzahl der Einträge abzufragen:
select count(*) from student where age > 10 and age < 15
Der Optimierer wählt diesen gemeinsamen Index:

Der gemeinsame Index bezieht sich auf die Indizierung mehrerer Spalten in der Tabelle.
Das Folgende ist ein Beispiel für die Erstellung eines gemeinsamen Index idx_a_b:

Die interne Struktur des gemeinsamen Index:
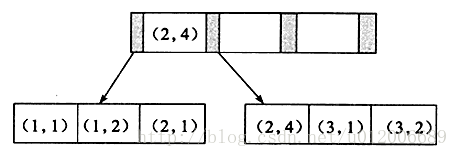
联合索引也是一棵B+树,其键值数量大于等于2。键值都是排序的,通过叶子节点可以逻辑上顺序的读出所有数据。数据(1,1)(1,2)(2,1)(2,4)(3,1)(3,2)是按照(a,b)先比较a再比较b的顺序排列。
基于上面的结构,对于以下查询显然是可以使用(a,b)这个联合索引的:
select * from table where a=xxx and b=xxx ; select * from table where a=xxx;
但是对于下面的sql是不能使用这个联合索引的,因为叶子节点的b值,1,2,1,4,1,2显然不是排序的。
select * from table where b=xxx
联合索引的第二个好处是对第二个键值已经做了排序。举个例子:
create table buy_log(
userid int not null,
buy_date DATE
)ENGINE=InnoDB;
insert into buy_log values(1, '2009-01-01');
insert into buy_log values(2, '2009-02-01');
alter table buy_log add key(userid);
alter table buy_log add key(userid, buy_date);当执行
select * from buy_log where user_id = 2;
时,优化器会选择key(userid);但是当执行以下sql:
select * from buy_log where user_id = 2 order by buy_date desc;
时,优化器会选择key(userid, buy_date),因为buy_date是在userid排序的基础上做的排序。
如果把key(userid,buy_date)删除掉,再执行:
select * from buy_log where user_id = 2 order by buy_date desc;
优化器会选择key(userid),但是对查询出来的结果会进行一次filesort,即按照buy_date重新排下序。所以联合索引的好处在于可以避免filesort排序。
Das obige ist der detaillierte Inhalt vonSo verwenden Sie Clustered-Index, Hilfsindex, Covering-Index und Joint-Index in MySQL. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 MySQL ändert den Namen der Datentabelle
MySQL ändert den Namen der Datentabelle
 MySQL erstellt eine gespeicherte Prozedur
MySQL erstellt eine gespeicherte Prozedur
 Der Unterschied zwischen Mongodb und MySQL
Der Unterschied zwischen Mongodb und MySQL
 So überprüfen Sie, ob das MySQL-Passwort vergessen wurde
So überprüfen Sie, ob das MySQL-Passwort vergessen wurde
 MySQL-Datenbank erstellen
MySQL-Datenbank erstellen
 MySQL-Standard-Transaktionsisolationsstufe
MySQL-Standard-Transaktionsisolationsstufe
 Der Unterschied zwischen SQL Server und MySQL
Der Unterschied zwischen SQL Server und MySQL
 mysqlPasswort vergessen
mysqlPasswort vergessen








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



