

Wie Redis+Caffeine verteilte Cache-Komponenten der zweiten Ebene implementiert

Der sogenannte Second-Level-Cache
Caching besteht darin, Daten von einem langsamer lesenden Medium zu lesen und sie auf einem schneller lesenden Medium, z. B. einem Festplattenspeicher, abzulegen.
Normalerweise speichern wir Daten auf Datenträgern, beispielsweise in einer Datenbank. Wenn Sie jedes Mal aus der Datenbank lesen, wird die Lesegeschwindigkeit durch die E/A der Festplatte selbst beeinflusst, sodass ein Speichercache wie bei Redis vorhanden ist. Die Daten können ausgelesen und im Speicher abgelegt werden, sodass die Daten bei Bedarf direkt aus dem Speicher zurückgegeben werden können, was die Geschwindigkeit erheblich verbessern kann.
Aber im Allgemeinen wird Redis separat in einem Cluster bereitgestellt, sodass ein Netzwerk-E/A-Verbrauch entsteht. Obwohl die Verbindung mit dem Redis-Cluster bereits über ein Tool wie einen Verbindungspool verfügt, wird dennoch ein gewisser Datenübertragungsverbrauch auftreten. Es gibt also einen In-Process-Cache, beispielsweise Koffein. Wenn der In-Application-Cache über qualifizierte Daten verfügt, können diese direkt verwendet werden, ohne dass sie über das Netzwerk von Redis abgerufen werden müssen. Dadurch entsteht ein zweistufiger Cache. Der In-Application-Cache wird als Cache der ersten Ebene bezeichnet, und der Remote-Cache (z. B. Redis) wird als Cache der zweiten Ebene bezeichnet.
Muss das System die CPU-Auslastung zwischenspeichern: Wenn Sie bestimmte Anwendungen haben, die viel CPU verbrauchen müssen, um zu berechnen und Ergebnisse zu erhalten.
Wenn Ihr Datenbankverbindungspool relativ inaktiv ist, sollten Sie den Cache nicht verwenden, um die E/A-Ressourcen der Datenbank zu belegen. Erwägen Sie die Verwendung von Caching, wenn der Datenbankverbindungspool ausgelastet ist oder häufig Warnungen über unzureichende Verbindungen meldet.
Vorteile des verteilten Second-Level-Cache
Redis wird zum Speichern heißer Daten verwendet, und auf Daten, die sich nicht in Redis befinden, wird direkt aus der Datenbank zugegriffen.
Haben Sie bereits Redis, warum müssen wir über Prozess-Caches wie Guava und Koffein Bescheid wissen:
Wenn Redis nicht verfügbar ist, können wir zu diesem Zeitpunkt nur auf die Datenbank zugreifen, was leicht zu einer Lawine führen kann, im Allgemeinen jedoch wird nicht passieren.
Der Zugriff auf Redis erfordert einen gewissen Netzwerk-E/A- und Serialisierungs- und Deserialisierungsaufwand. Obwohl die Leistung sehr hoch ist, ist sie nicht so schnell wie die lokale Methode, um den Zugriff weiter zu beschleunigen. Diese Idee gilt nicht nur für unsere Internetarchitektur. Wir verwenden L1-, L2- und L3-Mehrebenen-Caches in Computersystemen, um den direkten Zugriff auf den Speicher zu reduzieren und dadurch den Zugriff zu beschleunigen.
Wenn wir also nur Redis verwenden, kann es die meisten unserer Anforderungen erfüllen. Wenn wir jedoch eine höhere Leistung und eine höhere Verfügbarkeit anstreben müssen, müssen wir den mehrstufigen Cache verstehen.
Beschreibung des Datenleseprozesses des Cache-Betriebsprozesses der zweiten Ebene
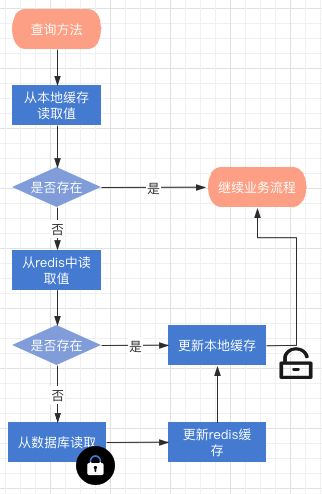
Wenn weder Redis noch der lokale Cache den Wert abfragen können, wird der Aktualisierungsprozess ausgelöst. Der gesamte Prozess ist eine Beschreibung des Prozesses zur Ungültigmachung des gesperrten Caches
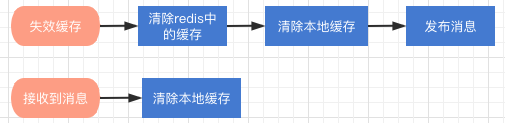
redis-Update Es wird durch das Löschen des Cache-Schlüssels ausgelöst. Wie verwende ich die Komponente nach dem Löschen des Redis-Cache?
Die Komponente wird basierend auf dem Spring Cache-Framework geändert. Um den verteilten Cache im Projekt zu verwenden, müssen Sie nur Folgendes hinzufügen: CacheManager = „L2_CacheManager“ oder CacheManager = CacheRedisCaffeineAutoConfiguration
//这个方法会使用分布式二级缓存来提供查询
@Cacheable(cacheNames = CacheNames.CACHE_12HOUR, cacheManager = "L2_CacheManager")
public Config getAllValidateConfig() {
}Wenn Sie möchten Wenn Sie sowohl verteilte Cache-Komponenten als auch verteilte Second-Level-Cache-Komponenten verwenden möchten, müssen Sie eine @Primary CacheManager-Bean in Spring einfügen. Cache Die .CacheManager-Schnittstelle und die Vererbung org.springframework.cache.support.AbstractValueAdaptingCache implementieren das Lesen und Schreiben des Caches unter dem Spring-Cache-Framework.
RedisCaffeineCacheManager implementiert die CacheManager-Schnittstelle
RedisCaffeineCacheManager.class verwaltet hauptsächlich Cache-Instanzen, generiert entsprechende Cache-Verwaltungs-Beans basierend auf verschiedenen CacheNames und fügt sie dann in eine Karte ein.
@Primary
@Bean("deaultCacheManager")
public RedisCacheManager cacheManager(RedisConnectionFactory factory) {
// 生成一个默认配置,通过config对象即可对缓存进行自定义配置
RedisCacheConfiguration config = RedisCacheConfiguration.defaultCacheConfig();
// 设置缓存的默认过期时间,也是使用Duration设置
config = config.entryTtl(Duration.ofMinutes(2)).disableCachingNullValues();
// 设置一个初始化的缓存空间set集合
Set<String> cacheNames = new HashSet<>();
cacheNames.add(CacheNames.CACHE_15MINS);
cacheNames.add(CacheNames.CACHE_30MINS);
// 对每个缓存空间应用不同的配置
Map<String, RedisCacheConfiguration> configMap = new HashMap<>();
configMap.put(CacheNames.CACHE_15MINS, config.entryTtl(Duration.ofMinutes(15)));
configMap.put(CacheNames.CACHE_30MINS, config.entryTtl(Duration.ofMinutes(30)));
// 使用自定义的缓存配置初始化一个cacheManager
RedisCacheManager cacheManager = RedisCacheManager.builder(factory)
.initialCacheNames(cacheNames) // 注意这两句的调用顺序,一定要先调用该方法设置初始化的缓存名,再初始化相关的配置
.withInitialCacheConfigurations(configMap)
.build();
return cacheManager;
}RedisCaffeineCache erbt AbstractValueAdaptingCache
Der Kern ist die get-Methode und die put-Methode.
//这个方法会使用分布式二级缓存
@Cacheable(cacheNames = CacheNames.CACHE_12HOUR, cacheManager = "L2_CacheManager")
public Config getAllValidateConfig() {
}
//这个方法会使用分布式缓存
@Cacheable(cacheNames = CacheNames.CACHE_12HOUR)
public Config getAllValidateConfig2() {
}Das obige ist der detaillierte Inhalt vonWie Redis+Caffeine verteilte Cache-Komponenten der zweiten Ebene implementiert. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 So erstellen Sie den Redis -Clustermodus
Apr 10, 2025 pm 10:15 PM
So erstellen Sie den Redis -Clustermodus
Apr 10, 2025 pm 10:15 PM
Der Redis -Cluster -Modus bietet Redis -Instanzen durch Sharding, die Skalierbarkeit und Verfügbarkeit verbessert. Die Bauschritte sind wie folgt: Erstellen Sie ungerade Redis -Instanzen mit verschiedenen Ports; Erstellen Sie 3 Sentinel -Instanzen, Monitor -Redis -Instanzen und Failover; Konfigurieren von Sentinel -Konfigurationsdateien, Informationen zur Überwachung von Redis -Instanzinformationen und Failover -Einstellungen hinzufügen. Konfigurieren von Redis -Instanzkonfigurationsdateien, aktivieren Sie den Cluster -Modus und geben Sie den Cluster -Informationsdateipfad an. Erstellen Sie die Datei nodes.conf, die Informationen zu jeder Redis -Instanz enthält. Starten Sie den Cluster, führen Sie den Befehl erstellen aus, um einen Cluster zu erstellen und die Anzahl der Replikate anzugeben. Melden Sie sich im Cluster an, um den Befehl cluster info auszuführen, um den Clusterstatus zu überprüfen. machen
 So löschen Sie Redis -Daten
Apr 10, 2025 pm 10:06 PM
So löschen Sie Redis -Daten
Apr 10, 2025 pm 10:06 PM
So löschen Sie Redis -Daten: Verwenden Sie den Befehl Flushall, um alle Schlüsselwerte zu löschen. Verwenden Sie den Befehl flushdb, um den Schlüsselwert der aktuell ausgewählten Datenbank zu löschen. Verwenden Sie SELECT, um Datenbanken zu wechseln, und löschen Sie dann FlushDB, um mehrere Datenbanken zu löschen. Verwenden Sie den Befehl del, um einen bestimmten Schlüssel zu löschen. Verwenden Sie das Redis-Cli-Tool, um die Daten zu löschen.
 So lesen Sie Redis -Warteschlange
Apr 10, 2025 pm 10:12 PM
So lesen Sie Redis -Warteschlange
Apr 10, 2025 pm 10:12 PM
Um eine Warteschlange aus Redis zu lesen, müssen Sie den Warteschlangenname erhalten, die Elemente mit dem Befehl LPOP lesen und die leere Warteschlange verarbeiten. Die spezifischen Schritte sind wie folgt: Holen Sie sich den Warteschlangenname: Nennen Sie ihn mit dem Präfix von "Warteschlange:" wie "Warteschlangen: My-Queue". Verwenden Sie den Befehl LPOP: Wischen Sie das Element aus dem Kopf der Warteschlange aus und geben Sie seinen Wert zurück, z. B. die LPOP-Warteschlange: my-queue. Verarbeitung leerer Warteschlangen: Wenn die Warteschlange leer ist, gibt LPOP NIL zurück, und Sie können überprüfen, ob die Warteschlange existiert, bevor Sie das Element lesen.
 So verwenden Sie den Befehl Redis
Apr 10, 2025 pm 08:45 PM
So verwenden Sie den Befehl Redis
Apr 10, 2025 pm 08:45 PM
Die Verwendung der REDIS -Anweisung erfordert die folgenden Schritte: Öffnen Sie den Redis -Client. Geben Sie den Befehl ein (Verbschlüsselwert). Bietet die erforderlichen Parameter (variiert von der Anweisung bis zur Anweisung). Drücken Sie die Eingabetaste, um den Befehl auszuführen. Redis gibt eine Antwort zurück, die das Ergebnis der Operation anzeigt (normalerweise in Ordnung oder -err).
 So verwenden Sie Redis Lock
Apr 10, 2025 pm 08:39 PM
So verwenden Sie Redis Lock
Apr 10, 2025 pm 08:39 PM
Um die Operationen zu sperren, muss die Sperre durch den Befehl setNX erfasst werden und dann den Befehl Ablauf verwenden, um die Ablaufzeit festzulegen. Die spezifischen Schritte sind: (1) Verwenden Sie den Befehl setNX, um zu versuchen, ein Schlüsselwertpaar festzulegen; (2) Verwenden Sie den Befehl Ablauf, um die Ablaufzeit für die Sperre festzulegen. (3) Verwenden Sie den Befehl Del, um die Sperre zu löschen, wenn die Sperre nicht mehr benötigt wird.
 So lesen Sie den Quellcode von Redis
Apr 10, 2025 pm 08:27 PM
So lesen Sie den Quellcode von Redis
Apr 10, 2025 pm 08:27 PM
Der beste Weg, um Redis -Quellcode zu verstehen, besteht darin, Schritt für Schritt zu gehen: Machen Sie sich mit den Grundlagen von Redis vertraut. Wählen Sie ein bestimmtes Modul oder eine bestimmte Funktion als Ausgangspunkt. Beginnen Sie mit dem Einstiegspunkt des Moduls oder der Funktion und sehen Sie sich die Codezeile nach Zeile an. Zeigen Sie den Code über die Funktionsaufrufkette an. Kennen Sie die von Redis verwendeten Datenstrukturen. Identifizieren Sie den von Redis verwendeten Algorithmus.
 So verwenden Sie die Befehlszeile der Redis
Apr 10, 2025 pm 10:18 PM
So verwenden Sie die Befehlszeile der Redis
Apr 10, 2025 pm 10:18 PM
Verwenden Sie das Redis-Befehlszeilen-Tool (REDIS-CLI), um Redis in folgenden Schritten zu verwalten und zu betreiben: Stellen Sie die Adresse und den Port an, um die Adresse und den Port zu stellen. Senden Sie Befehle mit dem Befehlsnamen und den Parametern an den Server. Verwenden Sie den Befehl Hilfe, um Hilfeinformationen für einen bestimmten Befehl anzuzeigen. Verwenden Sie den Befehl zum Beenden, um das Befehlszeilenwerkzeug zu beenden.
 So konfigurieren Sie die Ausführungszeit der Lua -Skript in CentOS Redis
Apr 14, 2025 pm 02:12 PM
So konfigurieren Sie die Ausführungszeit der Lua -Skript in CentOS Redis
Apr 14, 2025 pm 02:12 PM
Auf CentOS -Systemen können Sie die Ausführungszeit von LuA -Skripten einschränken, indem Sie Redis -Konfigurationsdateien ändern oder Befehle mit Redis verwenden, um zu verhindern, dass bösartige Skripte zu viele Ressourcen konsumieren. Methode 1: Ändern Sie die Redis -Konfigurationsdatei und suchen Sie die Redis -Konfigurationsdatei: Die Redis -Konfigurationsdatei befindet sich normalerweise in /etc/redis/redis.conf. Konfigurationsdatei bearbeiten: Öffnen Sie die Konfigurationsdatei mit einem Texteditor (z. B. VI oder Nano): Sudovi/etc/redis/redis.conf Setzen Sie die LUA -Skriptausführungszeit.
