

Was sind die gängigen Möglichkeiten, Redis zu verwenden?

1. Zu den gängigen Verwendungsmethoden von Redis gehören:
1. Redis-Mehrfachkopien (Master-Slave);
4 .Redis-Cluster;
5.Redis selbst entwickelt.
2. Vor- und Nachteile verschiedener Verwendungsmethoden
Redis-Einzelkopie verwendet eine einzelne Redis-Knoten-Bereitstellungsarchitektur. Es gibt keinen Sicherungsknoten zum Synchronisieren von Daten in Echtzeit und bietet keine Datenpersistenz und -sicherung Es eignet sich für reine Daten-Caching-Geschäftsszenarien mit geringen Zuverlässigkeitsanforderungen.
Vorteile:
Einfache Architektur und einfache Bereitstellung;
Hohe Kostenleistung: Bei Verwendung des Caches ist kein Backup-Knoten erforderlich (die Verfügbarkeit einzelner Instanzen kann natürlich durch Supervisor oder Crontab garantiert werden). Aufgrund der hohen Verfügbarkeit des Unternehmens kann auch ein Backup-Knoten geopfert werden, aber nur eine Instanz stellt gleichzeitig externe Dienste bereit. 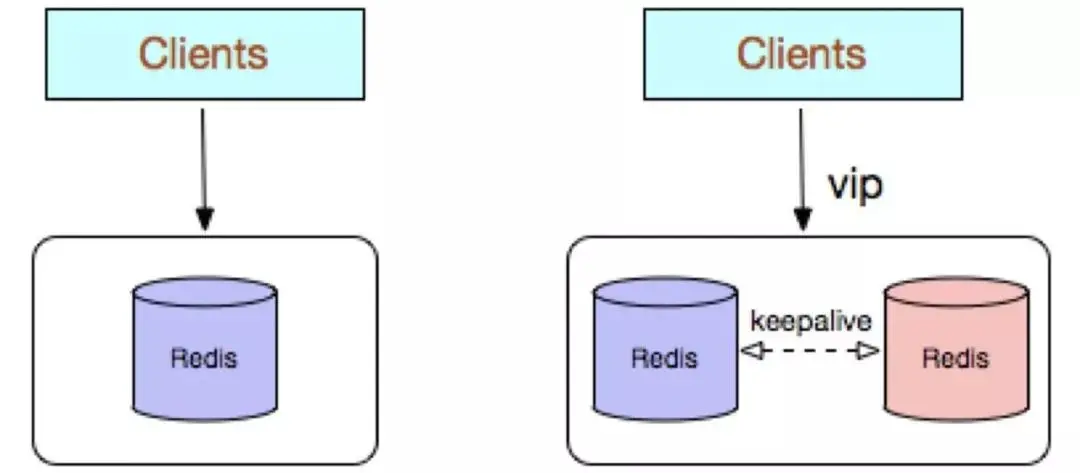
Hohe Leistung.
Nachteile:
Garantiert nicht die Zuverlässigkeit der Daten.
Nachdem der Cache verwendet und der Prozess neu gestartet wurde, gehen Daten verloren. Auch wenn Backup-Knoten zur Lösung der Hochverfügbarkeit vorhanden sind, kann das Problem der Cache-Vorwärmung immer noch nicht gelöst werden Daher ist es nicht für Unternehmen mit hohen Leistungsanforderungen geeignet.
Hohe Leistung wird durch die Verarbeitungsleistung einer Single-Core-CPU begrenzt (Redis ist ein Single-Thread-Mechanismus), und die CPU ist der Hauptengpass. Daher eignet es sich für Szenarien mit einfachen Bedienbefehlen und weniger Sortieren und Berechnen. Sie können stattdessen auch die Verwendung von Memcached in Betracht ziehen.
2. Redis-Mehrfachkopie (Master-Slave)
Redis-Mehrfachkopie verwendet eine Master-Slave-Bereitstellungsstruktur (Replikation). Das größte Merkmal ist die Echtzeit-Datensynchronisierung zwischen Master- und Slave-Instanzen Datenpersistenz und Backup-Strategien. Die grundlegende Umgebungskonfiguration des Unternehmens ermöglicht die Bereitstellung von Master-Slave-Instanzen auf verschiedenen physischen Servern, um eine gleichzeitige Bereitstellung externer Dienste und Strategien zur Lese-/Schreibtrennung zu erreichen.
Vorteile:
Hohe Zuverlässigkeit: Einerseits wird eine Aktiv-Standby-Architektur mit zwei Maschinen verwendet, die automatisch zwischen Aktiv und Standby wechseln kann, wenn die Hauptdatenbank ausfällt und zur Slave-Datenbank heraufgestuft wird Bereitstellung von Diensten für die Hauptdatenbank, um einen reibungslosen Betrieb des Dienstes zu gewährleisten. Andererseits können durch die Aktivierung der Datenpersistenzfunktion und die Konfiguration einer angemessenen Sicherungsstrategie die Probleme von Datenfehlfunktionen und abnormalem Datenverlust wirksam gelöst werden Trennungsstrategie: Der Slave-Knoten kann die Lesekapazität des Hauptdatenbankknotens erweitern und so große gleichzeitige Lesevorgänge effektiv bewältigen.
Nachteile: 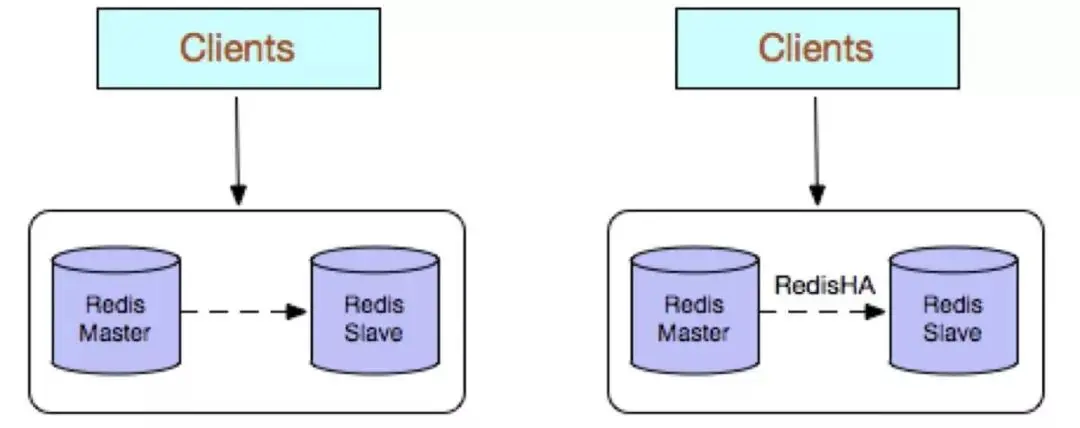
Wenn kein RedisHA-System vorhanden ist (Entwicklung erforderlich), muss bei einem Ausfall des Hauptdatenbankknotens manuell ein Slave-Knoten zum Master-Knoten hochgestuft werden Um die Konfiguration zu ändern, müssen Sie benachrichtigt werden, und andere Slaves müssen den neuen Hauptbibliotheksknoten replizieren. Der gesamte Prozess erfordert menschliches Eingreifen und ist relativ umständlich
Die Speicherkapazität der Hauptbibliothek ist durch eine einzelne Maschine begrenzt, sodass Pika in Betracht gezogen werden kann.
Die Nachteile der nativen Replikation werden in früheren Versionen auch stärker ausgeprägt sein Die Redis-Replikation wird unterbrochen. Wenn die Synchronisierung zu diesem Zeitpunkt fehlschlägt, führt die Hauptbibliothek möglicherweise gleichzeitig eine vollständige Sicherung durch Der COW-Mechanismus führt im Extremfall dazu, dass der Hauptbibliotheksspeicher überläuft und das Programm abnormal beendet wird oder abstürzt. Der Hauptbibliotheksknoten generiert Sicherungsdateien, was zu einem Ressourcenverbrauch der Serverfestplatte führt Mehrere GB führen zu einem drastischen Anstieg der Ausgangsbandbreite des Servers und blockieren Anfragen. Es wird empfohlen, auf die neueste Version zu aktualisieren.
3. Redis Sentinel (Sentinel)
Redis Sentinel ist eine native Hochverfügbarkeitslösung, die in der Community-Version eingeführt wurde. Die Bereitstellungsarchitektur besteht hauptsächlich aus zwei Teilen: dem Redis Sentinel-Cluster und dem Redis-Datencluster.
Der Redis Sentinel-Cluster ist ein verteilter Cluster, der aus mehreren Sentinel-Knoten besteht und Fehlererkennung, automatisches Failover, Konfigurationscenter und Clientbenachrichtigung realisieren kann. Die Anzahl der Knoten, die Redis Sentinel erfüllen, muss eine ungerade Zahl sein und die Zahl ist 2n+1 (n≥1).
Vorteile:
Die Bereitstellung von Redis Sentinel-Clustern ist einfach Datenknoten und Redis können leicht durchbrochen werden. Der eigene Single-Thread-Engpass kann die Geschäftsanforderungen von Redis mit großer Kapazität oder hoher Leistung erheblich erfüllen Knoten.
Nachteile: 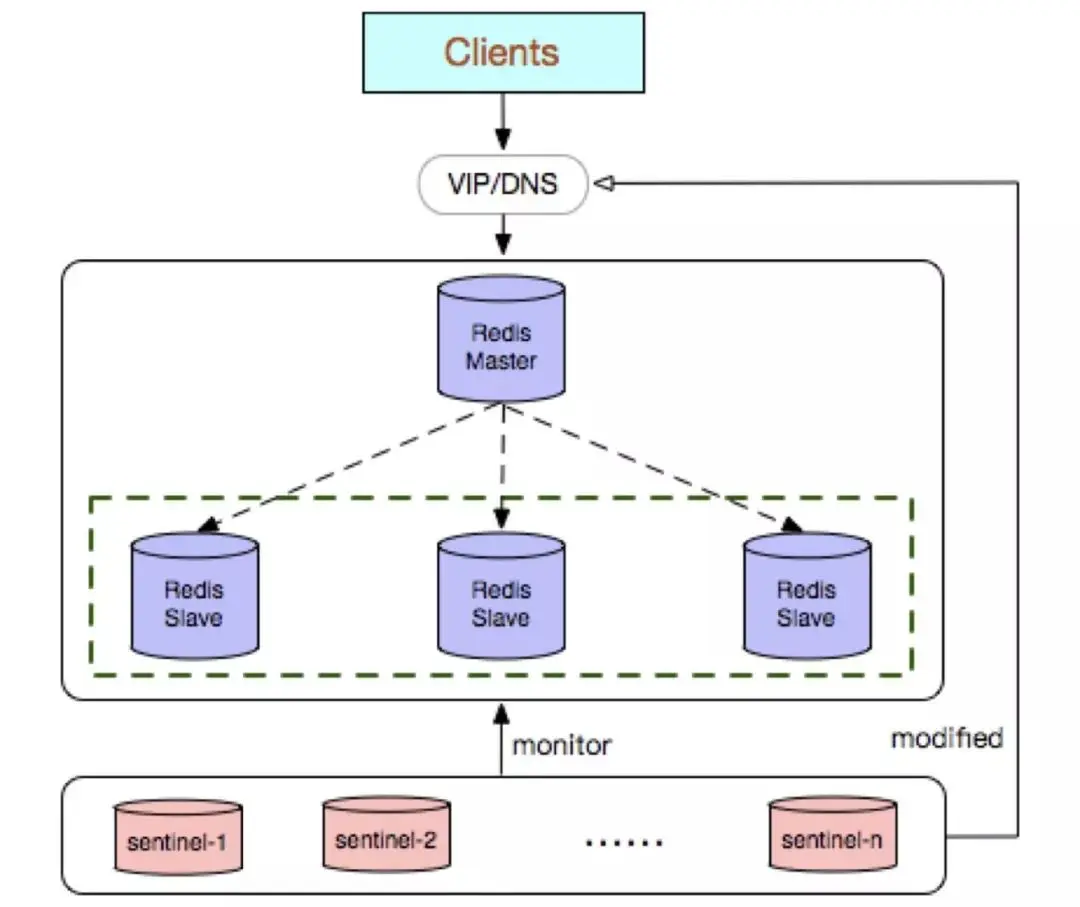
Die Bereitstellung ist komplizierter als im Redis-Master-Slave-Modus und das Prinzip ist umständlicher.
Eine Verschwendung von Ressourcen. Der Slave-Knoten im Redis-Datenknoten dient nicht als Sicherungsknoten Bereitstellung von Diensten; 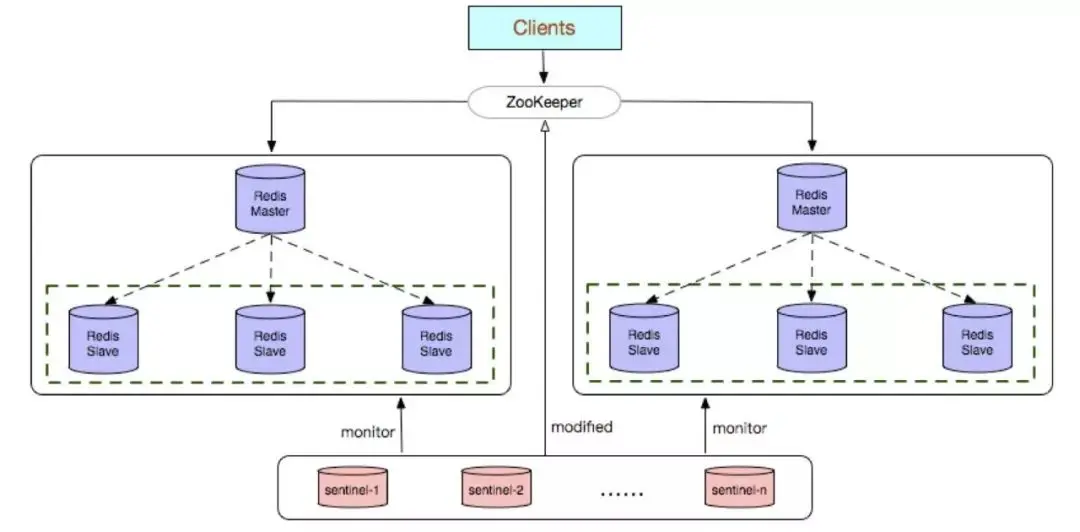
Redis Sentinel ist hauptsächlich für den Redis-Datenknoten gedacht. Für die Hochverfügbarkeitsvermittlung des Redis-Datenknotens wird die Fehlerbestimmung des Redis-Datenknotens in zwei Typen unterteilt: subjektiv offline und objektiv offline Für den Redis-Slave-Knoten. Der Knoten ist subjektiv offline und es wird kein Failover durchgeführt.
Es kann das Problem der Lese- und Schreibtrennung nicht lösen und ist relativ kompliziert zu implementieren.
Empfehlung:
Wenn Sie dasselbe Unternehmen überwachen, können Sie einen Sentinel-Cluster zur Überwachung mehrerer Gruppen von Redis-Datenknoten auswählen. Andernfalls wählen Sie einen Sentinel-Cluster zur Überwachung einer Gruppe von Redis-Datenknoten.
Die empfohlene Einstellung in der Sentinel-Monitorkonfiguration ist die Hälfte der Sentinel-Knoten plus 1. Wenn Sentinel in mehreren IDCs bereitgestellt wird, wird empfohlen, die Anzahl der in einem einzelnen IDC bereitgestellten Sentinels nicht zu überschreiten (Sentinel-Anzahl – Quorum).
Stellen Sie die Parameter angemessen ein, um ein versehentliches Ausschalten zu verhindern und die Empfindlichkeitskontrolle zu steuern:
b. Ausfallzeit nach Millisekunden
d Die Serverzeit jedes bereitgestellten Knotens muss so weit wie möglich synchronisiert werden, da sonst das Timing der Protokolle verwirrt wird.
Redis empfiehlt die Verwendung von Pipeline- und Multi-Key-Operationen, um die Anzahl der RTTs zu reduzieren und die Anforderungseffizienz zu verbessern.
Konfigurieren Sie das Konfigurationscenter (Zookeeper) selbst, um den Clientzugriff auf den Instanzlink zu erleichtern.
4. Redis-Cluster ist eine verteilte Redis-Cluster-Lösung, die hauptsächlich die Anforderungen der Redis-Verteilung löst, z. B. bei Engpässen wie Einzelmaschinenspeicher, Parallelität und Datenverkehr Kann Es dient dem Zweck einer guten Lastverteilung.
Die Mindestkonfiguration des Redis-Cluster-Clusterknotens beträgt mehr als 6 Knoten (3 Master und 3 Slaves). Der Masterknoten stellt Lese- und Schreibvorgänge bereit, und der Slave-Knoten dient als Backup-Knoten und stellt keine Anforderungen bereit Wird nur für Failover verwendet.
Redis-Cluster verwendet die virtuelle Slot-Partitionierung. Alle Schlüssel werden gemäß der Hash-Funktion auf 0 bis 16383 Integer-Slots abgebildet. Jeder Knoten ist für die Verwaltung eines Teils der Slots und der durch die Slots zugeordneten Schlüsselwertdaten verantwortlich.
Vorteile:
Keine zentrale Architektur;
Daten werden je nach Slots in mehreren Knoten gespeichert und verteilt, Daten werden zwischen Knoten geteilt und die Datenverteilung kann dynamisch angepasst werden;
Skalierbarkeit: linear erweiterbar auf mehr Mehr als 1.000 Knoten können dynamisch hinzugefügt oder gelöscht werden. 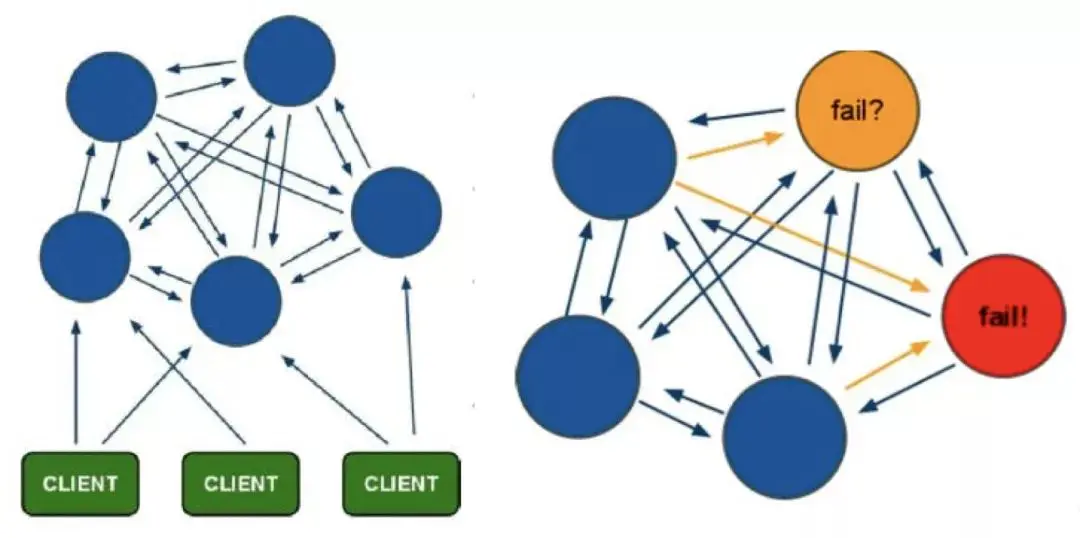
Hohe Verfügbarkeit: Wenn einige Knoten nicht verfügbar sind, ist der Cluster weiterhin verfügbar. Durch das Hinzufügen von Slave als Standby-Datenkopie kann ein automatischer Failover erreicht werden, der Statusinformationen über das Gossip-Protokoll austauscht und den Abstimmungsmechanismus verwendet, um die Rollenförderung vom Slave zum Master abzuschließen.
Reduzieren Sie die Betriebs- und Wartungskosten und verbessern Sie die Skalierbarkeit und Verfügbarkeit des Systems.
Nachteile:
Die Client-Implementierung ist komplex, und der Treiber erfordert die Implementierung von Smart Client, das Zwischenspeichern und rechtzeitige Aktualisieren von Slot-Mapping-Informationen, was die Schwierigkeit der Entwicklung erhöht. Die Unreife des Clients wirkt sich auf die Stabilität des Unternehmens aus. Derzeit ist nur JedisCluster relativ ausgereift und der Ausnahmebehandlungsteil ist noch nicht perfekt, wie beispielsweise die übliche „Max Redirect-Ausnahme“.
Der Knoten wird aus bestimmten Gründen blockiert (die Blockierungszeit ist länger als das Clutser-Node-Timeout) und wird als offline eingestuft. Diese Art von Failover ist nicht erforderlich.
Daten werden asynchron kopiert und eine starke Datenkonsistenz ist nicht garantiert.
Wenn mehrere Unternehmen denselben Cluster verwenden, ist es unmöglich, heiße und kalte Daten anhand von Statistiken zu unterscheiden. Die Ressourcenisolierung ist schlecht und es kann leicht zu gegenseitiger Beeinflussung kommen.
Slave fungiert als „Cold Standby“ im Cluster und kann den Lesedruck nicht abbauen. Natürlich kann die Nutzung der Slave-Ressourcen durch das sinnvolle Design des SDK verbessert werden.
Einschränkungen für Schlüssel-Batch-Operationen, wie z. B. die Verwendung von mset und mget, unterstützen derzeit nur Schlüssel mit demselben Slot-Wert, um Batch-Operationen durchzuführen. Für Schlüssel, die unterschiedlichen Slot-Werten zugeordnet sind, ist es nicht benutzerfreundlich, Vorgänge wie mset, mget und sunion auszuführen, da Keys keine Slot-übergreifende Abfrage unterstützt.
Die Unterstützung für Schlüsseltransaktionsvorgänge ist begrenzt. Es werden nur Transaktionsvorgänge für mehrere Schlüssel auf demselben Knoten unterstützt. Wenn mehrere Schlüssel auf verschiedene Knoten verteilt sind, kann die Transaktionsfunktion nicht verwendet werden.
Daten, die große Schlüsselwertobjekte (wie Hash, Liste usw.) enthalten, können nicht verschiedenen Knoten zugeordnet werden, da bei der Datenpartitionierung der Schlüssel die kleinste Granularität aufweist.
Mehrere Datenbankbereiche werden im Standalone-Modus nicht unterstützt. Im Clustermodus kann nur 1 Datenbankbereich verwendet werden.
Die Replikationsstruktur unterstützt nur eine Ebene. Der Slave-Knoten kann nur den Master-Knoten replizieren, und die verschachtelte Baum-Replikationsstruktur wird nicht unterstützt.
Vermeiden Sie die Generierung von Hotkeys, da sonst der Hauptbibliotheksknoten zu einer Schwachstelle des Systems wird.
Vermeiden Sie die Generierung großer Schlüssel, da dies zu einer Überlastung der Netzwerkkarte, langsamen Abfragen usw. führen kann.
Die Wiederholungszeit sollte größer sein als die Clusterknotenzeit.
Redis Cluster empfiehlt nicht, Pipeline- und Multi-Key-Vorgänge zu verwenden, um maximale Umleitungsszenarien zu reduzieren.
Teilen Sie einen Interviewleitfaden „Java Core Knowledge Points Compilation.pdf“ mit den Themen JVM, Sperren, hohe Parallelität, Reflexion, Spring-Prinzipien, Microservices, Zookeeper, Datenbank, Datenstruktur usw. sowie Java208-Interviewfragen (einschließlich). Antworten) können Sie kostenlos erhalten, indem Sie sich anmelden (Java Advanced Architecture) 705127209!
5. Redis selbst entwickelte
Die selbst entwickelte Hochverfügbarkeitslösung spiegelt sich hauptsächlich im Konfigurationscenter, in den Fehlererkennungs- und Failover-Verarbeitungsmechanismen wider, die normalerweise an die tatsächliche Online-Umgebung des Unternehmens angepasst werden müssen .
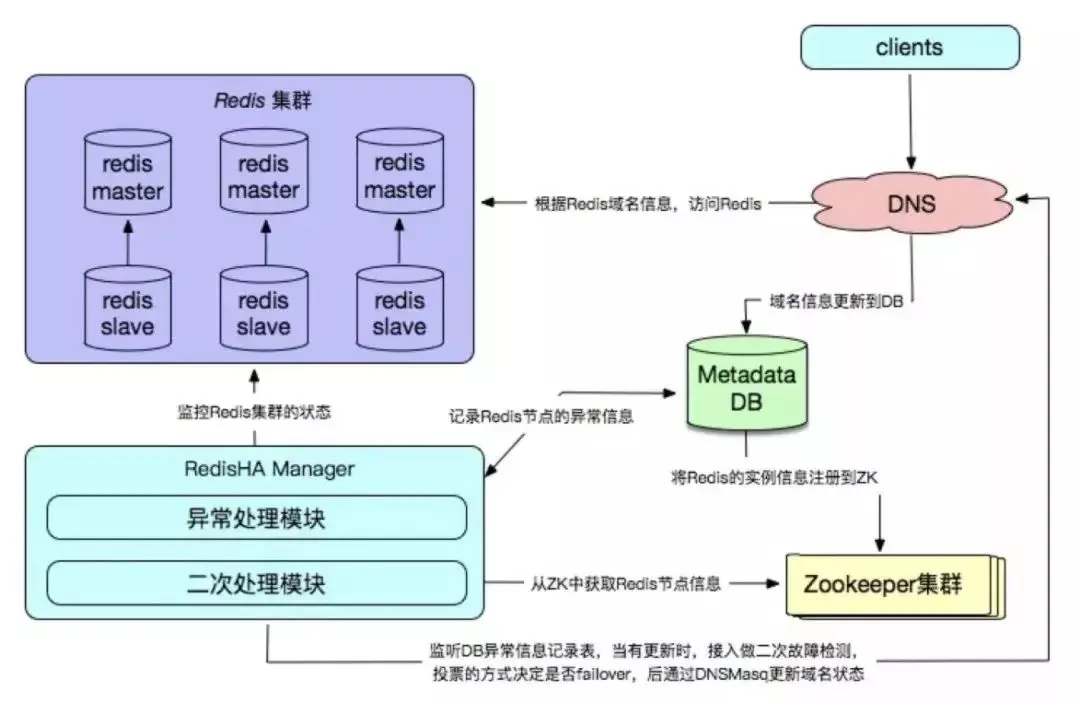
Vorteile:
hohe Zuverlässigkeit und hohe Verfügbarkeit;
hohe Autonomie und Kontrollierbarkeit;
angemessen an den tatsächlichen Geschäftsanforderungen, gute Skalierbarkeit und gute Kompatibilität.
Nachteile:
Komplexe Implementierung und hohe Entwicklungskosten;
Notwendigkeit, unterstützende Peripherieeinrichtungen wie Überwachung, Domainnamendienste, Datenbanken zum Speichern von Metadateninformationen usw. einzurichten;
Hohe Wartungskosten.
Das obige ist der detaillierte Inhalt vonWas sind die gängigen Möglichkeiten, Redis zu verwenden?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1382
1382
 52
52

 So erstellen Sie den Redis -Clustermodus
Apr 10, 2025 pm 10:15 PM
So erstellen Sie den Redis -Clustermodus
Apr 10, 2025 pm 10:15 PM
Der Redis -Cluster -Modus bietet Redis -Instanzen durch Sharding, die Skalierbarkeit und Verfügbarkeit verbessert. Die Bauschritte sind wie folgt: Erstellen Sie ungerade Redis -Instanzen mit verschiedenen Ports; Erstellen Sie 3 Sentinel -Instanzen, Monitor -Redis -Instanzen und Failover; Konfigurieren von Sentinel -Konfigurationsdateien, Informationen zur Überwachung von Redis -Instanzinformationen und Failover -Einstellungen hinzufügen. Konfigurieren von Redis -Instanzkonfigurationsdateien, aktivieren Sie den Cluster -Modus und geben Sie den Cluster -Informationsdateipfad an. Erstellen Sie die Datei nodes.conf, die Informationen zu jeder Redis -Instanz enthält. Starten Sie den Cluster, führen Sie den Befehl erstellen aus, um einen Cluster zu erstellen und die Anzahl der Replikate anzugeben. Melden Sie sich im Cluster an, um den Befehl cluster info auszuführen, um den Clusterstatus zu überprüfen. machen
 So löschen Sie Redis -Daten
Apr 10, 2025 pm 10:06 PM
So löschen Sie Redis -Daten
Apr 10, 2025 pm 10:06 PM
So löschen Sie Redis -Daten: Verwenden Sie den Befehl Flushall, um alle Schlüsselwerte zu löschen. Verwenden Sie den Befehl flushdb, um den Schlüsselwert der aktuell ausgewählten Datenbank zu löschen. Verwenden Sie SELECT, um Datenbanken zu wechseln, und löschen Sie dann FlushDB, um mehrere Datenbanken zu löschen. Verwenden Sie den Befehl del, um einen bestimmten Schlüssel zu löschen. Verwenden Sie das Redis-Cli-Tool, um die Daten zu löschen.
 So verwenden Sie den Befehl Redis
Apr 10, 2025 pm 08:45 PM
So verwenden Sie den Befehl Redis
Apr 10, 2025 pm 08:45 PM
Die Verwendung der REDIS -Anweisung erfordert die folgenden Schritte: Öffnen Sie den Redis -Client. Geben Sie den Befehl ein (Verbschlüsselwert). Bietet die erforderlichen Parameter (variiert von der Anweisung bis zur Anweisung). Drücken Sie die Eingabetaste, um den Befehl auszuführen. Redis gibt eine Antwort zurück, die das Ergebnis der Operation anzeigt (normalerweise in Ordnung oder -err).
 So verwenden Sie Redis Lock
Apr 10, 2025 pm 08:39 PM
So verwenden Sie Redis Lock
Apr 10, 2025 pm 08:39 PM
Um die Operationen zu sperren, muss die Sperre durch den Befehl setNX erfasst werden und dann den Befehl Ablauf verwenden, um die Ablaufzeit festzulegen. Die spezifischen Schritte sind: (1) Verwenden Sie den Befehl setNX, um zu versuchen, ein Schlüsselwertpaar festzulegen; (2) Verwenden Sie den Befehl Ablauf, um die Ablaufzeit für die Sperre festzulegen. (3) Verwenden Sie den Befehl Del, um die Sperre zu löschen, wenn die Sperre nicht mehr benötigt wird.
 So lesen Sie Redis -Warteschlange
Apr 10, 2025 pm 10:12 PM
So lesen Sie Redis -Warteschlange
Apr 10, 2025 pm 10:12 PM
Um eine Warteschlange aus Redis zu lesen, müssen Sie den Warteschlangenname erhalten, die Elemente mit dem Befehl LPOP lesen und die leere Warteschlange verarbeiten. Die spezifischen Schritte sind wie folgt: Holen Sie sich den Warteschlangenname: Nennen Sie ihn mit dem Präfix von "Warteschlange:" wie "Warteschlangen: My-Queue". Verwenden Sie den Befehl LPOP: Wischen Sie das Element aus dem Kopf der Warteschlange aus und geben Sie seinen Wert zurück, z. B. die LPOP-Warteschlange: my-queue. Verarbeitung leerer Warteschlangen: Wenn die Warteschlange leer ist, gibt LPOP NIL zurück, und Sie können überprüfen, ob die Warteschlange existiert, bevor Sie das Element lesen.
 So implementieren Sie die zugrunde liegenden Redis
Apr 10, 2025 pm 07:21 PM
So implementieren Sie die zugrunde liegenden Redis
Apr 10, 2025 pm 07:21 PM
Redis verwendet Hash -Tabellen, um Daten zu speichern und unterstützt Datenstrukturen wie Zeichenfolgen, Listen, Hash -Tabellen, Sammlungen und geordnete Sammlungen. Ernähren sich weiterhin über Daten über Snapshots (RDB) und appendiert Mechanismen nur Schreibmechanismen. Redis verwendet die Master-Slave-Replikation, um die Datenverfügbarkeit zu verbessern. Redis verwendet eine Ereignisschleife mit einer Thread, um Verbindungen und Befehle zu verarbeiten, um die Datenatomizität und Konsistenz zu gewährleisten. Redis legt die Ablaufzeit für den Schlüssel fest und verwendet den faulen Löschmechanismus, um den Ablaufschlüssel zu löschen.
 So lesen Sie den Quellcode von Redis
Apr 10, 2025 pm 08:27 PM
So lesen Sie den Quellcode von Redis
Apr 10, 2025 pm 08:27 PM
Der beste Weg, um Redis -Quellcode zu verstehen, besteht darin, Schritt für Schritt zu gehen: Machen Sie sich mit den Grundlagen von Redis vertraut. Wählen Sie ein bestimmtes Modul oder eine bestimmte Funktion als Ausgangspunkt. Beginnen Sie mit dem Einstiegspunkt des Moduls oder der Funktion und sehen Sie sich die Codezeile nach Zeile an. Zeigen Sie den Code über die Funktionsaufrufkette an. Kennen Sie die von Redis verwendeten Datenstrukturen. Identifizieren Sie den von Redis verwendeten Algorithmus.
 So erstellen Sie Message Middleware für Redis
Apr 10, 2025 pm 07:51 PM
So erstellen Sie Message Middleware für Redis
Apr 10, 2025 pm 07:51 PM
Redis unterstützt als Messing Middleware Modelle für Produktionsverbrauch, kann Nachrichten bestehen und eine zuverlässige Lieferung sicherstellen. Die Verwendung von Redis als Message Middleware ermöglicht eine geringe Latenz, zuverlässige und skalierbare Nachrichten.
