

So implementieren Sie Redis zig Milliarden wichtiger Speicherlösungen

1. Anforderungshintergrund
In diesem Anwendungsszenario muss DMP viele ID-Daten von Drittanbietern verwalten, einschließlich der Zuordnungsbeziehung zwischen jedem Medien-Cookie und seinem eigenen Cookie (im Folgenden zusammengefasst). als Superrid bezeichnet) sowie Es enthält das Populations-Tag von Superrid, das Populations-Tag von Mobil-IDs (hauptsächlich IDFA und IMEI) sowie einige Blacklist-IDs, IPs und andere Daten.
Es ist nicht schwierig, HDFS zum Offline-Speichern von Hunderten Milliarden Datensätzen zu verwenden, aber für DMP müssen Echtzeitabfragen auf Millisekundenebene bereitgestellt werden. Da die Cookie-ID selbst instabil ist, führt das Surfverhalten vieler realer Benutzer zur Generierung einer großen Anzahl neuer Cookies. Nur die Zuordnungsdaten können rechtzeitig synchronisiert werden, um das DMP-Populations-Tag zu erreichen, und es können keine höheren Treffer erzielt werden durch Vorheizen, was große Herausforderungen an die Cache-Speicherung mit sich bringt.
Nach tatsächlichen Tests erfordert die herkömmliche Speicherung von mehr als 5 Milliarden kv-Datensätzen mehr als 1 T Speicher. Wenn mehrere Kopien mit hoher Verfügbarkeit erforderlich sind, ist der Verbrauch enorm wird auch verursachen Es bringt eine starke Speicherfragmentierung mit sich, was eine sehr umfangreiche Speicherlösung erfordert, um die oben genannten Probleme zu lösen.
2. Welche Art von Daten werden gespeichert?
Personen-Tags sind hauptsächlich Cookie, IMEI, IDFA und ihr entsprechendes Geschlecht (Geschlecht), Alter (Altersgruppe), Geo (Region) usw.; Es handelt sich hauptsächlich um die Medienzuordnung von Cookies zu Superriden. Das Folgende ist ein Beispiel für die Datenspeicherung:
1) PC-seitige ID:
Mediennummer – Mediencookie=>supperid
supperid => , geo= >Geolocation-Kodierung}
2) Geräteseitige ID:
imei oder idfa => PC Die Daten müssen zwei Arten von key=>value und key=>hashmap speichern, während die Gerätedaten einen Typ von
key=>hashmap speichern müssen.
3. Dateneigenschaften
- Superid ist eine 21-stellige Zahl: z. B. 1605242015141689522; imei ist Kleinbuchstabe md5: z 4103633 ;idfa ist ein Großbuchstabe mit „-“ md5: für Beispiel: 51DFFC83 – 9541-4411-FA4F-356927E39D04;
- Milliarden von Mapping-Beziehungen werden jeden Tag generiert;
- Hot-Daten können innerhalb eines größeren Zeitfensters vorhergesagt werden (es gibt noch einige stabile Cookies); Die aktuellen Zuordnungsdaten können nicht vorhergesagt werden. Viele davon sind neu generierte Cookies.
- 4) Unterschiedliche Längen können leicht zu Speicherfragmentierung führen Bei einer großen Anzahl von Zeigern ist die Speichererweiterungsrate relativ hoch, im Allgemeinen 7-mal, ein häufiges Problem der reinen Speicherspeicherung
3) Obwohl die Beliebtheit von Cookies anhand ihres Verhaltens vorhergesagt werden kann, gibt es immer noch viele neu generierte IDs Tag (der Prozentsatz ist sensibel und wird vorerst nicht bekannt gegeben);
4) Da der Dienst in einer öffentlichen Netzwerkumgebung innerhalb von 100 ms erfolgen muss (inländische öffentliche Netzwerkverzögerung beträgt weniger als 60 ms), im Prinzip alle Neu aktualisierte Zuordnungen und Bevölkerungsbezeichnungen am Tag müssen im Speicher sein, damit die Anfrage nicht in die kalten Daten des Backends fällt. 5) Aus geschäftlicher Sicht werden grundsätzlich alle Daten für mindestens 35 Tage aufbewahrt Tage oder sogar länger;
6) Speicher ist immer noch relativ teuer und Dutzende Milliarden Schlüssel oder sogar Hunderte Milliarden Speicherlösungen sind zwingend erforderlich! - 5. Lösung
5.1 Eliminierungsstrategie
Da täglich große Mengen neuer Daten in die Datenbank gelangen, ist es besonders wichtig, die Daten rechtzeitig zu bereinigen, was eine wichtige Rolle spielt Grund für Lagermangel. Die Hauptmethode besteht darin, heiße Daten zu erkennen und zu speichern und kalte Daten zu eliminieren.
Die Zahl der Netzwerknutzer erreicht bei weitem nicht die Milliardengrenze, und ihre IDs werden sich im Laufe der Zeit weiterhin ändern und eine gewisse Lebensdauer haben. Die von uns gespeicherten IDs sind also größtenteils ungültig. Tatsächlich ist die Logik der Front-End-Abfrage die Werbepräsenz, die mit menschlichem Verhalten zusammenhängt, sodass das Zugriffsverhalten einer ID in einem bestimmten Zeitfenster (vielleicht eine Kampagne, ein halbes Jahr) ein gewisses Maß an Wiederholbarkeit aufweist Monat, ein paar Monate).
Vor der Dateninitialisierung verwenden wir zunächst hbase, um Protokoll-IDs zu aggregieren und zu deduplizieren und den TTL-Bereich abzugrenzen, normalerweise 35 Tage, sodass IDs, die in den letzten 35 Tagen nicht angezeigt wurden, abgeschnitten werden können. Darüber hinaus ist die Ablaufzeit in Redis auf 35 Tage eingestellt. Beim Zugriff und Drücken wird der Schlüssel erneuert, die Ablaufzeit verlängert und diejenigen, die nicht innerhalb von 35 Tagen angezeigt werden, werden auf natürliche Weise entfernt. Dies kann für stabile Cookies oder IDs effektiv sein. Es ist tatsächlich erwiesen, dass die Lebensverlängerungsmethode für IDFA und IMEI praktischer ist und eine langfristige Akkumulation sehr ideale Ergebnisse erzielen kann.
5.2 Erweiterung reduzieren
Die Größe des Hash-Tabellenbereichs und die Anzahl der Schlüssel bestimmen die Konfliktrate (oder gemessen am Auslastungsfaktor): Je mehr Schlüssel, desto größer die Hash-Tabelle Speicherplatz und Verbrauch Der Speicher wird natürlich groß sein. Darüber hinaus handelt es sich bei vielen Zeigern selbst um Long-Integer-Typen, sodass die Speichererweiterung erheblich ist. Lassen Sie uns zunächst darüber sprechen, wie Sie die Anzahl der Schlüssel reduzieren können. Lassen Sie uns zunächst eine Speicherstruktur verstehen. Gemäß den folgenden Schritten kann key1=>value1 in Redis gespeichert werden, was wir erwarten. Verwenden Sie zunächst einen zufälligen Hash-MD5-Wert (Schlüsselwert) fester Länge als Redis-Schlüssel, den wir BucketId nennen, und speichern Sie key1 => value1 in der Hashmap-Struktur, damit der Client beim Abfragen dem obigen Prozess folgen kann. Berechnen Sie den Hash und fragen Sie ihn ab Wert1. Die Prozessänderungen werden einfach wie folgt beschrieben: get(key1) -> hget(md5(key1), key1) um value1 zu erhalten. Wenn wir durch Vorberechnung zulassen, dass viele Schlüssel im BucketId-Bereich kollidieren, kann davon ausgegangen werden, dass sich unter einer BucketId mehrere Schlüssel befinden. Wenn beispielsweise durchschnittlich 10 Schlüssel pro BucketId vorhanden sind, reduzieren wir theoretisch die Anzahl der Redis-Schlüssel um mehr als 90 %. Die spezifische Implementierung ist etwas mühsam und Sie müssen über die Kapazitätsskala nachdenken, bevor Sie diese Methode verwenden. Der MD5, den wir normalerweise verwenden, ist ein 32-Bit-Hex-String (Hexadezimalzeichen) und sein Speicherplatz ist zu groß. Wir müssen mehrere zehn Milliarden speichern, was etwa 33 Bit entspricht Berechnen Um einen Hash mit der entsprechenden Anzahl von Ziffern zu generieren und um Speicherplatz zu sparen, müssen wir anstelle von HexString alle Zeichentypen (ASCII-Codes zwischen 0 und 127) zum Füllen verwenden, damit die Länge des Schlüssels verkürzt werden kann auf die Hälfte. Das Folgende ist die spezifische Implementierungsmethode public static byte [] getBucketId(byte [] key, Integer bit) {
MessageDigest mdInst = MessageDigest.getInstance("MD5");
mdInst.update(key);
byte [] md = mdInst.digest();
byte [] r = new byte[(bit-1)/7 + 1];// 因为一个字节中只有7位能够表示成单字符
int a = (int) Math.pow(2, bit%7)-2;
md[r.length-1] = (byte) (md[r.length-1] & a);
System.arraycopy(md, 0, r, 0, r.length);
for(int i=0;i<r.length if r return></r.length>
Die endgültige Größe des BucketId-Raums wird durch das Parameterbit bestimmt. Der optionale Satz von Raumgrößen ist eine diskrete ganzzahlige Potenz von 2. Hier finden Sie eine Erklärung, warum in einem Byte nur 7 Bits verfügbar sind. Dies liegt daran, dass Redis beim Speichern des Schlüssels ASCII (0 ~ 127) und kein Byte-Array sein muss. Wenn wir zig Milliarden Speicher planen und 10 KVs pro Bucket gemeinsam nutzen möchten, benötigen wir nur 2^30=1073741824 Buckets, was der endgültigen Anzahl an Schlüsseln entspricht.
5.3 Fragmentierung reduzieren
Der Hauptgrund für die Fragmentierung besteht darin, dass der Speicher nicht ausgerichtet werden kann und der Speicher nach Ablauf und Löschung nicht neu zugewiesen werden kann. Mit der oben beschriebenen Methode können wir Bevölkerungsbezeichnungen und Zuordnungsdaten auf die oben beschriebene Weise speichern. Der Vorteil besteht darin, dass die Redis-Schlüssel gleich lang sind. Darüber hinaus haben wir auch relevante Optimierungen für den Schlüssel in der Hashmap vorgenommen und die letzten sechs Ziffern des Cookies oder der Geräte-ID als Schlüssel abgefangen, wodurch auch die Speicherausrichtung sichergestellt werden kann. Theoretisch besteht die Möglichkeit eines Konflikts, aber die Wahrscheinlichkeit des gleichen Suffixes im gleichen Bucket Extrem niedrig (Stellen Sie sich vor, die ID ist eine nahezu zufällige Zeichenfolge. Die Wahrscheinlichkeit, dass 10 zufällige IDs aus längeren Zeichen mit demselben Suffix bestehen * Anzahl der Bucket-Stichproben = erwarteter Konfliktwert
Darüber hinaus gibt es eine sehr geringe, aber effektive Möglichkeit, die Fragmentierung zu reduzieren. Starten Sie den Slave neu und erzwingen Sie dann einen Failover, um den Master und den Slave zu wechseln.
Empfehlen Sie die Speicherzuweisung von Google-tcmalloc und facebook-jemalloc, die die Speicherfragmentierung und den Speicherverbrauch reduzieren können, wenn der Wert nicht groß ist. Einige Leute haben gemessen, dass libc wirtschaftlicher ist, wenn der Wert groß ist.
6. Probleme, die bei der MD5-Hash-Bucket-Methode beachtet werden müssen
1) Die Größe der KV-Speicherung muss im Voraus geplant werden. Der Floating-Bereich beträgt etwa das Zehn- bis Fünfzehnfache der Anzahl der Buckets Wenn Sie beispielsweise Dutzende Milliarden KV speichern möchten, wählen Sie am besten 30 Bit bis 31 Bit als Anzahl der Buckets. Mit anderen Worten, es gibt kein Problem beim Geschäftswachstum innerhalb eines angemessenen Bereichs (10- bis 15-faches Wachstum), was dazu führt, dass das Hashset zu schnell wächst, die Abfragezeit verlängert und sogar ausgelöst wird Der Schwellenwert für die Zip-Liste wird überschritten, was dazu führt, dass der Speicher dramatisch zunimmt.
2) Wenn der Wert zu groß ist oder zu viele Felder vorhanden sind, ist dies nicht geeignet, da bei dieser Methode der Wert auf einmal herausgenommen werden muss. Die Bevölkerungsbezeichnung ist beispielsweise a Sehr kleine Kodierung, sogar nur 3 oder 4 Bits (Bit) können eingebaut werden. 3) Die typische Methode zum Austausch von Zeit gegen Speicherplatz. Da unser Geschäftsszenario keine extrem hohen QPS erfordert, die im Allgemeinen bei 100 Millionen bis 1 Milliarde pro Tag liegen, ist es auch sehr wirtschaftlich, die CPU-Miete sinnvoll zu nutzen Wert.
Nach der Verwendung von Information Digest kann der Schlüssel nicht zufällig von Redis generiert werden, da die Größe des Schlüssels reduziert und die Länge begrenzt ist. Wenn ein Export erforderlich ist, muss dieser in Kaltdaten exportiert werden.
5) Ablauf muss von Ihnen selbst implementiert werden. Da der Verbrauch nur während des Schreibvorgangs zunimmt, wird er während des Schreibvorgangs in einem bestimmten Verhältnis abgetastet und zur Bestimmung werden HLEN-Treffer verwendet ob mehr als 15 Einträge vorhanden sind. Abgelaufene Schlüssel werden gelöscht und der TTL-Zeitstempel wird in den ersten 32 Bits des Werts gespeichert.
6) Statistiken zum Bucket-Verbrauch müssen erstellt werden. Abgelaufene Schlüssel müssen regelmäßig bereinigt werden, um sicherzustellen, dass Redis-Abfragen nicht langsamer werden.
7. Testergebnisse
10 Milliarden Datensätze mit Bevölkerungskennzeichnung und Kartierungsdaten.
Vor der Optimierung wurden etwa 2,3 T Speicherplatz verwendet, und die Fragmentierungsrate betrug etwa 2. Nach der Optimierung wurden etwa 500 g Speicherplatz verwendet, und die durchschnittliche Nutzung jedes Buckets betrug etwa 4. Die Fragmentierungsrate liegt bei etwa 1,02. Dies verbraucht beim Abfragen sehr wenig CPU.
Es sollte auch erwähnt werden, dass der Verbrauch jedes Eimers nicht wirklich gleichmäßig ist, sondern einer Polynomverteilung entspricht.
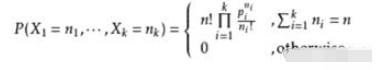
Mit der obigen Formel kann die Wahrscheinlichkeitsverteilung des Eimerverbrauchs berechnet werden. Diese Formel soll nur alle daran erinnern, dass der Bucket-Verbrauch nicht selbstverständlich ist. Es ist möglich, dass einige Buckets Hunderte von Schlüsseln enthalten. Aber die Wahrheit ist nicht so übertrieben. Stellen Sie sich vor, Sie werfen eine Münze und es gibt nur zwei mögliche Ergebnisse: Kopf und Zahl. Es ist gleichbedeutend mit nur zwei Eimern. Wenn Sie unendlich oft werfen, entspricht jedes Mal einem Bernoulli-Experiment, dann sind die beiden Eimer definitiv sehr gleichmäßig. Wenn Sie viele verallgemeinerte Bernoulli-Experimente durchführen und mit vielen Fässern konfrontiert werden, ist die Wahrscheinlichkeitsverteilung wie eine unsichtbare Magie, die über Ihnen schwebt. Die Verbrauchsverteilung der Buckets tendiert zu einem stabilen Wert. Werfen wir als Nächstes einen Blick auf die spezifische Bucket-Verbrauchsverteilung:
Durch Stichprobenstatistik
31-Bit-Buckets (mehr als 2 Milliarden) beträgt der durchschnittliche Verbrauch 4,18
#🎜 🎜#
Das obige ist der detaillierte Inhalt vonSo implementieren Sie Redis zig Milliarden wichtiger Speicherlösungen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1371
1371
 52
52

 Lösung für den Fehler 0x80242008 bei der Installation von Windows 11 10.0.22000.100
May 08, 2024 pm 03:50 PM
Lösung für den Fehler 0x80242008 bei der Installation von Windows 11 10.0.22000.100
May 08, 2024 pm 03:50 PM
1. Starten Sie das Menü [Start], geben Sie [cmd] ein, klicken Sie mit der rechten Maustaste auf [Eingabeaufforderung] und wählen Sie Als [Administrator] ausführen. 2. Geben Sie nacheinander die folgenden Befehle ein (kopieren und fügen Sie sie sorgfältig ein): SCconfigwuauservstart=auto, drücken Sie die Eingabetaste. SCconfigbitsstart=auto, drücken Sie die Eingabetaste. SCconfigcryptsvcstart=auto, drücken Sie die Eingabetaste. SCconfigtrustedinstallerstart=auto, drücken Sie die Eingabetaste. SCconfigwuauservtype=share, drücken Sie die Eingabetaste. netstopwuauserv, drücken Sie die Eingabetaste für netstopcryptS
 Golang API-Caching-Strategie und -Optimierung
May 07, 2024 pm 02:12 PM
Golang API-Caching-Strategie und -Optimierung
May 07, 2024 pm 02:12 PM
Die Caching-Strategie in GolangAPI kann die Leistung verbessern und die Serverlast reduzieren. Häufig verwendete Strategien sind: LRU, LFU, FIFO und TTL. Zu den Optimierungstechniken gehören die Auswahl geeigneter Cache-Speicher, hierarchisches Caching, Invalidierungsmanagement sowie Überwachung und Optimierung. Im praktischen Fall wird der LRU-Cache verwendet, um die API zum Abrufen von Benutzerinformationen aus der Datenbank zu optimieren. Andernfalls kann der Cache nach dem Abrufen aus der Datenbank aktualisiert werden.
 Die nicht patchbare Sicherheitslücke im Yubico-Zwei-Faktor-Authentifizierungsschlüssel beeinträchtigt die Sicherheit der meisten Yubikey 5-, Security Key- und YubiHSM 2FA-Geräte
Sep 04, 2024 pm 06:32 PM
Die nicht patchbare Sicherheitslücke im Yubico-Zwei-Faktor-Authentifizierungsschlüssel beeinträchtigt die Sicherheit der meisten Yubikey 5-, Security Key- und YubiHSM 2FA-Geräte
Sep 04, 2024 pm 06:32 PM
Eine nicht patchbare Schwachstelle im Yubico-Zwei-Faktor-Authentifizierungsschlüssel hat die Sicherheit der meisten Yubikey 5-, Security Key- und YubiHSM 2FA-Geräte beeinträchtigt. Die Feitian A22 JavaCard und andere Geräte, die TPMs der Infineon SLB96xx-Serie verwenden, sind ebenfalls anfällig.Alle
 Caching-Mechanismus und Anwendungspraxis in der PHP-Entwicklung
May 09, 2024 pm 01:30 PM
Caching-Mechanismus und Anwendungspraxis in der PHP-Entwicklung
May 09, 2024 pm 01:30 PM
In der PHP-Entwicklung verbessert der Caching-Mechanismus die Leistung, indem er häufig aufgerufene Daten vorübergehend im Speicher oder auf der Festplatte speichert und so die Anzahl der Datenbankzugriffe reduziert. Zu den Cache-Typen gehören hauptsächlich Speicher-, Datei- und Datenbank-Cache. In PHP können Sie integrierte Funktionen oder Bibliotheken von Drittanbietern verwenden, um Caching zu implementieren, wie zum Beispiel Cache_get() und Memcache. Zu den gängigen praktischen Anwendungen gehören das Zwischenspeichern von Datenbankabfrageergebnissen zur Optimierung der Abfrageleistung und das Zwischenspeichern von Seitenausgaben zur Beschleunigung des Renderings. Der Caching-Mechanismus verbessert effektiv die Reaktionsgeschwindigkeit der Website, verbessert das Benutzererlebnis und reduziert die Serverlast.
 So aktualisieren Sie Win11 Englisch 21996 auf vereinfachtes Chinesisch 22000_So aktualisieren Sie Win11 Englisch 21996 auf vereinfachtes Chinesisch 22000
May 08, 2024 pm 05:10 PM
So aktualisieren Sie Win11 Englisch 21996 auf vereinfachtes Chinesisch 22000_So aktualisieren Sie Win11 Englisch 21996 auf vereinfachtes Chinesisch 22000
May 08, 2024 pm 05:10 PM
Zuerst müssen Sie die Systemsprache auf die Anzeige in vereinfachtem Chinesisch einstellen und neu starten. Wenn Sie die Anzeigesprache zuvor auf vereinfachtes Chinesisch geändert haben, können Sie diesen Schritt natürlich einfach überspringen. Beginnen Sie als Nächstes mit dem Betrieb der Registrierung regedit.exe, navigieren Sie direkt zu HKEY_LOCAL_MACHINESYSTEMCurrentControlSetControlNlsLanguage in der linken Navigationsleiste oder der oberen Adressleiste und ändern Sie dann den InstallLanguage-Schlüsselwert und den Standardschlüsselwert auf 0804 (wenn Sie ihn in Englisch ändern möchten). us, Sie müssen zunächst die Anzeigesprache des Systems auf en-us einstellen, das System neu starten und dann alles auf 0409 ändern) Sie müssen das System an dieser Stelle neu starten.
 Wie verwende ich den Redis-Cache bei der PHP-Array-Paginierung?
May 01, 2024 am 10:48 AM
Wie verwende ich den Redis-Cache bei der PHP-Array-Paginierung?
May 01, 2024 am 10:48 AM
Durch die Verwendung des Redis-Cache kann die Leistung des PHP-Array-Pagings erheblich optimiert werden. Dies kann durch die folgenden Schritte erreicht werden: Installieren Sie den Redis-Client. Stellen Sie eine Verbindung zum Redis-Server her. Erstellen Sie Cache-Daten und speichern Sie jede Datenseite in einem Redis-Hash mit dem Schlüssel „page:{page_number}“. Rufen Sie Daten aus dem Cache ab und vermeiden Sie teure Vorgänge auf großen Arrays.
 So finden Sie die von Win11 heruntergeladene Update-Datei. Geben Sie den Speicherort der von Win11 heruntergeladenen Update-Datei an
May 08, 2024 am 10:34 AM
So finden Sie die von Win11 heruntergeladene Update-Datei. Geben Sie den Speicherort der von Win11 heruntergeladenen Update-Datei an
May 08, 2024 am 10:34 AM
1. Doppelklicken Sie zunächst auf dem Desktop auf das Symbol [Dieser PC], um es zu öffnen. 2. Doppelklicken Sie dann mit der linken Maustaste, um [Laufwerk C] einzugeben. Systemdateien werden im Allgemeinen automatisch auf Laufwerk C gespeichert. 3. Suchen Sie dann den Ordner [Windows] auf dem Laufwerk C und doppelklicken Sie, um ihn aufzurufen. 4. Nachdem Sie den Ordner [Windows] aufgerufen haben, suchen Sie den Ordner [SoftwareDistribution]. 5. Suchen Sie nach der Eingabe den Ordner [Download], der alle Win11-Download- und Update-Dateien enthält. 6. Wenn wir diese Dateien löschen möchten, löschen Sie sie einfach direkt in diesem Ordner.
 PHP-Redis-Caching-Anwendungen und Best Practices
May 04, 2024 am 08:33 AM
PHP-Redis-Caching-Anwendungen und Best Practices
May 04, 2024 am 08:33 AM
Redis ist ein leistungsstarker Schlüsselwert-Cache. Die PHPRedis-Erweiterung stellt eine API für die Interaktion mit dem Redis-Server bereit. Führen Sie die folgenden Schritte aus, um eine Verbindung zu Redis herzustellen sowie Daten zu speichern und abzurufen: Verbinden: Verwenden Sie die Redis-Klassen, um eine Verbindung zum Server herzustellen. Speicherung: Verwenden Sie die Set-Methode, um Schlüssel-Wert-Paare festzulegen. Abrufen: Verwenden Sie die get-Methode, um den Wert des Schlüssels abzurufen.
