

So konfigurieren Sie mehrere MySQL-Master und einen Slave in Centos7

Geschäftsszenario:
Mehrere Hauptgeschäfte des Unternehmens wurden unabhängig und auf verschiedenen Datenbankservern platziert, aber ein Unternehmen muss für gemeinsame Abfragestatistiken mit mehreren Geschäftsbibliotheken verknüpft werden. Zu diesem Zeitpunkt ist es für Statistikzwecke erforderlich, verschiedene Geschäftsdatenbankdaten mit einer Slave-Datenbank zu synchronisieren. Gemäß dem MySQL-Master-Slave-Synchronisationsprinzip wird die Lösung mehrerer Slaves und eines Masters verwendet. Die Hauptbibliothek verwendet die Innodb-Engine, und die Slave-Bibliothek verwendet die Myisam-Engine, um mehrere Instanzen zu öffnen, die Daten mehrerer Instanzen im selben Verzeichnis zu synchronisieren und über Flush-Tabellen auf die Daten anderer Instanzen in einer Instanz zuzugreifen.
Lösungsideen:
1. Verwenden Sie die innodb-Engine für die Hauptdatenbank und setzen Sie sql_mode auf no_auto_create_user
2. Aktivieren Sie mehrere Instanzen aus der Slave-Bibliothek und synchronisieren Sie die Daten in mehreren Master-Bibliotheken über dasselbe Datenverzeichnis Master-Slave-Replikation. Jede Instanz der Slave-Bibliothek entspricht einer Master-Bibliothek. Mehrere Instanzen verwenden dasselbe Datenverzeichnis.
3. Verwenden Sie die Myisam-Engine aus der Datenbank und schließen Sie die Standard-Innodb-Engine aus der Datenbank. Die Myisam-Engine kann auf Tabellen anderer Instanzen im selben Datenverzeichnis zugreifen.
4. Jede Instanz der Slave-Bibliothek muss Flush-Tabellen ausführen, um die Datenänderungen anderer Instanztabellen zu sehen. Sie können den Crontab-Task-Zeitplan so einstellen, dass die Tabelle jede Minute bei der ersten Instanz aktualisiert wird, sodass die Standardinstanz mit dem Programm verbunden ist können die Echtzeitdaten der Tabelle sehen.
5. Setzen Sie den sql_mode sowohl der Hauptbibliothek als auch der Slave-Bibliothek auf no_auto_create_user. Nur so kann die SQL der Innodb-Engine der Hauptbibliothek zur erfolgreichen Ausführung synchronisiert werden.
Projektarchitekturdiagramm:
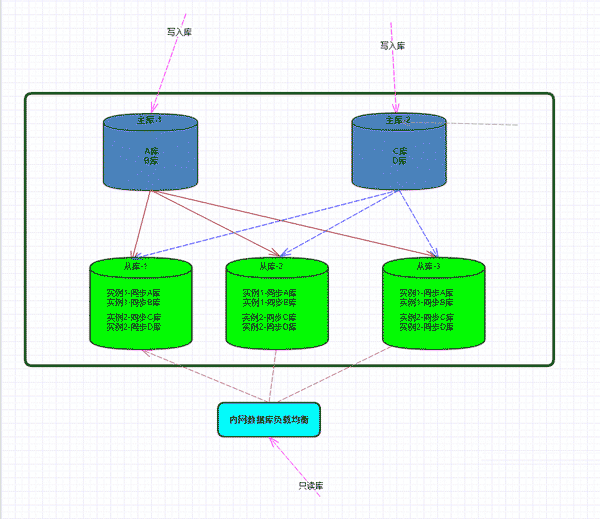
Umgebungsbeschreibung:
Hauptbibliothek-1: 192.168.1.1
Hauptbibliothek-2: 192.168.1.2
Slave-Bibliothek-3: 192 .168.1.3
Von der Bibliothek -3: 192.168.1.4
Slave-Bibliothek -3: 192.168.1.5
Implementierungsschritte: (MySQL-Installationsschritte werden hier nicht beschrieben)
1. Hauptdatenbankkonfigurationsdatei, mehrere Hauptdatenbankkonfigurationsdateien können nicht außer Server sein -id Alles andere ist gleich.
[root@masterdb01 ~]#cat /etc/my.cnf [client] port= 3306 socket= /tmp/mysql.sock [mysqld] port = 3306 basedir = /usr/local/mysql datadir = /data/mysql character-set-server = utf8mb4 default-storage-engine = innodb socket = /tmp/mysql.sock skip-name-resolv = 1 open_files_limit = 65535 back_log = 103 max_connections = 512 max_connect_errors = 100000 table_open_cache = 2048 tmp-table-size = 32m max-heap-table-size = 32m #query-cache-type = 0 query-cache-size = 0 external-locking = false max_allowed_packet = 32m sort_buffer_size = 2m join_buffer_size = 2m thread_cache_size = 51 query_cache_size = 32m tmp_table_size = 96m max_heap_table_size = 96m query_cache_type=1 log-error=/data/logs/mysqld.log slow_query_log = 1 slow_query_log_file = /data/logs/slow.log long_query_time = 0.1 # binary logging # server-id = 1 log-bin = /data/binlog/mysql-bin log-bin-index =/data/binlog/mysql-bin.index expire-logs-days = 14 sync_binlog = 1 binlog_cache_size = 4m max_binlog_cache_size = 8m max_binlog_size = 1024m log_slave_updates #binlog_format = row binlog_format = mixed //这里使用的混合模式复制 relay_log_recovery = 1 #不需要同步的表 replicate-wild-ignore-table=mydb.sp_counter #不需要同步的库 replicate-ignore-db = mysql,information_schema,performance_schema key_buffer_size = 32m read_buffer_size = 1m read_rnd_buffer_size = 16m bulk_insert_buffer_size = 64m myisam_sort_buffer_size = 128m myisam_max_sort_file_size = 10g myisam_repair_threads = 1 myisam_recover transaction_isolation = repeatable-read innodb_additional_mem_pool_size = 16m innodb_buffer_pool_size = 5734m innodb_buffer_pool_load_at_startup = 1 innodb_buffer_pool_dump_at_shutdown = 1 innodb_data_file_path = ibdata1:1024m:autoextend innodb_flush_log_at_trx_commit = 2 innodb_log_buffer_size = 32m innodb_log_file_size = 2g innodb_log_files_in_group = 2 innodb_io_capacity = 4000 innodb_io_capacity_max = 8000 innodb_max_dirty_pages_pct = 50 innodb_flush_method = o_direct innodb_file_format = barracuda innodb_file_format_max = barracuda innodb_lock_wait_timeout = 10 innodb_rollback_on_timeout = 1 innodb_print_all_deadlocks = 1 innodb_file_per_table = 1 innodb_locks_unsafe_for_binlog = 0 [mysqldump] quick max_allowed_packet = 32m
2. Konfigurationsdatei der Slave-Bibliothek. Mehrere Slave-Konfigurationsdateien müssen bis auf die Server-ID gleich sein.
[root@slavedb01 ~]# cat /etc/my.cnf [client] port= 3306 socket= /tmp/mysql.sock [mysqld_multi] # 指定相关命令的路径 mysqld = /usr/local/mysql/bin/mysqld_safe mysqladmin = /usr/local/mysql/bin/mysqladmin ##复制主库1的数据## [mysqld2] port = 3306 basedir = /usr/local/mysql datadir = /data/mysql character-set-server = utf8mb4 #指定实例1的sock文件和pid文件 socket = /tmp/mysql.sock pid-file=/data/mysql/mysql.pid skip-name-resolv = 1 open_files_limit = 65535 back_log = 103 max_connections = 512 max_connect_errors = 100000 table_open_cache = 2048 tmp-table-size = 32m max-heap-table-size = 32m query-cache-size = 0 external-locking = false max_allowed_packet = 32m sort_buffer_size = 2m join_buffer_size = 2m thread_cache_size = 51 query_cache_size = 32m tmp_table_size = 96m max_heap_table_size = 96m query_cache_type=1 #指定第一个实例的错误日志和慢查询日志路径 log-error=/data/logs/mysqld.log slow_query_log = 1 slow_query_log_file = /data/logs/slow.log long_query_time = 0.1 # binary logging# # 指定实例1的binlog和relaylog路径为/data/binlog目录 # 每个从库和每个实例的server_id不能一样。 server-id = 2 log-bin = /data/binlog/mysql-bin log-bin-index =/data/binlog/mysql-bin.index relay_log = /data/binlog/mysql-relay-bin relay_log_index = /data/binlog/mysql-relay.index master-info-file = /data/mysql/master.info relay_log_info_file = /data/mysql/relay-log.info read_only = 1 expire-logs-days = 14 sync_binlog = 1 #需要同步的库,如果不设置,默认同步所有库。 #replicate-do-db = xxx #不需要同步的表 replicate-wild-ignore-table=mydb.sp_counter #不需要同步的库 replicate-ignore-db = mysql,information_schema,performance_schema binlog_cache_size = 4m max_binlog_cache_size = 8m max_binlog_size = 1024m log_slave_updates =1 #binlog_format = row binlog_format = mixed relay_log_recovery = 1 key_buffer_size = 32m read_buffer_size = 1m read_rnd_buffer_size = 16m bulk_insert_buffer_size = 64m myisam_sort_buffer_size = 128m myisam_max_sort_file_size = 10g myisam_repair_threads = 1 myisam_recover #设置默认引擎为myisam,下面这些参数一定要加上。 default-storage-engine=myisam default-tmp-storage-engine=myisam #关闭innodb引擎 skip-innodb innodb = off disable-innodb #设置sql_mode模式为no_auto_create_user sql_mode = no_auto_create_user #关闭innodb引擎 loose-skip-innodb loose-innodb-trx=0 loose-innodb-locks=0 loose-innodb-lock-waits=0 loose-innodb-cmp=0 loose-innodb-cmp-per-index=0 loose-innodb-cmp-per-index-reset=0 loose-innodb-cmp-reset=0 loose-innodb-cmpmem=0 loose-innodb-cmpmem-reset=0 loose-innodb-buffer-page=0 loose-innodb-buffer-page-lru=0 loose-innodb-buffer-pool-stats=0 loose-innodb-metrics=0 loose-innodb-ft-default-stopword=0 loose-innodb-ft-inserted=0 loose-innodb-ft-deleted=0 loose-innodb-ft-being-deleted=0 loose-innodb-ft-config=0 loose-innodb-ft-index-cache=0 loose-innodb-ft-index-table=0 loose-innodb-sys-tables=0 loose-innodb-sys-tablestats=0 loose-innodb-sys-indexes=0 loose-innodb-sys-columns=0 loose-innodb-sys-fields=0 loose-innodb-sys-foreign=0 loose-innodb-sys-foreign-cols=0 ##复制主库2的数据## [mysqld3] port = 3307 basedir = /usr/local/mysql datadir = /data/mysql character-set-server = utf8mb4 #指定实例2的sock文件和pid文件 socket = /tmp/mysql3.sock pid-file=/data/mysql/mysql3.pid skip-name-resolv = 1 open_files_limit = 65535 back_log = 103 max_connections = 512 max_connect_errors = 100000 table_open_cache = 2048 tmp-table-size = 32m max-heap-table-size = 32m query-cache-size = 0 external-locking = false max_allowed_packet = 32m sort_buffer_size = 2m join_buffer_size = 2m thread_cache_size = 51 query_cache_size = 32m tmp_table_size = 96m max_heap_table_size = 96m query_cache_type=1 log-error=/data/logs/mysqld3.log slow_query_log = 1 slow_query_log_file = /data/logs/slow3.log long_query_time = 0.1 # binary logging # # 这里一定要注意,不能把两个实例的binlog和relaylog放到同一个目录, # 这里指定实例2的binlog日志为/data/binlog2目录 # 每个从库和每个实例的server_id不能一样。 server-id = 22 log-bin = /data/binlog2/mysql-bin log-bin-index =/data/binlog2/mysql-bin.index relay_log = /data/binlog2/mysql-relay-bin relay_log_index = /data/binlog2/mysql-relay.index master-info-file = /data/mysql/master3.info relay_log_info_file = /data/mysql/relay-log3.info read_only = 1 expire-logs-days = 14 sync_binlog = 1 #不需要复制的库 replicate-ignore-db = mysql,information_schema,performance_schema binlog_cache_size = 4m max_binlog_cache_size = 8m max_binlog_size = 1024m log_slave_updates =1 #binlog_format = row binlog_format = mixed relay_log_recovery = 1 key_buffer_size = 32m read_buffer_size = 1m read_rnd_buffer_size = 16m bulk_insert_buffer_size = 64m myisam_sort_buffer_size = 128m myisam_max_sort_file_size = 10g myisam_repair_threads = 1 myisam_recover #设置默认引擎为myisam default-storage-engine=myisam default-tmp-storage-engine=myisam #关闭innodb引擎 skip-innodb innodb = off disable-innodb #设置sql_mode模式为no_auto_create_user sql_mode = no_auto_create_user #关闭innodb引擎,下面这些参数一定要加上。 loose-skip-innodb loose-innodb-trx=0 loose-innodb-locks=0 loose-innodb-lock-waits=0 loose-innodb-cmp=0 loose-innodb-cmp-per-index=0 loose-innodb-cmp-per-index-reset=0 loose-innodb-cmp-reset=0 loose-innodb-cmpmem=0 loose-innodb-cmpmem-reset=0 loose-innodb-buffer-page=0 loose-innodb-buffer-page-lru=0 loose-innodb-buffer-pool-stats=0 loose-innodb-metrics=0 loose-innodb-ft-default-stopword=0 loose-innodb-ft-inserted=0 loose-innodb-ft-deleted=0 loose-innodb-ft-being-deleted=0 loose-innodb-ft-config=0 loose-innodb-ft-index-cache=0 loose-innodb-ft-index-table=0 loose-innodb-sys-tables=0 loose-innodb-sys-tablestats=0 loose-innodb-sys-indexes=0 loose-innodb-sys-columns=0 loose-innodb-sys-fields=0 loose-innodb-sys-foreign=0 loose-innodb-sys-foreign-cols=0 [mysqldump] quick max_allowed_packet = 32m ```
3. Legen Sie den sql_mode der Hauptbibliothek fest. Standardmäßig muss mysql5.6 sql_mode in der Startdatei festlegen, damit er wirksam wird.
# cat /etc/init.d/mysqld
#other_args="$*" # uncommon, but needed when called from an rpm upgrade action
# expected: "--skip-networking --skip-grant-tables"
# they are not checked here, intentionally, as it is the resposibility
# of the "spec" file author to give correct arguments only.
#将上面默认的#other_args开启后改为
other_args="--sql-mode=no_auto_create_user"4. Aktivieren Sie die Master- und Slave-Datenbanken
#主库 service mysqld start #开启从库的二个实例 /usr/local/mysql/bin/mysqld_multi start 2 /usr/local/mysql/bin/mysqld_multi start 3
5. Autorisieren Sie die Kopierkonten auf den beiden Master-Datenbanken.
#需要授权三个从库的ip可以同步 mysql> grant replication slave on *.* to rep@'192.168.1.3' identified by 'rep123'; mysql> grant replication slave on *.* to rep@'192.168.1.4' identified by 'rep123'; mysql> grant replication slave on *.* to rep@'192.168.1.5' identified by 'rep123'; mysql> flush privileges;
6.
#进入第一个实例执行 $ mysql -s /tmp/mysql.sock mysql> change master to master_host='192.168.1.1',master_user='rep',master_password='rep123',master_log_file='mysql-bin.000001',master_log_pos=112; #进入第二个实例执行 $ mysql -s /tmp/mysql3.sock mysql> change master to master_host='192.168.1.2',master_user='rep',master_password='rep123',master_log_file='mysql-bin.000001',master_log_pos=112;
7. Testen Sie die Datensynchronisierung. Erstellen Sie Tabellen und fügen Sie Daten in die beiden Master-Datenbanken ein. Wenn Sie die Slave-Datenbank überprüfen, können Sie sehen, dass die beiden Master-Datenbanken mit allen Daten in derselben Slave-Datenbank synchronisiert sind.
8. Legen Sie auf jedem Slave-Server einen Aufgabenplan fest, um die Tabelle der ersten Instanz jede Minute zu aktualisieren. Die Fallstricke mehrerer Master und eines Slaves in MySQL5.6. Die Standard-Engine von MySQL5. 6 ist innodb Standardmäßig muss der Parameter no_engine_substitution im sql_mode-Modus des Masters und Slaves während der Synchronisierung deaktiviert sein. Wenn Sie die Innodb-Synchronisierung mit SQL in der Slave-Datenbank nicht deaktivieren, wird die Innodb-Engine nicht gefunden und die Synchronisierung schlägt fehl.
2. Wenn Sie mehrere Instanzen von mysql5.6 öffnen, wird die Konfigurationsdatei my.cnf standardmäßig im Installationsverzeichnis Ihrer Datenbank (/usr/local/mysql/) generiert , werden zuerst die Datenbankinstallationsdateien im Verzeichnis gelesen. Dies hat zur Folge, dass mehrere Instanzen nicht wirksam werden.
Das obige ist der detaillierte Inhalt vonSo konfigurieren Sie mehrere MySQL-Master und einen Slave in Centos7. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Die Beziehung zwischen MySQL -Benutzer und Datenbank
Apr 08, 2025 pm 07:15 PM
Die Beziehung zwischen MySQL -Benutzer und Datenbank
Apr 08, 2025 pm 07:15 PM
In der MySQL -Datenbank wird die Beziehung zwischen dem Benutzer und der Datenbank durch Berechtigungen und Tabellen definiert. Der Benutzer verfügt über einen Benutzernamen und ein Passwort, um auf die Datenbank zuzugreifen. Die Berechtigungen werden über den Zuschussbefehl erteilt, während die Tabelle durch den Befehl create table erstellt wird. Um eine Beziehung zwischen einem Benutzer und einer Datenbank herzustellen, müssen Sie eine Datenbank erstellen, einen Benutzer erstellen und dann Berechtigungen erfüllen.
 MySQL: Die einfache Datenverwaltung für Anfänger
Apr 09, 2025 am 12:07 AM
MySQL: Die einfache Datenverwaltung für Anfänger
Apr 09, 2025 am 12:07 AM
MySQL ist für Anfänger geeignet, da es einfach zu installieren, leistungsfähig und einfach zu verwalten ist. 1. Einfache Installation und Konfiguration, geeignet für eine Vielzahl von Betriebssystemen. 2. Unterstützung grundlegender Vorgänge wie Erstellen von Datenbanken und Tabellen, Einfügen, Abfragen, Aktualisieren und Löschen von Daten. 3. Bereitstellung fortgeschrittener Funktionen wie Join Operations und Unterabfragen. 4. Die Leistung kann durch Indexierung, Abfrageoptimierung und Tabellenpartitionierung verbessert werden. 5. Backup-, Wiederherstellungs- und Sicherheitsmaßnahmen unterstützen, um die Datensicherheit und -konsistenz zu gewährleisten.
 RDS MySQL -Integration mit RedShift Zero ETL
Apr 08, 2025 pm 07:06 PM
RDS MySQL -Integration mit RedShift Zero ETL
Apr 08, 2025 pm 07:06 PM
Vereinfachung der Datenintegration: AmazonRDSMYSQL und Redshifts Null ETL-Integration Die effiziente Datenintegration steht im Mittelpunkt einer datengesteuerten Organisation. Herkömmliche ETL-Prozesse (Extrakt, Konvertierung, Last) sind komplex und zeitaufwändig, insbesondere bei der Integration von Datenbanken (wie AmazonRDSMysQL) in Data Warehouses (wie Rotverschiebung). AWS bietet jedoch keine ETL-Integrationslösungen, die diese Situation vollständig verändert haben und eine vereinfachte Lösung für die Datenmigration von RDSMysQL zu Rotverschiebung bietet. Dieser Artikel wird in die Integration von RDSMYSQL Null ETL mit RedShift eintauchen und erklärt, wie es funktioniert und welche Vorteile es Dateningenieuren und Entwicklern bringt.
 So füllen Sie MySQL Benutzername und Passwort aus
Apr 08, 2025 pm 07:09 PM
So füllen Sie MySQL Benutzername und Passwort aus
Apr 08, 2025 pm 07:09 PM
Ausfüllen des MySQL -Benutzernamens und des Kennworts: 1. Bestimmen Sie den Benutzernamen und das Passwort; 2. Verbinden Sie eine Verbindung zur Datenbank; 3. Verwenden Sie den Benutzernamen und das Passwort, um Abfragen und Befehle auszuführen.
 Die Abfrageoptimierung in MySQL ist für die Verbesserung der Datenbankleistung von wesentlicher Bedeutung, insbesondere im Umgang mit großen Datensätzen
Apr 08, 2025 pm 07:12 PM
Die Abfrageoptimierung in MySQL ist für die Verbesserung der Datenbankleistung von wesentlicher Bedeutung, insbesondere im Umgang mit großen Datensätzen
Apr 08, 2025 pm 07:12 PM
1. Verwenden Sie den richtigen Index, um das Abrufen von Daten zu beschleunigen, indem die Menge der skanierten Datenmenge ausgewählt wird. Wenn Sie mehrmals eine Spalte einer Tabelle nachschlagen, erstellen Sie einen Index für diese Spalte. Wenn Sie oder Ihre App Daten aus mehreren Spalten gemäß den Kriterien benötigen, erstellen Sie einen zusammengesetzten Index 2. Vermeiden Sie aus. Auswählen * Nur die erforderlichen Spalten. Wenn Sie alle unerwünschten Spalten auswählen, konsumiert dies nur mehr Serverspeicher und veranlasst den Server bei hoher Last oder Frequenzzeiten, beispielsweise die Auswahl Ihrer Tabelle, wie beispielsweise die Spalten wie innovata und updated_at und Zeitsteuer und dann zu entfernen.
 Verstehen von Säureeigenschaften: Die Säulen einer zuverlässigen Datenbank
Apr 08, 2025 pm 06:33 PM
Verstehen von Säureeigenschaften: Die Säulen einer zuverlässigen Datenbank
Apr 08, 2025 pm 06:33 PM
Detaillierte Erläuterung von Datenbanksäureattributen Säureattribute sind eine Reihe von Regeln, um die Zuverlässigkeit und Konsistenz von Datenbanktransaktionen sicherzustellen. Sie definieren, wie Datenbanksysteme Transaktionen umgehen, und sorgen dafür, dass die Datenintegrität und -genauigkeit auch im Falle von Systemabstürzen, Leistungsunterbrechungen oder mehreren Benutzern gleichzeitiger Zugriff. Säureattributübersicht Atomizität: Eine Transaktion wird als unteilbare Einheit angesehen. Jeder Teil schlägt fehl, die gesamte Transaktion wird zurückgerollt und die Datenbank behält keine Änderungen bei. Wenn beispielsweise eine Banküberweisung von einem Konto abgezogen wird, jedoch nicht auf ein anderes erhöht wird, wird der gesamte Betrieb widerrufen. begintransaktion; updateAccountsSetBalance = Balance-100WH
 Kann ich das Datenbankkennwort in Navicat abrufen?
Apr 08, 2025 pm 09:51 PM
Kann ich das Datenbankkennwort in Navicat abrufen?
Apr 08, 2025 pm 09:51 PM
Navicat selbst speichert das Datenbankkennwort nicht und kann das verschlüsselte Passwort nur abrufen. Lösung: 1. Überprüfen Sie den Passwort -Manager. 2. Überprüfen Sie Navicats "Messnot Password" -Funktion; 3.. Setzen Sie das Datenbankkennwort zurück; 4. Kontaktieren Sie den Datenbankadministrator.
 Master SQL Limit -Klausel: Steuern Sie die Anzahl der Zeilen in einer Abfrage
Apr 08, 2025 pm 07:00 PM
Master SQL Limit -Klausel: Steuern Sie die Anzahl der Zeilen in einer Abfrage
Apr 08, 2025 pm 07:00 PM
SQllimit -Klausel: Steuern Sie die Anzahl der Zeilen in Abfrageergebnissen. Die Grenzklausel in SQL wird verwendet, um die Anzahl der von der Abfrage zurückgegebenen Zeilen zu begrenzen. Dies ist sehr nützlich, wenn große Datensätze, paginierte Anzeigen und Testdaten verarbeitet werden und die Abfrageeffizienz effektiv verbessern können. Grundlegende Syntax der Syntax: SelectColumn1, Spalte2, ... Fromtable_Namelimitnumber_of_rows; number_of_rows: Geben Sie die Anzahl der zurückgegebenen Zeilen an. Syntax mit Offset: SelectColumn1, Spalte2, ... Fromtable_NamelimitOffset, Number_of_rows; Offset: Skip überspringen
