

So verwenden Sie das itertools-Modul in Python

itertools — Funktionen, die Iteratoren für effiziente Schleifen erstellen
accumulate(iterable: Iterable, func: None, initial:None)
iterable: Iterierbare Objekte, die betrieben werden müssen
func: Erforderlich für iterierbare Objekte Die Operation Funktion muss zwei Parameter enthalten
initial: der Startwert der Akkumulation
Wenn func verwendet wird, um binokulare Operationen an iterierbaren Objekten durchzuführen, müssen zwei Parameter angegeben werden. Was zurückgegeben wird, ist ein Iterator, der unter functools funktioniert. Der Unterschied besteht darin, dass Reduzieren nur das letzte Element zurückgibt, während akkumulieren alle Elemente anzeigt ist wie folgt:
| Differenz | reduzieren | akkumulieren |
|---|---|---|
| Der Rückgabewert | gibt ein Element zurück zu | functools |
| Leistung | etwas schlechter | |
| Anfangswert | kann den Anfangswert festlegen | |
import time
from itertools import accumulate
from functools import reduce
l_data = [1, 2, 3, 4]
data = accumulate(l_data, lambda x, y: x + y, initial=2)
print(list(data))
start = time.time()
for i in range(100000):
data = accumulate(l_data, lambda x, y: x + y, initial=2)
print(time.time() - start)
start = time.time()
for i in range(100000):
data = reduce(lambda x, y: x + y, l_data)
print(time.time() - start)
#输出
[2, 3, 5, 8, 12]
0.027924537658691406
0.03989362716674805Nach dem Login kopieren Aus den obigen Ergebnissen ist ersichtlich, dass die Akkumulation eine etwas bessere Leistung als die Reduzierung aufweist und auch den Zwischenverarbeitungsprozess ausgeben kann. chain(*iterables)iterables: Mehrere iterierbare Objekte empfangen Die Elemente mehrerer iterierbarer Objekte nacheinander zurückgeben und einen Iterator zurückgeben, Bei der Ausgabe von Elementen aus einem Wörterbuch wird standardmäßig der Schlüssel des Wörterbuchs ausgegeben betrieben #🎜 🎜# r: Die Anzahl der extrahierten TeilsequenzelementeBetreibt das iterierbare Objekt und gibt die Teilsequenz entsprechend der Anzahl der zu extrahierenden Teilsequenzen zurück sind ebenfalls geordnet, nicht wiederholbar und werden in Form von Tupeln dargestellt.from itertools import chain
import time
list_data = [1, 2, 3]
dict_data = {"a": 1, "b": 2}
set_data = {4, 5, 6}
print(list(chain(list_data, dict_data, set_data)))
list_data = [1, 2, 3]
list_data2 = [4, 5, 6]
start = time.time()
for i in range(100000):
chain(list_data, list_data2)
print(time.time() - start)
start = time.time()
for i in range(100000):
list_data.extend(list_data2)
print(time.time() - start)
#输出
[1, 2, 3, 'a', 'b', 4, 5, 6]
0.012955427169799805
0.013965129852294922Nach dem Login kopieren from itertools import combinations data = range(5) print(tuple(combinations(data, 2))) str_data = "asdfgh" print(tuple(combinations(str_data, 2))) #输出 ((0, 1), (0, 2), (0, 3), (0, 4), (1, 2), (1, 3), (1, 4), (2, 3), (2, 4), (3, 4)) (('a', 's'), ('a', 'd'), ('a', 'f'), ('a', 'g'), ('a', 'h'), ('s', 'd'), ('s', 'f'), ('s', 'g'), ('s', 'h'), ('d', 'f'), ('d', 'g'), ('d', 'h'), ('f', 'g'), ('f', 'h'), ('g', 'h')) Nach dem Login kopieren
count(start, step)start: Das Startelement step: Die Schrittlänge des Elementwachstums seit dem Start #🎜 🎜## 🎜🎜#Generieren Sie einen steigenden Iterator mit dem Startpunkt und dem steigenden Schritt als gegebenem Wert. Es wird empfohlen, die Methode next() zu verwenden, um Elemente rekursiv abzurufen. from itertools import combinations_with_replacement data = range(5) print(tuple(combinations_with_replacement(data, 2))) str_data = "asdfgh" print(tuple(combinations_with_replacement(str_data, 2))) #输出 ((0, 0), (0, 1), (0, 2), (0, 3), (0, 4), (1, 1), (1, 2), (1, 3), (1, 4), (2, 2), (2, 3), (2, 4), (3, 3), (3, 4), (4, 4)) (('a', 'a'), ('a', 's'), ('a', 'd'), ('a', 'f'), ('a', 'g'), ('a', 'h'), ('s', 's'), ('s', 'd'), ('s', 'f'), ('s', 'g'), ('s', 'h'), ('d', 'd'), ('d', 'f'), ('d', 'g'), ('d', 'h'), ('f', 'f'), ('f', 'g'), ('f', 'h'), ('g', 'g'), ('g', 'h'), ('h', 'h')) Nach dem Login kopieren from itertools import compress data = "asdfg" list_data = [1, 0, 0, 0, 1, 4] print(list(compress(data, list_data))) #输出 ['a', 'g'] Nach dem Login kopieren from itertools import count c = count(start=10, step=20) print(next(c)) print(next(c)) print(next(c)) print(next(c)) print(c) #输出 10 30 50 70 count(90, 20) Nach dem Login kopieren #🎜🎜 #Durch Filtern der Berechnungsergebnisse des Prädikats einen Iterator zurückgeben und die Elemente verwerfen, deren Berechnungsergebnisse in diesem Iterator wahr sind. Unabhängig davon, ob das folgende Element wahr oder falsch ist, wird es ausgegeben, wenn das Prädikat falsch ist. from itertools import cycle a = "asdfg" data = cycle(a) print(next(data)) print(next(data)) print(next(data)) print(next(data)) #输出 a s d f Nach dem Login kopieren filterfalse(predicate, iterable) predicate: Kriterien dafür, ob Elemente verworfen werden solleniterable: iterierbares Objekt #🎜🎜 #Generieren Sie einen Iterator und bestimmen Sie, ob er die Prädikatbedingung erfüllt, bevor Sie Operationen für jedes Element ausführen. Ähnlich der Filtermethode, aber das Gegenteil von Filter.from itertools import dropwhile list_data = [1, 2, 3, 4, 5] print(list(dropwhile(lambda i: i < 3, list_data))) print(list(dropwhile(lambda x: x < 5, [1, 4, 6, 4, 1]))) #输出 [3, 4, 5] [6, 4, 1] Nach dem Login kopieren import time
from itertools import filterfalse
print(list(filterfalse(lambda i: i % 2 == 0, range(10))))
start = time.time()
for i in range(100000):
filterfalse(lambda i: i % 2 == 0, range(10))
print(time.time() - start)
start = time.time()
for i in range(100000):
filter(lambda i: i % 2 == 0, range(10))
print(time.time() - start)
#输出
[1, 3, 5, 7, 9]
0.276653528213501
0.2768676280975342Nach dem Login kopieren #🎜 🎜 #start: Die Indexposition, an der die Operation beginnt stop: Die Indexposition, an der die Operation endet step: Schrittlänge Gibt eine zurück Iterator. Ähnlich wie beim Slicing, aber sein Index unterstützt keine negativen Zahlen. from itertools import groupby
str_data = "babada"
for k, v in groupby(str_data):
print(k, list(v))
str_data = "aaabbbcd"
for k, v in groupby(str_data):
print(k, list(v))
def func(x: str):
print(x)
return x.isdigit()
str_data = "12a34d5"
for k, v in groupby(str_data, key=func):
print(k, list(v))
#输出
b ['b']
a ['a']
b ['b']
a ['a']
d ['d']
a ['a']
a ['a', 'a', 'a']
b ['b', 'b', 'b']
c ['c']
d ['d']
1
2
a
True ['1', '2']
3
False ['a']
4
d
True ['3', '4']
5
False ['d']
True ['5']Nach dem Login kopieren Aus den obigen Ergebnissen ist ersichtlich, dass die Slicing-Leistung etwas besser ist als die Islice-Leistung.pairwise(iterable) Iterierbares Objekt, das bedient werden muss Gibt einen Iterator zurück und gibt aufeinanderfolgende überlappende Paare im iterierbaren Objekt zurück, abzüglich Rückgaben null für beide. from itertools import islice
import time
list_data = [1, 5, 4, 2, 7]
#学习中遇到问题没人解答?小编创建了一个Python学习交流群:725638078
start = time.time()
for i in range(100000):
data = list_data[:2:]
print(time.time() - start)
start = time.time()
for i in range(100000):
data = islice(list_data, 2)
print(time.time() - start)
print(list(islice(list_data, 1, 3)))
print(list(islice(list_data, 1, 4, 2)))
#输出
0.010963201522827148
0.01595783233642578
[5, 4]
[5, 2]
0.010963201522827148
0.01595783233642578
[5, 4]
[5, 2]Nach dem Login kopieren permutations(iterable, r=None) iterable: Iterierbares Objekt, das bedient werden muss r: Extrahierte Teilsequenz #🎜🎜 # Ähnlich wie Kombinationen extrahieren sie Teilsequenzen iterierbarer Objekte. Permutationen sind jedoch nicht wiederholbar und ungeordnet, genau das Gegenteil von Kombinationen_mit_Ersetzung.
product(*iterables, repeat=1)iterables: iterierbares Objekt, kann mehrere sein repeat: iterierbares Objekt Die Anzahl der Wiederholungen Das heißt, die Anzahl der Kopien gibt den Iterator zurück. Analoge Permutationen und Kombinationen erzeugen iterierbare Objekte kartesischer Produkte. Die Produktfunktion ähnelt der Zip-Funktion, aber während zip Elemente eins zu eins zuordnet, erstellt das Produkt eine Eins-zu-viele-Beziehung. from itertools import pairwise str_data = "asdfweffva" list_data = [1, 2, 5, 76, 8] print(list(pairwise(str_data))) print(list(pairwise(list_data))) #输出 [('a', 's'), ('s', 'd'), ('d', 'f'), ('f', 'w'), ('w', 'e'), ('e', 'f'), ('f', 'f'), ('f', 'v'), ('v', 'a')] [(1, 2), (2, 5), (5, 76), (76, 8)] Nach dem Login kopieren from itertools import permutations data = range(5) print(tuple(permutations(data, 2))) str_data = "asdfgh" print(tuple(permutations(str_data, 2))) #输出 ((0, 1), (0, 2), (0, 3), (0, 4), (1, 0), (1, 2), (1, 3), (1, 4), (2, 0), (2, 1), (2, 3), (2, 4), (3, 0), (3, 1), (3, 2), (3, 4), (4, 0), (4, 1), (4, 2), (4, 3)) (('a', 's'), ('a', 'd'), ('a', 'f'), ('a', 'g'), ('a', 'h'), ('s', 'a'), ('s', 'd'), ('s', 'f'), ('s', 'g'), ('s', 'h'), ('d', 'a'), ('d', 's'), ('d', 'f'), ('d', 'g'), ('d', 'h'), ('f', 'a'), ('f', 's'), ('f', 'd'), ('f', 'g'), ('f', 'h'), ('g', 'a'), ('g', 's'), ('g', 'd'), ('g', 'f'), ('g', 'h'), ('h', 'a'), ('h', 's'), ('h', 'd'), ('h', 'f'), ('h', 'g')) Nach dem Login kopieren from itertools import product list_data = [1, 2, 3] list_data2 = [4, 5, 6] print(list(product(list_data, list_data2))) print(list(zip(list_data, list_data2))) # 如下两个含义是一样的,都是将可迭代对象复制一份, 很方便的进行同列表的操作 print(list(product(list_data, repeat=2))) print(list(product(list_data, list_data))) # 同上述含义 print(list(product(list_data, list_data2, repeat=2))) print(list(product(list_data, list_data2, list_data, list_data2))) #输出 [(1, 4), (1, 5), (1, 6), (2, 4), (2, 5), (2, 6), (3, 4), (3, 5), (3, 6)] [(1, 4), (2, 5), (3, 6)] [(1, 1), (1, 2), (1, 3), (2, 1), (2, 2), (2, 3), (3, 1), (3, 2), (3, 3)] [(1, 1), (1, 2), (1, 3), (2, 1), (2, 2), (2, 3), (3, 1), (3, 2), (3, 3)] [(1, 4, 1, 4), (1, 4, 1, 5), (1, 4, 1, 6), (1, 4, 2, 4), (1, 4, 2, 5), (1, 4, 2, 6), (1, 4, 3, 4), (1, 4, 3, 5), (1, 4, 3, 6), (1, 5, 1, 4), (1, 5, 1, 5), (1, 5, 1, 6), (1, 5, 2, 4), (1, 5, 2, 5), (1, 5, 2, 6), (1, 5, 3, 4), (1, 5, 3, 5), (1, 5, 3, 6), (1, 6, 1, 4), (1, 6, 1, 5), (1, 6, 1, 6), (1, 6, 2, 4), (1, 6, 2, 5), (1, 6, 2, 6), (1, 6, 3, 4), (1, 6, 3, 5), (1, 6, 3, 6), (2, 4, 1, 4), (2, 4, 1, 5), (2, 4, 1, 6), (2, 4, 2, 4), (2, 4, 2, 5), (2, 4, 2, 6), (2, 4, 3, 4), (2, 4, 3, 5), (2, 4, 3, 6), (2, 5, 1, 4), (2, 5, 1, 5), (2, 5, 1, 6), (2, 5, 2, 4), (2, 5, 2, 5), (2, 5, 2, 6), (2, 5, 3, 4), (2, 5, 3, 5), (2, 5, 3, 6), (2, 6, 1, 4), (2, 6, 1, 5), (2, 6, 1, 6), (2, 6, 2, 4), (2, 6, 2, 5), (2, 6, 2, 6), (2, 6, 3, 4), (2, 6, 3, 5), (2, 6, 3, 6), (3, 4, 1, 4), (3, 4, 1, 5), (3, 4, 1, 6), (3, 4, 2, 4), (3, 4, 2, 5), (3, 4, 2, 6), (3, 4, 3, 4), (3, 4, 3, 5), (3, 4, 3, 6), (3, 5, 1, 4), (3, 5, 1, 5), (3, 5, 1, 6), (3, 5, 2, 4), (3, 5, 2, 5), (3, 5, 2, 6), (3, 5, 3, 4), (3, 5, 3, 5), (3, 5, 3, 6), (3, 6, 1, 4), (3, 6, 1, 5), (3, 6, 1, 6), (3, 6, 2, 4), (3, 6, 2, 5), (3, 6, 2, 6), (3, 6, 3, 4), (3, 6, 3, 5), (3, 6, 3, 6)] [(1, 4, 1, 4), (1, 4, 1, 5), (1, 4, 1, 6), (1, 4, 2, 4), (1, 4, 2, 5), (1, 4, 2, 6), (1, 4, 3, 4), (1, 4, 3, 5), (1, 4, 3, 6), (1, 5, 1, 4), (1, 5, 1, 5), (1, 5, 1, 6), (1, 5, 2, 4), (1, 5, 2, 5), (1, 5, 2, 6), (1, 5, 3, 4), (1, 5, 3, 5), (1, 5, 3, 6), (1, 6, 1, 4), (1, 6, 1, 5), (1, 6, 1, 6), (1, 6, 2, 4), (1, 6, 2, 5), (1, 6, 2, 6), (1, 6, 3, 4), (1, 6, 3, 5), (1, 6, 3, 6), (2, 4, 1, 4), (2, 4, 1, 5), (2, 4, 1, 6), (2, 4, 2, 4), (2, 4, 2, 5), (2, 4, 2, 6), (2, 4, 3, 4), (2, 4, 3, 5), (2, 4, 3, 6), (2, 5, 1, 4), (2, 5, 1, 5), (2, 5, 1, 6), (2, 5, 2, 4), (2, 5, 2, 5), (2, 5, 2, 6), (2, 5, 3, 4), (2, 5, 3, 5), (2, 5, 3, 6), (2, 6, 1, 4), (2, 6, 1, 5), (2, 6, 1, 6), (2, 6, 2, 4), (2, 6, 2, 5), (2, 6, 2, 6), (2, 6, 3, 4), (2, 6, 3, 5), (2, 6, 3, 6), (3, 4, 1, 4), (3, 4, 1, 5), (3, 4, 1, 6), (3, 4, 2, 4), (3, 4, 2, 5), (3, 4, 2, 6), (3, 4, 3, 4), (3, 4, 3, 5), (3, 4, 3, 6), (3, 5, 1, 4), (3, 5, 1, 5), (3, 5, 1, 6), (3, 5, 2, 4), (3, 5, 2, 5), (3, 5, 2, 6), (3, 5, 3, 4), (3, 5, 3, 5), (3, 5, 3, 6), (3, 6, 1, 4), (3, 6, 1, 5), (3, 6, 1, 6), (3, 6, 2, 4), (3, 6, 2, 5), (3, 6, 2, 6), (3, 6, 3, 4), (3, 6, 3, 5), (3, 6, 3, 6)] Nach dem Login kopieren #🎜🎜 #Gib einen Iterator zurück und wende die Funktion auf alle Elemente des iterierbaren Objekts an (alle Elemente müssen iterierbare Objekte sein, auch wenn nur ein Wert vorhanden ist, müssen sie mit einem iterierbaren Objekt wie einem Tupel (1,) umschlossen werden.) , ähnlich der Kartenfunktion; wenn der Funktionsparameter mit dem iterierbaren Objektelement übereinstimmt, wird anstelle des Elements ein Tupel verwendet, z. B. pow(a, b), was [(2,3), (3, 3)].Der Unterschied zwischen Map und Starmap besteht darin, dass Map normalerweise funktioniert, wenn eine Funktion nur einen Parameter hat, während Starmap funktionieren kann, wenn eine Funktion mehrere Parameter hat. from itertools import starmap
list_data = [1, 2, 3, 4, 5]
list_data2 = [(1, 1), (2, 2), (3, 3), (4, 4), (5, 5)]
list_data3 = [(1,), (2,), (3,), (4,), (5,)]
print(list(starmap(lambda x, y: x + y, list_data2)))
print(list(map(lambda x: x * x, list_data)))
print(list(starmap(lambda x: x * x, list_data)))
print(list(starmap(lambda x: x * x, list_data3)))
#输出
[2, 4, 6, 8, 10]
[1, 4, 9, 16, 25]
Traceback (most recent call last):
File "c:\Users\ts\Desktop\2022.7\2022.7.22\test.py", line 65, in <module>
print(list(starmap(lambda x: x * x, list_data)))
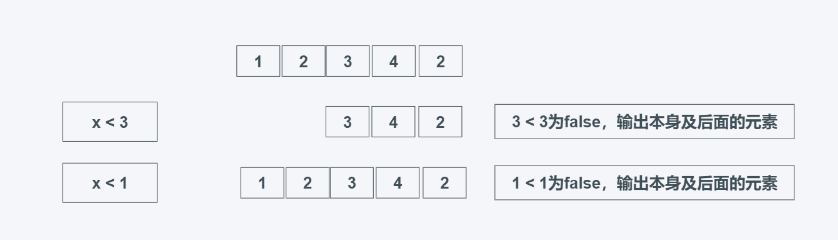
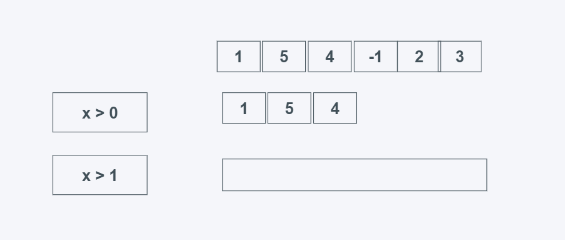
TypeError: 'int' object is not iterableNach dem Login kopieren takewhile(predicate, iterable)predicate:判断条件,为真就返回 iterable: 可迭代对象 当predicate为真时返回元素,需要注意的是,当第一个元素不为True时,则后面的无论结果如何都不会返回,找的前多少个为True的元素。 from itertools import takewhile #学习中遇到问题没人解答?小编创建了一个Python学习交流群:725638078 list_data = [1, 5, 4, 6, 2, 3] print(list(takewhile(lambda x: x > 0, list_data))) print(list(takewhile(lambda x: x > 1, list_data))) Nach dem Login kopieren zip_longest(*iterables, fillvalue=None)iterables:可迭代对象 fillvalue:当长度超过时,缺省值、默认值, 默认为None 返回迭代器, 可迭代对象元素一一对应生成元组,当两个可迭代对象长度不一致时,会按照最长的有元素输出并使用fillvalue补充,是zip的反向扩展,zip为最小长度输出。 from itertools import zip_longest list_data = [1, 2, 3] list_data2 = ["a", "b", "c", "d"] print(list(zip_longest(list_data, list_data2, fillvalue="-"))) print(list(zip_longest(list_data, list_data2))) print(list(zip(list_data, list_data2))) [(1, 'a'), (2, 'b'), (3, 'c'), ('-', 'd')] [(1, 'a'), (2, 'b'), (3, 'c'), (None, 'd')] [(1, 'a'), (2, 'b'), (3, 'c')] Nach dem Login kopieren 总结accumulate(iterable: Iterable, func: None, initial:None): 进行可迭代对象元素的累计运算,可以设置初始值,类似于reduce,相比较reduce,accumulate可以输出中间过程的值,reduce只能输出最后结果,且accumulate性能略好于reduce。 chain(*iterables) 依次输出迭代器中的元素,不会循环输出,有多少输出多少。当输出字典元素时,默认会输出字典的键;而对于列表,则相当于使用extend函数。 combinations(iterable: Iterable, r): 抽取可迭代对象的子序列,其实就是排列组合,不过只返回有序、不重复的子序列,以元组形式呈现。 combinations_with_replacement(iterable: Iterable, r) 类似于combinations,从可迭代对象中提取子序列,但是返回的子序列是无序且不重复的,以元组的形式呈现。 compress(data: Iterable, selectors: Iterable) 根据selectors中的元素是否为True或者False返回可迭代对象的合法元素,selectors为str时,都为True,并且只会决定长度。 count(start, step): 从start开始安装step不断生成元素,是无限循环的,最好控制输出个数或者使用next(),send()等获取、设置结果 cycle(iterable) 循环输出可迭代对象的元素,相当于对chain函数进行无限循环。建议控制输出数据的数量,或使用next()、send()等函数获取或设置返回结果。 dropwhile(predicate, iterable) 根据predicate是否为False来返回可迭代器元素,predicate可以为函数, 返回的是第一个False及之后的所有元素,不管后面的元素是否为True或者False。这个函数适用于舍弃迭代器或可迭代对象的开头部分,比如在写入文件时忽略文档注释
filterfalse(predicate, iterable) 类似于filter方法,返回所有满足predicate条件的元素,作为一个可迭代对象。 groupby(iterable, key=None) 输出连续符合key要求的键值对,默认为x == x。 islice(iterable, stop)\islice(iterable, start, stop[, step]) 对可迭代对象进行切片,和普通切片类似,但是这个不支持负数。这种方法适用于迭代对象的切片,比如你需要获取文件中的某几行内容 pairwise(iterable) 返回连续的重叠对象(两个元素), 少于两个元素返回空,不返回。 permutations(iterable, r=None) 从可迭代对象中抽取子序列,与combinations类似,不过抽取的子序列是无序、可重复。 product(*iterables, repeat=1) 输出可迭代对象的笛卡尔积,类似于排序组合,不可重复,是两个或者多个可迭代对象进行操作,当是一个可迭代对象时,则返回元素,以元组形式返回。 repeat(object[, times]) 重复返回object对象,默认时无限循环 starmap(function, iterable) 批量操作可迭代对象中的元素,操作的可迭代对象中的元素必须也要是可迭代对象,与map类似,但是可以对类似于多元素的元组进行操作。 takewhile(predicate, iterable) 返回前多少个predicate为True的元素,如果第一个为False,则直接输出一个空。
zip_longest(*iterables, fillvalue=None) 将可迭代对象中的元素一一对应,组成元组形式存储,与zip方法类似,不过zip是取最短的,而zip_longest是取最长的,缺少的使用缺省值。 |
Das obige ist der detaillierte Inhalt vonSo verwenden Sie das itertools-Modul in Python. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 PHP und Python: Vergleich von zwei beliebten Programmiersprachen
Apr 14, 2025 am 12:13 AM
PHP und Python: Vergleich von zwei beliebten Programmiersprachen
Apr 14, 2025 am 12:13 AM
PHP und Python haben jeweils ihre eigenen Vorteile und wählen nach den Projektanforderungen. 1.PHP ist für die Webentwicklung geeignet, insbesondere für die schnelle Entwicklung und Wartung von Websites. 2. Python eignet sich für Datenwissenschaft, maschinelles Lernen und künstliche Intelligenz mit prägnanter Syntax und für Anfänger.
 Wie Debian Readdir sich in andere Tools integriert
Apr 13, 2025 am 09:42 AM
Wie Debian Readdir sich in andere Tools integriert
Apr 13, 2025 am 09:42 AM
Die Readdir -Funktion im Debian -System ist ein Systemaufruf, der zum Lesen des Verzeichnisgehalts verwendet wird und häufig in der C -Programmierung verwendet wird. In diesem Artikel wird erläutert, wie Readdir in andere Tools integriert wird, um seine Funktionalität zu verbessern. Methode 1: Kombinieren Sie C -Sprachprogramm und Pipeline zuerst ein C -Programm, um die Funktion der Readdir aufzurufen und das Ergebnis auszugeben:#include#include#includeIntmain (intargc, char*argv []) {Dir*Dir; structDirent*Eintrag; if (argc! = 2) {{
 So konfigurieren Sie den HTTPS -Server in Debian OpenSSL
Apr 13, 2025 am 11:03 AM
So konfigurieren Sie den HTTPS -Server in Debian OpenSSL
Apr 13, 2025 am 11:03 AM
Das Konfigurieren eines HTTPS -Servers auf einem Debian -System umfasst mehrere Schritte, einschließlich der Installation der erforderlichen Software, der Generierung eines SSL -Zertifikats und der Konfiguration eines Webservers (z. B. Apache oder NGINX) für die Verwendung eines SSL -Zertifikats. Hier ist eine grundlegende Anleitung unter der Annahme, dass Sie einen Apacheweb -Server verwenden. 1. Installieren Sie zuerst die erforderliche Software, stellen Sie sicher, dass Ihr System auf dem neuesten Stand ist, und installieren Sie Apache und OpenSSL: sudoaptupdatesudoaptupgradesudoaptinsta
 Python und Zeit: Machen Sie das Beste aus Ihrer Studienzeit
Apr 14, 2025 am 12:02 AM
Python und Zeit: Machen Sie das Beste aus Ihrer Studienzeit
Apr 14, 2025 am 12:02 AM
Um die Effizienz des Lernens von Python in einer begrenzten Zeit zu maximieren, können Sie Pythons DateTime-, Zeit- und Zeitplanmodule verwenden. 1. Das DateTime -Modul wird verwendet, um die Lernzeit aufzuzeichnen und zu planen. 2. Das Zeitmodul hilft, die Studie zu setzen und Zeit zu ruhen. 3. Das Zeitplanmodul arrangiert automatisch wöchentliche Lernaufgaben.
 Gitlabs Plug-in-Entwicklungshandbuch zu Debian
Apr 13, 2025 am 08:24 AM
Gitlabs Plug-in-Entwicklungshandbuch zu Debian
Apr 13, 2025 am 08:24 AM
Die Entwicklung eines Gitlab -Plugins für Debian erfordert einige spezifische Schritte und Kenntnisse. Hier ist ein grundlegender Leitfaden, mit dem Sie mit diesem Prozess beginnen können. Wenn Sie zuerst GitLab installieren, müssen Sie GitLab in Ihrem Debian -System installieren. Sie können sich auf das offizielle Installationshandbuch von GitLab beziehen. Holen Sie sich API Access Token, bevor Sie die API -Integration durchführen. Öffnen Sie das GitLab -Dashboard, finden Sie die Option "AccessTokens" in den Benutzereinstellungen und generieren Sie ein neues Zugriffs -Token. Wird generiert
 Welcher Dienst ist Apache
Apr 13, 2025 pm 12:06 PM
Welcher Dienst ist Apache
Apr 13, 2025 pm 12:06 PM
Apache ist der Held hinter dem Internet. Es ist nicht nur ein Webserver, sondern auch eine leistungsstarke Plattform, die enormen Datenverkehr unterstützt und dynamische Inhalte bietet. Es bietet eine extrem hohe Flexibilität durch ein modulares Design und ermöglicht die Ausdehnung verschiedener Funktionen nach Bedarf. Modularität stellt jedoch auch Konfigurations- und Leistungsherausforderungen vor, die ein sorgfältiges Management erfordern. Apache eignet sich für Serverszenarien, die hoch anpassbare und entsprechende komplexe Anforderungen erfordern.
 PHP und Python: Code Beispiele und Vergleich
Apr 15, 2025 am 12:07 AM
PHP und Python: Code Beispiele und Vergleich
Apr 15, 2025 am 12:07 AM
PHP und Python haben ihre eigenen Vor- und Nachteile, und die Wahl hängt von den Projektbedürfnissen und persönlichen Vorlieben ab. 1.PHP eignet sich für eine schnelle Entwicklung und Wartung großer Webanwendungen. 2. Python dominiert das Gebiet der Datenwissenschaft und des maschinellen Lernens.
 In welcher Sprache wird Apache geschrieben?
Apr 13, 2025 pm 12:42 PM
In welcher Sprache wird Apache geschrieben?
Apr 13, 2025 pm 12:42 PM
Apache ist in C geschrieben. Die Sprache bietet Geschwindigkeit, Stabilität, Portabilität und direkten Zugriff auf Hardware, wodurch es für die Entwicklung von Webserver ideal ist.
