

Wie lautet die Algorithmusformel für die Redis-Bloom-Filtergröße?

1. Einführung
Kunde: Existiert dieser Schlüssel?
Server: existiert nicht/weiß nicht
Der Bloom-Filter ist eine relativ clevere probabilistische Datenstruktur, und sein Wesen ist eine Datenstruktur. Es bietet effizientes Einfügen und Abfragen. Wenn wir jedoch mithilfe eines Bloom-Filters überprüfen möchten, ob ein Schlüssel in einer bestimmten Struktur vorhanden ist, können wir schnell lernen, dass „dieser Schlüssel nicht existieren darf oder existieren kann“. Im Vergleich zu herkömmlichen Datenstrukturen wie List, Set und Map ist es effizienter und nimmt weniger Platz ein, aber die zurückgegebenen Ergebnisse sind probabilistisch und ungenau.
Bloom-Filter werden nur zum Testen der Mitgliedschaft in einer Sammlung verwendet. Das klassische Beispiel eines Bloom-Filters besteht darin, die Effizienz zu verbessern, indem teure Suchvorgänge auf der Festplatte (oder im Netzwerk) nach nicht vorhandenen Schlüsseln reduziert werden. Wie wir sehen können, kann ein Bloom-Filter in der konstanten Zeit von O(k) nach einem Schlüssel suchen, wobei k die Anzahl der Hash-Funktionen ist, und die Prüfung auf das Nichtvorhandensein eines Schlüssels erfolgt sehr schnell.
2. Anwendungsszenario
2.1 Cache-Penetration
Um die Zugriffseffizienz zu verbessern, werden wir einige Daten in den Redis-Cache legen. Bei der Datenabfrage können Sie zunächst die Daten aus dem Cache abrufen, ohne die Datenbank zu lesen. Dadurch kann die Leistung effektiv verbessert werden.
Beim Abfragen von Daten müssen Sie zunächst feststellen, ob sich Daten im Cache befinden. Wenn Daten vorhanden sind, rufen Sie die Daten direkt aus dem Cache ab.
Aber wenn keine Daten vorhanden sind, müssen Sie die Daten aus der Datenbank abrufen und sie dann in den Cache legen. Wenn eine große Anzahl von Zugriffen nicht auf den Cache zugreifen kann, wird die Datenbank einem größeren Druck ausgesetzt, was zum Absturz der Datenbank führt. Mithilfe von Bloom-Filtern können Sie beim Zugriff auf einen nicht vorhandenen Cache schnell zurückkehren, um einen Cache- oder DB-Absturz zu vermeiden.
2.2 Bestimmen Sie, ob bestimmte Daten in massiven Daten vorhanden sind.
HBase speichert eine sehr große Datenmenge, um festzustellen, ob bestimmte ROWKEYS oder eine bestimmte Spalte vorhanden sind Der Filter kann schnell ermitteln, ob bestimmte Daten vorhanden sind. Aber es gibt eine gewisse Fehleinschätzungsquote. Wenn ein Schlüssel jedoch nicht existiert, muss er korrekt sein.
3. Probleme mit HashMap
Um festzustellen, ob ein Element vorhanden ist, ist die Effizienz der Verwendung von HashMap sehr hoch. HashMap kann eine konstante Zeitkomplexität von O(1) erreichen, indem Werte HashMap-Schlüsseln zugeordnet werden.
Wenn jedoch die gespeicherte Datenmenge sehr groß ist (z. B. Hunderte Millionen Daten), verbraucht HashMap sehr viel Speicher. Und es ist einfach unmöglich, riesige Datenmengen auf einmal in den Speicher einzulesen.
4. Verstehen Sie das Funktionsprinzip des Bloom-Filters
:
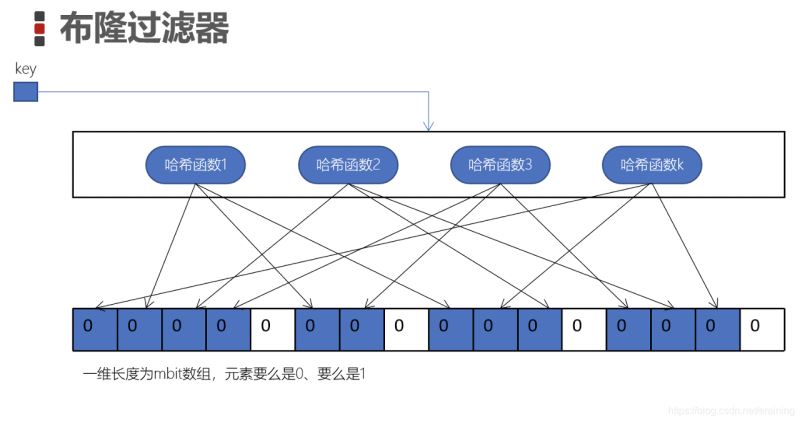
Bloom-Filter Gerät ist ein Bit-Array oder ein Bit-Binärvektor
Die Elemente in diesem Array sind entweder 0 oder 1
k Hash-Funktionen sind unabhängig voneinander und jede Hash-Funktion Das berechnete Ergebnis modulo der Länge m der Array und setzt ein Bit auf 1 (blaue Zelle)
Wir setzen die Zellen für jeden Schlüssel auf diese Weise, nämlich „Bloom-Filtergerät“
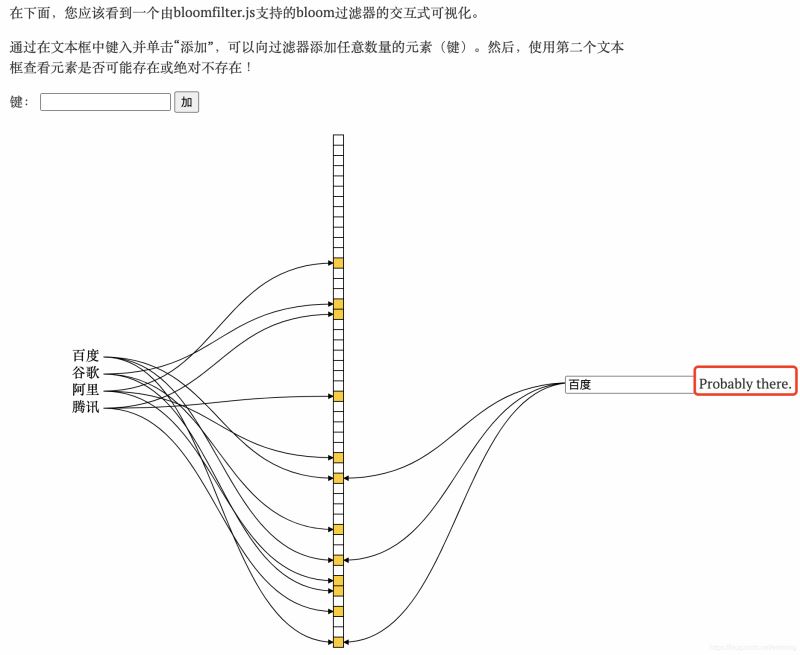
5. Elemente basierend auf Bloom abfragen Filter
Angenommen, ein Schlüssel ist eingegeben, verwenden wir die vorherigen k-Hash-Funktionen, um den Hash zu finden und k-Werte zu erhalten#🎜 🎜# Bestimmen Sie, ob die k-Werte alle blau sind. Wenn einer nicht vorhanden ist blau, dann darf der Schlüssel nicht existieren
Wenn alle blau sind, dann kann der Schlüssel existieren (Bloom-Filter führt zu Fehleinschätzungen)
Denn wenn es viele Eingabeobjekte gibt und die Sammlung relativ klein ist, sind die meisten Positionen in Wenn ein bestimmter Schlüssel blau markiert wird, wird zu diesem Zeitpunkt fälschlicherweise angenommen, dass sich der Schlüssel in der Sammlung befindet gelöscht werden?
Herkömmliche Bloom-Filter unterstützen keine Löschvorgänge. Allerdings kann eine Variante namens Counting Bloom-Filter verwendet werden, um zu testen, ob die Anzahl der Elementzählungen absolut unter einem bestimmten Schwellenwert liegt, und sie unterstützt das Löschen von Elementen. Das Prinzip und die Umsetzung des Artikels Counting Bloom Filter sind ausführlich beschrieben und können ausführlich gelesen werden.
7. So wählen Sie die Anzahl der Hash-Funktionen und die Länge des Bloom-Filters aus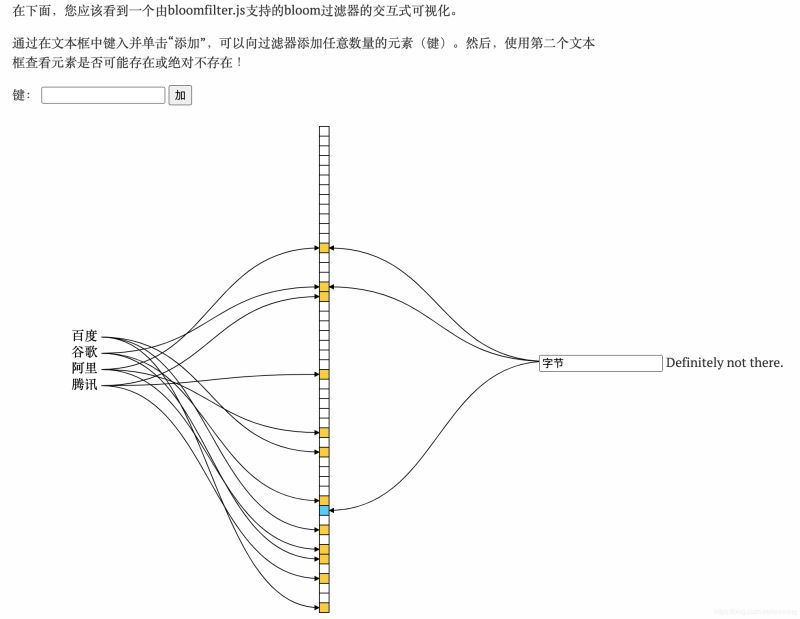
 Darüber hinaus muss auch die Anzahl der Hash-Funktionen gewichtet werden. Je größer die Anzahl, desto schneller wird die Bloom-Filter-Bitposition auf 1 gesetzt und desto geringer ist die Effizienz des Bloom-Filters Wenn es zu wenig ist, ist unsere Fehlalarmrate hoch.
Darüber hinaus muss auch die Anzahl der Hash-Funktionen gewichtet werden. Je größer die Anzahl, desto schneller wird die Bloom-Filter-Bitposition auf 1 gesetzt und desto geringer ist die Effizienz des Bloom-Filters Wenn es zu wenig ist, ist unsere Fehlalarmrate hoch.
Keine Sorge, wir müssen tatsächlich die Werte von m und k bestätigen. Nun, wenn wir die Fehlertoleranz p und die Anzahl der Elemente n angeben, können diese Parameter mit der folgenden Formel berechnet werden:
Wir können Fehlalarme basierend auf der Größe des Filters m, der Anzahl der Hash-Funktionen k und dem berechnen Anzahl der eingefügten Elemente n Die Rate p, die Formel lautet wie folgt: Wie wählt man auf der Grundlage des oben Gesagten die für das Unternehmen geeigneten k- und m-Werte aus?
Formel:
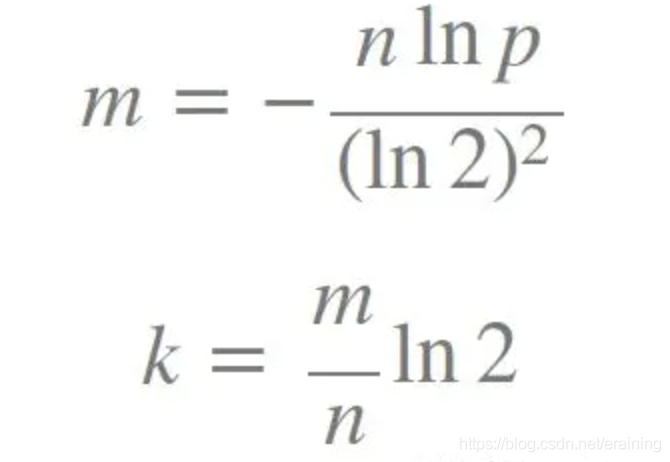
k ist die Anzahl der Hash-Funktionen, m ist die Bloom-Filterlänge, n ist die Anzahl der eingefügten Elemente und p ist die Falsch-Positiv-Rate.
Wie man diese Formel herleitet, wird in dem Artikel behandelt, den ich auf Zhihu veröffentlicht habe. Wenn Sie interessiert sind, können Sie ihn einfach lesen.
Außerdem möchte ich hier noch einen weiteren wichtigen Punkt erwähnen. Da der einzige Zweck der Verwendung eines Bloom-Filters darin besteht, schneller zu suchen, können wir keine langsame Hash-Funktion verwenden, oder? Kryptografische Hash-Funktionen (z. B. Sha-1, MD5) sind für Bloom-Filter keine gute Wahl, da sie etwas langsam sind. Bessere Optionen für schnellere Hash-Funktionsimplementierungen sind Murmur, Fnv-Familien-Hashing, Jenkins-Hashing und HashMix.
Weitere Anwendungsszenarien
Im gegebenen Beispiel haben Sie gesehen, dass wir damit den Benutzer warnen können, wenn er ein schwaches Passwort eingibt.
Sie können den Bloom-Filter verwenden, um zu verhindern, dass Benutzer schädliche Websites besuchen.
Anstatt eine SQL-Datenbank abzufragen, um zu prüfen, ob ein Benutzer mit einer bestimmten E-Mail-Adresse existiert, können Sie zunächst den Bloom Bloom-Filter verwenden, um eine kostengünstige Suchprüfung durchzuführen. Wenn die E-Mail nicht existiert, großartig! Wenn es vorhanden ist, müssen Sie möglicherweise zusätzliche Abfragen an die Datenbank durchführen. Auf die gleiche Weise können Sie auch nach „Benutzername bereits vergeben“ suchen.
Sie können einen Bloom-Filter basierend auf der IP-Adresse Ihrer Website-Besucher verwenden, um zu überprüfen, ob die Benutzer Ihrer Website „wiederkehrende Benutzer“ oder „neue Benutzer“ sind. Ein paar Fehlalarme von „wiederkehrenden Benutzern“ können Ihnen nicht schaden, oder?
Sie können auch eine Rechtschreibprüfung durchführen, indem Sie Wörterbuchwörter mithilfe von Bloom-Filtern verfolgen.
Das obige ist der detaillierte Inhalt vonWie lautet die Algorithmusformel für die Redis-Bloom-Filtergröße?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1393
1393
 52
1207
24
52
1207
24

 So erstellen Sie den Redis -Clustermodus
Apr 10, 2025 pm 10:15 PM
So erstellen Sie den Redis -Clustermodus
Apr 10, 2025 pm 10:15 PM
Der Redis -Cluster -Modus bietet Redis -Instanzen durch Sharding, die Skalierbarkeit und Verfügbarkeit verbessert. Die Bauschritte sind wie folgt: Erstellen Sie ungerade Redis -Instanzen mit verschiedenen Ports; Erstellen Sie 3 Sentinel -Instanzen, Monitor -Redis -Instanzen und Failover; Konfigurieren von Sentinel -Konfigurationsdateien, Informationen zur Überwachung von Redis -Instanzinformationen und Failover -Einstellungen hinzufügen. Konfigurieren von Redis -Instanzkonfigurationsdateien, aktivieren Sie den Cluster -Modus und geben Sie den Cluster -Informationsdateipfad an. Erstellen Sie die Datei nodes.conf, die Informationen zu jeder Redis -Instanz enthält. Starten Sie den Cluster, führen Sie den Befehl erstellen aus, um einen Cluster zu erstellen und die Anzahl der Replikate anzugeben. Melden Sie sich im Cluster an, um den Befehl cluster info auszuführen, um den Clusterstatus zu überprüfen. machen
 So löschen Sie Redis -Daten
Apr 10, 2025 pm 10:06 PM
So löschen Sie Redis -Daten
Apr 10, 2025 pm 10:06 PM
So löschen Sie Redis -Daten: Verwenden Sie den Befehl Flushall, um alle Schlüsselwerte zu löschen. Verwenden Sie den Befehl flushdb, um den Schlüsselwert der aktuell ausgewählten Datenbank zu löschen. Verwenden Sie SELECT, um Datenbanken zu wechseln, und löschen Sie dann FlushDB, um mehrere Datenbanken zu löschen. Verwenden Sie den Befehl del, um einen bestimmten Schlüssel zu löschen. Verwenden Sie das Redis-Cli-Tool, um die Daten zu löschen.
 So lesen Sie Redis -Warteschlange
Apr 10, 2025 pm 10:12 PM
So lesen Sie Redis -Warteschlange
Apr 10, 2025 pm 10:12 PM
Um eine Warteschlange aus Redis zu lesen, müssen Sie den Warteschlangenname erhalten, die Elemente mit dem Befehl LPOP lesen und die leere Warteschlange verarbeiten. Die spezifischen Schritte sind wie folgt: Holen Sie sich den Warteschlangenname: Nennen Sie ihn mit dem Präfix von "Warteschlange:" wie "Warteschlangen: My-Queue". Verwenden Sie den Befehl LPOP: Wischen Sie das Element aus dem Kopf der Warteschlange aus und geben Sie seinen Wert zurück, z. B. die LPOP-Warteschlange: my-queue. Verarbeitung leerer Warteschlangen: Wenn die Warteschlange leer ist, gibt LPOP NIL zurück, und Sie können überprüfen, ob die Warteschlange existiert, bevor Sie das Element lesen.
 So verwenden Sie den Befehl Redis
Apr 10, 2025 pm 08:45 PM
So verwenden Sie den Befehl Redis
Apr 10, 2025 pm 08:45 PM
Die Verwendung der REDIS -Anweisung erfordert die folgenden Schritte: Öffnen Sie den Redis -Client. Geben Sie den Befehl ein (Verbschlüsselwert). Bietet die erforderlichen Parameter (variiert von der Anweisung bis zur Anweisung). Drücken Sie die Eingabetaste, um den Befehl auszuführen. Redis gibt eine Antwort zurück, die das Ergebnis der Operation anzeigt (normalerweise in Ordnung oder -err).
 So verwenden Sie Redis Lock
Apr 10, 2025 pm 08:39 PM
So verwenden Sie Redis Lock
Apr 10, 2025 pm 08:39 PM
Um die Operationen zu sperren, muss die Sperre durch den Befehl setNX erfasst werden und dann den Befehl Ablauf verwenden, um die Ablaufzeit festzulegen. Die spezifischen Schritte sind: (1) Verwenden Sie den Befehl setNX, um zu versuchen, ein Schlüsselwertpaar festzulegen; (2) Verwenden Sie den Befehl Ablauf, um die Ablaufzeit für die Sperre festzulegen. (3) Verwenden Sie den Befehl Del, um die Sperre zu löschen, wenn die Sperre nicht mehr benötigt wird.
 So lesen Sie den Quellcode von Redis
Apr 10, 2025 pm 08:27 PM
So lesen Sie den Quellcode von Redis
Apr 10, 2025 pm 08:27 PM
Der beste Weg, um Redis -Quellcode zu verstehen, besteht darin, Schritt für Schritt zu gehen: Machen Sie sich mit den Grundlagen von Redis vertraut. Wählen Sie ein bestimmtes Modul oder eine bestimmte Funktion als Ausgangspunkt. Beginnen Sie mit dem Einstiegspunkt des Moduls oder der Funktion und sehen Sie sich die Codezeile nach Zeile an. Zeigen Sie den Code über die Funktionsaufrufkette an. Kennen Sie die von Redis verwendeten Datenstrukturen. Identifizieren Sie den von Redis verwendeten Algorithmus.
 So verwenden Sie die Befehlszeile der Redis
Apr 10, 2025 pm 10:18 PM
So verwenden Sie die Befehlszeile der Redis
Apr 10, 2025 pm 10:18 PM
Verwenden Sie das Redis-Befehlszeilen-Tool (REDIS-CLI), um Redis in folgenden Schritten zu verwalten und zu betreiben: Stellen Sie die Adresse und den Port an, um die Adresse und den Port zu stellen. Senden Sie Befehle mit dem Befehlsnamen und den Parametern an den Server. Verwenden Sie den Befehl Hilfe, um Hilfeinformationen für einen bestimmten Befehl anzuzeigen. Verwenden Sie den Befehl zum Beenden, um das Befehlszeilenwerkzeug zu beenden.
 So konfigurieren Sie die Ausführungszeit der Lua -Skript in CentOS Redis
Apr 14, 2025 pm 02:12 PM
So konfigurieren Sie die Ausführungszeit der Lua -Skript in CentOS Redis
Apr 14, 2025 pm 02:12 PM
Auf CentOS -Systemen können Sie die Ausführungszeit von LuA -Skripten einschränken, indem Sie Redis -Konfigurationsdateien ändern oder Befehle mit Redis verwenden, um zu verhindern, dass bösartige Skripte zu viele Ressourcen konsumieren. Methode 1: Ändern Sie die Redis -Konfigurationsdatei und suchen Sie die Redis -Konfigurationsdatei: Die Redis -Konfigurationsdatei befindet sich normalerweise in /etc/redis/redis.conf. Konfigurationsdatei bearbeiten: Öffnen Sie die Konfigurationsdatei mit einem Texteditor (z. B. VI oder Nano): Sudovi/etc/redis/redis.conf Setzen Sie die LUA -Skriptausführungszeit.
