

Was ist das Datenbankkonzept von Redis?

1. Der Ursprung von 16 Datenbanken
Redis ist ein Speicherserver mit Wörterbuchstruktur. Eine Redis-Instanz stellt mehrere Wörterbücher zum Speichern von Daten bereit. Der Client kann angeben, in welchem Wörterbuch die Daten gespeichert werden sollen. Dies ähnelt der Art und Weise, wie mehrere Datenbanken in einer relationalen Datenbankinstanz erstellt werden können (wie in der Abbildung unten gezeigt), sodass jedes Wörterbuch als unabhängige Datenbank verstanden werden kann.
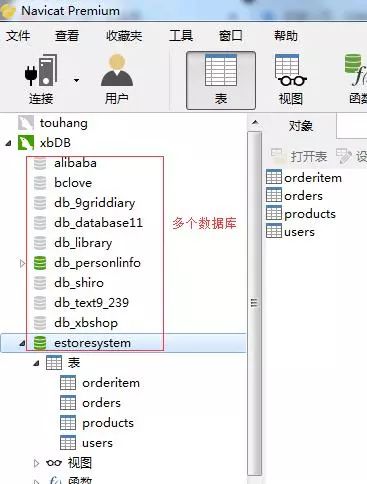
Nehmen Sie die MySQL-Instanz als Beispiel.
Redis unterstützt standardmäßig 16 Datenbanken. Sie können diesen Wert ändern, indem Sie die Datenbanken in der Redis-Konfigurationsdatei redis/redis.conf anpassen. Starten Sie Redis neu, um den Vorgang abzuschließen die Konfiguration.

Nachdem der Client eine Verbindung mit Redis hergestellt hat, wählt er standardmäßig die Datenbank Nr. 0 aus. Sie können die Datenbank jedoch jederzeit mit dem Befehl SELECT ändern.
In tatsächlichen Projekten können Sie die Datenbank in Form einer Redis-Konfigurationsdatei angeben, wie in der Abbildung unten gezeigt
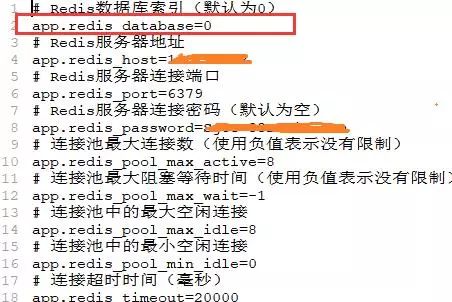
2. Verstehen Sie das „Datenbank“-Konzept von Redis richtig
Da Redis keine benutzerdefinierten Datenbanknamen unterstützt, wird jede Datenbank mit einer Nummer benannt. Entwickler müssen die Korrespondenz zwischen den gespeicherten Daten und der Datenbank aufzeichnen. Darüber hinaus unterstützt Redis nicht das Festlegen unterschiedlicher Zugriffskennwörter für jede Datenbank, sodass ein Client entweder auf alle Datenbanken zugreifen kann oder alle Datenbanken keine Zugriffsberechtigung haben. Um jedoch das „Datenbank“-Konzept von Redis richtig zu verstehen, müssen wir einen Befehl erwähnen:

Dieser Befehl kann alle Datenbankdaten unter der Instanz löschen, was sich von der uns bekannten relationalen Datenbank unterscheidet. Oft werden mehrere Bibliotheken relationaler Datenbanken zum Speichern von Daten für verschiedene Anwendungen verwendet, und es gibt keine Möglichkeit, alle Bibliotheksdaten unter einer Instanz gleichzeitig zu löschen. Für Redis ähneln diese Datenbanken also eher Namespaces und eignen sich nicht zum Speichern von Daten aus verschiedenen Anwendungen. Beispielsweise können Sie Datenbank Nr. 0 zum Speichern von Daten in der Produktionsumgebung einer Anwendung und Datenbank Nr. 1 zum Speichern von Daten in der Testumgebung verwenden. Die Verwendung von Datenbank Nr. 0 ist jedoch nicht zum Speichern geeignet Daten von Anwendung A und Datenbank Nr. 1 zum Speichern der Daten von Anwendung B verwenden. Es ist unterschiedlich, dass die Anwendung verschiedene Redis-Instanzen zum Speichern von Daten verwenden sollte. Redis ist sehr leichtgewichtig. Eine leere Redis-Instanz benötigt nur etwa 1 MB, sodass Sie sich keine Sorgen machen müssen, dass mehrere Redis-Instanzen viel zusätzlichen Speicher beanspruchen.
3. Unterstützt eine Instanz mehrere DBs in einem Cluster?
Bitte beachten Sie, dass die oben genannten Punkte alle auf einzelnen Redis basieren. Im Falle eines Clusters wird die Verwendung des Befehls „select“ zum Wechseln der Datenbank nicht unterstützt, da es im Redis-Clustermodus nur eine Datenbank0 gibt. Um die Unterschiede zwischen Clustern und eigenständigen Reids zu vertiefen, können interessierte Freunde relevante Informationen für ein tieferes Verständnis lesen, die hier nicht besprochen werden.
Schlüssel-Batch-Operationen werden nur begrenzt unterstützt: Beispielsweise müssen sich mget und mset in einem Slot befinden.
Schlüsseltransaktionen und Lua werden nur begrenzt unterstützt: Der Schlüssel der Operation muss sich in einem Knoten befinden die Mindestgranularität der Datenpartition: Nicht unterstützt. Bigkey-Partition
unterstützt nicht mehrere Datenbanken: Es gibt nur eine Datenbank0 im Clustermodus.
Replikation unterstützt nur eine Ebene: Baumreplikationsstruktur wird nicht unterstützt
Das obige ist der detaillierte Inhalt vonWas ist das Datenbankkonzept von Redis?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1379
1379
 52
52

 So erstellen Sie den Redis -Clustermodus
Apr 10, 2025 pm 10:15 PM
So erstellen Sie den Redis -Clustermodus
Apr 10, 2025 pm 10:15 PM
Der Redis -Cluster -Modus bietet Redis -Instanzen durch Sharding, die Skalierbarkeit und Verfügbarkeit verbessert. Die Bauschritte sind wie folgt: Erstellen Sie ungerade Redis -Instanzen mit verschiedenen Ports; Erstellen Sie 3 Sentinel -Instanzen, Monitor -Redis -Instanzen und Failover; Konfigurieren von Sentinel -Konfigurationsdateien, Informationen zur Überwachung von Redis -Instanzinformationen und Failover -Einstellungen hinzufügen. Konfigurieren von Redis -Instanzkonfigurationsdateien, aktivieren Sie den Cluster -Modus und geben Sie den Cluster -Informationsdateipfad an. Erstellen Sie die Datei nodes.conf, die Informationen zu jeder Redis -Instanz enthält. Starten Sie den Cluster, führen Sie den Befehl erstellen aus, um einen Cluster zu erstellen und die Anzahl der Replikate anzugeben. Melden Sie sich im Cluster an, um den Befehl cluster info auszuführen, um den Clusterstatus zu überprüfen. machen
 So verwenden Sie den Befehl Redis
Apr 10, 2025 pm 08:45 PM
So verwenden Sie den Befehl Redis
Apr 10, 2025 pm 08:45 PM
Die Verwendung der REDIS -Anweisung erfordert die folgenden Schritte: Öffnen Sie den Redis -Client. Geben Sie den Befehl ein (Verbschlüsselwert). Bietet die erforderlichen Parameter (variiert von der Anweisung bis zur Anweisung). Drücken Sie die Eingabetaste, um den Befehl auszuführen. Redis gibt eine Antwort zurück, die das Ergebnis der Operation anzeigt (normalerweise in Ordnung oder -err).
 So löschen Sie Redis -Daten
Apr 10, 2025 pm 10:06 PM
So löschen Sie Redis -Daten
Apr 10, 2025 pm 10:06 PM
So löschen Sie Redis -Daten: Verwenden Sie den Befehl Flushall, um alle Schlüsselwerte zu löschen. Verwenden Sie den Befehl flushdb, um den Schlüsselwert der aktuell ausgewählten Datenbank zu löschen. Verwenden Sie SELECT, um Datenbanken zu wechseln, und löschen Sie dann FlushDB, um mehrere Datenbanken zu löschen. Verwenden Sie den Befehl del, um einen bestimmten Schlüssel zu löschen. Verwenden Sie das Redis-Cli-Tool, um die Daten zu löschen.
 So verwenden Sie ein einzelnes Gewinde -Redis
Apr 10, 2025 pm 07:12 PM
So verwenden Sie ein einzelnes Gewinde -Redis
Apr 10, 2025 pm 07:12 PM
Redis verwendet eine einzelne Gewindearchitektur, um hohe Leistung, Einfachheit und Konsistenz zu bieten. Es wird E/A-Multiplexing, Ereignisschleifen, nicht blockierende E/A und gemeinsame Speicher verwendet, um die Parallelität zu verbessern, jedoch mit Einschränkungen von Gleichzeitbeschränkungen, einem einzelnen Ausfallpunkt und ungeeigneter Schreib-intensiver Workloads.
 So lesen Sie den Quellcode von Redis
Apr 10, 2025 pm 08:27 PM
So lesen Sie den Quellcode von Redis
Apr 10, 2025 pm 08:27 PM
Der beste Weg, um Redis -Quellcode zu verstehen, besteht darin, Schritt für Schritt zu gehen: Machen Sie sich mit den Grundlagen von Redis vertraut. Wählen Sie ein bestimmtes Modul oder eine bestimmte Funktion als Ausgangspunkt. Beginnen Sie mit dem Einstiegspunkt des Moduls oder der Funktion und sehen Sie sich die Codezeile nach Zeile an. Zeigen Sie den Code über die Funktionsaufrufkette an. Kennen Sie die von Redis verwendeten Datenstrukturen. Identifizieren Sie den von Redis verwendeten Algorithmus.
 So implementieren Sie die zugrunde liegenden Redis
Apr 10, 2025 pm 07:21 PM
So implementieren Sie die zugrunde liegenden Redis
Apr 10, 2025 pm 07:21 PM
Redis verwendet Hash -Tabellen, um Daten zu speichern und unterstützt Datenstrukturen wie Zeichenfolgen, Listen, Hash -Tabellen, Sammlungen und geordnete Sammlungen. Ernähren sich weiterhin über Daten über Snapshots (RDB) und appendiert Mechanismen nur Schreibmechanismen. Redis verwendet die Master-Slave-Replikation, um die Datenverfügbarkeit zu verbessern. Redis verwendet eine Ereignisschleife mit einer Thread, um Verbindungen und Befehle zu verarbeiten, um die Datenatomizität und Konsistenz zu gewährleisten. Redis legt die Ablaufzeit für den Schlüssel fest und verwendet den faulen Löschmechanismus, um den Ablaufschlüssel zu löschen.
 So lesen Sie Redis -Warteschlange
Apr 10, 2025 pm 10:12 PM
So lesen Sie Redis -Warteschlange
Apr 10, 2025 pm 10:12 PM
Um eine Warteschlange aus Redis zu lesen, müssen Sie den Warteschlangenname erhalten, die Elemente mit dem Befehl LPOP lesen und die leere Warteschlange verarbeiten. Die spezifischen Schritte sind wie folgt: Holen Sie sich den Warteschlangenname: Nennen Sie ihn mit dem Präfix von "Warteschlange:" wie "Warteschlangen: My-Queue". Verwenden Sie den Befehl LPOP: Wischen Sie das Element aus dem Kopf der Warteschlange aus und geben Sie seinen Wert zurück, z. B. die LPOP-Warteschlange: my-queue. Verarbeitung leerer Warteschlangen: Wenn die Warteschlange leer ist, gibt LPOP NIL zurück, und Sie können überprüfen, ob die Warteschlange existiert, bevor Sie das Element lesen.
 So sehen Sie alle Schlüssel in Redis
Apr 10, 2025 pm 07:15 PM
So sehen Sie alle Schlüssel in Redis
Apr 10, 2025 pm 07:15 PM
Um alle Schlüssel in Redis anzuzeigen, gibt es drei Möglichkeiten: Verwenden Sie den Befehl keys, um alle Schlüssel zurückzugeben, die dem angegebenen Muster übereinstimmen. Verwenden Sie den Befehl scan, um über die Schlüssel zu iterieren und eine Reihe von Schlüssel zurückzugeben. Verwenden Sie den Befehl Info, um die Gesamtzahl der Schlüssel zu erhalten.
