

Datenvisualisierung ist ein sehr wichtiger Bestandteil von Data-Science- oder Machine-Learning-Projekten. In der Regel müssen Sie zu Beginn eines Projekts eine explorative Datenanalyse (EDA) durchführen, um ein gewisses Verständnis der Daten zu erlangen. Durch die Erstellung von Visualisierungen kann die Analyseaufgabe wirklich klarer und verständlicher gemacht werden, insbesondere bei umfangreichen, hochdimensionalen Daten . Satz. Gegen Ende eines Projekts ist es auch wichtig, das Endergebnis klar, prägnant und überzeugend zu präsentieren, damit Ihr Publikum (bei dem es sich oft um technisch nicht versierte Kunden handelt) es verstehen kann.
Eine Methode zur Verwendung von Farbe zur Darstellung des Werts jedes Elements in einer Datenmatrix wird als Heat Map bezeichnet. Durch die Matrixindizierung werden zwei zu vergleichende Elemente oder Merkmale verknüpft und unterschiedliche Farben werden verwendet, um ihre unterschiedlichen Werte darzustellen. Heatmaps eignen sich zur Darstellung von Beziehungen zwischen mehreren Merkmalsvariablen, da die Farbe direkt die Größe des Matrixelements an dieser Position widerspiegeln kann. Sie können jede Beziehung über andere Punkte in der Heatmap mit anderen Beziehungen im Datensatz vergleichen. Aufgrund der intuitiven Natur der Farbe bietet sie uns eine einfache und leicht verständliche Möglichkeit, Daten zu interpretieren.
Werfen wir nun einen Blick auf den Implementierungscode. Im Vergleich zu „matplotlib“ kann „seaborn“ zum Zeichnen komplexerer Grafiken verwendet werden, für die normalerweise mehr Komponenten erforderlich sind, z. B. mehrere Farben, Grafiken oder Variablen. „matplotlib“ kann zum Anzeigen von Grafiken, „NumPy“ zum Generieren von Daten und „pandas“ zum Verarbeiten von Daten verwendet werden! Zeichnen ist nur eine einfache Funktion von „seaborn“.
# Importing libs import seaborn as sns import pandas as pd import numpy as np import matplotlib.pyplot as plt # Create a random dataset data = pd.DataFrame(np.random.random((10,6)), columns=["Iron Man","Captain America","Black Widow","Thor","Hulk", "Hawkeye"]) print(data) # Plot the heatmap heatmap_plot = sns.heatmap(data, center=0, cmap='gist_ncar') plt.show()
Das zweidimensionale Dichtediagramm (2D-Dichtediagramm) ist eine intuitive Erweiterung der eindimensionalen Version des Dichtediagramms und hat im Vergleich zur eindimensionalen Version den Vorteil, dass dies möglich ist siehe die Wahrscheinlichkeitsverteilung zweier Variablen. Das Skalendiagramm auf der rechten Seite verwendet Farben, um die Wahrscheinlichkeit jedes Punkts im 2D-Dichtediagramm unten darzustellen. Der Ort, an dem unsere Daten die höchste Wahrscheinlichkeit des Auftretens haben (d. h. der Ort, an dem die Datenpunkte am stärksten konzentriert sind), scheint bei Größe = 0,5 und Geschwindigkeit = 1,4 zu liegen. Wie Sie inzwischen wissen, sind 2D-Dichtediagramme sehr nützlich, um mit zwei Variablen schnell die Bereiche zu finden, in denen unsere Daten am stärksten konzentriert sind, im Gegensatz zu nur einer Variablen wie bei einem 1D-Dichtediagramm. Das Beobachten der Daten mit einem zweidimensionalen Dichtediagramm ist nützlich, wenn Sie zwei Variablen haben, die für die Ausgabe wichtig sind, und verstehen möchten, wie sie zusammenarbeiten, um zur Verteilung der Ausgabe beizutragen.
Fakten haben wieder einmal bewiesen, dass die Verwendung von „seaborn“ zum Schreiben von Code sehr praktisch ist! Dieses Mal erstellen wir eine verzerrte Verteilung, um die Datenvisualisierung interessanter zu gestalten. Sie können die meisten optionalen Parameter anpassen, um die Visualisierung übersichtlicher zu gestalten.
# Importing libs import seaborn as sns import matplotlib.pyplot as plt from scipy.stats import skewnorm # Create the data speed = skewnorm.rvs(4, size=50) size = skewnorm.rvs(4, size=50) # Create and shor the 2D Density plot ax = sns.kdeplot(speed, size, cmap="Reds", shade=False, bw=.15, cbar=True) ax.set(xlabel='speed', ylabel='size') plt.show()
Spider-Plots sind eine der besten Möglichkeiten, Eins-zu-viele-Beziehungen darzustellen. Mit anderen Worten: Sie können die Werte mehrerer Variablen in Bezug auf eine bestimmte Variable oder Kategorie grafisch darstellen und anzeigen. In einem Spinnennetzdiagramm ist die Bedeutung einer Variablen gegenüber einer anderen klar und offensichtlich, da die abgedeckte Fläche und die Länge vom Zentrum in einer bestimmten Richtung größer werden. Sie können die verschiedenen Kategorien von Objekten, die durch diese Variablen beschrieben werden, nebeneinander darstellen, um die Unterschiede zwischen ihnen zu sehen. In der Tabelle unten können Sie die verschiedenen Eigenschaften der Avengers leicht vergleichen und sehen, wo sie sich jeweils auszeichnen! (Bitte beachten Sie, dass diese Daten zufällig festgelegt werden und ich nicht voreingenommen gegenüber den Mitgliedern der Avengers bin.)
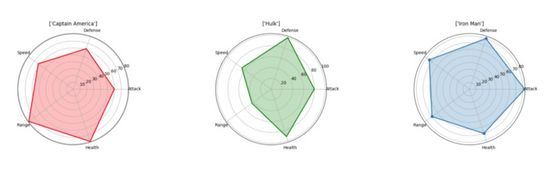
Wir können „matplotlib“ verwenden, um Visualisierungsergebnisse zu generieren, ohne „seaborn“ zu verwenden. Wir müssen dafür sorgen, dass jedes Attribut gleichmäßig über den Umfang verteilt ist. An jeder Ecke wird es Beschriftungen geben und wir werden die Werte als einen Punkt darstellen, dessen Abstand von der Mitte proportional zu seinem Wert/seiner Größe ist. Um dies deutlicher zu verdeutlichen, füllen wir den Bereich, der durch die Verbindungslinien zwischen den Eigenschaftspunkten gebildet wird, mit einer halbtransparenten Farbe.
# Import libs
import pandas as pd
import seaborn as sns
import numpy as np
import matplotlib.pyplot as plt
# Get the data
df=pd.read_csv("avengers_data.csv")
print(df)
"""
# Name Attack Defense Speed Range Health
0 1 Iron Man 83 80 75 70 70
1 2 Captain America 60 62 63 80 80
2 3 Thor 80 82 83 100 100
3 3 Hulk 80 100 67 44 92
4 4 Black Widow 52 43 60 50 65
5 5 Hawkeye 58 64 58 80 65
"""
# Get the data for Iron Man
labels=np.array(["Attack","Defense","Speed","Range","Health"])
stats=df.loc[0,labels].values
# Make some calculations for the plot
angles=np.linspace(0, 2*np.pi, len(labels), endpoint=False)
stats=np.concatenate((stats,[stats[0]]))
angles=np.concatenate((angles,[angles[0]]))
# Plot stuff
fig = plt.figure()
ax = fig.add_subplot(111, polar=True)
ax.plot(angles, stats, 'o-', linewidth=2)
ax.fill(angles, stats, alpha=0.25)
ax.set_thetagrids(angles * 180/np.pi, labels)
ax.set_title([df.loc[0,"Name"]])
ax.grid(True)
plt.show()Wir haben seit der Grundschule gelernt, mit Baumkarten umzugehen. Da Baumdiagramme von Natur aus intuitiv sind, sind sie leicht zu verstehen. Knoten, die direkt verbunden sind, sind eng miteinander verbunden, während Knoten mit mehreren Verbindungen weniger ähnlich sind. In der folgenden Visualisierung habe ich ein Dendrogramm einer kleinen Teilmenge des Datensatzes des Pokémon-Spiels basierend auf Kaggles Statistiken (Gesundheit, Angriff, Verteidigung, Spezialangriff, Spezialverteidigung, Geschwindigkeit) gezeichnet.
因此,统计意义上最匹配的口袋妖怪将被紧密地连接在一起。例如,在图的顶部,阿柏怪 和尖嘴鸟是直接连接的,如果我们查看数据,阿柏怪的总分为 438,尖嘴鸟则为 442,二者非常接近!但是如果我们看看拉达,我们可以看到其总得分为 413,这和阿柏怪、尖嘴鸟就具有较大差别了,所以它们在树状图中是被分开的!当我们沿着树往上移动时,绿色组的口袋妖怪彼此之间比它们和红色组中的任何口袋妖怪都更相似,即使这里并没有直接的绿色的连接。
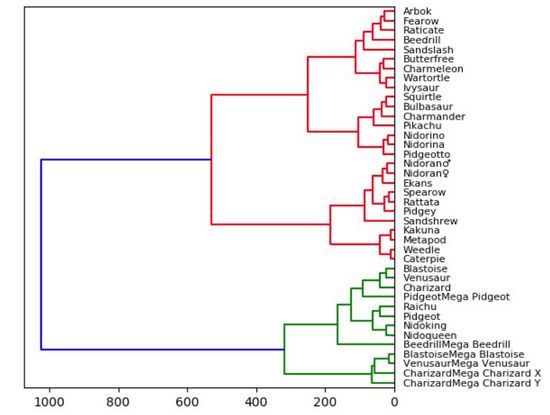
实际上,我们需要使用「Scipy」来绘制树状图。一旦读取了数据集中的数据,我们就会删除字符串列。这么做只是为了使可视化结果更加直观、便于理解,但在实践中,将这些字符串转换为分类变量会得到更好的结果和对比效果。我们还创建了数据帧的索引,以方便在每个节点上正确引用它的列。告诉大家的最后一件事是:在“Scipy”中,计算和绘制树状图只需一行简单代码。
# Import libs import pandas as pd from matplotlib import pyplot as plt from scipy.cluster import hierarchy import numpy as np # Read in the dataset # Drop any fields that are strings # Only get the first 40 because this dataset is big df = pd.read_csv('Pokemon.csv') df = df.set_index('Name') del df.index.name df = df.drop(["Type 1", "Type 2", "Legendary"], axis=1) df = df.head(n=40) # Calculate the distance between each sample Z = hierarchy.linkage(df, 'ward') # Orientation our tree hierarchy.dendrogram(Z, orientation="left", labels=df.index) plt.show()
Das obige ist der detaillierte Inhalt vonWas sind die schnellen und benutzerfreundlichen Python-Datenvisualisierungsmethoden?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



