
Einführung in Redis
Redis ist vollständig Open Source und kostenlos, entspricht dem BSD-Protokoll und ist eine leistungsstarke Schlüsselwertdatenbank
Redis weist im Vergleich zu anderen Schlüsselwert-Cache-Produkten die folgenden drei Merkmale auf:
Redis unterstützt Datenpersistenz und kann die Daten im Speicher auf der Festplatte speichern und zur Verwendung beim Neustart erneut laden.
Redis unterstützt nicht nur einfache Daten vom Typ Schlüsselwert, sondern bietet auch die Speicherung von Datenstrukturen wie Liste, Satz, Zset, Hash usw.
Redis unterstützt die Datensicherung, also den Master-Slave-Modus Datensicherung
Vorteile von Redis
Extrem hohe Leistung– Die Lesegeschwindigkeit von Redis beträgt 110.000 Mal/s und die Schreibgeschwindigkeit beträgt 81.000 Mal/s.
Umfangreiche Datentypen – Redis unterstützt Datentypoperationen vom Typ Strings, Listen, Hashes, Mengen und geordnete Mengen für binäre Fälle.
Atomarität – Alle Operationen von Redis sind atomar, was bedeutet, dass sie entweder erfolgreich oder überhaupt nicht ausgeführt werden. Einzelne Operationen sind atomar. Transaktionen mit mehreren Operationen können mithilfe der Anweisungen MULTI und EXEC implementiert werden, um die Atomizität sicherzustellen.
Weitere Funktionen – Redis unterstützt auch Veröffentlichungs-/Abonnementbenachrichtigungen, Schlüsselablauf und andere Funktionen.
Redis-Datentyp
Redis unterstützt 5 Datentypen: String (String), Hash (Hash), Liste (Liste), Set (Satz), Zset (sortierter Satz: geordneter Satz)
String
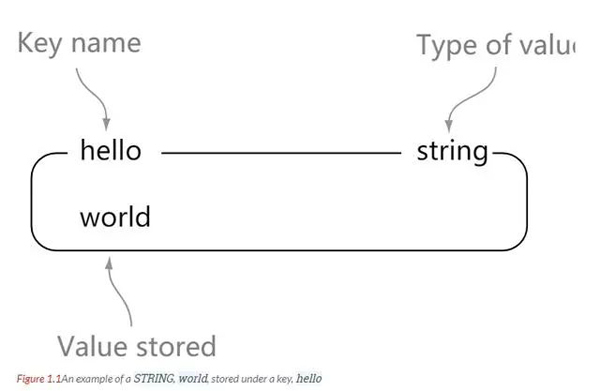
string ist der grundlegendste Datentyp von Redis. Ein Schlüssel entspricht einem Wert.
string ist binärsicher. Das heißt, die Zeichenfolge von Redis kann beliebige Daten enthalten. Zum Beispiel JPG-Bilder oder serialisierte Objekte.
Einer der grundlegenden Datentypen von Redis ist der String-Typ, und die Wertgröße des String-Typs kann bis zu 512 MB betragen.
Verstehen: Eine Zeichenfolge ist wie eine Karte in Java. Ein Schlüssel entspricht einem Wert. Redis-Hash ist eine Zuordnungstabelle von Schlüsseln und Werten vom Typ String. Hash eignet sich besonders zum Speichern von Objekten.
 Verstehen
Verstehen
und String
: String ist ein Schlüssel-Wert-Paar, während Hash aus mehreren Schlüssel-Wert-Paaren besteht.
127.0.0.1:6379> set hello world OK 127.0.0.1:6379> get hello "world"
listRedis-Listen sind einfache Listen von Zeichenfolgen, sortiert in der Einfügungsreihenfolge. Wir können Elemente links oder rechts von der Liste hinzufügen.
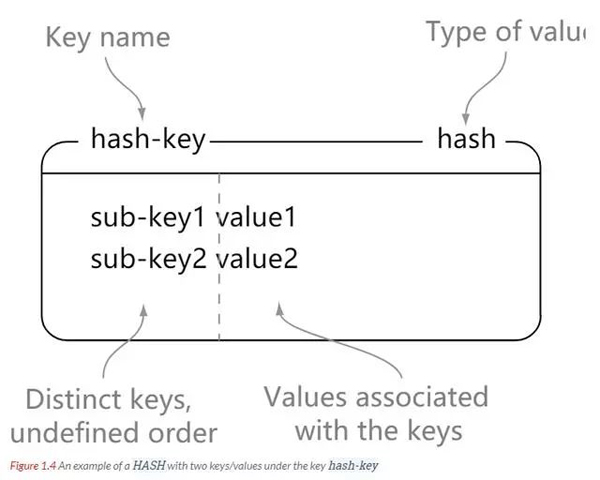
// hash-key 可以看成是一个键值对集合的名字,在这里分别为其添加了 sub-key1 : value1、 sub-key2 : value2、sub-key3 : value3 这三个键值对 127.0.0.1:6379> hset hash-key sub-key1 value1 (integer) 1 127.0.0.1:6379> hset hash-key sub-key2 value2 (integer) 1 127.0.0.1:6379> hset hash-key sub-key3 value3 (integer) 1 // 获取 hash-key 这个 hash 里面的所有键值对 127.0.0.1:6379> hgetall hash-key 1) "sub-key1" 2) "value1" 3) "sub-key2" 4) "value2" 5) "sub-key3" 6) "value3" // 删除 hash-key 这个 hash 里面的 sub-key2 键值对 127.0.0.1:6379> hdel hash-key sub-key2 (integer) 1 127.0.0.1:6379> hget hash-key sub-key2 (nil) 127.0.0.1:6379> hget hash-key sub-key1 "value1" 127.0.0.1:6379> hgetall hash-key 1) "sub-key1" 2) "value1" 3) "sub-key3" 4) "value3"
Wir können sehen, dass die Liste eine einfache Sammlung von Zeichenfolgen ist, die sich nicht wesentlich von der Liste in Java unterscheidet. Der Unterschied besteht darin, dass die Liste hier Zeichenfolgen speichert. Die Elemente in der Liste sind wiederholbar.
setredis‘ Set ist eine ungeordnete Sammlung von String-Typen. Da der Satz unter Verwendung der Datenstruktur einer Hash-Tabelle implementiert wird, beträgt die zeitliche Komplexität seiner Einfüge-, Lösch- und Suchvorgänge O(1). Der Satz von Redis unterscheidet sich etwas vom Satz in Java. 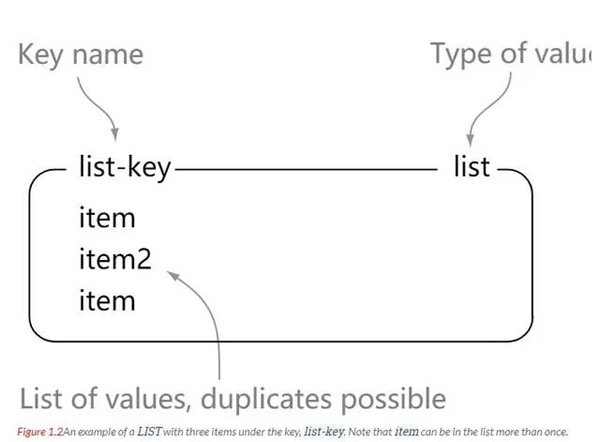
Zset
redis zset ist wie set eine Sammlung von Elementen vom Typ String, und die Elemente im Set können nicht wiederholt werden. Der Unterschied besteht darin, dass jedem Element in zset eine doppelte Typbewertung zugeordnet ist. Redis verwendet Scores, um die Mitglieder im Satz von klein nach groß zu sortieren. Die Elemente von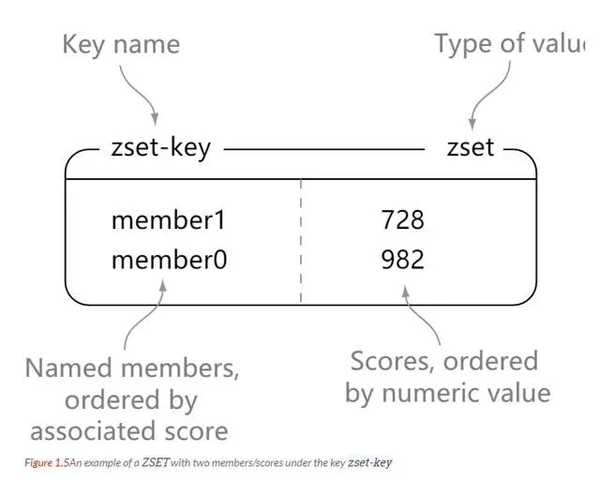 zset sind einzigartig, aber die Ergebnisse können wiederholt werden.
zset sind einzigartig, aber die Ergebnisse können wiederholt werden.
127.0.0.1:6379> rpush list-key v1 (integer) 1 127.0.0.1:6379> rpush list-key v2 (integer) 2 127.0.0.1:6379> rpush list-key v1 (integer) 3 127.0.0.1:6379> lrange list-key 0 -1 1) "v1" 2) "v2" 3) "v1" 127.0.0.1:6379> lindex list-key 1 "v2" 127.0.0.1:6379> lpop list (nil) 127.0.0.1:6379> lpop list-key "v1" 127.0.0.1:6379> lrange list-key 0 -1 1) "v2" 2) "v1"
Veröffentlichen und Abonnieren
Im Allgemeinen wird Redis nicht zum Veröffentlichen und Abonnieren von Nachrichten verwendet.Einführung
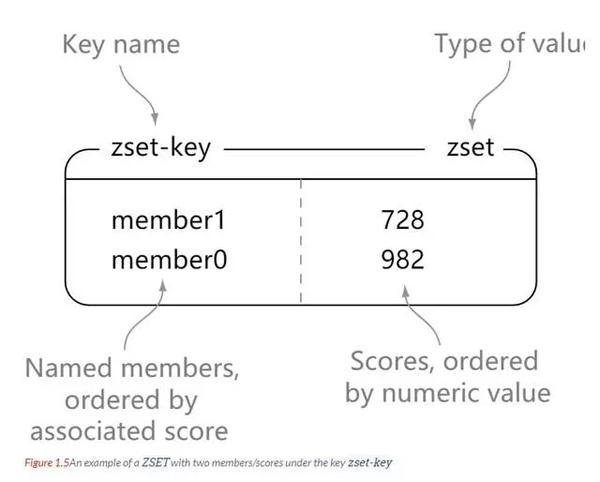 Redis Publish and Subscribe (Pub/Sub) ist ein Nachrichtenkommunikationsmodell: Der Absender (Pub) sendet Nachrichten und die Abonnenten (Sub) empfangen Nachrichten.
Redis Publish and Subscribe (Pub/Sub) ist ein Nachrichtenkommunikationsmodell: Der Absender (Pub) sendet Nachrichten und die Abonnenten (Sub) empfangen Nachrichten.
Redis-Kunden können beliebig viele Kanäle abonnieren.
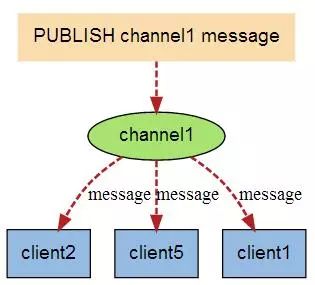
Die folgende Abbildung zeigt die Beziehung zwischen dem Kanal Kanal1 und den drei Clients, die diesen Kanal abonnieren – Client2, Client5 und Client1:
学Redis这篇就够了
当有新消息通过 PUBLISH 命令发送给频道 channel1 时, 这个消息就会被发送给订阅它的三个客户端:
学Redis这篇就够了
实例
以下实例演示了发布订阅是如何工作的。在我们实例中我们创建了订阅频道名为 redisChat:
127.0.0.1:6379> SUBsCRIBE redisChat Reading messages... (press Ctrl-C to quit) 1) "subscribe" 2) "redisChat"
现在,我们先重新开启个 redis 客户端,然后在同一个频道 redisChat 发布两次消息,订阅者就能接收到消息。
127.0.0.1:6379> PUBLISH redisChat "send message" (integer) 1 127.0.0.1:6379> PUBLISH redisChat "hello world" (integer) 1 # 订阅者的客户端显示如下 1) "message" 2) "redisChat" 3) "send message" 1) "message" 2) "redisChat" 3) "hello world"
事务
redis 事务一次可以执行多条命令,服务器在执行命令期间,不会去执行其他客户端的命令请求。
事务中的多条命令被一次性发送给服务器,而不是一条一条地发送,这种方式被称为流水线,它可以减少客户端与服务器之间的网络通信次数从而提升性能。
Redis 最简单的事务实现方式是使用 MULTI 和 EXEC 命令将事务操作包围起来。
批量操作在发送 EXEC 命令前被放入队列缓存。
在接收到 EXEC 命令后,进入事务执行。如果在事务中有命令执行失败,其他命令仍然会继续执行。也就是说 Redis 事务不保证原子性。
在事务执行过程中,其他客户端提交的命令请求不会插入到事务执行命令序列中。
一个事务从开始到执行会经历以下三个阶段:
开始事务。
命令入队。
执行事务。
实例
以下是一个事务的例子, 它先以 MULTI 开始一个事务, 然后将多个命令入队到事务中, 最后由 EXEC 命令触发事务, 一并执行事务中的所有命令:
redis 127.0.0.1:6379> MULTI OK redis 127.0.0.1:6379> SET book-name "Mastering C++ in 21 days" QUEUED redis 127.0.0.1:6379> GET book-name QUEUED redis 127.0.0.1:6379> SADD tag "C++" "Programming" "Mastering Series" QUEUED redis 127.0.0.1:6379> SMEMBERS tag QUEUED redis 127.0.0.1:6379> EXEC 1) OK 2) "Mastering C++ in 21 days" 3) (integer) 3 4) 1) "Mastering Series" 2) "C++" 3) "Programming"
单个 Redis 命令的执行是原子性的,但 Redis 没有在事务上增加任何维持原子性的机制,所以 Redis 事务的执行并不是原子性的。
事务可以理解为一个打包的批量执行脚本,但批量指令并非原子化的操作,中间某条指令的失败不会导致前面已做指令的回滚,也不会造成后续的指令不做。
这是官网上的说明 From redis docs on transactions:
It's important to note that even when a command fails, all the other commands in the queue are processed – Redis will not stop the processing of commands.
比如:
redis 127.0.0.1:7000> multi OK redis 127.0.0.1:7000> set a aaa QUEUED redis 127.0.0.1:7000> set b bbb QUEUED redis 127.0.0.1:7000> set c ccc QUEUED redis 127.0.0.1:7000> exec 1) OK 2) OK 3) OK
如果在 set b bbb 处失败,set a 已成功不会回滚,set c 还会继续执行。
Redis 事务命令
下表列出了 redis 事务的相关命令:
序号命令及描述:
1. DISCARD 取消事务,放弃执行事务块内的所有命令。
2. EXEC 执行所有事务块内的命令。
3. MULTI 标记一个事务块的开始。
4. UNWATCH 取消 WATCH 命令对所有 key 的监视。
5. WATCH key [key …]监视一个 (或多个) key ,如果在事务执行之前这个 (或这些) key 被其他命令所改动,那么事务将被打断。
持久化
Redis 是内存型数据库,为了保证数据在断电后不会丢失,需要将内存中的数据持久化到硬盘上。
RDB 持久化
将某个时间点的所有数据都存放到硬盘上。
可以将快照复制到其他服务器从而创建具有相同数据的服务器副本。
如果系统发生故障,将会丢失最后一次创建快照之后的数据。
如果数据量大,保存快照的时间会很长。
AOF 持久化
将写命令添加到 AOF 文件(append only file)末尾。
使用 AOF 持久化需要设置同步选项,从而确保写命令同步到磁盘文件上的时机。
这是因为对文件进行写入并不会马上将内容同步到磁盘上,而是先存储到缓冲区,然后由操作系统决定什么时候同步到磁盘。
选项同步频率always每个写命令都同步eyerysec每秒同步一次no让操作系统来决定何时同步
always 选项会严重减低服务器的性能
everysec 选项比较合适,可以保证系统崩溃时只会丢失一秒左右的数据,并且 Redis 每秒执行一次同步对服务器几乎没有任何影响。
no 选项并不能给服务器性能带来多大的提升,而且会增加系统崩溃时数据丢失的数量。
随着服务器写请求的增多,AOF 文件会越来越大。Redis提供了一项称作AOF重写的功能,能够消除AOF文件中的重复写入命令。
复制
Machen Sie einen Server zum Slave eines anderen Servers, indem Sie den Befehl „slaveof host port“ verwenden.
Ein Slave-Server kann nur einen Master-Server haben und die Master-Master-Replikation wird nicht unterstützt.
Verbindungsprozess
Der Master-Server erstellt eine Snapshot-Datei, also eine RDB-Datei, sendet sie an den Slave-Server und zeichnet während des Sendens die ausgeführten Schreibbefehle im Puffer auf.
Nachdem die Snapshot-Datei gesendet wurde, beginnen Sie mit dem Senden der im Puffer gespeicherten Schreibbefehle vom Server.
Der Slave-Server verwirft alle alten Daten, lädt die vom Master-Server gesendete Snapshot-Datei und dann beginnt der Slave-Server, Schreibbefehle vom Master-Server anzunehmen.
Jedes Mal, wenn der Master-Server einen Schreibbefehl ausführt, sendet er denselben Schreibbefehl an den Slave-Server.
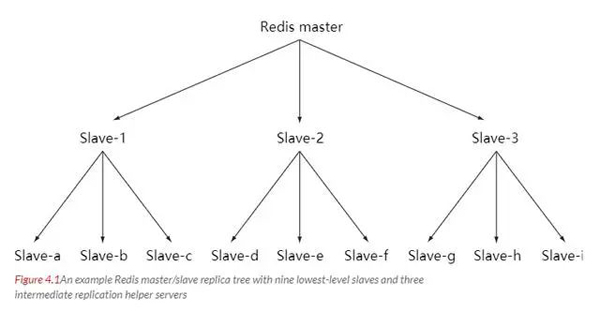
Master-Slave-Kette
Wenn die Last weiter zunimmt und der Master-Server nicht alle Slave-Server schnell aktualisieren oder die Slave-Server nicht erneut verbinden und synchronisieren kann, wird das System überlastet.
Um dieses Problem zu lösen, kann eine Zwischenschicht eingerichtet werden, um die Replikationsarbeitslast des Hauptservers zu reduzieren. Der Server der mittleren Ebene fungiert gleichzeitig als Slave-Server des Servers der oberen Ebene und als Master-Server des Servers der unteren Ebene.
Sentinel
Sentinel kann die Server im Cluster überwachen und automatisch einen neuen Master-Server aus den Slave-Servern auswählen, wenn der Master-Server offline geht.
Sharding
Sharding ist eine Methode zur Aufteilung von Daten in mehrere Teile. Mit dieser Methode kann bei der Lösung bestimmter Probleme eine lineare Leistungsverbesserung erzielt werden.
Angenommen, es gibt 4 Redis-Instanzen R0, R1, R2, R3 und es gibt viele Schlüssel, die die Benutzer user:1, user:2, … repräsentieren. Es gibt verschiedene Möglichkeiten, auszuwählen, in welcher Instanz ein bestimmter Schlüssel gespeichert wird.
Die einfachste Möglichkeit ist Range Sharding. Beispielsweise werden Benutzer-IDs von 0 bis 1000 in Instanz R0 gespeichert, Benutzer-IDs von 1001 bis 2000 in Instanz R1 und so weiter. Dies erfordert jedoch die Pflege einer Zuordnungsbereichstabelle, deren Pflege teuer ist.
Eine andere Möglichkeit ist das Hash-Sharding. Die zu speichernden Instanzen werden ermittelt, indem eine CRC32-Hash-Funktion auf dem Schlüssel ausgeführt, in eine Zahl umgewandelt und dann die Anzahl der Instanzen moduliert wird.
Je nachdem, wo das Sharding durchgeführt wird, kann es in drei Sharding-Methoden unterteilt werden:
Clientseitiges Sharding: Der Client verwendet Algorithmen wie konsistentes Hashing, um zu entscheiden, an welchen Knoten es verteilt werden soll.
Proxy-Sharding: Senden Sie die Anfrage des Clients an den Proxy, und der Proxy leitet sie an den richtigen Knoten weiter.
Server-Sharding: Redis-Cluster.
Das obige ist der detaillierte Inhalt vonWas sind die umfassenden Wissenspunkte von Redis?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Häufig verwendete Datenbanksoftware
Häufig verwendete Datenbanksoftware
 Was sind In-Memory-Datenbanken?
Was sind In-Memory-Datenbanken?
 Welches hat eine schnellere Lesegeschwindigkeit, Mongodb oder Redis?
Welches hat eine schnellere Lesegeschwindigkeit, Mongodb oder Redis?
 So verwenden Sie Redis als Cache-Server
So verwenden Sie Redis als Cache-Server
 Wie Redis die Datenkonsistenz löst
Wie Redis die Datenkonsistenz löst
 Wie stellen MySQL und Redis die Konsistenz beim doppelten Schreiben sicher?
Wie stellen MySQL und Redis die Konsistenz beim doppelten Schreiben sicher?
 Welche Daten speichert der Redis-Cache im Allgemeinen?
Welche Daten speichert der Redis-Cache im Allgemeinen?
 Was sind die 8 Datentypen von Redis?
Was sind die 8 Datentypen von Redis?









![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



