
 Technologie-Peripheriegeräte
KI
7-nm-Prozess, effizienter als GPU, Meta veröffentlicht KI-Inferenzbeschleuniger der ersten Generation
Technologie-Peripheriegeräte
KI
7-nm-Prozess, effizienter als GPU, Meta veröffentlicht KI-Inferenzbeschleuniger der ersten Generation
7-nm-Prozess, effizienter als GPU, Meta veröffentlicht KI-Inferenzbeschleuniger der ersten Generation

Machine Heart Report
Heart of Machine-Redaktion
Kürzlich hat Meta seine neuesten Fortschritte in der künstlichen Intelligenz vorgestellt.
Wenn Menschen an Meta denken, denken sie normalerweise an seine Apps, darunter Facebook, Instagram, WhatsApp oder das kommende Metaverse. Was viele jedoch nicht wissen, ist, dass dieses Unternehmen sehr hochentwickelte Rechenzentren für den Betrieb dieser Dienste entwirft und baut.
Im Gegensatz zu Cloud-Service-Anbietern wie AWS, GCP oder Azure ist Meta nicht verpflichtet, Details zu seiner Siliziumauswahl, Infrastruktur oder seinem Rechenzentrumsdesign offenzulegen, mit der Ausnahme, dass sein OCP darauf ausgelegt ist, Käufer zu beeindrucken. Die Benutzer von Meta wünschen sich ein besseres, konsistenteres Erlebnis, unabhängig davon, wie es erreicht wird.
Bei Meta sind KI-Workloads allgegenwärtig und bilden die Grundlage für eine Vielzahl von Anwendungsfällen, darunter Inhaltsverständnis, Informationsfluss, generative KI und Anzeigenranking. Diese Workloads laufen auf PyTorch, mit erstklassiger Python-Integration, Eager-Mode-Entwicklung und API-Einfachheit. Insbesondere Deep-Learning-Empfehlungsmodelle (DLRMs) sind sehr wichtig für die Verbesserung der Dienste und des Anwendungserlebnisses von Meta. Da diese Modelle jedoch immer größer und komplexer werden, müssen die zugrunde liegenden Hardwaresysteme exponentiell mehr Speicher und Rechenleistung bereitstellen und gleichzeitig effizient bleiben.
Meta hat herausgefunden, dass GPUs für aktuelle KI-Operationen und bestimmte Arbeitslasten ineffizient und nicht die beste Wahl sind. Daher schlug das Unternehmen den Inferenzbeschleuniger MTIA vor, um KI-Systeme schneller zu trainieren.
MTIA V1
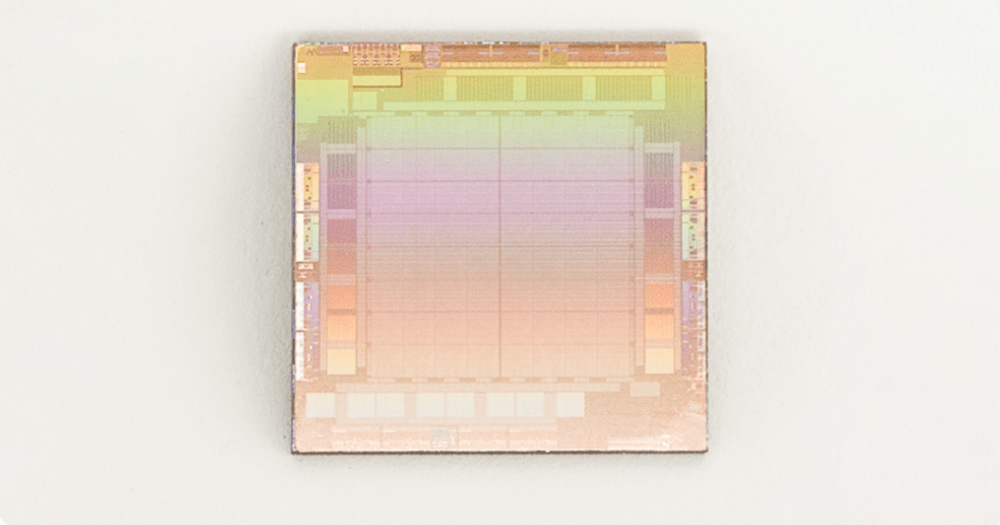
MTIA v1 (Inferenz) Chip (Sterben)
Im Jahr 2020 entwickelte Meta den MTIA ASIC-Inferenzbeschleuniger der ersten Generation für seine internen Workloads. Der Inferenzbeschleuniger ist Teil seiner Full-Stack-Lösung, die Silizium-, PyTorch- und Empfehlungsmodelle umfasst.
MTIA-Beschleuniger wird im TSMC 7-nm-Prozess hergestellt und läuft mit 800 MHz und liefert 102,4 TOPS bei INT8-Präzision und 51,2 TFLOPS bei FP16-Präzision. Es hat eine Thermal Design Power (TDP) von 25 W.
Der MTIA-Beschleuniger besteht aus Verarbeitungselementen (PEs), On-Chip- und Off-Chip-Speicherressourcen sowie Verbindungen. Der Beschleuniger ist mit einem speziellen Steuerungssubsystem ausgestattet, auf dem die Systemfirmware läuft. Die Firmware verwaltet die verfügbaren Rechen- und Speicherressourcen, kommuniziert über eine dedizierte Hostschnittstelle mit dem Host und koordiniert die Jobausführung auf dem Beschleuniger.
Das Speichersubsystem nutzt LPDDR5 als Off-Chip-DRAM-Ressource, erweiterbar auf bis zu 128 GB. Der Chip verfügt außerdem über 128 MB On-Chip-SRAM, der von allen PEs gemeinsam genutzt wird und eine höhere Bandbreite und geringere Latenz für häufig abgerufene Daten und Anweisungen bietet.
Das MTIA-Beschleunigergitter besteht aus 64 PEs, die in einer 8x8-Konfiguration organisiert sind und über ein Mesh-Netzwerk miteinander und mit Speicherblöcken verbunden sind. Das gesamte Raster kann als Ganzes zum Ausführen eines Jobs verwendet werden oder es kann in mehrere Unterraster unterteilt werden, die unabhängige Jobs ausführen können.
Jedes PE ist mit zwei Prozessorkernen (von denen einer mit Vektorerweiterungen ausgestattet ist) und einer Reihe fester Funktionseinheiten ausgestattet, die für die Durchführung wichtiger Operationen wie Matrixmultiplikation, Akkumulation, Datenverschiebung und nichtlineare Funktionsberechnungen optimiert sind. Der Prozessorkern basiert auf der offenen Befehlssatzarchitektur (ISA) von RISC-V und ist stark angepasst, um die erforderlichen Rechen- und Steuerungsaufgaben auszuführen.
Jedes PE verfügt außerdem über 128 KB lokalen SRAM-Speicher für die schnelle Speicherung und Bearbeitung von Daten. Diese Architektur maximiert Parallelität und Datenwiederverwendung, die für die effiziente Ausführung von Workloads von grundlegender Bedeutung sind.
Der Chip bietet Parallelität auf Thread- und Datenebene (TLP und DLP), nutzt Parallelität auf Befehlsebene (ILP) und ermöglicht eine massive Parallelität auf Speicherebene (MLP), indem er die gleichzeitige Verarbeitung einer großen Anzahl von Speicheranforderungen ermöglicht.
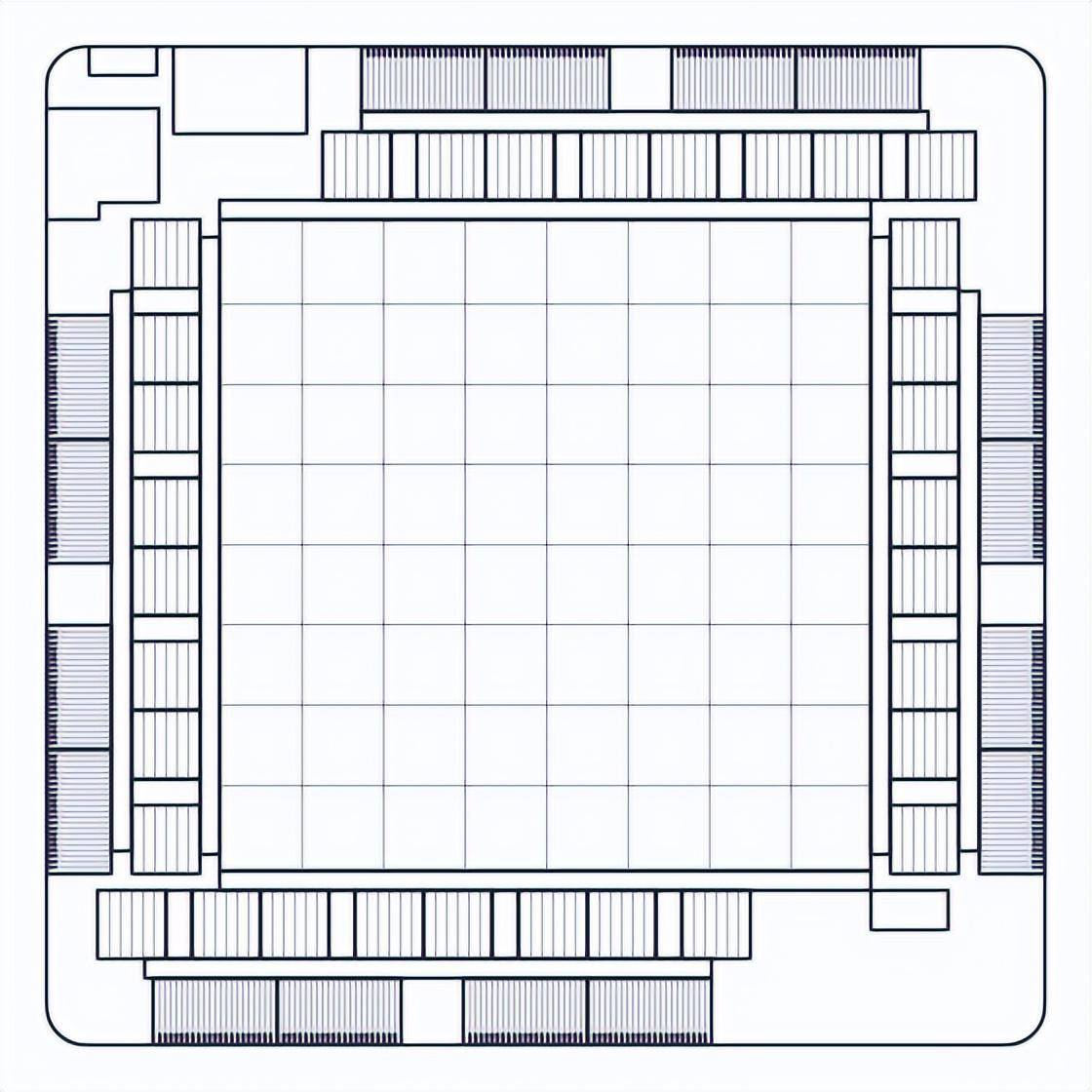
MTIA v1-Systemdesign
Der MTIA-Beschleuniger ist zur einfacheren Integration in Server auf einer kleinen Dual-M.2-Platine montiert. Die Platinen nutzen eine PCIe Gen4 x8-Verbindung zur Verbindung mit der Host-CPU auf dem Server und verbrauchen dabei nur 35 W.

Beispieltestplatine mit MTIA
Die Server, auf denen diese Beschleuniger gehostet werden, verwenden die Yosemite V3-Serverspezifikation des Open Compute Project. Jeder Server enthält 12 Beschleuniger, die über eine PCIe-Switch-Hierarchie mit der Host-CPU und untereinander verbunden sind. Daher muss die Host-CPU nicht an der Kommunikation zwischen verschiedenen Beschleunigern beteiligt sein. Diese Topologie ermöglicht die Verteilung von Arbeitslasten auf mehrere Beschleuniger und die parallele Ausführung. Die Anzahl der Beschleuniger und Serverkonfigurationsparameter werden sorgfältig ausgewählt, um aktuelle und zukünftige Arbeitslasten optimal auszuführen.
MTIA-Software-Stack
MTIA-Software (SW)-Stack wurde entwickelt, um Entwicklern eine bessere Entwicklungseffizienz und ein leistungsstarkes Erlebnis zu bieten. Es ist vollständig in PyTorch integriert und bietet Benutzern eine vertraute Entwicklungserfahrung. Die Verwendung von PyTorch mit MTIA ist genauso einfach wie die Verwendung von PyTorch mit einer CPU oder GPU. Und dank des florierenden PyTorch-Entwickler-Ökosystems und der Tools kann der MTIA-SW-Stack jetzt PyTorch FX IR verwenden, um Transformationen und Optimierungen auf Modellebene durchzuführen, und LLVM IR für Optimierungen auf niedriger Ebene und unterstützt gleichzeitig benutzerdefinierte MTIA-Beschleunigerarchitekturen und ISAs.
Das Bild unten zeigt das MTIA-Software-Stack-Framework-Diagramm:
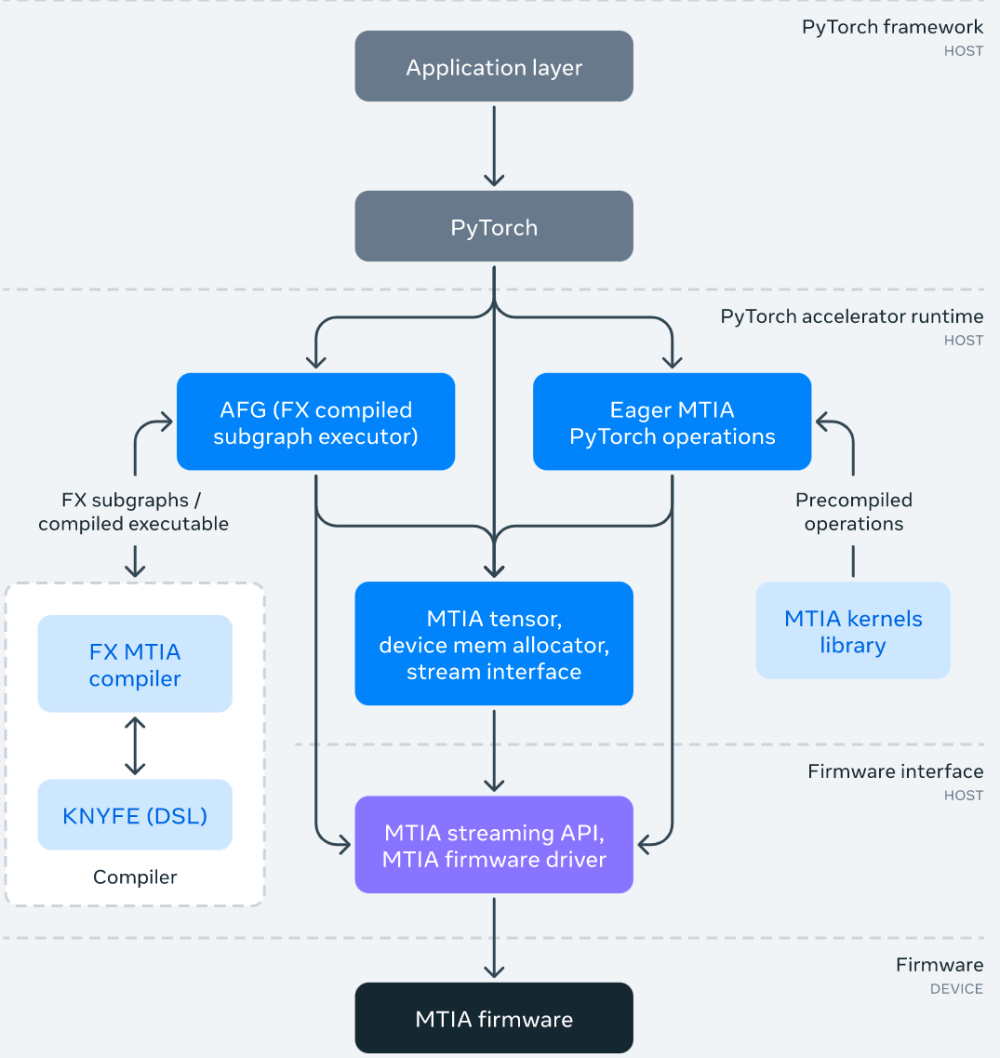
Als Teil des SW-Stacks hat Meta auch eine handabgestimmte und hochoptimierte Kernel-Bibliothek für leistungskritische ML-Kernel entwickelt, wie zum Beispiel vollständig verbundene und eingebettete Paketoperatoren. Höhere Ebenen im SW-Stack haben die Möglichkeit, diese hochoptimierten Kernel während der Kompilierung und Codegenerierung zu instanziieren und zu verwenden.
Darüber hinaus entwickelt sich der MTIA SW-Stack durch die Integration mit PyTorch 2.0 weiter, das schneller und pythonischer, aber so dynamisch wie eh und je ist. Dadurch werden neue Funktionen wie TorchDynamo und TorchInductor ermöglicht. Meta erweitert außerdem das Triton DSL, um den MTIA-Beschleuniger zu unterstützen und MLIR für die interne Darstellung und erweiterte Optimierung zu verwenden.
MTIA-Leistung
Meta hat die Leistung von MTIA mit anderen Beschleunigern verglichen und die Ergebnisse sind wie folgt:
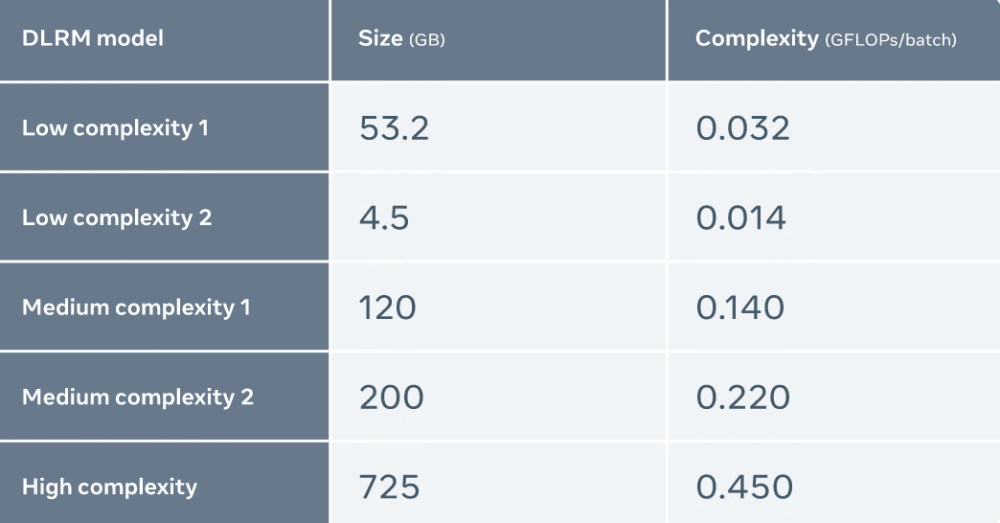
Meta verwendet fünf verschiedene DLRMs (von niedriger bis hoher Komplexität), um MTIA auszuwerten
Darüber hinaus hat Meta MTIA mit NNPI und GPU verglichen und die Ergebnisse sind wie folgt:

Die Auswertung ergab, dass MTIA bei der Verarbeitung von Modellen geringer Komplexität (LC1 und LC2) und mittlerer Komplexität (MC1 und MC2) effizienter ist als NNPI und GPU. Darüber hinaus wurde Meta nicht für MTIA für Modelle mit hoher Komplexität (HC) optimiert.
Referenzlink:
https://ai.facebook.com/blog/meta-training-inference-accelerator-AI-MTIA/
Das obige ist der detaillierte Inhalt von7-nm-Prozess, effizienter als GPU, Meta veröffentlicht KI-Inferenzbeschleuniger der ersten Generation. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 Ich habe versucht, die Vibe -Codierung mit Cursor AI und es ist erstaunlich!
Mar 20, 2025 pm 03:34 PM
Ich habe versucht, die Vibe -Codierung mit Cursor AI und es ist erstaunlich!
Mar 20, 2025 pm 03:34 PM
Die Vibe -Codierung verändert die Welt der Softwareentwicklung, indem wir Anwendungen mit natürlicher Sprache anstelle von endlosen Codezeilen erstellen können. Inspiriert von Visionären wie Andrej Karpathy, lässt dieser innovative Ansatz Dev
 Top 5 Genai Starts vom Februar 2025: GPT-4,5, GROK-3 & MEHR!
Mar 22, 2025 am 10:58 AM
Top 5 Genai Starts vom Februar 2025: GPT-4,5, GROK-3 & MEHR!
Mar 22, 2025 am 10:58 AM
Februar 2025 war ein weiterer bahnbrechender Monat für die Generative KI, die uns einige der am meisten erwarteten Modell-Upgrades und bahnbrechenden neuen Funktionen gebracht hat. Von Xais Grok 3 und Anthropics Claude 3.7 -Sonett, um g zu eröffnen
 Wie benutze ich Yolo V12 zur Objekterkennung?
Mar 22, 2025 am 11:07 AM
Wie benutze ich Yolo V12 zur Objekterkennung?
Mar 22, 2025 am 11:07 AM
Yolo (Sie schauen nur einmal) war ein führender Echtzeit-Objekterkennungsrahmen, wobei jede Iteration die vorherigen Versionen verbessert. Die neueste Version Yolo V12 führt Fortschritte vor, die die Genauigkeit erheblich verbessern
 Ist Chatgpt 4 o verfügbar?
Mar 28, 2025 pm 05:29 PM
Ist Chatgpt 4 o verfügbar?
Mar 28, 2025 pm 05:29 PM
Chatgpt 4 ist derzeit verfügbar und weit verbreitet, wodurch im Vergleich zu seinen Vorgängern wie ChatGPT 3.5 signifikante Verbesserungen beim Verständnis des Kontextes und des Generierens kohärenter Antworten zeigt. Zukünftige Entwicklungen können mehr personalisierte Inters umfassen
 Beste KI -Kunstgeneratoren (kostenlos & amp; bezahlt) für kreative Projekte
Apr 02, 2025 pm 06:10 PM
Beste KI -Kunstgeneratoren (kostenlos & amp; bezahlt) für kreative Projekte
Apr 02, 2025 pm 06:10 PM
Der Artikel überprüft Top -KI -Kunstgeneratoren, diskutiert ihre Funktionen, Eignung für kreative Projekte und Wert. Es zeigt MidJourney als den besten Wert für Fachkräfte und empfiehlt Dall-E 2 für hochwertige, anpassbare Kunst.
 O1 gegen GPT-4O: Ist OpenAIs neues Modell besser als GPT-4O?
Mar 16, 2025 am 11:47 AM
O1 gegen GPT-4O: Ist OpenAIs neues Modell besser als GPT-4O?
Mar 16, 2025 am 11:47 AM
Openais O1: Ein 12-tägiger Geschenkbummel beginnt mit ihrem bisher mächtigsten Modell Die Ankunft im Dezember bringt eine globale Verlangsamung, Schneeflocken in einigen Teilen der Welt, aber Openai fängt gerade erst an. Sam Altman und sein Team starten ein 12-tägiges Geschenk Ex
 Gencast von Google: Wettervorhersage mit Gencast Mini Demo
Mar 16, 2025 pm 01:46 PM
Gencast von Google: Wettervorhersage mit Gencast Mini Demo
Mar 16, 2025 pm 01:46 PM
Gencast von Google Deepmind: Eine revolutionäre KI für die Wettervorhersage Die Wettervorhersage wurde einer dramatischen Transformation unterzogen, die sich von rudimentären Beobachtungen zu ausgefeilten AI-angetriebenen Vorhersagen überschreitet. Google DeepMinds Gencast, ein Bodenbrei
 Welche KI ist besser als Chatgpt?
Mar 18, 2025 pm 06:05 PM
Welche KI ist besser als Chatgpt?
Mar 18, 2025 pm 06:05 PM
Der Artikel erörtert KI -Modelle, die Chatgpt wie Lamda, Lama und Grok übertreffen und ihre Vorteile in Bezug auf Genauigkeit, Verständnis und Branchenauswirkungen hervorheben. (159 Charaktere)
