
 Technologie-Peripheriegeräte
KI
Google stellt PaLM nicht als Open-Source-Lösung zur Verfügung, aber Netizens öffnen es als Open-Source-Lösung! Miniaturversion von Hunderten Milliarden Parametern: Das Maximum beträgt nur 1 Milliarde, 8K-Kontext
Technologie-Peripheriegeräte
KI
Google stellt PaLM nicht als Open-Source-Lösung zur Verfügung, aber Netizens öffnen es als Open-Source-Lösung! Miniaturversion von Hunderten Milliarden Parametern: Das Maximum beträgt nur 1 Milliarde, 8K-Kontext
Google stellt PaLM nicht als Open-Source-Lösung zur Verfügung, aber Netizens öffnen es als Open-Source-Lösung! Miniaturversion von Hunderten Milliarden Parametern: Das Maximum beträgt nur 1 Milliarde, 8K-Kontext

Google hat kein Open-Source-PaLM, aber Internetnutzer haben es als Open-Source-Lösung bereitgestellt.
Gestern hat ein Entwickler drei Miniaturversionen des PaLM-Modells auf GitHub als Open Source bereitgestellt: Parameter sind 150 Millionen (PalM-150m), 410 Millionen (PalM -410m) und 1 Milliarde (PalM-1b).
Projektadresse: https://github.com/conceptofmind/PaLM
Diese drei Modelle wurden auf dem Google C4-Datensatz mit einer Kontextlänge von 8 KB trainiert. Zukünftig werden Modelle mit 2 Milliarden Parametern trainiert.
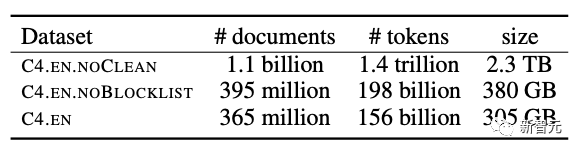
Google C4-Datensatz
#🎜 🎜 #Open Source PaLMBeispiel generiert mit 410-Millionen-Parameter-Modell:
Mein Hund ist sehr süß, aber nicht sehr gut im Sozialisieren mit anderen Hunden. Der Hund liebt alle neuen Menschen und er mag es, mit anderen Hunden in den Park zu gehen. Er hat zwar Mundgeruch, aber das passiert nur, wenn er reinrennt Eine Richtung, in die er derzeit nicht gehen möchte. Er möchte im Park „Hallo“ sagen, möchte aber lieber eine Weile auf sich selbst aufpassen Ich muss mir schon seit 3 Monaten eine Zahnspange besorgen. Der Hund ist sehr schüchtern und verhält sich ein wenig Ich bin mir nicht sicher, ob es eine Hundesache ist oder ob er seine Spielsachen liebt und die ganze Zeit mit seinen Spielsachen spielt. Er ist sogar ein wenig wählerisch mit anderen Hunden. Der Hund ist nur ein kleiner Welpe, der in den Park geht. Er hatte weder schlechtes Maul noch schlechten Atem. aber er kann nicht gut mit anderen Menschen umgehen. Dieser Hund liebt alle neuen Menschen und er liebt es, mit anderen Hunden zu spielen. Ich muss ihn unbedingt mit den anderen Hunden in den Park bringen. Er hat zwar ein wenig den Atem eines Welpen, aber nur, wenn er in eine Richtung rennt, in die er nicht gehen möchte. Jetzt ist mein Hund sehr ungezogen. Er wollte im Park Hallo sagen, wollte aber lieber eine Weile auf sich selbst aufpassen. Er hat auch Mundgeruch. Es ist drei Monate her, seit ich ihm eine Zahnspange kaufen musste. Der Hund hat einige wunde Bissspuren um sein Maul herum. Dieser Hund ist sehr schüchtern und ängstlich. Dieser Hund ist sehr verspielt und etwas verwöhnt. Ich bin mir nicht sicher, ob es die Schuld des Hundes ist oder ob er einfach nur verwöhnt ist. Er liebt seine Spielsachen und möchte einfach nur damit spielen. Er spielt ständig mit seinen Spielsachen und geht sogar spazieren. Er ist etwas wählerisch und versteht sich nicht gut mit anderen Hunden. Der Hund war noch ein Welpe, der in den Park ging. Er ist ein super freundlicher Hund. Er hat kein Problem mehr mit Mundgeruch.Obwohl die Parameter tatsächlich etwas klein sind, ist der erzeugte Effekt immer noch etwas schwer zu beschreiben ...
Diese Modelle sind mit vielen beliebten Lucidrain-Repositories wie Toolformer-pytorch, Palm-rlhf-pytorch und Palm-pytorch kompatibel.
Die drei neuesten Open-Source-Modelle sind Basismodelle und werden anhand größerer Datensätze trainiert.
Alle Modelle werden mit Anweisungen auf FLAN weiter angepasst, um Flan-PaLM-Modelle bereitzustellen.
Das Open-Source-PaLM-Modell wird durch Flash Attention und Xpos Rotary Embeddings trainiert, wodurch eine bessere Längenextrapolation erreicht wird, und verwendet Multi-Query Einzelschlüsselwert-Aufmerksamkeitsmechanismus für eine effizientere Dekodierung. 
In Bezug auf den Optimierungsalgorithmus wird die entkoppelte Gewichtsdämpfung Adam W verwendet, Sie können sich jedoch auch für die Verwendung von Mitchell Wortsmans Stable Adam W entscheiden.
Derzeit wurde das Modell auf den Torch-Hub hochgeladen und die Dateien werden auch im Huggingface-Hub gespeichert.
Wenn das Modell nicht korrekt vom Torch-Hub heruntergeladen werden kann, löschen Sie unbedingt die Prüfpunkte und Modellordner in .cache/torch/hub/. Wenn das Problem immer noch nicht behoben ist, können Sie die Datei aus dem Huggingface-Repository herunterladen. Derzeit wird an der Integration von Huggingface gearbeitet.
Alle Trainingsdaten wurden mit dem GPTNEOX-Tagger vorbeschriftet und die Sequenzlänge wurde auf 8192 gekürzt. Dadurch können erhebliche Kosten bei der Datenvorverarbeitung eingespart werden.
Diese Datensätze wurden auf Huggingface im Parkettformat gespeichert. Die einzelnen Datenblöcke finden Sie hier: C4 Chunk 1, C4 Chunk 2, C4 Chunk 3, C4 Chunk 4 und C4 Chunk 5.
Es gibt eine weitere Option im verteilten Trainingsskript, nicht den bereitgestellten vorbeschrifteten C4-Datensatz zu verwenden, sondern einen anderen Datensatz wie openwebtext zu laden und zu verarbeiten.
Installation
Es ist eine Installationswelle erforderlich, bevor versucht wird, das Modell auszuführen.
<code>git clone https://github.com/conceptofmind/PaLM.gitcd PaLM/pip3 install -r requirements.txt</code>
Mit
können Sie vorab trainierte Modelle über den Torch-Hub für zusätzliches Training oder Feinabstimmung laden:
<code>model = torch.hub.load("conceptofmind/PaLM", "palm_410m_8k_v0").cuda()</code>Darüber hinaus können Sie PyTorch-Modellprüfpunkte auch direkt über die folgende Methode laden:
<code>from palm_rlhf_pytorch import PaLMmodel = PaLM(num_tokens=50304, dim=1024, depth=24, dim_head=128, heads=8, flash_attn=True, qk_rmsnorm = False,).cuda()model.load('/palm_410m_8k_v0.pt')</code>Um das Modell zum Generieren von Text zu verwenden, können Sie die Befehlszeile verwenden:
prompt – Eingabeaufforderung zum Generieren von Text.
seq_len – die Sequenzlänge des generierten Textes, der Standardwert ist 256.
temperature – Probenahmetemperatur, Standard ist 0,8
filter_thres – Filterschwelle, die für die Probenahme verwendet wird. Der Standardwert ist 0,9.
Modell – das für die Generierung verwendete Modell. Es gibt drei verschiedene Parameter (150m, 410m, 1b): palm_150m_8k_v0, palm_410m_8k_v0, palm_1b_8k_v0.
<code>python3 inference.py "My dog is very cute" --seq_len 256 --temperature 0.8 --filter_thres 0.9 --model "palm_410m_8k_v0"</code>
Um die Leistung zu verbessern, verwendet Reasoning Torch.compile(), Flash Attention und Hidet.
Wenn Sie die Generierung durch Hinzufügen von Stream-Verarbeitung oder anderen Funktionen erweitern möchten, stellt der Autor ein allgemeines Inferenzskript „inference.py“ zur Verfügung.
Training
Diese „Open Source Palm“-Modelle werden auf 64 A100 (80GB) GPUs trainiert.
Um das Modelltraining zu erleichtern, stellt der Autor auch ein verteiltes Trainingsskript train_distributed.py bereit.
Es steht Ihnen frei, die Modellebenen und die Hyperparameterkonfiguration zu ändern, um die Hardwareanforderungen zu erfüllen. Außerdem können Sie die Gewichte des Modells laden und das Trainingsskript ändern, um das Modell zu verfeinern.
Abschließend erklärte der Autor, dass er in Zukunft ein spezifisches Feinabstimmungsskript hinzufügen und LoRA erkunden werde.

Daten
Verschiedene Datensätze können vorverarbeitet werden, indem das Skript build_dataset.py auf ähnliche Weise wie der während des Trainings verwendete C4-Datensatz ausgeführt wird. Dadurch werden die Daten vorab gekennzeichnet, in Blöcke mit der angegebenen Sequenzlänge aufgeteilt und auf den Huggingface-Hub hochgeladen.
Zum Beispiel:
<code>python3 build_dataset.py --seed 42 --seq_len 8192 --hf_account "your_hf_account" --tokenizer "EleutherAI/gpt-neox-20b" --dataset_name "EleutherAI/the_pile_deduplicated"</code>
PaLM 2 kommt
Im April 2022 kündigte Google PaLM erstmals offiziell mit 540 Milliarden Parametern an. Wie andere LLMs kann PaLM eine Vielzahl von Textgenerierungs- und Bearbeitungsaufgaben übernehmen.
PaLM ist Googles erster groß angelegter Einsatz des Pathways-Systems zur Skalierung des Trainings auf 6144 Chips. Dies ist die bisher größte TPU-basierte Systemkonfiguration, die für das Training verwendet wurde.
Seine Verständnisfähigkeit ist hervorragend. Es kann nicht nur die Witze verstehen, sondern auch denen, die es nicht verstehen, die lustigen Punkte erklären.

Erst Mitte März öffnete Google zum ersten Mal seine PaLM-API für große Sprachmodelle.

Das bedeutet, dass Menschen damit Aufgaben wie das Zusammenfassen von Text, das Schreiben von Code und sogar das Trainieren von PaLM in einen Konversations-Chatbot wie ChatGPT verwenden können.
Auf der kommenden Google-Jahreskonferenz I/O wird Pichai die neuesten Entwicklungen des Unternehmens im Bereich KI bekannt geben.
Es heißt, dass das neueste und fortschrittlichste groß angelegte Sprachmodell PaLM 2 bald auf den Markt kommen wird.
PaLM 2 umfasst mehr als 100 Sprachen und läuft unter dem internen Codenamen „Unified Language Model“. Darüber hinaus werden umfangreiche Tests in den Bereichen Codierung und Mathematik sowie kreatives Schreiben durchgeführt.
Letzten Monat gab Google bekannt, dass sein medizinisches LLM „Med-PalM2“ medizinische Untersuchungsfragen mit einer Genauigkeit von 85 % auf „Expert Doctor Level“ beantworten kann.
Darüber hinaus wird Google auch den Chat-Roboter Bard veröffentlichen, der von großen Modellen unterstützt wird, sowie ein generatives Erlebnis für die Suche.
Ob die neueste KI-Version Google den Rücken stärken kann, bleibt abzuwarten.
Das obige ist der detaillierte Inhalt vonGoogle stellt PaLM nicht als Open-Source-Lösung zur Verfügung, aber Netizens öffnen es als Open-Source-Lösung! Miniaturversion von Hunderten Milliarden Parametern: Das Maximum beträgt nur 1 Milliarde, 8K-Kontext. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Wie man Deepseek kommentiert
Feb 19, 2025 pm 05:42 PM
Wie man Deepseek kommentiert
Feb 19, 2025 pm 05:42 PM
Deepseek ist ein leistungsstarkes Informations -Abruf -Tool. .
 So suchen Sie Deepseek
Feb 19, 2025 pm 05:39 PM
So suchen Sie Deepseek
Feb 19, 2025 pm 05:39 PM
Deepseek ist eine proprietäre Suchmaschine, die nur schneller und genauer in einer bestimmten Datenbank oder einem bestimmten System sucht. Bei der Verwendung wird den Benutzern empfohlen, das Dokument zu lesen, verschiedene Suchstrategien auszuprobieren, Hilfe und Feedback zur Benutzererfahrung zu suchen, um die Vorteile optimal zu nutzen.
 Sesame Open Door Exchange -Webseite Registrierung Link Gate Trading App Registrierung Website Neueste
Feb 28, 2025 am 11:06 AM
Sesame Open Door Exchange -Webseite Registrierung Link Gate Trading App Registrierung Website Neueste
Feb 28, 2025 am 11:06 AM
In diesem Artikel wird der Registrierungsprozess der Webversion Sesam Open Exchange (GATE.IO) und die Gate Trading App im Detail vorgestellt. Unabhängig davon, ob es sich um eine Webregistrierung oder eine App -Registrierung handelt, müssen Sie die offizielle Website oder den offiziellen App Store besuchen, um die Genuine App herunterzuladen, und dann den Benutzernamen, das Kennwort, die E -Mail, die Mobiltelefonnummer und die anderen Informationen eingeben und eine E -Mail- oder Mobiltelefonüberprüfung abschließen.
 Warum kann der Bybit -Exchange -Link nicht direkt heruntergeladen und installiert werden?
Feb 21, 2025 pm 10:57 PM
Warum kann der Bybit -Exchange -Link nicht direkt heruntergeladen und installiert werden?
Feb 21, 2025 pm 10:57 PM
Warum kann der Bybit -Exchange -Link nicht direkt heruntergeladen und installiert werden? Bitbit ist eine Kryptowährungsbörse, die den Benutzern Handelsdienste anbietet. Die mobilen Apps der Exchange können aus den folgenden Gründen nicht direkt über AppStore oder Googleplay heruntergeladen werden: 1. App Store -Richtlinie beschränkt Apple und Google daran, strenge Anforderungen an die im App Store zulässigen Anwendungsarten zu haben. Kryptowährungsanträge erfüllen diese Anforderungen häufig nicht, da sie Finanzdienstleistungen einbeziehen und spezifische Vorschriften und Sicherheitsstandards erfordern. 2. Die Einhaltung von Gesetzen und Vorschriften In vielen Ländern werden Aktivitäten im Zusammenhang mit Kryptowährungstransaktionen reguliert oder eingeschränkt. Um diese Vorschriften einzuhalten, kann die Bitbit -Anwendung nur über offizielle Websites oder andere autorisierte Kanäle verwendet werden
 Sesame Open Door Trading Platform Download Mobile Version Gateio Trading Platform Download -Adresse
Feb 28, 2025 am 10:51 AM
Sesame Open Door Trading Platform Download Mobile Version Gateio Trading Platform Download -Adresse
Feb 28, 2025 am 10:51 AM
Es ist wichtig, einen formalen Kanal auszuwählen, um die App herunterzuladen und die Sicherheit Ihres Kontos zu gewährleisten.
 Top 10 für Crypto Digital Asset Trading App (2025 Global Ranking) empfohlen
Mar 18, 2025 pm 12:15 PM
Top 10 für Crypto Digital Asset Trading App (2025 Global Ranking) empfohlen
Mar 18, 2025 pm 12:15 PM
Dieser Artikel empfiehlt die Top Ten Ten Cryptocurrency -Handelsplattformen, die es wert sind, auf Binance, OKX, Gate.io, Bitflyer, Kucoin, Bybit, Coinbase Pro, Kraken, BYDFI und Xbit -dezentrale Börsen geachtet zu werden. Diese Plattformen haben ihre eigenen Vorteile in Bezug auf Transaktionswährungsmenge, Transaktionstyp, Sicherheit, Konformität und Besonderheiten. Die Auswahl einer geeigneten Plattform erfordert eine umfassende Überlegung, die auf eigener Handelserfahrung, Risikotoleranz und Investitionspräferenzen basiert. Ich hoffe, dieser Artikel hilft Ihnen dabei, den besten Anzug für sich selbst zu finden
 Binance Binance Offizielle Website Neueste Version Anmeldeportal
Feb 21, 2025 pm 05:42 PM
Binance Binance Offizielle Website Neueste Version Anmeldeportal
Feb 21, 2025 pm 05:42 PM
Befolgen Sie diese einfachen Schritte, um auf die neueste Version des Binance -Website -Login -Portals zuzugreifen. Gehen Sie zur offiziellen Website und klicken Sie in der oberen rechten Ecke auf die Schaltfläche "Anmeldung". Wählen Sie Ihre vorhandene Anmeldemethode. Geben Sie Ihre registrierte Handynummer oder E -Mail und Kennwort ein und vervollständigen Sie die Authentifizierung (z. B. Mobilfifizierungscode oder Google Authenticator). Nach einer erfolgreichen Überprüfung können Sie auf das neueste Version des offiziellen Website -Login -Portals von Binance zugreifen.
 Die neueste Download -Adresse des Bitgets im Jahr 2025: Schritte zum Erhalten der offiziellen App
Feb 25, 2025 pm 02:54 PM
Die neueste Download -Adresse des Bitgets im Jahr 2025: Schritte zum Erhalten der offiziellen App
Feb 25, 2025 pm 02:54 PM
Dieser Leitfaden enthält detaillierte Download- und Installationsschritte für die offizielle Bitget Exchange -App, die für Android- und iOS -Systeme geeignet ist. Der Leitfaden integriert Informationen aus mehreren maßgeblichen Quellen, einschließlich der offiziellen Website, dem App Store und Google Play, und betont Überlegungen während des Downloads und des Kontoverwaltung. Benutzer können die App aus offiziellen Kanälen herunterladen, einschließlich App Store, offizieller Website APK Download und offizieller Website -Sprung sowie vollständige Registrierung, Identitätsüberprüfung und Sicherheitseinstellungen. Darüber hinaus deckt der Handbuch häufig gestellte Fragen und Überlegungen ab, wie z.
