

Warum ist Redis so schnell?

Redis ist eine NoSQL-Datenbank, die auf Schlüssel-Wert-Paaren basiert. Der Wert von Redis kann aus verschiedenen Datenstrukturen und Algorithmen wie String, Hash, Liste, Set, Zset, Bitmaps, HyperLogLog usw. bestehen. Redis verfügt über viele Funktionen, wie z. B. Schlüsselablauf, Veröffentlichung und Abonnement, Transaktionen, Lua-Skripte, Sentinels, Cluster usw.
Laut offiziellen Leistungsdaten kann Redis Befehle mit sehr hoher Geschwindigkeit ausführen und seine QPS können mehr als 100.000 erreichen. Daher stellt dieser Artikel hauptsächlich vor, wo Redis schnell ist. Die Hauptpunkte sind wie folgt:
1. Entwicklungssprache
Jetzt verwenden wir alle Hochsprachen für die Programmierung, wie Java, Python usw. Sie denken vielleicht, dass die C-Sprache sehr alt ist, aber sie ist wirklich nützlich. Schließlich ist das Unix-System in C implementiert, sodass die C-Sprache dem Betriebssystem sehr nahe kommt. Redis wurde in der Sprache C entwickelt, sodass die Ausführung schneller erfolgt.
Eine weitere Sache: Die Schüler sollten sich auf das Erlernen der C-Sprache konzentrieren, da dies zu einem besseren Verständnis der Computerbetriebssysteme beiträgt. Denken Sie nicht, dass Sie nach dem Erlernen einer Hochsprache nicht auf die unterste Schicht achten müssen. Die Schulden, die Sie schulden, müssen immer zurückgezahlt werden. Hier ist ein Buch, das schwieriger zu empfehlen ist: „In-Depth Understanding of Computing Systems“.
2. Reiner Speicherzugriff
Redis verwendet Speicher zum Speichern aller Daten, sodass im normalen Betrieb keine Daten von der Festplatte gelesen werden müssen, um keine Daten zu synchronisieren. Daher beträgt die Anzahl der E/As 0. Die Speicherreaktionszeit beträgt etwa 100 Nanosekunden, was eine wichtige Grundlage für die hohe Geschwindigkeit von Redis darstellt. Werfen wir zunächst einen Blick auf die Geschwindigkeit der CPU:
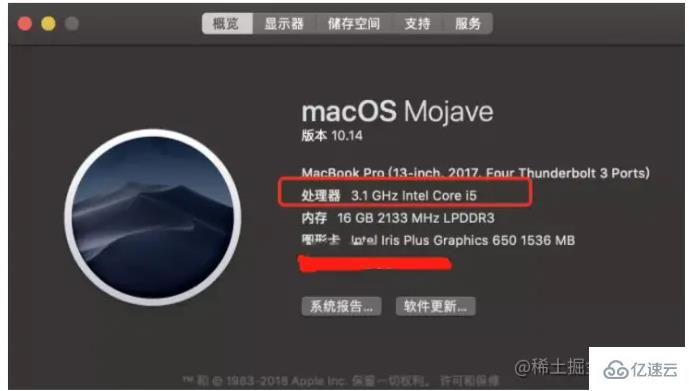
Nehmen wir als Beispiel meinen Computer. Seine Hauptfrequenz beträgt 3,1 G, was bedeutet, dass er 3,1 Milliarden Anweisungen pro Sekunde ausführen kann. Die Verarbeitungsgeschwindigkeit der CPU ist sehr langsam. Im Vergleich dazu ist der Speicher 100-mal langsamer und die Festplatte 1.000.000-mal langsamer.
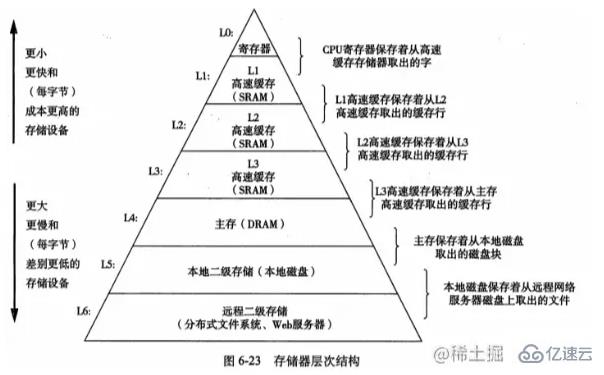
Ich habe mir ein Bild aus „In-Depth Understanding of Computer Systems“ ausgeliehen, das eine typische Speicherhierarchie zeigt. Auf der L0-Ebene kann die CPU in mehreren Taktzyklen erneuert werden In CPU-Taktzyklen und dann im DRAM-basierten Hauptspeicher kann in Dutzenden bis Hunderten von Taktzyklen darauf zugegriffen werden.
3. Einzelthread
Einzelthread kann die Implementierung von Algorithmen vereinfachen, aber es ist nicht nur schwierig, gleichzeitige Datenstrukturen zu implementieren, sondern auch mühsam zu testen. Bei der serverseitigen Entwicklung sind Sperren und Thread-Wechsel normalerweise Leistungskiller, und die Verwendung eines einzelnen Threads kann den damit verbundenen Verbrauch vermeiden. Natürlich hat Single-Threading auch seine Nachteile, was auch der Albtraum von Redis ist: das Blockieren. Wenn die Ausführung eines Befehls zu lange dauert, werden andere Befehle blockiert, was für Redis sehr schwerwiegend ist. Daher ist Redis eine Datenbank für schnelle Ausführungsszenarien.
Neben Redis ist auch Node.js Single-Threaded und Nginx ist ebenfalls Single-Threaded, aber beides sind Modelle von Hochleistungsservern.
4. Nicht blockierender Mehrkanal-E/A-Multiplexmechanismus
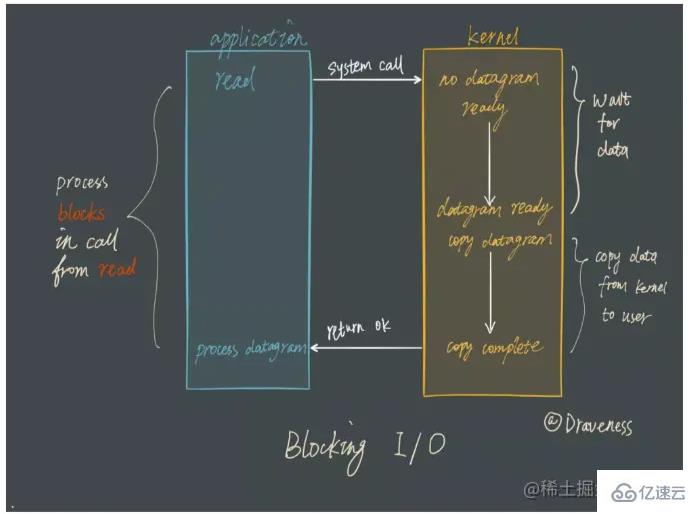
Lassen Sie uns vorher darüber sprechen, wie herkömmliche blockierende E/A funktioniert: wenn Sie einen bestimmten Dateideskriptor (File Descriptor) lesen oder schreiben Lesen und Schreiben: Wenn die Daten nicht empfangen werden, wird der Thread angehalten, bis die Daten empfangen werden.
Obwohl das Blockierungsmodell leicht zu verstehen ist, wird es nicht verwendet, wenn mehrere Client-Aufgaben verarbeitet werden müssen.
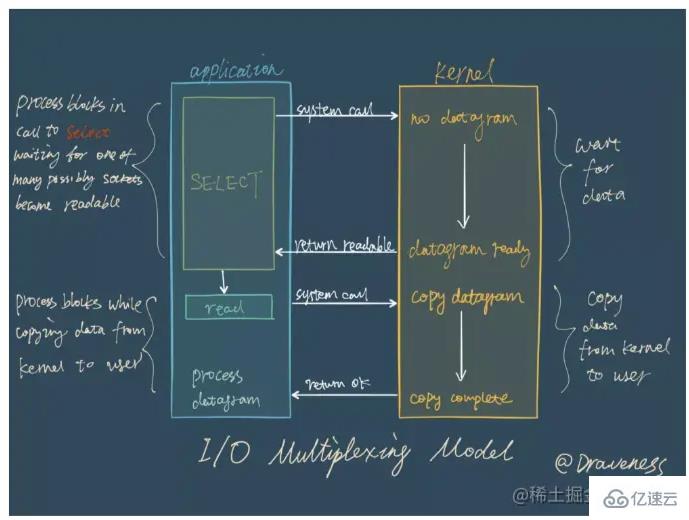
I/O-Multiplexing bedeutet eigentlich, dass die Verwaltung mehrerer Verbindungen im selben Prozess erfolgen kann. Mehrkanal bezieht sich auf Netzwerkverbindungen, und Multiplexing ist genau derselbe Thread. Bei Netzwerkdiensten besteht die Aufgabe des E/A-Multiplexings darin, den Geschäftscode über mehrere Verbindungsereignisse gleichzeitig zu informieren. Die Verarbeitungsmethode wird durch den Geschäftscode bestimmt.
Im I/O-Multiplexing-Modell ist der wichtigste Funktionsaufruf die I/O-Multiplexing-Funktion. Diese Methode kann das gleichzeitige Lesen und Schreiben mehrerer Dateideskriptoren (fd) überwachen gelesen/geschrieben werden kann, gibt diese Methode die Anzahl der lesbaren/schreibbaren fds zurück.
Redis verwendet Epoll als Implementierung der E/A-Multiplexing-Technologie, und das eigene Ereignisverarbeitungsmodell von Redis wandelt das Lesen, Schreiben, Schließen usw. von Epoll in Ereignisse um, sodass keine Verschwendung von Netzwerk-E/A zu viel Zeit entsteht . Realisieren Sie die Überwachung mehrerer FD-Lese- und Schreibvorgänge, um die Leistung zu verbessern.
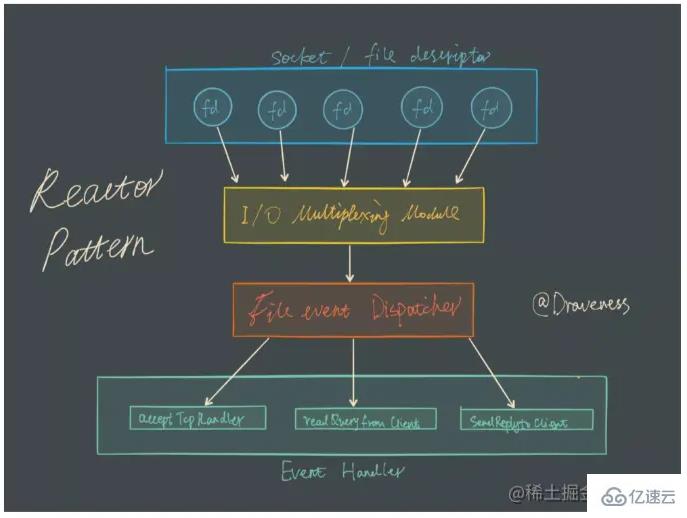
Lassen Sie uns ein anschauliches Beispiel geben. Ein TCP-Server verwaltet beispielsweise 20 Client-Sockets.
Ein Plan: Sequentielle Verarbeitung. Wenn der erste Socket aufgrund der Netzwerkkarte langsam Daten liest, wird nach der Blockierung alles durcheinander gebracht.
Plan B: Erstellen Sie einen Klon-Unterprozess, um jede Socket-Anfrage zu verarbeiten. Ganz zu schweigen davon, dass jeder Prozess viele Systemressourcen verbraucht und der Prozesswechsel allein ausreicht, um das Betriebssystem zu ermüden.
C-Schema (E/A-Multiplexmodell, epoll): Registrieren Sie den fd, der dem Benutzer-Socket entspricht, in epoll (tatsächlich wird zwischen dem Server und dem Betriebssystem nicht der fd des Sockets, sondern die Datenstruktur von fd_set übergeben). und dann sagt epoll nur, dass für Sockets, die gelesen/geschrieben werden müssen, nur die aktiven und sich ändernden Socket-FDs verarbeitet werden müssen.
Auf diese Weise wird der gesamte Prozess nur blockiert, wenn Epoll aufgerufen wird, und das Senden und Empfangen von Kundennachrichten wird nicht blockiert.
Das obige ist der detaillierte Inhalt vonWarum ist Redis so schnell?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1393
1393
 52
1207
24
52
1207
24

 So erstellen Sie den Redis -Clustermodus
Apr 10, 2025 pm 10:15 PM
So erstellen Sie den Redis -Clustermodus
Apr 10, 2025 pm 10:15 PM
Der Redis -Cluster -Modus bietet Redis -Instanzen durch Sharding, die Skalierbarkeit und Verfügbarkeit verbessert. Die Bauschritte sind wie folgt: Erstellen Sie ungerade Redis -Instanzen mit verschiedenen Ports; Erstellen Sie 3 Sentinel -Instanzen, Monitor -Redis -Instanzen und Failover; Konfigurieren von Sentinel -Konfigurationsdateien, Informationen zur Überwachung von Redis -Instanzinformationen und Failover -Einstellungen hinzufügen. Konfigurieren von Redis -Instanzkonfigurationsdateien, aktivieren Sie den Cluster -Modus und geben Sie den Cluster -Informationsdateipfad an. Erstellen Sie die Datei nodes.conf, die Informationen zu jeder Redis -Instanz enthält. Starten Sie den Cluster, führen Sie den Befehl erstellen aus, um einen Cluster zu erstellen und die Anzahl der Replikate anzugeben. Melden Sie sich im Cluster an, um den Befehl cluster info auszuführen, um den Clusterstatus zu überprüfen. machen
 So löschen Sie Redis -Daten
Apr 10, 2025 pm 10:06 PM
So löschen Sie Redis -Daten
Apr 10, 2025 pm 10:06 PM
So löschen Sie Redis -Daten: Verwenden Sie den Befehl Flushall, um alle Schlüsselwerte zu löschen. Verwenden Sie den Befehl flushdb, um den Schlüsselwert der aktuell ausgewählten Datenbank zu löschen. Verwenden Sie SELECT, um Datenbanken zu wechseln, und löschen Sie dann FlushDB, um mehrere Datenbanken zu löschen. Verwenden Sie den Befehl del, um einen bestimmten Schlüssel zu löschen. Verwenden Sie das Redis-Cli-Tool, um die Daten zu löschen.
 So lesen Sie Redis -Warteschlange
Apr 10, 2025 pm 10:12 PM
So lesen Sie Redis -Warteschlange
Apr 10, 2025 pm 10:12 PM
Um eine Warteschlange aus Redis zu lesen, müssen Sie den Warteschlangenname erhalten, die Elemente mit dem Befehl LPOP lesen und die leere Warteschlange verarbeiten. Die spezifischen Schritte sind wie folgt: Holen Sie sich den Warteschlangenname: Nennen Sie ihn mit dem Präfix von "Warteschlange:" wie "Warteschlangen: My-Queue". Verwenden Sie den Befehl LPOP: Wischen Sie das Element aus dem Kopf der Warteschlange aus und geben Sie seinen Wert zurück, z. B. die LPOP-Warteschlange: my-queue. Verarbeitung leerer Warteschlangen: Wenn die Warteschlange leer ist, gibt LPOP NIL zurück, und Sie können überprüfen, ob die Warteschlange existiert, bevor Sie das Element lesen.
 So verwenden Sie den Befehl Redis
Apr 10, 2025 pm 08:45 PM
So verwenden Sie den Befehl Redis
Apr 10, 2025 pm 08:45 PM
Die Verwendung der REDIS -Anweisung erfordert die folgenden Schritte: Öffnen Sie den Redis -Client. Geben Sie den Befehl ein (Verbschlüsselwert). Bietet die erforderlichen Parameter (variiert von der Anweisung bis zur Anweisung). Drücken Sie die Eingabetaste, um den Befehl auszuführen. Redis gibt eine Antwort zurück, die das Ergebnis der Operation anzeigt (normalerweise in Ordnung oder -err).
 So verwenden Sie Redis Lock
Apr 10, 2025 pm 08:39 PM
So verwenden Sie Redis Lock
Apr 10, 2025 pm 08:39 PM
Um die Operationen zu sperren, muss die Sperre durch den Befehl setNX erfasst werden und dann den Befehl Ablauf verwenden, um die Ablaufzeit festzulegen. Die spezifischen Schritte sind: (1) Verwenden Sie den Befehl setNX, um zu versuchen, ein Schlüsselwertpaar festzulegen; (2) Verwenden Sie den Befehl Ablauf, um die Ablaufzeit für die Sperre festzulegen. (3) Verwenden Sie den Befehl Del, um die Sperre zu löschen, wenn die Sperre nicht mehr benötigt wird.
 So lesen Sie den Quellcode von Redis
Apr 10, 2025 pm 08:27 PM
So lesen Sie den Quellcode von Redis
Apr 10, 2025 pm 08:27 PM
Der beste Weg, um Redis -Quellcode zu verstehen, besteht darin, Schritt für Schritt zu gehen: Machen Sie sich mit den Grundlagen von Redis vertraut. Wählen Sie ein bestimmtes Modul oder eine bestimmte Funktion als Ausgangspunkt. Beginnen Sie mit dem Einstiegspunkt des Moduls oder der Funktion und sehen Sie sich die Codezeile nach Zeile an. Zeigen Sie den Code über die Funktionsaufrufkette an. Kennen Sie die von Redis verwendeten Datenstrukturen. Identifizieren Sie den von Redis verwendeten Algorithmus.
 So verwenden Sie die Befehlszeile der Redis
Apr 10, 2025 pm 10:18 PM
So verwenden Sie die Befehlszeile der Redis
Apr 10, 2025 pm 10:18 PM
Verwenden Sie das Redis-Befehlszeilen-Tool (REDIS-CLI), um Redis in folgenden Schritten zu verwalten und zu betreiben: Stellen Sie die Adresse und den Port an, um die Adresse und den Port zu stellen. Senden Sie Befehle mit dem Befehlsnamen und den Parametern an den Server. Verwenden Sie den Befehl Hilfe, um Hilfeinformationen für einen bestimmten Befehl anzuzeigen. Verwenden Sie den Befehl zum Beenden, um das Befehlszeilenwerkzeug zu beenden.
 So konfigurieren Sie die Ausführungszeit der Lua -Skript in CentOS Redis
Apr 14, 2025 pm 02:12 PM
So konfigurieren Sie die Ausführungszeit der Lua -Skript in CentOS Redis
Apr 14, 2025 pm 02:12 PM
Auf CentOS -Systemen können Sie die Ausführungszeit von LuA -Skripten einschränken, indem Sie Redis -Konfigurationsdateien ändern oder Befehle mit Redis verwenden, um zu verhindern, dass bösartige Skripte zu viele Ressourcen konsumieren. Methode 1: Ändern Sie die Redis -Konfigurationsdatei und suchen Sie die Redis -Konfigurationsdatei: Die Redis -Konfigurationsdatei befindet sich normalerweise in /etc/redis/redis.conf. Konfigurationsdatei bearbeiten: Öffnen Sie die Konfigurationsdatei mit einem Texteditor (z. B. VI oder Nano): Sudovi/etc/redis/redis.conf Setzen Sie die LUA -Skriptausführungszeit.
