
 Technologie-Peripheriegeräte
KI
Innerhalb von 24 Stunden und 200 US-Dollar für die Kopie des RLHF-Prozesses stellte Stanford die „Alpaca Farm' als Open-Source-Lösung zur Verfügung.
Technologie-Peripheriegeräte
KI
Innerhalb von 24 Stunden und 200 US-Dollar für die Kopie des RLHF-Prozesses stellte Stanford die „Alpaca Farm' als Open-Source-Lösung zur Verfügung.
Innerhalb von 24 Stunden und 200 US-Dollar für die Kopie des RLHF-Prozesses stellte Stanford die „Alpaca Farm' als Open-Source-Lösung zur Verfügung.

Ende Februar veröffentlichte Meta eine große Modellreihe LLaMA (wörtlich übersetzt „Alpaka“) als Open-Source-Version mit Parametern zwischen 7 und 65 Milliarden, die als Prototyp der Meta-Version von ChatGPT bezeichnet wird. Danach führten Institutionen wie die Stanford University und die University of California, Berkeley, „sekundäre Innovationen“ auf Basis von LLaMA durch und brachten nacheinander mehrere Open-Source-Großmodelle wie Alpaca und Vicuna auf den Markt. Eine Zeit lang wurde „Alpaca“ zum Spitzenmodell im KI-Kreis. Diese von der Open-Source-Community erstellten ChatGPT-ähnlichen Modelle lassen sich sehr schnell iterieren und sind hochgradig anpassbar. Sie werden als Open-Source-Ersatz von ChatGPT bezeichnet.
Der Grund, warum ChatGPT jedoch leistungsstarke Fähigkeiten beim Verstehen, Generieren, Denken usw. von Texten zeigen kann, liegt darin, dass OpenAI ein neues Trainingsparadigma für große Modelle wie ChatGPT verwendet – RLHF (Reinforcement Learning from Human Feedback). Das Sprachmodell wird basierend auf menschlichem Feedback durch verstärkendes Lernen optimiert. Mit RLHF-Methoden können große Sprachmodelle an menschlichen Vorlieben ausgerichtet werden, menschlichen Absichten folgen und nicht hilfreiche, verzerrte oder voreingenommene Ausgaben minimieren. Allerdings ist die RLHF-Methode auf umfangreiche manuelle Anmerkungen und Auswertungen angewiesen, was oft Wochen und Tausende von Dollar erfordert, um menschliches Feedback zu sammeln, was kostspielig ist.
Jetzt hat die Stanford University, die das Open-Source-Modell Alpaca auf den Markt gebracht hat, einen weiteren Simulator vorgeschlagen – AlpacaFarm (wörtlich übersetzt als Alpaka-Farm). AlpacaFarm kann den RLHF-Prozess in 24 Stunden für nur etwa 200 US-Dollar replizieren, wodurch Open-Source-Modelle die Ergebnisse menschlicher Auswertungen schnell verbessern können, was als Äquivalent zu RLHF bezeichnet werden kann.

AlpacaFarm versucht, schnell und kostengünstig Lernmethoden aus menschlichem Feedback zu entwickeln. Zu diesem Zweck identifizierte das Stanford-Forschungsteam zunächst drei Hauptschwierigkeiten bei der Untersuchung von RLHF-Methoden: die hohen Kosten für menschliche Präferenzdaten, den Mangel an vertrauenswürdigen Auswertungen und den Mangel an Referenzimplementierungen.
Um diese drei Probleme zu lösen, hat AlpacaFarm spezifische Implementierungen von Simulationsannotatoren, automatischer Auswertung und SOTA-Methoden entwickelt. Derzeit ist der AlpacaFarm-Projektcode Open Source.
- GitHub-Adresse: https://github.com/tatsu-lab/alpaca_farm
- Paper-Adresse: https://tatsu-lab.github.io/alpaca_farm_paper. pdf
Wie in der Abbildung unten gezeigt, können Forscher mit dem AlpacaFarm-Simulator schnell neue Lernmethoden aus menschlichen Feedbackdaten entwickeln und auch bestehende SOTA-Methoden auf tatsächliche menschliche Präferenzdaten migrieren.
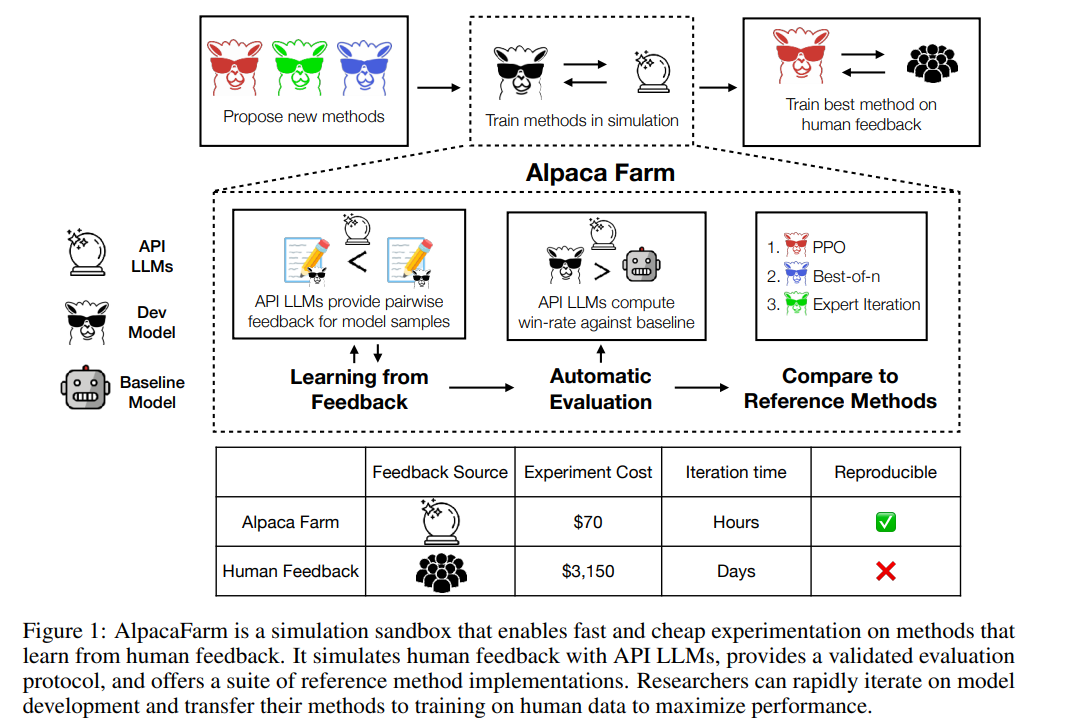
Simulationsannotator
AlpacaFarm basiert auf den 52.000 Anweisungen des Alpaca-Datensatzes, von denen 10.000 Anweisungen zur Feinabstimmung der grundlegenden Anweisungen nach dem Modell verwendet werden und die restlichen 42.000 Anweisungen verwendet werden Wird zum Erlernen menschlicher Vorlieben und Bewertungen verwendet und wird hauptsächlich zum Lernen von simulierten Annotatoren verwendet. Diese Studie befasst sich mit den drei Hauptherausforderungen Annotationskosten, Bewertung und Verifizierungsimplementierung der RLHF-Methode und schlägt nacheinander Lösungen vor.
Um die Annotationskosten zu reduzieren, wurden in dieser Studie zunächst Eingabeaufforderungen für API-zugängliche LLMs (wie GPT-4, ChatGPT) erstellt, die es AlpacaFarm ermöglichen, menschliches Feedback zu nur 1/45 der Kosten für die Datenerfassung zu simulieren die RLHF-Methode. Diese Studie entwarf ein zufälliges, verrauschtes Annotationsschema unter Verwendung von 13 verschiedenen Eingabeaufforderungen, um unterschiedliche menschliche Präferenzen aus mehreren LLMs zu extrahieren. Dieses Annotationsschema zielt darauf ab, verschiedene Aspekte des menschlichen Feedbacks zu erfassen, wie z. B. Qualitätsbeurteilungen, Variabilität zwischen Annotatoren und Stilpräferenzen.
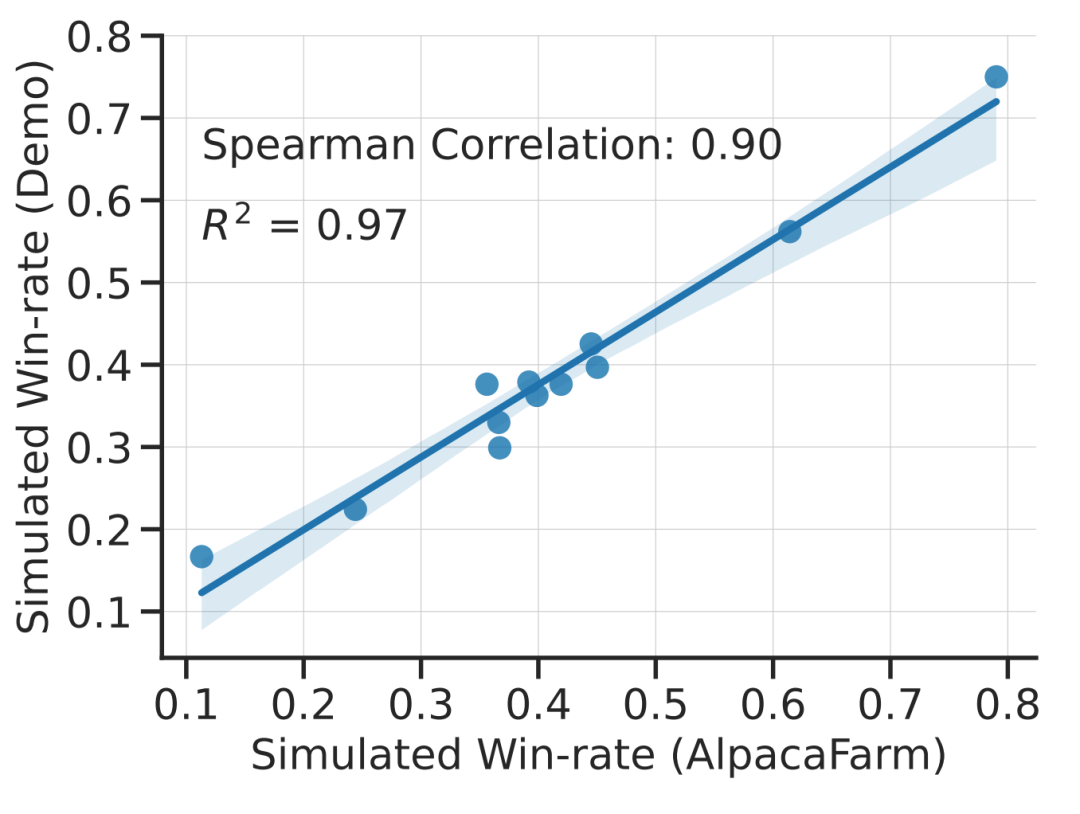
Diese Studie zeigt experimentell, dass die Simulationen von AlpacaFarm korrekt sind. Als das Forschungsteam AlpacaFarm zum Trainieren und Entwickeln von Methoden nutzte, rangierten die Methoden sehr konsistent mit den gleichen Methoden, die mithilfe tatsächlichen menschlichen Feedbacks trainiert und entwickelt wurden. Die folgende Abbildung zeigt die hohe Korrelation in den Rankings zwischen den Methoden, die sich aus dem AlpacaFarm-Simulationsworkflow und dem Human-Feedback-Workflow ergeben. Diese Eigenschaft ist von entscheidender Bedeutung, da sie zeigt, dass experimentelle Schlussfolgerungen aus Simulationen wahrscheinlich auch in realen Situationen zutreffen.
Zusätzlich zur Korrelation auf Methodenebene kann der AlpacaFarm-Simulator auch qualitative Phänomene wie eine Überoptimierung des Belohnungsmodells nachbilden, aber kontinuierliches RLHF-Training für Ersatzbelohnungen kann die Modellleistung beeinträchtigen. Die folgende Abbildung zeigt dieses Phänomen im Fall von menschlichem Feedback (links) und AlpacaFarm (rechts). Wir können sehen, dass AlpacaFarm zunächst das korrekte deterministische Verhalten der Modellleistungsverbesserung erfasst und dann mit fortschreitendem RLHF-Training die Modellleistung abnimmt.
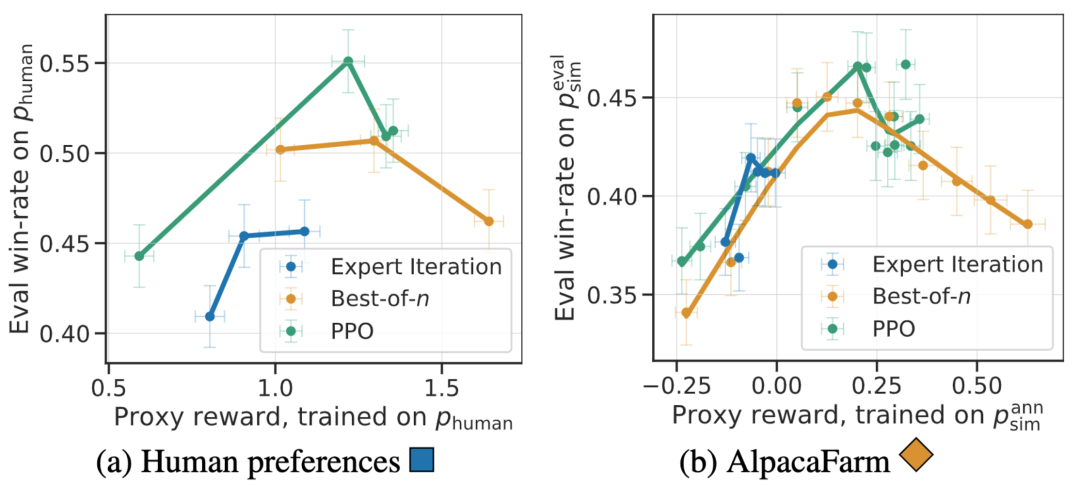
Bewertung
Zur Bewertung nutzte das Forschungsteam Echtzeit-Benutzerinteraktionen mit Alpaca 7B als Orientierungshilfe und simulierte die Verteilung von Anweisungen, indem es mehrere vorhandene öffentliche Datensätze kombinierte, darunter Selbstanweisungsdatensätze und anthropopische Hilfsbereitschaft Datensatz und Auswertungssatz für Open Assistant, Koala und Vicuna. Anhand dieser Bewertungsanweisungen verglich die Studie die Reaktion des RLHF-Modells mit der des Davinci003-Modells und verwendete einen Score, um zu messen, wie oft das RLHF-Modell besser reagierte, wobei dieser Score als Win-Rate bezeichnet wurde. Wie in der folgenden Abbildung dargestellt, zeigt eine quantitative Auswertung der Systemrankings anhand der Auswertungsdaten der Studie, dass Systemrankings und Echtzeit-Benutzerbefehle stark korrelieren. Dieses Ergebnis zeigt, dass durch die Aggregation vorhandener öffentlicher Daten eine ähnliche Leistung wie bei einfachen realen Anweisungen erzielt werden kann.
Referenzmethode
Für die dritte Herausforderung – fehlende Referenzimplementierung – implementierte und testete das Forschungsteam mehrere beliebte Lernalgorithmen (wie PPO, Experteniteration, Best-of-n-Sampling). . Das Forschungsteam stellte fest, dass einfachere Methoden, die in anderen Bereichen funktionierten, nicht besser waren als das ursprüngliche SFT-Modell der Studie, was darauf hindeutet, dass es wichtig ist, diese Algorithmen in einer realen Umgebung zur Befolgung von Anweisungen zu testen.
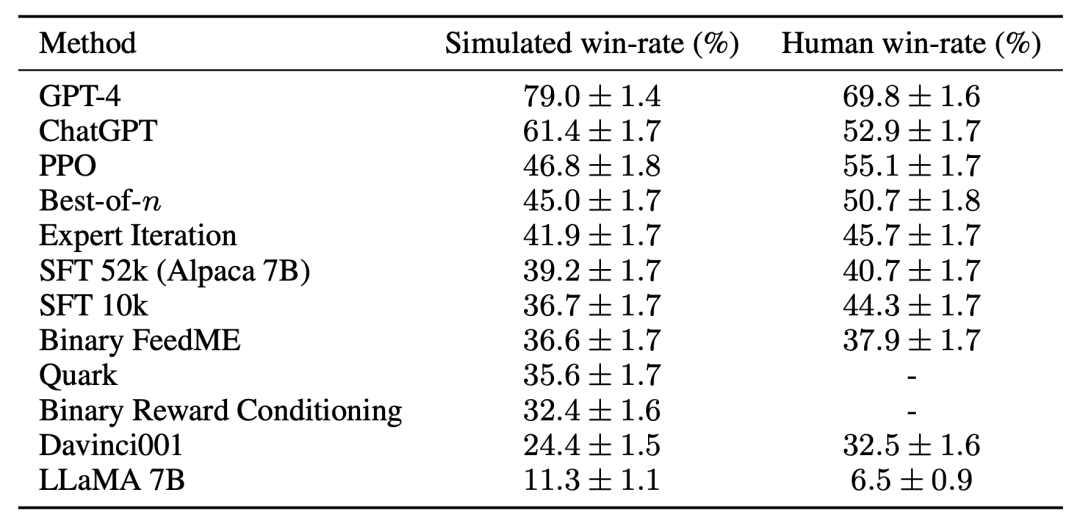
Basierend auf der manuellen Auswertung erwies sich der PPO-Algorithmus als der effektivste und erhöhte die Gewinnquote des Modells von 44 % auf 55 % im Vergleich zu Davinci003 und übertraf sogar ChatGPT.
Diese Ergebnisse zeigen, dass der PPO-Algorithmus die Gewinnquote für das Modell sehr effektiv optimiert. Es ist wichtig zu beachten, dass diese Ergebnisse spezifisch für die Bewertungsdaten und Kommentatoren dieser Studie sind. Während es sich bei den Bewertungsanweisungen der Studie um Benutzeranweisungen in Echtzeit handelt, decken sie möglicherweise keine anspruchsvolleren Probleme ab, und es ist nicht sicher, inwieweit die Verbesserung der Erfolgsquote durch die Ausnutzung von Stilpräferenzen und nicht durch Faktizität oder Korrektheit erzielt wird. Die Studie ergab beispielsweise, dass das PPO-Modell eine viel längere Ausgabezeit lieferte und oft detailliertere Erklärungen für die Antworten lieferte, wie unten gezeigt: Simulierte Präferenzen können die menschlichen Bewertungsergebnisse des Modells erheblich verbessern, ohne dass das Modell erneut auf menschliche Präferenzen trainiert werden muss. Obwohl dieser Übertragungsprozess fragil und immer noch etwas weniger effektiv ist als die Umschulung des Modells anhand menschlicher Präferenzdaten. Es kann jedoch die RLHF-Pipeline innerhalb von 24 Stunden für nur 200 US-Dollar kopieren, sodass das Modell die Leistung der menschlichen Bewertung schnell verbessern kann. Der Simulator AlpacaFarm wird von der Open-Source-Community erstellt, um die leistungsstarken Funktionen von Modellen wie z ChatGPT. Ein weiterer Versuch.
Das obige ist der detaillierte Inhalt vonInnerhalb von 24 Stunden und 200 US-Dollar für die Kopie des RLHF-Prozesses stellte Stanford die „Alpaca Farm' als Open-Source-Lösung zur Verfügung.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Verarbeiten Sie 7 Millionen Aufzeichnungen effizient und erstellen Sie interaktive Karten mit Geospatial -Technologie. In diesem Artikel wird untersucht, wie über 7 Millionen Datensätze mithilfe von Laravel und MySQL effizient verarbeitet und in interaktive Kartenvisualisierungen umgewandelt werden können. Erstes Herausforderungsprojektanforderungen: Mit 7 Millionen Datensätzen in der MySQL -Datenbank wertvolle Erkenntnisse extrahieren. Viele Menschen erwägen zunächst Programmiersprachen, aber ignorieren die Datenbank selbst: Kann sie den Anforderungen erfüllen? Ist Datenmigration oder strukturelle Anpassung erforderlich? Kann MySQL einer so großen Datenbelastung standhalten? Voranalyse: Schlüsselfilter und Eigenschaften müssen identifiziert werden. Nach der Analyse wurde festgestellt, dass nur wenige Attribute mit der Lösung zusammenhängen. Wir haben die Machbarkeit des Filters überprüft und einige Einschränkungen festgelegt, um die Suche zu optimieren. Kartensuche basierend auf der Stadt
 Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Es gibt viele Gründe, warum MySQL Startup fehlschlägt und durch Überprüfung des Fehlerprotokolls diagnostiziert werden kann. Zu den allgemeinen Ursachen gehören Portkonflikte (prüfen Portbelegung und Änderung der Konfiguration), Berechtigungsprobleme (Überprüfen Sie den Dienst Ausführen von Benutzerberechtigungen), Konfigurationsdateifehler (Überprüfung der Parametereinstellungen), Datenverzeichniskorruption (Wiederherstellung von Daten oder Wiederaufbautabellenraum), InnoDB-Tabellenraumprobleme (prüfen IBDATA1-Dateien), Plug-in-Ladeversagen (Überprüfen Sie Fehlerprotokolle). Wenn Sie Probleme lösen, sollten Sie sie anhand des Fehlerprotokolls analysieren, die Hauptursache des Problems finden und die Gewohnheit entwickeln, Daten regelmäßig zu unterstützen, um Probleme zu verhindern und zu lösen.
 So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
Der Artikel führt den Betrieb der MySQL -Datenbank vor. Zunächst müssen Sie einen MySQL -Client wie MySQLworkBench oder Befehlszeilen -Client installieren. 1. Verwenden Sie den Befehl mySQL-uroot-P, um eine Verbindung zum Server herzustellen und sich mit dem Stammkonto-Passwort anzumelden. 2. Verwenden Sie die Erstellung von Createdatabase, um eine Datenbank zu erstellen, und verwenden Sie eine Datenbank aus. 3.. Verwenden Sie CreateTable, um eine Tabelle zu erstellen, Felder und Datentypen zu definieren. 4. Verwenden Sie InsertInto, um Daten einzulegen, Daten abzufragen, Daten nach Aktualisierung zu aktualisieren und Daten nach Löschen zu löschen. Nur indem Sie diese Schritte beherrschen, lernen, mit gemeinsamen Problemen umzugehen und die Datenbankleistung zu optimieren, können Sie MySQL effizient verwenden.
 Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineer Job Vacant Company: Circle Standort: Remote-Büro-Jobtyp: Vollzeitgehalt: 130.000 bis 140.000 US-Dollar Stellenbeschreibung Nehmen Sie an der Forschung und Entwicklung von Mobilfunkanwendungen und öffentlichen API-bezogenen Funktionen, die den gesamten Lebenszyklus der Softwareentwicklung abdecken. Die Hauptaufgaben erledigen die Entwicklungsarbeit unabhängig von RubyonRails und arbeiten mit dem Front-End-Team von React/Redux/Relay zusammen. Erstellen Sie die Kernfunktionalität und -verbesserungen für Webanwendungen und arbeiten Sie eng mit Designer und Führung während des gesamten funktionalen Designprozesses zusammen. Fördern Sie positive Entwicklungsprozesse und priorisieren Sie die Iterationsgeschwindigkeit. Erfordert mehr als 6 Jahre komplexes Backend für Webanwendungen
 Kann MySQL JSON zurückgeben?
Apr 08, 2025 pm 03:09 PM
Kann MySQL JSON zurückgeben?
Apr 08, 2025 pm 03:09 PM
MySQL kann JSON -Daten zurückgeben. Die JSON_EXTRACT -Funktion extrahiert Feldwerte. Über komplexe Abfragen sollten Sie die Where -Klausel verwenden, um JSON -Daten zu filtern, aber auf die Leistungsauswirkungen achten. Die Unterstützung von MySQL für JSON nimmt ständig zu, und es wird empfohlen, auf die neuesten Versionen und Funktionen zu achten.
 Verstehen von Säureeigenschaften: Die Säulen einer zuverlässigen Datenbank
Apr 08, 2025 pm 06:33 PM
Verstehen von Säureeigenschaften: Die Säulen einer zuverlässigen Datenbank
Apr 08, 2025 pm 06:33 PM
Detaillierte Erläuterung von Datenbanksäureattributen Säureattribute sind eine Reihe von Regeln, um die Zuverlässigkeit und Konsistenz von Datenbanktransaktionen sicherzustellen. Sie definieren, wie Datenbanksysteme Transaktionen umgehen, und sorgen dafür, dass die Datenintegrität und -genauigkeit auch im Falle von Systemabstürzen, Leistungsunterbrechungen oder mehreren Benutzern gleichzeitiger Zugriff. Säureattributübersicht Atomizität: Eine Transaktion wird als unteilbare Einheit angesehen. Jeder Teil schlägt fehl, die gesamte Transaktion wird zurückgerollt und die Datenbank behält keine Änderungen bei. Wenn beispielsweise eine Banküberweisung von einem Konto abgezogen wird, jedoch nicht auf ein anderes erhöht wird, wird der gesamte Betrieb widerrufen. begintransaktion; updateAccountsSetBalance = Balance-100WH
 MySQL kann nach dem Herunterladen nicht installiert werden
Apr 08, 2025 am 11:24 AM
MySQL kann nach dem Herunterladen nicht installiert werden
Apr 08, 2025 am 11:24 AM
Die Hauptgründe für den Fehler bei MySQL -Installationsfehlern sind: 1. Erlaubnisprobleme, Sie müssen als Administrator ausgeführt oder den Sudo -Befehl verwenden. 2. Die Abhängigkeiten fehlen, und Sie müssen relevante Entwicklungspakete installieren. 3. Portkonflikte müssen Sie das Programm schließen, das Port 3306 einnimmt, oder die Konfigurationsdatei ändern. 4. Das Installationspaket ist beschädigt. Sie müssen die Integrität herunterladen und überprüfen. 5. Die Umgebungsvariable ist falsch konfiguriert und die Umgebungsvariablen müssen korrekt entsprechend dem Betriebssystem konfiguriert werden. Lösen Sie diese Probleme und überprüfen Sie jeden Schritt sorgfältig, um MySQL erfolgreich zu installieren.
 Der Hauptschlüssel von MySQL kann null sein
Apr 08, 2025 pm 03:03 PM
Der Hauptschlüssel von MySQL kann null sein
Apr 08, 2025 pm 03:03 PM
Der MySQL -Primärschlüssel kann nicht leer sein, da der Primärschlüssel ein Schlüsselattribut ist, das jede Zeile in der Datenbank eindeutig identifiziert. Wenn der Primärschlüssel leer sein kann, kann der Datensatz nicht eindeutig identifiziert werden, was zu Datenverwirrung führt. Wenn Sie selbstsinkrementelle Ganzzahlsspalten oder UUIDs als Primärschlüssel verwenden, sollten Sie Faktoren wie Effizienz und Raumbelegung berücksichtigen und eine geeignete Lösung auswählen.
