

Groß angelegte Sprachmodelle wie GPT und PaLM werden immer besser in der Lage, Aufgaben wie Mathematik, Symbolik, gesunden Menschenverstand und wissensbasiertes Denken zu bewältigen. Es überrascht vielleicht, dass die Grundlage all dieser Fortschritte der ursprüngliche autoregressive Mechanismus zur Textgenerierung bleibt. Es trifft Entscheidungen Token für Token und generiert Text von links nach rechts. Reicht ein so einfacher Mechanismus aus, um ein Sprachmodell für einen allgemeinen Problemlöser zu erstellen? Wenn nicht, welche Probleme werden das aktuelle Paradigma in Frage stellen und welche alternativen Mechanismen sollten eingesetzt werden?
Die Literatur zur menschlichen Kognition bietet einige Hinweise zur Beantwortung dieser Fragen. Untersuchungen zum „dualen Prozess“-Modell zeigen, dass Menschen zwei Modi haben, wenn sie Entscheidungen treffen: einen schnellen, automatischen und unbewussten Modus (System 1) und den anderen einen langsamen, bewussten und bewussten Modus (System 2). . Diese beiden Muster wurden zuvor mit verschiedenen mathematischen Modellen in Verbindung gebracht, die beim maschinellen Lernen verwendet werden. In der Forschung zum verstärkenden Lernen bei Menschen und anderen Tieren wird beispielsweise untersucht, ob sie assoziatives „modellfreies“ Lernen oder eine bewusstere „modellbasierte“ Planung betreiben. Die einfache assoziative Auswahl von Sprachmodellen auf Token-Ebene ähnelt auch „System 1“ und kann daher von der Verbesserung eines durchdachteren „System 2“-Planungsprozesses profitieren, der mehrere Alternativen zur aktuellen Auswahl verwaltet und untersucht und nicht nur eine auswählt . Darüber hinaus bewertet es seinen aktuellen Status und blickt aktiv nach vorne oder zurück, um globalere Entscheidungen zu treffen.
Um einen solchen Planungsprozess zu entwerfen, entschieden sich Forscher der Princeton University und von Google DeepMind, zunächst auf die Ursprünge der künstlichen Intelligenz (und der Kognitionswissenschaft) zurückzublicken und aus dem von Newell, Shaw und Simon untersuchten Planungsprozess zu lernen die 1950er Jahre. Newell und Kollegen beschreiben Problemlösung als Suche in einem kombinatorischen Problemraum, der als Baum dargestellt wird. Daher schlugen sie ein Tree of Thought (ToT)-Framework vor, das an Sprachmodelle zur allgemeinen Problemlösung angepasst ist.

Papierlink: https://arxiv.org/pdf/2305.10601.pdf
Projektadresse: https://github.com/ysymyth/tree-of -thought-llm
Wie in Abbildung 1 gezeigt, lösen bestehende Methoden das Problem durch Abtasten kontinuierlicher Sprachsequenzen, während ToT aktiv einen Gedankenbaum pflegt, in dem jeder Gedanke eine kohärente Sprachsequenz als Zwischenschritte bei der Problemlösung darstellt (Tabelle 1).
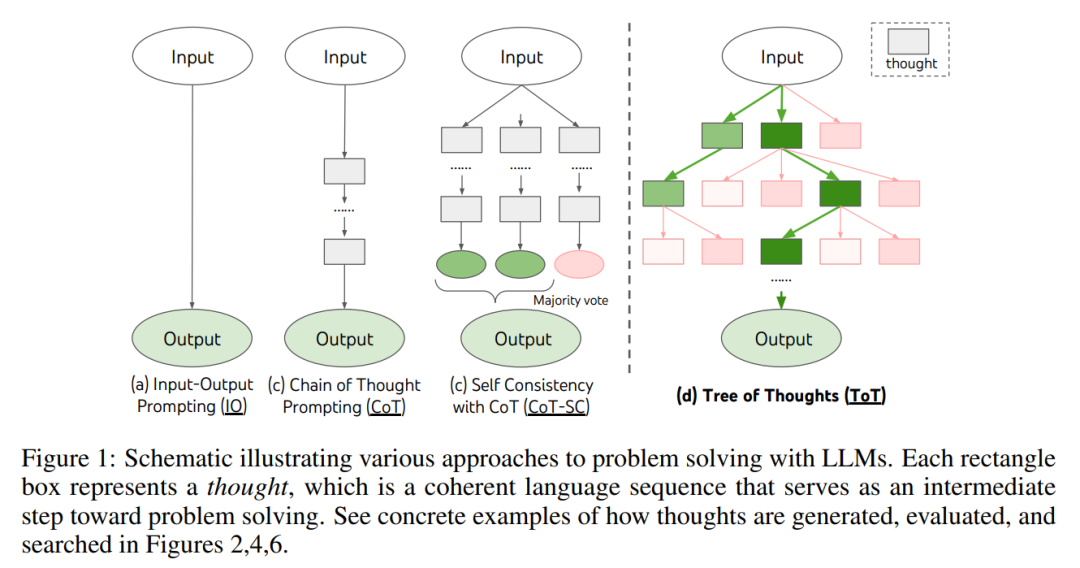

Eine solche semantische Einheit auf hoher Ebene ermöglicht es LM, den Beitrag verschiedener Zwischengedanken zum Fortschritt der Problemlösung durch einen durchdachten Argumentationsprozess selbst zu bewerten (Abbildungen 2, 4, 6) . Die Implementierung von Suchheuristiken durch LM-Selbstbewertung und -Deliberation ist ein neuartiger Ansatz, da frühere Suchheuristiken entweder programmiert oder erlernt wurden.


Schließlich kombinierten die Forscher diese sprachbasierte Fähigkeit, vielfältige Gedanken zu generieren und auszuwerten, mit Suchalgorithmen wie der Breadth-First Search (BFS) oder der Depth-First Search (DFS). ) ermöglichen diese Algorithmen die systematische Erforschung von Denkbäumen mit Möglichkeiten zur Vorwärts- und Rückverfolgung.
In der experimentellen Phase stellten die Forscher drei Aufgaben, nämlich 24-Punkte-Spiel, kreatives Schreiben und Kreuzworträtsel (Tabelle 1). Diese Probleme stellen selbst für bestehende LM-Inferenzmethoden eine große Herausforderung dar GPT-4. Diese Aufgaben erfordern deduktives, mathematisches, allgemeines Wissen, lexikalisches Denken und die Möglichkeit, systematische Planung oder Suche einzubeziehen. Experimentelle Ergebnisse zeigen, dass ToT bei diesen drei Aufgaben überlegene Ergebnisse erzielt, da es vielseitig und flexibel genug ist, um unterschiedliche Denkebenen, unterschiedliche Arten der Denkgenerierung und -bewertung zu unterstützen und sich an unterschiedliche Arten von Problemen anzupassen. Durch systematische experimentelle Ablationsanalysen untersuchen die Autoren auch, wie sich diese Entscheidungen auf die Modellleistung auswirken, und diskutieren zukünftige Richtungen für das Training und die Verwendung von LMs.
Ein echter Problemlösungsprozess beinhaltet die iterative Verwendung verfügbarer Informationen, um eine Erkundung zu initiieren, die weitere Informationen enthüllt, bis sie schließlich entdeckt wird ein Weg zu einer Lösung. —— Newell et al.
Untersuchungen zur menschlichen Problemlösung zeigen, dass Menschen Probleme lösen, indem sie einen kombinatorischen Problemraum durchsuchen. Dies kann als Baum betrachtet werden, in dem Knoten Teillösungen darstellen und Zweige Operatoren entsprechen, die sie ändern. Welcher Zweig ausgewählt wird, wird durch Heuristiken bestimmt, die dabei helfen, sich im Problemraum zurechtzufinden und den Problemlöser in Richtung der Lösung zu führen. Diese Perspektive verdeutlicht zwei wesentliche Mängel bestehender Ansätze, die Sprachmodelle zur Lösung allgemeiner Probleme verwenden: 1) Lokal erforschen sie nicht unterschiedliche Fortsetzungen im Denkprozess – Zweige des Baums. 2) Im Großen und Ganzen beinhalten sie keinerlei Planung, Vorausschauen oder Zurückverfolgen, um diese verschiedenen Optionen zu bewerten – die Art heuristisch geführter Suche, die das Lösen menschlicher Probleme zu charakterisieren scheint.
Um diese Probleme zu lösen, führte der Autor den Denkbaum (ToT) ein, ein Paradigma, das es dem Sprachmodell ermöglicht, mehrere Argumentationsmethoden für das Denken zu untersuchen Pfad (Abbildung 1(c)). ToT stellt jedes Problem als eine Suche in einem Baum dar, wobei jeder Knoten ein Zustand s = [x, z_1・・・i] ist, der eine Teillösung mit Eingaben und einer Folge von bisherigen Gedanken darstellt. Zu den konkreten Beispielen für ToT gehört die Beantwortung der folgenden vier Fragen:
3. Zustandsbewerter V (p_θ, S). Anhand der Grenzen verschiedener Staaten bewertet der Staatenbewerter deren Fortschritte bei der Lösung des Problems, um zu bestimmen, welche Staaten weiterhin erkundet werden sollten und in welcher Reihenfolge. Während Heuristiken eine Standardmethode zur Lösung von Suchproblemen sind, sind sie oft entweder programmatisch (z. B. DeepBlue) oder erlernt (z. B. AlphaGo). In diesem Artikel wird eine dritte Alternative vorgeschlagen, nämlich die Verwendung von Sprache, um absichtlich über Zustände nachzudenken. Gegebenenfalls können solche durchdachten Heuristiken flexibler sein als Programmierregeln und effizienter als Lernmodelle.
Betrachten Sie ähnlich wie beim Gedankengenerator zwei Strategien zur Bewertung von Zuständen einzeln oder zusammen:
# 🎜 🎜# (1) Bewerten Sie jeden Bundesstaat unabhängig
(2) Abstimmung zwischen Bundesstaaten
4. Suchalgorithmus. Schließlich ist es innerhalb des ToT-Frameworks möglich, verschiedene Suchalgorithmen basierend auf der Baumstruktur per Plug-and-Play einzusetzen. Dieser Artikel untersucht zwei relativ einfache Suchalgorithmen und überlässt fortgeschrittenere Algorithmen der zukünftigen Forschung:
Konzeptionell hat ToT als Sprachmodellansatz zur Lösung allgemeiner Probleme mehrere Vorteile:
24-Punkte-Mathe-Spiel
Die Spieler brauchen vier Zahlen diese vier Zahlen und grundlegende mathematische Operationssymbole (Pluszeichen, Minuszeichen, Multiplikationszeichen, Divisionszeichen) innerhalb einer begrenzten Zeit zu verwenden, um einen Ausdruck zu erstellen, der 24 ergibt. Wenn beispielsweise die Zahlen 4, 6, 8, 2 gegeben sind, ist eine mögliche Lösung: (8 ÷ (4 - 2)) × 6 = 24.
Wie in Tabelle 2 gezeigt, erbrachte die Verwendung von IO-, CoT- und CoT-SC-Eingabemethoden eine schlechte Leistung bei der Aufgabe und erreichte nur eine Erfolgsquote von 7,3 %, 4,0 % und 9,0 % . Im Vergleich dazu hat ToT mit b(Breite) = 1 eine Erfolgsquote von 45 % erreicht, mit b = 5 erreicht sie 74 %. Sie berücksichtigten auch die Oracle-Einstellung von IO/CoT, um die Erfolgsquote zu berechnen, indem sie den besten Wert unter k Stichproben (1 ≤ k ≤ 100) verwendeten.
Um IO/CoT (k beste Ergebnisse) mit ToT zu vergleichen, erwogen die Forscher, die Anzahl der in jeder Aufgabe besuchten Baumknoten in ToT zu zählen, wobei b = 1 bis 5, und die 5 Erfolgsraten sind in Abbildung 3 (a) dargestellt, wobei IO/CoT (k beste Ergebnisse) als Besuch von k Knoten im Spielautomaten betrachtet werden. Es überrascht nicht, dass CoT skalierbarer ist als IO und die besten 100 CoT-Beispiele eine Erfolgsquote von 49 % erreichten, was immer noch weitaus weniger ist als die Erkundung von mehr Knoten in ToT (b > 1).
 Bild 3 (b) unten Zerlegt die Situation von CoT- und ToT-Stichproben, wenn die Aufgabe fehlschlägt. Bemerkenswert ist, dass etwa 60 % der CoT-Stichproben bereits nach dem ersten Schritt der Generierung fehlschlugen, was der Generierung der ersten drei Wörter entspricht (z. B. „4 + 9“). Dies macht das Problem der direkten Decodierung von links nach rechts noch deutlicher. kreatives Schreiben
Bild 3 (b) unten Zerlegt die Situation von CoT- und ToT-Stichproben, wenn die Aufgabe fehlschlägt. Bemerkenswert ist, dass etwa 60 % der CoT-Stichproben bereits nach dem ersten Schritt der Generierung fehlschlugen, was der Generierung der ersten drei Wörter entspricht (z. B. „4 + 9“). Dies macht das Problem der direkten Decodierung von links nach rechts noch deutlicher. kreatives Schreiben
Die Forscher erfanden außerdem eine kreative Schreibaufgabe, indem sie vier zufällige Sätze eingaben und einen zusammenhängenden Artikel mit vier Absätzen ausgab, wobei jeder Absatz mit 4 Eingaben begann Satzenden. Solche Aufgaben sind ergebnisoffen und explorativ und fordern kreatives Denken und Planung auf hohem Niveau heraus.
Abbildung 5 (a) unten zeigt die durchschnittliche Punktzahl von GPT-4 in 100 Aufgaben, wobei ToT (7,56) besser ist als IO (6,19) und CoT (6,93). ) ) führt zu kohärenteren Absätzen. Obwohl solche automatischen Messungen verrauscht sein können, bestätigt Abbildung 5(b), dass Menschen bei 41 von 100 Durchgangspaaren ToT gegenüber CoT bevorzugen, während nur 21 Paare CoT gegenüber ToT bevorzugen (die anderen 38 Paare wurden als „ähnlich kohärent“ befunden). Schließlich erzielte der iterative Optimierungsalgorithmus bessere Ergebnisse bei dieser Aufgabe in natürlicher Sprache, wobei der IO-Konsistenzwert von 6,19 auf 7,67 und der ToT-Konsistenzwert von 7,56 auf 7,91 stiegen. Die Forscher glauben, dass dies als dritte Methode der Denkgenerierung im ToT-Framework angesehen werden kann. Neues Denken kann durch die Verfeinerung alten Denkens und nicht durch sequentielle Generierung generiert werden. #🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜#mini fill Wortspiel Beim „24-Punkte-Mathe-Spiel“ und kreativem Schreiben ist ToT relativ einfach – es sind bis zu 3 Denkschritte erforderlich, um das endgültige Ergebnis zu erzielen . Forscher werden das 5×5 Mini-Kreuzworträtsel als schwierigere Ebene von Suchfragen zur natürlichen Sprache untersuchen. Auch dieses Mal besteht das Ziel nicht nur darin, die Aufgabe zu lösen, da allgemeine Kreuzworträtsel leicht durch eine spezielle NLP-Pipeline gelöst werden können, die groß angelegten Abruf anstelle von LM nutzt. Stattdessen zielen Forscher darauf ab, die Grenzen eines Sprachmodells als allgemeiner Problemlöser zu erkunden, sein eigenes Denken zu erforschen und rigoroses Denken als Heuristik zu verwenden, um seine Erforschung zu leiten.


Das obige ist der detaillierte Inhalt vonDenken, denken, denken ohne anzuhalten, Thinking Tree ToT „Military Training' LLM. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Einführung in die Verwendung von vscode
Einführung in die Verwendung von vscode
 So legen Sie ein PPT-Hintergrundbild fest
So legen Sie ein PPT-Hintergrundbild fest
 Fünf Hauptkomponenten eines von Neumann-Computers
Fünf Hauptkomponenten eines von Neumann-Computers
 So spielen Sie Videos mit Python ab
So spielen Sie Videos mit Python ab
 So verwenden Sie den Fragezeichenausdruck in der C-Sprache
So verwenden Sie den Fragezeichenausdruck in der C-Sprache
 C#-Task-Nutzung
C#-Task-Nutzung
 So konvertieren Sie das WAV-Format
So konvertieren Sie das WAV-Format
 Zweck des Zugriffs auf die Datenbank
Zweck des Zugriffs auf die Datenbank








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



