

So stellen Sie die Double-Write-Konsistenz von MySQL und Redis sicher

1. Szenario:
Doppelte Schreibkonsistenz bedeutet, dass nach der Aktualisierung der Daten in der Datenbank auch die Daten in Redis synchron aktualisiert werden müssen. Der Prozess des Lesens von Daten mithilfe von Redis. Wenn der Benutzer auf die Daten zugreift, werden die Daten im Cache direkt an den Benutzer zurückgegeben Im Cache wird zuerst die Datenbank abgefragt. Speichern Sie die abgefragten Daten im Cache und geben Sie sie dann an den Benutzer zurück.
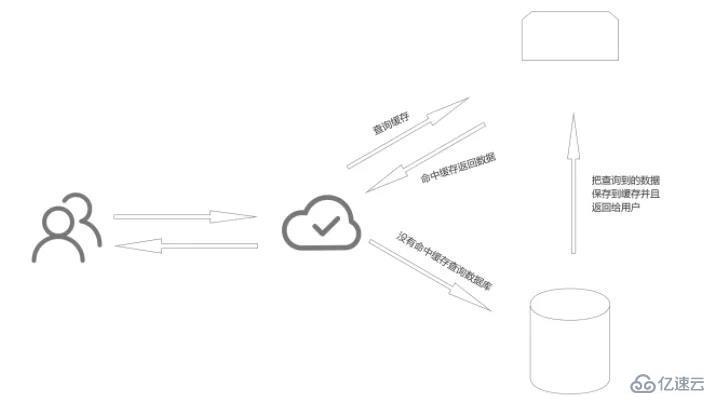
2. Strategie zur Gewährleistung der Doppelschreibkonsistenz
1. Aktualisieren Sie zuerst den Cache, dann aktualisieren Sie die Datenbank
3. Löschen Sie dann den Cache Aktualisieren Sie die Datenbank
4, Aktualisieren Sie zuerst die Datenbank und löschen Sie dann den Cache
Drei, die Vor- und Nachteile der vier Strategien
1. Aktualisieren Sie zuerst den Cache und aktualisieren Sie dann die DatenbankDas Problem ist Offensichtlich. Wenn der Cache erfolgreich aktualisiert wird, die Datenbankaktualisierung jedoch fehlschlägt, werden die Daten beschädigt.
2. Aktualisieren Sie zuerst die Datenbank und dann den Cache. Wenn die Parallelität hoch ist, kann die folgende Situation auftreten Thread A aktualisiert die Datenbank. Wenn Thread A aus Netzwerk- oder anderen Gründen nicht vorhanden ist, aktualisiert ein Prozess B die Datenbank Zu diesem Zeitpunkt geht die Aktualisierung des Caches durch Thread B verloren.3 Löschen Sie zuerst den Cache und aktualisieren Sie dann die Datenbank. Diese Strategie hat möglicherweise die Cache-Verlustsituation vermieden 2, aber egal wie hoch die Parallelität ist, es kommt zu Inkonsistenzen. Beispielsweise führt Thread A zuerst den Cache aus und bereitet die Aktualisierung der Datenbank vor Der Cache wird nicht aufgerufen. Anschließend wird der alte Wert gelesen und im Cache gespeichert. Nach Abschluss der Datenbankaktualisierung sind die Datenbank und der Cache wieder inkonsistent. Wir müssen nur A erneut einfädeln. Nach Abschluss der Datenbankaktualisierung wird der Cache mit einer leichten Verzögerung erneut gelöscht, was auch als verzögertes doppeltes Löschen bezeichnet wird. Die Verzögerungszeit muss dabei größer sein als die Zeit eines Lesevorgangs des Unternehmens.
4. Aktualisieren Sie zuerst die Datenbank und löschen Sie dann den Cache.Auch in Situationen mit hoher Parallelität kommt es zu Inkonsistenzen. Thread A bereitet sich beispielsweise darauf vor, in den Cache zu schreiben Auf die Datenbank wird zugegriffen und dann der Cache gelöscht. Zu diesem Zeitpunkt schreibt Thread A den alten Wert in den Cache. Die Wahrscheinlichkeit, dass dies geschieht, ist jedoch relativ gering, da der Schreibvorgang länger dauert als ein Lesevorgang. Alternativ können die ursprünglichen Wörter vereinfacht und umstrukturiert werden: Um Löschfehler zu beheben, wird empfohlen, eine Lösung mit verzögerter doppelter Löschung zu verwenden. Auch wenn beim verzögerten Doppellöschen weiterhin Probleme auftreten, kann der Löschvorgang wiederholt werden, bis der Cache vollständig geleert ist. Wenn der Löschvorgang fehlschlägt, können wir die zu löschenden Schlüssel in die Warteschlange stellen und versuchen, sie immer wieder zu löschen, bis der Löschvorgang erfolgreich ist.
Das obige ist der detaillierte Inhalt vonSo stellen Sie die Double-Write-Konsistenz von MySQL und Redis sicher. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 So erstellen Sie den Redis -Clustermodus
Apr 10, 2025 pm 10:15 PM
So erstellen Sie den Redis -Clustermodus
Apr 10, 2025 pm 10:15 PM
Der Redis -Cluster -Modus bietet Redis -Instanzen durch Sharding, die Skalierbarkeit und Verfügbarkeit verbessert. Die Bauschritte sind wie folgt: Erstellen Sie ungerade Redis -Instanzen mit verschiedenen Ports; Erstellen Sie 3 Sentinel -Instanzen, Monitor -Redis -Instanzen und Failover; Konfigurieren von Sentinel -Konfigurationsdateien, Informationen zur Überwachung von Redis -Instanzinformationen und Failover -Einstellungen hinzufügen. Konfigurieren von Redis -Instanzkonfigurationsdateien, aktivieren Sie den Cluster -Modus und geben Sie den Cluster -Informationsdateipfad an. Erstellen Sie die Datei nodes.conf, die Informationen zu jeder Redis -Instanz enthält. Starten Sie den Cluster, führen Sie den Befehl erstellen aus, um einen Cluster zu erstellen und die Anzahl der Replikate anzugeben. Melden Sie sich im Cluster an, um den Befehl cluster info auszuführen, um den Clusterstatus zu überprüfen. machen
 Wie man phpmyadmin öffnet
Apr 10, 2025 pm 10:51 PM
Wie man phpmyadmin öffnet
Apr 10, 2025 pm 10:51 PM
Sie können PhpMyAdmin in den folgenden Schritten öffnen: 1. Melden Sie sich beim Website -Bedienfeld an; 2. Finden und klicken Sie auf das Symbol phpmyadmin. 3. Geben Sie MySQL -Anmeldeinformationen ein; 4. Klicken Sie auf "Login".
 PhpMyAdmin Connection MySQL
Apr 10, 2025 pm 10:57 PM
PhpMyAdmin Connection MySQL
Apr 10, 2025 pm 10:57 PM
Wie verbinde ich mit PhpMyAdmin mit MySQL? Die URL zum Zugriff auf phpmyadmin ist normalerweise http: // localhost/phpmyadmin oder http: // [Ihre Server -IP -Adresse]/Phpmyadmin. Geben Sie Ihren MySQL -Benutzernamen und Ihr Passwort ein. Wählen Sie die Datenbank aus, mit der Sie eine Verbindung herstellen möchten. Klicken Sie auf die Schaltfläche "Verbindung", um eine Verbindung herzustellen.
 So lesen Sie den Quellcode von Redis
Apr 10, 2025 pm 08:27 PM
So lesen Sie den Quellcode von Redis
Apr 10, 2025 pm 08:27 PM
Der beste Weg, um Redis -Quellcode zu verstehen, besteht darin, Schritt für Schritt zu gehen: Machen Sie sich mit den Grundlagen von Redis vertraut. Wählen Sie ein bestimmtes Modul oder eine bestimmte Funktion als Ausgangspunkt. Beginnen Sie mit dem Einstiegspunkt des Moduls oder der Funktion und sehen Sie sich die Codezeile nach Zeile an. Zeigen Sie den Code über die Funktionsaufrufkette an. Kennen Sie die von Redis verwendeten Datenstrukturen. Identifizieren Sie den von Redis verwendeten Algorithmus.
 So verwenden Sie den Befehl Redis
Apr 10, 2025 pm 08:45 PM
So verwenden Sie den Befehl Redis
Apr 10, 2025 pm 08:45 PM
Die Verwendung der REDIS -Anweisung erfordert die folgenden Schritte: Öffnen Sie den Redis -Client. Geben Sie den Befehl ein (Verbschlüsselwert). Bietet die erforderlichen Parameter (variiert von der Anweisung bis zur Anweisung). Drücken Sie die Eingabetaste, um den Befehl auszuführen. Redis gibt eine Antwort zurück, die das Ergebnis der Operation anzeigt (normalerweise in Ordnung oder -err).
 So lesen Sie Redis -Warteschlange
Apr 10, 2025 pm 10:12 PM
So lesen Sie Redis -Warteschlange
Apr 10, 2025 pm 10:12 PM
Um eine Warteschlange aus Redis zu lesen, müssen Sie den Warteschlangenname erhalten, die Elemente mit dem Befehl LPOP lesen und die leere Warteschlange verarbeiten. Die spezifischen Schritte sind wie folgt: Holen Sie sich den Warteschlangenname: Nennen Sie ihn mit dem Präfix von "Warteschlange:" wie "Warteschlangen: My-Queue". Verwenden Sie den Befehl LPOP: Wischen Sie das Element aus dem Kopf der Warteschlange aus und geben Sie seinen Wert zurück, z. B. die LPOP-Warteschlange: my-queue. Verarbeitung leerer Warteschlangen: Wenn die Warteschlange leer ist, gibt LPOP NIL zurück, und Sie können überprüfen, ob die Warteschlange existiert, bevor Sie das Element lesen.
 So verwenden Sie Redis Lock
Apr 10, 2025 pm 08:39 PM
So verwenden Sie Redis Lock
Apr 10, 2025 pm 08:39 PM
Um die Operationen zu sperren, muss die Sperre durch den Befehl setNX erfasst werden und dann den Befehl Ablauf verwenden, um die Ablaufzeit festzulegen. Die spezifischen Schritte sind: (1) Verwenden Sie den Befehl setNX, um zu versuchen, ein Schlüsselwertpaar festzulegen; (2) Verwenden Sie den Befehl Ablauf, um die Ablaufzeit für die Sperre festzulegen. (3) Verwenden Sie den Befehl Del, um die Sperre zu löschen, wenn die Sperre nicht mehr benötigt wird.
 So implementieren Sie Redis -Zähler
Apr 10, 2025 pm 10:21 PM
So implementieren Sie Redis -Zähler
Apr 10, 2025 pm 10:21 PM
Der Redis-Zähler ist ein Mechanismus, der die Speicherung von Redis-Schlüsselwertpaaren verwendet, um Zählvorgänge zu implementieren, einschließlich der folgenden Schritte: Erstellen von Zählerschlüssel, Erhöhung der Zählungen, Verringerung der Anzahl, Zurücksetzen der Zählungen und Erhalt von Zählungen. Die Vorteile von Redis -Zählern umfassen schnelle Geschwindigkeit, hohe Parallelität, Haltbarkeit und Einfachheit und Benutzerfreundlichkeit. Es kann in Szenarien wie Benutzerzugriffszählungen, Echtzeit-Metrikverfolgung, Spielergebnissen und Ranglisten sowie Auftragsverarbeitungszählung verwendet werden.
