

Beispielanalyse des Redis-Caching-Problems

1. Anwendung des Redis-Cache
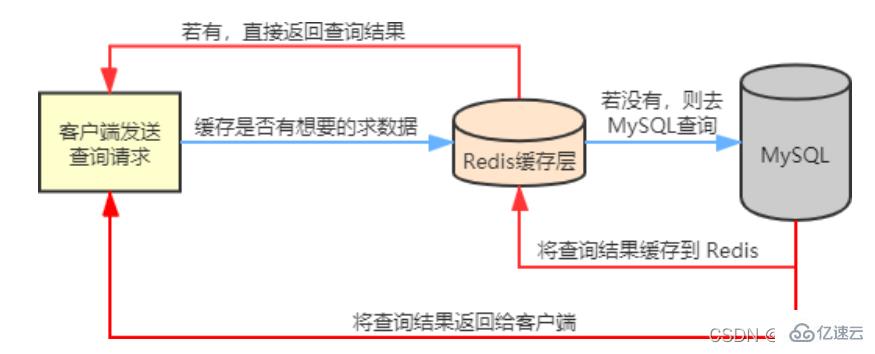
In unseren tatsächlichen Geschäftsszenarien wird Redis im Allgemeinen in Verbindung mit anderen Datenbanken verwendet, um den Druck auf das Back-End zu verringern Datenbank, wie sie beispielsweise in Verbindung mit der relationalen Datenbank MySQL verwendet wird.
Redis speichert häufig abgefragte Daten in MySQL , z. B. Hotspot-Daten, zwischen, sodass beim Zugriff durch Benutzer keine Notwendigkeit besteht Stattdessen werden die zwischengespeicherten Daten in Redis direkt abgerufen, wodurch der Lesedruck auf die Back-End-Datenbank verringert wird.
Wenn die vom Benutzer abgefragten Daten in Redis nicht verfügbar sind, wird die Abfrageanforderung des Benutzers an die MySQL-Datenbank übertragen, wenn MySQL die Daten an den Client zurückgibt Daten gleichzeitig in Redis, sodass Benutzer beim erneuten Lesen Daten direkt von Redis erhalten können. Das Flussdiagramm lautet wie folgt:
2.2 LösungBei der Verwendung von Redis als Cache-Datenbank werden wir unweigerlich mit drei gemeinsamen Cachings konfrontiert Probleme 🎜#Cache-Aufschlüsselung
Cache-Lawine
- #🎜 🎜 #
2. Cache-Penetration
2.1 EinführungCache-Penetration bezieht sich darauf, wann der Benutzer ein bestimmtes Wann abfragt Die Daten werden abgerufen, die Daten sind nicht in Redis vorhanden, das heißt, der Cache wird nicht erreicht. Zu diesem Zeitpunkt wird die Abfrageanforderung an die Persistenzschichtdatenbank MySQL übertragen , und MySQL kann nur ein leeres Objekt zurückgeben, um den Abfragefehler darzustellen. Wenn es viele solcher Anfragen gibt oder Benutzer solche Anfragen für böswillige Angriffe verwenden, wird die MySQL-Datenbank stark belastet und sogar zusammengebrochen. Dieses Phänomen wird als Cache-Penetration bezeichnet.
Leeres Objekt zwischenspeichernleeres Objekt# 🎜🎜#Wenn MySQL ein leeres Objekt zurückgibt, speichert Redis das Objekt im Cache und legt eine Ablaufzeit dafür fest.
Wenn der Benutzer dieselbe Anfrage erneut initiiert, erhält er ein
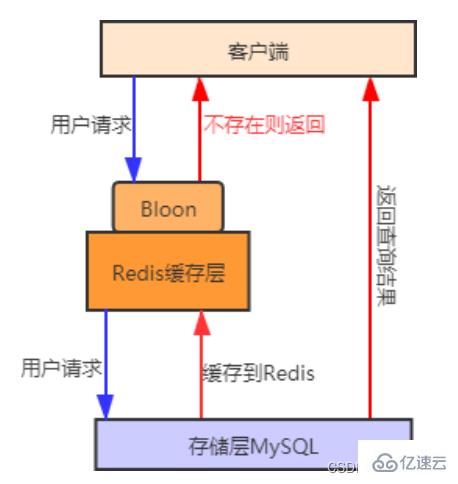
aus dem Cache. Die Anfrage des Benutzers wird in der Cache-Ebene blockiert, wodurch die Back-End-Datenbank geschützt wird Bei diesem Ansatz gibt es auch einige Probleme. Obwohl die Anforderung nicht in MSQL gelangen kann, belegt diese Strategie 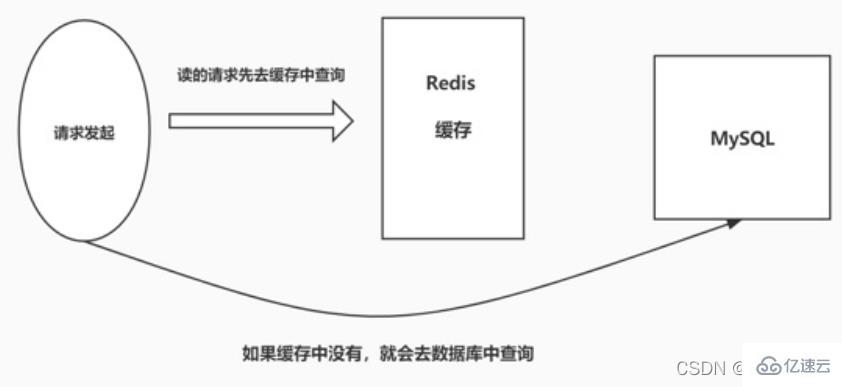 Redis-Cache-Speicherplatz. #? der Hotspot-Daten, auf die Benutzer zugreifen können, werden in Bloom-Filtern gespeichert (auch Cache-Vorwärmung genannt).
Redis-Cache-Speicherplatz. #? der Hotspot-Daten, auf die Benutzer zugreifen können, werden in Bloom-Filtern gespeichert (auch Cache-Vorwärmung genannt).
Wenn er nicht vorhanden ist, wird die Anfrage weiterhin ausgeführt. Wenn der Cache nicht vorhanden ist, gehen Sie zu die abzufragende Datenbank. Im Vergleich zur ersten Methode ist die Verwendung der
Bloom-Filtermethode effizienter und praktischer.Das Prozessdiagramm sieht wie folgt aus:
Bei der Cache-Vorwärmung werden relevante Daten vorab zwischengespeichert Das System startet den Ladevorgang in das Redis-Cache-System. Dadurch wird vermieden, dass Daten geladen werden, wenn der Benutzer sie anfordert.
2.3 Vergleich der Lösungen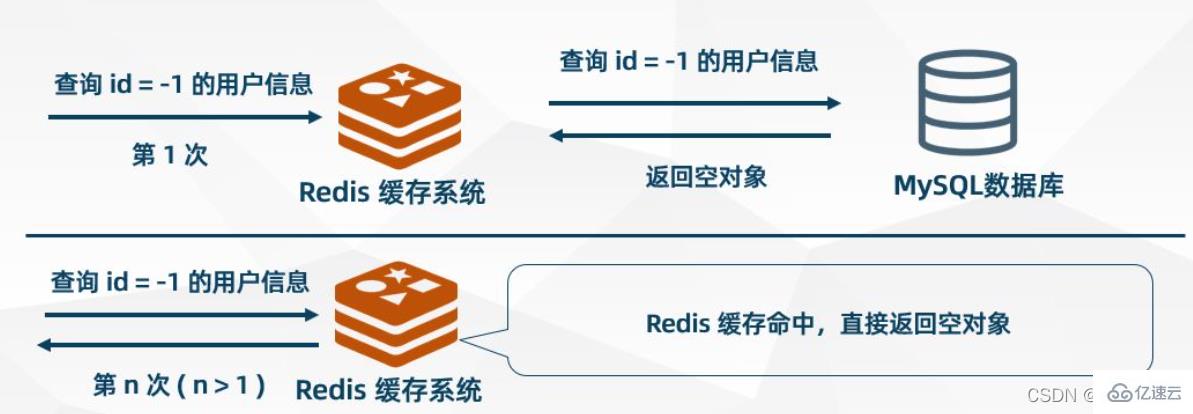
Leere Objekte zwischenspeichern: Geeignet für Szenarien, in denen die Anzahl der Schlüssel für leere Daten begrenzt ist und die Wahrscheinlichkeit wiederholter Schlüsselanforderungen hoch ist. Bloom-Filter: Geeignet für Szenarien, in denen die Schlüssel leerer Daten unterschiedlich sind und die Wahrscheinlichkeit wiederholter Schlüsselanforderungen gering ist. 3. Cache-Aufschlüsselung dass die vom Benutzer abgefragten Daten nicht im Cache vorhanden sind, sondern in der Back-End-Datenbank. Der Grund für dieses Phänomen liegt im Allgemeinen im Ablauf des Schlüssels im Cache. Beispielsweise erhält ein Hot-Data-Schlüssel ständig eine große Anzahl gleichzeitiger Zugriffe. Wenn der Schlüssel zu einem bestimmten Zeitpunkt plötzlich ausfällt, gelangen viele gleichzeitige Anforderungen in die Back-End-Datenbank, wodurch der Druck sofort zunimmt. Dieses Phänomen wird als Cache-Zusammenbruch bezeichnet.
 3.2 Lösung
3.2 Lösung
Ablaufzeit ändern
Hotspot-Daten so einstellen, dass sie niemals ablaufen.
Verteilte Sperre
Übernehmen Sie die verteilte Sperrmethode, um die Verwendung des Caches neu zu gestalten. Der Prozess ist wie folgt:
Sperre: Wenn wir Daten nach Schlüssel abfragen, fragen wir zuerst den Cache ab. Wenn nicht, sperren Sie es über eine verteilte Sperre. Der erste Prozess, der die Sperre erhält, betritt die Back-End-Datenbank zur Abfrage und puffert die Abfrageergebnisse in Redis.
Entsperren: Wenn andere Prozesse feststellen, dass die Sperre von einem bestimmten Prozess belegt ist, wechseln sie in den Wartezustand. Nach dem Entsperren greifen andere Prozesse nacheinander auf den zwischengespeicherten Schlüssel zu.
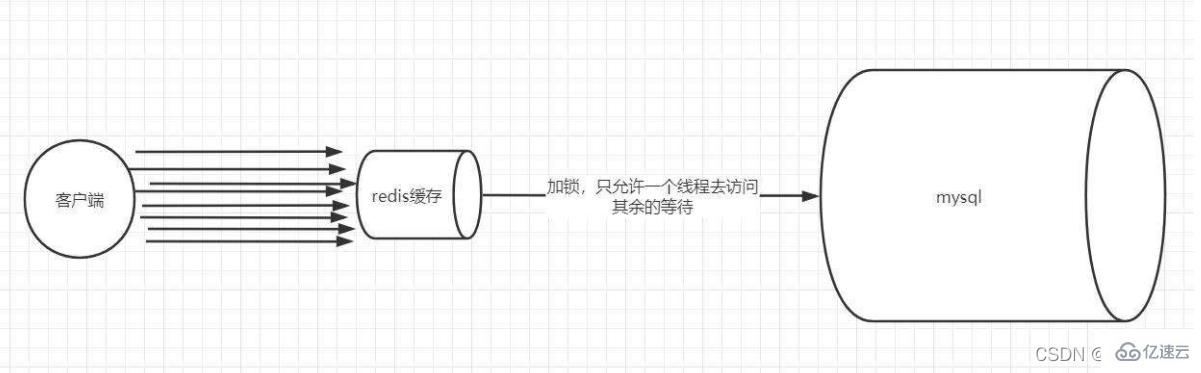
3.3 Vergleich der Lösungen
Läuft nie ab: Da diese Lösung keine echte Ablaufzeit festlegt, gibt es eigentlich keine Reihe von Gefahren durch Hotspot-Schlüssel, aber es kommt zu Dateninkonsistenzen und Die Codekomplexität wird zunehmen.
Mutex-Sperre: Die Idee dieser Lösung ist relativ einfach, aber es gibt bestimmte versteckte Gefahren. Wenn beim Cache-Erstellungsprozess ein Problem auftritt oder er lange dauert, besteht möglicherweise die Gefahr eines Deadlocks Thread-Pool-Blockierung, aber diese Methode kann effizienter sein. Eine gute Methode reduziert die Back-End-Speicherlast und sorgt für eine bessere Konsistenz.
4. Cache-Lawine
4.1 Einführung
Cache-Lawine bedeutet, dass eine große Anzahl von Schlüsseln im Cache gleichzeitig abläuft und zu diesem Zeitpunkt der Datenzugriff sehr groß ist, was zu einem Plötzlicher Druckanstieg auf die Back-End-Datenbank und sogar Hang, dieses Phänomen wird als Cache-Lawine bezeichnet. Es unterscheidet sich von einem Cache-Ausfall, wenn ein bestimmter Hotkey plötzlich abläuft, wenn die Parallelität besonders groß ist, während eine Cache-Lawine auftritt, wenn eine große Anzahl von Schlüsseln gleichzeitig abläuft, sodass sie nicht in derselben Reihenfolge sind überhaupt von der Größenordnung.
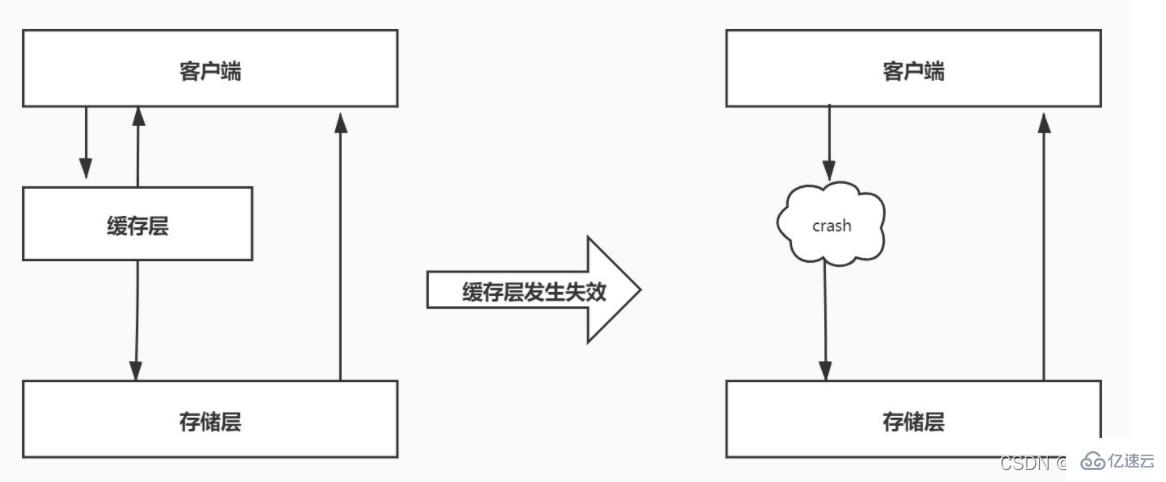
4.2 Lösung
Umgang mit dem Ablauf
Um Cache-Ausfälle und Lawinenprobleme zu reduzieren, die durch eine große Anzahl gleichzeitig ablaufender Schlüssel verursacht werden, können Sie die Strategie anwenden, dass Hotspot-Daten niemals ablaufen Ablauf, was sich von Cache Avalanche unterscheidet Es gibt Ähnlichkeiten. Um zu verhindern, dass Schlüssel gleichzeitig ablaufen, können Sie außerdem eine zufällige Ablaufzeit für sie festlegen.
redis hohe Verfügbarkeit
Ein Redis kann aufgrund einer Lawine hängen bleiben, dann können Sie ein paar weitere Redis hinzufügen und einen Cluster aufbauen.
Das obige ist der detaillierte Inhalt vonBeispielanalyse des Redis-Caching-Problems. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 So erstellen Sie den Redis -Clustermodus
Apr 10, 2025 pm 10:15 PM
So erstellen Sie den Redis -Clustermodus
Apr 10, 2025 pm 10:15 PM
Der Redis -Cluster -Modus bietet Redis -Instanzen durch Sharding, die Skalierbarkeit und Verfügbarkeit verbessert. Die Bauschritte sind wie folgt: Erstellen Sie ungerade Redis -Instanzen mit verschiedenen Ports; Erstellen Sie 3 Sentinel -Instanzen, Monitor -Redis -Instanzen und Failover; Konfigurieren von Sentinel -Konfigurationsdateien, Informationen zur Überwachung von Redis -Instanzinformationen und Failover -Einstellungen hinzufügen. Konfigurieren von Redis -Instanzkonfigurationsdateien, aktivieren Sie den Cluster -Modus und geben Sie den Cluster -Informationsdateipfad an. Erstellen Sie die Datei nodes.conf, die Informationen zu jeder Redis -Instanz enthält. Starten Sie den Cluster, führen Sie den Befehl erstellen aus, um einen Cluster zu erstellen und die Anzahl der Replikate anzugeben. Melden Sie sich im Cluster an, um den Befehl cluster info auszuführen, um den Clusterstatus zu überprüfen. machen
 So implementieren Sie die zugrunde liegenden Redis
Apr 10, 2025 pm 07:21 PM
So implementieren Sie die zugrunde liegenden Redis
Apr 10, 2025 pm 07:21 PM
Redis verwendet Hash -Tabellen, um Daten zu speichern und unterstützt Datenstrukturen wie Zeichenfolgen, Listen, Hash -Tabellen, Sammlungen und geordnete Sammlungen. Ernähren sich weiterhin über Daten über Snapshots (RDB) und appendiert Mechanismen nur Schreibmechanismen. Redis verwendet die Master-Slave-Replikation, um die Datenverfügbarkeit zu verbessern. Redis verwendet eine Ereignisschleife mit einer Thread, um Verbindungen und Befehle zu verarbeiten, um die Datenatomizität und Konsistenz zu gewährleisten. Redis legt die Ablaufzeit für den Schlüssel fest und verwendet den faulen Löschmechanismus, um den Ablaufschlüssel zu löschen.
 Was tun, wenn Redis-Server nicht gefunden werden kann
Apr 10, 2025 pm 06:54 PM
Was tun, wenn Redis-Server nicht gefunden werden kann
Apr 10, 2025 pm 06:54 PM
Schritte zur Lösung des Problems, das Redis-Server nicht finden kann: Überprüfen Sie die Installation, um sicherzustellen, dass Redis korrekt installiert ist. Setzen Sie die Umgebungsvariablen Redis_host und Redis_port; Starten Sie den Redis-Server Redis-Server; Überprüfen Sie, ob der Server Redis-Cli Ping ausführt.
 So sehen Sie alle Schlüssel in Redis
Apr 10, 2025 pm 07:15 PM
So sehen Sie alle Schlüssel in Redis
Apr 10, 2025 pm 07:15 PM
Um alle Schlüssel in Redis anzuzeigen, gibt es drei Möglichkeiten: Verwenden Sie den Befehl keys, um alle Schlüssel zurückzugeben, die dem angegebenen Muster übereinstimmen. Verwenden Sie den Befehl scan, um über die Schlüssel zu iterieren und eine Reihe von Schlüssel zurückzugeben. Verwenden Sie den Befehl Info, um die Gesamtzahl der Schlüssel zu erhalten.
 So sehen Sie die Versionsnummer der Redis
Apr 10, 2025 pm 05:57 PM
So sehen Sie die Versionsnummer der Redis
Apr 10, 2025 pm 05:57 PM
Um die Redis -Versionsnummer anzuzeigen, können Sie die folgenden drei Methoden verwenden: (1) Geben Sie den Info -Befehl ein, (2) Starten Sie den Server mit der Option --version und (3) die Konfigurationsdatei anzeigen.
 So lesen Sie den Quellcode von Redis
Apr 10, 2025 pm 08:27 PM
So lesen Sie den Quellcode von Redis
Apr 10, 2025 pm 08:27 PM
Der beste Weg, um Redis -Quellcode zu verstehen, besteht darin, Schritt für Schritt zu gehen: Machen Sie sich mit den Grundlagen von Redis vertraut. Wählen Sie ein bestimmtes Modul oder eine bestimmte Funktion als Ausgangspunkt. Beginnen Sie mit dem Einstiegspunkt des Moduls oder der Funktion und sehen Sie sich die Codezeile nach Zeile an. Zeigen Sie den Code über die Funktionsaufrufkette an. Kennen Sie die von Redis verwendeten Datenstrukturen. Identifizieren Sie den von Redis verwendeten Algorithmus.
 So verwenden Sie den Befehl Redis
Apr 10, 2025 pm 08:45 PM
So verwenden Sie den Befehl Redis
Apr 10, 2025 pm 08:45 PM
Die Verwendung der REDIS -Anweisung erfordert die folgenden Schritte: Öffnen Sie den Redis -Client. Geben Sie den Befehl ein (Verbschlüsselwert). Bietet die erforderlichen Parameter (variiert von der Anweisung bis zur Anweisung). Drücken Sie die Eingabetaste, um den Befehl auszuführen. Redis gibt eine Antwort zurück, die das Ergebnis der Operation anzeigt (normalerweise in Ordnung oder -err).
 So verwenden Sie Redis Zset
Apr 10, 2025 pm 07:27 PM
So verwenden Sie Redis Zset
Apr 10, 2025 pm 07:27 PM
Redis bestellte Sets (ZSETs) werden verwendet, um bestellte Elemente und Sortieren nach zugehörigen Bewertungen zu speichern. Die Schritte zur Verwendung von ZSET umfassen: 1. Erstellen Sie ein Zset; 2. Fügen Sie ein Mitglied hinzu; 3.. Holen Sie sich eine Mitgliederbewertung; 4. Holen Sie sich eine Rangliste; 5. Holen Sie sich ein Mitglied in der Rangliste; 6. Ein Mitglied löschen; 7. Holen Sie sich die Anzahl der Elemente; 8. Holen Sie sich die Anzahl der Mitglieder im Score -Bereich.
