

So beherrschen Sie die MySQL-Replikationsarchitektur


Replikationsarchitektur mit einem Master und mehreren Slaves
In praktischen Anwendungen kopieren die meisten MySQL-Replikationsarchitekturmuster einen Master auf einen oder mehrere Slaves.
In einem Szenario, in dem der Leseanforderungsdruck der Hauptbibliothek sehr hoch ist, können Sie die Ein-Master-Mehrfach-Slave-Replikationsarchitektur konfigurieren, um eine Lese- und Schreibtrennung zu erreichen und eine große Anzahl von Leseanforderungen zu verteilen, die keinen besonders hohen Realwert erfordern -Zeitleistung für die Datenbank durch Lastausgleich bei mehreren Slave-Bibliotheken (Leseanforderungen mit hohen Echtzeitanforderungen können aus der Master-Bibliothek gelesen werden), um den Lesedruck auf die Master-Bibliothek zu reduzieren, wie in der folgenden Abbildung dargestellt.
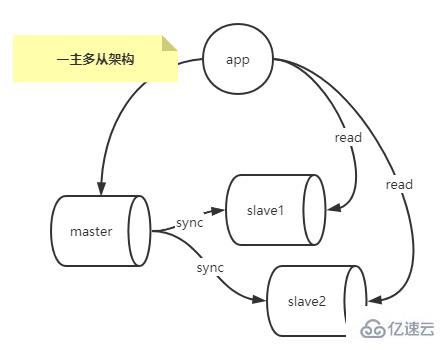
Nachteile:
Der Master kann nicht heruntergefahren werden und kann beim Herunterfahren keine Schreibanforderungen empfangen.
Wenn zu viele Slaves vorhanden sind, kommt es zu Verzögerungen Muss für routinemäßige Wartungsarbeiten heruntergefahren werden, dann muss ein Slave der Kommissionsmaster sein. Welches soll man wählen, ist eine Frage?
Wenn ein Slave zum Master wird, kommt es zu Inkonsistenzen zwischen den Daten des aktuellen Masters und des vorherigen Masters, und der vorherige Master hat die Binlog-Datei und den POS-Standort des aktuellen Masterknotens nicht gespeichert.
Multi-Master-Replikationsarchitektur
Die Multi-Master-Replikationsarchitektur löst das Single-Point-of-Failure-Problem des Masters in der Single-Master-Multi-Slave-Replikationsarchitektur.
Sie können ein Drittanbieter-Tool wie Keepalived verwenden, um eine IP-Drift einfach zu erreichen, sodass Ausfallzeiten und Wartungsarbeiten des Masters den Schreibvorgang nicht beeinträchtigen.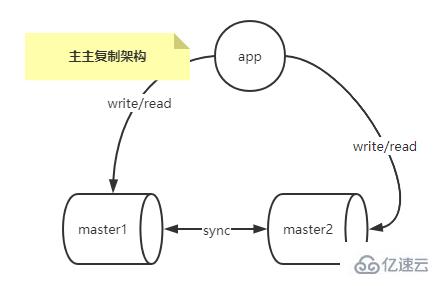 Kaskadierende Replikationsarchitektur
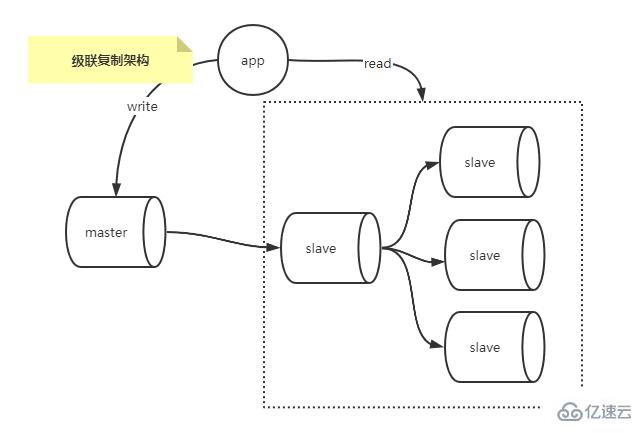
Kaskadierende Replikationsarchitektur
Ein Master und viele Slaves, der E/A-Druck und der Netzwerkdruck der Hauptbibliothek nehmen mit der Anzahl der Slave-Bibliotheken zu, da jede Slave-Bibliothek über ein unabhängiges BINLOG verfügt Zum Senden von Ereignissen wird ein Dump-Thread verwendet, und die „Kaskaden-Replikationsarchitektur“ löst den zusätzlichen E/A- und Netzwerkdruck auf die Hauptbibliothek im Master-Multi-Slave-Szenario.
Wie im Bild unten gezeigt.
Im Vergleich zur Ein-Master-Mehrfach-Slave-Architektur kopiert die Kaskadenreplikation nur Daten aus der Master-Datenbank in eine kleine Anzahl von Slave-Datenbanken, und andere Slave-Datenbanken kopieren dann Daten aus dieser kleinen Anzahl von Slave-Datenbanken Erleichterung der Arbeitsbelastung der Master-Datenbank. Natürlich gibt es Nachteile: Die herkömmliche Replikation von MySQL ist asynchron. Im Kaskadenreplikationsszenario müssen die Daten in der Master-Datenbank zweimal repliziert werden, bevor sie andere Slave-Datenbanken erreichen. Multi-Slave-Replikationsszenario, bei dem die Daten nur einmal vorhanden sind. Die Kopie ist sogar noch größer.
 Durch Auswahl der BLACKHOLE-Tabellen-Engine in der sekundären Slave-Datenbank kann die Latenz der Kaskadenreplikation reduziert werden. Wie der Name schon sagt, handelt es sich bei der BLACKHOLE-Engine um eine „Black-Hole“-Engine. Die in die BLACKHOLE-Tabelle geschriebenen Daten werden nicht auf die Festplatte geschrieben. Die BLACKHOLE-Tabelle ist immer eine leere Tabelle, die nur Ereignisse aufzeichnet im BINLOG.
Durch Auswahl der BLACKHOLE-Tabellen-Engine in der sekundären Slave-Datenbank kann die Latenz der Kaskadenreplikation reduziert werden. Wie der Name schon sagt, handelt es sich bei der BLACKHOLE-Engine um eine „Black-Hole“-Engine. Die in die BLACKHOLE-Tabelle geschriebenen Daten werden nicht auf die Festplatte geschrieben. Die BLACKHOLE-Tabelle ist immer eine leere Tabelle, die nur Ereignisse aufzeichnet im BINLOG.
Das Folgende demonstriert die BLACKHOLE-Engine:
mysql> CREATE TABLE `user` (
-> `id` int NOT NULL AUTO_INCREMENT PRIMARY KEY,
-> `name` varchar(255) NOT NULL DEFAULT '',
-> `age` tinyint unsigned NOT NULL DEFAULT 0
-> )ENGINE=BLACKHOLE charset=utf8mb4;Query OK, 0 rows affected (0.00 sec)mysql> INSERT INTO `user` (`name`,`age`) values("itbsl", "26");Query OK, 1 row affected (0.00 sec)mysql> select * from user;Empty set (0.00 sec)Sie können sehen, dass in der Benutzertabelle keine Daten vorhanden sind, deren Speicher-Engine BLACKHOLE ist.
Kombinierte Multi-Master- und Kaskaden-Replikationsarchitektur
Kombiniert Multi-Master- und Kaskaden-Replikationsarchitektur, die das Problem des Single-Point-Masters und das Problem der Slave-Kaskadenverzögerung löst.
Aufbau einer Multi-Master-ReplikationsarchitekturHostplanung: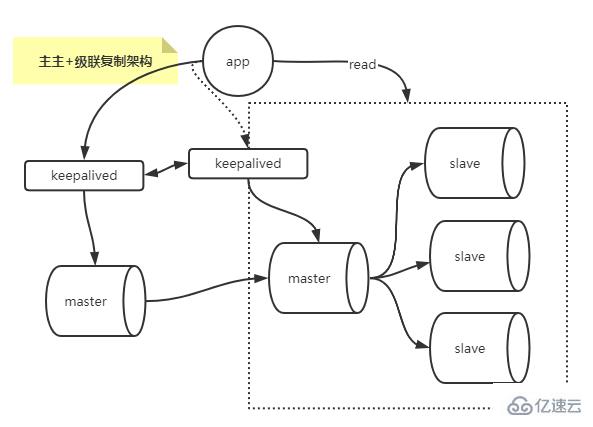
Master1: Docker, Port 3314
- Master2: Docker, Port 3315
- Master1. Konfiguration
-
Konfigurationsdatei my.cnf :
$ cat /home/mysql/docker-data/3315/conf/my.cnf [mysqld] character_set_server=utf8 init_connect='SET NAMES utf8' symbolic-links=0 lower_case_table_names=1 server-id=1403314 log-bin=mysql-bin binlog-format=ROW auto_increment_increment=2 # 几个主库,这里就配几 auto_increment_offset=1 # 每个主库的偏移量需要不一致 gtid_mode=ON enforce-gtid-consistency=true binlog-do-db=order # 要同步的数据库
Nach dem Login kopierenDocker starten:
$ docker run --name mysql3314 -p 3314:3306 --privileged=true -ti -e MYSQL_ROOT_PASSWORD=root -e MYSQL_DATABASE=order -e MYSQL_USER=user -e MYSQL_PASSWORD=pass -v /home/mysql/docker-data/3314/conf:/etc/mysql/conf.d -v /home/mysql/docker-data/3314/data/:/var/lib/mysql -v /home/mysql/docker-data/3314/logs/:/var/log/mysql -d mysql:5.7
Benutzer für die Replikation hinzufügen und autorisieren:
mysql> GRANT REPLICATION SLAVE,FILE,REPLICATION CLIENT ON *.* TO 'repluser'@'%' IDENTIFIED BY '123456'; Query OK, 0 rows affected, 1 warning (0.01 sec) mysql> FLUSH PRIVILEGES; Query OK, 0 rows affected (0.01 sec)
Synchronisierung Master1 aktivieren (der Benutzer kommt hier von Master2):
mysql> change master to master_host='172.23.252.98',master_port=3315,master_user='repluser',master_password='123456',master_auto_position=1; Query OK, 0 rows affected, 2 warnings (0.03 sec) mysql> start slave; Query OK, 0 rows affected (0.00 sec)
Konfiguration von Master2
Die Konfiguration von Master2 ähnelt Master1.
Der Hauptunterschied besteht darin, dass es in my.cnf ein Attribut gibt, das inkonsistent sein muss:
auto_increment_offset=2 # 每个主库的偏移量需要不一致
Test:
Erstellen Sie eine Tabelle in Master2 und fügen Sie Daten hinzu:
mysql> create table t_order(id int primary key auto_increment, name varchar(20));
Query OK, 0 rows affected (0.01 sec)
mysql> insert into t_order(name) values("A");
Query OK, 1 row affected (0.01 sec)
mysql> insert into t_order(name) values("B");
Query OK, 1 row affected (0.00 sec)
mysql> select * from t_order;
+----+------+
| id | name |
+----+------+
| 2 | A |
| 4 | B |
+----+------+
2 rows in set (0.00 sec)Sie finden die Schrittgröße von id in Master2 ist 2 und beginnt mit einer Erhöhung um 2.
Fragen Sie dann die Daten in Master1 ab und fügen Sie Folgendes hinzu:
mysql> select * from t_order;
+----+------+
| id | name |
+----+------+
| 2 | A |
| 4 | B |
+----+------+
2 rows in set (0.00 sec)
mysql> insert into t_order(name) values("E");
Query OK, 1 row affected (0.00 sec)
mysql> select * from t_order;
+----+------+
| id | name |
+----+------+
| 2 | A |
| 4 | B |
| 5 | E |
+----+------+
3 rows in set (0.00 sec)Sie können feststellen, dass die Schrittgröße der ID in Master1 2 beträgt und ab 1 zunimmt. Fragen Sie dann die Daten in Master2 ab und Sie können die Daten mit finden ID 5 gibt die Master-Master-Replikationskonfiguration an. Kein Problem.
Warum sind die Offsets des ID-Inkrements in den beiden Mastern inkonsistent? Wenn die beiden Master gleichzeitig die Einfügungsanforderung empfangen, kann sichergestellt werden, dass die ID nicht in Konflikt gerät. Dies kann tatsächlich nur sicherstellen, dass die eingefügten Daten nicht in Konflikt geraten, kann jedoch nicht die durch Löschen und Ändern verursachte Dateninkonsistenz garantieren.
In tatsächlichen Anwendungsszenarien kann dem Client also nur ein Master zur Verfügung gestellt werden, um die Datenkonsistenz sicherzustellen.
MySQL-Hochverfügbarkeitskonstruktion
Hier verwenden wir Keepalived, um die oben genannte Multi-Master-Replikationsarchitektur zu transformieren, um eine hohe Verfügbarkeit von MySQL zu erreichen. keepalived-Installation:$ sudo apt-get install -y keepalived
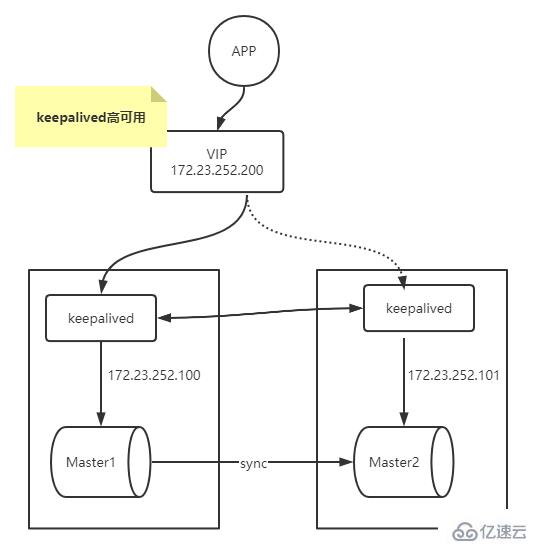 keepalived.conf
keepalived.conf$ cat /etc/keepalived/keepalived3314.conf! Configuration File for keepalived#简单的头部,这里主要可以做邮件通知报警等的设置,此处就暂不配置了;global_defs {
#notificationd LVS_DEVEL}#预先定义一个脚本,方便后面调用,也可以定义多个,方便选择;vrrp_script chk_haproxy {
script "/etc/keepalived/chkmysql.sh" #具体脚本路径
interval 2 #脚本循环运行间隔}#VRRP虚拟路由冗余协议配置vrrp_instance VI_1 { #VI_1 是自定义的名称;
state BACKUP #MASTER表示是一台主设备,BACKUP表示为备用设备【我们这里因为设置为开启不抢占,所以都设置为备用】
nopreempt #开启不抢占
interface eth0 #指定VIP需要绑定的物理网卡
virtual_router_id 11 #VRID虚拟路由标识,也叫做分组名称,该组内的设备需要相同
priority 130 #定义这台设备的优先级 1-254;开启了不抢占,所以此处优先级必须高于另一台
advert_int 1 #生存检测时的组播信息发送间隔,组内一致
authentication { #设置验证信息,组内一致
auth_type PASS #有PASS 和 AH 两种,常用 PASS
auth_pass asd #密码
}
virtual_ipaddress {
172.23.252.200 #指定VIP地址,组内一致,可以设置多个IP
}
track_script { #使用在这个域中使用预先定义的脚本,上面定义的
chk_haproxy }
#notify_backup "/etc/init.d/haproxy restart" #表示当切换到backup状态时,要执行的脚本
#notify_fault "/etc/init.d/haproxy stop" #故障时执行的脚本}/etc/keepalived/chkmysql.sh
$ cat /etc/keepalived/chkmysql.s.sh#!/bin/bashmysql -uroot -proot -P 3314 -e "show status;" > /dev/null 2>&1if [ $? == 0 ];then
echo "$host mysql login successfully"
exit 0else
echo "$host login failed"
killall keepalived exit 2fiDas obige ist der detaillierte Inhalt vonSo beherrschen Sie die MySQL-Replikationsarchitektur. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Die Beziehung zwischen MySQL -Benutzer und Datenbank
Apr 08, 2025 pm 07:15 PM
Die Beziehung zwischen MySQL -Benutzer und Datenbank
Apr 08, 2025 pm 07:15 PM
In der MySQL -Datenbank wird die Beziehung zwischen dem Benutzer und der Datenbank durch Berechtigungen und Tabellen definiert. Der Benutzer verfügt über einen Benutzernamen und ein Passwort, um auf die Datenbank zuzugreifen. Die Berechtigungen werden über den Zuschussbefehl erteilt, während die Tabelle durch den Befehl create table erstellt wird. Um eine Beziehung zwischen einem Benutzer und einer Datenbank herzustellen, müssen Sie eine Datenbank erstellen, einen Benutzer erstellen und dann Berechtigungen erfüllen.
 MySQL: Die einfache Datenverwaltung für Anfänger
Apr 09, 2025 am 12:07 AM
MySQL: Die einfache Datenverwaltung für Anfänger
Apr 09, 2025 am 12:07 AM
MySQL ist für Anfänger geeignet, da es einfach zu installieren, leistungsfähig und einfach zu verwalten ist. 1. Einfache Installation und Konfiguration, geeignet für eine Vielzahl von Betriebssystemen. 2. Unterstützung grundlegender Vorgänge wie Erstellen von Datenbanken und Tabellen, Einfügen, Abfragen, Aktualisieren und Löschen von Daten. 3. Bereitstellung fortgeschrittener Funktionen wie Join Operations und Unterabfragen. 4. Die Leistung kann durch Indexierung, Abfrageoptimierung und Tabellenpartitionierung verbessert werden. 5. Backup-, Wiederherstellungs- und Sicherheitsmaßnahmen unterstützen, um die Datensicherheit und -konsistenz zu gewährleisten.
 RDS MySQL -Integration mit RedShift Zero ETL
Apr 08, 2025 pm 07:06 PM
RDS MySQL -Integration mit RedShift Zero ETL
Apr 08, 2025 pm 07:06 PM
Vereinfachung der Datenintegration: AmazonRDSMYSQL und Redshifts Null ETL-Integration Die effiziente Datenintegration steht im Mittelpunkt einer datengesteuerten Organisation. Herkömmliche ETL-Prozesse (Extrakt, Konvertierung, Last) sind komplex und zeitaufwändig, insbesondere bei der Integration von Datenbanken (wie AmazonRDSMysQL) in Data Warehouses (wie Rotverschiebung). AWS bietet jedoch keine ETL-Integrationslösungen, die diese Situation vollständig verändert haben und eine vereinfachte Lösung für die Datenmigration von RDSMysQL zu Rotverschiebung bietet. Dieser Artikel wird in die Integration von RDSMYSQL Null ETL mit RedShift eintauchen und erklärt, wie es funktioniert und welche Vorteile es Dateningenieuren und Entwicklern bringt.
 So füllen Sie MySQL Benutzername und Passwort aus
Apr 08, 2025 pm 07:09 PM
So füllen Sie MySQL Benutzername und Passwort aus
Apr 08, 2025 pm 07:09 PM
Ausfüllen des MySQL -Benutzernamens und des Kennworts: 1. Bestimmen Sie den Benutzernamen und das Passwort; 2. Verbinden Sie eine Verbindung zur Datenbank; 3. Verwenden Sie den Benutzernamen und das Passwort, um Abfragen und Befehle auszuführen.
 Die Abfrageoptimierung in MySQL ist für die Verbesserung der Datenbankleistung von wesentlicher Bedeutung, insbesondere im Umgang mit großen Datensätzen
Apr 08, 2025 pm 07:12 PM
Die Abfrageoptimierung in MySQL ist für die Verbesserung der Datenbankleistung von wesentlicher Bedeutung, insbesondere im Umgang mit großen Datensätzen
Apr 08, 2025 pm 07:12 PM
1. Verwenden Sie den richtigen Index, um das Abrufen von Daten zu beschleunigen, indem die Menge der skanierten Datenmenge ausgewählt wird. Wenn Sie mehrmals eine Spalte einer Tabelle nachschlagen, erstellen Sie einen Index für diese Spalte. Wenn Sie oder Ihre App Daten aus mehreren Spalten gemäß den Kriterien benötigen, erstellen Sie einen zusammengesetzten Index 2. Vermeiden Sie aus. Auswählen * Nur die erforderlichen Spalten. Wenn Sie alle unerwünschten Spalten auswählen, konsumiert dies nur mehr Serverspeicher und veranlasst den Server bei hoher Last oder Frequenzzeiten, beispielsweise die Auswahl Ihrer Tabelle, wie beispielsweise die Spalten wie innovata und updated_at und Zeitsteuer und dann zu entfernen.
 Kann ich das Datenbankkennwort in Navicat abrufen?
Apr 08, 2025 pm 09:51 PM
Kann ich das Datenbankkennwort in Navicat abrufen?
Apr 08, 2025 pm 09:51 PM
Navicat selbst speichert das Datenbankkennwort nicht und kann das verschlüsselte Passwort nur abrufen. Lösung: 1. Überprüfen Sie den Passwort -Manager. 2. Überprüfen Sie Navicats "Messnot Password" -Funktion; 3.. Setzen Sie das Datenbankkennwort zurück; 4. Kontaktieren Sie den Datenbankadministrator.
 Verstehen von Säureeigenschaften: Die Säulen einer zuverlässigen Datenbank
Apr 08, 2025 pm 06:33 PM
Verstehen von Säureeigenschaften: Die Säulen einer zuverlässigen Datenbank
Apr 08, 2025 pm 06:33 PM
Detaillierte Erläuterung von Datenbanksäureattributen Säureattribute sind eine Reihe von Regeln, um die Zuverlässigkeit und Konsistenz von Datenbanktransaktionen sicherzustellen. Sie definieren, wie Datenbanksysteme Transaktionen umgehen, und sorgen dafür, dass die Datenintegrität und -genauigkeit auch im Falle von Systemabstürzen, Leistungsunterbrechungen oder mehreren Benutzern gleichzeitiger Zugriff. Säureattributübersicht Atomizität: Eine Transaktion wird als unteilbare Einheit angesehen. Jeder Teil schlägt fehl, die gesamte Transaktion wird zurückgerollt und die Datenbank behält keine Änderungen bei. Wenn beispielsweise eine Banküberweisung von einem Konto abgezogen wird, jedoch nicht auf ein anderes erhöht wird, wird der gesamte Betrieb widerrufen. begintransaktion; updateAccountsSetBalance = Balance-100WH
 Master SQL Limit -Klausel: Steuern Sie die Anzahl der Zeilen in einer Abfrage
Apr 08, 2025 pm 07:00 PM
Master SQL Limit -Klausel: Steuern Sie die Anzahl der Zeilen in einer Abfrage
Apr 08, 2025 pm 07:00 PM
SQllimit -Klausel: Steuern Sie die Anzahl der Zeilen in Abfrageergebnissen. Die Grenzklausel in SQL wird verwendet, um die Anzahl der von der Abfrage zurückgegebenen Zeilen zu begrenzen. Dies ist sehr nützlich, wenn große Datensätze, paginierte Anzeigen und Testdaten verarbeitet werden und die Abfrageeffizienz effektiv verbessern können. Grundlegende Syntax der Syntax: SelectColumn1, Spalte2, ... Fromtable_Namelimitnumber_of_rows; number_of_rows: Geben Sie die Anzahl der zurückgegebenen Zeilen an. Syntax mit Offset: SelectColumn1, Spalte2, ... Fromtable_NamelimitOffset, Number_of_rows; Offset: Skip überspringen
