

Springboot-Cache-Redis-Integrationsmethode

Der Standardwert ist ConcurrentMapCache von ConcurrentMapCacheManager als Cache-Komponente.
Bei Verwendung von ConcurrentMap werden die Daten in ConcurrentMap<object></object> gespeichert.
Tatsächlich verwenden wir während des Entwicklungsprozesses häufig Caching-Middleware.
Zum Beispiel verwenden wir häufig Redis, Memcache, einschließlich des von uns verwendeten Ehcaches usw. Wir alle verwenden Caching-Middleware.
Als wir das Prinzip zuvor erklärt haben, haben wir auch festgestellt, dass Springboot viele Cache-Konfigurationen unterstützt:
Wie in der folgenden Abbildung gezeigt:
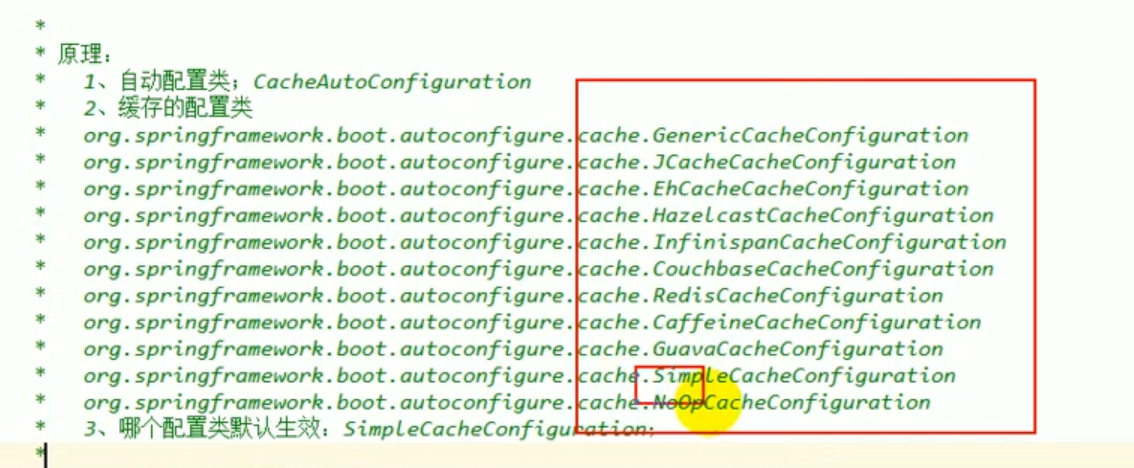
Die Standardstartkonfiguration ist: SimpleCacheConfiguration.
Wann sind andere Caches aktiviert?
Wir können mit Strg + N nach diesen Konfigurationsklassen suchen und dann hineingehen und ihre Bedingungsbedingungen sehen:
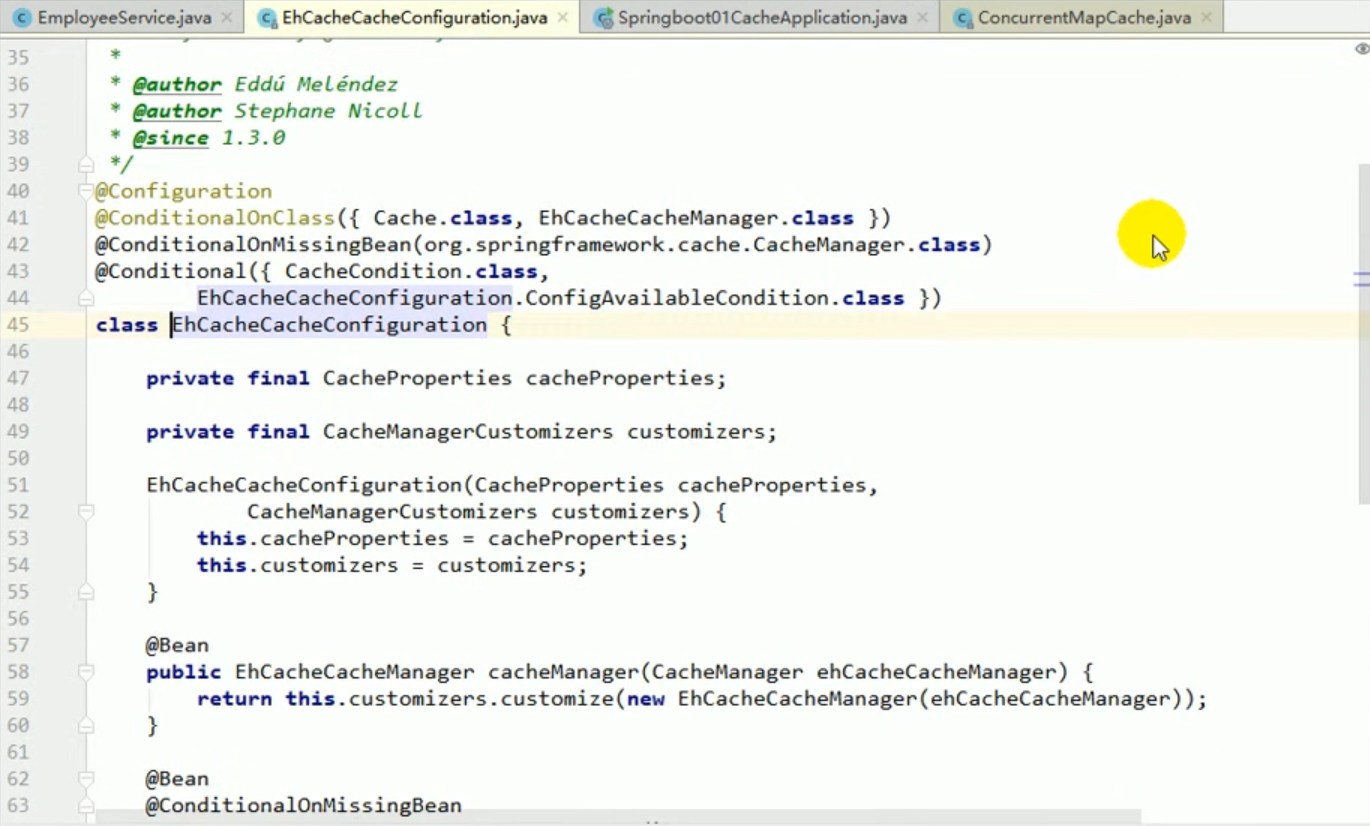
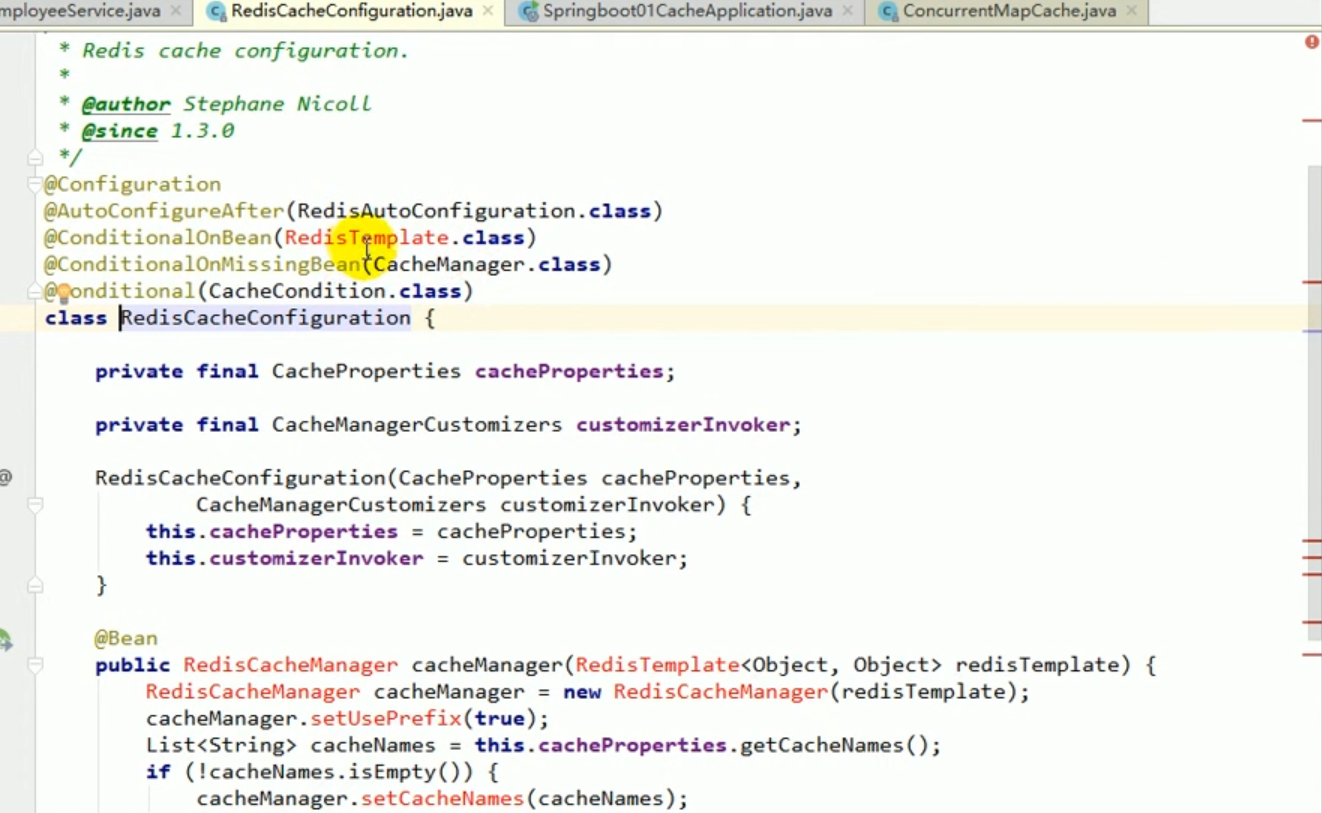
Dies alles bedeutet, dass diese Konfigurationen wirksam werden, wenn Sie das entsprechende Paket importieren.
Redis als Cache integrieren
Wenn es Schüler gibt, die die Technologie von Redis nicht kennen, gibt es ein Erklärungsvideo der Redis-Serie, das von Lehrer Zhou Yang im Shang Silicon Valley veröffentlicht wurde. Oder besuchen Sie so schnell wie möglich die offizielle Website von Redis, um mehr darüber zu erfahren. Redis.cn ist die chinesische Website für Redis-Lernen.
Redis installieren
Suche nach Redis-Image
Dies ist mit einem ausländischen Lager verbunden und die Geschwindigkeit ist relativ langsam.
Wir empfehlen die Verwendung von Docker China.
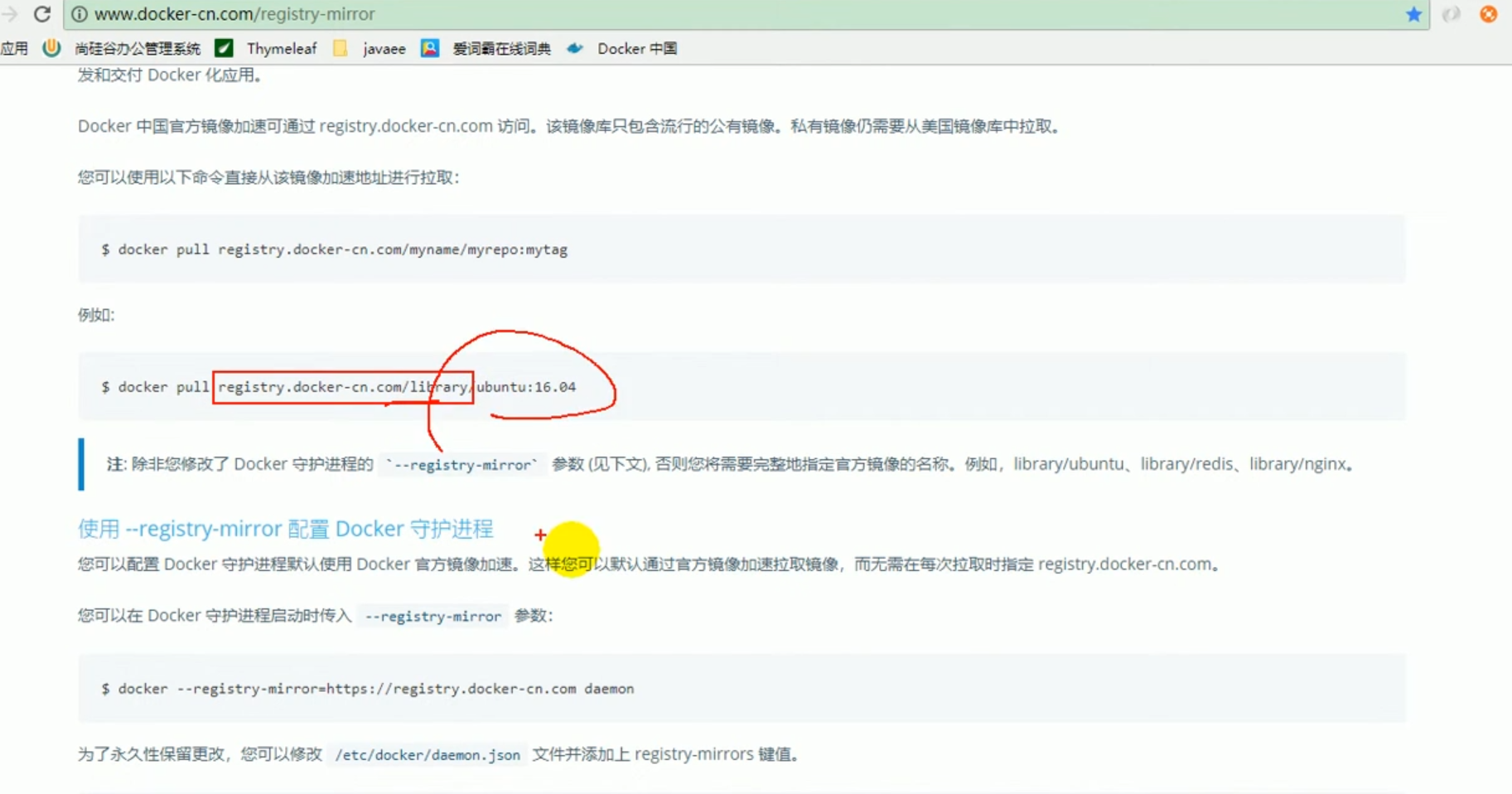
Docker Pull Registry.docker-cn.com/library/redis
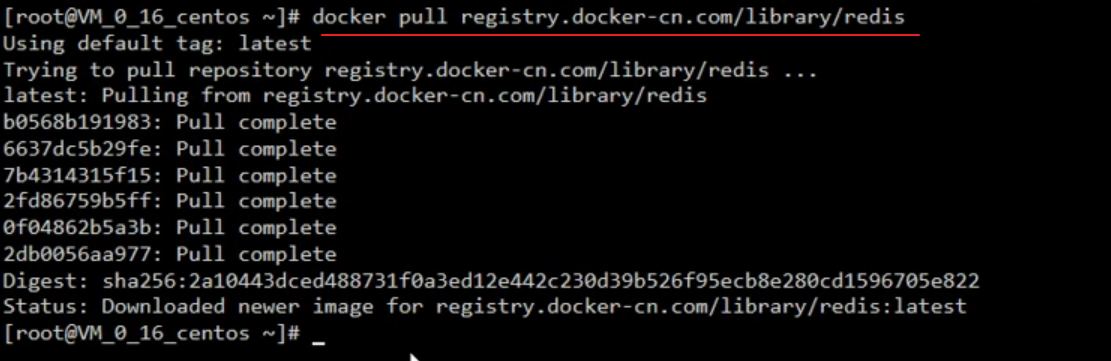

Starten Sie das Redis-Image
docker run -d -p 6379:6379 --name myredis [REPOSITORY] docker ps
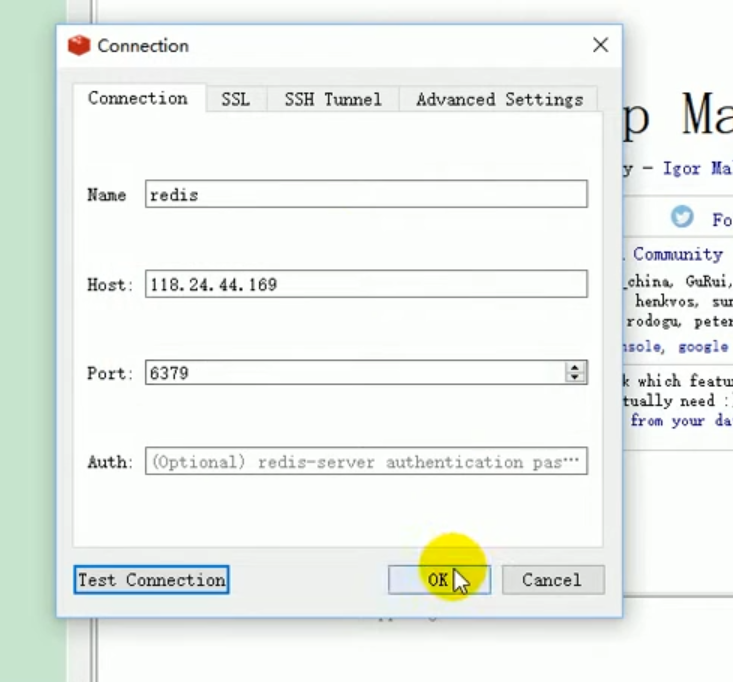
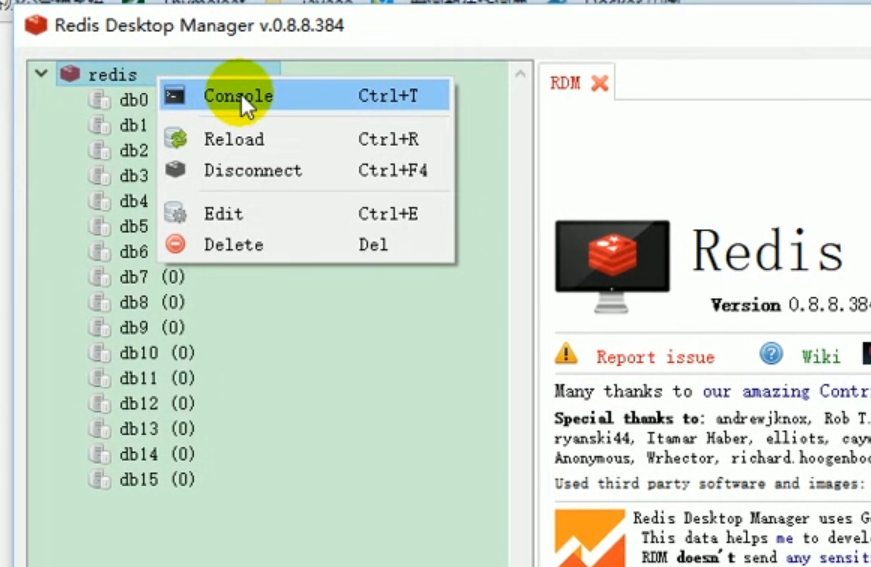
Öffnen Sie zum Testen das Redis-Verbindungstool. „Redis Desktop Manager“
Redis-Operationsliste
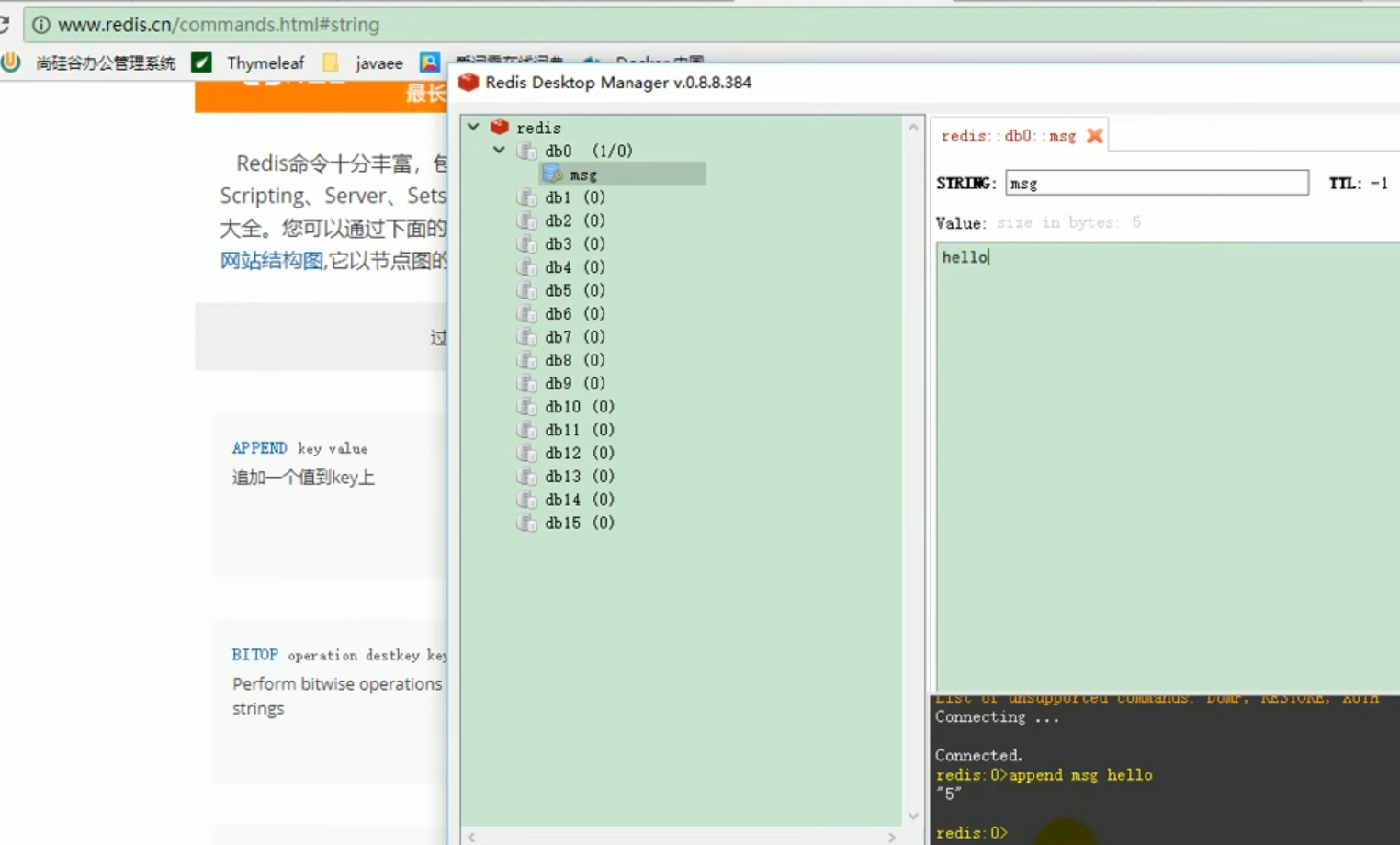
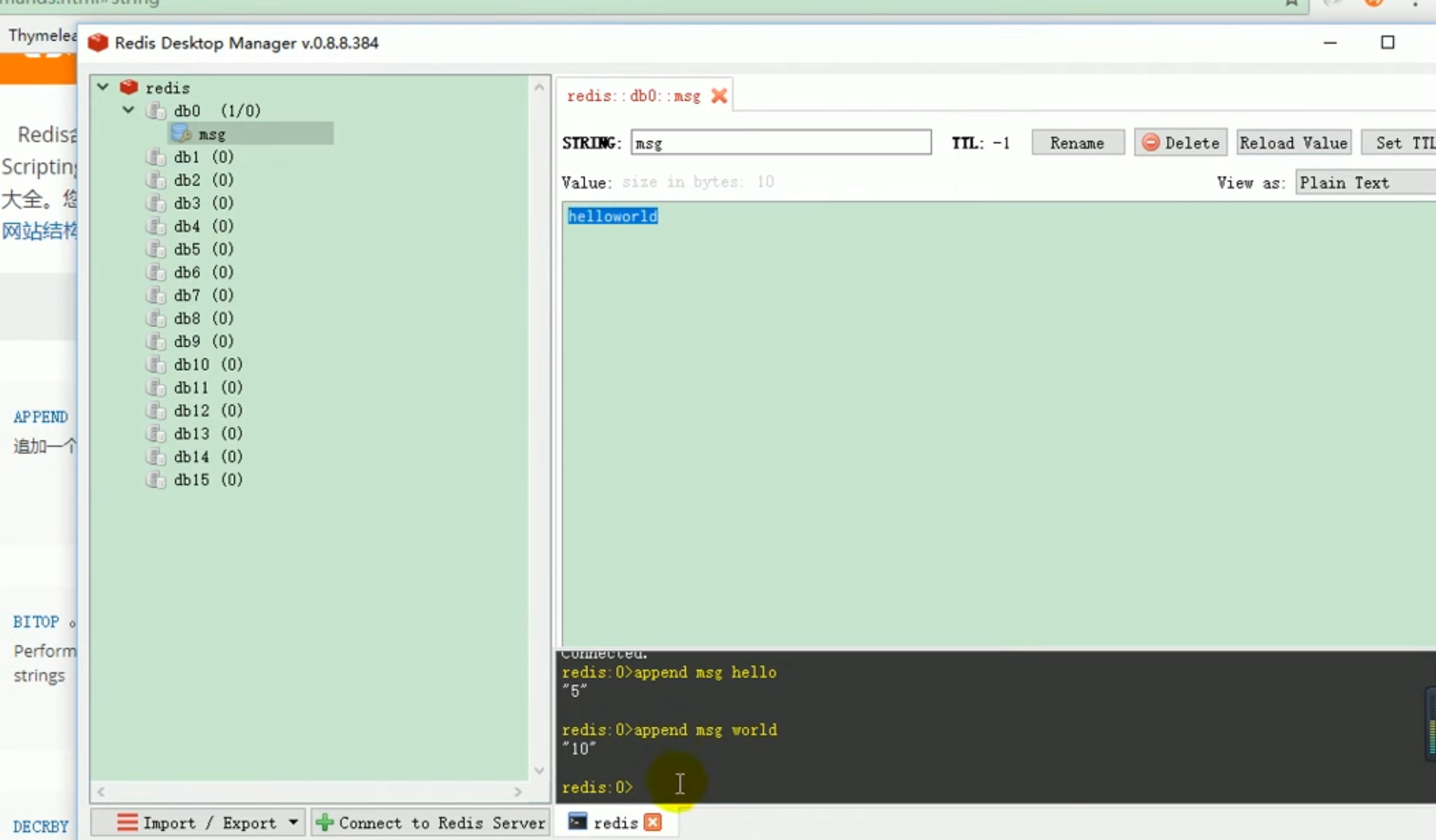 Wir stellen den Redis-Starter vor
Wir stellen den Redis-Starter vor
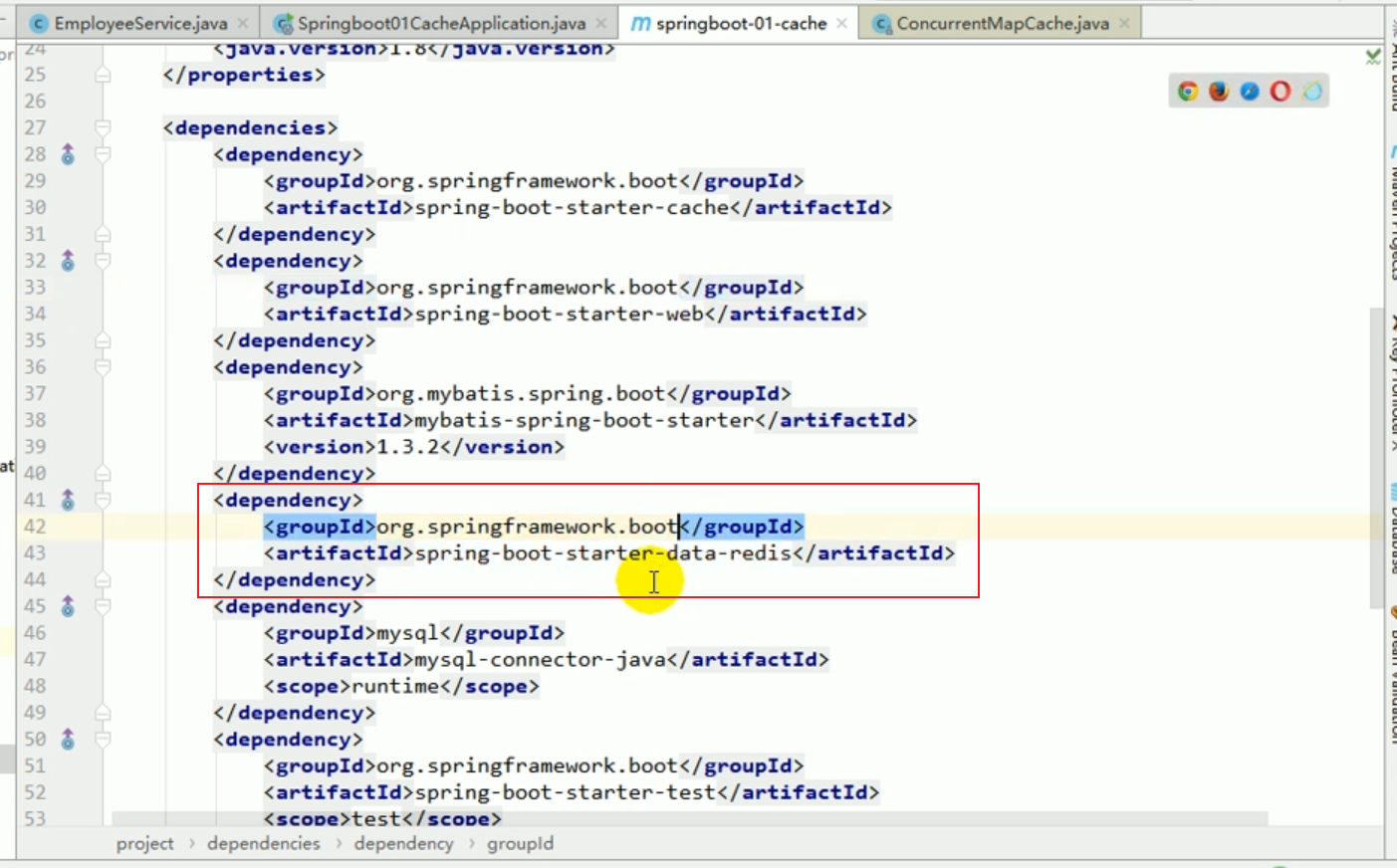
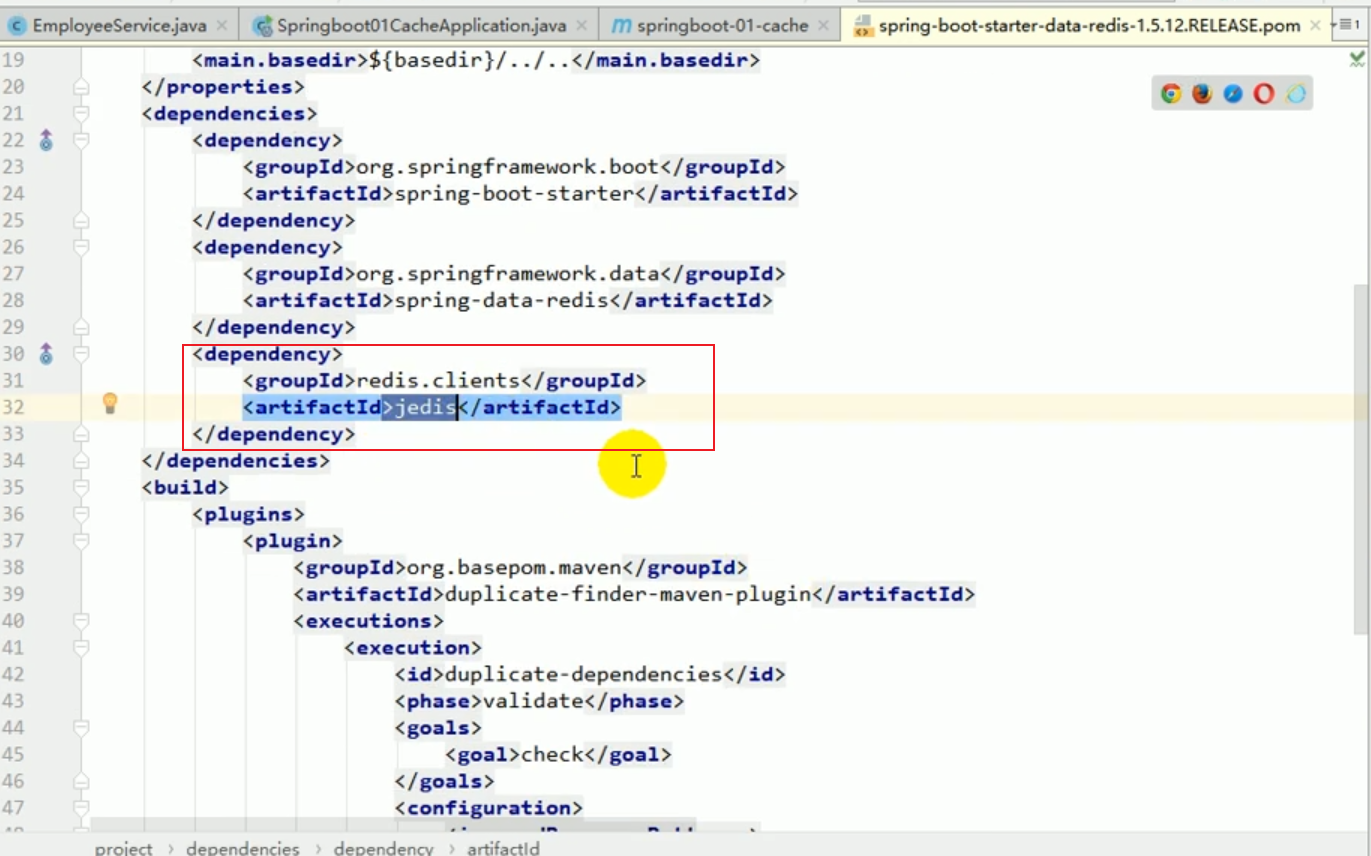
Redis konfigurieren
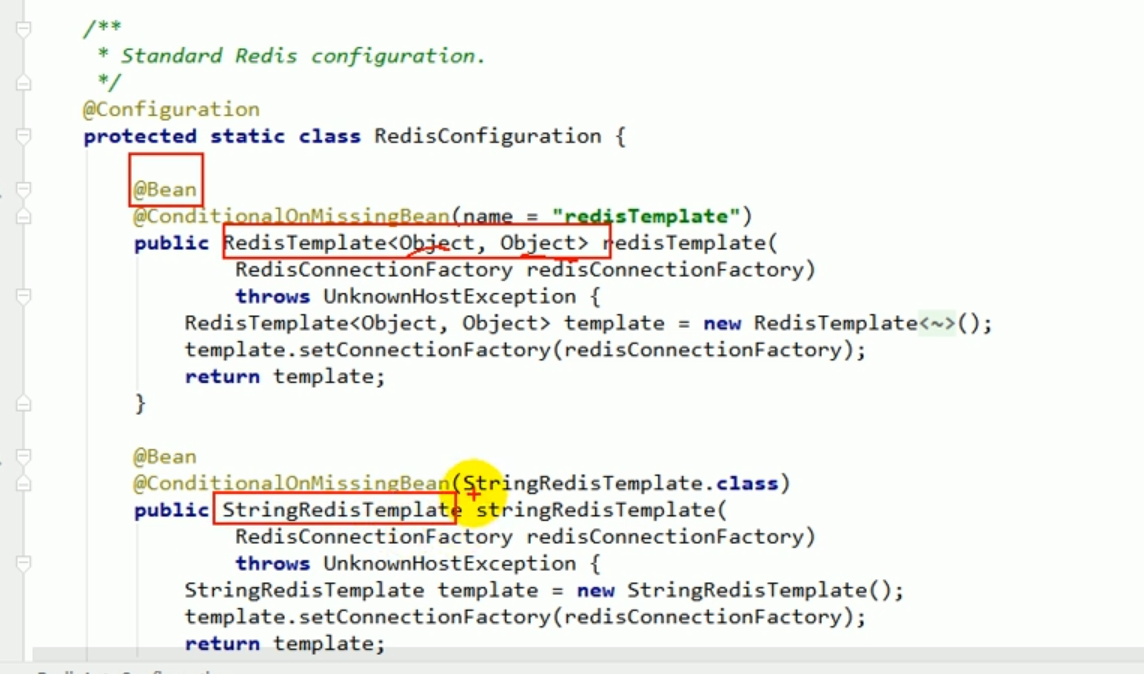 #🎜 🎜# Hinzufügen Komponenten in den Container, eine heißt RedisTemplate und die andere heißt StringRedisTemplate, zwei Dinge.
#🎜 🎜# Hinzufügen Komponenten in den Container, eine heißt RedisTemplate und die andere heißt StringRedisTemplate, zwei Dinge.
Diese beiden Dinge werden zum Betrieb von Redis verwendet.
Dies ist das gleiche wie die jdbcTemplate, die alle zuvor zum Betrieb der Datenbank verwendet haben.
Dies sind die beiden Vorlagen, die Spring verwendet, um die Bedienung von Redis zu vereinfachen. Wenn Sie diese beiden Dinge im Programm verwenden möchten, fügen Sie sie einfach automatisch ein. #? #
Redis-Operationsliste:
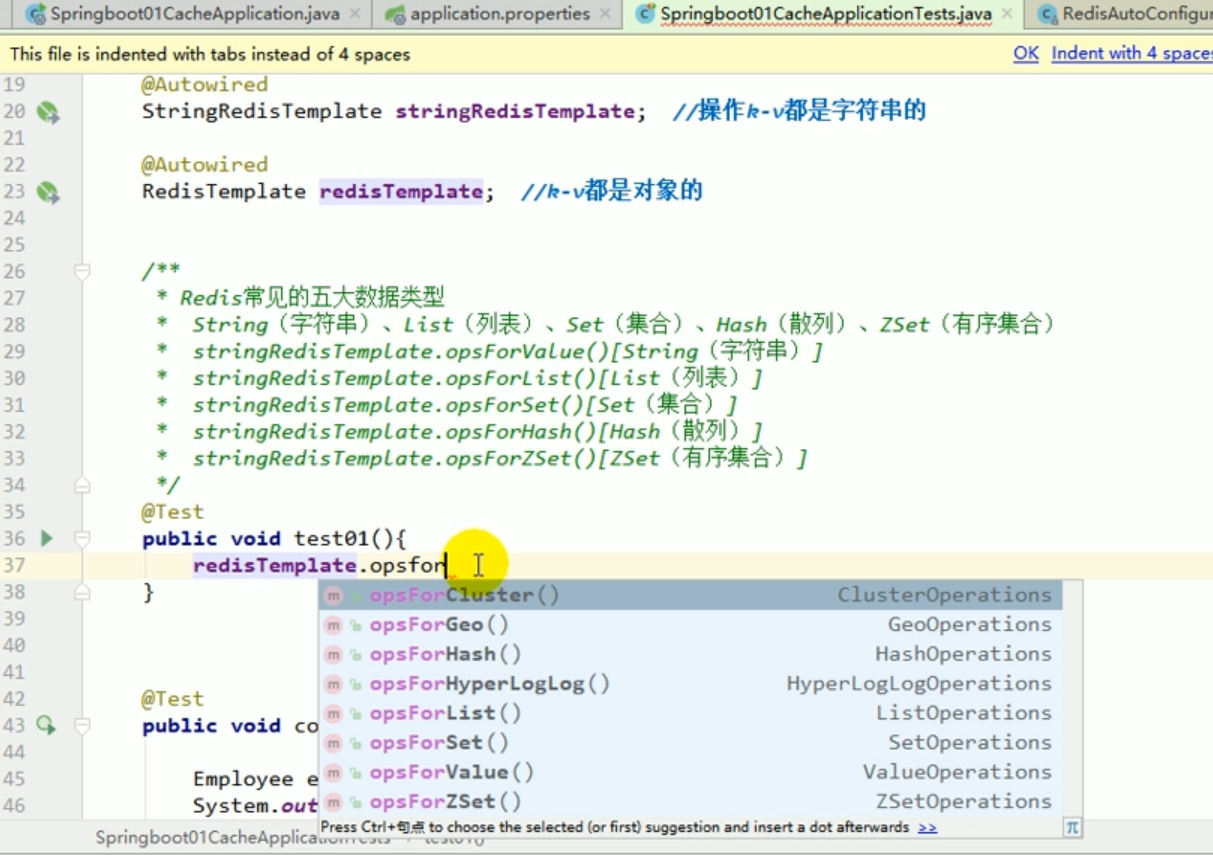
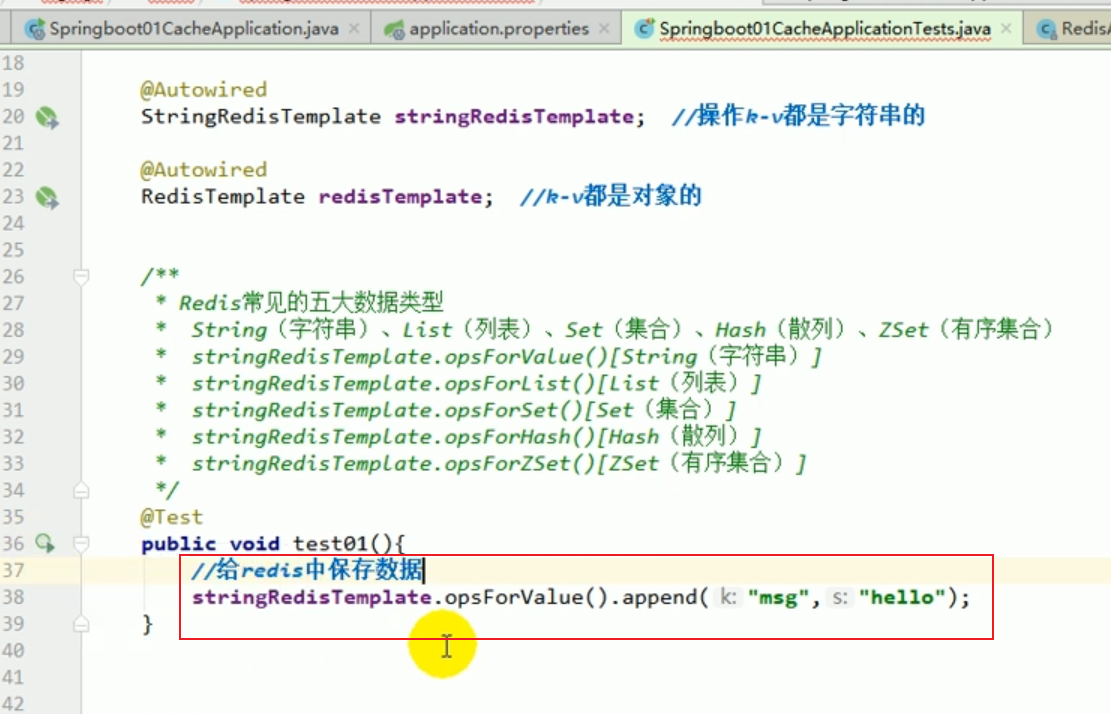
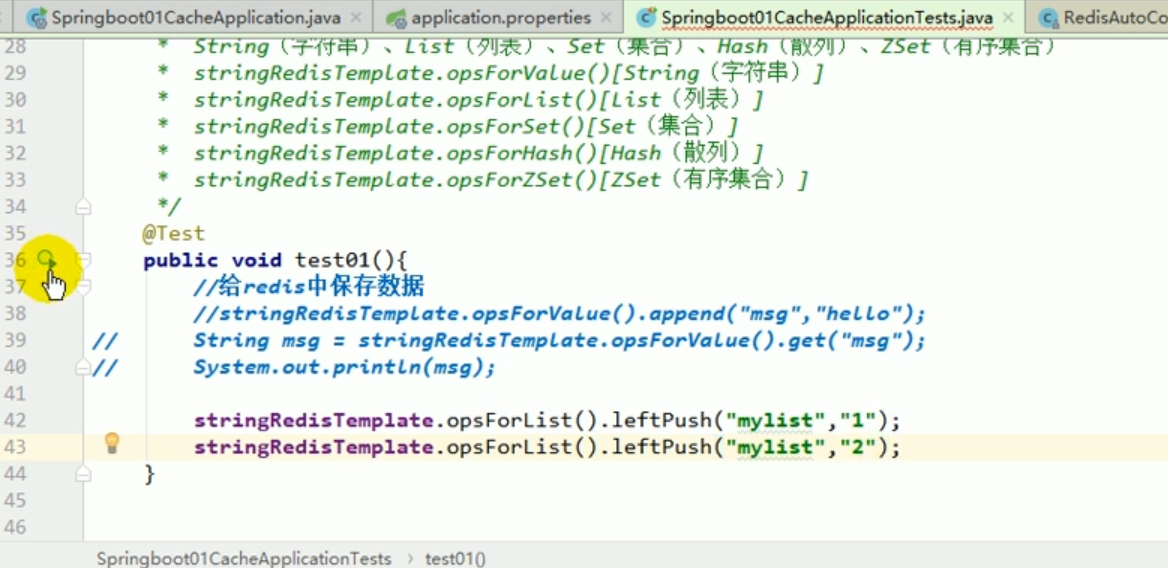
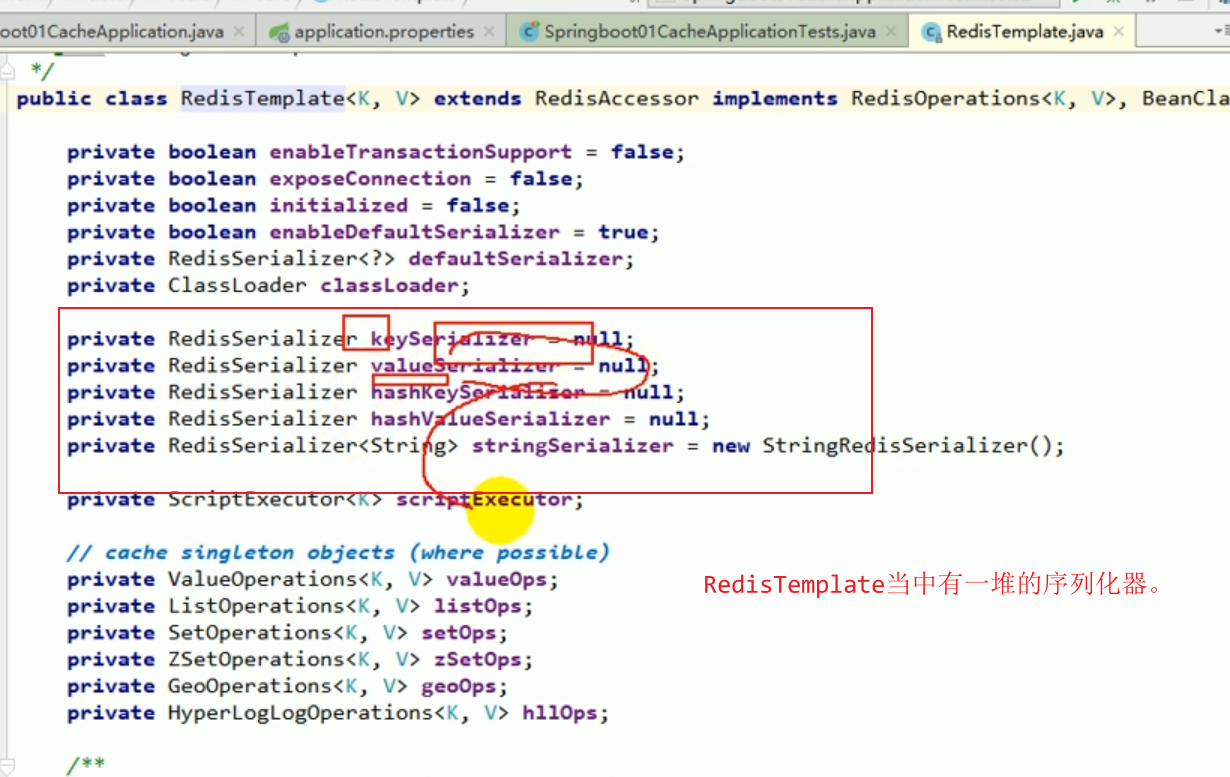
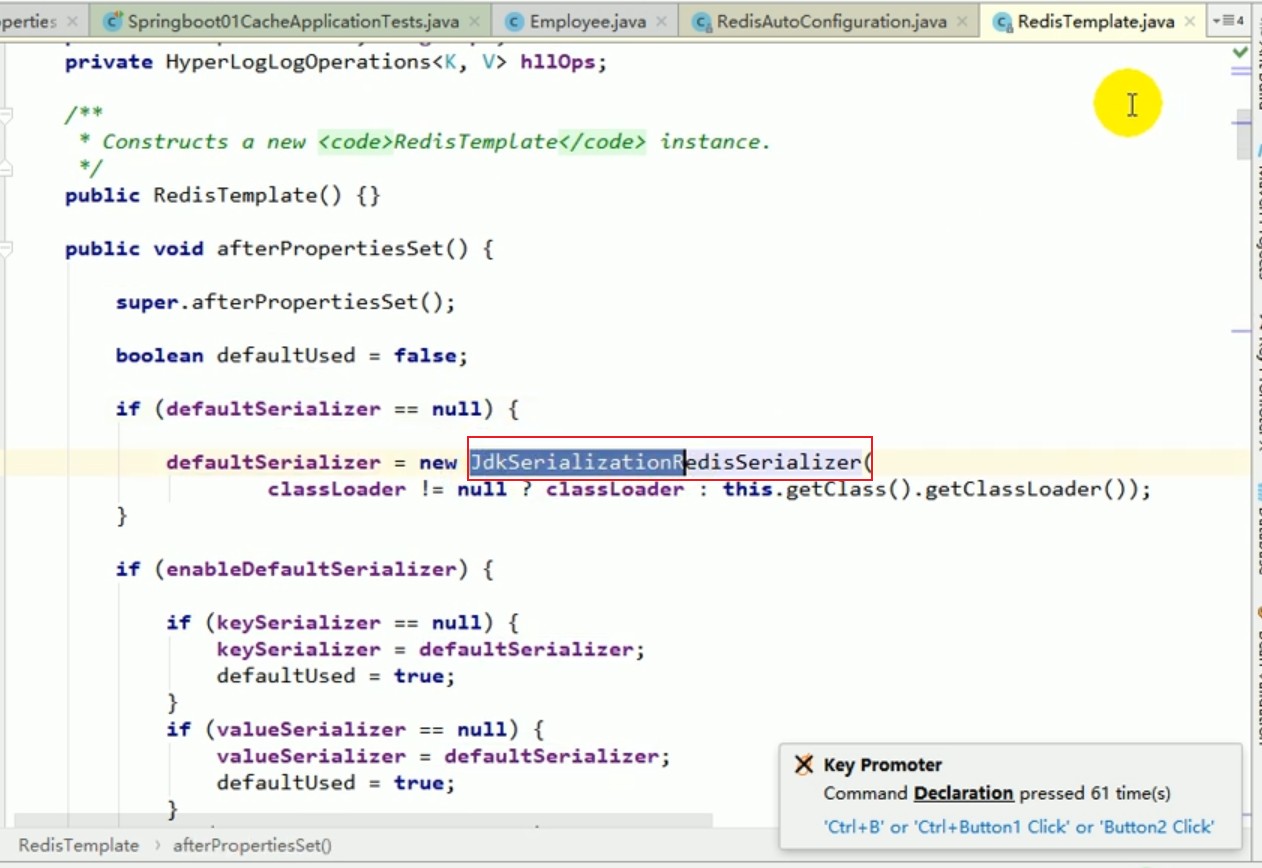
Diese unverständlichen Dinge sind alle das Ergebnis der Serialisierung. #🎜🎜 ## 🎜🎜#redistemplate Standard -Serialisierungsregeln#🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜##🎜 🎜 🎜#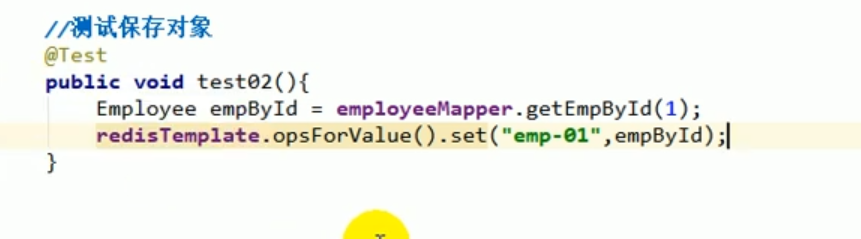 Der Standard-Serializer ist der verwendete JdkSerializationRedisSerializer.
Der Standard-Serializer ist der verwendete JdkSerializationRedisSerializer.
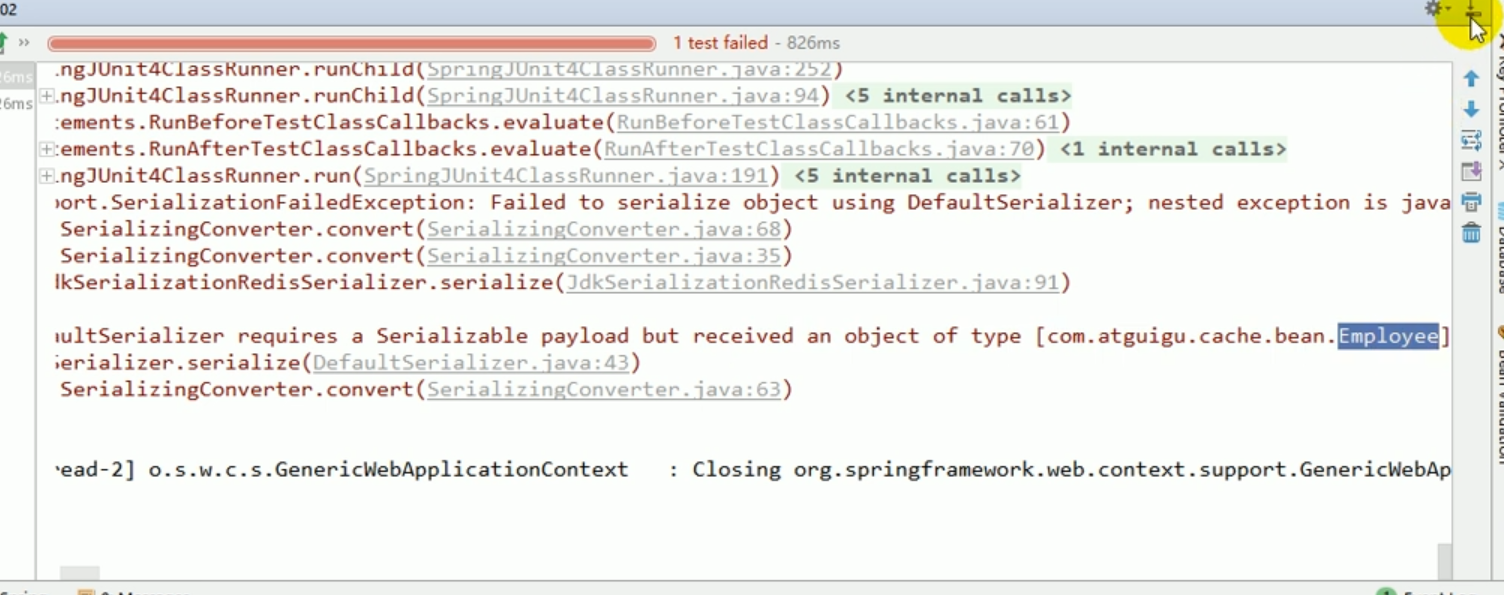
Der Standard-Serializer ist der verwendete JDK-Serializer. 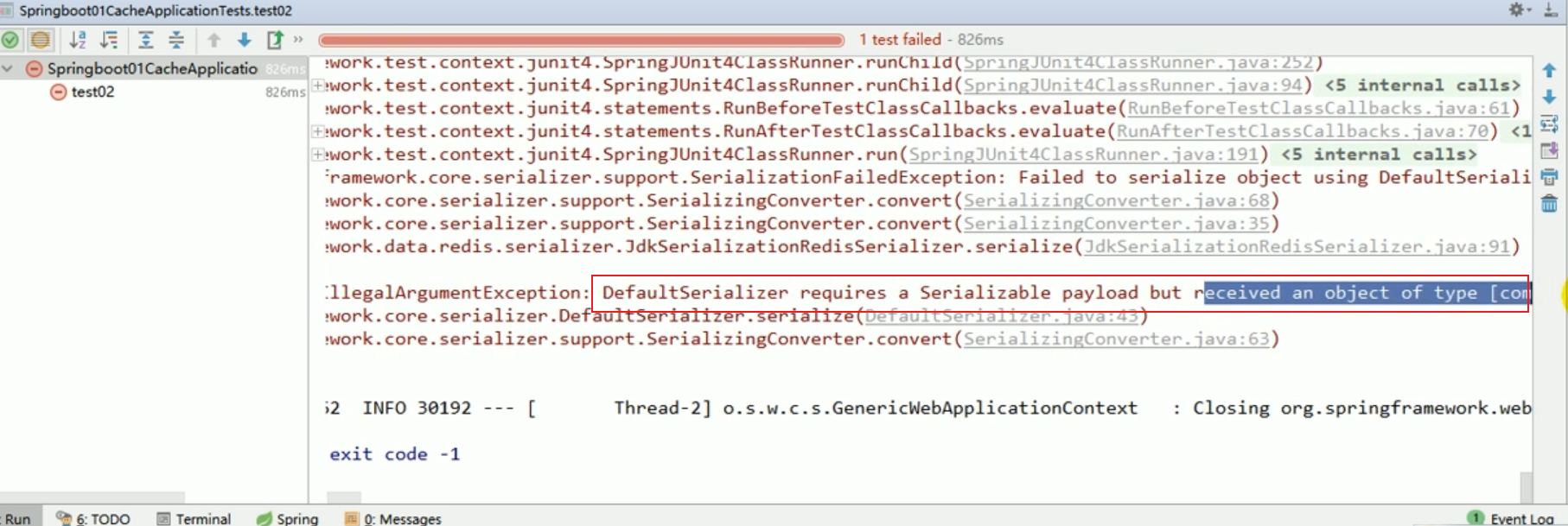
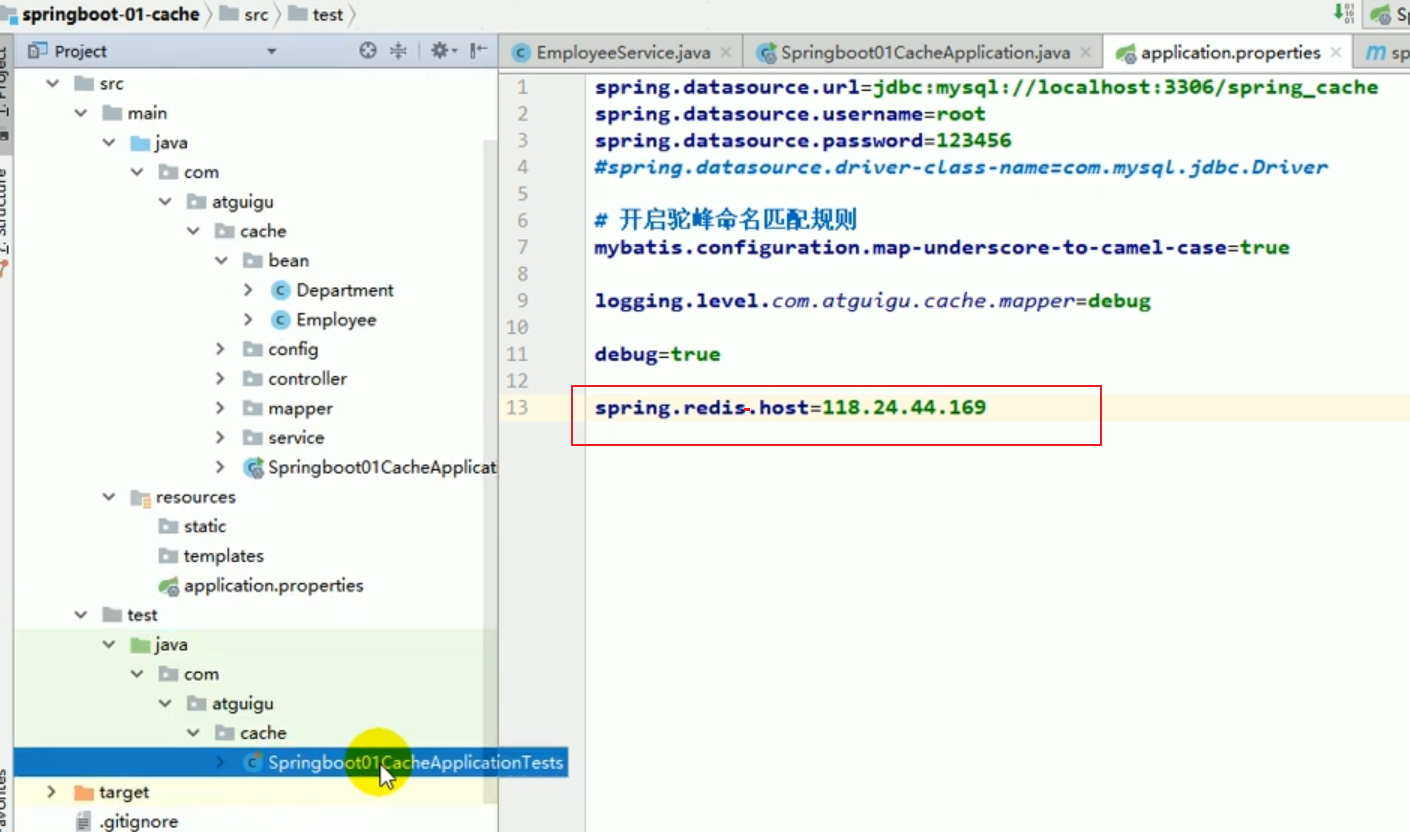
 Redis-Konfiguration
Redis-Konfiguration
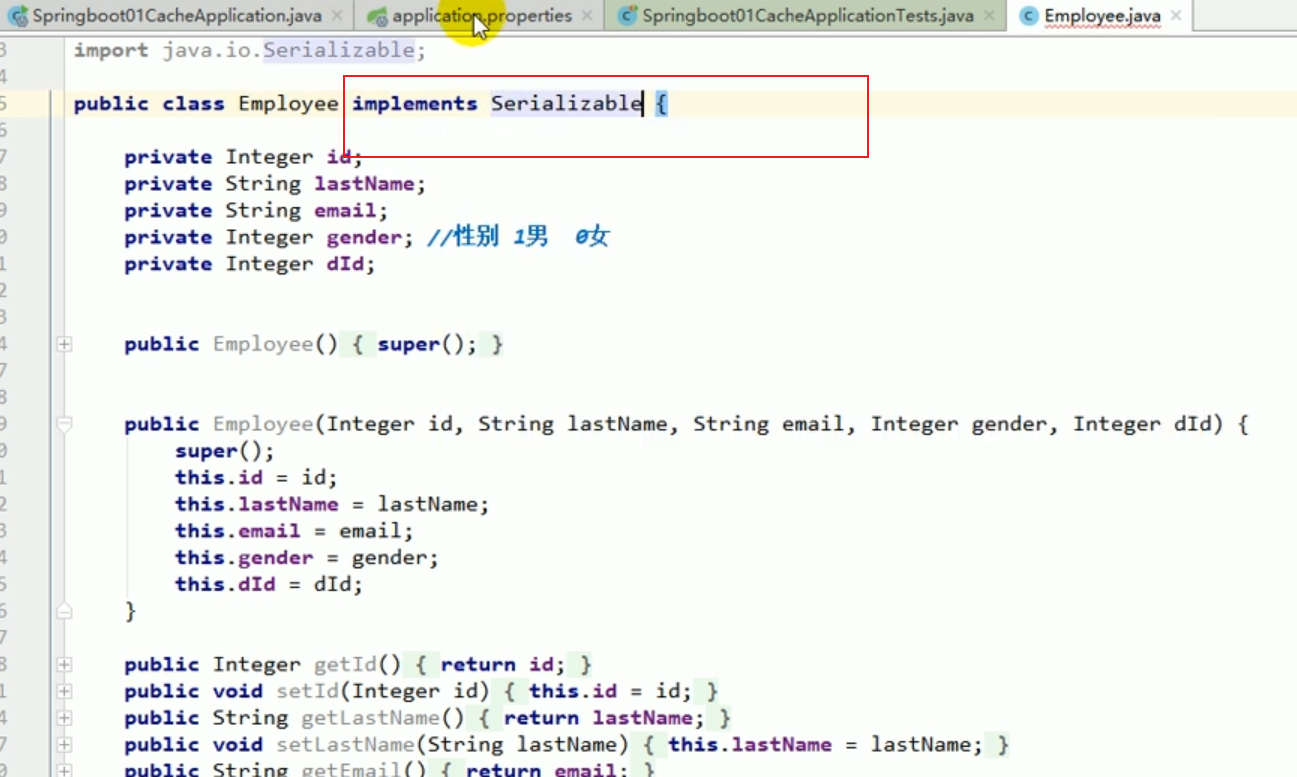
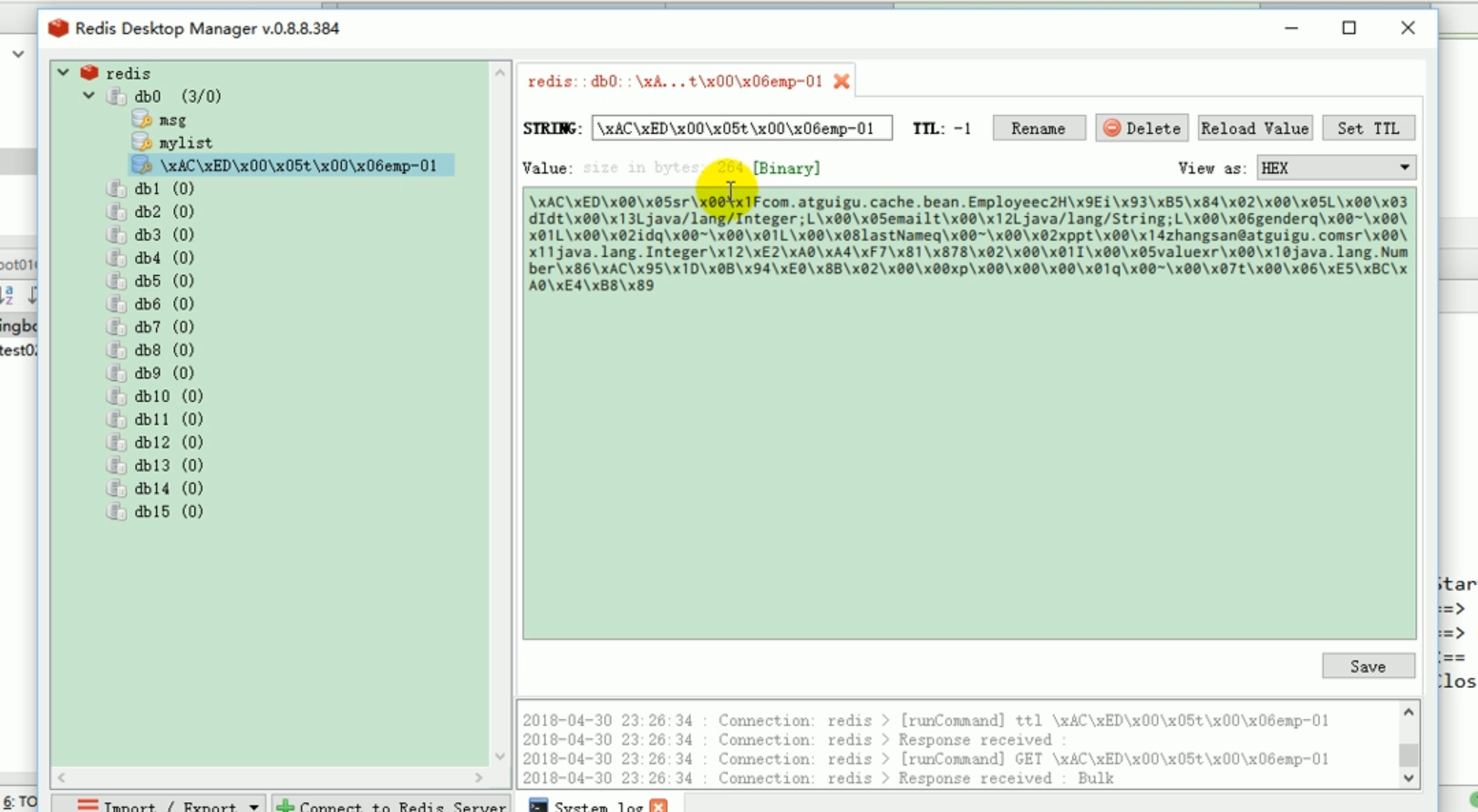
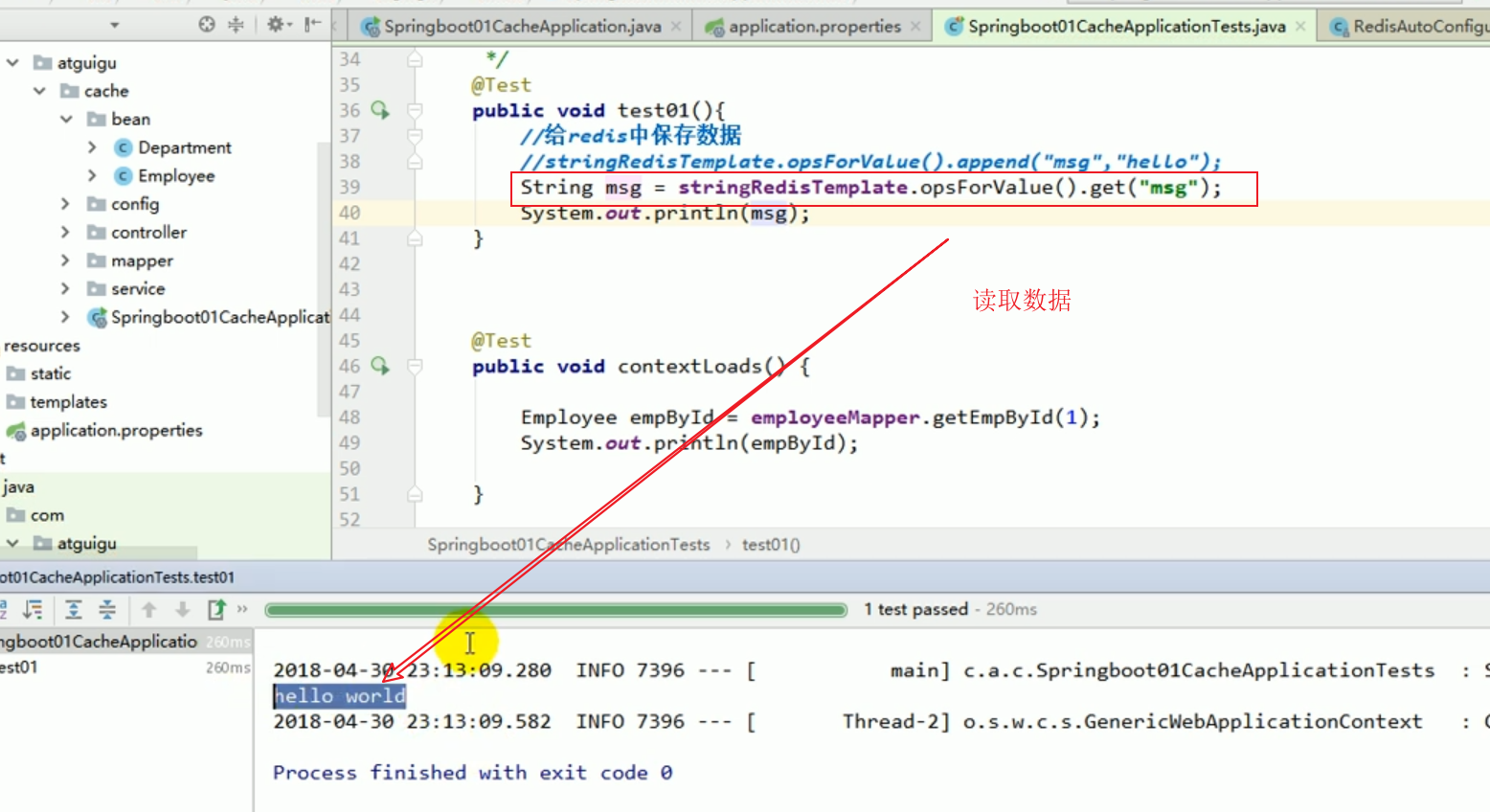
In der Testklasse sind wir automatisch dabei injiziert Konfigurieren Sie Ihr eigenes redisTemplate.
 Anschließend testen wir das Speichern des Objekts erneut.
Anschließend testen wir das Speichern des Objekts erneut.
Dies zeigt, dass unsere Serializer-Modifikation erfolgreich war.
Dadurch wird deutlich, dass wir häufig den Serializer ändern müssen, wenn wir das Objekt später speichern möchten.
Cache testen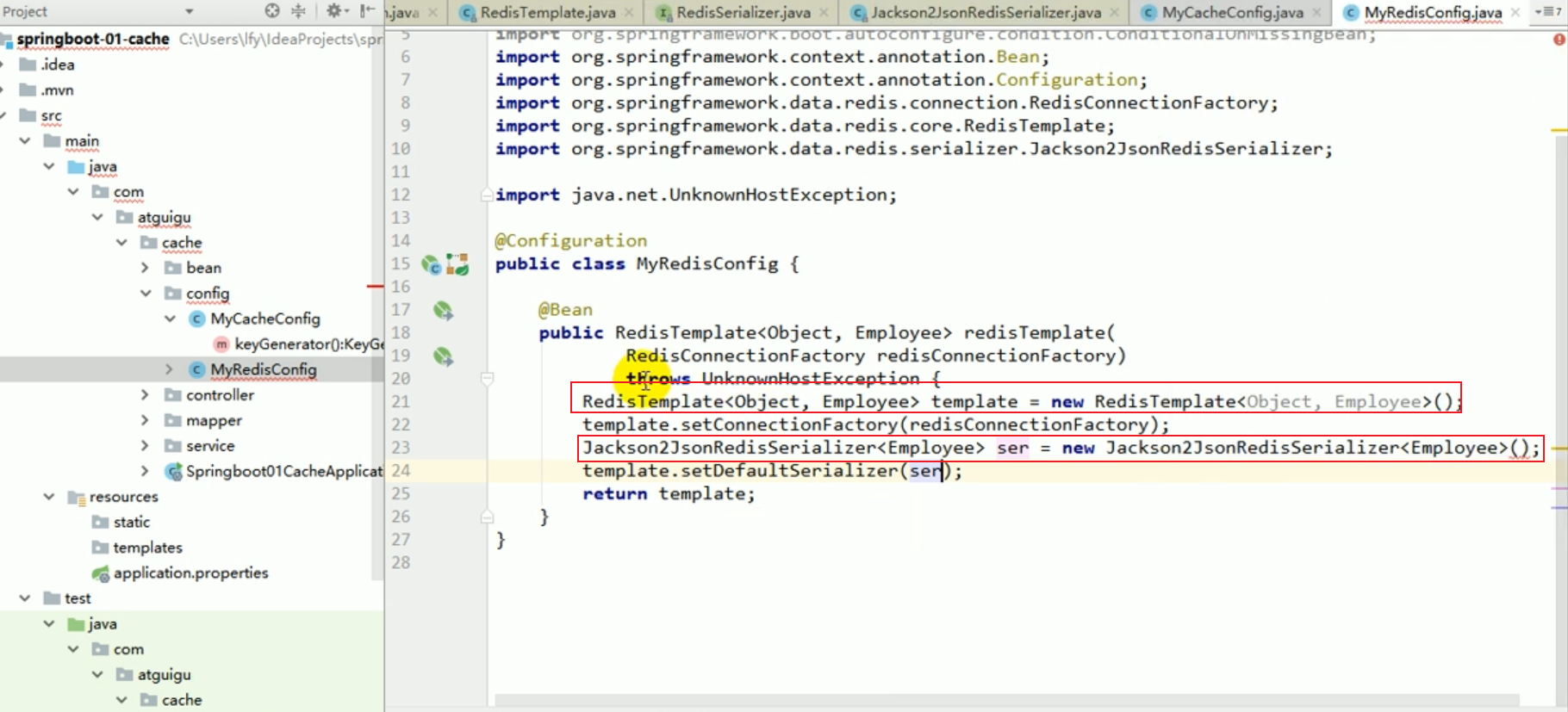
Wir haben zuvor den Cache-Manager von ConCurrentMap verwendet.
Dieser Cache-Manager hilft uns beim Erstellen von Cache-Komponenten.
Die Cache-Komponente wird zum tatsächlichen Zwischenspeichern und Durchführen von CRUD-Arbeiten verwendet.
Was wird nun passieren, nachdem wir Redis eingeführt haben?
Wir setzen immer noch debug=true in application.properties, damit der automatische Konfigurationsbericht aktiviert werden kann.
Zu diesem Zeitpunkt starten wir unser Programm neu und suchen in der Konsole.
Mal sehen, welche automatische Konfigurationsklasse effektiv ist?
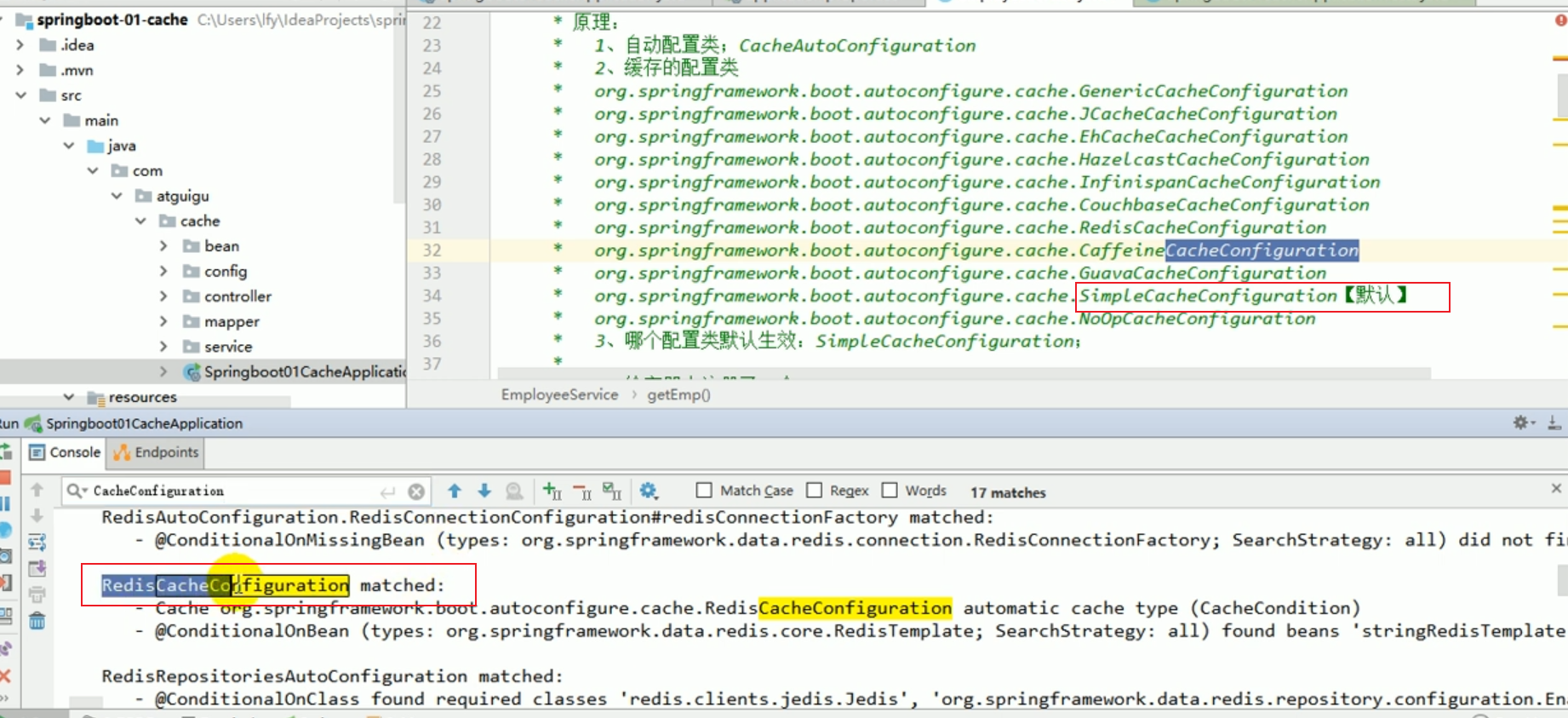
Es stellt sich heraus, dass SimpleCacheConfiguration standardmäßig aktiviert ist.
Nachdem wir die Redis-bezogenen Starter eingeführt haben, aktiviert das Programm standardmäßig RedisCacheConfiguration.

Einfach das Programm starten und direkt testen.
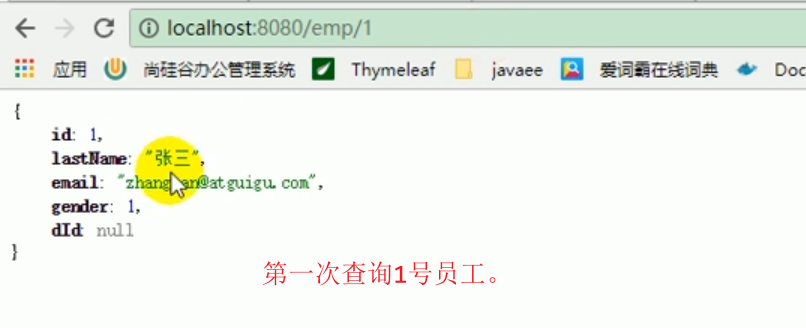

Das bedeutet, dass Sie bei der ersten Abfrage die Datenbank abfragen.
Bei der zweiten Abfrage gab es keine Ausgabe auf der Konsole, was darauf hinweist, dass der Cache abgefragt wurde.
Cache ist standardmäßig nur von Redis aktiviert.
Dann muss es in Redis sein.
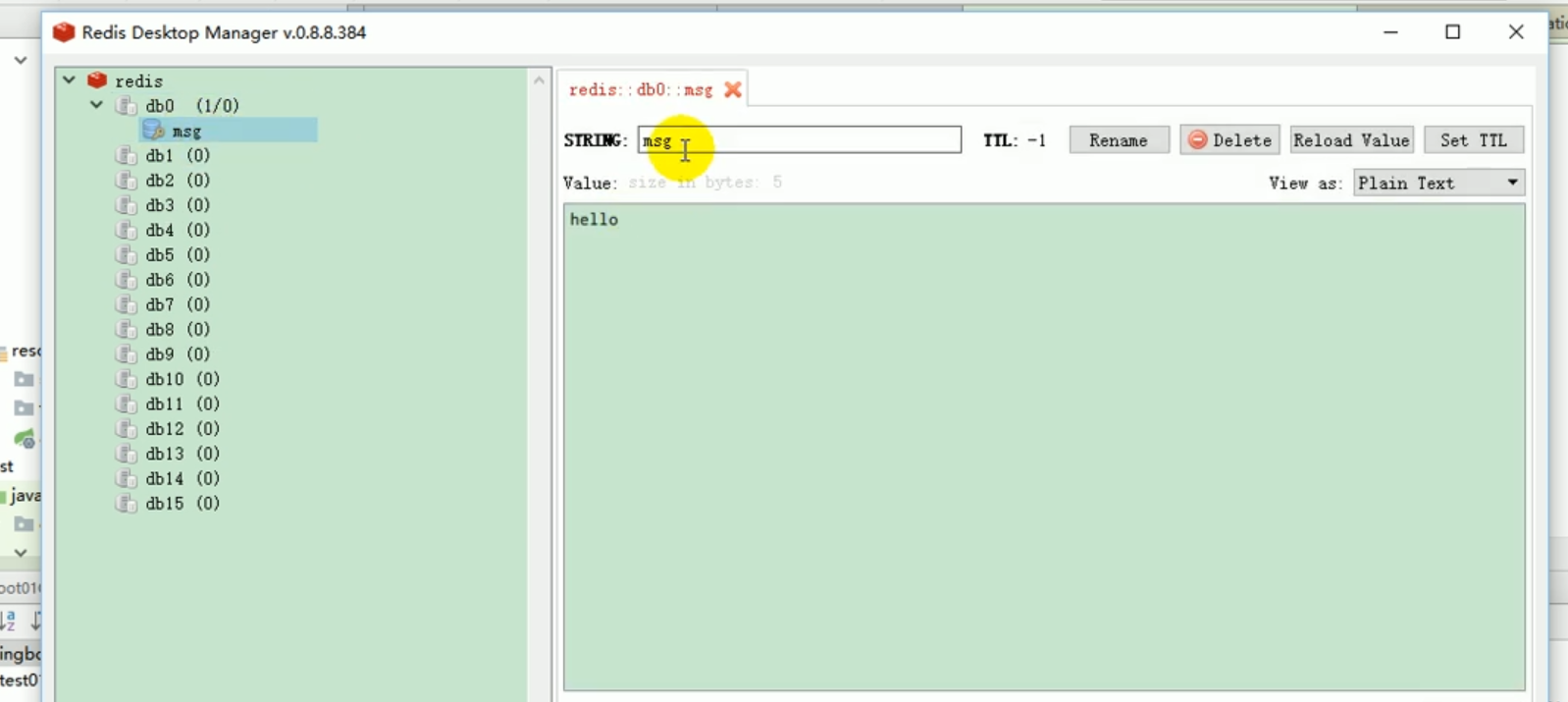
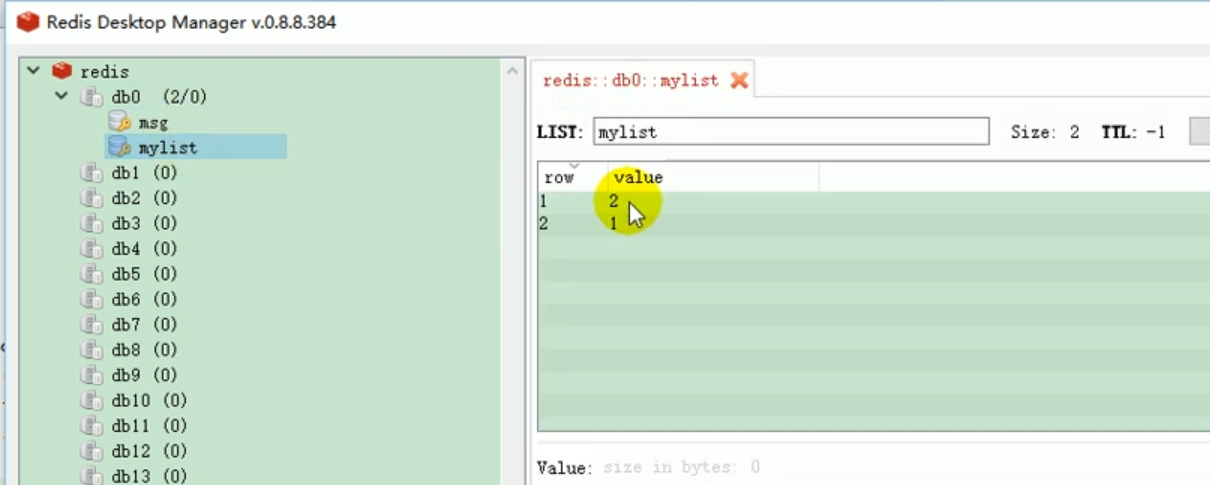
Wir können es überprüfen:
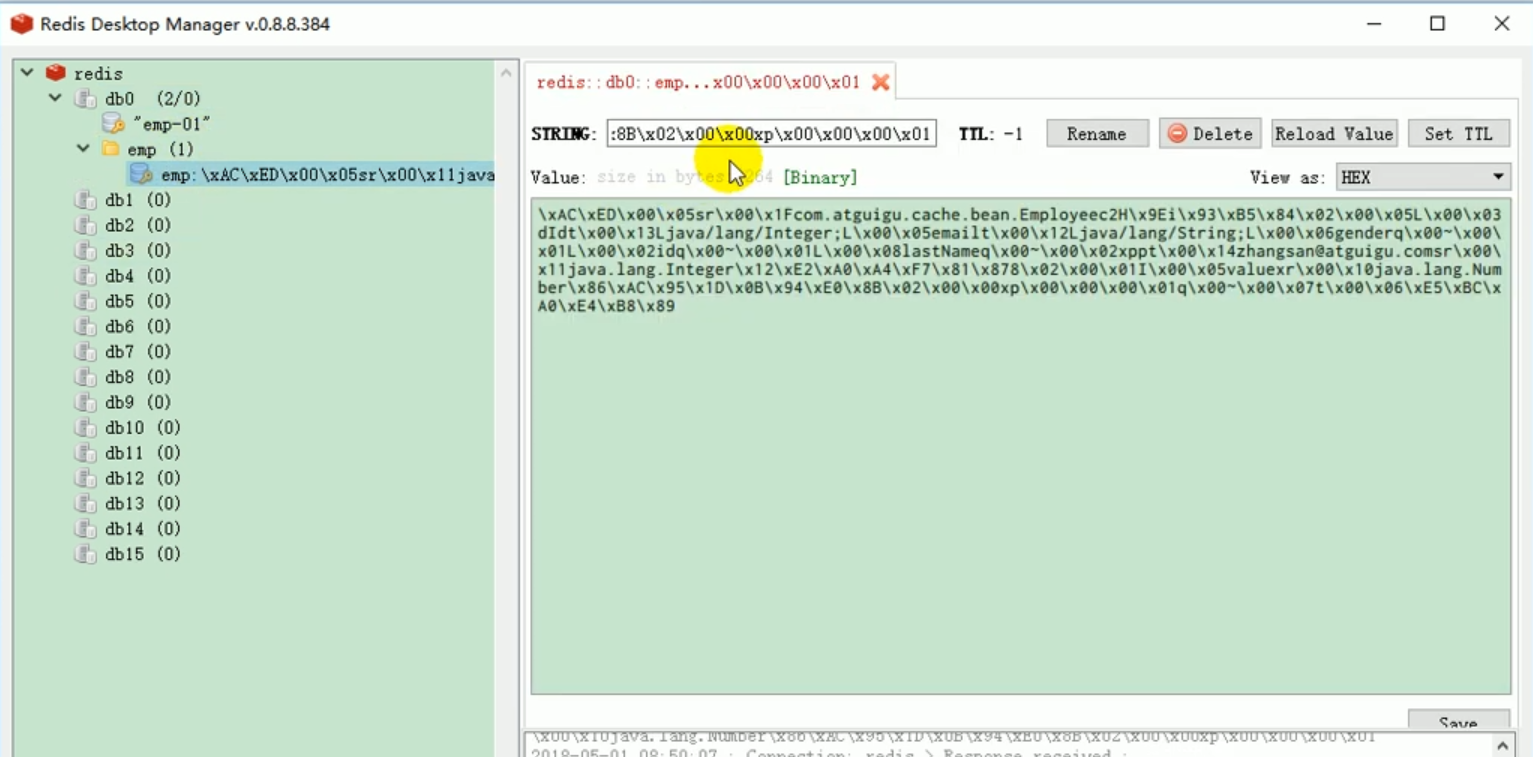
Dies veranschaulicht ein Problem, wenn k und v beide Objekte sind, werden sie gespeichert Standardmäßig werden Objekte mithilfe der Serialisierung gespeichert. Wir möchten, dass Redis es automatisch als JSON speichert.
Was sollen wir tun?
Lassen Sie uns zunächst die Prinzipien dieser Prozesse analysieren.
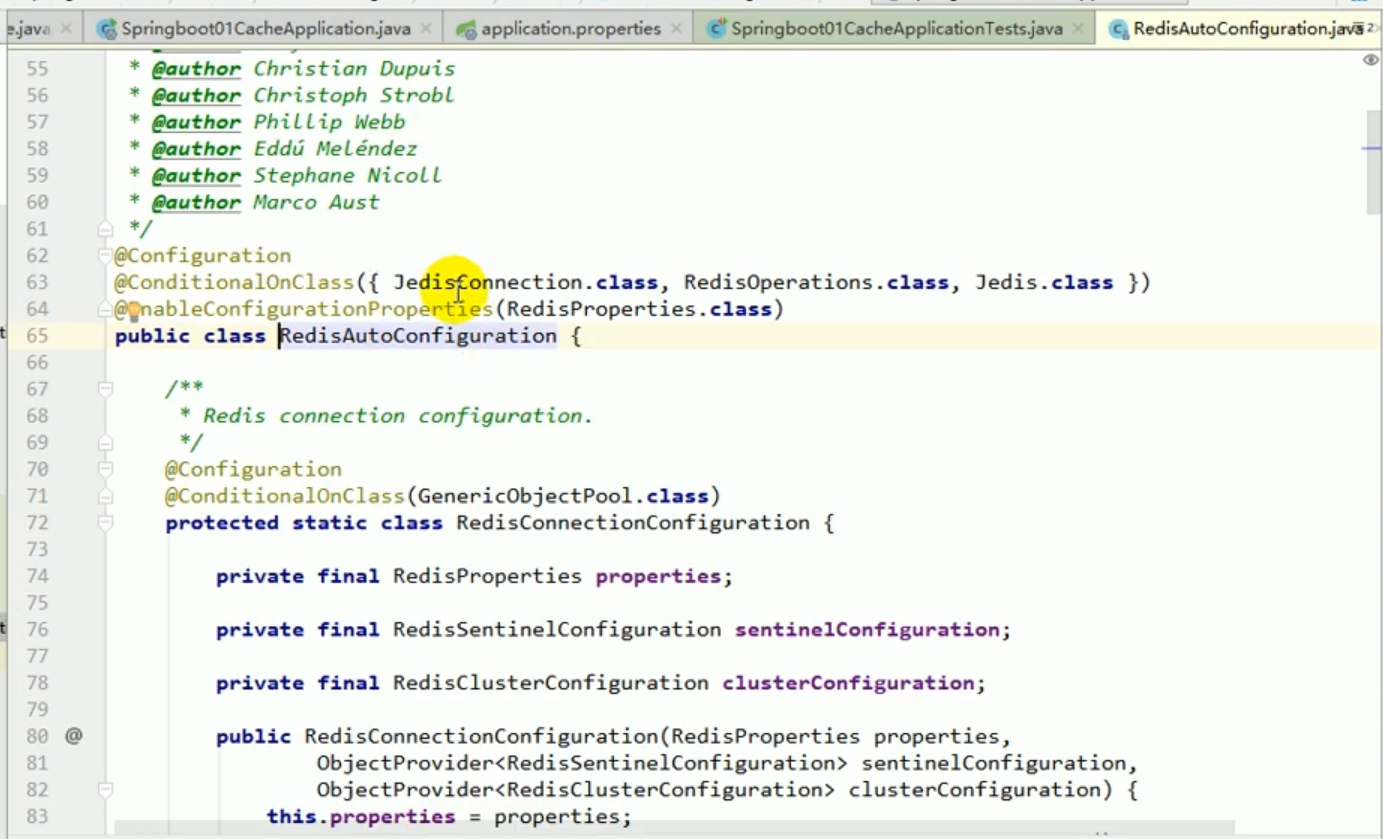
1. Wir haben den Starter von Redis eingeführt, daher ist unser Cachemanager zum Rediscachemanager geworden,
2. Wenn der Rediscachemanager standardmäßig erstellt wird und unsere Daten verarbeitet, wird er eingefügt eine Redestemplate-Sache.

3 Dieses Redistemplate wurde für uns von redisautoconfiguration erstellt. Der von dieser Redistemplate verwendete Standard-Serialisierungsmechanismus ist jdkserializationredisserializer. Dies entspricht der Tatsache, dass der von Redis standardmäßig verhinderte redisCacheManager unseren Anforderungen nicht ganz entspricht.
Was sollen wir tun?
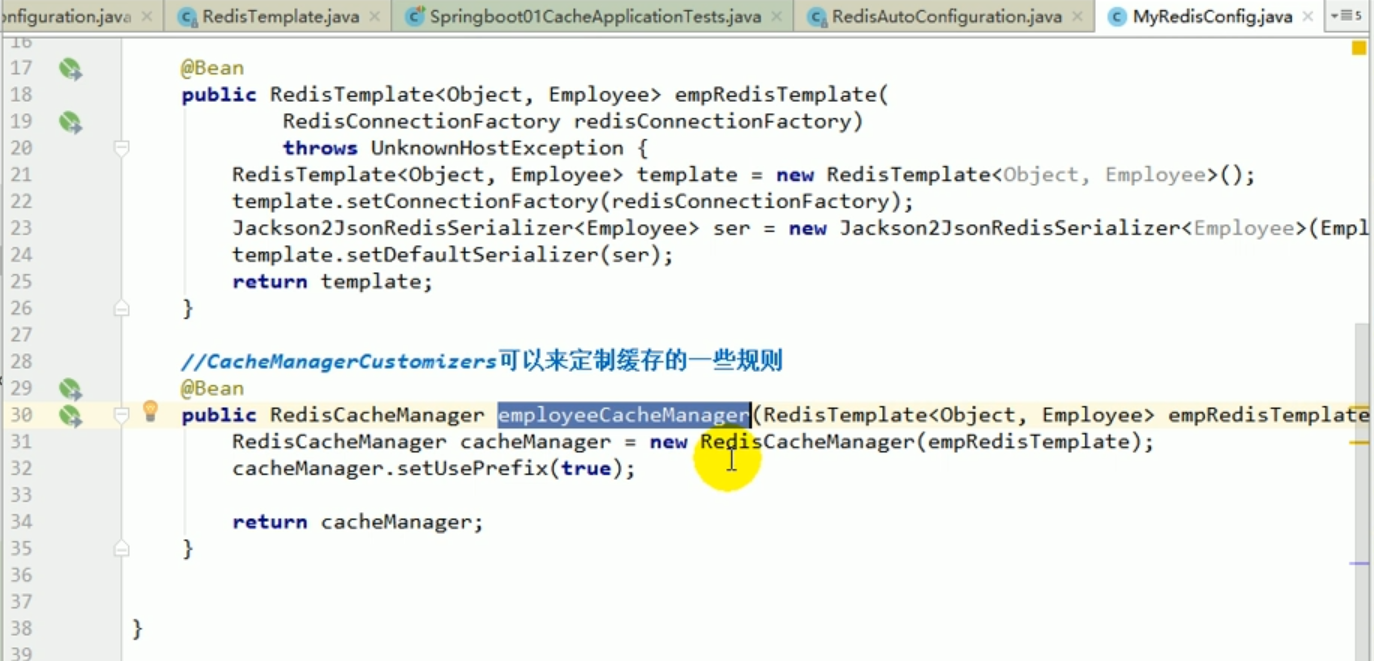
Wir sollten CacheManager anpassen.
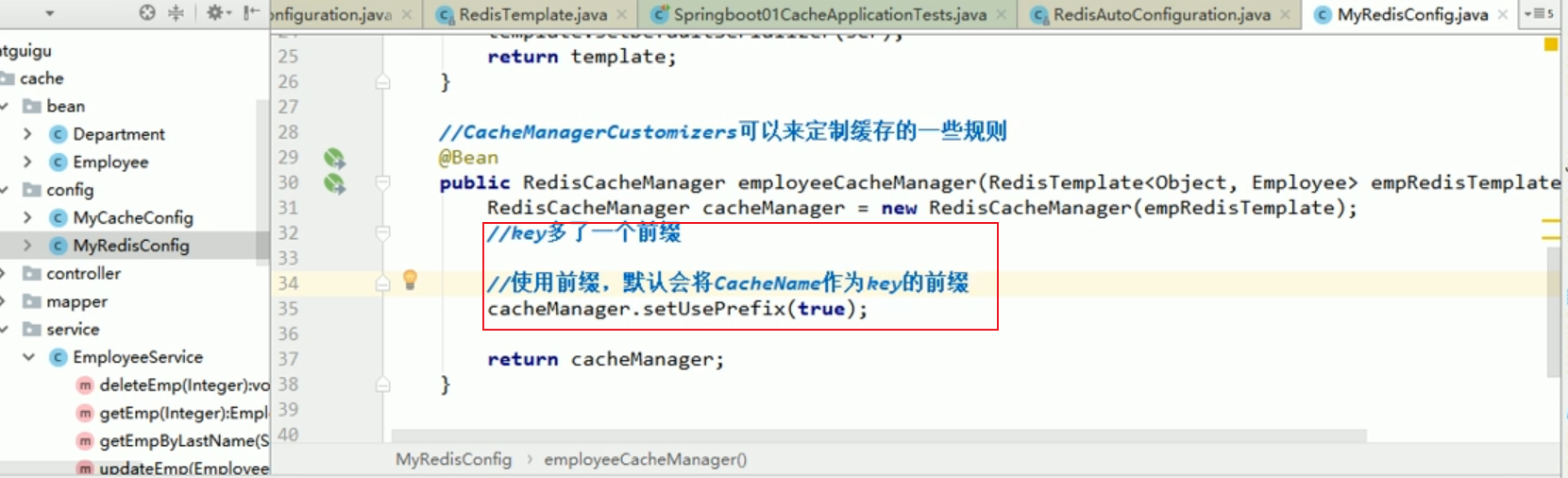
Angepasster redisCacheManager
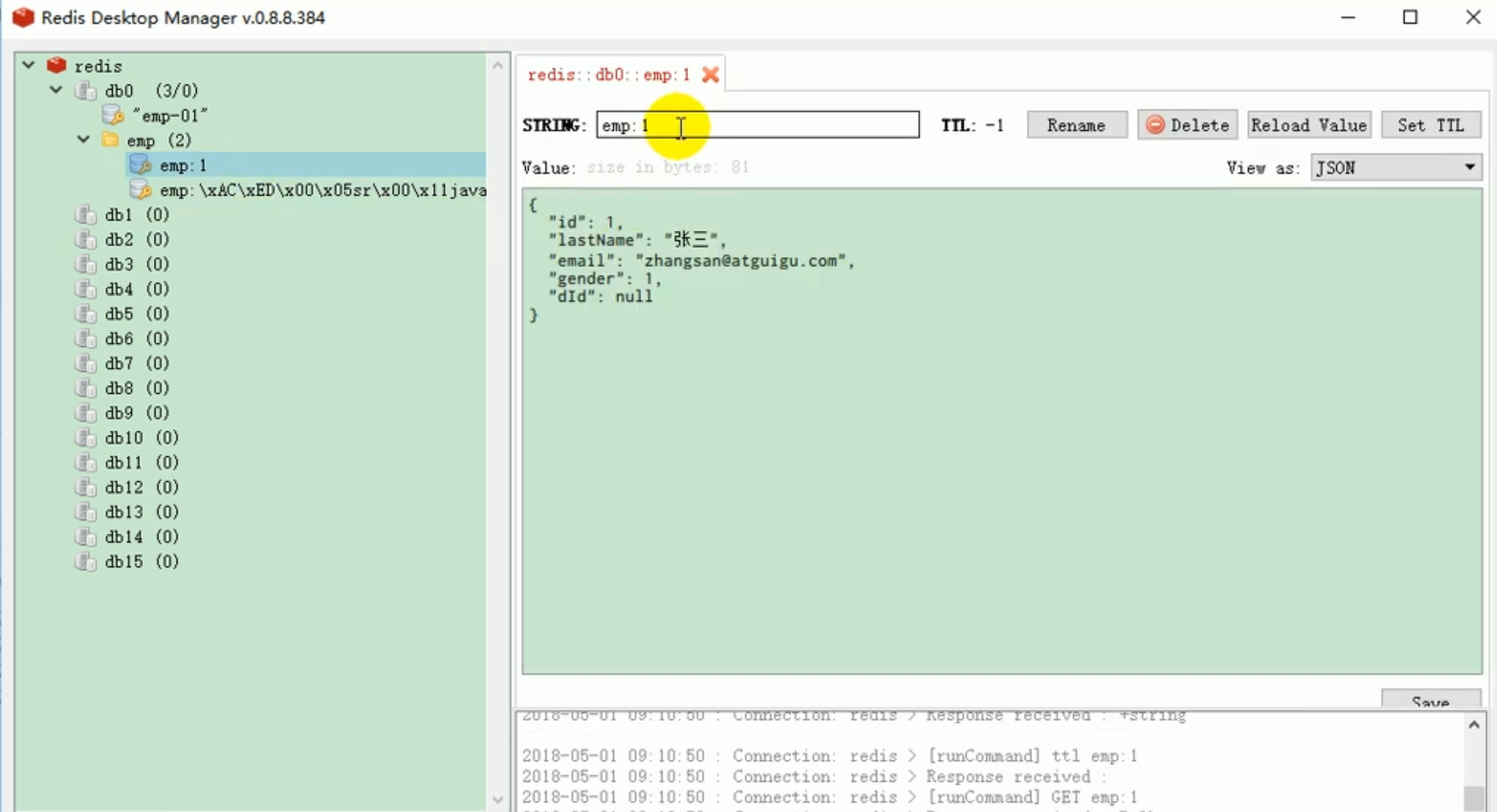
Zu diesem Zeitpunkt können wir das Projekt erneut zum Testen starten Ergebnis in Redis ist das, was wir wollen.
Während des nächsten Interviews kann Yun Qiu diejenigen, die in den Softwarepark kommen möchten, fragen: Kennen Sie den Redis-Starter? Was sind die Standard-Serialisierungsregeln von redisTemplate beim Speichern von Objekten?
Was sollen wir tun, wenn wir die Standard-Serialisierungsregeln bei Verwendung von Redis ändern möchten?
Wir können redisCacheManager anpassen, dann redisTemplate anpassen und den JSON-bezogenen Serializer in redisTemplate übergeben.
Wenig verbleibende Probleme
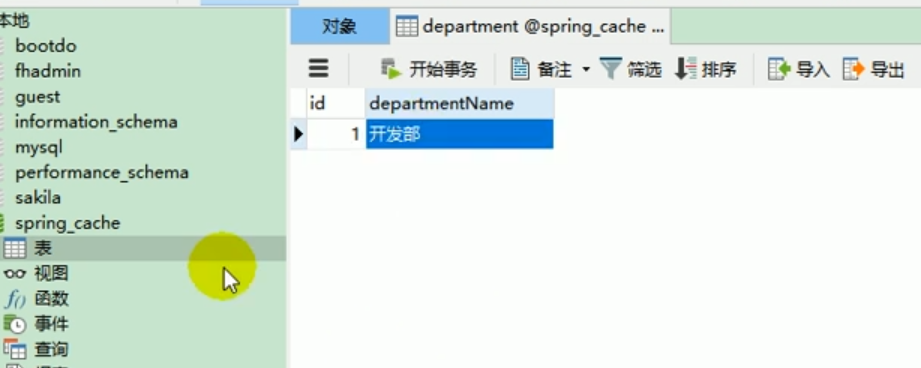
Datenbank
Was wir in der Datenbank haben , fügen Sie ein Datenelement in die Abteilungstabelle ein:
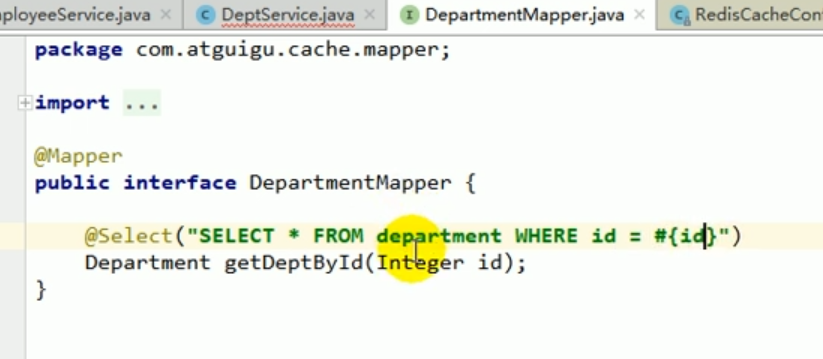
Mapper
Wir schreiben einen Mapper, der dem Abteilungsvorgang entspricht.
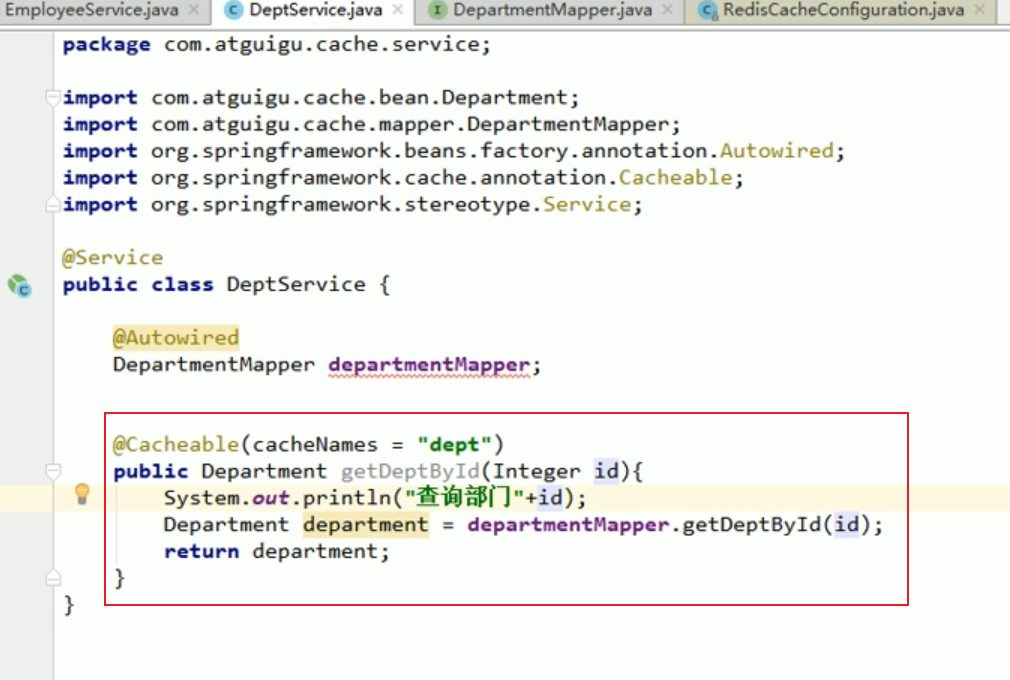
Service
Lassen Sie uns einen entsprechenden Service schreiben
 #🎜 🎜#
#🎜 🎜#
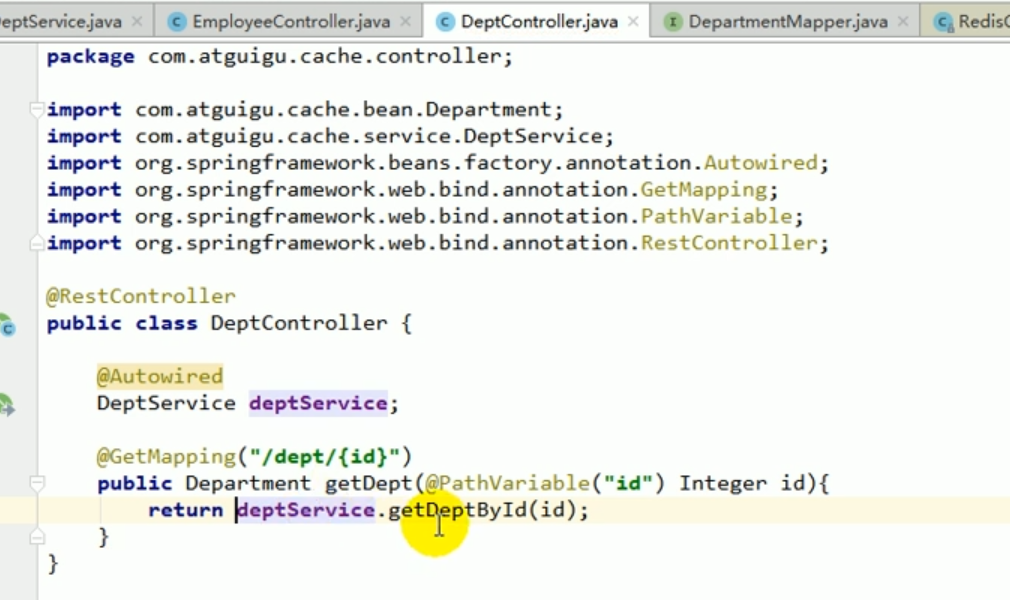
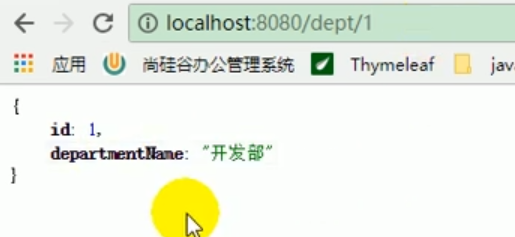
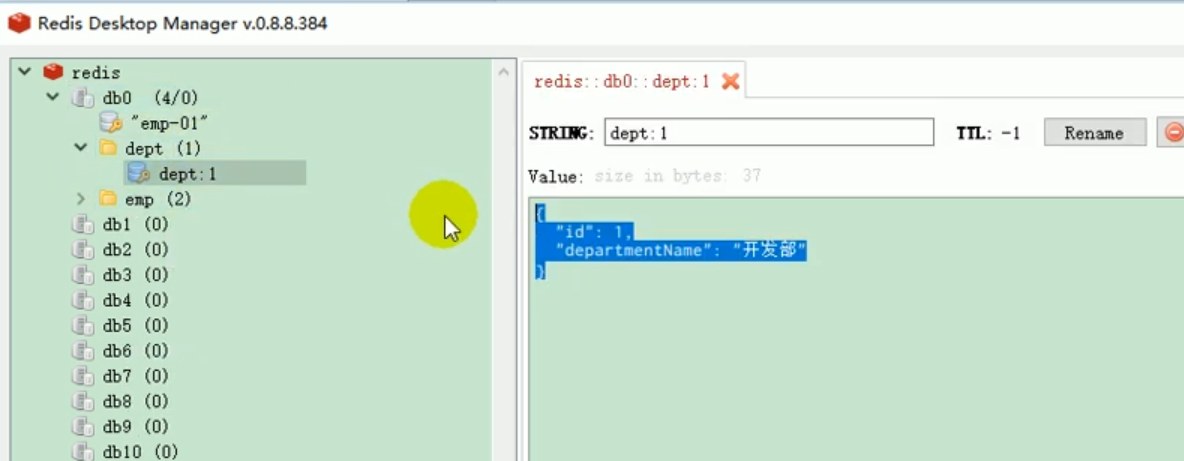
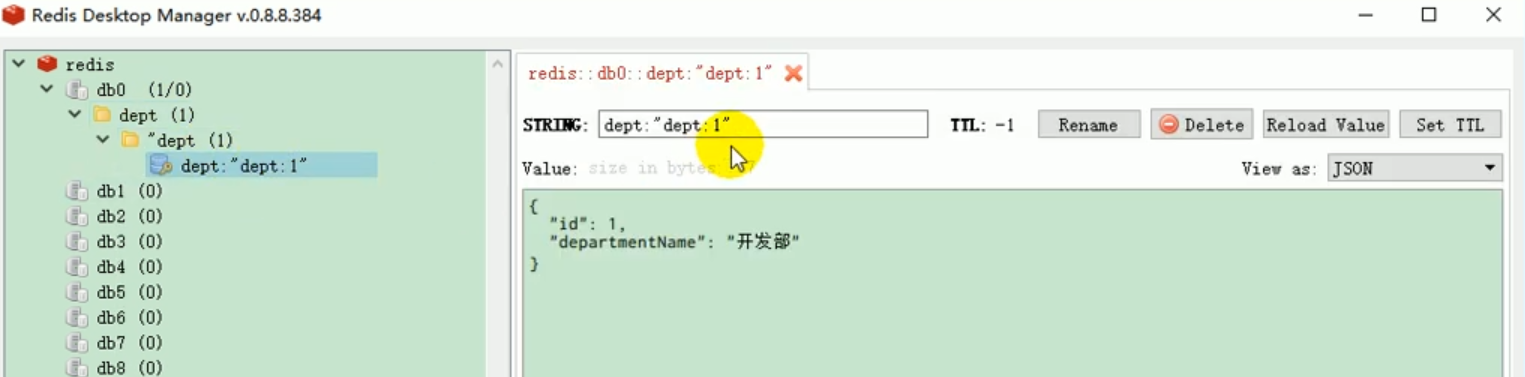
Wir haben einen Blick darauf geworfen und festgestellt, dass Redis abteilungsbezogene Daten enthält.
Wenn wir die Abteilung zum zweiten Mal abfragen, sollten wir Caching Redis verwenden.
Aber als wir zum zweiten Mal nachschauten, trat der folgende Fehler auf.
Fehler
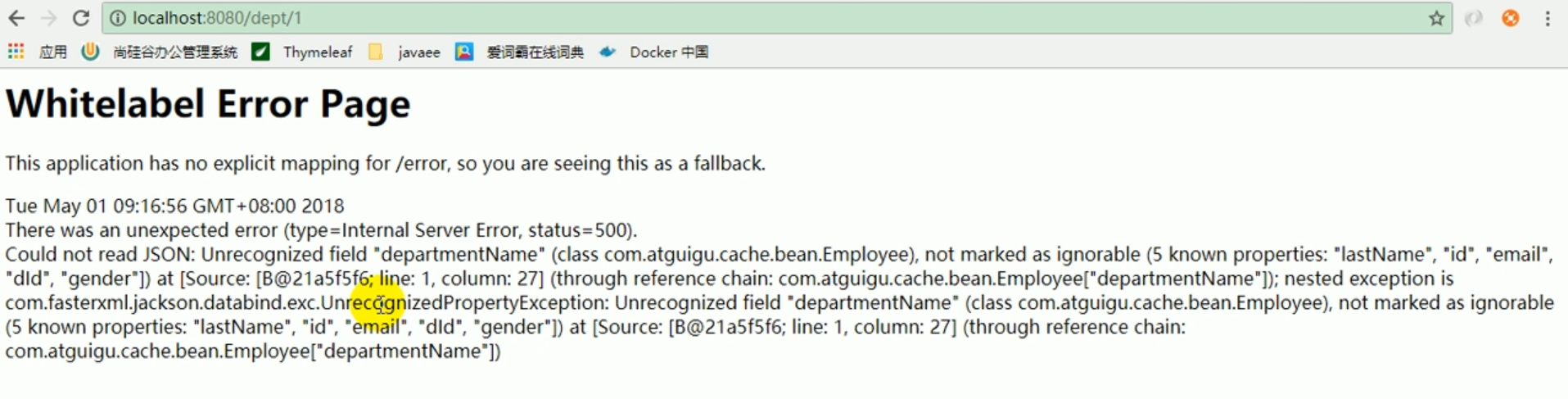
Der oben gemeldete Fehler bedeutet, dass JSON nicht gelesen werden kann.
Weil es notwendig ist, das JSON-Objekt der Abteilung in das JSON-Objekt des Mitarbeiters umzuwandeln, was nicht möglich ist.
Das liegt daran, dass der von uns platzierte redisCacheManager für Betriebsmitarbeiter gedacht ist.
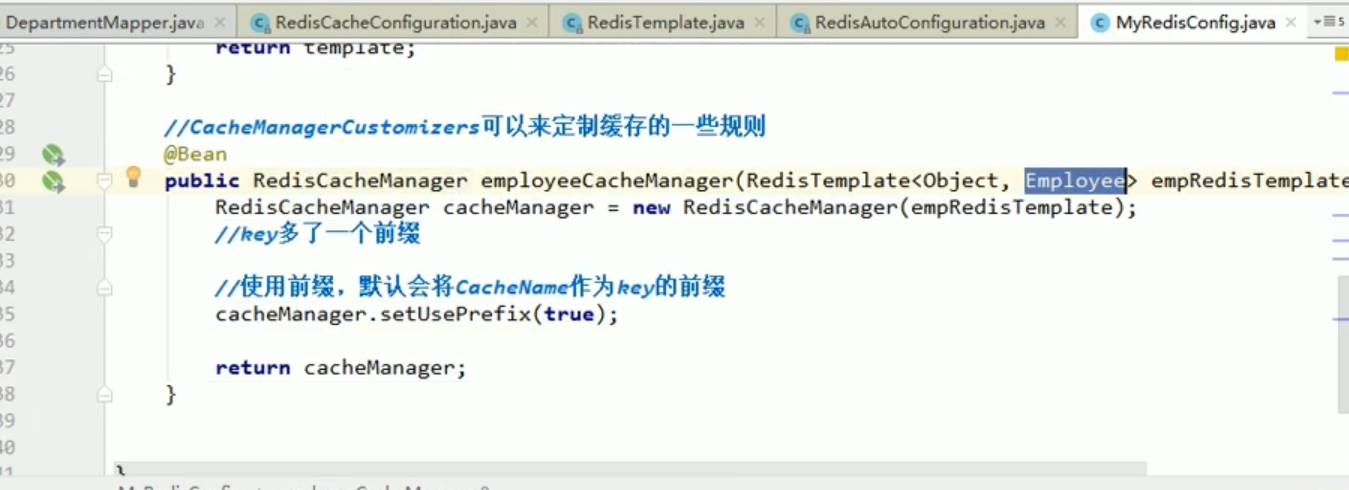
Der Effekt, den wir jetzt sehen, ist also sehr magisch.
Zwischengespeicherte Daten können in Redis gespeichert werden.
Aber wenn wir den Cache zum zweiten Mal abfragen, können wir ihn nicht wieder deserialisieren.
Es stellt sich heraus, dass wir die JSON-Daten der Abteilung speichern und unser Cachemanager standardmäßig die Vorlage des Mitarbeiters verwendet, um Redis zu betreiben.
Dieses Ding kann nur Mitarbeiterdaten deserialisieren.
Lösen Sie den Fehler
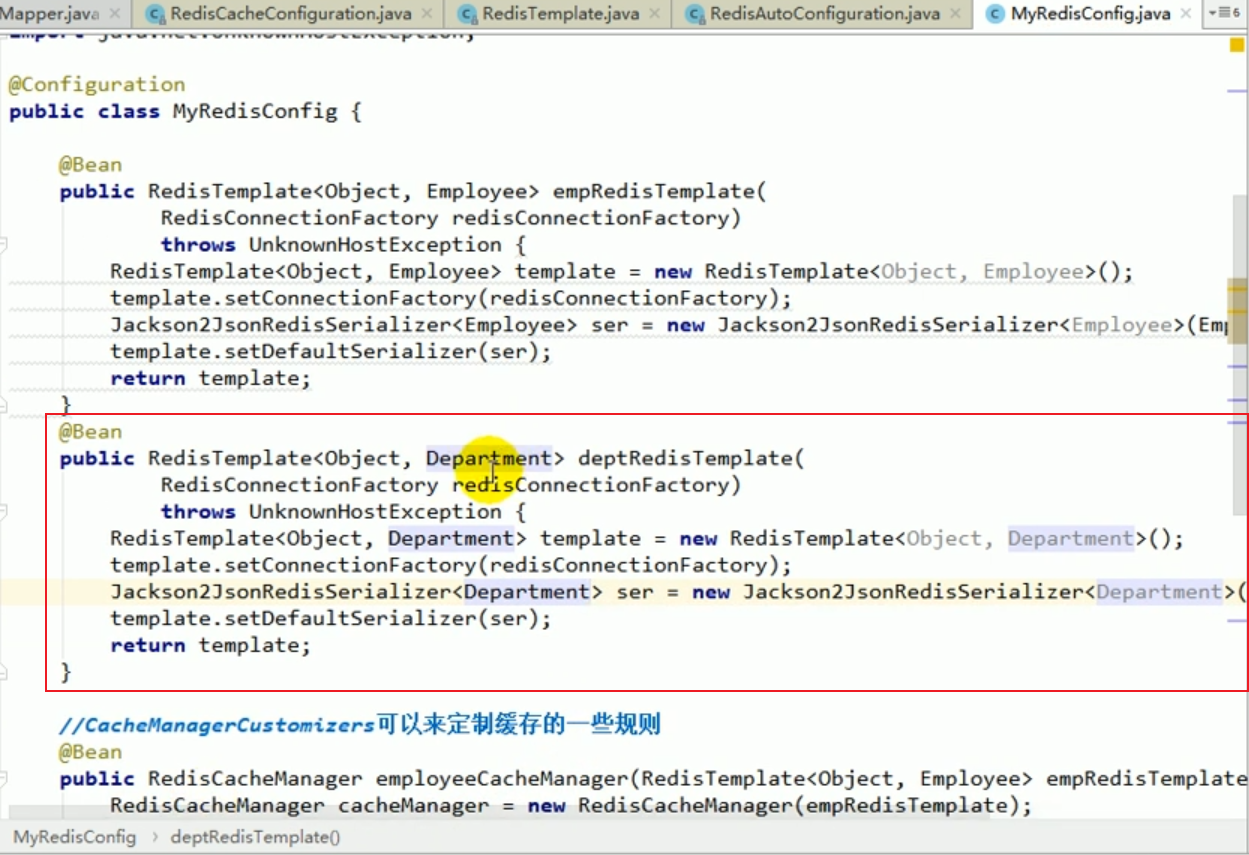
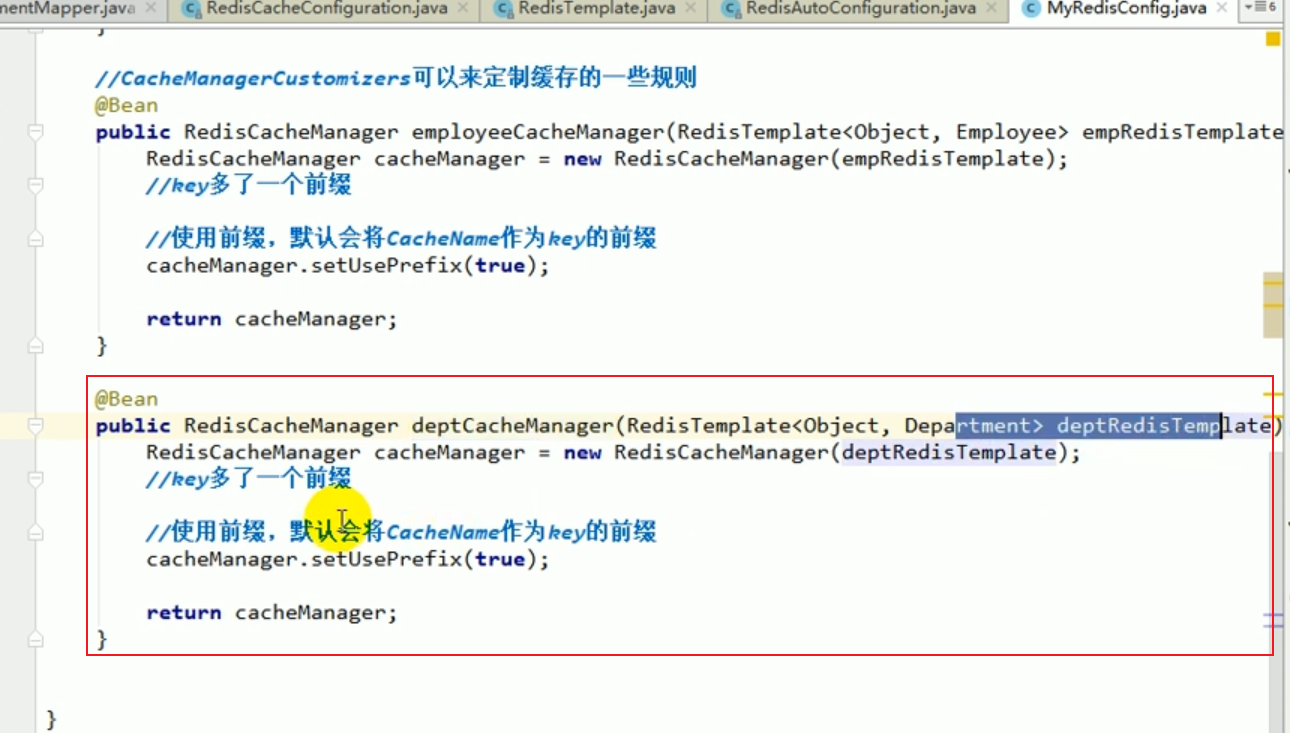
Zu diesem Zeitpunkt gibt es zwei redisCacheManager. Welchen sollten wir verwenden?
Wir können es im Service angeben.
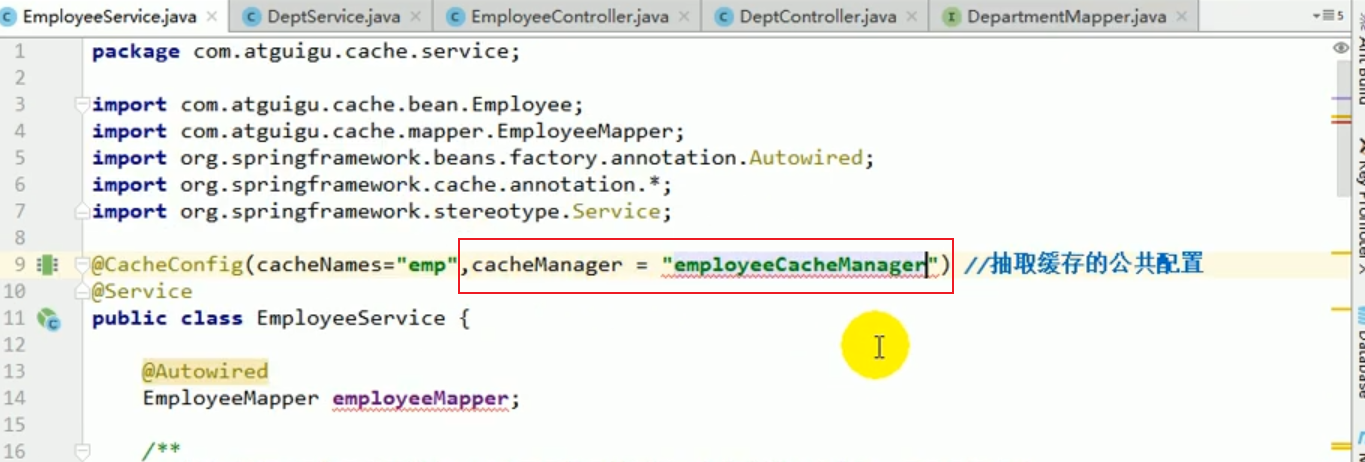
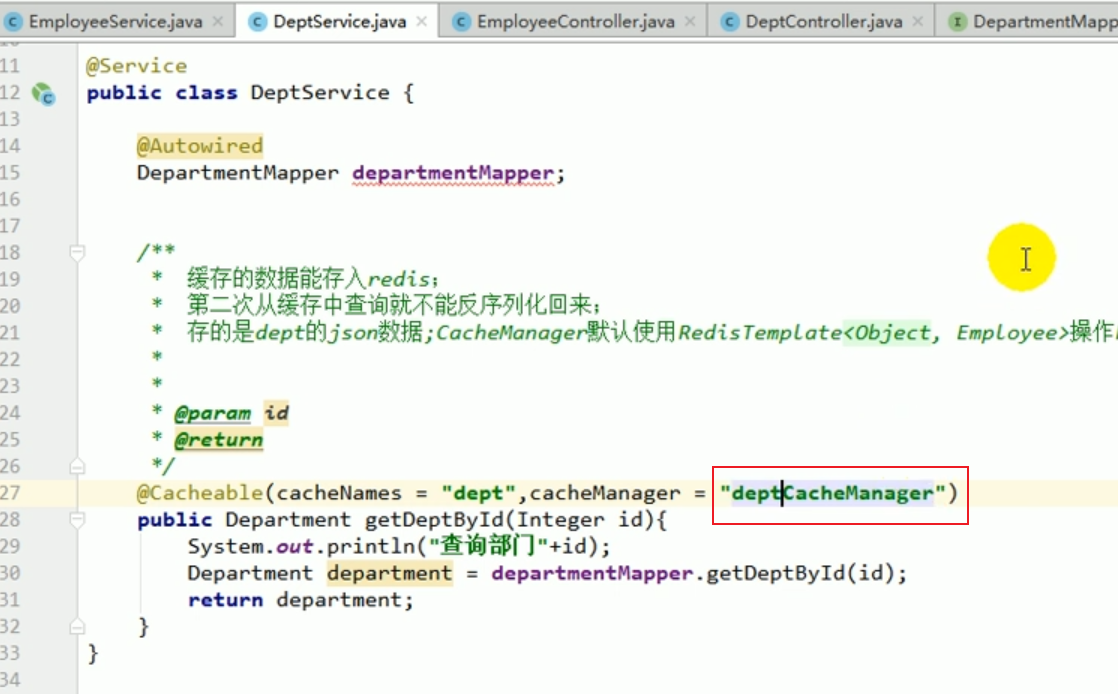
Dann haben wir das Projekt neu gestartet und das Ergebnis war ein Fehler:

Wenn wir mehrere CacheManager haben, müssen wir einen bestimmten CacheManager als Standardkonfiguration für die Cache-Verwaltung des Geräts verwenden.
Zum Beispiel können wir die folgenden Vorgänge ausführen, um den Inhalt dieses Startfehlers zu beheben:
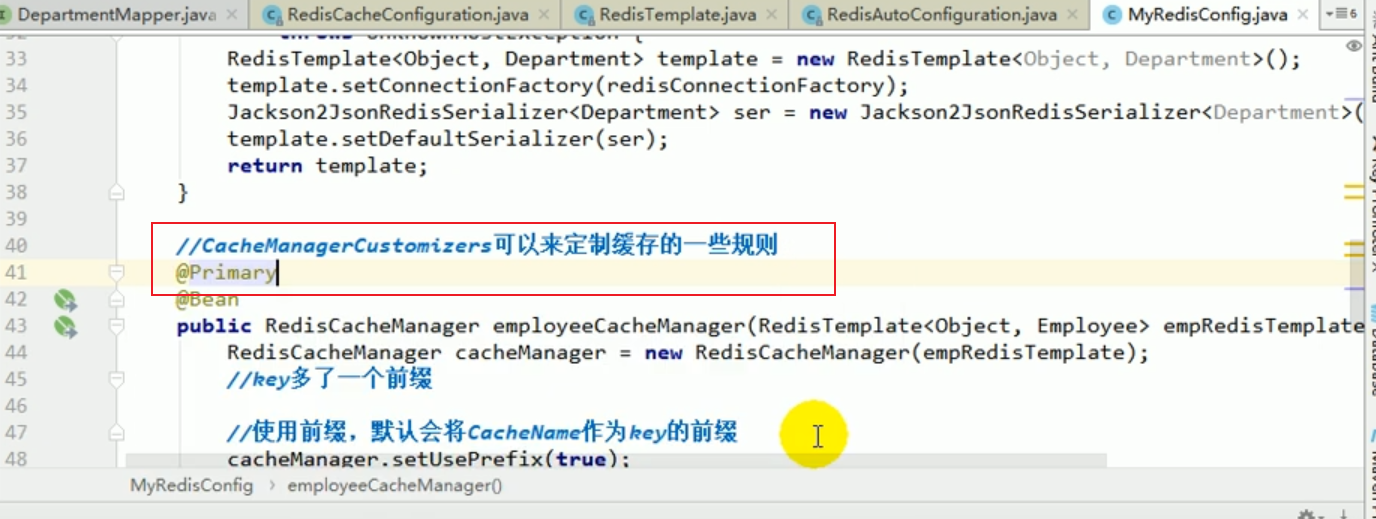
Neustart für Projekttests
Werfen Sie zu diesem Zeitpunkt einen Blick darauf, ob wir bei der zweiten Abteilungsanfrage eine Deserialisierung durchführen können und unsere Abteilungsinformationen von Redis normal und erfolgreich lesen?
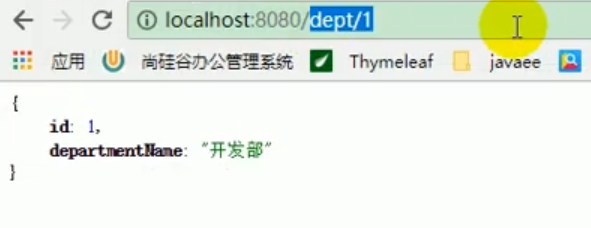
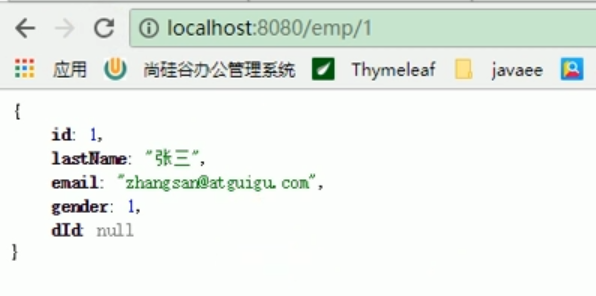
Zu diesem Zeitpunkt stellten wir fest, dass wir Redis erfolgreich deserialisieren und abfragen können, unabhängig davon, ob es sich um einen Mitarbeiter oder eine Abteilung handelt.
Das ist perfekt.
Operations-Cache mit Codierung
Was wir zuvor gesagt haben, ist die Verwendung von Anmerkungen, um Daten im Cache zu platzieren.
Während der Entwicklung stoßen wir jedoch häufig auf solche Situationen.
Das heißt, wenn unsere Entwicklung ein bestimmtes Stadium erreicht, müssen wir einige Daten in den Cache legen.
Wir müssen Codierung verwenden, um den Cache zu betreiben.
Nachdem wir beispielsweise die Abteilungsinformationen abgefragt haben, möchten wir diese Informationen in Redis einfügen.
Wir können den CacheManager der Abteilung einbinden.
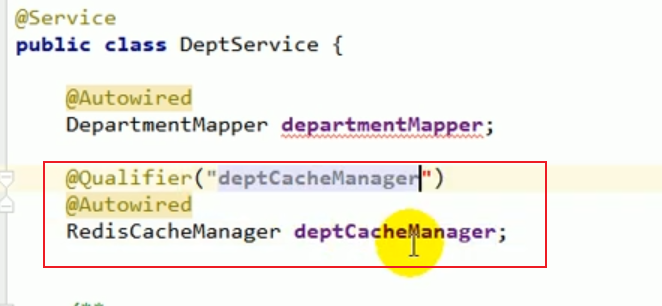
Dann können wir während des Codierungsprozesses den Cache erhalten, indem wir diesen CacheManager bedienen.
Dann können wir die Cache-Komponente bedienen, um die Daten hinzuzufügen, zu löschen, zu ändern und zu überprüfen.
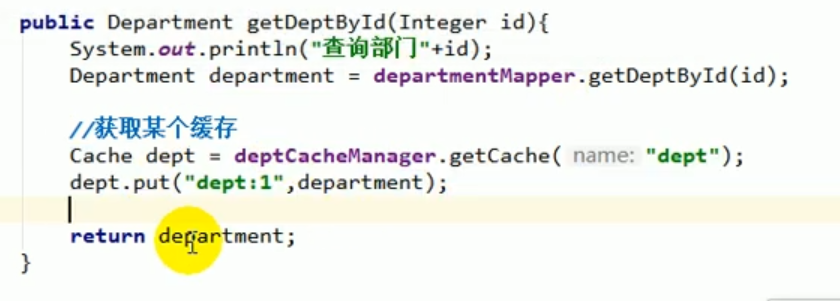
Wir haben den obigen Code getestet und das Projekt gestartet und festgestellt, dass er in Ordnung ist und die Daten erfolgreich in Redis eingegeben wurden:
Das obige ist der detaillierte Inhalt vonSpringboot-Cache-Redis-Integrationsmethode. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1379
1379
 52
52

 So erstellen Sie den Redis -Clustermodus
Apr 10, 2025 pm 10:15 PM
So erstellen Sie den Redis -Clustermodus
Apr 10, 2025 pm 10:15 PM
Der Redis -Cluster -Modus bietet Redis -Instanzen durch Sharding, die Skalierbarkeit und Verfügbarkeit verbessert. Die Bauschritte sind wie folgt: Erstellen Sie ungerade Redis -Instanzen mit verschiedenen Ports; Erstellen Sie 3 Sentinel -Instanzen, Monitor -Redis -Instanzen und Failover; Konfigurieren von Sentinel -Konfigurationsdateien, Informationen zur Überwachung von Redis -Instanzinformationen und Failover -Einstellungen hinzufügen. Konfigurieren von Redis -Instanzkonfigurationsdateien, aktivieren Sie den Cluster -Modus und geben Sie den Cluster -Informationsdateipfad an. Erstellen Sie die Datei nodes.conf, die Informationen zu jeder Redis -Instanz enthält. Starten Sie den Cluster, führen Sie den Befehl erstellen aus, um einen Cluster zu erstellen und die Anzahl der Replikate anzugeben. Melden Sie sich im Cluster an, um den Befehl cluster info auszuführen, um den Clusterstatus zu überprüfen. machen
 So verwenden Sie den Befehl Redis
Apr 10, 2025 pm 08:45 PM
So verwenden Sie den Befehl Redis
Apr 10, 2025 pm 08:45 PM
Die Verwendung der REDIS -Anweisung erfordert die folgenden Schritte: Öffnen Sie den Redis -Client. Geben Sie den Befehl ein (Verbschlüsselwert). Bietet die erforderlichen Parameter (variiert von der Anweisung bis zur Anweisung). Drücken Sie die Eingabetaste, um den Befehl auszuführen. Redis gibt eine Antwort zurück, die das Ergebnis der Operation anzeigt (normalerweise in Ordnung oder -err).
 So löschen Sie Redis -Daten
Apr 10, 2025 pm 10:06 PM
So löschen Sie Redis -Daten
Apr 10, 2025 pm 10:06 PM
So löschen Sie Redis -Daten: Verwenden Sie den Befehl Flushall, um alle Schlüsselwerte zu löschen. Verwenden Sie den Befehl flushdb, um den Schlüsselwert der aktuell ausgewählten Datenbank zu löschen. Verwenden Sie SELECT, um Datenbanken zu wechseln, und löschen Sie dann FlushDB, um mehrere Datenbanken zu löschen. Verwenden Sie den Befehl del, um einen bestimmten Schlüssel zu löschen. Verwenden Sie das Redis-Cli-Tool, um die Daten zu löschen.
 So verwenden Sie ein einzelnes Gewinde -Redis
Apr 10, 2025 pm 07:12 PM
So verwenden Sie ein einzelnes Gewinde -Redis
Apr 10, 2025 pm 07:12 PM
Redis verwendet eine einzelne Gewindearchitektur, um hohe Leistung, Einfachheit und Konsistenz zu bieten. Es wird E/A-Multiplexing, Ereignisschleifen, nicht blockierende E/A und gemeinsame Speicher verwendet, um die Parallelität zu verbessern, jedoch mit Einschränkungen von Gleichzeitbeschränkungen, einem einzelnen Ausfallpunkt und ungeeigneter Schreib-intensiver Workloads.
 So lesen Sie den Quellcode von Redis
Apr 10, 2025 pm 08:27 PM
So lesen Sie den Quellcode von Redis
Apr 10, 2025 pm 08:27 PM
Der beste Weg, um Redis -Quellcode zu verstehen, besteht darin, Schritt für Schritt zu gehen: Machen Sie sich mit den Grundlagen von Redis vertraut. Wählen Sie ein bestimmtes Modul oder eine bestimmte Funktion als Ausgangspunkt. Beginnen Sie mit dem Einstiegspunkt des Moduls oder der Funktion und sehen Sie sich die Codezeile nach Zeile an. Zeigen Sie den Code über die Funktionsaufrufkette an. Kennen Sie die von Redis verwendeten Datenstrukturen. Identifizieren Sie den von Redis verwendeten Algorithmus.
 So implementieren Sie die zugrunde liegenden Redis
Apr 10, 2025 pm 07:21 PM
So implementieren Sie die zugrunde liegenden Redis
Apr 10, 2025 pm 07:21 PM
Redis verwendet Hash -Tabellen, um Daten zu speichern und unterstützt Datenstrukturen wie Zeichenfolgen, Listen, Hash -Tabellen, Sammlungen und geordnete Sammlungen. Ernähren sich weiterhin über Daten über Snapshots (RDB) und appendiert Mechanismen nur Schreibmechanismen. Redis verwendet die Master-Slave-Replikation, um die Datenverfügbarkeit zu verbessern. Redis verwendet eine Ereignisschleife mit einer Thread, um Verbindungen und Befehle zu verarbeiten, um die Datenatomizität und Konsistenz zu gewährleisten. Redis legt die Ablaufzeit für den Schlüssel fest und verwendet den faulen Löschmechanismus, um den Ablaufschlüssel zu löschen.
 So lesen Sie Redis -Warteschlange
Apr 10, 2025 pm 10:12 PM
So lesen Sie Redis -Warteschlange
Apr 10, 2025 pm 10:12 PM
Um eine Warteschlange aus Redis zu lesen, müssen Sie den Warteschlangenname erhalten, die Elemente mit dem Befehl LPOP lesen und die leere Warteschlange verarbeiten. Die spezifischen Schritte sind wie folgt: Holen Sie sich den Warteschlangenname: Nennen Sie ihn mit dem Präfix von "Warteschlange:" wie "Warteschlangen: My-Queue". Verwenden Sie den Befehl LPOP: Wischen Sie das Element aus dem Kopf der Warteschlange aus und geben Sie seinen Wert zurück, z. B. die LPOP-Warteschlange: my-queue. Verarbeitung leerer Warteschlangen: Wenn die Warteschlange leer ist, gibt LPOP NIL zurück, und Sie können überprüfen, ob die Warteschlange existiert, bevor Sie das Element lesen.
 So sehen Sie alle Schlüssel in Redis
Apr 10, 2025 pm 07:15 PM
So sehen Sie alle Schlüssel in Redis
Apr 10, 2025 pm 07:15 PM
Um alle Schlüssel in Redis anzuzeigen, gibt es drei Möglichkeiten: Verwenden Sie den Befehl keys, um alle Schlüssel zurückzugeben, die dem angegebenen Muster übereinstimmen. Verwenden Sie den Befehl scan, um über die Schlüssel zu iterieren und eine Reihe von Schlüssel zurückzugeben. Verwenden Sie den Befehl Info, um die Gesamtzahl der Schlüssel zu erhalten.
