

So verwenden Sie das Python-Async-Modul

Coroutinen, auch Micro-Threads genannt, sind eine Technologie zur Kontextumschaltung im Benutzermodus. Kurz gesagt, es handelt sich tatsächlich um einen Thread zum Umschalten von Codeblöcken zur Ausführung. Die Unterstützung von Python für Coroutinen wird durch Generatoren implementiert.
Im Generator können wir nicht nur die for-Schleife durchlaufen, sondern auch kontinuierlich die Funktion next() aufrufen, um den nächsten von der yield-Anweisung zurückgegebenen Wert zu erhalten. Pythons yield kann nicht nur zur Rückgabe von Werten verwendet werden, sondern kann auch vom Aufrufer übergebene Parameter empfangen.
1. Was ist ein Generator?
Der Mechanismus namens Generator in Python wird während der Schleife berechnet. Indem Sie einen Algorithmus angeben und dann während des Anrufs den wahren Wert berechnen.
Sie können next() verwenden, wenn Sie den Wert vom Generator abrufen müssen, aber im Allgemeinen verwenden Sie eine for-Schleife, um ihn abzurufen.
Generator-Implementierungsmethodengenerator, verwenden Sie () zur Darstellung von
wie: [1, 2, 3, 4, 5], Generatormethode:
data = [1, 2, 3, 4, 5] (x * x for x in len(data))
Funktionsdefinition Verwenden Sie in einigen logisch komplexen Szenarien die erste Methode. Die Methode ist nicht geeignet, daher gibt es Möglichkeiten, Typfunktionen zu definieren, wie zum Beispiel:
def num(x):
while (x < 10):
print(x * x)
x += 1
g = num(1)
for item in g:
print(item)Wenn yield in der Funktion erscheint, wird sie zu diesem Zeitpunkt zu einem Generator.
def num(x):
while (x < 10):
yield x * x # 返回结果,下次从这个地方继续?
x += 1
g = num(1) # 返回的是generator对象
for item in g:
print(item)Wird eine Generatorfunktion, die jedes Mal ausgeführt wird, wenn next() aufgerufen wird , kehrt zurück, wenn eine Yield-Anweisung auftritt, und setzt die Ausführung bei der letzten zurückgegebenen Yield-Anweisung fort, wenn sie erneut ausgeführt wird.
2. Verwenden Sie Asyncio, um asynchrones IO zu implementieren.
Asynchrones IO wird über eine Ereignisschleife und eine Coroutine-Funktion implementiert. Die Ereignisschleife überwacht kontinuierlich interne Aufgaben und führt sie aus, wenn sie vorhanden sind. Aufgaben werden durch das Ereignis bestimmt Schleife Aufgaben verarbeiten. Wenn die Aufgabenliste leer ist, wird das Ereignis beendet.
import asyncio # 生成或获取事件循环对象loop;类比Java的Netty,我理解为开启一个selector loop = asyncio.get_event_loop() # 将协程函数(任务)提交到事件循环的任务列表中,协程函数执行完成之后终止。 # run_until_complete 会检查协程函数的运行状态,并执行协程函数 loop.run_until_complete( func() )
Testdemo
import asyncio
import time
async def test():
print("io等待")
await asyncio.sleep(1)
return 'hello'
async def hello():
print("Hello world")
r = await test()
print("hello again")
loop = asyncio.get_event_loop()
tasks = [hello(), hello()]
loop.run_until_complete(asyncio.wait(tasks))
loop.close()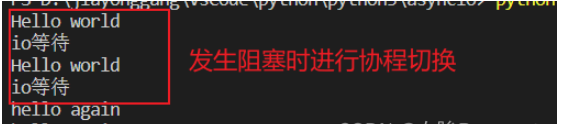 Wenn Sie die Coroutine-Funktion ausführen möchten, müssen Sie dieses Objekt zur Verarbeitung an die Ereignisschleife übergeben.
Wenn Sie die Coroutine-Funktion ausführen möchten, müssen Sie dieses Objekt zur Verarbeitung an die Ereignisschleife übergeben.
# 测试协程
import asyncio
import time, datetime
# 异步函数不同于普通函数,调用普通函数会得到返回值
# 而调用异步函数会得到一个协程对象。我们需要将协程对象放到一个事件循环中才能达到与其他协程对象协作的效果
# 因为事件循环会负责处理子程 序切换的操作。
async def Print():
return "hello"
loop = asyncio.get_event_loop()
loop.run_until_complete(Print)Warten:
Verwendung: Antwort = Warten + Erwartbares ObjektErwartete Objekte: Coroutine-Objekte, Zukunft, Aufgabenobjekte können als IO-Warten verstanden werdenAntwort: Das Ergebnis des Wartens wird auf IO-Operationen stoßen Wenn die aktuelle Coroutine (Aufgabe) angehalten wird, kann die Ereignisschleife andere Coroutinen (Aufgaben) ausführen. Hinweis: Wenn es sich bei dem wartebaren Objekt um ein Task-Objekt handelt, wird es zum Task-Objekt gleichzeitig ausgeführt werden, können mehrere Aufgaben zur Ereignisschleifenliste hinzugefügt werden. Sie können „asyncio.create_task()“ verwenden, um ein „Task“-Objekt zu erstellen, und der übergebene Parameter ist das Coroutine-Objekt 3. aiohttp
asyncio kann gleichzeitige E/A-Vorgänge mit einem Thread implementieren. Wenn es nur auf der Clientseite verwendet wird, ist es nicht sehr leistungsfähig. Wenn Asyncio auf der Serverseite verwendet wird, z. B. auf einem Webserver, kann ein einzelner Thread + Coroutine verwendet werden, um eine hohe Parallelitätsunterstützung für mehrere Benutzer zu erreichen, da es sich bei HTTP-Verbindungen um E / A-Vorgänge handelt.
aiohttp ist ein HTTP-Framework, das auf Asyncio basiert.
Sie können eine Anfrage wie eine Get-Anfrage wie Anfragen senden.
Sie können die Parameter angeben, die über den Parameter params übergeben werden sollen.
import asyncio
import time, datetime
async def display(num):
pass
tasks = []
for num in range(10):
tasks.append(display(num)) # 生成任务列表
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(tasks))Anfrage posten Eine Sitzung, und dann verwendet aiohttp ClientSession, um die Sitzung zu verwalten.
Verwenden Sie session.method, um Anfragen zu senden ; Sie können text( ) verwenden, um das Kodierungsformat anzugeben. Bevor Sie auf das Antwortergebnis warten, müssen Sie vor „response.text()“ das Schlüsselwort „await“
async def fetch(session):
async with session.get("http://localhost:10056/test/") as response:
data = json.loads(await response.text())
print(data["data"])- hinzufügen.
Das obige ist der detaillierte Inhalt vonSo verwenden Sie das Python-Async-Modul. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 Der 2-stündige Python-Plan: ein realistischer Ansatz
Apr 11, 2025 am 12:04 AM
Der 2-stündige Python-Plan: ein realistischer Ansatz
Apr 11, 2025 am 12:04 AM
Sie können grundlegende Programmierkonzepte und Fähigkeiten von Python innerhalb von 2 Stunden lernen. 1. Lernen Sie Variablen und Datentypen, 2. Master Control Flow (bedingte Anweisungen und Schleifen), 3.. Verstehen Sie die Definition und Verwendung von Funktionen, 4. Beginnen Sie schnell mit der Python -Programmierung durch einfache Beispiele und Code -Snippets.
 So lesen Sie Redis -Warteschlange
Apr 10, 2025 pm 10:12 PM
So lesen Sie Redis -Warteschlange
Apr 10, 2025 pm 10:12 PM
Um eine Warteschlange aus Redis zu lesen, müssen Sie den Warteschlangenname erhalten, die Elemente mit dem Befehl LPOP lesen und die leere Warteschlange verarbeiten. Die spezifischen Schritte sind wie folgt: Holen Sie sich den Warteschlangenname: Nennen Sie ihn mit dem Präfix von "Warteschlange:" wie "Warteschlangen: My-Queue". Verwenden Sie den Befehl LPOP: Wischen Sie das Element aus dem Kopf der Warteschlange aus und geben Sie seinen Wert zurück, z. B. die LPOP-Warteschlange: my-queue. Verarbeitung leerer Warteschlangen: Wenn die Warteschlange leer ist, gibt LPOP NIL zurück, und Sie können überprüfen, ob die Warteschlange existiert, bevor Sie das Element lesen.
 So sehen Sie die Serverversion von Redis
Apr 10, 2025 pm 01:27 PM
So sehen Sie die Serverversion von Redis
Apr 10, 2025 pm 01:27 PM
FRAGE: Wie kann man die Redis -Server -Version anzeigen? Verwenden Sie das Befehlszeilen-Tool-REDIS-CLI-Verssion, um die Version des angeschlossenen Servers anzuzeigen. Verwenden Sie den Befehl "Info Server", um die interne Version des Servers anzuzeigen, und muss Informationen analysieren und zurückgeben. Überprüfen Sie in einer Cluster -Umgebung die Versionskonsistenz jedes Knotens und können automatisch mit Skripten überprüft werden. Verwenden Sie Skripte, um die Anzeigeversionen zu automatisieren, z. B. eine Verbindung mit Python -Skripten und Druckversionsinformationen.
 So starten Sie den Server mit Redis
Apr 10, 2025 pm 08:12 PM
So starten Sie den Server mit Redis
Apr 10, 2025 pm 08:12 PM
Zu den Schritten zum Starten eines Redis -Servers gehören: Installieren von Redis gemäß dem Betriebssystem. Starten Sie den Redis-Dienst über Redis-Server (Linux/macOS) oder redis-server.exe (Windows). Verwenden Sie den Befehl redis-cli ping (linux/macOS) oder redis-cli.exe ping (Windows), um den Dienststatus zu überprüfen. Verwenden Sie einen Redis-Client wie Redis-Cli, Python oder Node.js, um auf den Server zuzugreifen.
 Wie setzen Sie die Redis -Speichergröße nach geschäftlichen Anforderungen fest?
Apr 10, 2025 pm 02:18 PM
Wie setzen Sie die Redis -Speichergröße nach geschäftlichen Anforderungen fest?
Apr 10, 2025 pm 02:18 PM
Die Einstellung der Redis -Speichergröße muss die folgenden Faktoren berücksichtigen: Datenvolumen und Wachstumstrend: Schätzen Sie die Größe und Wachstumsrate gespeicherter Daten. Datentyp: Verschiedene Typen (z. B. Listen, Hashes) belegen einen anderen Speicher. Caching -Richtlinie: Vollständige Cache, teilweise Cache und Phasen -Richtlinien beeinflussen die Speicherverwendung. Business Peak: Verlassen Sie genug Speicher, um mit Verkehrsspitzen umzugehen.
 Welche Auswirkungen haben die Wiederherstellung des Gedächtnisses?
Apr 10, 2025 pm 02:15 PM
Welche Auswirkungen haben die Wiederherstellung des Gedächtnisses?
Apr 10, 2025 pm 02:15 PM
Die Wiederherstellung der Wiederherstellung nimmt zusätzlichen Speicher an, RDB erhöht vorübergehend die Speicherverwendung beim Generieren von Snapshots, und AOF nimmt beim Anhängen von Protokollen weiterhin Speicher auf. Einflussfaktoren umfassen Datenvolumen, Persistenzrichtlinien und Redis -Konfiguration. Um die Auswirkungen zu mildern, können Sie RDB -Snapshot -Richtlinien vernünftigerweise konfigurieren, die AOF -Konfiguration optimieren, die Hardware verbessern und Speicherverbrauch überwachen. Darüber hinaus ist es wichtig, ein Gleichgewicht zwischen Leistung und Datensicherheit zu finden.
 Python vs. C: Anwendungen und Anwendungsfälle verglichen
Apr 12, 2025 am 12:01 AM
Python vs. C: Anwendungen und Anwendungsfälle verglichen
Apr 12, 2025 am 12:01 AM
Python eignet sich für Datenwissenschafts-, Webentwicklungs- und Automatisierungsaufgaben, während C für Systemprogrammierung, Spieleentwicklung und eingebettete Systeme geeignet ist. Python ist bekannt für seine Einfachheit und sein starkes Ökosystem, während C für seine hohen Leistung und die zugrunde liegenden Kontrollfunktionen bekannt ist.
 Was sind die Redis -Speicherkonfigurationsparameter?
Apr 10, 2025 pm 02:03 PM
Was sind die Redis -Speicherkonfigurationsparameter?
Apr 10, 2025 pm 02:03 PM
** Der Kernparameter der Redis -Speicherkonfiguration ist MaxMemory, der die Menge an Speicher einschränkt, die Redis verwenden kann. Wenn diese Grenze überschritten wird, führt Redis eine Eliminierungsstrategie gemäß MaxMemory-Policy durch, einschließlich: Noeviction (direkt abgelehnt), Allkeys-LRU/Volatile-LRU (eliminiert von LRU), Allkeys-Random/Volatile-Random-Random-Random-Random-Random-Random-Random-Random-Random-Random-Random-Random-Random-Random-Random-Random (eliminiert) und volatile TTL (eliminierte Zeit). Andere verwandte Parameter umfassen MaxMemory-Samples (LRU-Probenmenge), RDB-Kompression
