

Wie SpringBoot AOP Redis die verzögerte Doppellöschfunktion implementiert

1. Geschäftsszenario
Angenommen, es gibt zwei Datenbankänderungsanforderungen, um die Datenkonsistenz zwischen der Datenbank und Redis sicherzustellen:
Die Implementierung der Änderungsanforderung erfordert eine Kaskadierung Änderungen nach der Änderung der Datenbank in Redis.
Anfrage 1: A ändert die Datenbankdaten B ändert die Redis-Daten
Anfrage 2: C ändert die Datenbankdaten D ändert die Redis-Daten
In einer gleichzeitigen Situation gibt es die Situation A —> –> , und C hat auch die Datenbank nach A-Daten geändert.
Hinweis: Sie müssen wissen, dass häufig geänderte Datentabellen nicht für die Verwendung von Redis geeignet sind, da das Ergebnis der doppelten Löschstrategie darin besteht, die in Redis gespeicherten Daten zu löschen und nachfolgende Abfragen die Datenbank abfragen. Daher verwendet Redis einen Datencache, der weit mehr liest als ändert.
Ausführungsschritte des verzögerten Doppellöschplans1> Cache löschen
3> Verzögerung 500 Millisekunden (stellen Sie die verzögerte Ausführungszeit entsprechend dem jeweiligen Unternehmen ein)
3 500 Millisekunden?Wenn wir keinen zweiten Löschvorgang durchführen und zu diesem Zeitpunkt eine Anforderung zum Zugriff auf Daten vorliegt, sind die Redis-Daten möglicherweise nicht geändert. Nach der Ausführung des Löschvorgangs ist Redis leer Wenn eine Anfrage eingeht, wird auf die Datenbank zugegriffen. Zu diesem Zeitpunkt handelt es sich bei den Daten in der Datenbank bereits um aktualisierte Daten, wodurch die Datenkonsistenz sichergestellt wird. 2. Code-Praxis1. Einführung von Redis- und SpringBoot-AOP-Abhängigkeiten
Wir müssen den Datenbankaktualisierungsvorgang vor der zweiten Redis-Löschung abschließen. Nehmen wir an, wenn kein dritter Schritt erfolgt, besteht eine hohe Wahrscheinlichkeit, dass die Daten in der Datenbank nach Abschluss der beiden Redis-Löschvorgänge nicht aktualisiert wurden. Wenn zu diesem Zeitpunkt eine Anforderung zum Zugriff auf die Daten vorliegt, liegt das Problem vor Die eingangs erwähnte Frage wird auftauchen.
4. Warum muss der Cache zweimal gelöscht werden?
<!-- redis使用 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!-- aop -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-aop</artifactId>
</dependency>Nach dem Login kopieren
<!-- redis使用 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!-- aop -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-aop</artifactId>
</dependency>/**
*延时双删
**/
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Target(ElementType.METHOD)
public @interface ClearAndReloadCache {
String name() default "";
}3. Anwendung. yml
@Aspect
@Component
public class ClearAndReloadCacheAspect {
@Autowired
private StringRedisTemplate stringRedisTemplate;
/**
* 切入点
*切入点,基于注解实现的切入点 加上该注解的都是Aop切面的切入点
*
*/
@Pointcut("@annotation(com.pdh.cache.ClearAndReloadCache)")
public void pointCut(){
}
/**
* 环绕通知
* 环绕通知非常强大,可以决定目标方法是否执行,什么时候执行,执行时是否需要替换方法参数,执行完毕是否需要替换返回值。
* 环绕通知第一个参数必须是org.aspectj.lang.ProceedingJoinPoint类型
* @param proceedingJoinPoint
*/
@Around("pointCut()")
public Object aroundAdvice(ProceedingJoinPoint proceedingJoinPoint){
System.out.println("----------- 环绕通知 -----------");
System.out.println("环绕通知的目标方法名:" + proceedingJoinPoint.getSignature().getName());
Signature signature1 = proceedingJoinPoint.getSignature();
MethodSignature methodSignature = (MethodSignature)signature1;
Method targetMethod = methodSignature.getMethod();//方法对象
ClearAndReloadCache annotation = targetMethod.getAnnotation(ClearAndReloadCache.class);//反射得到自定义注解的方法对象
String name = annotation.name();//获取自定义注解的方法对象的参数即name
Set<String> keys = stringRedisTemplate.keys("*" + name + "*");//模糊定义key
stringRedisTemplate.delete(keys);//模糊删除redis的key值
//执行加入双删注解的改动数据库的业务 即controller中的方法业务
Object proceed = null;
try {
proceed = proceedingJoinPoint.proceed();
} catch (Throwable throwable) {
throwable.printStackTrace();
}
//开一个线程 延迟1秒(此处是1秒举例,可以改成自己的业务)
// 在线程中延迟删除 同时将业务代码的结果返回 这样不影响业务代码的执行
new Thread(() -> {
try {
Thread.sleep(1000);
Set<String> keys1 = stringRedisTemplate.keys("*" + name + "*");//模糊删除
stringRedisTemplate.delete(keys1);
System.out.println("-----------1秒钟后,在线程中延迟删除完毕 -----------");
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
return proceed;//返回业务代码的值
}
}4, user_db.sql-Skript
wird zum Erzeugen von Testdaten verwendet
server:
port: 8082
spring:
# redis setting
redis:
host: localhost
port: 6379
# cache setting
cache:
redis:
time-to-live: 60000 # 60s
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/test
username: root
password: 1234
# mp setting
mybatis-plus:
mapper-locations: classpath*:com/pdh/mapper/*.xml
global-config:
db-config:
table-prefix:
configuration:
# log of sql
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
# hump
map-underscore-to-camel-case: true5, UserController
DROP TABLE IF EXISTS `user_db`; CREATE TABLE `user_db` ( `id` int(4) NOT NULL AUTO_INCREMENT, `username` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, PRIMARY KEY (`id`) USING BTREE ) ENGINE = InnoDB AUTO_INCREMENT = 8 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic; -- ---------------------------- -- Records of user_db -- ---------------------------- INSERT INTO `user_db` VALUES (1, '张三'); INSERT INTO `user_db` VALUES (2, '李四'); INSERT INTO `user_db` VALUES (3, '王二'); INSERT INTO `user_db` VALUES (4, '麻子'); INSERT INTO `user_db` VALUES (5, '王三'); INSERT INTO `user_db` VALUES (6, '李三');
6, UserService
/**
* 用户控制层
*/
@RequestMapping("/user")
@RestController
public class UserController {
@Autowired
private UserService userService;
@GetMapping("/get/{id}")
@Cache(name = "get method")
//@Cacheable(cacheNames = {"get"})
public Result get(@PathVariable("id") Integer id){
return userService.get(id);
}
@PostMapping("/updateData")
@ClearAndReloadCache(name = "get method")
public Result updateData(@RequestBody User user){
return userService.update(user);
}
@PostMapping("/insert")
public Result insert(@RequestBody User user){
return userService.insert(user);
}
@DeleteMapping("/delete/{id}")
public Result delete(@PathVariable("id") Integer id){
return userService.delete(id);
}
}3. Testverifizierung
1, ID=10, neue Daten hinzufügen
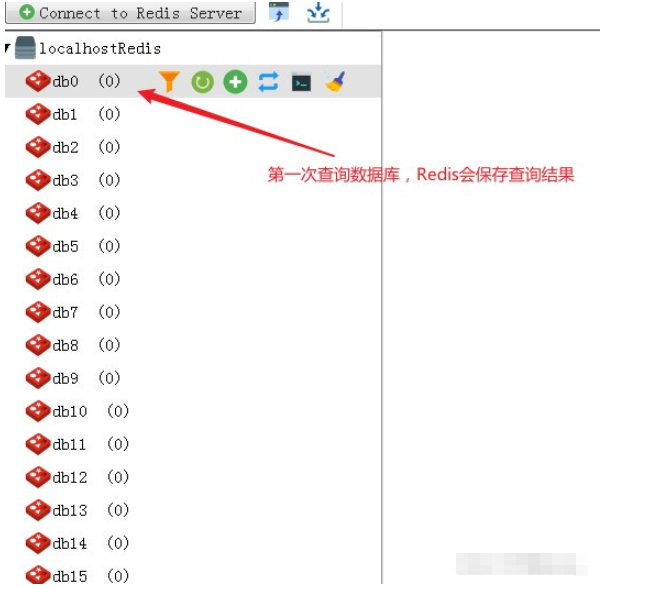
2 In Redis speichern
5, aktualisieren Sie den Benutzernamen, der der ID 10 entspricht (Datenbank- und Cache-Inkonsistenzschema überprüfen). Ein Thread zum Ausführen des ersten Nach einem Löschvorgang, bevor A die Aktualisierung der Datenbank abschließt, greift ein anderer Thread B auf ID=10 zu und liest die alten Daten.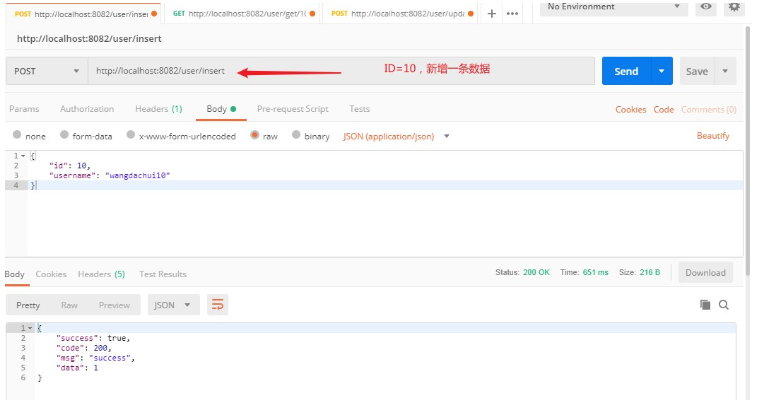
Verwenden Sie den zweiten Löschvorgang und stellen Sie die entsprechende Verzögerungszeit entsprechend dem Geschäftsszenario ein. Nachdem der Cache zweimal erfolgreich gelöscht wurde, ist das Ausgabeergebnis von Redis leer. Was gelesen wird, sind die tatsächlichen Daten der Datenbank, und es besteht keine Inkonsistenz zwischen dem Lesecache und der Datenbank.
4. Code Engineering
Der Kerncode wird im roten Feld angezeigt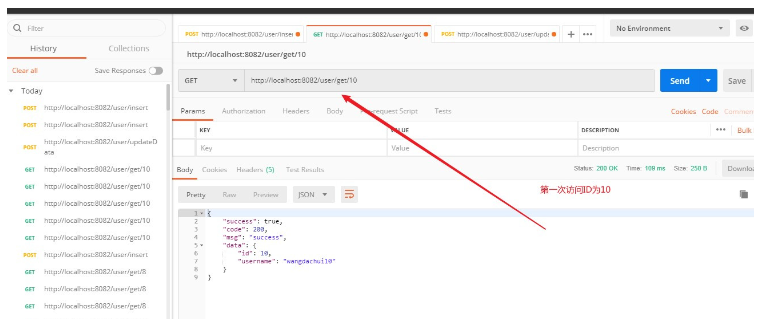
Das obige ist der detaillierte Inhalt vonWie SpringBoot AOP Redis die verzögerte Doppellöschfunktion implementiert. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 So erstellen Sie den Redis -Clustermodus
Apr 10, 2025 pm 10:15 PM
So erstellen Sie den Redis -Clustermodus
Apr 10, 2025 pm 10:15 PM
Der Redis -Cluster -Modus bietet Redis -Instanzen durch Sharding, die Skalierbarkeit und Verfügbarkeit verbessert. Die Bauschritte sind wie folgt: Erstellen Sie ungerade Redis -Instanzen mit verschiedenen Ports; Erstellen Sie 3 Sentinel -Instanzen, Monitor -Redis -Instanzen und Failover; Konfigurieren von Sentinel -Konfigurationsdateien, Informationen zur Überwachung von Redis -Instanzinformationen und Failover -Einstellungen hinzufügen. Konfigurieren von Redis -Instanzkonfigurationsdateien, aktivieren Sie den Cluster -Modus und geben Sie den Cluster -Informationsdateipfad an. Erstellen Sie die Datei nodes.conf, die Informationen zu jeder Redis -Instanz enthält. Starten Sie den Cluster, führen Sie den Befehl erstellen aus, um einen Cluster zu erstellen und die Anzahl der Replikate anzugeben. Melden Sie sich im Cluster an, um den Befehl cluster info auszuführen, um den Clusterstatus zu überprüfen. machen
 So verwenden Sie den Befehl Redis
Apr 10, 2025 pm 08:45 PM
So verwenden Sie den Befehl Redis
Apr 10, 2025 pm 08:45 PM
Die Verwendung der REDIS -Anweisung erfordert die folgenden Schritte: Öffnen Sie den Redis -Client. Geben Sie den Befehl ein (Verbschlüsselwert). Bietet die erforderlichen Parameter (variiert von der Anweisung bis zur Anweisung). Drücken Sie die Eingabetaste, um den Befehl auszuführen. Redis gibt eine Antwort zurück, die das Ergebnis der Operation anzeigt (normalerweise in Ordnung oder -err).
 So löschen Sie Redis -Daten
Apr 10, 2025 pm 10:06 PM
So löschen Sie Redis -Daten
Apr 10, 2025 pm 10:06 PM
So löschen Sie Redis -Daten: Verwenden Sie den Befehl Flushall, um alle Schlüsselwerte zu löschen. Verwenden Sie den Befehl flushdb, um den Schlüsselwert der aktuell ausgewählten Datenbank zu löschen. Verwenden Sie SELECT, um Datenbanken zu wechseln, und löschen Sie dann FlushDB, um mehrere Datenbanken zu löschen. Verwenden Sie den Befehl del, um einen bestimmten Schlüssel zu löschen. Verwenden Sie das Redis-Cli-Tool, um die Daten zu löschen.
 So lesen Sie den Quellcode von Redis
Apr 10, 2025 pm 08:27 PM
So lesen Sie den Quellcode von Redis
Apr 10, 2025 pm 08:27 PM
Der beste Weg, um Redis -Quellcode zu verstehen, besteht darin, Schritt für Schritt zu gehen: Machen Sie sich mit den Grundlagen von Redis vertraut. Wählen Sie ein bestimmtes Modul oder eine bestimmte Funktion als Ausgangspunkt. Beginnen Sie mit dem Einstiegspunkt des Moduls oder der Funktion und sehen Sie sich die Codezeile nach Zeile an. Zeigen Sie den Code über die Funktionsaufrufkette an. Kennen Sie die von Redis verwendeten Datenstrukturen. Identifizieren Sie den von Redis verwendeten Algorithmus.
 So verwenden Sie ein einzelnes Gewinde -Redis
Apr 10, 2025 pm 07:12 PM
So verwenden Sie ein einzelnes Gewinde -Redis
Apr 10, 2025 pm 07:12 PM
Redis verwendet eine einzelne Gewindearchitektur, um hohe Leistung, Einfachheit und Konsistenz zu bieten. Es wird E/A-Multiplexing, Ereignisschleifen, nicht blockierende E/A und gemeinsame Speicher verwendet, um die Parallelität zu verbessern, jedoch mit Einschränkungen von Gleichzeitbeschränkungen, einem einzelnen Ausfallpunkt und ungeeigneter Schreib-intensiver Workloads.
 So lesen Sie Redis -Warteschlange
Apr 10, 2025 pm 10:12 PM
So lesen Sie Redis -Warteschlange
Apr 10, 2025 pm 10:12 PM
Um eine Warteschlange aus Redis zu lesen, müssen Sie den Warteschlangenname erhalten, die Elemente mit dem Befehl LPOP lesen und die leere Warteschlange verarbeiten. Die spezifischen Schritte sind wie folgt: Holen Sie sich den Warteschlangenname: Nennen Sie ihn mit dem Präfix von "Warteschlange:" wie "Warteschlangen: My-Queue". Verwenden Sie den Befehl LPOP: Wischen Sie das Element aus dem Kopf der Warteschlange aus und geben Sie seinen Wert zurück, z. B. die LPOP-Warteschlange: my-queue. Verarbeitung leerer Warteschlangen: Wenn die Warteschlange leer ist, gibt LPOP NIL zurück, und Sie können überprüfen, ob die Warteschlange existiert, bevor Sie das Element lesen.
 So sehen Sie alle Schlüssel in Redis
Apr 10, 2025 pm 07:15 PM
So sehen Sie alle Schlüssel in Redis
Apr 10, 2025 pm 07:15 PM
Um alle Schlüssel in Redis anzuzeigen, gibt es drei Möglichkeiten: Verwenden Sie den Befehl keys, um alle Schlüssel zurückzugeben, die dem angegebenen Muster übereinstimmen. Verwenden Sie den Befehl scan, um über die Schlüssel zu iterieren und eine Reihe von Schlüssel zurückzugeben. Verwenden Sie den Befehl Info, um die Gesamtzahl der Schlüssel zu erhalten.
 So starten Sie den Server mit Redis
Apr 10, 2025 pm 08:12 PM
So starten Sie den Server mit Redis
Apr 10, 2025 pm 08:12 PM
Zu den Schritten zum Starten eines Redis -Servers gehören: Installieren von Redis gemäß dem Betriebssystem. Starten Sie den Redis-Dienst über Redis-Server (Linux/macOS) oder redis-server.exe (Windows). Verwenden Sie den Befehl redis-cli ping (linux/macOS) oder redis-cli.exe ping (Windows), um den Dienststatus zu überprüfen. Verwenden Sie einen Redis-Client wie Redis-Cli, Python oder Node.js, um auf den Server zuzugreifen.
