
 Technologie-Peripheriegeräte
KI
Multipfad, Multidomäne, alles inklusive! Google AI veröffentlicht das allgemeine Modell MDL für Multi-Domain-Lernen
Technologie-Peripheriegeräte
KI
Multipfad, Multidomäne, alles inklusive! Google AI veröffentlicht das allgemeine Modell MDL für Multi-Domain-Lernen
Multipfad, Multidomäne, alles inklusive! Google AI veröffentlicht das allgemeine Modell MDL für Multi-Domain-Lernen

Deep-Learning-Modelle für visuelle Aufgaben (z. B. Bildklassifizierung) werden normalerweise durchgängig mit Daten aus einer einzelnen visuellen Domäne (z. B. natürlichen Bildern oder computergenerierten Bildern) trainiert.
Im Allgemeinen muss eine Anwendung, die visuelle Aufgaben für mehrere Felder ausführt, mehrere Modelle für jedes einzelne Feld erstellen und diese unabhängig voneinander trainieren. Während der Inferenz werden die feldspezifischen Eingabedaten jedes Modells verarbeitet .
Auch wenn sie auf unterschiedliche Bereiche ausgerichtet sind, sind einige Merkmale der frühen Schichten zwischen diesen Modellen ähnlich, sodass das gemeinsame Training dieser Modelle effizienter ist. Dies reduziert die Latenz und den Stromverbrauch und reduziert die Speicherkosten für die Speicherung jedes Modellparameters. Dieser Ansatz wird als Multi-Domain-Learning (MDL) bezeichnet.
Darüber hinaus können MDL-Modelle auch besser sein als Einzeldomänenmodelle. Zusätzliches Training in einer Domäne kann die Leistung des Modells in einer anderen Domäne verbessern, es kann jedoch auch zu negativen Ergebnissen führen Auswirkungen auf den Wissenstransfer, der von der Trainingsmethode und der spezifischen Domänenkombination abhängt. Obwohl frühere Arbeiten zu MDL die Wirksamkeit domänenübergreifender gemeinsamer Lernaufgaben gezeigt haben, handelt es sich dabei um eine handgefertigte Modellarchitektur, die bei der Anwendung auf andere Arbeiten ineffizient ist.

Link zum Papier: https://arxiv.org/pdf/2010.04904.pdf
Um dieses Problem zu lösen, wird in „Multi-path Neural Networks for On-device Multi -domain Im Artikel „Visual Classification“ schlugen Google-Forscher ein allgemeines MDL-Modell vor.
Der Artikel besagt, dass dieses Modell effektiv eine hohe Genauigkeit erreichen, den negativen Wissenstransfer reduzieren und lernen kann, den positiven Wissenstransfer beim Umgang mit Schwierigkeiten in verschiedenen spezifischen Bereichen zu verbessern.
Zu diesem Zweck schlugen die Forscher eine MPNAS-Methode (Multi-Path Neural Architecture Search) vor, um ein einheitliches Modell mit heterogener Netzwerkarchitektur für mehrere Felder zu erstellen.
Diese Methode erweitert die effiziente Neural Architecture Search (NAS)-Methode von der Einzelpfadsuche auf die Mehrpfadsuche, um gemeinsam einen optimalen Pfad für jedes Feld zu finden. Außerdem wird eine neue Verlustfunktion namens Adaptive Balanced Domain Prioritization (ABDP) eingeführt, die sich an domänenspezifische Schwierigkeiten anpasst, um Modelle effizient zu trainieren. Die resultierende MPNAS-Methode ist effizient und skalierbar.
Obwohl keine Leistungseinbußen auftreten, reduziert das neue Modell die Modellgröße und FLOPS im Vergleich zu Einzeldomänenmethoden um 78 % bzw. 32 %.
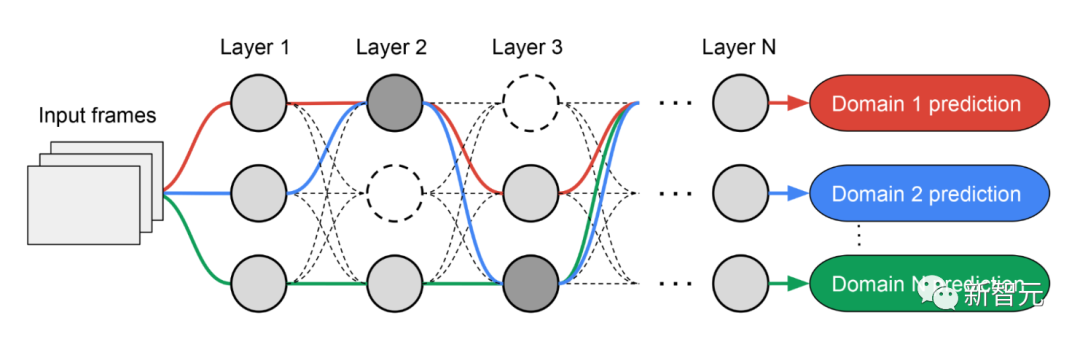
Multipfad-Suche nach neuronalen Strukturen
Um einen positiven Wissenstransfer zu fördern und einen negativen Transfer zu vermeiden, besteht die traditionelle Lösung darin, ein MDL-Modell zu erstellen, sodass jede Domäne die meisten Schichten teilt und die gemeinsamen Funktionen jeder Domäne lernt (Feature-Extraktion genannt) und dann einige domänenspezifische Ebenen darauf aufbauen. Diese Merkmalsextraktionsmethode kann jedoch keine Domänen mit deutlich unterschiedlichen Merkmalen verarbeiten (z. B. Objekte in natürlichen Bildern und künstlerischen Gemälden). Andererseits ist der Aufbau einer einheitlichen heterogenen Struktur für jedes MDL-Modell zeitaufwändig und erfordert domänenspezifisches Wissen.
Multi-path Neural Search Architecture Framework NAS ist ein leistungsstarkes Paradigma für die automatische Gestaltung von Deep-Learning-Architekturen. Es definiert einen Suchraum, der aus verschiedenen potenziellen Bausteinen besteht, die Teil des endgültigen Modells werden können.
Der Suchalgorithmus findet die beste Kandidatenarchitektur aus dem Suchraum, um Modellziele wie Klassifizierungsgenauigkeit zu optimieren. Neuere NAS-Methoden wie TuNAS verbessern die Sucheffizienz durch die Verwendung von End-to-End-Path-Sampling.
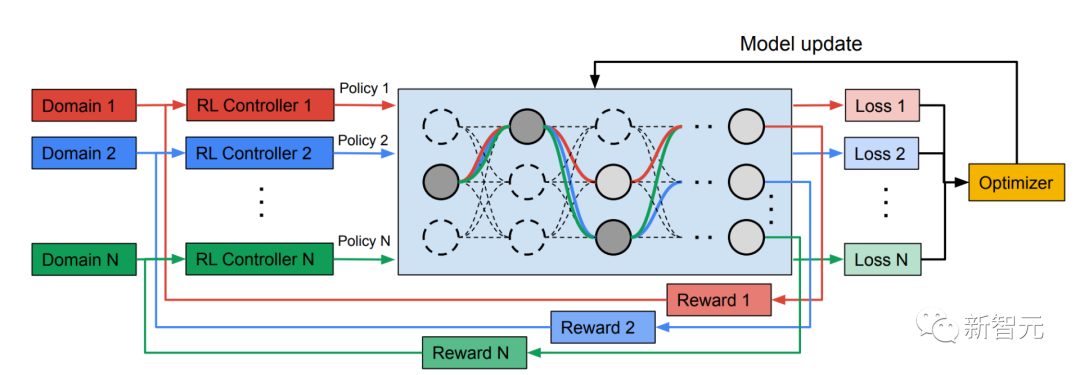
Inspiriert von TuNAS erstellt MPNAS die MDL-Modellarchitektur in zwei Phasen: Suche und Training.
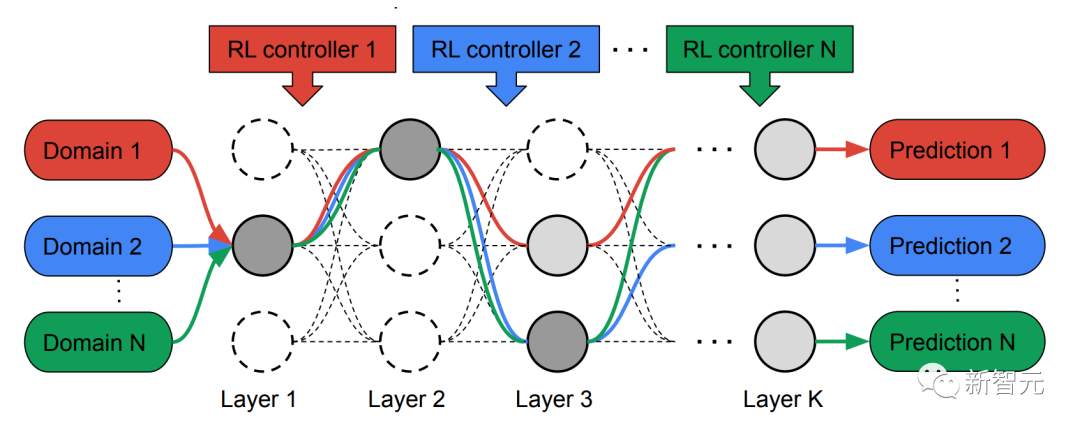
Um gemeinsam einen optimalen Pfad für jede Domäne zu finden, erstellt MPNAS in der Suchphase einen separaten Reinforcement Learning (RL)-Controller für jede Domäne, der im Supernetzwerk (d. h. zwischen den durch die Suche definierten Kandidatenknoten) beginnt Beispiel für End-to-End-Pfade (von der Eingabeschicht zur Ausgabeschicht) innerhalb einer Obermenge aller möglichen Teilnetzwerke.
Über mehrere Iterationen hinweg aktualisieren alle RL-Controller die Pfade, um die RL-Belohnungen in allen Bereichen zu optimieren. Am Ende der Suchphase erhalten wir für jede Domain ein Subnetzwerk. Abschließend werden alle Teilnetzwerke zusammengefasst, um eine heterogene Struktur für das MDL-Modell zu erstellen, wie in der folgenden Abbildung dargestellt.
Da das Subnetzwerk jeder Domäne unabhängig durchsucht wird, können die Komponenten jeder Schicht von mehreren Domänen gemeinsam genutzt werden (d. h. dunkelgraue Knoten) und von einer einzelnen Domäne (d. h. hellgrau) verwendet werden Knoten) oder von keinem Subnetz verwendet wird (d. h. Punktknoten).
Der Pfad jeder Domain kann während des Suchvorgangs auch jede Ebene überspringen. Das Ausgabenetzwerk ist sowohl heterogen als auch effizient, da die Subnetzwerke frei wählen können, welche Blöcke sie unterwegs verwenden möchten, um die Leistung zu optimieren.
Die folgende Abbildung zeigt die Sucharchitektur von zwei Bereichen des Visual Domain Decathlon.
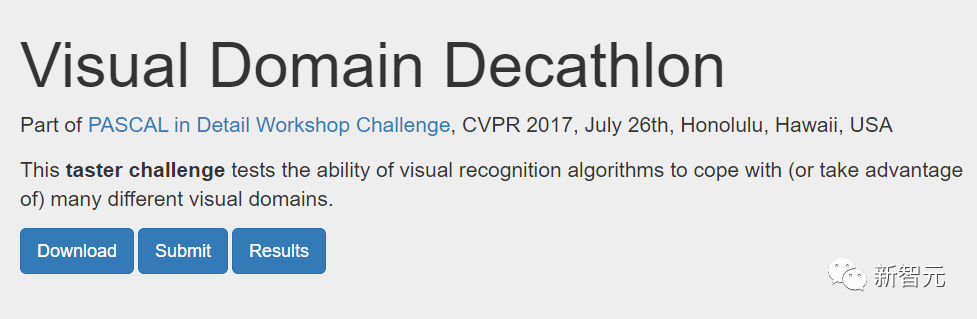
Visual Domain Decathlon ist Teil der PASCAL in Detail Workshop Challenge beim CVPR 2017 und testet die Fähigkeit visueller Erkennungsalgorithmen, viele verschiedene visuelle Domänen zu verarbeiten (oder auszunutzen). Wie man sehen kann, haben die Teilnetze dieser beiden stark verwandten Domänen (eine rote, die andere grüne) die meisten Bausteine ihrer überlappenden Pfade gemeinsam, es gibt jedoch immer noch Unterschiede zwischen ihnen.
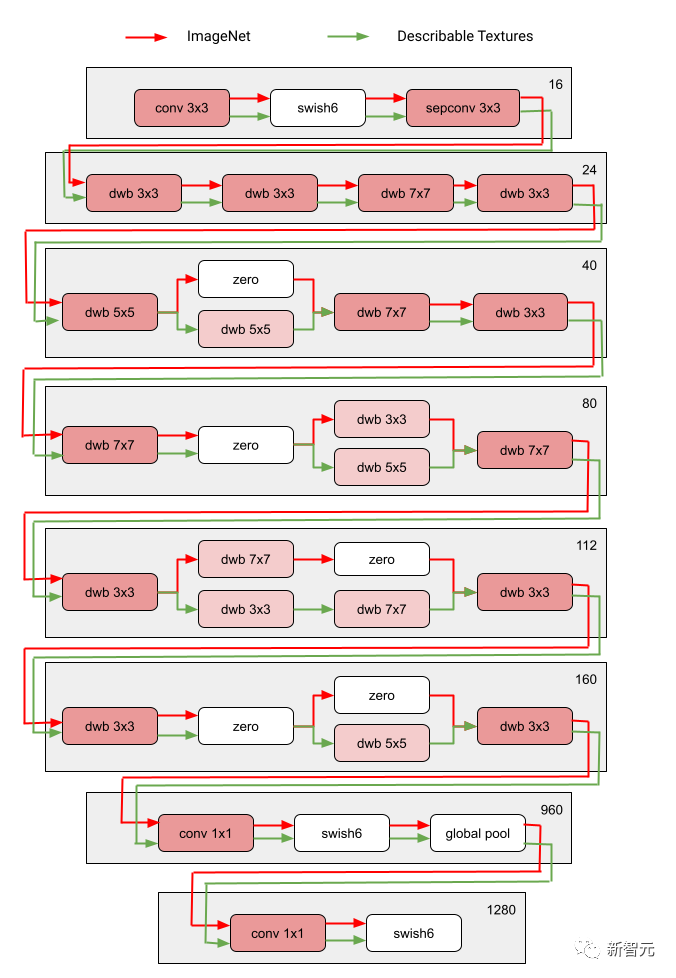
Die roten und grünen Pfade in der Abbildung stellen die Subnetzwerke von ImageNet bzw. Describable Textures dar, die dunkelrosa Knoten stellen Blöcke dar, die von mehreren Domänen gemeinsam genutzt werden, und die hellrosa Knoten stellen die Blöcke dar, die von jedem Pfad verwendet werden. Der „dwb“-Block im Diagramm stellt den dwbottleneck-Block dar. Der Nullblock in der Abbildung zeigt an, dass das Subnetz den Block überspringt Die folgende Abbildung zeigt die Pfadähnlichkeit in den beiden oben genannten Bereichen. Die Ähnlichkeit wird anhand des Jaccard-Ähnlichkeitswerts zwischen Subnetzen für jede Domäne gemessen, wobei ein höherer Wert mehr ähnliche Pfade bedeutet.

Das Bild zeigt die Verwirrungsmatrix der Jaccard-Ähnlichkeitswerte zwischen Pfaden in zehn Domänen. Der Wert liegt zwischen 0 und 1. Je höher der Wert, desto mehr Knoten teilen sich die beiden Pfade.
Heterogene Multidomänenmodelle trainieren
In der zweiten Phase werden die von MPNAS generierten Modelle für alle Domänen von Grund auf trainiert. Dazu ist es notwendig, eine einheitliche Zielfunktion für alle Domänen zu definieren. Um erfolgreich mit einer Vielzahl von Domänen umgehen zu können, haben die Forscher einen Algorithmus namens Adaptive Balanced Domain Prioritization (ABDP) entwickelt, der sich während des gesamten Lernprozesses anpasst, um Verluste zwischen den Domänen auszugleichen. Nachfolgend werden die Genauigkeit, Modellgröße und FLOPS von Modellen angezeigt, die unter verschiedenen Einstellungen trainiert wurden. Wir vergleichen MPNAS mit drei anderen Methoden:
Domänenunabhängiges NAS: Modelle werden für jede Domäne separat gesucht und trainiert.
Single Path Multi-Head: Verwenden Sie ein vorab trainiertes Modell als gemeinsames Rückgrat für alle Domänen mit separaten Klassifizierungsköpfen für jede Domäne.
Multi-Head-NAS: Durchsuchen Sie eine einheitliche Backbone-Architektur für alle Domänen mit separaten Klassifizierungsköpfen für jede Domäne.
Aus den Ergebnissen können wir erkennen, dass NAS für jede Domäne eine Reihe von Modellen erstellen muss, was zu großen Modellen führt. Obwohl Single-Path-Multi-Head- und Multi-Head-NAS die Modellgröße und FLOPS erheblich reduzieren können, führt die Erzwingung der gemeinsamen Nutzung desselben Backbones durch Domänen zu einem negativen Wissenstransfer und verringert dadurch die Gesamtgenauigkeit.

Im Gegensatz dazu kann MPNAS kleine und effiziente Modelle erstellen und dabei dennoch eine hohe Gesamtgenauigkeit beibehalten. Die durchschnittliche Genauigkeit von MPNAS ist sogar 1,9 % höher als die domänenunabhängige NAS-Methode, da das Modell einen aktiven Wissenstransfer erreichen kann. Die folgende Abbildung vergleicht die Top-1-Genauigkeit pro Domäne dieser Methoden.
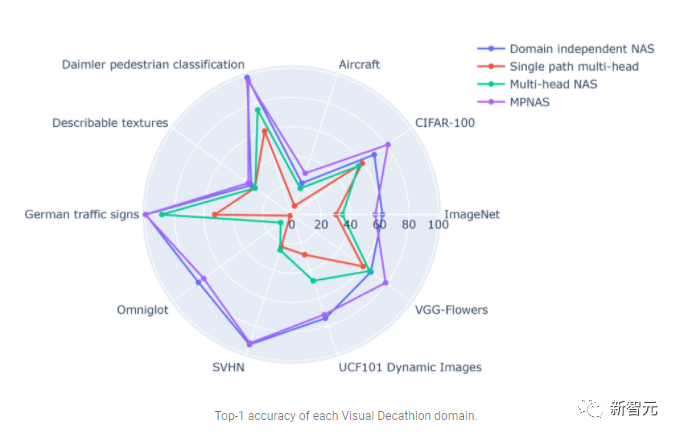
Die Auswertung zeigt, dass durch die Verwendung von ABDP als Teil der Such- und Trainingsphasen die Top-1-Genauigkeit von 69,96 % auf 71,78 % steigt (Delta: +1,81 %).
Zukünftige Richtungen
MPNAS ist eine effektive Lösung für den Aufbau heterogener Netzwerke, um Datenungleichgewicht, Domänenvielfalt, negative Migration, Domänenskalierbarkeit und großen Suchraum für mögliche Strategien zur Parameterfreigabe in MDL anzugehen. Durch die Verwendung eines MobileNet-ähnlichen Suchraums ist das generierte Modell auch mobilfreundlich. Für Aufgaben, die mit vorhandenen Suchalgorithmen nicht kompatibel sind, erweitern Forscher MPNAS weiterhin für das Lernen mit mehreren Aufgaben und hoffen, MPNAS zum Aufbau einheitlicher Multidomänenmodelle verwenden zu können.
Das obige ist der detaillierte Inhalt vonMultipfad, Multidomäne, alles inklusive! Google AI veröffentlicht das allgemeine Modell MDL für Multi-Domain-Lernen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 YOLO ist unsterblich! YOLOv9 wird veröffentlicht: Leistung und Geschwindigkeit SOTA~
Feb 26, 2024 am 11:31 AM
YOLO ist unsterblich! YOLOv9 wird veröffentlicht: Leistung und Geschwindigkeit SOTA~
Feb 26, 2024 am 11:31 AM
Heutige Deep-Learning-Methoden konzentrieren sich darauf, die am besten geeignete Zielfunktion zu entwerfen, damit die Vorhersageergebnisse des Modells der tatsächlichen Situation am nächsten kommen. Gleichzeitig muss eine geeignete Architektur entworfen werden, um ausreichend Informationen für die Vorhersage zu erhalten. Bestehende Methoden ignorieren die Tatsache, dass bei der schichtweisen Merkmalsextraktion und räumlichen Transformation der Eingabedaten eine große Menge an Informationen verloren geht. Dieser Artikel befasst sich mit wichtigen Themen bei der Datenübertragung über tiefe Netzwerke, nämlich Informationsengpässen und umkehrbaren Funktionen. Darauf aufbauend wird das Konzept der programmierbaren Gradienteninformation (PGI) vorgeschlagen, um die verschiedenen Änderungen zu bewältigen, die tiefe Netzwerke zur Erreichung mehrerer Ziele erfordern. PGI kann vollständige Eingabeinformationen für die Zielaufgabe zur Berechnung der Zielfunktion bereitstellen und so zuverlässige Gradienteninformationen zur Aktualisierung der Netzwerkgewichte erhalten. Darüber hinaus wird ein neues, leichtgewichtiges Netzwerk-Framework entworfen
 Dieser „Fehler' ist nicht wirklich ein Fehler: Beginnen Sie mit vier klassischen Aufsätzen, um zu verstehen, was am Transformer-Architekturdiagramm „falsch' ist
Jun 14, 2023 pm 01:43 PM
Dieser „Fehler' ist nicht wirklich ein Fehler: Beginnen Sie mit vier klassischen Aufsätzen, um zu verstehen, was am Transformer-Architekturdiagramm „falsch' ist
Jun 14, 2023 pm 01:43 PM
Vor einiger Zeit löste ein Tweet, der auf die Inkonsistenz zwischen dem Transformer-Architekturdiagramm und dem Code im Papier „AttentionIsAllYouNeed“ des Google Brain-Teams hinwies, viele Diskussionen aus. Manche Leute halten Sebastians Entdeckung für einen unbeabsichtigten Fehler, aber sie ist auch überraschend. Angesichts der Popularität des Transformer-Papiers hätte diese Inkonsistenz schließlich tausendmal erwähnt werden müssen. Sebastian Raschka antwortete auf Kommentare von Internetnutzern, dass der „originellste“ Code zwar mit dem Architekturdiagramm übereinstimme, die 2017 eingereichte Codeversion jedoch geändert, das Architekturdiagramm jedoch nicht gleichzeitig aktualisiert worden sei. Dies ist auch die Ursache für „inkonsistente“ Diskussionen.
 Multipfad, Multidomäne, alles inklusive! Google AI veröffentlicht das allgemeine Modell MDL für Multi-Domain-Lernen
May 28, 2023 pm 02:12 PM
Multipfad, Multidomäne, alles inklusive! Google AI veröffentlicht das allgemeine Modell MDL für Multi-Domain-Lernen
May 28, 2023 pm 02:12 PM
Deep-Learning-Modelle für Sehaufgaben (z. B. Bildklassifizierung) werden normalerweise durchgängig mit Daten aus einem einzelnen visuellen Bereich (z. B. natürlichen Bildern oder computergenerierten Bildern) trainiert. Im Allgemeinen muss eine Anwendung, die Vision-Aufgaben für mehrere Domänen ausführt, mehrere Modelle für jede einzelne Domäne erstellen und diese unabhängig voneinander trainieren. Während der Inferenz verarbeitet jedes Modell eine bestimmte Domäne. Auch wenn sie auf unterschiedliche Bereiche ausgerichtet sind, sind einige Merkmale der frühen Schichten zwischen diesen Modellen ähnlich, sodass das gemeinsame Training dieser Modelle effizienter ist. Dies reduziert die Latenz und den Stromverbrauch und reduziert die Speicherkosten für die Speicherung jedes Modellparameters. Dieser Ansatz wird als Multi-Domain-Learning (MDL) bezeichnet. Darüber hinaus können MDL-Modelle auch Single-Modelle übertreffen
 Was ist die Architektur und das Arbeitsprinzip von Spring Data JPA?
Apr 17, 2024 pm 02:48 PM
Was ist die Architektur und das Arbeitsprinzip von Spring Data JPA?
Apr 17, 2024 pm 02:48 PM
SpringDataJPA basiert auf der JPA-Architektur und interagiert mit der Datenbank über Mapping, ORM und Transaktionsmanagement. Sein Repository bietet CRUD-Operationen und abgeleitete Abfragen vereinfachen den Datenbankzugriff. Darüber hinaus nutzt es Lazy Loading, um Daten nur bei Bedarf abzurufen und so die Leistung zu verbessern.
 1,3 ms dauert 1,3 ms! Tsinghuas neueste Open-Source-Architektur für mobile neuronale Netzwerke RepViT
Mar 11, 2024 pm 12:07 PM
1,3 ms dauert 1,3 ms! Tsinghuas neueste Open-Source-Architektur für mobile neuronale Netzwerke RepViT
Mar 11, 2024 pm 12:07 PM
Papieradresse: https://arxiv.org/abs/2307.09283 Codeadresse: https://github.com/THU-MIG/RepViTRepViT funktioniert gut in der mobilen ViT-Architektur und zeigt erhebliche Vorteile. Als nächstes untersuchen wir die Beiträge dieser Studie. In dem Artikel wird erwähnt, dass Lightweight-ViTs bei visuellen Aufgaben im Allgemeinen eine bessere Leistung erbringen als Lightweight-CNNs, hauptsächlich aufgrund ihres Multi-Head-Selbstaufmerksamkeitsmoduls (MSHA), das es dem Modell ermöglicht, globale Darstellungen zu lernen. Allerdings wurden die architektonischen Unterschiede zwischen Lightweight-ViTs und Lightweight-CNNs noch nicht vollständig untersucht. In dieser Studie integrierten die Autoren leichte ViTs in die effektiven
 Wie steil ist die Lernkurve der Golang-Framework-Architektur?
Jun 05, 2024 pm 06:59 PM
Wie steil ist die Lernkurve der Golang-Framework-Architektur?
Jun 05, 2024 pm 06:59 PM
Die Lernkurve der Go-Framework-Architektur hängt von der Vertrautheit mit der Go-Sprache und der Backend-Entwicklung sowie der Komplexität des gewählten Frameworks ab: einem guten Verständnis der Grundlagen der Go-Sprache. Es ist hilfreich, Erfahrung in der Backend-Entwicklung zu haben. Frameworks mit unterschiedlicher Komplexität führen zu unterschiedlichen Lernkurven.
 Wussten Sie, dass es bei Programmierern in ein paar Jahren einen Niedergang geben wird?
Nov 08, 2023 am 11:17 AM
Wussten Sie, dass es bei Programmierern in ein paar Jahren einen Niedergang geben wird?
Nov 08, 2023 am 11:17 AM
Die Zeitschrift „ComputerWorld“ schrieb einmal in einem Artikel, dass „die Programmierung bis 1960 verschwinden wird“, weil IBM eine neue Sprache FORTRAN entwickelt hat, die es Ingenieuren ermöglicht, die benötigten mathematischen Formeln zu schreiben und sie dann dem Computer zu übermitteln, damit das Programmieren endet. Ein paar Jahre später hörten wir ein neues Sprichwort: Jeder Unternehmer kann Geschäftsbegriffe verwenden, um seine Probleme zu beschreiben und dem Computer zu sagen, was er tun soll. Mit dieser Programmiersprache namens COBOL brauchen Unternehmen keine Programmierer mehr. Später soll IBM eine neue Programmiersprache namens RPG entwickelt haben, mit der Mitarbeiter Formulare ausfüllen und Berichte erstellen können, sodass die meisten Programmieranforderungen des Unternehmens damit erfüllt werden können.
 Erforschung siamesischer Netzwerke unter Verwendung von Kontrastverlust zum Vergleich der Bildähnlichkeit
Apr 02, 2024 am 11:37 AM
Erforschung siamesischer Netzwerke unter Verwendung von Kontrastverlust zum Vergleich der Bildähnlichkeit
Apr 02, 2024 am 11:37 AM
Einleitung Im Bereich Computer Vision ist die genaue Messung der Bildähnlichkeit eine wichtige Aufgabe mit einem breiten Spektrum praktischer Anwendungen. Von Bildsuchmaschinen über Gesichtserkennungssysteme bis hin zu inhaltsbasierten Empfehlungssystemen ist die Fähigkeit, ähnliche Bilder effektiv zu vergleichen und zu finden, wichtig. Das siamesische Netzwerk bietet in Kombination mit Kontrastverlust einen leistungsstarken Rahmen für das datengesteuerte Erlernen der Bildähnlichkeit. In diesem Blogbeitrag werden wir uns mit den Details siamesischer Netzwerke befassen, das Konzept des Kontrastverlusts untersuchen und untersuchen, wie diese beiden Komponenten zusammenarbeiten, um ein effektives Bildähnlichkeitsmodell zu erstellen. Erstens besteht das siamesische Netzwerk aus zwei identischen Teilnetzwerken mit denselben Gewichten und Parametern. Jedes Subnetzwerk codiert das Eingabebild in einen Merkmalsvektor, der
