

Wie lautet die Syntax des MySQL-Index?


Indexdefinition
Ein Index ist eine geordnete Datenstruktur, die MySQL dabei hilft, Daten effizient zu erhalten. Dies ist MySQLs offizielle Definition eines Index. Zur Verbesserung der Abfrageeffizienz sind Indizes ein Mechanismus, der Feldern in Datenbanktabellen hinzugefügt wird. Zusätzlich zu den Daten verwaltet das Datenbanksystem auch Datenstrukturen, die bestimmte Suchalgorithmen erfüllen. Diese Datenstrukturen verweisen auf die Daten, sodass erweiterte Suchalgorithmen auf diesen Datenstrukturen implementiert werden können Index. Wie im Diagramm unten gezeigt:
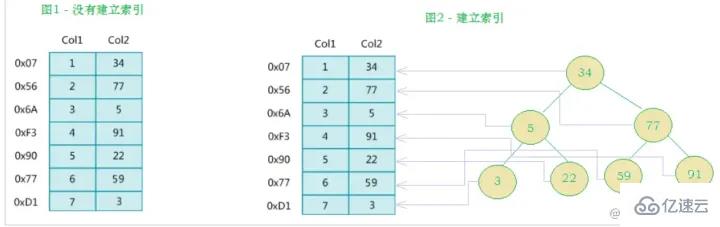
Tatsächlich ist ein Index, einfach ausgedrückt, eine sortierte Datenstruktur
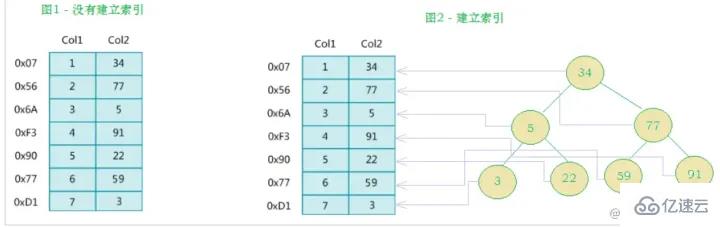
Die linke Seite ist die Datentabelle mit insgesamt zwei Spalten und sieben Datensätzen und die ganz linke Seite Eine davon ist die physische Struktur der Datensatzadresse (beachten Sie, dass logisch benachbarte Datensätze nicht unbedingt physisch benachbart auf der Festplatte liegen). Um die Suche nach Col2 zu beschleunigen, können Sie einen binären Suchbaum pflegen, wie rechts gezeigt. Jeder Knoten enthält einen Indexschlüsselwert und einen Zeiger auf die physische Adresse des entsprechenden Datensatzes Verwenden Sie die binäre Suche, um schnell an die entsprechenden Daten zu gelangen.
Indexvorteile
Beschleunigen Sie die Geschwindigkeit von Suchen und Sortieren, reduzieren Sie die E/A-Kosten der Datenbank und den CPU-Verbrauch
Durch die Erstellung eines eindeutigen Indexes können Sie die Einzigartigkeit jedes einzelnen Indexes sicherstellen Datenzeile in der Datenbanktabelle.
Nachteile des Index
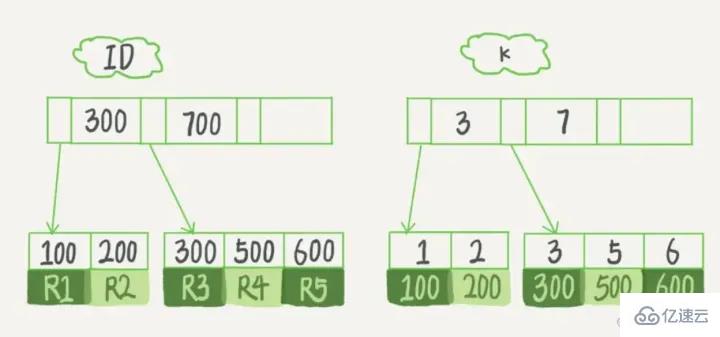
Der Index ist eigentlich eine Tabelle, die den Primärschlüssel und das Indexfeld speichert und auf den Datensatz der Entitätsklasse verweist.
Obwohl Es erhöht die Abfrageeffizienz. Jedes Mal, wenn die Tabelle geändert wird, muss der Index aktualisiert werden. Natürlich müssen neue Knoten zum Indexbaum hinzugefügt werden Der Indexbaum kann ungültig werden, was bedeutet, dass viele Knoten in diesem Indexbaum ungültig sind. Änderung: Der -Zeiger des Knotens im Indexbaum muss möglicherweise geändert werden
Tatsächlich verwenden wir ihn jedoch nicht binärer Suchbaum zum Speichern in MySQL Warum?
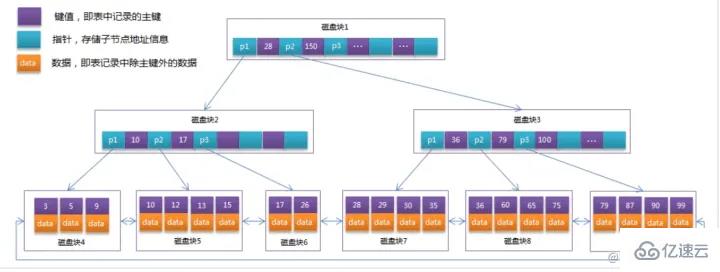
Sie müssen wissen, dass in einem binären Suchbaum ein Knoten hier nur ein Datenelement speichern kann und ein Knoten einem Festplattenblock in MySQL entspricht. Auf diese Weise können wir jedes Mal einen Festplattenblock lesen Um ein einzelnes Datenelement zu erhalten, ist die Effizienz besonders gering, daher werden wir darüber nachdenken, eine B-Baum-Struktur zu verwenden, um es zu speichern.
Indexstruktur
Indizes werden in der Speicher-Engine-Schicht von MySQL implementiert, nicht in der Serverschicht. Daher können sich die Indizes zwischen den Speicher-Engines unterscheiden und nicht alle Engines unterstützen alle Arten von Indizes.
BTREE-Index: Der häufigste Indextyp. Die meisten Indizes unterstützen B-Tree-Indizes.
HASH-Index: Wird nur von der Speicher-Engine unterstützt, das Nutzungsszenario ist einfach.
R-Baum-Index (räumlicher Index): Der räumliche Index ist ein spezieller Indextyp der MyISAM-Engine. Er wird hauptsächlich für Geodatentypen verwendet und wird nicht speziell eingeführt.
Volltext (Volltextindex): Der Volltextindex ist ebenfalls ein spezieller Indextyp von MyISAM, der hauptsächlich für den Volltextindex verwendet wird, beginnend mit der Mysql5.6-Version.
Die drei Speicher-Engines MyISAM, InnoDB und Memory unterstützen verschiedene Indextypen MEMORY-Engine
BTREE index |
Unterstützt |
Unterstützt |
Unterstützt |
||||||
HASH-Index |
Nicht unterstützt | Nicht unterstützt |
Unterstützt |
||||||
| R-Baum Index: Nicht unterstützt Unterstützt |
Nicht unterstützt |

 Im Vergleich zu binären Suchbäumen ist die Höhe/Tiefe geringer und die natürliche Abfrageeffizienz höher.
Im Vergleich zu binären Suchbäumen ist die Höhe/Tiefe geringer und die natürliche Abfrageeffizienz höher.  Blattknoten
Blattknoten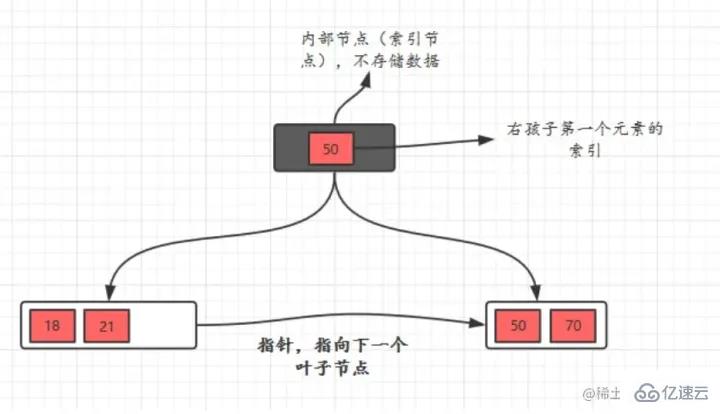
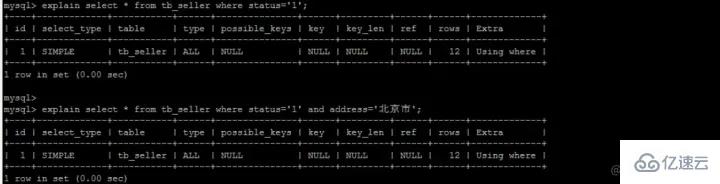
| 0 | # 🎜🎜#1# 🎜🎜# | 1 | # 🎜🎜#xiaomi2 | #🎜 🎜#
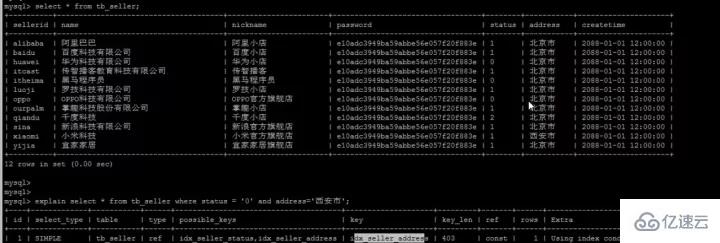
| 1 | #🎜 🎜# 2 | #🎜🎜 #我们执行这样一条语句: SELECT name FROM tb_seller WHERE name like '小米%' and status ='1' ; 复制代码 Nach dem Login kopieren
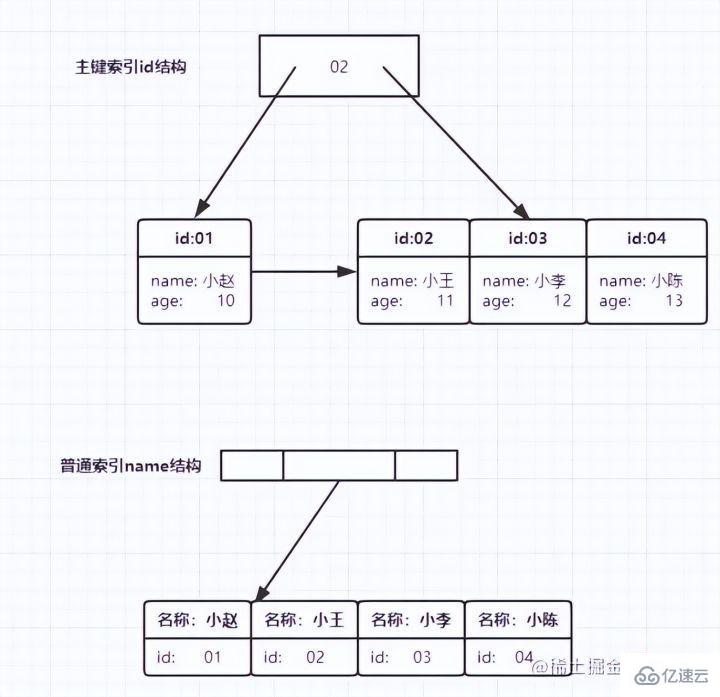
最左前缀原则所谓最左前缀,可以想象成一个爬楼梯的过程,假设我们有一个复合索引:name,status,address,那这个楼梯由低到高依次顺序是:name,status,address,最左前缀,要求我们不能出现跳跃楼梯的情况,否则会导致我们的索引失效:
这两个尽管where中字段的顺序不一样,第二个看起来越级了,但实际上效果是一样的
索引设计原则针对表
针对字段
其他原则
比如:
当我们where中根据status和address两个字段来查询时,数据库只会选择最优的一个索引,不会所有单列索引都使用。
创建复合索引: CREATE INDEX idx_name_email_status ON tb_seller(name,email,status); 就相当于 对name 创建索引 ; 对name , email 创建了索引 ; 对name , email, status 创建了索引 ; 复制代码 Nach dem Login kopieren 举个栗子假设我们有这么一个表,id为主键,没有创建索引: CREATE TABLE `tuser` ( `id` int(11) NOT NULL, `name` varchar(32) DEFAULT NULL, `age` int(11) DEFAULT NULL, PRIMARY KEY (`id`), ) ENGINE=InnoDB 复制代码 Nach dem Login kopieren 如果要在此处建立复合索引,我们要遵循什么原则呢? 通过调整顺序,可以少维护一个索引
如果我们建立索引(age,name),由于最左前缀原则,我们这个索引能实现的是根据age,根据age和name查询,并不能单纯根据name查询(因为跳跃了),为了实现我们的需求,我们还得再建立一个name索引; 而如果我们通过调整顺序,改成(name,age),就能实现我们的需求了,无需再维护一个name索引,这就是通过调整顺序,可以少维护一个索引。 考虑空间->短索引
我们有两种方案:
这两种方案都能实现我们的需求,这个时候我们就要考虑空间了,name字段是比age字段大的,显然方案1所耗费的空间是更小的,所以我们更倾向于方案1。 何时建立索引
何时达咩索引
索引相关语法创建索引
CREATE [UNIQUE|FULLTEXT|SPATIAL] INDEX index_name [USING index_type] ON tbl_name(index_col_name,...) index_col_name : column_name[(length)][ASC | DESC] 复制代码 Nach dem Login kopieren 查找索引
select index from tbl_name\G; 复制代码 Nach dem Login kopieren 删除索引drop INDEX index_name on tbl_name ; 复制代码 Nach dem Login kopieren 变更索引1). alter table tb_name add primary key(column_list); 该语句添加一个主键,这意味着索引值必须是唯一的,且不能为NULL 2). alter table tb_name add unique index_name(column_list); 这条语句创建索引的值必须是唯一的(除了NULL外,NULL可能会出现多次) 3). alter table tb_name add index index_name(column_list); 添加普通索引, 索引值可以出现多次。 4). alter table tb_name add fulltext index_name(column_list); 该语句指定了索引为FULLTEXT, 用于全文索引 复制代码 Nach dem Login kopieren 查看索引使用情况show status like 'Handler_read%'; -- 查看当前会话索引使用情况 show global status like 'Handler_read%'; -- 查看全局索引使用情况 复制代码 Nach dem Login kopieren Handler_read_first:索引中第一条被读的次数。如果较高,表示服务器正执行大量全索引扫描(这个值越低越好)。 Handler_read_key:如果索引正在工作,这个值代表一个行被索引值读的次数,如果值越低,表示索引得到的性能改善不高,因为索引不经常使用(这个值越高越好)。 Handler_read_next :按照键顺序读下一行的请求数。如果你用范围约束或如果执行索引扫描来查询索引列,该值增加。 Handler_read_prev:按照键顺序读前一行的请求数。该读方法主要用于优化ORDER BY ... DESC。 Handler_read_rnd :根据固定位置读一行的请求数。如果你正执行大量查询并需要对结果进行排序该值较高。你可能使用了大量需要MySQL扫描整个表的查询或你的连接没有正确使用键。这个值较高,意味着运行效率低,应该建立索引来补救。 Handler_read_rnd_next:在数据文件中读下一行的请求数。如果你正进行大量的表扫描,该值较高。通常说明你的表索引不正确或写入的查询没有利用索引。 |


Das obige ist der detaillierte Inhalt vonWie lautet die Syntax des MySQL-Index?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 Wie man phpmyadmin öffnet
Apr 10, 2025 pm 10:51 PM
Wie man phpmyadmin öffnet
Apr 10, 2025 pm 10:51 PM
Sie können PhpMyAdmin in den folgenden Schritten öffnen: 1. Melden Sie sich beim Website -Bedienfeld an; 2. Finden und klicken Sie auf das Symbol phpmyadmin. 3. Geben Sie MySQL -Anmeldeinformationen ein; 4. Klicken Sie auf "Login".
 MySQL: Eine Einführung in die beliebteste Datenbank der Welt
Apr 12, 2025 am 12:18 AM
MySQL: Eine Einführung in die beliebteste Datenbank der Welt
Apr 12, 2025 am 12:18 AM
MySQL ist ein Open Source Relational Database Management -System, das hauptsächlich zum schnellen und zuverlässigen Speicher und Abrufen von Daten verwendet wird. Sein Arbeitsprinzip umfasst Kundenanfragen, Abfragebedingungen, Ausführung von Abfragen und Rückgabergebnissen. Beispiele für die Nutzung sind das Erstellen von Tabellen, das Einsetzen und Abfragen von Daten sowie erweiterte Funktionen wie Join -Operationen. Häufige Fehler umfassen SQL -Syntax, Datentypen und Berechtigungen sowie Optimierungsvorschläge umfassen die Verwendung von Indizes, optimierte Abfragen und die Partitionierung von Tabellen.
 Mysqls Platz: Datenbanken und Programmierung
Apr 13, 2025 am 12:18 AM
Mysqls Platz: Datenbanken und Programmierung
Apr 13, 2025 am 12:18 AM
Die Position von MySQL in Datenbanken und Programmierung ist sehr wichtig. Es handelt sich um ein Open -Source -Verwaltungssystem für relationale Datenbankverwaltung, das in verschiedenen Anwendungsszenarien häufig verwendet wird. 1) MySQL bietet effiziente Datenspeicher-, Organisations- und Abruffunktionen und unterstützt Systeme für Web-, Mobil- und Unternehmensebene. 2) Es verwendet eine Client-Server-Architektur, unterstützt mehrere Speichermotoren und Indexoptimierung. 3) Zu den grundlegenden Verwendungen gehören das Erstellen von Tabellen und das Einfügen von Daten, und erweiterte Verwendungen beinhalten Multi-Table-Verknüpfungen und komplexe Abfragen. 4) Häufig gestellte Fragen wie SQL -Syntaxfehler und Leistungsprobleme können durch den Befehl erklären und langsam abfragen. 5) Die Leistungsoptimierungsmethoden umfassen die rationale Verwendung von Indizes, eine optimierte Abfrage und die Verwendung von Caches. Zu den Best Practices gehört die Verwendung von Transaktionen und vorbereiteten Staten
 Warum MySQL verwenden? Vorteile und Vorteile
Apr 12, 2025 am 12:17 AM
Warum MySQL verwenden? Vorteile und Vorteile
Apr 12, 2025 am 12:17 AM
MySQL wird für seine Leistung, Zuverlässigkeit, Benutzerfreundlichkeit und Unterstützung der Gemeinschaft ausgewählt. 1.MYSQL bietet effiziente Datenspeicher- und Abruffunktionen, die mehrere Datentypen und erweiterte Abfragevorgänge unterstützen. 2. Übernehmen Sie die Architektur der Client-Server und mehrere Speichermotoren, um die Transaktion und die Abfrageoptimierung zu unterstützen. 3. Einfach zu bedienend unterstützt eine Vielzahl von Betriebssystemen und Programmiersprachen. V.
 So stellen Sie eine Verbindung zur Datenbank von Apache her
Apr 13, 2025 pm 01:03 PM
So stellen Sie eine Verbindung zur Datenbank von Apache her
Apr 13, 2025 pm 01:03 PM
Apache verbindet eine Verbindung zu einer Datenbank erfordert die folgenden Schritte: Installieren Sie den Datenbanktreiber. Konfigurieren Sie die Datei web.xml, um einen Verbindungspool zu erstellen. Erstellen Sie eine JDBC -Datenquelle und geben Sie die Verbindungseinstellungen an. Verwenden Sie die JDBC -API, um über den Java -Code auf die Datenbank zuzugreifen, einschließlich Verbindungen, Erstellen von Anweisungen, Bindungsparametern, Ausführung von Abfragen oder Aktualisierungen und Verarbeitungsergebnissen.
 So starten Sie MySQL von Docker
Apr 15, 2025 pm 12:09 PM
So starten Sie MySQL von Docker
Apr 15, 2025 pm 12:09 PM
Der Prozess des Startens von MySQL in Docker besteht aus den folgenden Schritten: Ziehen Sie das MySQL -Image zum Erstellen und Starten des Containers an, setzen
 MySQLs Rolle: Datenbanken in Webanwendungen
Apr 17, 2025 am 12:23 AM
MySQLs Rolle: Datenbanken in Webanwendungen
Apr 17, 2025 am 12:23 AM
Die Hauptaufgabe von MySQL in Webanwendungen besteht darin, Daten zu speichern und zu verwalten. 1.Mysql verarbeitet effizient Benutzerinformationen, Produktkataloge, Transaktionsunterlagen und andere Daten. 2. Durch die SQL -Abfrage können Entwickler Informationen aus der Datenbank extrahieren, um dynamische Inhalte zu generieren. 3.Mysql arbeitet basierend auf dem Client-Server-Modell, um eine akzeptable Abfragegeschwindigkeit sicherzustellen.
 CentOS installieren MySQL
Apr 14, 2025 pm 08:09 PM
CentOS installieren MySQL
Apr 14, 2025 pm 08:09 PM
Die Installation von MySQL auf CentOS umfasst die folgenden Schritte: Hinzufügen der entsprechenden MySQL Yum -Quelle. Führen Sie den Befehl mySQL-server aus, um den MySQL-Server zu installieren. Verwenden Sie den Befehl mySQL_SECURE_INSTALLATION, um Sicherheitseinstellungen vorzunehmen, z. B. das Festlegen des Stammbenutzerkennworts. Passen Sie die MySQL -Konfigurationsdatei nach Bedarf an. Tune MySQL -Parameter und optimieren Sie Datenbanken für die Leistung.
