

Herz der Maschinensäule
Heart of Machine-Redaktion
Die Erfolgsquote von KI-Betrug ist sehr hoch. Vor ein paar Tagen war „4,3 Millionen Betrüger in 10 Minuten“ ein heißes Suchthema. Aufbauend auf dem angesagtesten großen Sprachmodell haben Forscher kürzlich eine Erkennungsmethode erforscht.
Mit der kontinuierlichen Weiterentwicklung großer generativer Modelle nähert sich der von ihnen generierte Korpus allmählich dem des Menschen an. Obwohl große Modelle die Hände unzähliger Angestellter befreien, wurde ihre mächtige Fähigkeit, gefälschte Modelle zu fälschen, auch von einigen Kriminellen genutzt, was zu einer Reihe sozialer Probleme führte:



Forscher der Peking-Universität und Huawei haben einen zuverlässigen Textdetektor zur Identifizierung verschiedener KI-generierter Korpora vorgeschlagen. Entsprechend den unterschiedlichen Merkmalen langer und kurzer Texte wird eine mehrskalige KI-generierte Textdetektor-Trainingsmethode basierend auf PU-Lernen vorgeschlagen. Durch die Verbesserung des Detektortrainingsprozesses können unter denselben Bedingungen erhebliche Verbesserungen der Erkennungsfähigkeiten für lange und kurze ChatGPT-Körper erzielt werden, wodurch das Problem der geringen Genauigkeit der Kurztexterkennung durch aktuelle Detektoren gelöst wird.

Papieradresse:
https://arxiv.org/abs/2305.18149
Codeadresse (MindSpore):
https://github.com/mindspore-lab/mindone/tree/master/examples/detect_chatgpt
Codeadresse (PyTorch):
https://github.com/YuchuanTian/AIGC_text_detector
Zitat
Da die Generierungseffekte großer Sprachmodelle immer realistischer werden, benötigen verschiedene Branchen dringend einen zuverlässigen KI-generierten Textdetektor. Allerdings stellen verschiedene Branchen unterschiedliche Anforderungen an das Erkennungskorpus. Im akademischen Bereich müssen beispielsweise große und vollständige akademische Texte auf sozialen Plattformen erkannt werden. Bestehende Detektoren können jedoch häufig verschiedene Anforderungen nicht erfüllen. Beispielsweise verfügen einige gängige KI-Textdetektoren im Allgemeinen über schlechte Vorhersagefähigkeiten für kürzere Korpusse.
In Bezug auf die unterschiedlichen Erkennungseffekte von Korpus unterschiedlicher Länge stellt der Autor fest, dass kürzere KI-generierte Texte eine gewisse „Unsicherheit“ in ihrer Zuschreibung aufweisen können, oder um es deutlicher auszudrücken: Einige KI-generierte kurze Sätze werden auch häufig von Menschen verwendet . Daher ist es schwierig zu definieren, ob der von KI generierte Kurztext von Menschen oder von KI stammt. Hier sind ein paar Beispiele dafür, wie Menschen und KI die gleiche Frage beantworten:

Aus diesen Beispielen geht hervor, dass es schwierig ist, von KI generierte kurze Antworten zu identifizieren: Der Unterschied zwischen dieser Art von Korpus und Menschen ist zu gering und es ist schwierig, seine wahren Eigenschaften genau zu beurteilen. Daher ist es unangemessen, kurze Texte einfach als Mensch/KI zu kommentieren und die Texterkennung gemäß herkömmlichen binären Klassifizierungsproblemen durchzuführen.
Als Reaktion auf dieses Problem wandelt diese Studie den Teil zur Erkennung binärer Klassifizierungen von Mensch und KI in ein partielles PU-Lernproblem (Positiv-Unbeschriftet) um, d. h. in kürzeren Sätzen ist die menschliche Sprache positiv (Positiv) und die Maschinensprache ist die unbeschriftete Klasse (Unbeschriftet), was die Trainingsverlustfunktion verbessert. Diese Verbesserung verbessert die Klassifizierungsleistung des Detektors für verschiedene Korpora erheblich.
Details zum Algorithmus
Unter der traditionellen PU-Lerneinstellung kann ein binäres Klassifizierungsmodell nur auf der Grundlage positiver Trainingsproben und unbeschrifteter Trainingsproben lernen. Eine häufig verwendete PU-Lernmethode besteht darin, den binären Klassifizierungsverlust entsprechend negativen Stichproben durch die Formulierung des PU-Verlusts abzuschätzen:
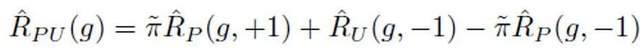
Darunter stellt es den binären Klassifizierungsverlust dar, der durch die Annahme aller nicht markierten Proben als negative Etiketten berechnet wird; stellt den binären Klassifizierungsverlust dar, der durch die Annahme positiver Proben als negative Etiketten berechnet wird; Die Wahrscheinlichkeit positiver Proben ist der geschätzte Anteil positiver Proben an allen PU-Proben. Beim traditionellen PU-Lernen wird der Prior normalerweise auf einen festen Hyperparameter gesetzt. Im Texterkennungsszenario muss der Detektor jedoch verschiedene Texte unterschiedlicher Länge verarbeiten. Bei Texten unterschiedlicher Länge ist auch der geschätzte Anteil positiver Stichproben unter allen PU-Stichproben unterschiedlich. Daher verbessert diese Studie den PU-Verlust und schlägt eine längenabhängige mehrskalige PU-Verlustfunktion (MPU) vor.
In dieser Studie wird insbesondere ein abstraktes wiederkehrendes Modell zur Modellierung der Erkennung kürzerer Texte vorgeschlagen. Wenn traditionelle NLP-Modelle Sequenzen verarbeiten, haben sie normalerweise eine Markov-Kettenstruktur wie RNN, LSTM usw. Der Prozess dieser Art von zyklischem Modell kann normalerweise als schrittweise iterativer Prozess verstanden werden, d. h. die Vorhersage jeder Token-Ausgabe wird durch Transformieren und Zusammenführen der Vorhersageergebnisse des vorherigen Tokens und der vorherigen Sequenz mit den Vorhersageergebnissen davon erhalten Token. Das ist der folgende Prozess:
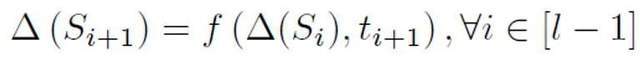
Um die A-priori-Wahrscheinlichkeit auf der Grundlage dieses abstrakten Modells abzuschätzen, muss davon ausgegangen werden, dass die Ausgabe des Modells das Vertrauen ist, dass ein bestimmter Satz positiv ist, d eine Person. Es wird davon ausgegangen, dass die Beitragsgröße jedes Tokens das umgekehrte Verhältnis zur Länge des Satztokens ist, positiv ist, dh unbeschriftet ist und die Wahrscheinlichkeit, unbeschriftet zu sein, viel größer ist als die Wahrscheinlichkeit, positiv zu sein. Denn wenn sich das Vokabular großer Modelle allmählich dem des Menschen annähert, werden die meisten Wörter sowohl in KI- als auch in menschlichen Korpora auftauchen. Basierend auf diesem vereinfachten Modell und der festgelegten positiven Token-Wahrscheinlichkeit wird die endgültige vorherige Schätzung erhalten, indem die Gesamterwartung der Modellausgabekonfidenz unter verschiedenen Eingabebedingungen ermittelt wird.
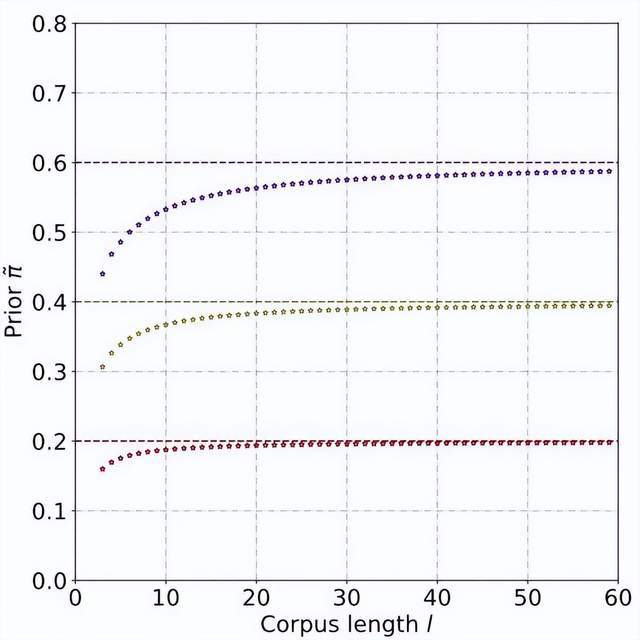
Durch theoretische Ableitungen und Experimente wird geschätzt, dass die A-priori-Wahrscheinlichkeit mit zunehmender Textlänge zunimmt und sich schließlich stabilisiert. Dieses Phänomen ist ebenfalls zu erwarten, da der Detektor mit zunehmender Länge des Textes mehr Informationen erfassen kann und die „Quellenunsicherheit“ des Textes allmählich abnimmt:
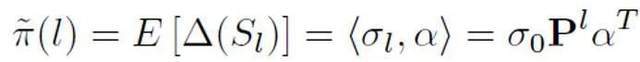
Danach wird für jede positive Probe der PU-Verlust basierend auf dem eindeutigen Prior berechnet, der durch die Probenlänge ermittelt wird. Da kürzere Texte schließlich nur eine gewisse „Unsicherheit“ aufweisen (dh kürzere Texte enthalten auch Textmerkmale einiger Personen oder der KI), können der binäre Verlust und der MPU-Verlust gewichtet und als endgültiges Optimierungsziel hinzugefügt werden:
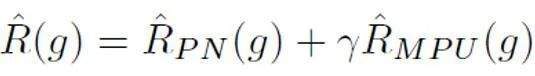
Darüber hinaus ist zu beachten, dass sich der MPU-Verlust an Trainingskörper unterschiedlicher Länge anpasst. Wenn die vorhandenen Trainingsdaten offensichtlich homogen sind und der Großteil des Korpus aus langen und langen Texten besteht, kann die MPU-Methode ihre Wirksamkeit nicht voll entfalten. Um die Länge des Trainingskorpus vielfältiger zu gestalten, wird in dieser Studie auch ein Multiskalierungsmodul auf Satzebene eingeführt. Dieses Modul deckt zufällig einige Sätze im Trainingskorpus ab und ordnet die übrigen Sätze unter Beibehaltung der ursprünglichen Reihenfolge neu. Nach dem mehrskaligen Betrieb des Trainingskorpus wurde die Länge des Trainingstextes erheblich erweitert, wodurch das PU-Lernen für das Training von KI-Textdetektoren voll ausgenutzt wurde.
Experimentelle Ergebnisse

Wie in der obigen Tabelle gezeigt, testete der Autor zunächst die Auswirkung des MPU-Verlusts auf den kürzeren, von der KI generierten Korpusdatensatz Tweep-Fake. Der Korpus in diesem Datensatz besteht aus relativ kurzen Segmenten auf Twitter. Der Autor ersetzt auch den traditionellen Zwei-Kategorien-Verlust durch ein Optimierungsziel, das den MPU-Verlust auf der Grundlage der traditionellen Feinabstimmung des Sprachmodells enthält. Der verbesserte Sprachmodelldetektor ist effektiver und übertrifft andere Basisalgorithmen.
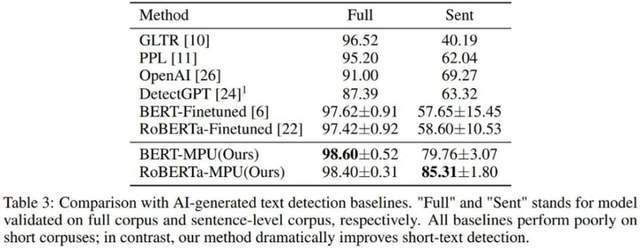
Der Autor hat auch den von chatGPT generierten Text getestet, der bei kurzen Sätzen schlecht abgeschnitten hat. Der unter den gleichen Bedingungen durch die MPU-Methode trainierte Detektor hat bei kurzen Sätzen eine gute Leistung erzielt wurde auf dem gesamten Korpus erreicht, wobei der F1-Score um 1 % stieg und SOTA-Algorithmen wie OpenAI und DetectGPT übertrifft.
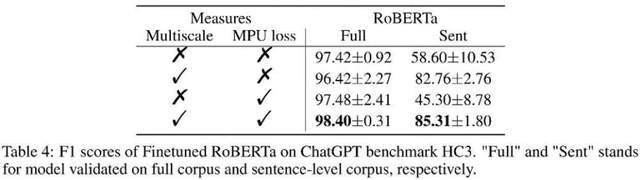
Wie in der Tabelle oben gezeigt, beobachtete der Autor den Effektgewinn, den jeder Teil im Ablationsexperiment mit sich brachte. Der MPU-Verlust verstärkt den Klassifizierungseffekt von langen und kurzen Materialien.

Der Autor verglich auch traditionelles PU und Multiscale PU (MPU). Aus der obigen Tabelle ist ersichtlich, dass der MPU-Effekt besser ist und sich besser an die Aufgabe der KI-Texterkennung in mehreren Maßstäben anpassen kann.
Zusammenfassung
Der Autor hat das Problem der Kurzsatzerkennung durch Textdetektoren gelöst, indem er eine Lösung vorgeschlagen hat, die auf mehrskaligem PU-Lernen basiert. Mit der zunehmenden Verbreitung von AIGC-Generierungsmodellen wird die Erkennung dieser Art von Inhalten immer wichtiger. Diese Forschung hat in der Frage der KI-Texterkennung einen deutlichen Fortschritt gemacht. Es besteht die Hoffnung, dass es in Zukunft weitere ähnliche Forschungen geben wird, um AIGC-Inhalte besser zu kontrollieren und den Missbrauch von KI-generierten Inhalten zu verhindern.
Das obige ist der detaillierte Inhalt vonBei der Erkennung von ChatGPT-Betrug übertrifft die Wirkung die von OpenAI: Die KI-generierten Detektoren der Peking-Universität und Huawei sind da. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



