
 Technologie-Peripheriegeräte
KI
Jeder versteht ChatGPT Kapitel 1: ChatGPT und die Verarbeitung natürlicher Sprache
Technologie-Peripheriegeräte
KI
Jeder versteht ChatGPT Kapitel 1: ChatGPT und die Verarbeitung natürlicher Sprache
Jeder versteht ChatGPT Kapitel 1: ChatGPT und die Verarbeitung natürlicher Sprache


ChatGPT (Chat Generative Pre-training Transformer) ist ein KI-Modell, das zum Bereich der Natural Language Processing (NLP) gehört, einem Zweig der künstlichen Intelligenz. Die sogenannte natürliche Sprache bezieht sich auf Englisch, Chinesisch, Deutsch usw., mit denen Menschen
in Kontakt kommen und die sie in ihrem täglichen Leben verwenden. Bei der Verarbeitung natürlicher Sprache geht es darum, es Computern zu ermöglichen, natürliche Sprache zu verstehen und korrekt zu verarbeiten, um von Menschen vorgegebene Aufgaben zu erfüllen. Zu den häufigsten Aufgaben im NLP gehören die Schlüsselwortextraktion aus Text, die Textklassifizierung, maschinelle Übersetzung usw.
Es gibt noch eine weitere sehr schwierige Aufgabe im NLP: Dialogsysteme, die allgemein auch als Chatbots bezeichnet werden können, und genau das macht ChatGPT.
ChatGPT und Turing-Test
Seit dem Aufkommen von Computern in den 1950er Jahren haben Menschen begonnen zu untersuchen, wie Computer Menschen beim Verstehen und Verarbeiten natürlicher Sprache unterstützen können Bereich des NLP Unter den Entwicklungszielen ist der Turing-Test das bekannteste.
Im Jahr 1950 führte Alan Turing, der Vater der Computer, einen Test ein, um zu überprüfen, ob eine Maschine wie ein Mensch denken kann. Dieser Test wurde Turing-Test genannt. Die spezifische Testmethode ist genau die gleiche wie die aktuelle ChatGPT-Methode, d. h. der Aufbau eines Computerdialogsystems, bei dem eine Person und das zu testende Modell miteinander sprechen Eine andere Person bedeutet, dass das Modell den Turing-Test bestanden hat und der Computer intelligent ist.
Der Turing-Test galt in akademischen Kreisen lange Zeit als schwer fassbarer Höhepunkt. Aus diesem Grund wird NLP auch als Kronjuwel der künstlichen Intelligenz bezeichnet. Die Arbeit, die ChatGPT leisten kann, geht weit über den Rahmen von Chat-Robotern hinaus. Es kann Artikel gemäß Benutzeranweisungen schreiben, technische Fragen beantworten, mathematische Probleme lösen, Fremdsprachenübersetzungen durchführen, Wortspiele spielen usw. ChatGPT hat sich also gewissermaßen das Kronjuwel gesichert.
ChatGPTs Modellierungsformular
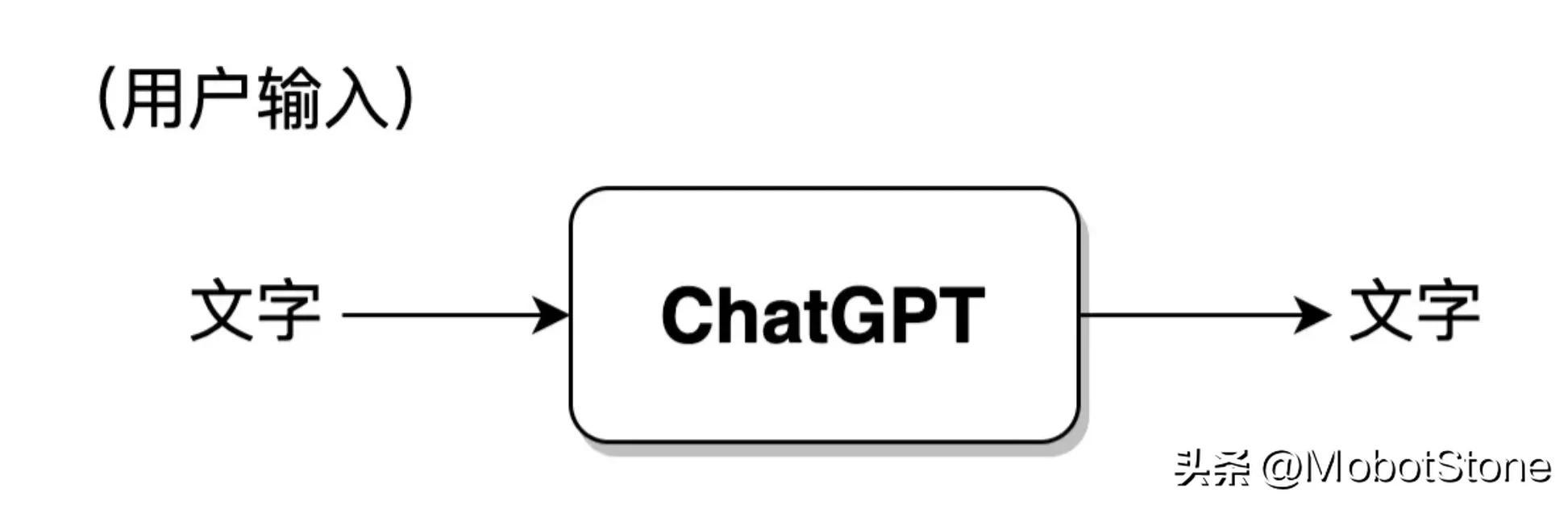
ChatGPTs Arbeitsformular ist sehr einfach. Benutzer können ChatGPT jede Frage stellen und das Modell wird sie beantworten.

Unter diesen liegen sowohl die Benutzereingabe als auch die Modellausgabe in Form von Text vor. Eine Benutzereingabe und eine entsprechende Ausgabe des Modells werden als Konversation bezeichnet. Wir können das ChatGPT-Modell in den folgenden Prozess abstrahieren:
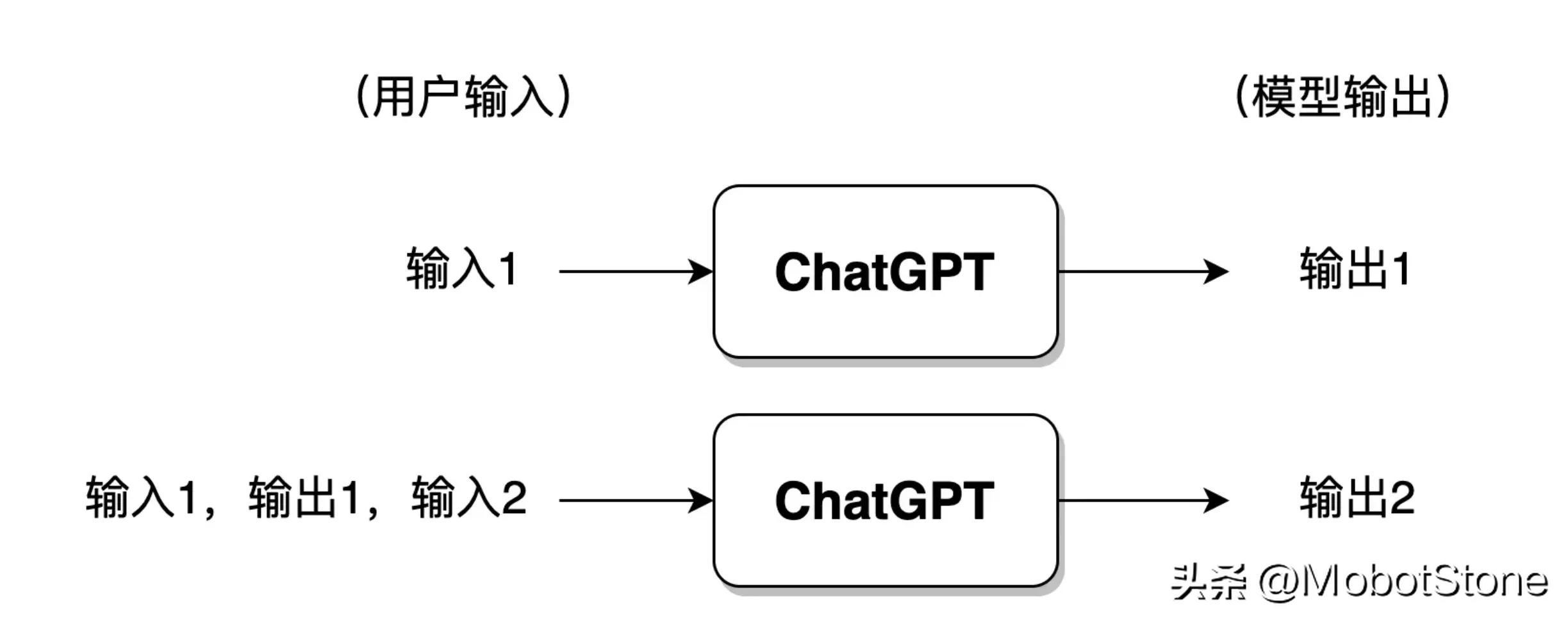
Darüber hinaus kann ChatGPT auch kontinuierliche Fragen von Benutzern beantworten, also mehrere Dialogrunden , mehrere Runden Es besteht eine Informationskorrelation zwischen Gesprächen. Die spezifische Form ist ebenfalls sehr einfach. Wenn der Benutzer zum zweiten Mal eingibt, fügt das System standardmäßig die Eingabe- und Ausgabeinformationen des ersten Mals zusammen, damit ChatGPT auf die Informationen der letzten Konversation verweist.
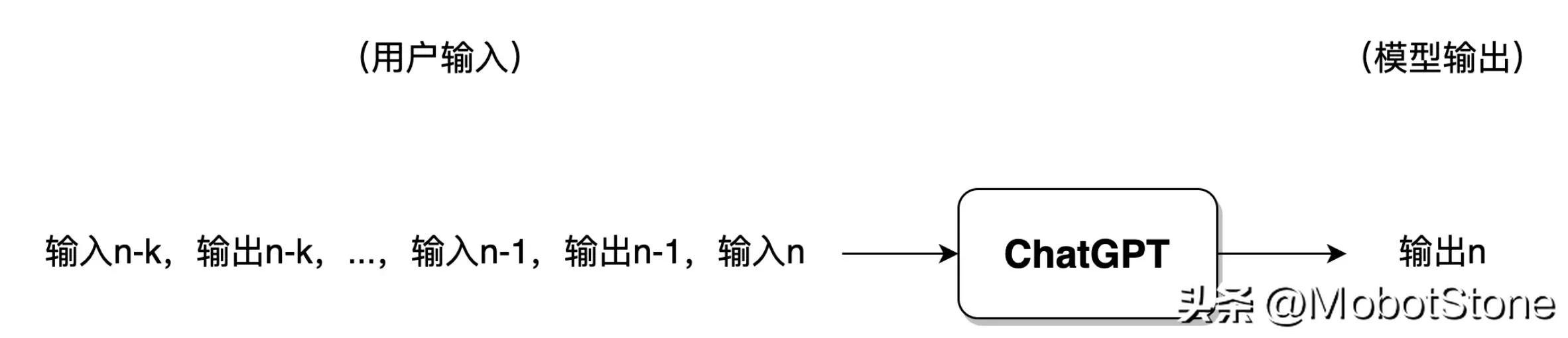
Wenn der Benutzer zu viele Gespräche mit ChatGPT geführt hat, speichert das Modell im Allgemeinen nur die Informationen der letzten Gesprächsrunden und Die vorherigen Gesprächsinformationen werden vergessen.
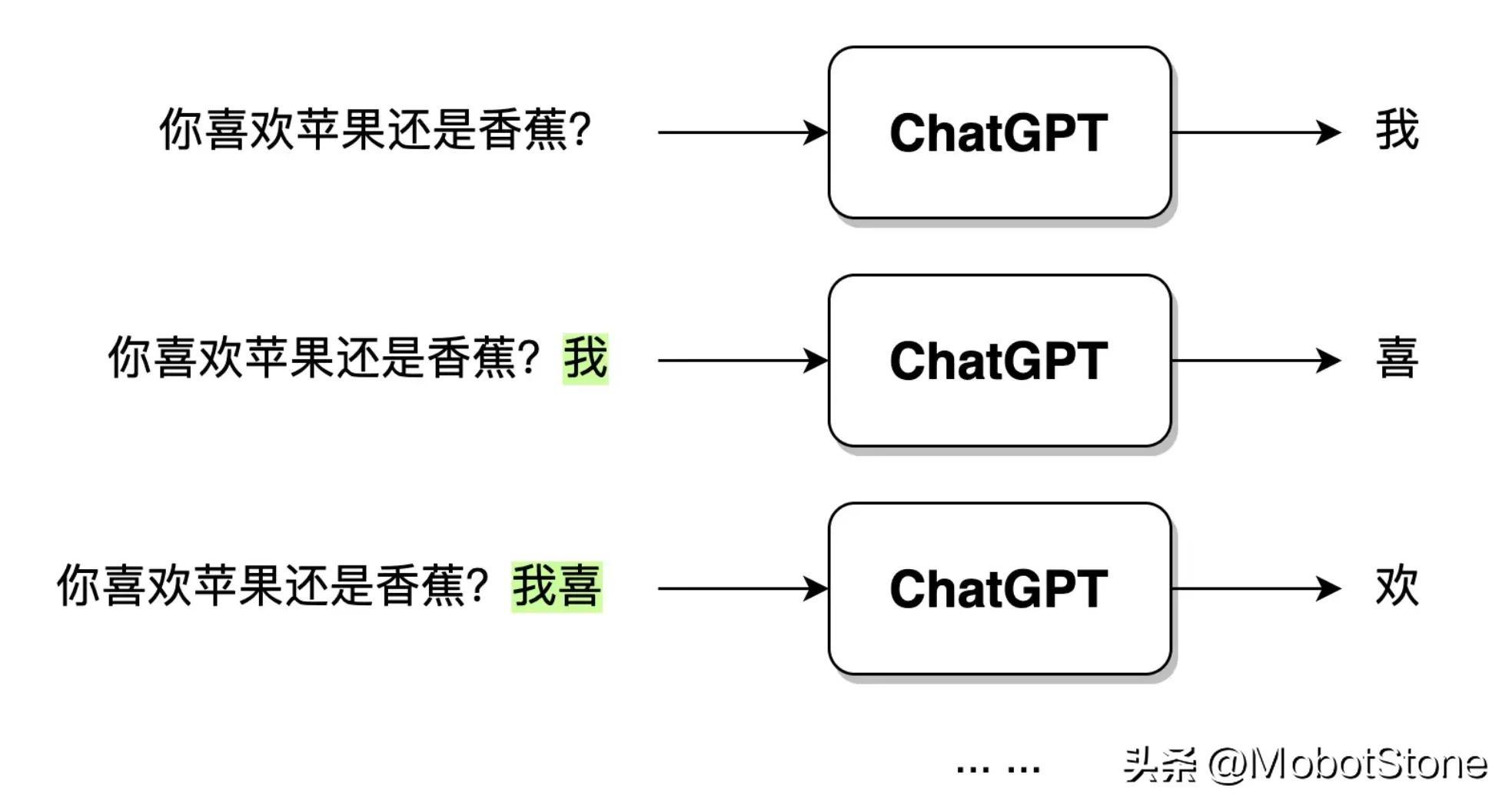
ChatGPT Nach Erhalt der Frageeingabe des Benutzers wird der Ausgabetext nicht direkt auf einmal generiert, sondern Wort für Wort generiert. Diese wörtliche Generierung ist # 🎜🎜#Generativ . Wie unten gezeigt.
Die Entwicklungsgeschichte von ChatGPT und NLP
Die Modellierungsform von ChatGPT wurde früher eingeführt. Stellen Sie sich vor, wenn Sie gebeten würden, ein ChatGPT-Modell zu implementieren, welche Ideen und Methoden hätten Sie? Tatsächlich gibt es grob zwei Strategien: NLP basierend auf Regeln und NLP basierend auf Statistik. Seit den Anfängen von ChatGPT ist der NLP-Bereich in die Ära des Verstärkungslernens eingetreten, also NLP, das auf Verstärkungslernen basiert.
Regelbasiertes NLP
Regelbasiertes NLP bezieht sich auf die Verwendung manuell geschriebener Regeln zur Verarbeitung natürlicher Sprache. Diese Regeln basieren in der Regel auf Kenntnissen in Grammatik, Semantik und Pragmatik und können zum Parsen und Generieren natürlicher Sprache verwendet werden. Beispielsweise können wir ein Dialogsystem entwerfen, das auf den folgenden Regeln basiert:
Regel 1: Wenn das Modell die Frage des Benutzers erhält, entfernen Sie das Wort „?“ aus der Frage „?“ „ „Ersetzen Sie“ durch „.“ , können wir ein Dialogmodell basierend auf diesen Regeln erstellen und den Dialogmodus starten.
Benutzer: Hallo. Modell: Hallo. Benutzer: Sind Sie ChatGPT? Modell: Ja, ich bin ChatGPT. Benutzer: Gefällt dir die Nuggets-Community? Modell: Ich liebe die Nuggets-Community. Benutzer: Haben Sie jemals das jionlp-Toolkit verwendet? Modell: Ich habe das Jionlp-Toolkit verwendet.
Das Obige ist ein sehr oberflächliches Beispiel für ein regelbasiertes Dialogsystem. Ich glaube, dass die Leser die bestehenden Probleme leicht herausfinden können. Was ist, wenn das Benutzerproblem zu komplex ist? Was ist, wenn die Frage kein Fragezeichen enthält? Wir müssen ständig verschiedene Regeln schreiben, um die oben genannten Sondersituationen abzudecken. Dies zeigt, dass es mehrere offensichtliche Mängel gibt, die auf Regeln basieren:In natürlicher Sprache kann keine Regel die Anforderungen vollständig abdecken, daher ist sie bei der Bearbeitung komplexer natürlichsprachlicher Aufgaben nicht effektiv;# 🎜🎜#Die Regeln sind endlos und es wird eine Menge Arbeit sein, sich auf die menschliche Kraft zu verlassen;
- Dies ist der Weg und die Methode in der frühen Entwicklung von NLP: Abschluss der Konstruktion von Modellsystemen auf der Grundlage von Regeln. In der Frühzeit wurde es auch allgemein als Symbolik bezeichnet.
- Statistikbasiertes NLP
- Statistikbasiertes NLP nutzt maschinelle Lernalgorithmen, um die regelmäßigen Merkmale natürlicher Sprache aus einer großen Anzahl von Korpora zu lernen. Dies wurde in der Literatur auch als Konnektionismus bezeichnet frühe Tage. Diese Methode erfordert kein manuelles Schreiben von Regeln. Die Regeln werden hauptsächlich durch das Erlernen der statistischen Merkmale der Sprache in das Modell einbezogen. Mit anderen Worten: Bei der regelbasierten Methode sind die Regeln explizit und werden manuell geschrieben. Bei der statistischen Methode sind die Regeln unsichtbar, implizit in den Modellparametern enthalten und werden vom Modell auf der Grundlage der Daten trainiert.
- Diese Modelle haben sich in den letzten Jahren rasant weiterentwickelt und ChatGPT ist eines davon. Darüber hinaus gibt es eine Vielzahl von Modellen mit unterschiedlichen Formen und Strukturen, deren Grundprinzipien jedoch gleich sind. Ihre Verarbeitungsmethoden sind hauptsächlich wie folgt:
In ChatGPT wird es hauptsächlich verwendet Die Pre-Training-Technologie (Pre-Training) wird verwendet, um das statistikbasierte Lernen von NLP-Modellen abzuschließen. Das Vortraining im NLP-Bereich wurde erstmals durch das ELMO-Modell (Embedding from Language Models) eingeführt, und diese Methode wurde von verschiedenen Modellen für tiefe neuronale Netze wie ChatGPT weitgehend übernommen.
Der Schwerpunkt liegt auf dem Erlernen eines Sprachmodells, das auf einem großen Originalkorpus basiert. Dieses Modell lernt nicht direkt, wie eine bestimmte Aufgabe gelöst werden soll, sondern lernt aus Grammatik, Morphologie, Pragmatik und gesundem Menschenverstand , Wissen und andere Informationen werden in das Sprachmodell integriert. Intuitiv ähnelt es eher einem Wissensgedächtnis als der Anwendung von Wissen zur Lösung praktischer Probleme.
Das Vortraining hat viele Vorteile und ist zu einem notwendigen Schritt für fast alle NLP-Modellschulungen geworden. Wir werden dies in den folgenden Kapiteln näher erläutern. Statistikbasierte Methoden sind weitaus beliebter als regelbasierte Methoden. Ihr größter Nachteil ist jedoch die Black-Box-Unsicherheit, das heißt, die Regeln sind unsichtbar und implizit in den Parametern enthalten. Beispielsweise liefert ChatGPT auch einige mehrdeutige und unverständliche Ergebnisse. Wir können anhand der Ergebnisse nicht beurteilen, warum das Modell eine solche Antwort gegeben hat.

NLP basierend auf Reinforcement Learning
Das ChatGPT-Modell basiert auf Statistiken, verwendet aber auch eine neue Methode, Reinforcement Learning mit menschlichem Feedback (RLHF), um hervorragende Ergebnisse zu erzielen und die Entwicklung von NLP in eine neue Phase zu bringen.
Vor ein paar Jahren besiegte Alpha GO Ke Jie. Dies kann fast beweisen, dass Verstärkungslernen unter geeigneten Bedingungen den Menschen vollständig besiegen und sich der Grenze der Perfektion nähern kann. Derzeit befinden wir uns noch im Zeitalter schwacher künstlicher Intelligenz, aber auf den Bereich Go beschränkt, ist Alpha GO eine starke künstliche Intelligenz, deren Kern im verstärkenden Lernen liegt.
Das sogenannte Reinforcement Learning ist eine Methode des maschinellen Lernens, die darauf abzielt, dem Agenten (Agent, bezieht sich im NLP hauptsächlich auf das tiefe neuronale Netzwerkmodell, das ChatGPT-Modell) zu ermöglichen, durch Interaktion mit der Umgebung optimale Entscheidungen zu treffen .
Diese Methode ist so, als würde man einem Hund (Agent) beibringen, auf eine Pfeife zu hören (Umgebung) und zu essen (Lernziel).
Ein Welpe wird mit Futter belohnt, wenn er seinen Besitzer pfeifen hört; wenn der Besitzer jedoch nicht pfeift, kann der Welpe nur verhungern. Durch wiederholtes Fressen und Hungern kann der Welpe entsprechende konditionierte Reflexe etablieren, wodurch ein Verstärkungslernen tatsächlich abgeschlossen wird.
Im Bereich NLP ist das Umfeld hier deutlich komplexer. Die Umgebung für das NLP-Modell ist keine echte menschliche Sprachumgebung, sondern ein künstlich konstruiertes Sprachumgebungsmodell. Daher liegt der Schwerpunkt hier auf dem verstärkenden Lernen mit künstlichem Feedback.

Basierend auf Statistiken kann das Modell den Trainingsdatensatz mit dem größten Freiheitsgrad anpassen, während das Lernen durch Verstärkung dem Modell einen größeren Freiheitsgrad verleiht, sodass das Modell unabhängig lernen und die Einschränkungen des Etablierten durchbrechen kann Datensatz. Das ChatGPT-Modell integriert statistische Lernmethoden und verstärkende Lernmethoden. Der Modelltrainingsprozess ist in der folgenden Abbildung dargestellt:
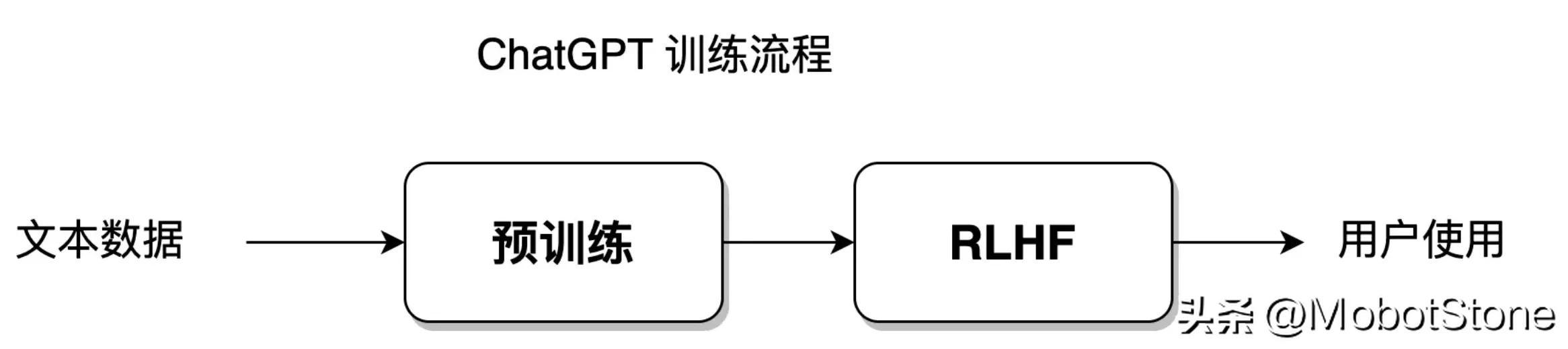
Dieser Teil des Trainingsprozesses wird in den Abschnitten 8–11 erläutert.
Der Entwicklungstrend der NLP-Technologie
Tatsächlich sind die drei auf Regeln, Statistiken und Verstärkungslernen basierenden Methoden nicht nur ein Mittel zur Verarbeitung natürlicher Sprache, sondern eine Idee. Ein Algorithmusmodell, das ein bestimmtes Problem löst, ist oft das Produkt einer Fusion dieser drei Lösungen.
Vergleicht man einen Computer mit einem Kind, ist die Verarbeitung natürlicher Sprache wie ein Mensch, der das Kind zum Wachsen erzieht.
Der regelbasierte Ansatz ist so, als ob ein Elternteil ein Kind zu 100 % kontrolliert und von ihm verlangt, gemäß seinen eigenen Anweisungen und Regeln zu handeln, z. B. die Lernstunden pro Tag festzulegen und dem Kind jede Frage beizubringen. Während des gesamten Prozesses liegt der Schwerpunkt auf praxisorientiertem Unterricht, wobei die Initiative und der Fokus auf den Eltern liegen. Beim NLP liegen die Initiative und der Fokus des gesamten Prozesses bei Programmierern und Forschern, die Sprachregeln schreiben.
Die statistikbasierte Methode ist so, als würden Eltern ihren Kindern nur sagen, wie sie lernen sollen, aber nicht jede einzelne Frage unterrichten. Der Schwerpunkt liegt auf der Halbanleitung. Bei NLP liegt der Schwerpunkt des Lernens auf neuronalen Netzwerkmodellen, die Initiative wird jedoch weiterhin von Algorithmeningenieuren gesteuert.
Basierend auf der Methode des verstärkenden Lernens ist es so, als würden Eltern ihren Kindern nur Bildungsziele setzen. Sie verlangen beispielsweise, dass ihre Kinder 90 Punkte in der Prüfung erreichen, aber es ist ihnen egal, wie die Kinder lernen auf Selbststudium. Die Kinder verfügen über ein äußerst hohes Maß an Freiheit und Eigeninitiative. Eltern belohnen oder bestrafen nur die Endergebnisse und beteiligen sich nicht am gesamten Bildungsprozess. Für NLP liegen der Fokus und die Initiative des gesamten Prozesses im Modell selbst.
Die Entwicklung von NLP hat sich allmählich den statistikbasierten Methoden angenähert, und schließlich hat die auf Verstärkungslernen basierende Methode den vollständigen Sieg erreicht. Das Symbol des Sieges ist das Aufkommen von ChatGPT; Die Methode wurde nach und nach auf eine Hilfsverarbeitungsmethode reduziert. Von Anfang an ging die Entwicklung des ChatGPT-Modells unbeirrt in die Richtung voran, das Modell selbst lernen zu lassen.
ChatGPTs neuronaler Netzwerkstrukturtransformator
Um den Lesern das Verständnis zu erleichtern, wurde in der vorherigen Einführung die spezifische interne Struktur des ChatGPT-Modells nicht erwähnt.
ChatGPT ist ein großes neuronales Netzwerk, das aus mehreren Transformer-Schichten besteht. Seit 2018 ist es eine gängige Standardmodellstruktur im NLP-Bereich und Transformer ist in fast allen NLP-Modellen zu finden.
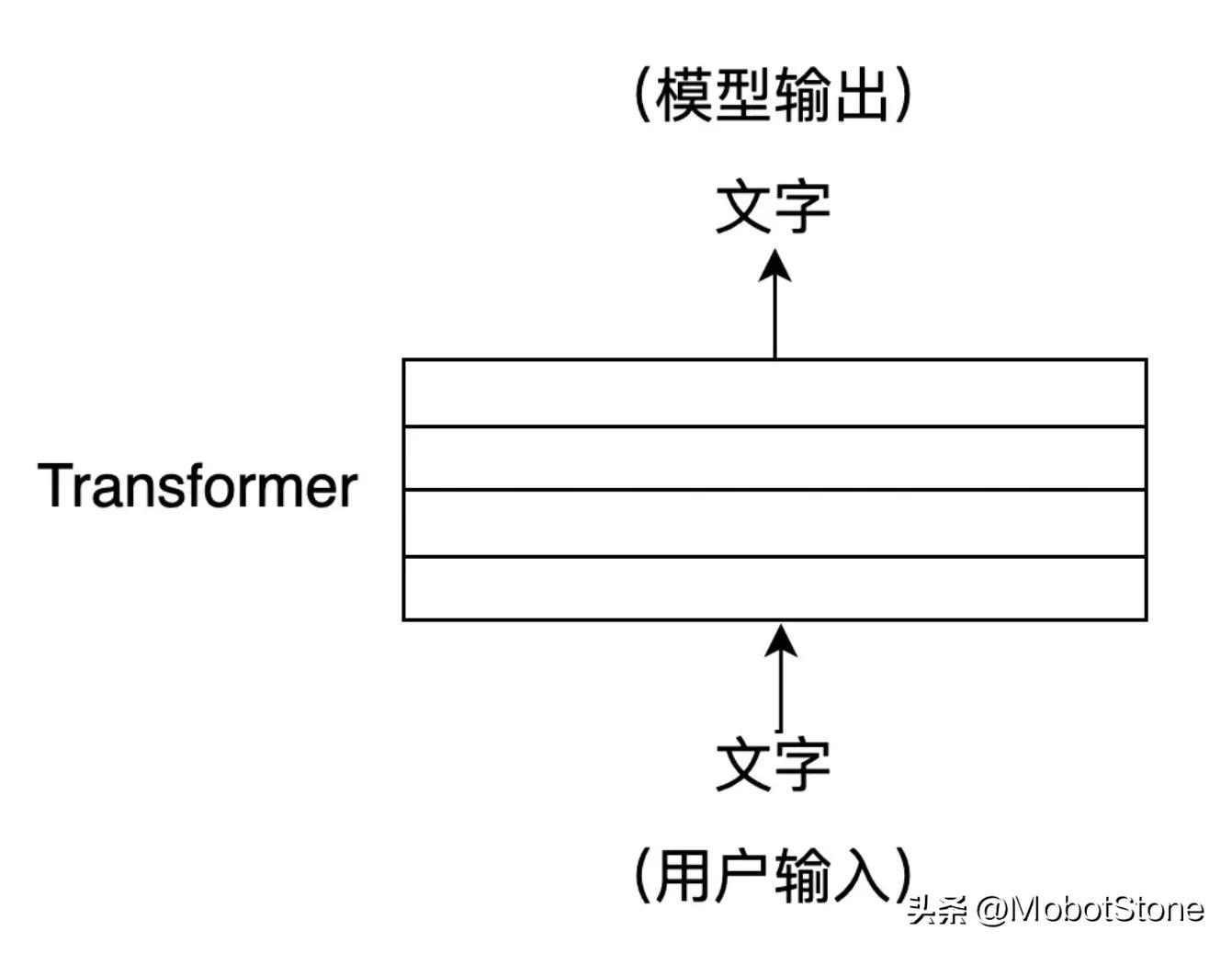
Wenn ChatGPT ein Haus ist, dann ist Transformer der Baustein, der ChatGPT aufbaut. Der Kern von
Transformer ist der Selbstaufmerksamkeitsmechanismus, der dem Modell helfen kann, bei der Verarbeitung der Eingabetextsequenz automatisch auf andere Positionszeichen zu achten, die mit dem aktuellen Positionszeichen in Zusammenhang stehen. Der Selbstaufmerksamkeitsmechanismus kann jede Position in der Eingabesequenz als Vektor darstellen, und diese Vektoren können gleichzeitig an Berechnungen teilnehmen, wodurch eine effiziente parallele Berechnung erreicht wird. Nennen Sie ein Beispiel:
Wenn bei der maschinellen Übersetzung der englische Satz „Ich bin ein guter Schüler“ ins Chinesische übersetzt wird, übersetzt das traditionelle maschinelle Übersetzungsmodell ihn möglicherweise in „Ich bin ein guter Schüler“, diese Übersetzung führt jedoch möglicherweise nicht zu Ergebnissen genau genug. Der Artikel „a“ im Englischen muss bei der Übersetzung ins Chinesische anhand des Kontexts bestimmt werden.
Wenn Sie das Transformer-Modell für die Übersetzung verwenden, können Sie genauere Übersetzungsergebnisse erhalten, z. B. „Ich bin ein guter Schüler“.
Das liegt daran, dass Transformer die Beziehung zwischen Wörtern über große Distanzen in englischen Sätzen besser erfassen und lange Abhängigkeiten vom Textkontext lösen kann. Der Selbstaufmerksamkeitsmechanismus wird in Abschnitt 5–6 vorgestellt, und die detaillierte Struktur von Transformer wird in Abschnitt 6–7 vorgestellt.
Zusammenfassung
- Die Entwicklung des NLP-Bereichs hat sich allmählich vom manuellen Schreiben von Regeln und der logischen Steuerung von Computerprogrammen zu einer völligen Überlassung der Anpassung an die Sprachumgebung an das Netzwerkmodell verlagert.
- ChatGPT ist derzeit das NLP-Modell, das dem Bestehen des Turing-Tests am nächsten kommt, und GPT4 und GPT5 werden in Zukunft noch näher dran sein. Der Workflow von
- ChatGPT ist ein generatives Dialogsystem. Der Trainingsprozess von
- ChatGPT umfasst das Vortraining des Sprachmodells und das RLHF-Verstärkungslernen mit manuellem Feedback. Die Modellstruktur von
- ChatGPT übernimmt Transformer mit Selbstaufmerksamkeitsmechanismus als Kern.
Das obige ist der detaillierte Inhalt vonJeder versteht ChatGPT Kapitel 1: ChatGPT und die Verarbeitung natürlicher Sprache. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1382
1382
 52
52

 YOLO ist unsterblich! YOLOv9 wird veröffentlicht: Leistung und Geschwindigkeit SOTA~
Feb 26, 2024 am 11:31 AM
YOLO ist unsterblich! YOLOv9 wird veröffentlicht: Leistung und Geschwindigkeit SOTA~
Feb 26, 2024 am 11:31 AM
Heutige Deep-Learning-Methoden konzentrieren sich darauf, die am besten geeignete Zielfunktion zu entwerfen, damit die Vorhersageergebnisse des Modells der tatsächlichen Situation am nächsten kommen. Gleichzeitig muss eine geeignete Architektur entworfen werden, um ausreichend Informationen für die Vorhersage zu erhalten. Bestehende Methoden ignorieren die Tatsache, dass bei der schichtweisen Merkmalsextraktion und räumlichen Transformation der Eingabedaten eine große Menge an Informationen verloren geht. Dieser Artikel befasst sich mit wichtigen Themen bei der Datenübertragung über tiefe Netzwerke, nämlich Informationsengpässen und umkehrbaren Funktionen. Darauf aufbauend wird das Konzept der programmierbaren Gradienteninformation (PGI) vorgeschlagen, um die verschiedenen Änderungen zu bewältigen, die tiefe Netzwerke zur Erreichung mehrerer Ziele erfordern. PGI kann vollständige Eingabeinformationen für die Zielaufgabe zur Berechnung der Zielfunktion bereitstellen und so zuverlässige Gradienteninformationen zur Aktualisierung der Netzwerkgewichte erhalten. Darüber hinaus wird ein neues, leichtgewichtiges Netzwerk-Framework entworfen
 Die Grundlage, Grenze und Anwendung von GNN
Apr 11, 2023 pm 11:40 PM
Die Grundlage, Grenze und Anwendung von GNN
Apr 11, 2023 pm 11:40 PM
Graphische neuronale Netze (GNN) haben in den letzten Jahren rasante und unglaubliche Fortschritte gemacht. Das graphische neuronale Netzwerk, auch bekannt als Graph Deep Learning, Graph Representation Learning (Graph Representation Learning) oder geometrisches Deep Learning, ist das am schnellsten wachsende Forschungsthema im Bereich des maschinellen Lernens, insbesondere des Deep Learning. Der Titel dieser Veröffentlichung lautet „Basics, Frontiers and Applications of GNN“ und stellt hauptsächlich den allgemeinen Inhalt des umfassenden Buches „Basics, Frontiers and Applications of Graph Neural Networks“ vor, das von den Wissenschaftlern Wu Lingfei, Cui Peng, Pei Jian und Zhao zusammengestellt wurde Liang. 1. Einführung in graphische neuronale Netze 1. Warum Graphen studieren? Graphen sind eine universelle Sprache zur Beschreibung und Modellierung komplexer Systeme. Der Graph selbst ist nicht kompliziert, er besteht hauptsächlich aus Kanten und Knoten. Wir können Knoten verwenden, um jedes Objekt darzustellen, das wir modellieren möchten, und Kanten, um zwei darzustellen
 Ein Überblick über die drei gängigen Chiparchitekturen für autonomes Fahren in einem Artikel
Apr 12, 2023 pm 12:07 PM
Ein Überblick über die drei gängigen Chiparchitekturen für autonomes Fahren in einem Artikel
Apr 12, 2023 pm 12:07 PM
Die aktuellen Mainstream-KI-Chips sind hauptsächlich in drei Kategorien unterteilt: GPU, FPGA und ASIC. Sowohl GPU als auch FPGA sind im Frühstadium relativ ausgereifte Chiparchitekturen und Allzweckchips. ASIC ist ein Chip, der für bestimmte KI-Szenarien angepasst ist. Die Industrie hat bestätigt, dass CPUs nicht für KI-Computing geeignet sind, sie aber auch für KI-Anwendungen unerlässlich sind. Vergleich der GPU-Lösungsarchitektur zwischen GPU und CPU Die CPU folgt der von Neumann-Architektur, deren Kern die Speicherung von Programmen/Daten und die serielle sequentielle Ausführung ist. Daher benötigt die CPU-Architektur viel Platz zum Platzieren der Speichereinheit (Cache) und der Steuereinheit (Steuerung). Im Gegensatz dazu nimmt die Recheneinheit (ALU) nur einen kleinen Teil ein, sodass die CPU eine große Leistung erbringt Paralleles Rechnen.
 „Der Eigentümer von Bilibili UP hat erfolgreich das weltweit erste Redstone-basierte neuronale Netzwerk geschaffen, das in den sozialen Medien für Aufsehen sorgte und von Yann LeCun gelobt wurde.'
May 07, 2023 pm 10:58 PM
„Der Eigentümer von Bilibili UP hat erfolgreich das weltweit erste Redstone-basierte neuronale Netzwerk geschaffen, das in den sozialen Medien für Aufsehen sorgte und von Yann LeCun gelobt wurde.'
May 07, 2023 pm 10:58 PM
In Minecraft ist Redstone ein sehr wichtiger Gegenstand. Es ist ein einzigartiges Material im Spiel. Schalter, Redstone-Fackeln und Redstone-Blöcke können Drähten oder Objekten stromähnliche Energie verleihen. Mithilfe von Redstone-Schaltkreisen können Sie Strukturen aufbauen, mit denen Sie andere Maschinen steuern oder aktivieren können. Sie können selbst so gestaltet sein, dass sie auf die manuelle Aktivierung durch Spieler reagieren, oder sie können wiederholt Signale ausgeben oder auf Änderungen reagieren, die von Nicht-Spielern verursacht werden, beispielsweise auf Bewegungen von Kreaturen und Gegenstände. Fallen, Pflanzenwachstum, Tag und Nacht und mehr. Daher kann Redstone in meiner Welt extrem viele Arten von Maschinen steuern, von einfachen Maschinen wie automatischen Türen, Lichtschaltern und Blitzstromversorgungen bis hin zu riesigen Aufzügen, automatischen Farmen, kleinen Spielplattformen und sogar in Spielcomputern gebauten Maschinen . Kürzlich, B-Station UP main @
 Eine Drohne, die starken Winden standhält? Caltech nutzt 12 Minuten Flugdaten, um Drohnen das Fliegen im Wind beizubringen
Apr 09, 2023 pm 11:51 PM
Eine Drohne, die starken Winden standhält? Caltech nutzt 12 Minuten Flugdaten, um Drohnen das Fliegen im Wind beizubringen
Apr 09, 2023 pm 11:51 PM
Wenn der Wind stark genug ist, um den Schirm zu blasen, ist die Drohne stabil, genau wie folgt: Das Fliegen im Wind ist ein Teil des Fliegens in der Luft. Wenn der Pilot das Flugzeug aus großer Höhe landet, kann die Windgeschwindigkeit variieren Auf einer kleineren Ebene können böige Winde auch den Drohnenflug beeinträchtigen. Derzeit werden Drohnen entweder unter kontrollierten Bedingungen, ohne Wind, geflogen oder von Menschen per Fernbedienung gesteuert. Drohnen werden von Forschern gesteuert, um in Formationen am freien Himmel zu fliegen. Diese Flüge werden jedoch normalerweise unter idealen Bedingungen und Umgebungen durchgeführt. Damit Drohnen jedoch autonom notwendige, aber routinemäßige Aufgaben wie die Zustellung von Paketen ausführen können, müssen sie sich in Echtzeit an die Windverhältnisse anpassen können. Um Drohnen beim Fliegen im Wind wendiger zu machen, hat ein Team von Ingenieuren des Caltech
 Multipfad, Multidomäne, alles inklusive! Google AI veröffentlicht das allgemeine Modell MDL für Multi-Domain-Lernen
May 28, 2023 pm 02:12 PM
Multipfad, Multidomäne, alles inklusive! Google AI veröffentlicht das allgemeine Modell MDL für Multi-Domain-Lernen
May 28, 2023 pm 02:12 PM
Deep-Learning-Modelle für Sehaufgaben (z. B. Bildklassifizierung) werden normalerweise durchgängig mit Daten aus einem einzelnen visuellen Bereich (z. B. natürlichen Bildern oder computergenerierten Bildern) trainiert. Im Allgemeinen muss eine Anwendung, die Vision-Aufgaben für mehrere Domänen ausführt, mehrere Modelle für jede einzelne Domäne erstellen und diese unabhängig voneinander trainieren. Während der Inferenz verarbeitet jedes Modell eine bestimmte Domäne. Auch wenn sie auf unterschiedliche Bereiche ausgerichtet sind, sind einige Merkmale der frühen Schichten zwischen diesen Modellen ähnlich, sodass das gemeinsame Training dieser Modelle effizienter ist. Dies reduziert die Latenz und den Stromverbrauch und reduziert die Speicherkosten für die Speicherung jedes Modellparameters. Dieser Ansatz wird als Multi-Domain-Learning (MDL) bezeichnet. Darüber hinaus können MDL-Modelle auch Single-Modelle übertreffen
 1,3 ms dauert 1,3 ms! Tsinghuas neueste Open-Source-Architektur für mobile neuronale Netzwerke RepViT
Mar 11, 2024 pm 12:07 PM
1,3 ms dauert 1,3 ms! Tsinghuas neueste Open-Source-Architektur für mobile neuronale Netzwerke RepViT
Mar 11, 2024 pm 12:07 PM
Papieradresse: https://arxiv.org/abs/2307.09283 Codeadresse: https://github.com/THU-MIG/RepViTRepViT funktioniert gut in der mobilen ViT-Architektur und zeigt erhebliche Vorteile. Als nächstes untersuchen wir die Beiträge dieser Studie. In dem Artikel wird erwähnt, dass Lightweight-ViTs bei visuellen Aufgaben im Allgemeinen eine bessere Leistung erbringen als Lightweight-CNNs, hauptsächlich aufgrund ihres Multi-Head-Selbstaufmerksamkeitsmoduls (MSHA), das es dem Modell ermöglicht, globale Darstellungen zu lernen. Allerdings wurden die architektonischen Unterschiede zwischen Lightweight-ViTs und Lightweight-CNNs noch nicht vollständig untersucht. In dieser Studie integrierten die Autoren leichte ViTs in die effektiven
 Erforschung siamesischer Netzwerke unter Verwendung von Kontrastverlust zum Vergleich der Bildähnlichkeit
Apr 02, 2024 am 11:37 AM
Erforschung siamesischer Netzwerke unter Verwendung von Kontrastverlust zum Vergleich der Bildähnlichkeit
Apr 02, 2024 am 11:37 AM
Einleitung Im Bereich Computer Vision ist die genaue Messung der Bildähnlichkeit eine wichtige Aufgabe mit einem breiten Spektrum praktischer Anwendungen. Von Bildsuchmaschinen über Gesichtserkennungssysteme bis hin zu inhaltsbasierten Empfehlungssystemen ist die Fähigkeit, ähnliche Bilder effektiv zu vergleichen und zu finden, wichtig. Das siamesische Netzwerk bietet in Kombination mit Kontrastverlust einen leistungsstarken Rahmen für das datengesteuerte Erlernen der Bildähnlichkeit. In diesem Blogbeitrag werden wir uns mit den Details siamesischer Netzwerke befassen, das Konzept des Kontrastverlusts untersuchen und untersuchen, wie diese beiden Komponenten zusammenarbeiten, um ein effektives Bildähnlichkeitsmodell zu erstellen. Erstens besteht das siamesische Netzwerk aus zwei identischen Teilnetzwerken mit denselben Gewichten und Parametern. Jedes Subnetzwerk codiert das Eingabebild in einen Merkmalsvektor, der
