

So konfigurieren Sie Hochverfügbarkeit und Persistenz in Redis


1. Redis-Hochverfügbarkeit
1. Übersicht über Redis-Hochverfügbarkeit
Bei Webservern bezieht sich Hochverfügbarkeit auf die Zeit, in der auf den Server normal zugegriffen werden kann, und der Messstandard ist, wie lange er normale Dienste bereitstellen kann (99,9 %, 99,99 %, 99,999 % usw.). [Verwandte Empfehlung: Redis-Video-Tutorial]
Im Kontext von Redis scheint die Bedeutung von Hochverfügbarkeit jedoch weiter gefasst zu sein als die Bereitstellung normaler Dienste (z. B. Master-Slave-Trennung, schnelle Disaster-Recovery-Technologie). Auch die Erweiterung der Datenkapazität muss berücksichtigt werden, die Datensicherheit geht nicht verloren usw.
2. Redis-Hochverfügbarkeitsstrategie
In Redis umfassen die Technologien zur Erzielung einer hohen Verfügbarkeit hauptsächlich Persistenz, Master-Slave-Trennung, Sentinels und Cluster.
| Hochverfügbarkeitsstrategie | Erklärung |
|---|---|
| Persistenz | Persistenz ist die einfachste Hochverfügbarkeitsmethode (manchmal nicht einmal als Hochverfügbarkeitsmethode klassifiziert). Ihre Hauptfunktion ist die Datensicherung, bald werden Daten gespeichert auf der Festplatte, um sicherzustellen, dass die Daten beim Beenden des Prozesses nicht verloren gehen. |
| Master-Slave-Replikation | Master-Slave-Replikation ist die Grundlage für hochverfügbares Redis. Sowohl Sentinel als auch Cluster erreichen eine hohe Verfügbarkeit basierend auf der Master-Slave-Replikation. Die Master-Slave-Replikation implementiert hauptsächlich die Datensicherung auf mehreren Maschinen sowie den Lastausgleich und die einfache Fehlerwiederherstellung für Lesevorgänge. Mängel: Die Wiederherstellung nach Fehlern kann nicht automatisiert werden, Schreibvorgänge können nicht lastverteilt werden und die Speicherkapazität ist durch eine einzelne Maschine begrenzt. |
| Sentinel | Basierend auf der Master-Slave-Replikation implementiert Sentinel eine automatisierte Fehlerbehebung. Nachteile: Schreibvorgänge können nicht lastverteilt werden und die Speicherkapazität ist durch eine einzelne Maschine begrenzt. |
| Cluster | Durch den Cluster löst Redis das Problem, dass Schreibvorgänge nicht lastausgleichbar sind und die Speicherkapazität durch eine einzelne Maschine begrenzt ist, und implementiert eine relativ vollständige Hochverfügbarkeitslösung. |
2. Redis-Persistenz
1. Redis-Persistenzfunktion
Redis ist eine In-Memory-Datenbank und Daten werden im Speicher gespeichert, um fällige Serverausfälle zu vermeiden Aus anderen Gründen gehen die Daten in Redis dauerhaft verloren, nachdem der Redis-Prozess abnormal beendet wurde. Es ist notwendig, die Daten in Redis regelmäßig in irgendeiner Form (Daten oder Befehle) aus dem Speicher zu speichern. Verwenden Sie persistente Dateien, um eine Datenwiederherstellung zu erreichen. Darüber hinaus können persistente Dateien zur Vorbereitung auf ein Notfall-Backup an einen Remote-Standort kopiert werden.
2. Zwei Arten der Redis-Persistenz
RDB-Persistenz
Das Prinzip besteht darin, die Redis-Datenbank regelmäßig im Speicher zu speichern .AOF-Persistenz (nur Datei anhängen)
Das Prinzip besteht darin, das Redis-Vorgangsprotokoll anhängend in die Datei zu schreiben, ähnlich dem Binlog von MySQL.
Da die AOF-Persistenz eine bessere Echtzeitleistung aufweist, d. h. weniger Daten verloren gehen, wenn der Prozess unerwartet beendet wird, ist AOF derzeit die gängige Persistenzmethode, aber die RDB-Persistenz hat immer noch ihren Platz.
3. RDB-Persistenz
RDB-Persistenz bezieht sich auf das Generieren einer Momentaufnahme der Daten im aktuellen Prozess im Speicher innerhalb eines bestimmten Zeitintervalls Verwenden Sie zum Speichern eine binäre Komprimierung auf der Festplatte (daher auch Snapshot-Persistenz genannt). Wenn Redis neu gestartet wird, kann die Snapshot-Datei gelesen werden, um die Daten wiederherzustellen.
3.1 Triggerbedingungen
Das Auslösen der RDB-Persistenz ist in zwei Typen unterteilt: manuelles Auslösen und automatisches Auslösen.
3.1.1 Manuell auslösen
Sowohl der Befehl save als auch der Befehl bgsave können RDB-Dateien generieren.
Der Speicherbefehl blockiert den Redis-Serverprozess, bis die RDB-Datei erstellt wird. Während der Zeit, in der der Redis-Server blockiert ist, kann der Server keine Befehlsanfragen verarbeiten.
Der Befehl bgsave fork() einen untergeordneten Prozess, der für die Erstellung der RDB-Datei verantwortlich ist, während der übergeordnete Prozess (d. h. der Redis-Hauptprozess) fortfährt Anfragen zu bearbeiten.
bgsave Befehlsausführungsprozess, nur der untergeordnete Fork-Prozess blockiert den Server, während für den Speicherbefehl der gesamte Prozess den Server blockiert, also wurde im Grunde gespeichert aufgegeben, Linie In der Umgebung muss die Verwendung von save eliminiert werden.
3.1.2 Automatische Auslösung
Beim automatischen Auslösen der RDB-Persistenz wählt Redis auch bgsave Anstatt Speichern Sie für die Persistenz.
3.2 Konfigurationsmethode
-
Konfigurieren Sie durch Ändern der Konfigurationsdatei: Speichern Sie m n
# 🎜 🎜# - Die häufigste Situation für die automatische Auslösung besteht darin, save m n in der Konfigurationsdatei zu übergeben und anzugeben, dass bgsave ausgelöst wird, wenn innerhalb von m Sekunden n Änderungen auftreten.
[root@localhost ~]# vim /etc/redis/6379.conf ##219行,以下三个save条件满足任意一个时,都会引起bgsave的调用save 900 1 ##当时间到900秒时,如果redis数据发生了至少1次变化,则执行bgsavesave 300 10 ##当时间到300秒时,如果redis数据发生了至少10次变化,则执行bgsavesave 60 10000 ##当时间到60秒时,如果redis数据发生了至少10000次变化,则执行bgsave##254行,指定RDB文件名dbfilename dump.rdb##264行,指定RDB文件和AOF文件所在目录dir /var/lib/redis/6379##242行,是否开启RDB文件压缩rdbcompression yes
#🎜 🎜#
- Wenn im Master-Slave-Replikationsszenario der Slave-Knoten einen vollständigen Kopiervorgang durchführt, führt der Master-Knoten den Befehl bgsave aus und sendet die RDB-Datei an den Slave-Knoten.
- Beim Ausführen des Befehls zum Herunterfahren wird die RDB-Persistenz automatisch ausgeführt.
- 3.4 Ausführungsprozess
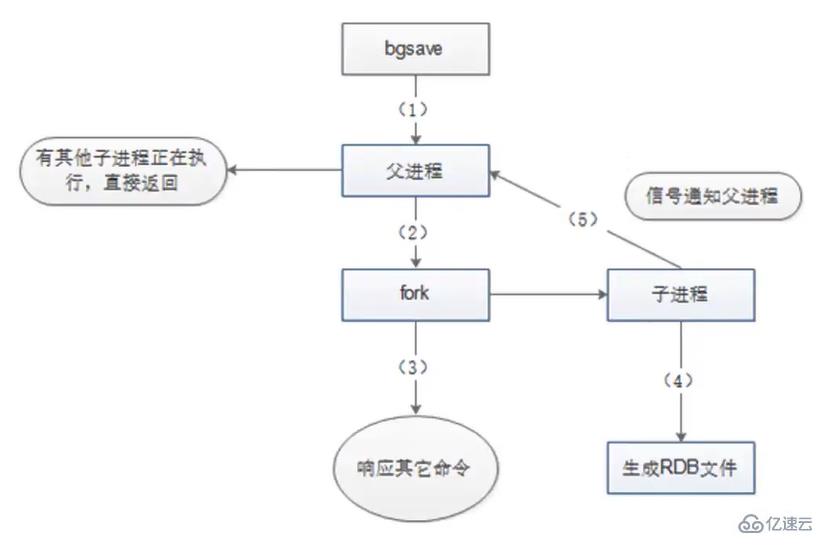
- Redis-Elternprozess Stellen Sie zunächst fest, ob der Speicher gerade ausgeführt wird oder ob der untergeordnete Prozess von bgsave/bgrewriteaof ausgeführt wird. Der Befehl bgsave kehrt direkt zurück. Die Unterprozesse von bgsave/bgrewriteaof können nicht gleichzeitig ausgeführt werden, hauptsächlich aus Leistungsgründen. Zwei gleichzeitige Unterprozesse führen gleichzeitig eine große Anzahl von Festplattenschreibvorgängen aus, was zu schwerwiegenden Leistungsproblemen führen kann.
- Beim Erstellen eines untergeordneten Prozesses führte der übergeordnete Prozess eine Fork-Operation durch, wodurch der übergeordnete Prozess blockiert wurde. Während dieser Zeit konnte Redis keine Befehle ausführen der Kunde.
- Nachdem der übergeordnete Prozess verzweigt ist, gibt der Befehl bgsave die Meldung „Hintergrundspeicherung gestartet“ zurück und blockiert den übergeordneten Prozess nicht mehr und kann auf andere Befehle #🎜🎜 reagieren #
- Der untergeordnete Prozess erstellt eine RDB-Datei, generiert eine temporäre Snapshot-Datei basierend auf dem Speicher-Snapshot des übergeordneten Prozesses und ersetzt die Originaldatei nach Abschluss atomar #🎜 🎜#
child Der Prozess sendet ein Signal an den übergeordneten Prozess, um den Abschluss anzuzeigen, und der übergeordnete Prozess aktualisiert statistische Informationen
3.5 Laden um Startup
Das Laden von RDB-Dateien erfolgt in Es wird automatisch ausgeführt, wenn der Server startet und es gibt keinen speziellen Befehl. Da AOF jedoch eine höhere Priorität hat, gibt Redis dem Laden der AOF-Datei zur Wiederherstellung von Daten nur dann Priorität, wenn AOF deaktiviert ist. Die RDB-Datei wird beim Start des Redis-Servers erkannt und automatisch geladen. Der Server wird beim Laden der RDB-Datei blockiert, bis der Ladevorgang abgeschlossen ist.
RDB-Persistenz schreibt Prozessdaten in Dateien, während AOF-Persistenz jeden von Redis ausgeführten Schreib- und Löschbefehl in einer separaten Protokolldatei aufzeichnet nicht aufgezeichnet werden; wenn Redis neu startet, führen Sie den Befehl in der AOF-Datei erneut aus, um die Daten wiederherzustellen.
4.1 开启 AOF
Redis服务器默认开启RDB,关闭AOF;要开启AOF,需要在配置文件中配置
[root@localhost ~]# vim /etc/redis/6379.conf ##700行,修改,开启AOFappendonly yes##704行,指定AOF文件名称appendfilename "appendonly.aof"##796行,是否忽略最后一条可能存在问题的指令aof-load-truncated yes[root@localhost ~]# /etc/init.d/redis_6379 restartStopping ... Redis stopped Starting Redis server...
4.2 执行流程
由于需要记录Redis的每条写命令,因此AOF不需要触发,下面介绍AOF的执行流程。
AOF的执行流程包括:
命令追加(append):将Redis的写命令追加到缓冲区aof_buf;
根据不同的同步策略,把aof_buf中的内容写入硬盘,并实现文件同步
文件重写(rewrite):定期重写AOF文件,达到压缩的目的。
4.2.1 命令追加(append)
Redis先将命令追加到缓冲区,而不是直接写入文件,主要是为了避免每次有写命令都直接写入硬盘,导致硬盘IO称为Redis负载的瓶颈。
命令追加的格式是Redis命令请求的协议格式,它是一种纯文本格式,具有兼容性好、可读性强、容易处理、操作简单、避免二次开销等优点。在AOF文件中,除了用于指定数据库的select命令(如select 0为选中0号数据库)是由Redis添加的,其他都是客户端发送来的写命令。
4.2.2 文件写入(write)和文件同步(sync)
Redis提供了多种AOF缓存区的同步文件策略,策略涉及到操作系统的write和fsync函数,说明如下:
为了提高文件写入效率,在现代操作系统中,当用户调用write函数将数据写入文件时,操作系统通常会将数据暂存到一个内存缓冲区里,当缓冲区被填满或超过了指定时限后,才真正将缓冲区的数据写入到硬盘里。这样的操作虽然提高了效率,但也带来了安全问题:如果计算机停机,内存缓冲区中的数据会丢失;因此系统同时提供了fsync、fdatasync等同步函数,可以强制操作系统立刻将缓冲区中的数据写入到硬盘里,从而确保数据的安全性。
4.2.3 三种同步方式
AOF缓存区的同步文件策略存在三种同步方式,通过对/etc/redis/6379.conf的729行的修改进行配置。
4.2.3.1 appendfsync always
将命令写入aof_buf后,立即进行系统fsync操作,将其同步到AOF文件,当fsync操作完成后,线程便会返回。这种情况下,每次有写命令都要同步到AOF文件,硬盘IO成为性能瓶颈,Redis只能支持大约几百TPS写入,严重降低了Redis的性能;即便是使用固态硬盘(SSD),每秒大约也就只能处理几万个命令,而且会大大降低SSD的寿命。
4.2.3.2 appendfsync no
命令写入aof_buf后调用系统write操作,不对AOF文件做fsync同步;同步由操作系统负载,通常同步周期为30秒。文件同步时间不可预测,并且缓冲区中的数据会堆积很多,导致数据安全性无法保障。
4.2.3.3 appendfsync everysec(推荐)
命令写入aof_buf后调用系统write操作,write完成后线程返回:fsync同步文件操作由专门的线程每秒调用一次。everysec是前述两种策略的折中,是性能和数据安全性的平衡,一次是Redis的默认配置,也是我们推荐的配置。
4.2.4 文件重写(rewrite)
随着时间流逝,Redis服务器执行的写命令越来越多,AOF文件也会越来越大;过大的AOF文件不仅会影响服务器的正常运行,也会导致数据恢复需要的时间过长。
文件重写是指定期重写AOF文件,减小AOF文件的体积。需要注意的是,AOF重写是把Redis进程内的数据转化为写命令,同步到新的AOF文件;不会对旧的AOF文件进行任何读取、写入操作。
关于文件重写需要注意的另一点是:对于AOF持久化来说,文件重写虽然是强烈推荐的,但并不是必须的;即使没有文件重写,数据也可以被持久化并在Redis启动的时候导入;因此在一些现实中,会关闭自动的文件重写,然后定时任务在每天的某一时刻定时执行。
4.2.4.1 具有压缩功能的原因
文件重写之所以能够压缩AOF文件,原因在于:
过期的数据不再写入文件。
无效的命令不再写入文件:如有些数据被重复设置(set mykey v1,set mykey v2)、有些数据被删除了(set myset v1,del myset)等。
多条命令可以合并为一个:如sadd myset v1,sadd myset v2,sadd myset v3可以合并为sadd myset v1 v2 v3。
通过上述原因可以看出,由于重写后AOF执行的命令减少了,文件重写既可以减少文件占用的空间,也可以加快恢复速度。
4.2.4.2 文件重写的触发
文件重写分为手动触发和自动触发:
Manuelle Auslösung: Rufen Sie den Befehl bfrewriteaof direkt auf. Die Ausführung dieses Befehls ähnelt in gewisser Weise der Ausführung von bgsave und blockiert nur beim Forken.
Automatische Auslösung: Führen Sie bgrewriteaof automatisch aus, indem Sie die Optionen „auto-aof-rewrite-min-size“ und „auto-aof-rewrite-percentage“ festlegen. Nur wenn die beiden Optionen auto-aof-rewrite-min-size und auto-aof-rewrite-percentage gleichzeitig erfüllt sind, wird das AOF-Umschreiben, also der bgrewriteaof-Vorgang, automatisch ausgelöst.
Die automatisch ausgelöste Konfiguration befindet sich in den Zeilen 771 und 772 von /etc/redis/6379.conf自动触发的配置位于/etc/redis/6379.conf的771行和772行
auto-aof-rewrite-percentage 100
当前AOF文件大小(即aof_current_size)是上次日志重写时AOF文件大小(aof_base_size)两倍时,发生bgrewriteaof操作auto-aof-rewrite-min-size 64mb
当前AOF文件执行bgrewriteaof命令的最小值,避免刚开始启动Redis时由于文件尺寸较小导致频繁的bgrewriteaof
4.2.4.3 文件重写的流程
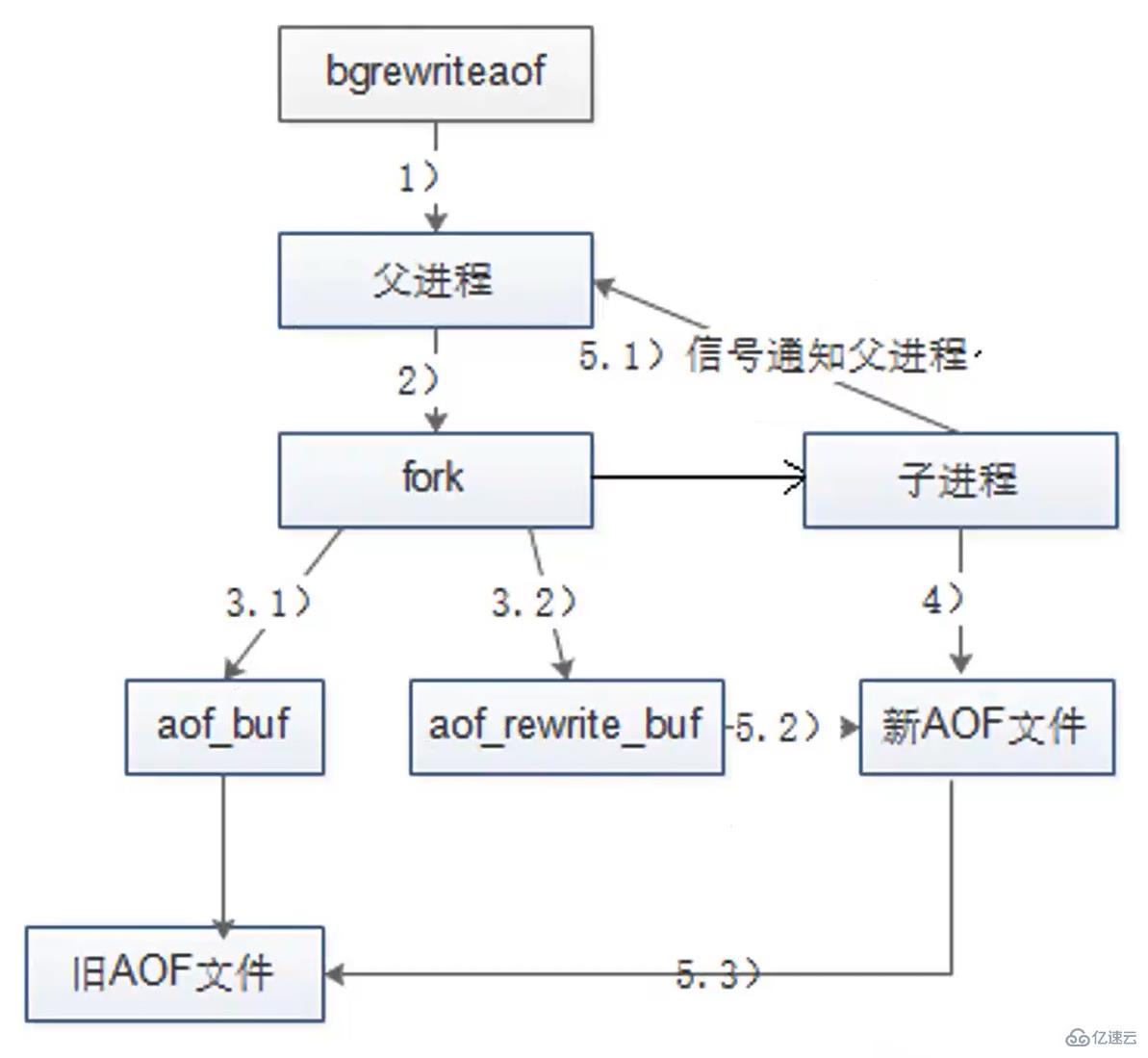
文件重写的流程如下:
Redis父进程首先平判断当前是否存在正在执行bgsave/bgrewriteaof的子进程;如果存在则bgrewriteaof命令直接返回,如果存在bgsave命令则等bgsave执行完成后再执行。
父进程执行fork操作创建子进程,这个过程中父进程是阻塞的。
父进程fork后,bgrewriteaof命令返回“Background append only file rewrite started”信息并不再阻塞父进程,并可以响应其他命令。Redis的所有写命令依然写入AOF缓冲区,并根据appendfsync策略同步到硬盘,保证原有AOF机制的正确。
子进程只能共享fork操作时的内存数据,这是因为fork操作使用了写时复制技术。由于父进程依然在响应命令,因此Redis使用AOF重写缓冲区(aof_rewrite_buf)保存这部分数据,防止新AOF文件生成期间丢失这部分数据。也就是说,bgrewriteaof执行期间,Redis的写命令同时追加到aof_buf和aof_rewrite_buf两个缓冲区。
子进程根据内存快照,按照命令合并规则写入到新的AOF文件。
子进程写完新的AOF文件后,向父进程发信号,父进程更新统计信息,具体可以通过info persistence查看。
父进程把AOF重写缓冲区的数据写入到新的AOF文件,这样就保证了新AOF文件所保存的数据库状态和服务器当前状态一致。
使用新的AOF文件替换老文件,文成AOF重写。
关于文件重写的流程,有两点需要特别注意:
- auto-aof-rewrite-percentage 100
Die aktuelle AOF-Dateigröße ( d. h. aof_current_size) ist das Doppelte der AOF-Dateigröße (aof_base_size). Während des letzten Protokollumschreibens wird der bgrewriteaof-Vorgang ausgeführt Um den ersten Start zu vermeiden, kommt es aufgrund der geringen Dateigröße in Redis häufig zu bgrewriteaof
-
4.2.4.3 Prozess zum Umschreiben von Dateien
Der Prozess des Umschreibens von Dateien ist wie folgt:
- Der übergeordnete Prozess führt eine Verzweigungsoperation durch, um einen untergeordneten Prozess zu erstellen. Während dieses Prozesses ist der übergeordnete Prozess blockiert.
- Nachdem sich der übergeordnete Prozess verzweigt hat, gibt der Befehl bgrewriteaof die Meldung „Nur Datei-Rewrite im Hintergrund anhängen“ zurück und blockiert den übergeordneten Prozess nicht mehr und kann auf andere Befehle reagieren. Alle Redis-Schreibbefehle werden weiterhin in den AOF-Puffer geschrieben und gemäß der appendfsync-Richtlinie mit der Festplatte synchronisiert, um die Richtigkeit des ursprünglichen AOF-Mechanismus sicherzustellen.
- Der untergeordnete Prozess kann die Speicherdaten nur während des Fork-Vorgangs gemeinsam nutzen. Dies liegt daran, dass der Fork-Vorgang die Copy-on-Write-Technologie verwendet. Da der übergeordnete Prozess immer noch auf den Befehl reagiert, verwendet Redis den AOF-Rewrite-Puffer (aof_rewrite_buf), um diesen Teil der Daten zu speichern und zu verhindern, dass dieser Teil der Daten während der Generierung der neuen AOF-Datei verloren geht. Mit anderen Worten: Während der Ausführung von bgrewriteaof wird der Schreibbefehl von Redis gleichzeitig an die Puffer aof_buf und aof_rewrite_buf angehängt.
Nachdem der untergeordnete Prozess das Schreiben der neuen AOF-Datei abgeschlossen hat, sendet er ein Signal an den übergeordneten Prozess und der übergeordnete Prozess aktualisiert die statistischen Informationen, die über die Informationspersistenz angezeigt werden können.
Ersetzen Sie die alte Datei durch die neue AOF-Datei und schreiben Sie sie in AOF um.
In Bezug auf den Prozess des Umschreibens von Dateien gibt es zwei Punkte, die besondere Aufmerksamkeit erfordern: 🎜🎜🎜🎜Das Umschreiben wird dadurch durchgeführt, dass der übergeordnete Prozess den untergeordneten Prozess verzweigt. 🎜🎜🎜🎜Der Schreibbefehl wird ausgeführt von Redis während des Umschreibens, muss an die neue AOF-Datei angehängt werden. Aus diesem Grund führt Redis den aof_rewrite_buf-Cache ein Daten wiederherstellen, wenn es gestartet wird; nur wenn AOF geschlossen ist, wird die RDB-Datei geladen, um Daten wiederherzustellen. 🎜🎜🎜🎜Wenn AOF aktiviert ist, die AOF-Datei jedoch nicht vorhanden ist, wird die RDB-Datei nicht geladen, selbst wenn sie vorhanden ist. 🎜🎜🎜🎜Wenn Redis eine AOF-Datei lädt, wird die AOF-Datei überprüft. Wenn die Datei beschädigt ist, wird ein Fehler im Protokoll gedruckt und Redis kann nicht gestartet werden. Wenn jedoch das Ende der AOF-Datei unvollständig ist (ein plötzlicher Maschinenausfall kann leicht dazu führen, dass das Ende der Datei unvollständig ist) und der Parameter aof_load_truncated aktiviert ist, wird eine Warnung im Protokoll ausgegeben und von Redis ignoriert das Ende der AOF-Datei und startet erfolgreich. Der Parameter aof_load_truncated ist standardmäßig aktiviert. 🎜🎜🎜🎜5. Vor- und Nachteile von RDB und AOF🎜🎜🎜RDB-Persistenz🎜🎜🎜Vorteile: RDB-Dateien sind kompakt, klein, schnell in der Netzwerkübertragung und für vollständige Kopien geeignet; Einer der wichtigsten Vorteile von RDB besteht natürlich darin, dass es im Vergleich zu AOF einen relativ geringen Einfluss auf die Leistung hat. 🎜 Nachteile: Der bekannte Nachteil von RDB-Dateien besteht darin, dass die Persistenzmethode von Daten-Snapshots dazu führt, dass eine Echtzeit-Persistenz nicht erreicht werden kann. Heutzutage, wenn Daten immer wichtiger werden, ist ein großer Datenverlust oft inakzeptabel. So wird die AOF-Persistenz zum Mainstream. Darüber hinaus müssen RDB-Dateien einem bestimmten Format entsprechen und eine schlechte Kompatibilität aufweisen (z. B. ist die alte Version von Redis nicht mit der neuen Version von RDB-Dateien kompatibel). 🎜 Für die RDB-Persistenz wird einerseits der Redis-Hauptprozess blockiert, wenn bgsave einen Fork-Vorgang ausführt. Andererseits führt das Schreiben von Daten auf die Festplatte durch den Unterprozess auch zu E/A-Druck. 🎜🎜🎜AOF-Persistenz🎜🎜🎜Entsprechend der RDB-Persistenz liegt die Priorität von AOF in der Unterstützung der zweiten Ebene der Persistenz und einer guten Kompatibilität. Die Nachteile sind große Dateien, langsame Wiederherstellungsgeschwindigkeit und große Auswirkungen auf die Leistung. 🎜🎜Für die AOF-Persistenz wird die Häufigkeit des Schreibens von Daten auf die Festplatte erheblich erhöht (zweite Ebene unter der Everysec-Richtlinie), der E/A-Druck ist größer und es kann sogar zu zusätzlichen Blockierungsproblemen im AOF kommen. 🎜Ähnlich wie bgsave von RDB wird auch das Umschreiben von AOF-Dateien mit den Problemen der Fork-Blockierung und der E/A-Last des untergeordneten Prozesses konfrontiert sein. AOF schreibt Daten häufiger auf die Festplatte, was einen größeren Einfluss auf die Leistung des Redis-Hauptprozesses hat.
Im Allgemeinen wird empfohlen, die automatische Umschreibfunktion von AOF zu deaktivieren, eine geplante Aufgabe für den Umschreibvorgang festzulegen und diese am frühen Morgen bei geringem Geschäftsvolumen auszuführen, um die Auswirkungen von AOF zu verringern auf der Leistung des Hauptprozesses und dem Lese- und Schreibdruck von IO.
Das obige ist der detaillierte Inhalt vonSo konfigurieren Sie Hochverfügbarkeit und Persistenz in Redis. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 So erstellen Sie den Redis -Clustermodus
Apr 10, 2025 pm 10:15 PM
So erstellen Sie den Redis -Clustermodus
Apr 10, 2025 pm 10:15 PM
Der Redis -Cluster -Modus bietet Redis -Instanzen durch Sharding, die Skalierbarkeit und Verfügbarkeit verbessert. Die Bauschritte sind wie folgt: Erstellen Sie ungerade Redis -Instanzen mit verschiedenen Ports; Erstellen Sie 3 Sentinel -Instanzen, Monitor -Redis -Instanzen und Failover; Konfigurieren von Sentinel -Konfigurationsdateien, Informationen zur Überwachung von Redis -Instanzinformationen und Failover -Einstellungen hinzufügen. Konfigurieren von Redis -Instanzkonfigurationsdateien, aktivieren Sie den Cluster -Modus und geben Sie den Cluster -Informationsdateipfad an. Erstellen Sie die Datei nodes.conf, die Informationen zu jeder Redis -Instanz enthält. Starten Sie den Cluster, führen Sie den Befehl erstellen aus, um einen Cluster zu erstellen und die Anzahl der Replikate anzugeben. Melden Sie sich im Cluster an, um den Befehl cluster info auszuführen, um den Clusterstatus zu überprüfen. machen
 So löschen Sie Redis -Daten
Apr 10, 2025 pm 10:06 PM
So löschen Sie Redis -Daten
Apr 10, 2025 pm 10:06 PM
So löschen Sie Redis -Daten: Verwenden Sie den Befehl Flushall, um alle Schlüsselwerte zu löschen. Verwenden Sie den Befehl flushdb, um den Schlüsselwert der aktuell ausgewählten Datenbank zu löschen. Verwenden Sie SELECT, um Datenbanken zu wechseln, und löschen Sie dann FlushDB, um mehrere Datenbanken zu löschen. Verwenden Sie den Befehl del, um einen bestimmten Schlüssel zu löschen. Verwenden Sie das Redis-Cli-Tool, um die Daten zu löschen.
 So lesen Sie Redis -Warteschlange
Apr 10, 2025 pm 10:12 PM
So lesen Sie Redis -Warteschlange
Apr 10, 2025 pm 10:12 PM
Um eine Warteschlange aus Redis zu lesen, müssen Sie den Warteschlangenname erhalten, die Elemente mit dem Befehl LPOP lesen und die leere Warteschlange verarbeiten. Die spezifischen Schritte sind wie folgt: Holen Sie sich den Warteschlangenname: Nennen Sie ihn mit dem Präfix von "Warteschlange:" wie "Warteschlangen: My-Queue". Verwenden Sie den Befehl LPOP: Wischen Sie das Element aus dem Kopf der Warteschlange aus und geben Sie seinen Wert zurück, z. B. die LPOP-Warteschlange: my-queue. Verarbeitung leerer Warteschlangen: Wenn die Warteschlange leer ist, gibt LPOP NIL zurück, und Sie können überprüfen, ob die Warteschlange existiert, bevor Sie das Element lesen.
 So verwenden Sie den Befehl Redis
Apr 10, 2025 pm 08:45 PM
So verwenden Sie den Befehl Redis
Apr 10, 2025 pm 08:45 PM
Die Verwendung der REDIS -Anweisung erfordert die folgenden Schritte: Öffnen Sie den Redis -Client. Geben Sie den Befehl ein (Verbschlüsselwert). Bietet die erforderlichen Parameter (variiert von der Anweisung bis zur Anweisung). Drücken Sie die Eingabetaste, um den Befehl auszuführen. Redis gibt eine Antwort zurück, die das Ergebnis der Operation anzeigt (normalerweise in Ordnung oder -err).
 So verwenden Sie Redis Lock
Apr 10, 2025 pm 08:39 PM
So verwenden Sie Redis Lock
Apr 10, 2025 pm 08:39 PM
Um die Operationen zu sperren, muss die Sperre durch den Befehl setNX erfasst werden und dann den Befehl Ablauf verwenden, um die Ablaufzeit festzulegen. Die spezifischen Schritte sind: (1) Verwenden Sie den Befehl setNX, um zu versuchen, ein Schlüsselwertpaar festzulegen; (2) Verwenden Sie den Befehl Ablauf, um die Ablaufzeit für die Sperre festzulegen. (3) Verwenden Sie den Befehl Del, um die Sperre zu löschen, wenn die Sperre nicht mehr benötigt wird.
 So lesen Sie den Quellcode von Redis
Apr 10, 2025 pm 08:27 PM
So lesen Sie den Quellcode von Redis
Apr 10, 2025 pm 08:27 PM
Der beste Weg, um Redis -Quellcode zu verstehen, besteht darin, Schritt für Schritt zu gehen: Machen Sie sich mit den Grundlagen von Redis vertraut. Wählen Sie ein bestimmtes Modul oder eine bestimmte Funktion als Ausgangspunkt. Beginnen Sie mit dem Einstiegspunkt des Moduls oder der Funktion und sehen Sie sich die Codezeile nach Zeile an. Zeigen Sie den Code über die Funktionsaufrufkette an. Kennen Sie die von Redis verwendeten Datenstrukturen. Identifizieren Sie den von Redis verwendeten Algorithmus.
 So verwenden Sie die Befehlszeile der Redis
Apr 10, 2025 pm 10:18 PM
So verwenden Sie die Befehlszeile der Redis
Apr 10, 2025 pm 10:18 PM
Verwenden Sie das Redis-Befehlszeilen-Tool (REDIS-CLI), um Redis in folgenden Schritten zu verwalten und zu betreiben: Stellen Sie die Adresse und den Port an, um die Adresse und den Port zu stellen. Senden Sie Befehle mit dem Befehlsnamen und den Parametern an den Server. Verwenden Sie den Befehl Hilfe, um Hilfeinformationen für einen bestimmten Befehl anzuzeigen. Verwenden Sie den Befehl zum Beenden, um das Befehlszeilenwerkzeug zu beenden.
 So konfigurieren Sie die Ausführungszeit der Lua -Skript in CentOS Redis
Apr 14, 2025 pm 02:12 PM
So konfigurieren Sie die Ausführungszeit der Lua -Skript in CentOS Redis
Apr 14, 2025 pm 02:12 PM
Auf CentOS -Systemen können Sie die Ausführungszeit von LuA -Skripten einschränken, indem Sie Redis -Konfigurationsdateien ändern oder Befehle mit Redis verwenden, um zu verhindern, dass bösartige Skripte zu viele Ressourcen konsumieren. Methode 1: Ändern Sie die Redis -Konfigurationsdatei und suchen Sie die Redis -Konfigurationsdatei: Die Redis -Konfigurationsdatei befindet sich normalerweise in /etc/redis/redis.conf. Konfigurationsdatei bearbeiten: Öffnen Sie die Konfigurationsdatei mit einem Texteditor (z. B. VI oder Nano): Sudovi/etc/redis/redis.conf Setzen Sie die LUA -Skriptausführungszeit.
