

So installieren und konfigurieren Sie Redis in CentOS7

Installation
Entpacken Sie das Verzeichnis und geben Sie es ein
tar xzf redis-4.0.12.tar.gz code>、<code>cd redis-4.0.12/;tar xzf redis-4.0.12.tar.gz、cd redis-4.0.12/;编译到指定目录
make prefix=/usr/local/redis install创建/usr/local/redis/ect目录,将redis.conf复制过来

/usr/local/redis 目录结构如下

将 redis 添加系统服务,执行 vim /usr/lib/systemd/system/redis-server.service,内容如下
[unit] description=the redis-server process manager after=syslog.target network.target [service] type=simple pidfile=/var/run/redis.pid execstart=/usr/local/redis/bin/redis-server /usr/local/redis/etc/redis.conf execreload=/bin/kill -s hup $mainpid execstop=/bin/kill -s quit $mainpid [install] wantedby=multi-user.target
开启服务 systemctl start redis-server
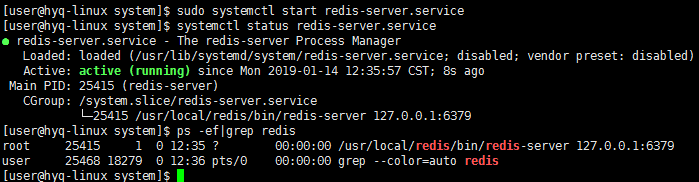
设置为开机启动 systemctl enable redis-server
测试,使用 redis-cli 测试看下
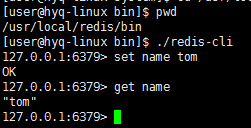
修改 redis 配置
修改数据保存路径,新建
/usr/local/redis/data目录,设置dir为 这个路径;rdb 和 aof 持久化
默认的 rdb 是 save 900 1 save 300 10 save 60 10000,即 900 秒 1 次更改、300 秒 10 次更改、60 秒 10000 次更改,满足上述任一条件即可,使用默认值;
aof 是默认关闭的,修改 appendonly 为 yes。更新条件有三种选择,是 always 表示每次更新操作后手动调用fsync()将数据写到磁盘(慢,安全)、everysec 表示每秒同步一次(折中,默认值)、no 表示等操作系统进行数据缓存同步到磁盘(快),使用默认值就好了;
二者是可以同时使用的,其它的相关配置就使用默认值了。
修改数据淘汰策略
最大占用内存 maxmemory 默认是注释的,设置为 512m,注意单位是 bytes ,所以值为 536870912;
redis 共提供了 6 种超值后的数据淘汰策略,分别是
volatile-lru:从设置了过期时间的数据集中,选择最近最久未使用的数据释放;
allkeys-lru:从数据集中(包括设置过期时间以及未设置过期时间的数据集中),选择最近最久未使用的数据释放;
volatile-random:从设置了过期时间的数据集中,随机选择一个数据进行释放;
allkeys-random:从数据集中(包括了设置过期时间以及未设置过期时间)随机选择一个数据进行入释放;
volatile-ttl:从设置了过期时间的数据集中,选择马上就要过期的数据进行释放操作;
noeviction:不删除任意数据(但redis还会根据引用计数器进行释放),这时如果内存不够时,会直接返回错误。
这里设置 maxmemory-policy 为 volatile-lru。
其它配置保持默认值,后续根据需求进行修改。记得修改完成后重启服务 systemctl restart redis-server
make prefix=/usr/local/ redis installErstellen Sie das Verzeichnis /usr/local/redis/ect und kopieren Sie redis.conf #🎜🎜##🎜 🎜##🎜🎜## 🎜🎜# /usr/local/redis Die Verzeichnisstruktur ist wie folgt#🎜🎜##🎜🎜# #🎜🎜##🎜🎜#Redis zum Systemdienst hinzufügen und
#🎜🎜##🎜🎜#Redis zum Systemdienst hinzufügen und vim /usr/lib/systemd/ ausführen system/redis-server.service, der Inhalt lautet wie folgt #🎜🎜#rrreee#🎜🎜#Starten Sie den Dienst systemctl start redis-server#🎜🎜##🎜🎜##🎜🎜##🎜🎜# Beim Booten starten systemctl enable redis-server# 🎜🎜##🎜🎜#Testen, mit redis-cli testen und sehen#🎜🎜##🎜🎜#  #🎜🎜##🎜🎜 ##🎜🎜#Redis-Konfiguration ändern#🎜🎜##🎜🎜##🎜🎜##🎜 🎜##🎜🎜#Datenspeicherpfad ändern, neuen
#🎜🎜##🎜🎜 ##🎜🎜#Redis-Konfiguration ändern#🎜🎜##🎜🎜##🎜🎜##🎜 🎜##🎜🎜#Datenspeicherpfad ändern, neuen /usr/local/redis/data erstellen code>-Verzeichnis und setzen Sie <code>dir auf diesen Pfad; #🎜🎜#Die Standard-RDB ist save 900 1 save 300 10 save 60 10000, das heißt 1 Änderung in 900 Sekunden, 10 Änderungen in 300 Sekunden und 10.000 Änderungen in 60 Sekunden Wenn die oben genannten Bedingungen erfüllt sind, verwenden Sie den Standardwert;#🎜🎜##🎜🎜#aof ist standardmäßig deaktiviert, ändern Sie
appendonly auf yes. Es gibt drei Optionen für Aktualisierungsbedingungen: always bedeutet, dass fsync() manuell aufgerufen wird, um Daten nach jedem Aktualisierungsvorgang auf die Festplatte zu schreiben (langsam, sicher), everysec bedeutet, einmal pro Sekunde zu synchronisieren (Kompromiss, Standardwert), nein bedeutet, dass darauf gewartet wird, dass das Betriebssystem den Datencache mit der Festplatte synchronisiert (schnell), einfach den Standardwert verwenden;#🎜🎜##🎜🎜 #二Beide können gleichzeitig verwendet werden, und andere verwandte Konfigurationen verwenden die Standardwerte. #🎜🎜##🎜🎜##🎜🎜#Strategie zur Dateneliminierung ändern#🎜🎜##🎜🎜##🎜🎜#Der maximal belegte Speicher
maxmemory ist standardmäßig kommentiert und auf 512 m eingestellt, Bezahlung Beachten Sie die Einheit. Es handelt sich um Bytes, daher ist der Wert 536870912;Redis bietet insgesamt 6 Dateneliminierungsstrategien nach Überbewertung, die #🎜🎜#
volatile-lru: Aus dem Datensatz mit Ablaufzeit Wählen Sie aus dem Datensatz (einschließlich Datensätzen mit festgelegter Ablaufzeit und Datensätzen ohne festgelegte Ablaufzeit) die neuesten und am häufigsten verwendeten Daten aus freizugeben;#🎜🎜#Setzen Sie hier
volatile-random: Wählen Sie zufällig ein Datenelement zur Freigabe aus dem Datensatz mit einer festgelegten Ablaufzeit aus;
allkeys-random: Wählen Sie zufällig ein Datenelement aus dem Datensatz aus (einschließlich Satz). Ablaufzeit und nicht festgelegte Ablaufzeit) für die Freigabe;
volatile-ttl: Wählen Sie aus dem Datensatz mit festgelegter Ablaufzeit die Daten aus, die bald für den Freigabevorgang ablaufen;
noeviction: Keine Daten löschen (Redis gibt es jedoch auch basierend auf dem Referenzzähler frei.) Wenn zu diesem Zeitpunkt nicht genügend Speicher vorhanden ist, wird direkt ein Fehler zurückgegeben.
maxmemory-policy auf volatile-lru. #🎜🎜##🎜🎜#Andere Konfigurationen bleiben auf den Standardwerten und werden bei Bedarf geändert. Denken Sie daran, den Dienst systemctl restart redis-server neu zu starten, nachdem die Änderung abgeschlossen ist. #🎜🎜#Das obige ist der detaillierte Inhalt vonSo installieren und konfigurieren Sie Redis in CentOS7. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1385
1385
 52
52

 So erstellen Sie den Redis -Clustermodus
Apr 10, 2025 pm 10:15 PM
So erstellen Sie den Redis -Clustermodus
Apr 10, 2025 pm 10:15 PM
Der Redis -Cluster -Modus bietet Redis -Instanzen durch Sharding, die Skalierbarkeit und Verfügbarkeit verbessert. Die Bauschritte sind wie folgt: Erstellen Sie ungerade Redis -Instanzen mit verschiedenen Ports; Erstellen Sie 3 Sentinel -Instanzen, Monitor -Redis -Instanzen und Failover; Konfigurieren von Sentinel -Konfigurationsdateien, Informationen zur Überwachung von Redis -Instanzinformationen und Failover -Einstellungen hinzufügen. Konfigurieren von Redis -Instanzkonfigurationsdateien, aktivieren Sie den Cluster -Modus und geben Sie den Cluster -Informationsdateipfad an. Erstellen Sie die Datei nodes.conf, die Informationen zu jeder Redis -Instanz enthält. Starten Sie den Cluster, führen Sie den Befehl erstellen aus, um einen Cluster zu erstellen und die Anzahl der Replikate anzugeben. Melden Sie sich im Cluster an, um den Befehl cluster info auszuführen, um den Clusterstatus zu überprüfen. machen
 So löschen Sie Redis -Daten
Apr 10, 2025 pm 10:06 PM
So löschen Sie Redis -Daten
Apr 10, 2025 pm 10:06 PM
So löschen Sie Redis -Daten: Verwenden Sie den Befehl Flushall, um alle Schlüsselwerte zu löschen. Verwenden Sie den Befehl flushdb, um den Schlüsselwert der aktuell ausgewählten Datenbank zu löschen. Verwenden Sie SELECT, um Datenbanken zu wechseln, und löschen Sie dann FlushDB, um mehrere Datenbanken zu löschen. Verwenden Sie den Befehl del, um einen bestimmten Schlüssel zu löschen. Verwenden Sie das Redis-Cli-Tool, um die Daten zu löschen.
 So verwenden Sie den Befehl Redis
Apr 10, 2025 pm 08:45 PM
So verwenden Sie den Befehl Redis
Apr 10, 2025 pm 08:45 PM
Die Verwendung der REDIS -Anweisung erfordert die folgenden Schritte: Öffnen Sie den Redis -Client. Geben Sie den Befehl ein (Verbschlüsselwert). Bietet die erforderlichen Parameter (variiert von der Anweisung bis zur Anweisung). Drücken Sie die Eingabetaste, um den Befehl auszuführen. Redis gibt eine Antwort zurück, die das Ergebnis der Operation anzeigt (normalerweise in Ordnung oder -err).
 So verwenden Sie Redis Lock
Apr 10, 2025 pm 08:39 PM
So verwenden Sie Redis Lock
Apr 10, 2025 pm 08:39 PM
Um die Operationen zu sperren, muss die Sperre durch den Befehl setNX erfasst werden und dann den Befehl Ablauf verwenden, um die Ablaufzeit festzulegen. Die spezifischen Schritte sind: (1) Verwenden Sie den Befehl setNX, um zu versuchen, ein Schlüsselwertpaar festzulegen; (2) Verwenden Sie den Befehl Ablauf, um die Ablaufzeit für die Sperre festzulegen. (3) Verwenden Sie den Befehl Del, um die Sperre zu löschen, wenn die Sperre nicht mehr benötigt wird.
 So lesen Sie Redis -Warteschlange
Apr 10, 2025 pm 10:12 PM
So lesen Sie Redis -Warteschlange
Apr 10, 2025 pm 10:12 PM
Um eine Warteschlange aus Redis zu lesen, müssen Sie den Warteschlangenname erhalten, die Elemente mit dem Befehl LPOP lesen und die leere Warteschlange verarbeiten. Die spezifischen Schritte sind wie folgt: Holen Sie sich den Warteschlangenname: Nennen Sie ihn mit dem Präfix von "Warteschlange:" wie "Warteschlangen: My-Queue". Verwenden Sie den Befehl LPOP: Wischen Sie das Element aus dem Kopf der Warteschlange aus und geben Sie seinen Wert zurück, z. B. die LPOP-Warteschlange: my-queue. Verarbeitung leerer Warteschlangen: Wenn die Warteschlange leer ist, gibt LPOP NIL zurück, und Sie können überprüfen, ob die Warteschlange existiert, bevor Sie das Element lesen.
 So implementieren Sie die zugrunde liegenden Redis
Apr 10, 2025 pm 07:21 PM
So implementieren Sie die zugrunde liegenden Redis
Apr 10, 2025 pm 07:21 PM
Redis verwendet Hash -Tabellen, um Daten zu speichern und unterstützt Datenstrukturen wie Zeichenfolgen, Listen, Hash -Tabellen, Sammlungen und geordnete Sammlungen. Ernähren sich weiterhin über Daten über Snapshots (RDB) und appendiert Mechanismen nur Schreibmechanismen. Redis verwendet die Master-Slave-Replikation, um die Datenverfügbarkeit zu verbessern. Redis verwendet eine Ereignisschleife mit einer Thread, um Verbindungen und Befehle zu verarbeiten, um die Datenatomizität und Konsistenz zu gewährleisten. Redis legt die Ablaufzeit für den Schlüssel fest und verwendet den faulen Löschmechanismus, um den Ablaufschlüssel zu löschen.
 So lesen Sie den Quellcode von Redis
Apr 10, 2025 pm 08:27 PM
So lesen Sie den Quellcode von Redis
Apr 10, 2025 pm 08:27 PM
Der beste Weg, um Redis -Quellcode zu verstehen, besteht darin, Schritt für Schritt zu gehen: Machen Sie sich mit den Grundlagen von Redis vertraut. Wählen Sie ein bestimmtes Modul oder eine bestimmte Funktion als Ausgangspunkt. Beginnen Sie mit dem Einstiegspunkt des Moduls oder der Funktion und sehen Sie sich die Codezeile nach Zeile an. Zeigen Sie den Code über die Funktionsaufrufkette an. Kennen Sie die von Redis verwendeten Datenstrukturen. Identifizieren Sie den von Redis verwendeten Algorithmus.
 So erstellen Sie Message Middleware für Redis
Apr 10, 2025 pm 07:51 PM
So erstellen Sie Message Middleware für Redis
Apr 10, 2025 pm 07:51 PM
Redis unterstützt als Messing Middleware Modelle für Produktionsverbrauch, kann Nachrichten bestehen und eine zuverlässige Lieferung sicherstellen. Die Verwendung von Redis als Message Middleware ermöglicht eine geringe Latenz, zuverlässige und skalierbare Nachrichten.
