
 Datenbank
MySQL-Tutorial
Welche Lösungen gibt es für die MySQL-Datensynchronisierung mit Elasticsearch?
Datenbank
MySQL-Tutorial
Welche Lösungen gibt es für die MySQL-Datensynchronisierung mit Elasticsearch?
Welche Lösungen gibt es für die MySQL-Datensynchronisierung mit Elasticsearch?

Produktabfrage
Sie sollten auf verschiedenen E-Commerce-Websites nach Produkten gesucht haben. Wie suchen Sie normalerweise nach Produkten? Suchmaschine Elasticsearch.
Dann stellt sich die Frage: Wenn ein Produkt in den Handel kommt, werden die Daten normalerweise in die MySQL-Datenbank geschrieben. Wie werden die Daten zum Abruf mit Elasticsearch synchronisiert?
MySQL synchronisiert ES
1. Synchrones Doppelschreiben
Dies ist der direkteste Weg, den man sich vorstellen kann. Beim Schreiben in MySQL wird gleichzeitig auch eine Kopie der Daten direkt in ES geschrieben.
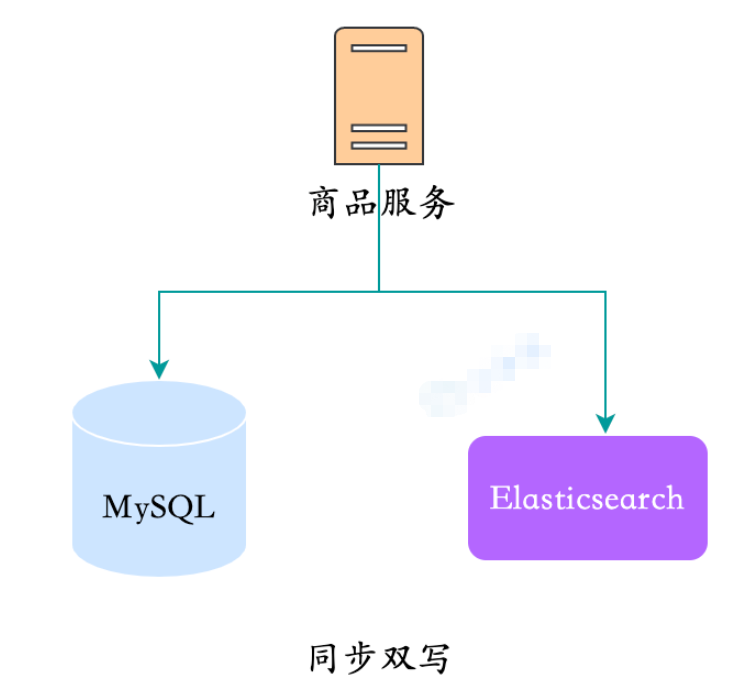
Synchronisiertes Doppelschreiben
Für diese Methode:
Vorteile: Einfache Implementierung
Nachteile:
Geschäftskopplung, Kopplung einer großen Menge an Datensynchronisationscode in der Warenverwaltung
beeinträchtigt die Leistung , Schreiben Mit zwei Speichern wird die Antwortzeit länger
Unpraktisch zu erweitern: Die Suche kann einige personalisierte Anforderungen haben, die eine Aggregation von Daten erfordern, was umständlich zu implementieren ist
2. Asynchrones Doppelschreiben
Wir können Stellen Sie sich das auch leicht vor: Bei der asynchronen Dual-Writing-Methode werden die Produktdaten beim Auflisten von Produkten zunächst in MQ geworfen. Um die Kopplung zu verstehen, teilen wir normalerweise einen Suchdienst auf und der Suchdienst abonniert die Produktnachrichten Änderungen bis zur vollständigen Synchronisierung.
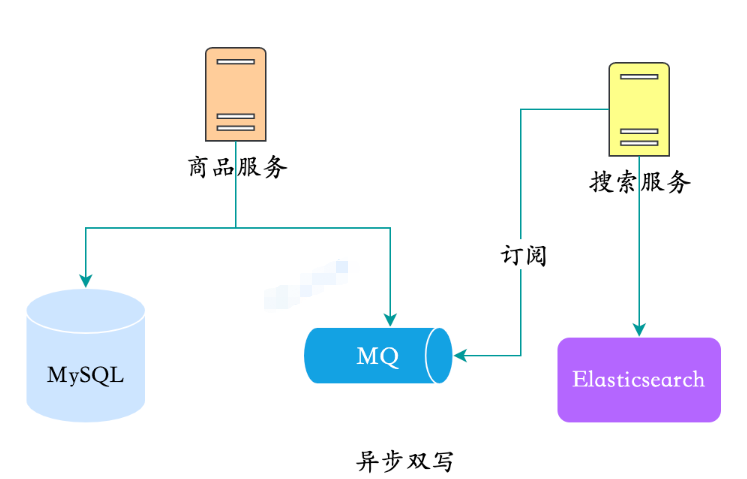
Asynchrones Doppelschreiben
Wie bereits erwähnt, was soll ich tun, wenn einige Daten in einer Struktur ähnlich einer breiten Tabelle aggregiert werden müssen? Beispielsweise sind die Produktkategorie-, SPU- und SKU-Tabellen der Produktbibliothek getrennt, aber die erneute Aggregation in ES ist weniger effizient. Es ist am besten, die Produktdaten zu aggregieren und eine ähnliche Größe zu verwenden -scale-Methode in ES Es wird in Form einer breiten Tabelle gespeichert, sodass die Abfrageeffizienz höher ist.
Mehrdimensionale Abfrage mit mehreren Bedingungen
Es gibt eigentlich keine gute Möglichkeit, dies zu tun. Grundsätzlich müssen Sie immer noch den Dienst durchsuchen, um die Datenbank direkt zu überprüfen, oder ihn aus der Ferne aufrufen und dann die Produktdatenbank erneut abfragen. das ist der sogenannte Backcheck.
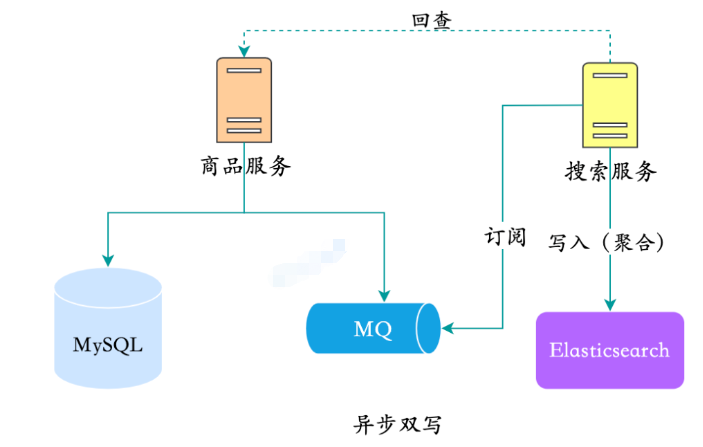
Überprüfen, um die Aggregation abzuschließen
Auf diese Weise:
Vorteile:
Entkopplung, Produkte und Dienste müssen nicht auf Datensynchronisation achten
Gute Echtzeitleistung mit MQ unter Unter normalen Umständen ist die Synchronisierung auf der zweiten Ebene abgeschlossen. Nachteile: Einführung neuer Komponenten und Dienste, wodurch die Komplexität erhöht wird Daten nicht so groß? Was tun? Geplante Aufgaben sind ebenfalls verfügbar.
- Das Problem bei geplanten Aufgaben ist, dass die Häufigkeit hoch ist und es zu unnatürlichen Spitzenzeiten kommt, wodurch die Speicher-CPU- und Speicherauslastung in Spitzenzeiten ansteigt. Wenn die Frequenz niedrig ist, steigt sie in Echtzeit an. Der Sex ist relativ schlecht und es gibt auch Spitzen. Diese Methode:
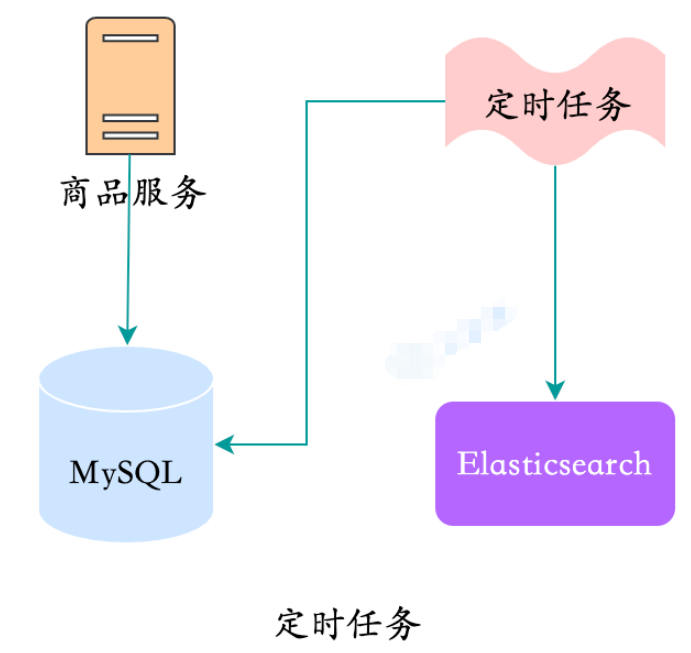 Schwierig, Echtzeitleistung zu garantieren
Schwierig, Echtzeitleistung zu garantieren
höherer Speicherdruck
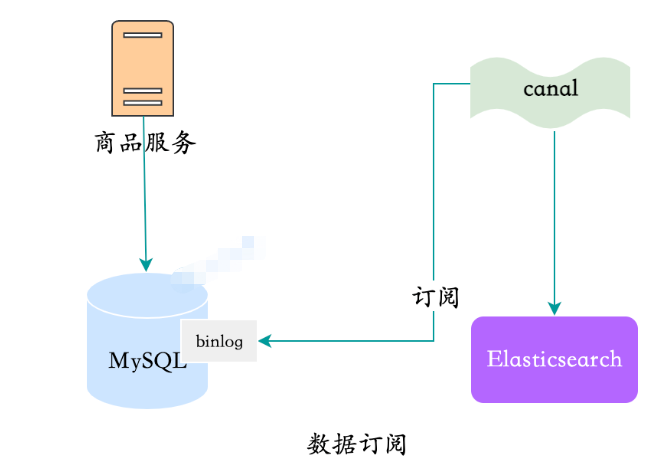
4. Datenabonnement
Es gibt auch einen anderen Weg , das ist das beliebteste Datenabonnement.
- MySQL erreicht die Master-Slave-Synchronisation durch Binlog-Abonnements. Verschiedene Datenabonnement-Frameworks wie Canal nutzen dieses Prinzip, um die Client-Komponente als Slave-Bibliothek zu tarnen, um ein Datenabonnement zu implementieren.
- MySQL-Master-Slave-SynchronisationWir nehmen den am weitesten verbreiteten Kanal, der eine Vielzahl von Adaptern unterstützt, einschließlich des ES-Adapters, nach dem Start können Sie MySQL-Daten direkt synchronisieren Mit ES ist dieser Prozess Zero-Code.
Kanalsynchronisationsdaten
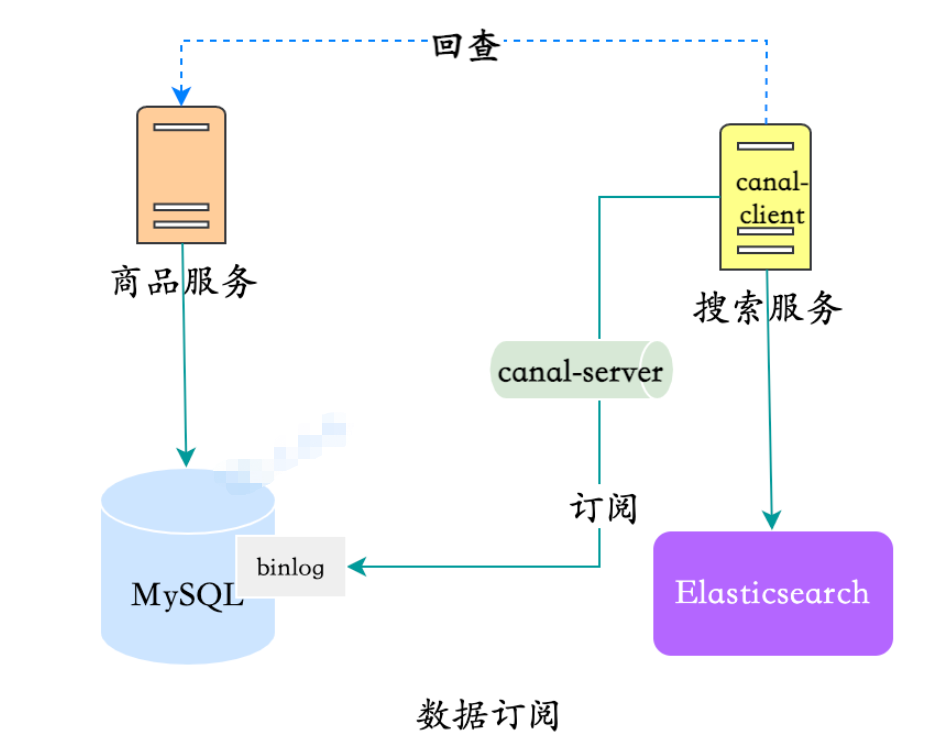
Obwohl wir dem Rat des Chefs folgen und den Kanal für Synchronisationsarbeiten verwenden, müssen wir tatsächlich noch Code schreiben. Warum?
Aufgrund der begrenzten Unterstützung von Canal muss die oben erwähnte Datenaggregation mehrerer Tabellen noch durch Überprüfung implementiert werden. Zu diesem Zeitpunkt ist die Verwendung von Canal-Adapter nicht angebracht. Sie müssen den Canal-Client selbst implementieren, Daten überwachen und aggregieren und an ES schreiben: 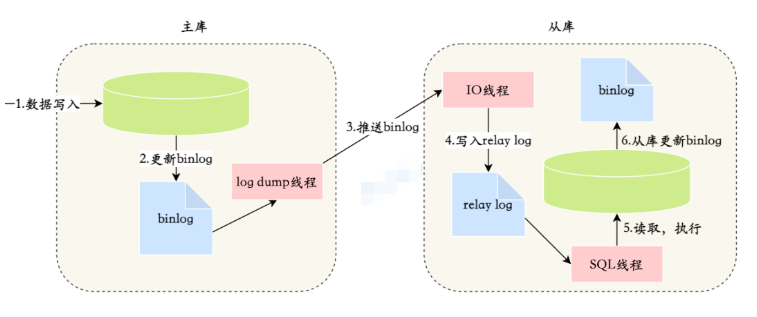
Datenabonnement + Überprüfung canal-adapter
 Nutzen Sie also das Datenabonnement:
Nutzen Sie also das Datenabonnement:
Vorteile:
Weniger geschäftliche Eingriffe
Was die Auswahl an Datenabonnement-Frameworks betrifft, sind die gängigsten im Allgemeinen die folgenden: Quelle
|
Community |
Entwicklungssprache | Java | |
|---|---|---|---|
| Aktivität | Aktiv | Aktiv | |
| Hohe Verfügbarkeit | Support | Support | |
| Client | Java/Go/PHP/Python/Rust | None | |
| Message Landing | Kafka/RocketMQ usw. | Kafka/RabbitNQ/Redis usw. | |
| Nachrichtenformat | Angepasst | JSON | |
| Dokument detailliert | Detailliert | Detailliert | |
| Boostrap | Nicht unterstützt | Unterstützt | |
| MySQL synchronisiert zu anderen Datenspeichern wie HBase, grundsätzlich mit ähnlichen Methoden. |
Das obige ist der detaillierte Inhalt vonWelche Lösungen gibt es für die MySQL-Datensynchronisierung mit Elasticsearch?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 MySQL: Die einfache Datenverwaltung für Anfänger
Apr 09, 2025 am 12:07 AM
MySQL: Die einfache Datenverwaltung für Anfänger
Apr 09, 2025 am 12:07 AM
MySQL ist für Anfänger geeignet, da es einfach zu installieren, leistungsfähig und einfach zu verwalten ist. 1. Einfache Installation und Konfiguration, geeignet für eine Vielzahl von Betriebssystemen. 2. Unterstützung grundlegender Vorgänge wie Erstellen von Datenbanken und Tabellen, Einfügen, Abfragen, Aktualisieren und Löschen von Daten. 3. Bereitstellung fortgeschrittener Funktionen wie Join Operations und Unterabfragen. 4. Die Leistung kann durch Indexierung, Abfrageoptimierung und Tabellenpartitionierung verbessert werden. 5. Backup-, Wiederherstellungs- und Sicherheitsmaßnahmen unterstützen, um die Datensicherheit und -konsistenz zu gewährleisten.
 MySQL: Einfache Konzepte für einfaches Lernen
Apr 10, 2025 am 09:29 AM
MySQL: Einfache Konzepte für einfaches Lernen
Apr 10, 2025 am 09:29 AM
MySQL ist ein Open Source Relational Database Management System. 1) Datenbank und Tabellen erstellen: Verwenden Sie die Befehle erstellte und creatEtable. 2) Grundlegende Vorgänge: Einfügen, aktualisieren, löschen und auswählen. 3) Fortgeschrittene Operationen: Join-, Unterabfrage- und Transaktionsverarbeitung. 4) Debugging -Fähigkeiten: Syntax, Datentyp und Berechtigungen überprüfen. 5) Optimierungsvorschläge: Verwenden Sie Indizes, vermeiden Sie ausgewählt* und verwenden Sie Transaktionen.
 Wie man phpmyadmin öffnet
Apr 10, 2025 pm 10:51 PM
Wie man phpmyadmin öffnet
Apr 10, 2025 pm 10:51 PM
Sie können PhpMyAdmin in den folgenden Schritten öffnen: 1. Melden Sie sich beim Website -Bedienfeld an; 2. Finden und klicken Sie auf das Symbol phpmyadmin. 3. Geben Sie MySQL -Anmeldeinformationen ein; 4. Klicken Sie auf "Login".
 So erstellen Sie Navicat Premium
Apr 09, 2025 am 07:09 AM
So erstellen Sie Navicat Premium
Apr 09, 2025 am 07:09 AM
Erstellen Sie eine Datenbank mit Navicat Premium: Stellen Sie eine Verbindung zum Datenbankserver her und geben Sie die Verbindungsparameter ein. Klicken Sie mit der rechten Maustaste auf den Server und wählen Sie Datenbank erstellen. Geben Sie den Namen der neuen Datenbank und den angegebenen Zeichensatz und die angegebene Kollektion ein. Stellen Sie eine Verbindung zur neuen Datenbank her und erstellen Sie die Tabelle im Objektbrowser. Klicken Sie mit der rechten Maustaste auf die Tabelle und wählen Sie Daten einfügen, um die Daten einzufügen.
 MySQL und SQL: Wesentliche Fähigkeiten für Entwickler
Apr 10, 2025 am 09:30 AM
MySQL und SQL: Wesentliche Fähigkeiten für Entwickler
Apr 10, 2025 am 09:30 AM
MySQL und SQL sind wesentliche Fähigkeiten für Entwickler. 1.MYSQL ist ein Open -Source -Relational Database Management -System, und SQL ist die Standardsprache, die zum Verwalten und Betrieb von Datenbanken verwendet wird. 2.MYSQL unterstützt mehrere Speichermotoren durch effiziente Datenspeicher- und Abruffunktionen, und SQL vervollständigt komplexe Datenoperationen durch einfache Aussagen. 3. Beispiele für die Nutzung sind grundlegende Abfragen und fortgeschrittene Abfragen wie Filterung und Sortierung nach Zustand. 4. Häufige Fehler umfassen Syntaxfehler und Leistungsprobleme, die durch Überprüfung von SQL -Anweisungen und Verwendung von Erklärungsbefehlen optimiert werden können. 5. Leistungsoptimierungstechniken umfassen die Verwendung von Indizes, die Vermeidung vollständiger Tabellenscanning, Optimierung von Join -Operationen und Verbesserung der Code -Lesbarkeit.
 So erstellen Sie eine neue Verbindung zu MySQL in Navicat
Apr 09, 2025 am 07:21 AM
So erstellen Sie eine neue Verbindung zu MySQL in Navicat
Apr 09, 2025 am 07:21 AM
Sie können eine neue MySQL -Verbindung in Navicat erstellen, indem Sie den Schritten folgen: Öffnen Sie die Anwendung und wählen Sie eine neue Verbindung (Strg N). Wählen Sie "MySQL" als Verbindungstyp. Geben Sie die Hostname/IP -Adresse, den Port, den Benutzernamen und das Passwort ein. (Optional) Konfigurieren Sie erweiterte Optionen. Speichern Sie die Verbindung und geben Sie den Verbindungsnamen ein.
 So wiederherstellen Sie Daten nach dem Löschen von SQL Zeilen
Apr 09, 2025 pm 12:21 PM
So wiederherstellen Sie Daten nach dem Löschen von SQL Zeilen
Apr 09, 2025 pm 12:21 PM
Das Wiederherstellen von gelöschten Zeilen direkt aus der Datenbank ist normalerweise unmöglich, es sei denn, es gibt einen Backup- oder Transaktions -Rollback -Mechanismus. Schlüsselpunkt: Transaktionsrollback: Führen Sie einen Rollback aus, bevor die Transaktion Daten wiederherstellt. Sicherung: Regelmäßige Sicherung der Datenbank kann verwendet werden, um Daten schnell wiederherzustellen. Datenbank-Snapshot: Sie können eine schreibgeschützte Kopie der Datenbank erstellen und die Daten wiederherstellen, nachdem die Daten versehentlich gelöscht wurden. Verwenden Sie eine Löschanweisung mit Vorsicht: Überprüfen Sie die Bedingungen sorgfältig, um das Verhandlich von Daten zu vermeiden. Verwenden Sie die WHERE -Klausel: Geben Sie die zu löschenden Daten explizit an. Verwenden Sie die Testumgebung: Testen Sie, bevor Sie einen Löschvorgang ausführen.
 So verwenden Sie ein einzelnes Gewinde -Redis
Apr 10, 2025 pm 07:12 PM
So verwenden Sie ein einzelnes Gewinde -Redis
Apr 10, 2025 pm 07:12 PM
Redis verwendet eine einzelne Gewindearchitektur, um hohe Leistung, Einfachheit und Konsistenz zu bieten. Es wird E/A-Multiplexing, Ereignisschleifen, nicht blockierende E/A und gemeinsame Speicher verwendet, um die Parallelität zu verbessern, jedoch mit Einschränkungen von Gleichzeitbeschränkungen, einem einzelnen Ausfallpunkt und ungeeigneter Schreib-intensiver Workloads.
