

Erstellen Sie zunächst eine Datenbanktabelle:
rreeeDer einfachste Plan zur Abfrageausführung besteht darin, alle Datensätze in der Tabelle zu scannen und zu prüfen, ob jeder Suchdatensatz die Suchbedingungen erfüllt. Wenn es übereinstimmt, senden Sie es an den Client, andernfalls überspringen Sie den Datensatz. Dieses Ausführungsschema wird als vollständiger Tabellenscan bezeichnet.
Für die InnoDB-Speicher-Engine bedeutet ein vollständiger Tabellenscan, dass beim ersten Datensatz des ersten Blattknotens des Clustered-Index entlang der unidirektionalen Richtung, in der sich der Datensatz befindet, begonnen wird Die verknüpfte Liste durchsucht den letzten Datensatz des letzten Blattknotens rückwärts. Wenn Sie den B+-Baum verwenden können, um Datensätze zu finden, deren Indexspaltenwert einem bestimmten Wert entspricht, können Sie die Anzahl der zu durchsuchenden Datensätze reduzieren. InnoDB存储引擎来说,全表扫描意味着从聚簇索引第一个叶子节点的第一条记录开始,沿着记录所在的单向链表向后扫描,直到最后一个叶子节点的最后一条记录,如果可以利用B+树查找索引列值等于某个值的记录,这样就可以减少需要扫描的记录的数量。
由于B+树叶子节点中的记录是按照索引列值有小到大的顺序排序的,所以只需要扫描某个区间或者某些区间中的记录也可以明显减少需要扫描的记录的数量。
对于查询语句:
create table single_table(
id int not auto_increment,
key1 varchar(100),
key2 int,
key3 varchar(100),
key_part1 varchar(100),
key_part2 varchar(100),
key_part3 varchar(100),
common_field varchar(100),
primary key(id), # 聚簇索引
key idx_key1(key1), # 二级索引
unique key uk_key2(key2), # 二级索引,而且该索引是唯一二级索引
key idx_key3(key3), # 二级索引
key idx_key_part(key_part1,key_part2,key_part3) # 二级索引,也是联合索引
)Engine=InnoDB CHARSET=utf8;这个语句其实就是想查找id值在[2,100]区间中的所有聚簇索引记录,我们可以通过聚簇索引对应的B+树快速的找到id=2的那条聚簇索引记录,然后沿着记录所在的单向链表向后扫描,直到某条聚簇索引记录的id值不在[2,100]区间中为止,与扫描全部的聚簇索引记录相比,这种方式大大减少了需要扫描的记录数量,所以提升了查询效率。
其实,对于B+树来说,只要索引列和常数使用=、<=>、in、not in、is null、is not null、>、<、>=、<=、between、!=、或者like操作符连接起来,就可以产生扫描区间,从而提高查询效率。
我们在编写查询语句时,经常需要使用order by子句对查询出来的记录按照某种规则进行排序。在一般情况下,我们只能把记录加载到内存中,然后再用一些排序算法在内存中对这些记录进行排序。有时查询的结果集可能太大以至于在内存中无法进行排序,此时就需要暂时借助磁盘的空间来存放中间结果,在排序操作完成后再把排序的结果返回给客户端。
在MySQL中,这种在内存中或者磁盘中进行排序的方式称为文件排序,但是如果order by子句中使用了索引列,就有可能省去在内存或磁盘中排序的步骤。
select * from single_table where id>=2 and id<=100;
这个查询语句的结果集需要先按照key_part1值排序,如果记录的key_part1值相同,再按照key_part2值排序,如果key_part1值和key_part2值都相同,再按照key_part3排序。而我们建立的联合索引idx_key_part就是按照上面的规则排序的,如下为idx_key_part索引的简化示意图:
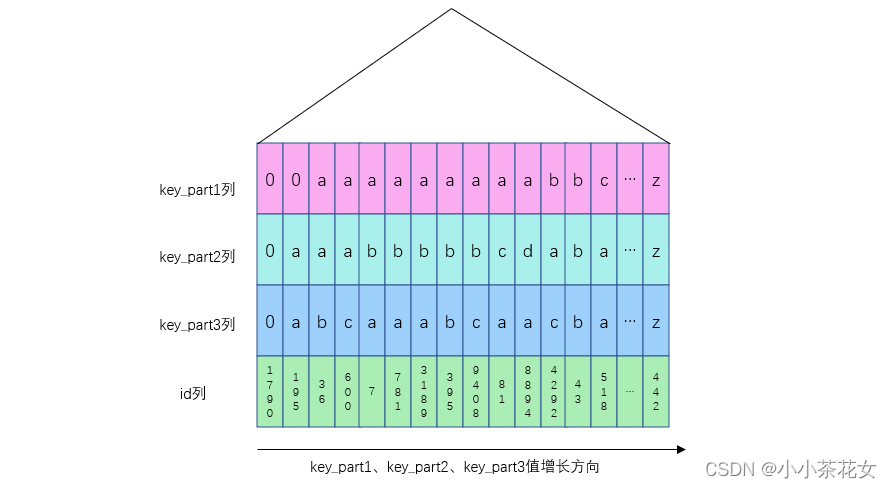
所以我们可以从第一条idx_key_part二级索引记录开始,沿着记录所在的单向链表向后扫描,取10条二级索引记录即可。由于我们的查询列表是*,也就是需要读取完整的用户记录,所以针对获取到的每一条二级索引记录都执行一次回表操作,将完整的用户记录发送给客户端。这样就省去了给10000条记录排序的时间。
这里我们在执行查询语句时加了limit语句,如果不限制需要获取的记录数量,会导致为大量二级索引记录执行回表操作,这样会影响整体的性能。
在使用联合索引时,需要注意:order by子句后面的列的顺序也必须按照索引列的顺序给出;如果给出order by key_part3,key_part2,key_part1的顺序,则无法使用B+树索引。
之所以颠倒排序列顺序就不能使用索引,原因还是联合索引中页面和记录的排序规则是规定的,即先按照key_part1值排序,如果记录的key_part1值相同,再按照key_part2值排序,如果记录的key_part1值和key_part2值都相同,再按照key_part3值排序。如果order by子句的内容是order by key_part3,key_part2,key_part1,那就要求先按照key_part3值排序,如果记录的key_part3值相同,再按照key_part2值排序,如果记录的key_part3值和key_part2值都相同,再按照key_part1
select * form single_table order by key_part1,key_part2,key_part3 limit 10;
id-Wert in finden [2.100]Alle Clustered-Index-Datensätze im Intervall. Wir können den Clustered-Index-Datensatz mit id=2 schnell über den B+-Baum finden, der dem Clustered-Index entspricht, und dann der Position folgen Der Datensatz Die einseitig verknüpfte Liste wird rückwärts gescannt, bis der id-Wert eines bestimmten Clustered-Index-Datensatzes nicht im [2,100]-Intervall liegt Datensätze reduziert diese Methode die Anzahl der Datensätze, die gescannt werden müssen, erheblich und verbessert so die Abfrageeffizienz. #🎜🎜##🎜🎜#Tatsächlich gilt für B+-Bäume, solange die Indexspalten und Konstanten = verwenden, <=>, in, not in, ist null, ist nicht null, >, < , >=, <=, between, != oder like-Operatoren können verbunden werden, um ein Scanintervall zu generieren und so die Abfrageeffizienz zu verbessern. #🎜🎜##🎜🎜#2. Der Index wird zum Sortieren verwendet#🎜🎜##🎜🎜#Wenn wir Abfrageanweisungen schreiben, müssen wir häufig die Klausel order by verwenden, um die abgefragten Datensätze zu sortieren nach bestimmten Sortierregeln. Unter normalen Umständen können wir Datensätze nur in den Speicher laden und dann einige Sortieralgorithmen verwenden, um diese Datensätze im Speicher zu sortieren. Manchmal ist die Abfrageergebnismenge möglicherweise zu groß, um im Speicher sortiert zu werden. In diesem Fall ist es erforderlich, vorübergehend Speicherplatz zum Speichern der Zwischenergebnisse zu verwenden und die sortierten Ergebnisse nach Abschluss des Sortiervorgangs an den Client zurückzugeben. #🎜🎜##🎜🎜#In MySQL wird diese Sortiermethode im Speicher oder auf der Festplatte als Dateisortierung bezeichnet. Wenn jedoch eine Indexspalte in der order by-Klausel verwendet wird, besteht möglicherweise die Möglichkeit, die zu eliminieren Schritt des Sortierens im Speicher oder auf der Festplatte. #🎜🎜#select * from single_table order by key1,,key2 limit 10;
key_part1-Wert sortiert werden Der Wert von key_part1 ist derselbe und wird dann nach dem Wert von key_part2 sortiert. Wenn der Wert von key_part1 und der Wert von < code>key_part2 gleich sind, dann nach dem Wert von key_part3 Sortieren sortieren. Der von uns erstellte gemeinsame Index idx_key_part wird nach den oben genannten Regeln sortiert. Das Folgende ist ein vereinfachtes Diagramm des idx_key_part-Index: #🎜🎜##🎜🎜# #🎜🎜##🎜🎜#So können wir Beginnen Sie mit dem ersten. Scannen Sie ausgehend vom sekundären Indexdatensatz
#🎜🎜##🎜🎜#So können wir Beginnen Sie mit dem ersten. Scannen Sie ausgehend vom sekundären Indexdatensatz idx_key_part rückwärts entlang der einseitig verknüpften Liste, in der sich der Datensatz befindet, und erhalten Sie 10 sekundäre Indexdatensätze. Da unsere Abfrageliste * ist, müssen wir den vollständigen Benutzerdatensatz lesen. Daher führen wir für jeden erhaltenen sekundären Indexdatensatz eine Tabellenrückgabeoperation durch und senden den vollständigen Benutzerdatensatz an den Client. Dies spart Zeit beim Sortieren von 10.000 Datensätzen. #🎜🎜##🎜🎜#Hier fügen wir beim Ausführen der Abfrageanweisung eine Limit-Anweisung hinzu. Wenn die Anzahl der abzurufenden Datensätze nicht begrenzt ist, wird eine große Anzahl sekundärer Indexdatensätze an die Tabelle zurückgegeben , was sich auf die Gesamtleistung auswirkt. #🎜🎜#sortieren nach Die Spalte nach der Klausel Die Reihenfolge muss auch in der Reihenfolge der Indexspalten angegeben werden; wenn die Reihenfolge order by key_part3, key_part2, key_part1 angegeben ist, kann der B+-Baumindex nicht verwendet werden. #🎜🎜##🎜🎜#Der Grund, warum Sie den Index nicht verwenden können, wenn Sie die Sortierreihenfolge umkehren, liegt darin, dass die Sortierregeln für Seiten und Datensätze im gemeinsamen Index festgelegt sind, dh zuerst nach key_part1 sortieren -Wert. Wenn die Werte von key_part1 gleich sind, wird der Wert nach key_part2 sortiert. code>-Werte und key_part2-Werte sind gleich. Sortieren Sie dann nach dem key_part3-Wert. Wenn der Inhalt der order by-Klausel order by key_part3,key_part2,key_part1 ist, muss zuerst nach dem key_part3-Wert sortiert werden . Wenn der aufgezeichnete Wert von key_part3 gleich ist und dann nach dem Wert von key_part2 sortiert wird Der Wert von key_part2 ist derselbe, dann werden die Werte nach dem Wert von key_part1 sortiert, was offensichtlich einen Konflikt darstellt . #🎜🎜#(1) ASC、DESC混用;
对于使用联合索引进行排序的场景,我们要求各个排序列的排序规则是一致的,也就是要么各个列都是按照升序规则排序,要么都是按照降序规则排序。
(2) 排序列包含非一个索引的列;
有时用来排序的多个列不是同一个索引中的,这种情况也不能使用索引进行排序,比如下面的查询语句:
select * from single_table order by key1,,key2 limit 10;
对于idx_key1的二级索引记录来说,只按照key1列的值进行排序,而且在key1列相同的情况下是不按照
key2列的值进行排序的,所以不能使用idx_key1索引执行上述查询。
(3) 排序列是某个联合索引的索引列,但是这些排序列在联合索引中并不连续;
(4) 排序列不是以单独列名的形式出现在order by子句中;
有时为了方便统计表中的一些信息,会把表中的记录按照某些列进行分组。比如下面的分组查询语句:
select key_part1,key_part2,key_part3,count(*) fron single_table group by key_part1,key_part2,key_part3;
这个查询语句相当于执行了3次分组操作:
先按照key_part1值把记录进行分组,key_part1值相同的所有记录划分为一组;
将key_part1值相同的每个分组中的记录再按照key_part2的值进行分组,将key_part2值相同的记录放到一个小分组中,看起来像是在一个大分组中又细分了好多小分组。
再将上一步中产生的小分组按照key_part3的值分成更小的分组。所以整体上看起来就像是先把记录分成一个大分组,然后再把大分组分成若干个小分组,最后把若干个小分组再细分为更多的小分组。
上面这个查询语句就是统计每个小小分组包含的记录条数。
如果没有idx_key_part索引,就得建立一个用于统计的临时表,在扫描聚簇索引的记录时将统计的中间结果填入这个临时表。当扫描完记录后,再把临时表中的结果作为结果集发送给客户端。
如果有了idx_key_part索引,恰巧这个分组顺序又与idx_key_part的索引列的顺序一致,因此可以直接使用idx_key_part的二级索引进行分组,而不用建立临时表了。
与使用B+树索引进行排序差不多,分组列的顺序页需要与索引列的顺序一致,也可以值使用索引列中左边连续的列进行分组。
Das obige ist der detaillierte Inhalt vonWelche Rolle spielt der MySQL-Index?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 MySQL ändert den Namen der Datentabelle
MySQL ändert den Namen der Datentabelle
 MySQL erstellt eine gespeicherte Prozedur
MySQL erstellt eine gespeicherte Prozedur
 Der Unterschied zwischen Mongodb und MySQL
Der Unterschied zwischen Mongodb und MySQL
 So überprüfen Sie, ob das MySQL-Passwort vergessen wurde
So überprüfen Sie, ob das MySQL-Passwort vergessen wurde
 MySQL-Datenbank erstellen
MySQL-Datenbank erstellen
 MySQL-Standard-Transaktionsisolationsstufe
MySQL-Standard-Transaktionsisolationsstufe
 Der Unterschied zwischen SQL Server und MySQL
Der Unterschied zwischen SQL Server und MySQL
 mysqlPasswort vergessen
mysqlPasswort vergessen








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



