

So integrieren Sie SpringBoot und Redis

Integration von SpringBoot und der nicht relationalen Datenbank Redis
(1) Spring Data Redis-Abhängigkeitsstarter hinzufügen
Fügen Sie diese Abhängigkeit ein, um ein Projekt zu erstellen. Die folgenden Abhängigkeiten werden in der Datei pom.xml des Projekts angezeigt:

(2) Schreiben Sie die Entitätsklasse
Person:
package com.hardy.springbootdataredis.domain;import org.springframework.data.annotation.Id;import org.springframework.data.redis.core.RedisHash;import org.springframework.data.redis.core.index.Indexed;/**
* @Author: HardyYao
* @Date: 2021/6/15 */@RedisHash("persons") // 指定操作实体类对象在Redis数据库中的存储空间public class Person {
@Id // 标识实体类主键private String id;
@Indexed // 标识对应属性在Redis数据库中生成二级索引private String firstname;
@Indexedprivate String lastname;private Address address;public String getId() {return id;
}public void setId(String id) {this.id = id;
}public String getFirstname() {return firstname;
}public void setFirstname(String firstname) {this.firstname = firstname;
}public String getLastname() {return lastname;
}public void setLastname(String lastname) {this.lastname = lastname;
}public Address getAddress() {return address;
}public void setAddress(Address address) {this.address = address;
}
@Overridepublic String toString() {return "Person{" +
"id='" + id + ''' +
", firstname='" + firstname + ''' +
", lastname='" + lastname + ''' +
", address=" + address +
'}';
}
}Adresse:
package com.hardy.springbootdataredis.domain;import org.springframework.data.redis.core.index.Indexed;/**
* @Author: HardyYao
* @Date: 2021/6/15 */public class Address {
@Indexedprivate String city;
@Indexedprivate String country;public String getCity() {return city;
}public void setCity(String city) {this.city = city;
}public String getCountry() {return country;
}public void setCountry(String country) {this.country = country;
}
@Overridepublic String toString() {return "Address{" +
"city='" + city + ''' +
", country='" + country + ''' +
'}';
}
}In den beiden oben genannten Entitätsklassen sind mehrere Anmerkungen zu Datenoperationen der Redis-Datenbank beteiligt:
@RedisHash("Personen ") : Wird verwendet, um den Speicherplatz des Betriebsentitätsklassenobjekts in der Redis-Datenbank anzugeben. Hier bedeutet dies, dass die Datenoperationen für die Person-Entitätsklasse im Speicherplatz mit dem Namen „Personen“ in der Redis-Datenbank gespeichert werden.
@Id: wird verwendet, um den Primärschlüssel der Entitätsklasse zu identifizieren. In der Redis-Datenbank wird standardmäßig ein HashKey in Form einer Zeichenfolge generiert, um die eindeutige Entitätsobjekt-ID darzustellen. Natürlich kann die ID auch manuell während der Datenspeicherung angegeben werden.
@Indexed: wird verwendet, um anzugeben, dass ein Sekundärindex für das entsprechende Attribut in der Redis-Datenbank generiert werden soll. Wenn diese Anmerkung verwendet wird, wird der dem Attribut entsprechende Sekundärindex in der Datenbank generiert, wodurch die Datenabfrage vereinfacht wird. Der Indexname ist derselbe wie der Attributname.
(3) Repository-Schnittstelle schreiben
SpringBoot bietet eine automatisierte Konfiguration für einige gängige Datenbanken, einschließlich Redis. Sie können das Hinzufügen, Löschen, Überprüfen und Ändern von Daten in der Datenbank vereinfachen, indem Sie die Repository-Schnittstelle implementieren:
package com.hardy.springbootdataredis.repository;import com.hardy.springbootdataredis.domain.Person;import org.springframework.data.repository.CrudRepository;import java.util.List;/**
* @Author: HardyYao
* @Date: 2021/6/15 */public interface PersonRepository extends CrudRepository<Person, String> {
List<Person> findByAddress_City(String City);
}Hinweis : Die beim Betrieb der Redis-Datenbank geschriebene Repository-Schnittstellenklasse muss die CrudRepository-Schnittstelle der untersten Ebene erben, anstatt JpaRepository zu erben (JpaRepository ist einzigartig für die JPA-Integration von SpringBoot). Natürlich können Sie auch die von SpringBoot integrierten JPA-Abhängigkeiten und Redis-Abhängigkeiten gleichzeitig in die Datei pom.xml des Projekts importieren, sodass Sie eine Schnittstelle schreiben können, die die JpaRepository-Schnittstelle erbt, um die Redis-Datenbank zu betreiben.
(4) Redis-Datenbankverbindungskonfiguration
Fügen Sie die Redis-Datenbankverbindungskonfiguration in der globalen Konfigurationsdatei application.properties hinzu. Der Beispielcode lautet wie folgt:
# Redis服务器地址 spring.redis.host=127.0.0.1 # Redis服务器连接端口 spring.redis.port=6379 # Redis服务器连接密码(默认为空) spring.redis.password=
(5) Unit-Test-Methode schreiben
package com.hardy.springbootdataredis;import com.hardy.springbootdataredis.domain.Address;import com.hardy.springbootdataredis.domain.Person;import com.hardy.springbootdataredis.repository.PersonRepository;import org.junit.jupiter.api.Test;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.boot.test.context.SpringBootTest;import java.util.List;
@SpringBootTestclass SpringbootdataRedisApplicationTests {
@Autowiredprivate PersonRepository repository;
@Testpublic void savePerson() {
Person person = new Person();
person.setFirstname("张");
person.setLastname("三");
Address address = new Address();
address.setCity("北京");
address.setCountry("中国");
person.setAddress(address);// 向Redis数据库添加数据Person save = repository.save(person);
}
@Testpublic void selectPerson() {
List<Person> list = repository.findByAddress_City("北京");for (Person person : list) {
System.out.println(person);
}
}
}(6) Integrationstest
Öffnen Sie das visuelle Verwaltungstool des Redis-Clients und stellen Sie zunächst eine Verbindung zum lokalen Redis-Server her:
Nach erfolgreicher Verbindung können Sie sehen, dass in der lokalen Redis-Datenbank keine Daten vorhanden sind:

Führen Sie die beiden oben beschriebenen Skripte aus. Überprüfen Sie als Testmethode die Druckergebnisse der Konsole:

Um zu überprüfen, ob die Methode save() die Daten tatsächlich in die lokale Redis-Datenbank geschrieben hat, öffnen Sie das visuelle Verwaltungstool des Redis-Clients. Aktualisieren Sie die Daten, und Sie können sehen, dass die Daten erfolgreich sind. Geschrieben:
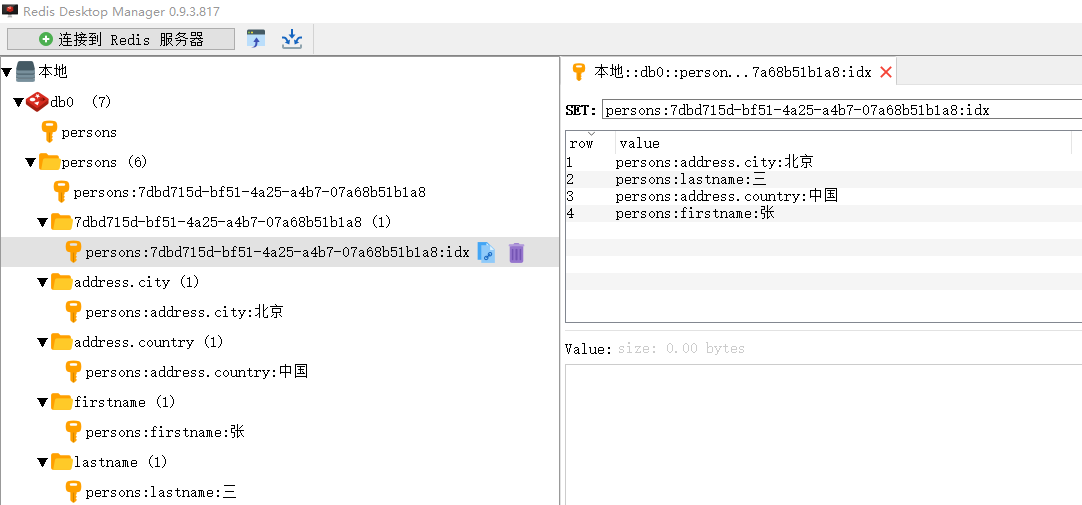
Wie aus dem obigen Bild ersichtlich ist: Die durch Ausführen der Methode save () hinzugefügten Daten werden erfolgreich in der Redis-Datenbank gespeichert. Darüber hinaus wird auf der linken Seite der Datenbankliste ein Sekundärindex ähnlich wie Adresse.Stadt, Vorname, Nachname usw. erstellt. Diese Sekundärindizes werden durch Hinzufügen der Annotation @Indexed zu den entsprechenden Attributen beim Erstellen der Personenklasse generiert. Da der dem Attribut entsprechende Sekundärindex in der Redis-Datenbank generiert wird, können gleichzeitig spezifische Dateninformationen über den Sekundärindex abgefragt werden. Beispielsweise fragt Repository.findByAddress_City („Peking“) die Daten ab, deren Indexwert Peking ist über den Adress-Stadt-Index. Wenn der Sekundärindex des entsprechenden Attributs nicht festgelegt ist, ist das über den Attributindex abgefragte Datenergebnis leer.
Das obige ist der detaillierte Inhalt vonSo integrieren Sie SpringBoot und Redis. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 So erstellen Sie den Redis -Clustermodus
Apr 10, 2025 pm 10:15 PM
So erstellen Sie den Redis -Clustermodus
Apr 10, 2025 pm 10:15 PM
Der Redis -Cluster -Modus bietet Redis -Instanzen durch Sharding, die Skalierbarkeit und Verfügbarkeit verbessert. Die Bauschritte sind wie folgt: Erstellen Sie ungerade Redis -Instanzen mit verschiedenen Ports; Erstellen Sie 3 Sentinel -Instanzen, Monitor -Redis -Instanzen und Failover; Konfigurieren von Sentinel -Konfigurationsdateien, Informationen zur Überwachung von Redis -Instanzinformationen und Failover -Einstellungen hinzufügen. Konfigurieren von Redis -Instanzkonfigurationsdateien, aktivieren Sie den Cluster -Modus und geben Sie den Cluster -Informationsdateipfad an. Erstellen Sie die Datei nodes.conf, die Informationen zu jeder Redis -Instanz enthält. Starten Sie den Cluster, führen Sie den Befehl erstellen aus, um einen Cluster zu erstellen und die Anzahl der Replikate anzugeben. Melden Sie sich im Cluster an, um den Befehl cluster info auszuführen, um den Clusterstatus zu überprüfen. machen
 So löschen Sie Redis -Daten
Apr 10, 2025 pm 10:06 PM
So löschen Sie Redis -Daten
Apr 10, 2025 pm 10:06 PM
So löschen Sie Redis -Daten: Verwenden Sie den Befehl Flushall, um alle Schlüsselwerte zu löschen. Verwenden Sie den Befehl flushdb, um den Schlüsselwert der aktuell ausgewählten Datenbank zu löschen. Verwenden Sie SELECT, um Datenbanken zu wechseln, und löschen Sie dann FlushDB, um mehrere Datenbanken zu löschen. Verwenden Sie den Befehl del, um einen bestimmten Schlüssel zu löschen. Verwenden Sie das Redis-Cli-Tool, um die Daten zu löschen.
 So lesen Sie Redis -Warteschlange
Apr 10, 2025 pm 10:12 PM
So lesen Sie Redis -Warteschlange
Apr 10, 2025 pm 10:12 PM
Um eine Warteschlange aus Redis zu lesen, müssen Sie den Warteschlangenname erhalten, die Elemente mit dem Befehl LPOP lesen und die leere Warteschlange verarbeiten. Die spezifischen Schritte sind wie folgt: Holen Sie sich den Warteschlangenname: Nennen Sie ihn mit dem Präfix von "Warteschlange:" wie "Warteschlangen: My-Queue". Verwenden Sie den Befehl LPOP: Wischen Sie das Element aus dem Kopf der Warteschlange aus und geben Sie seinen Wert zurück, z. B. die LPOP-Warteschlange: my-queue. Verarbeitung leerer Warteschlangen: Wenn die Warteschlange leer ist, gibt LPOP NIL zurück, und Sie können überprüfen, ob die Warteschlange existiert, bevor Sie das Element lesen.
 So verwenden Sie den Befehl Redis
Apr 10, 2025 pm 08:45 PM
So verwenden Sie den Befehl Redis
Apr 10, 2025 pm 08:45 PM
Die Verwendung der REDIS -Anweisung erfordert die folgenden Schritte: Öffnen Sie den Redis -Client. Geben Sie den Befehl ein (Verbschlüsselwert). Bietet die erforderlichen Parameter (variiert von der Anweisung bis zur Anweisung). Drücken Sie die Eingabetaste, um den Befehl auszuführen. Redis gibt eine Antwort zurück, die das Ergebnis der Operation anzeigt (normalerweise in Ordnung oder -err).
 So verwenden Sie Redis Lock
Apr 10, 2025 pm 08:39 PM
So verwenden Sie Redis Lock
Apr 10, 2025 pm 08:39 PM
Um die Operationen zu sperren, muss die Sperre durch den Befehl setNX erfasst werden und dann den Befehl Ablauf verwenden, um die Ablaufzeit festzulegen. Die spezifischen Schritte sind: (1) Verwenden Sie den Befehl setNX, um zu versuchen, ein Schlüsselwertpaar festzulegen; (2) Verwenden Sie den Befehl Ablauf, um die Ablaufzeit für die Sperre festzulegen. (3) Verwenden Sie den Befehl Del, um die Sperre zu löschen, wenn die Sperre nicht mehr benötigt wird.
 So konfigurieren Sie die Ausführungszeit der Lua -Skript in CentOS Redis
Apr 14, 2025 pm 02:12 PM
So konfigurieren Sie die Ausführungszeit der Lua -Skript in CentOS Redis
Apr 14, 2025 pm 02:12 PM
Auf CentOS -Systemen können Sie die Ausführungszeit von LuA -Skripten einschränken, indem Sie Redis -Konfigurationsdateien ändern oder Befehle mit Redis verwenden, um zu verhindern, dass bösartige Skripte zu viele Ressourcen konsumieren. Methode 1: Ändern Sie die Redis -Konfigurationsdatei und suchen Sie die Redis -Konfigurationsdatei: Die Redis -Konfigurationsdatei befindet sich normalerweise in /etc/redis/redis.conf. Konfigurationsdatei bearbeiten: Öffnen Sie die Konfigurationsdatei mit einem Texteditor (z. B. VI oder Nano): Sudovi/etc/redis/redis.conf Setzen Sie die LUA -Skriptausführungszeit.
 So verwenden Sie die Befehlszeile der Redis
Apr 10, 2025 pm 10:18 PM
So verwenden Sie die Befehlszeile der Redis
Apr 10, 2025 pm 10:18 PM
Verwenden Sie das Redis-Befehlszeilen-Tool (REDIS-CLI), um Redis in folgenden Schritten zu verwalten und zu betreiben: Stellen Sie die Adresse und den Port an, um die Adresse und den Port zu stellen. Senden Sie Befehle mit dem Befehlsnamen und den Parametern an den Server. Verwenden Sie den Befehl Hilfe, um Hilfeinformationen für einen bestimmten Befehl anzuzeigen. Verwenden Sie den Befehl zum Beenden, um das Befehlszeilenwerkzeug zu beenden.
 So optimieren Sie die Leistung von Debian Readdir
Apr 13, 2025 am 08:48 AM
So optimieren Sie die Leistung von Debian Readdir
Apr 13, 2025 am 08:48 AM
In Debian -Systemen werden Readdir -Systemaufrufe zum Lesen des Verzeichnisinhalts verwendet. Wenn seine Leistung nicht gut ist, probieren Sie die folgende Optimierungsstrategie aus: Vereinfachen Sie die Anzahl der Verzeichnisdateien: Teilen Sie große Verzeichnisse so weit wie möglich in mehrere kleine Verzeichnisse auf und reduzieren Sie die Anzahl der gemäß Readdir -Anrufe verarbeiteten Elemente. Aktivieren Sie den Verzeichnis -Inhalt Caching: Erstellen Sie einen Cache -Mechanismus, aktualisieren Sie den Cache regelmäßig oder bei Änderungen des Verzeichnisinhalts und reduzieren Sie häufige Aufrufe an Readdir. Speicher -Caches (wie Memcached oder Redis) oder lokale Caches (wie Dateien oder Datenbanken) können berücksichtigt werden. Nehmen Sie eine effiziente Datenstruktur an: Wenn Sie das Verzeichnis -Traversal selbst implementieren, wählen Sie effizientere Datenstrukturen (z.
