

Wenn in einer tatsächlichen Produktionsumgebung das Lesen und Schreiben der MySQL-Datenbank vollständig auf einem Datenbankserver ausgeführt wird, kann dieser die tatsächlichen Anforderungen an Sicherheit, hohe Verfügbarkeit oder hohe Parallelität im Allgemeinen nicht erfüllen. Daten werden durch Master-Slave-Replikation synchronisiert und anschließend wird die Lese-/Schreibtrennung verwendet, um die gleichzeitige Ladekapazität der Datenbank zu verbessern. 1. Das Konzept der Master-Slave-Replikation
Die Hauptbibliothek (Master) bietet externe
Dienste zum Hinzufügen, Löschen, Ändern und Abfragen von Daten in der Master-Bibliothek und wird in das Binlog geschrieben.Die Slave-Bibliothek (Slave) wird für die Datensynchronisierung und Datenerfassung verwendet Backup, über einen dedizierten Thread, synchronisiert das Binlog in der Hauptbibliothek Änderungen in Bezug auf die Hauptbibliothek und Daten, Berechtigungen und Tabellenstrukturen. Dies entspricht allen Änderungen, die an der Hauptbibliothek vorgenommen werden auf der Slave-Bibliothek über den Master-Slave-Replikationsmechanismus. Vorteile der Master-Slave-Replikation:
Datensicherung, wir können sogar ein Hot-Backup dafür erstellen, über die MySQL-Middleware mycat kann Katastrophentoleranz erreicht werden, und auch eine Notfallwiederherstellung ist möglich reflektiertmycat,可以实现容灾,容灾也体现了高可用。
容灾:如果主库挂了,由中间件代理mycat自动把服务的请求映射到从库,由从库继续对外提供服务,体现出了高可用性(后端的服务允许一定的异常发生,但是后端的架构服务要可以容错,把这些异常的错误处理掉,并对外重新提供正常的服务)
读写分离是基于主从复制来实现的。在实际的应用环境中,肯定是读操作多,就像我们在电商平台上去购买东西,可能看了100个也就买了一两个。所以读操作永远比写这种更新操作多很多。所以我们基于主从复制的读写分离配置,就是让一个主库专门用来做数据的修改,写的时候专门在主库上写,主库通过主从复制把数据的更改通过binlog同步到从库上去,那么其他的客户端查询的请求都会最终映射到从库上去,而我们一个主库带上两三个从库,主库专门用来做数据的更新(写操作),从库专门用来做读操作这样一来可以很好的分摊读写的压力,不用全部都集中在主库上,对于后端服务的并发处理能力有很大的提高,另外就是它的高可用容灾,当主库挂了以后,可以把指定的从库变成主库。
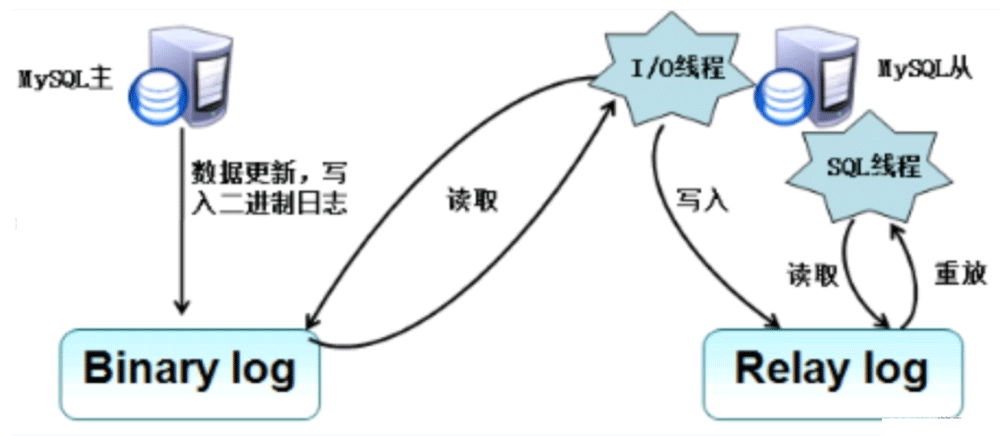
上图中的binlog,即使我们没有主从复制,也是会写binlog的,只不过主从复制是通过binlog来实现的。
主库master服务器创建一个binlog转储线程,将二进制日志内容发送到从服务器
从库里面专门有一个I/O线程专门读取接收主库发送的内容,它会把主库里面发过来的binlog内容接收并写到一个relay log Hohe Verfügbarkeit .
Notfallwiederherstellung: Wenn die Hauptdatenbank ausgefallen ist, ordnet der Middleware-Agent mycat die Dienstanforderung automatisch der Slave-Datenbank zu und die Slave-Datenbank stellt weiterhin Dienste für die Außenwelt bereit, was eine hohe Verfügbarkeit widerspiegelt
Die Lese-Schreib-Trennung wird basierend auf der Master-Slave-Replikation implementiert. In einer tatsächlichen Anwendungsumgebung muss es viele Lesevorgänge geben. Genauso wie wenn wir etwas auf einer E-Commerce-Plattform kaufen, kaufen wir möglicherweise nur ein oder zwei, nachdem wir uns 100 Artikel angesehen haben. Daher gibt es immer viel mehr Lesevorgänge als Schreibaktualisierungsvorgänge. Daher bedeutet unsere auf Master-Slave-Replikation basierende Konfiguration der Lese-/Schreibtrennung, dass eine Master-Datenbank ausschließlich für die Änderung von Daten vorgesehen ist. Beim Schreiben werden Datenänderungen ausschließlich auf der Master-Datenbank synchronisiert Replikation über die Binlog-Bibliothek, dann werden andere Client-Abfrageanforderungen schließlich der Slave-Bibliothek zugeordnet, und wir haben eine Hauptbibliothek mit zwei oder drei Slave-Bibliotheken. Die Hauptbibliothek wird speziell zum Aktualisieren von Daten (Schreibvorgänge) und dem Slave verwendet Die Bibliothek wird speziell zum Aktualisieren von Daten (Schreibvorgängen) verwendet, wodurch der Druck beim Lesen und Schreiben gut verteilt werden kann. Sie muss sich nicht auf die Hauptdatenbank konzentrieren Darüber hinaus bietet es eine hohe Verfügbarkeit und Notfallwiederherstellung. Wenn die Hauptbibliothek ausfällt, kann die angegebene Slave-Bibliothek in die Hauptbibliothek umgewandelt werden. Bild oben Im Binlog wird das Binlog trotzdem geschrieben, auch wenn wir keine Master-Slave-Replikation haben, aber die Master-Slave-Replikation wird über Binlog implementiert. 3. Hauptbibliothek und Slave-Bibliothek 2. Slave-Bibliothek
Relay-Protokoll schreiben. Das Relay-Protokoll entspricht einem Puffer, sodass der Master nicht auf den Abschluss der Slave-Ausführung warten muss, bevor er das nächste Ereignis sendet. Anstatt den Binlog-Inhalt in der Hauptbibliothek zu lesen und direkt auszuführen, besteht der Nachteil der direkten Ausführung darin, dass die Hauptbibliothek möglicherweise viele Binlog-Inhalte enthält und die Ausführung des von der Slave-Bibliothek empfangenen Binlog-Inhalts möglicherweise sehr langsam ist. Dadurch wird die Lücke zwischen den Daten und der Hauptdatenbank immer größer. Die Datenreplikation kann hinterherhinken. Die Slave-Bibliothek startet außerdem einen
SQL-ThreadRelay-Protokoll liest Alle SQL-Anweisungen werden einmal ausgeführt, wodurch
der Inhalt der Slave-Bibliothek erkannt wird der Hauptbibliothek. Synchronisierung4. Master-Slave-Replikationsprozess
🎜🎜Master-Slave-Replikationsprozess: 🎜Zwei Protokolle (Binlog-Binärprotokoll und Relay-Protokollprotokoll) und drei Threads (ein Master-Thread und zwei Threads). des Sklaven) ). 🎜🎜🎜🎜Der Aktualisierungsvorgang der Hauptbibliothek wird in das 🎜Binlog-Binärprotokoll🎜 geschrieben (die Hauptbibliothek muss den Binlog-Schalter einschalten) 🎜🎜🎜🎜Der Masterserver erstellt einen 🎜Binlog-Dump-Thread🎜 und sendet die Binärdatei Protokollinhalte auf dem Slave-Server🎜 Wenn der Slave-Computer den Befehl START SLAVE ausführt, erstellt er einen START SLAVE命令会在从服务器创建一个IO线程,接收master的binary log复制到其中继日志(处于内存中,读写快)。 首先slave开始一个工作线程(I/O线程),I/O线程会主动连接master ,然后主库会开启dump线程,dump线程从master的binlog中读取事件并发送给slave的I/O线程,如果dump线程已经跟上master(主库上的dump线程已经把binlog的内容发完了,而且主库上binlog没有产生更多的内容),dump线程会睡眠并等待binlog产生新的事件,slave的I/O线程接收的事件写入中继日志
slave的SQL线程处理该过程的最后一步,SQL线程从relay log中读取事件,并执行其中的事件更新slave的数据,使其与master的数据同步。只要SQL线程与I/O线程保持一致,中继日志通常会位于os缓存中,所以中继日志的开销很小
linux上的centos作为主库win10上的mysql server作为从库来演示:
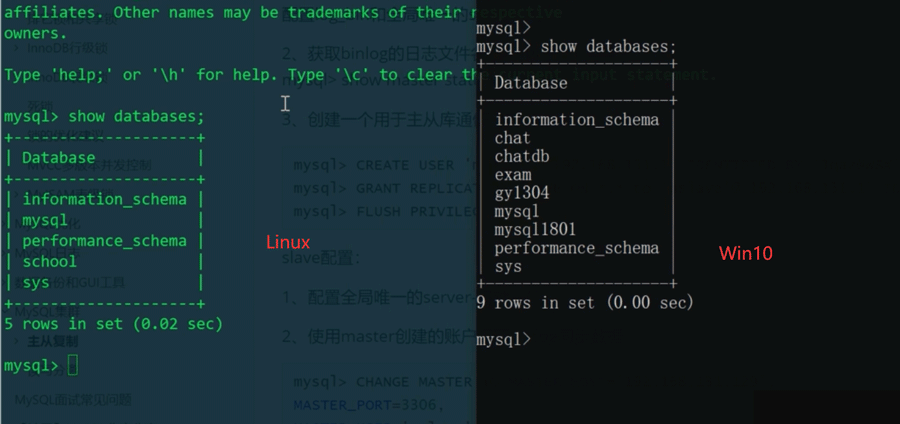
主从复制是单向同步,master的更改往slave同步。在设置主从复制时,主从库之间的数据可能不同。一旦配置完成,主库的所有更改将会同步到从库。
master创建mytest数据库:
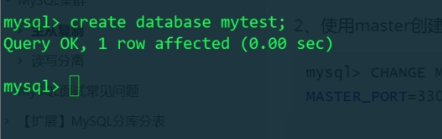
查看slave,发现mytest同步过来了:
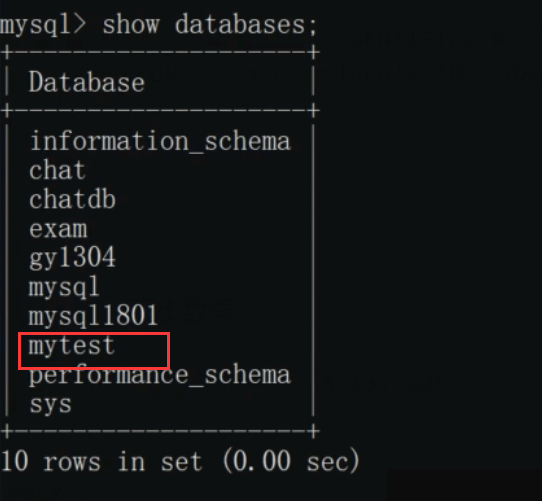
master创建了user表,slave也同步了user表:


现在linux端的MySQL(master)删除mytest库
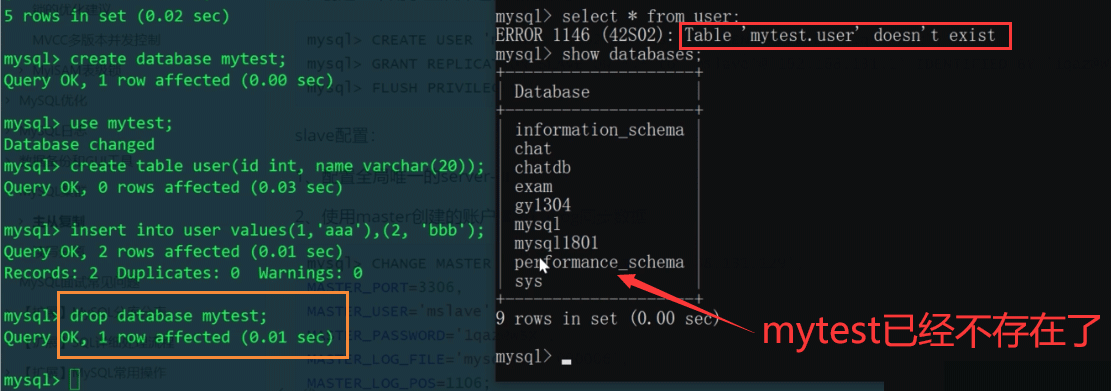
此时slave的mytest也不存在了
show processlistIO-Thread
Dump-Thread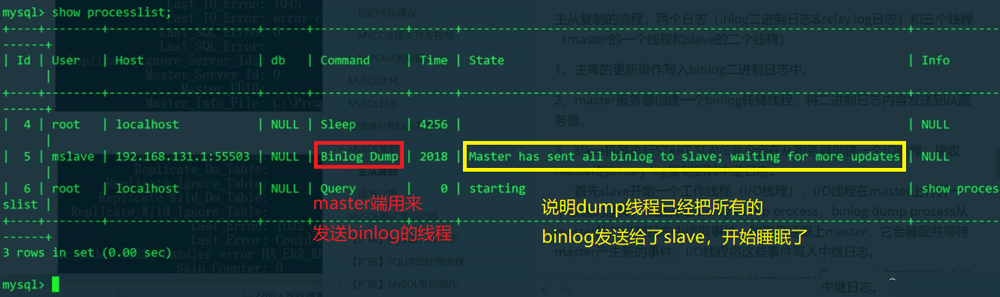 . Der Dump-Thread liest Ereignisse aus dem Binlog des Masters sie an den E/A-Thread des Slaves, wenn der Dump-Thread den Master eingeholt hat (der Dump-Thread in der Hauptbibliothek hat das Senden des Inhalts des Binlogs abgeschlossen und das Binlog in der Hauptbibliothek hat keinen weiteren Inhalt generiert). , der Dump-Thread schläft und wartet darauf, dass das Binlog neue Ereignisse generiert. Die vom E/A-Thread empfangenen Ereignisse werden in das Relay-Protokoll geschrieben. Der
. Der Dump-Thread liest Ereignisse aus dem Binlog des Masters sie an den E/A-Thread des Slaves, wenn der Dump-Thread den Master eingeholt hat (der Dump-Thread in der Hauptbibliothek hat das Senden des Inhalts des Binlogs abgeschlossen und das Binlog in der Hauptbibliothek hat keinen weiteren Inhalt generiert). , der Dump-Thread schläft und wartet darauf, dass das Binlog neue Ereignisse generiert. Die vom E/A-Thread empfangenen Ereignisse werden in das Relay-Protokoll geschrieben. Der
des Slaves übernimmt den letzten Schritt des Prozesses Der SQL-Thread liest Ereignisse aus dem Relay-Protokoll und führt die darin enthaltenen Ereignisse aus, um die Daten des Slaves zu aktualisieren und mit den Daten des Masters zu synchronisieren. Solange der SQL-Thread mit dem E/A-Thread konsistent ist, befindet sich das Relay-Protokoll normalerweise im Betriebssystem-Cache, sodass der Overhead des Relay-Protokolls sehr gering ist
Centos unter Linux als Hauptbibliothek und MySQL-Server unter Win10 als Slave-Bibliothek werden demonstriert: 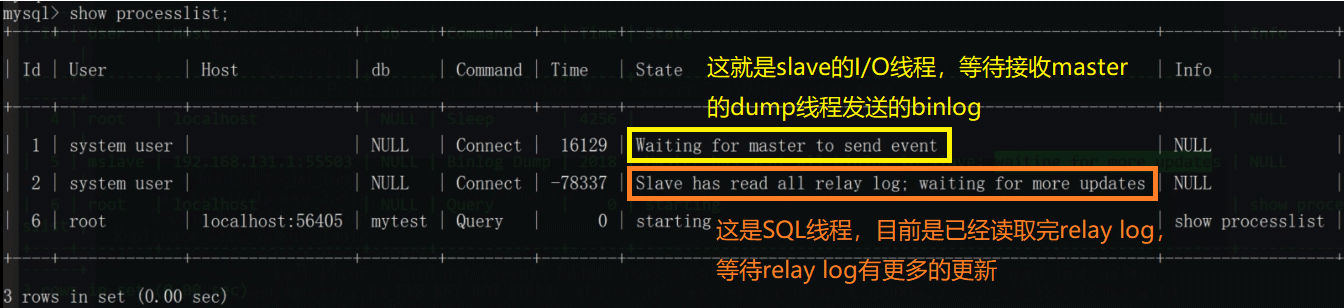
🎜🎜🎜Master hat die Benutzertabelle erstellt und Slave hat auch die Benutzertabelle synchronisiert: 🎜🎜🎜 🎜🎜
🎜🎜 🎜🎜🎜 Zu diesem Zeitpunkt existiert der Mytest des Slaves nicht mehr. 🎜🎜🎜
🎜🎜🎜 Zu diesem Zeitpunkt existiert der Mytest des Slaves nicht mehr. 🎜🎜🎜 prozessliste anzeigen code>Sie können die Arbeitsthreads in der aktuellen Umgebung des Masters anzeigen der Sklave🎜🎜🎜🎜🎜Das obige ist der detaillierte Inhalt vonWas ist das Prinzip der Master-Slave-Replikation in MySQL?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 MySQL ändert den Namen der Datentabelle
MySQL ändert den Namen der Datentabelle
 MySQL erstellt eine gespeicherte Prozedur
MySQL erstellt eine gespeicherte Prozedur
 Der Unterschied zwischen Mongodb und MySQL
Der Unterschied zwischen Mongodb und MySQL
 So überprüfen Sie, ob das MySQL-Passwort vergessen wurde
So überprüfen Sie, ob das MySQL-Passwort vergessen wurde
 MySQL-Datenbank erstellen
MySQL-Datenbank erstellen
 MySQL-Standard-Transaktionsisolationsstufe
MySQL-Standard-Transaktionsisolationsstufe
 Der Unterschied zwischen SQL Server und MySQL
Der Unterschied zwischen SQL Server und MySQL
 mysqlPasswort vergessen
mysqlPasswort vergessen








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



