
 Technologie-Peripheriegeräte
KI
Das Geheimnis der inländischen ChatGPT-„Shell' wurde nun gelüftet
Technologie-Peripheriegeräte
KI
Das Geheimnis der inländischen ChatGPT-„Shell' wurde nun gelüftet
Das Geheimnis der inländischen ChatGPT-„Shell' wurde nun gelüftet


„iFlytek deckt ChatGPT ab!“ „Baidu Wenxin verwendet ein Wort, um Stable Diffusion zu vertuschen!“ „Das große Modell von SenseTime ist tatsächlich ein Plagiat!“ große Modelle.
Die Erklärung für dieses Phänomen ist laut Brancheninsidern, dass es einen echten Mangel an qualitativ hochwertigen chinesischen Datensätzen gibt. Beim Training von Modellen können
die gekauften fremdsprachigen annotierten Datensätze nur als „Auslandshilfe“ fungieren . Wenn der für das Training verwendete Datensatz abstürzt, werden ähnliche Ergebnisse generiert, was zu einem eigenen Vorfall führt. Unter anderem ist die Verwendung vorhandener großer Modelle zur Unterstützung bei der Generierung von Trainingsdaten anfällig für eine unzureichende Datenbereinigung. Nur das Training spärlicher großer Modelle ist keine langfristige Lösung.
Nach und nach formiert sich in der Branche ein Konsens:
Der Weg zur AGI wird weiterhin extrem hohe Anforderungen sowohl an die Datenmenge als auch an die Datenqualität stellen.
Die aktuelle Situation erfordert, dass viele inländische Teams
sukzessive chinesische Open-Source-Datensätze veröffentlicht haben. Zusätzlich zu allgemeinen Datensätzen wurden auch spezielle chinesische Open-Source-Datensätze für vertikale Bereiche wie z Programmierung und medizinische Versorgung. Hochwertige Datensätze sind verfügbar, aber nur wenige.
Neue Durchbrüche bei großen Modellen basieren stark auf hochwertigen und umfangreichen Datensätzen.
Gemäß den „Skalierungsgesetzen für neuronale Sprachmodelle“ von OpenAI ist das von großen Modellen vorgeschlagene Skalierungsgesetz
(Skalierungsgesetz)Es ist ersichtlich, dass eine unabhängige Erhöhung der Trainingsdatenmenge die Wirkung des vorab trainierten Modells verbessern kann.
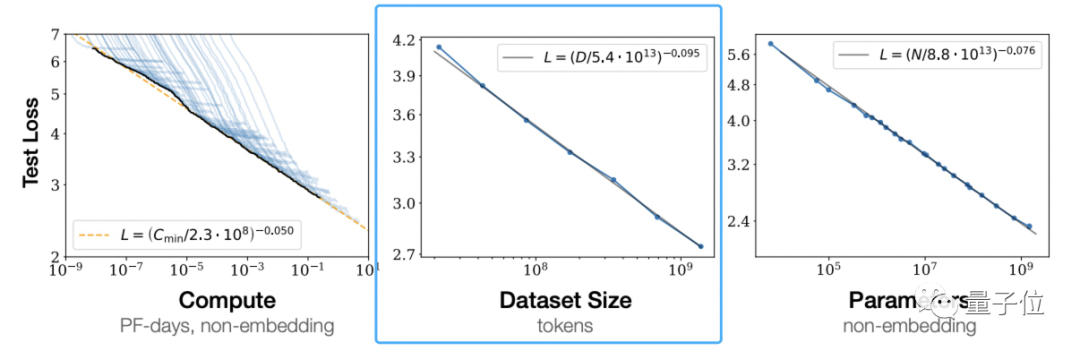 Dies ist nicht die Meinung von OpenAI.
Dies ist nicht die Meinung von OpenAI.
DeepMind wies im Chinchilla-Modellpapier auch darauf hin, dass die meisten der vorherigen großen Modelle unzureichend trainiert waren, und schlug auch die optimale Trainingsformel vor, die in der Branche zu einem anerkannten Standard geworden ist.
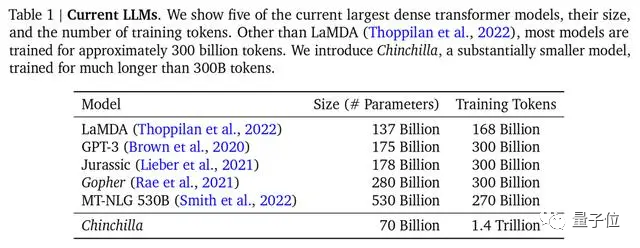
Das Mainstream-Großmodell Chinchilla hat die wenigsten Parameter, aber das ausreichendste TrainingDie für das Training verwendeten Mainstream-Datensätze sind jedoch hauptsächlich auf Englisch, Wie Common Crawl, BooksCorpus, WiKipedia, ROOT usw. machen die beliebtesten chinesischen Common Crawl-Daten nur 4,8 % aus.
Wie ist die Situation mit dem chinesischen Datensatz?
Es gibt keine öffentlichen Datensätze – dies wird durch Qubits von Zhou Ming, Gründer und CEO von Lanzhou Technology und einem der versiertesten Chinesen im NLP-Bereich heute, bestätigt – wie zum Beispiel benannte Entitätsdatensätze MSRA-NER, Weibo- NER usw. Es gibt auch CMRC2018, CMRC2019, ExpMRC2022 usw., die auf GitHub zu finden sind, aber die Gesamtzahl ist im Vergleich zum englischen Datensatz ein Tropfen auf den heißen Stein.
Und einige von ihnen sind alt und kennen möglicherweise nicht die neuesten NLP-Forschungskonzepte (Forschung zu neuen Konzepten erscheint nur auf Englisch auf arXiv).
Obwohl qualitativ hochwertige chinesische Datensätze vorhanden sind, sind ihre Anzahl gering und ihre Verwendung umständlich. Dies ist eine schwerwiegende Situation, mit der sich alle Teams auseinandersetzen müssen, die groß angelegte Modellforschung betreiben. Auf einem früheren Forum der Fakultät für Elektronik der Tsinghua-Universität teilte Tang Jie, Professor an der Fakultät für Informatik der Tsinghua-Universität, mit, dass er bei der Vorbereitung von Daten für das Vortraining des 100-Milliarden-Dollar-Modells ChatGLM-130B mit der Situation konfrontiert war dass nach der Bereinigung der chinesischen Daten die nutzbare Menge weniger als 2 TB betrug.
Es ist dringend erforderlich, den Mangel an qualitativ hochwertigen Datensätzen in der chinesischen Welt zu beheben.
Eine der effektivsten Lösungen besteht darin, englische Daten direkt zum Trainieren großer Modelle zu verwenden.
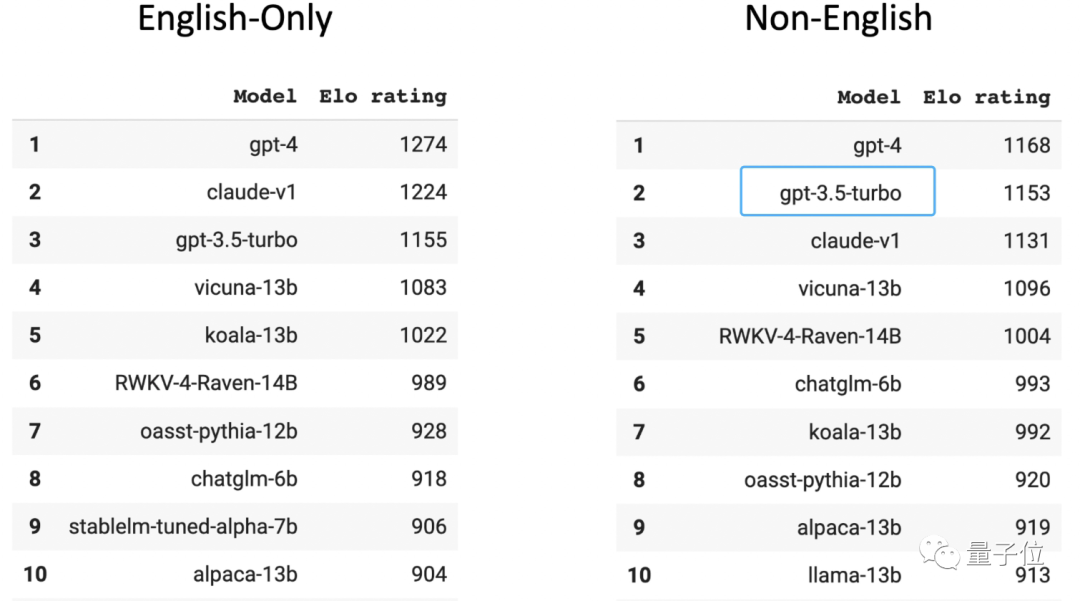
In der Chatbot-Arena-Liste der von menschlichen Spielern bewerteten großen anonymen Arenen belegt GPT-3.5 den zweiten Platz in der nicht-englischen Rangliste
(der erste ist GPT-4). Sie sollten wissen, dass 96 % der GPT-3.5-Trainingsdaten auf Englisch vorliegen. Mit Ausnahme anderer Sprachen ist die Menge der für das Training verwendeten chinesischen Daten so gering, dass sie in „n Tausendstel“ berechnet werden kann.
 Ein Doktorand in einem großen modellbezogenen Team an einer der drei besten Universitäten in China enthüllte, dass man, wenn diese Methode übernommen wird und nicht allzu mühsam ist, sogar eine Übersetzungssoftware mit dem zu konvertierenden Modell verbinden kann Alle Sprachen ins Englische, dann das Modell ausgeben, in Chinesisch konvertieren und an den Benutzer zurückgeben.
Ein Doktorand in einem großen modellbezogenen Team an einer der drei besten Universitäten in China enthüllte, dass man, wenn diese Methode übernommen wird und nicht allzu mühsam ist, sogar eine Übersetzungssoftware mit dem zu konvertierenden Modell verbinden kann Alle Sprachen ins Englische, dann das Modell ausgeben, in Chinesisch konvertieren und an den Benutzer zurückgeben.
Das auf diese Weise gefütterte große Modell ist jedoch immer das englische Denken. Wenn es um Inhalte mit chinesischen Sprachmerkmalen geht, z. B. um das Umschreiben von Redewendungen, umgangssprachlichem Verständnis und um das Umschreiben von Artikeln, werden diese oft nicht gut gehandhabt, was zu Übersetzungsfehlern oder möglichen kulturellen Abweichungen führt .
Eine andere Lösung besteht darin, den chinesischen Korpus zu sammeln, zu bereinigen und zu kennzeichnen,
einen neuen hochwertigen chinesischen Datensatz zu erstellen und ihn an große Modelle bereitzustellen. Nachdem sie die aktuelle Situation bemerkt hatten, entschieden sich viele große inländische Modellteams für den zweiten Weg und begannen, private Datenbanken zur Erstellung von Datensätzen zu verwenden. Baidu verfügt über inhaltliche ökologische Daten, Tencent über Daten zu öffentlichen Konten, Zhihu über Q&A-Daten und Alibaba über E-Commerce- und Logistikdaten. Mit unterschiedlichen gesammelten privaten Daten ist es möglich, Kernvorteilsbarrieren in bestimmten Szenarien und Bereichen festzulegen. Durch die strikte Erfassung, Sortierung, Überprüfung, Bereinigung und Kennzeichnung dieser Daten kann die Wirksamkeit und Effizienz der Schulung sichergestellt werden Modell. Genauigkeit. Die großen Modellteams, deren private Datenvorteile nicht so offensichtlich sind, begannen, Daten im gesamten Netzwerk zu crawlen (es ist absehbar, dass die Menge der Crawler-Daten sehr groß sein wird). Um das Pangu-Großmodell zu erstellen, hat Huawei 80 TB Text aus dem Internet gecrawlt und ihn schließlich in einen 1 TB großen chinesischen Datensatz bereinigt; der im Inspur Source 1.0-Training verwendete chinesische Datensatz erreichte 5000 GB (im Vergleich dazu). zu den Trainingsdaten des GPT3-Modells (Die Satzgröße beträgt 570 GB). Das kürzlich veröffentlichte Tianhe Tianyuan-Großmodell ist auch das Ergebnis der Sammlung und Organisation globaler Webdaten durch das Tianjin Supercomputing Center und umfasst auch verschiedene Open-Source-Trainingsdaten und professionelle Felddatensätze. Gleichzeitig kam es in den letzten zwei Monaten zu einem Phänomen, bei dem Menschen Brennholz für chinesische Datensätze sammelten – Viele Teams haben nacheinander Open-Source-Daten für China veröffentlicht setzt, um die aktuelle Situation auszugleichen. Unzulänglichkeiten oder Ungleichgewichte in chinesischen Open-Source-Datensätzen. Einige davon sind wie folgt organisiert: Wenn mehr chinesische Datensätze als Open-Source-Lösungen bereitgestellt und ins Rampenlicht gerückt werden, begrüßt die Branche die Haltung und freut sich. Zum Beispiel die Haltung von Zhang Peng, Gründer und CEO von Zhipu AI: Hochwertige chinesische Daten werden einfach im Boudoir versteckt. Jetzt ist sich jeder dieses Problems bewusst. Sie werden es natürlich tun. Es gibt entsprechende Lösungen, beispielsweise Open-Source-Daten. Es ist erwähnenswert, dass in dieser Phase zusätzlich zu den Daten vor dem Training auch menschliche Feedbackdaten unverzichtbar sind. Fertige Beispiele liegen vor Ihnen: Im Vergleich zu GPT-3 ist der wichtige Vorteil des ChatGPT-Overlays die Verwendung von RLHF (menschliches Feedback). Reinforcement Learning)#🎜 🎜#, generieren Sie qualitativ hochwertige, gekennzeichnete Daten zur Feinabstimmung, sodass sich große Modelle in eine Richtung entwickeln können, die den menschlichen Absichten entspricht. Open-Source-Datensatz, jeder sammelt Brennholz
Kurz gesagt, es entwickelt sich in eine gute Richtung, nicht wahr? 
Das obige ist der detaillierte Inhalt vonDas Geheimnis der inländischen ChatGPT-„Shell' wurde nun gelüftet. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Ich habe versucht, die Vibe -Codierung mit Cursor AI und es ist erstaunlich!
Mar 20, 2025 pm 03:34 PM
Ich habe versucht, die Vibe -Codierung mit Cursor AI und es ist erstaunlich!
Mar 20, 2025 pm 03:34 PM
Die Vibe -Codierung verändert die Welt der Softwareentwicklung, indem wir Anwendungen mit natürlicher Sprache anstelle von endlosen Codezeilen erstellen können. Inspiriert von Visionären wie Andrej Karpathy, lässt dieser innovative Ansatz Dev
 Top 5 Genai Starts vom Februar 2025: GPT-4,5, GROK-3 & MEHR!
Mar 22, 2025 am 10:58 AM
Top 5 Genai Starts vom Februar 2025: GPT-4,5, GROK-3 & MEHR!
Mar 22, 2025 am 10:58 AM
Februar 2025 war ein weiterer bahnbrechender Monat für die Generative KI, die uns einige der am meisten erwarteten Modell-Upgrades und bahnbrechenden neuen Funktionen gebracht hat. Von Xais Grok 3 und Anthropics Claude 3.7 -Sonett, um g zu eröffnen
 Wie benutze ich Yolo V12 zur Objekterkennung?
Mar 22, 2025 am 11:07 AM
Wie benutze ich Yolo V12 zur Objekterkennung?
Mar 22, 2025 am 11:07 AM
Yolo (Sie schauen nur einmal) war ein führender Echtzeit-Objekterkennungsrahmen, wobei jede Iteration die vorherigen Versionen verbessert. Die neueste Version Yolo V12 führt Fortschritte vor, die die Genauigkeit erheblich verbessern
 Ist Chatgpt 4 o verfügbar?
Mar 28, 2025 pm 05:29 PM
Ist Chatgpt 4 o verfügbar?
Mar 28, 2025 pm 05:29 PM
Chatgpt 4 ist derzeit verfügbar und weit verbreitet, wodurch im Vergleich zu seinen Vorgängern wie ChatGPT 3.5 signifikante Verbesserungen beim Verständnis des Kontextes und des Generierens kohärenter Antworten zeigt. Zukünftige Entwicklungen können mehr personalisierte Inters umfassen
 Gencast von Google: Wettervorhersage mit Gencast Mini Demo
Mar 16, 2025 pm 01:46 PM
Gencast von Google: Wettervorhersage mit Gencast Mini Demo
Mar 16, 2025 pm 01:46 PM
Gencast von Google Deepmind: Eine revolutionäre KI für die Wettervorhersage Die Wettervorhersage wurde einer dramatischen Transformation unterzogen, die sich von rudimentären Beobachtungen zu ausgefeilten AI-angetriebenen Vorhersagen überschreitet. Google DeepMinds Gencast, ein Bodenbrei
 Welche KI ist besser als Chatgpt?
Mar 18, 2025 pm 06:05 PM
Welche KI ist besser als Chatgpt?
Mar 18, 2025 pm 06:05 PM
Der Artikel erörtert KI -Modelle, die Chatgpt wie Lamda, Lama und Grok übertreffen und ihre Vorteile in Bezug auf Genauigkeit, Verständnis und Branchenauswirkungen hervorheben. (159 Charaktere)
 Beste KI -Kunstgeneratoren (kostenlos & amp; bezahlt) für kreative Projekte
Apr 02, 2025 pm 06:10 PM
Beste KI -Kunstgeneratoren (kostenlos & amp; bezahlt) für kreative Projekte
Apr 02, 2025 pm 06:10 PM
Der Artikel überprüft Top -KI -Kunstgeneratoren, diskutiert ihre Funktionen, Eignung für kreative Projekte und Wert. Es zeigt MidJourney als den besten Wert für Fachkräfte und empfiehlt Dall-E 2 für hochwertige, anpassbare Kunst.
 O1 gegen GPT-4O: Ist OpenAIs neues Modell besser als GPT-4O?
Mar 16, 2025 am 11:47 AM
O1 gegen GPT-4O: Ist OpenAIs neues Modell besser als GPT-4O?
Mar 16, 2025 am 11:47 AM
Openais O1: Ein 12-tägiger Geschenkbummel beginnt mit ihrem bisher mächtigsten Modell Die Ankunft im Dezember bringt eine globale Verlangsamung, Schneeflocken in einigen Teilen der Welt, aber Openai fängt gerade erst an. Sam Altman und sein Team starten ein 12-tägiges Geschenk Ex
