

Was sind die Wissenspunkte zur MySQL-Indizierung und -Optimierung?

Was ist ein Index?
Index ist eine Datenstruktur, die MySQL dabei hilft, effiziente Abfragen durchzuführen. Wie das Inhaltsverzeichnis eines Buches kann es die Abfrage beschleunigen
Die Struktur des Index?
Der Index kann einen B-Tree-Index und einen Hash-Index haben. Der Index ist in der Speicher-Engine implementiert
InnoDB / MyISAM unterstützt nur B-Tree-Index
Speicher/Heap unterstützt B-Tree-Index und Hash-Index
#🎜 🎜#- B-TreeB-Tree ist eine Datenstruktur, die sich sehr gut für Festplattenoperationen eignet. Es handelt sich um einen in mehrere Richtungen ausgewogenen Suchbaum. Seine Höhe beträgt im Allgemeinen 2-4, und seine Nicht-Blattknoten und Blattknoten speichern Daten. Alle seine Blattknoten befinden sich auf derselben Ebene. Das Bild unten ist ein B-Baum Eine Optimierung basierend auf B-Tree. Der Hauptunterschied zum B-Baum besteht darin, dass alle Daten des B+-Baums in den Blattknoten gespeichert sind und die Blattknoten durch eine verknüpfte Liste aneinandergereiht sind. Das Bild unten ist ein B+-Baum Wenn der Primärschlüssel der Tabelle INT ist und die Größe 4 Byte beträgt, kann ein Knoten auch 4K-Schlüsselwerte speichern. Unter der Annahme, dass sowohl Zeiger als auch Schlüsselwerte dieselbe Größe belegen, ist der B+-Baum mit Bei einer Höhe von 3 beträgt die zweite Schicht 2048 Knoten. Die Anzahl der Blattknoten in der dritten Schicht beträgt 2048 * 2048 = 4194304. Ein Knoten ist 16 KB groß, sodass insgesamt 67108864 KB oder 65536 MB oder 64 G Daten untergebracht werden können . Da die Blattknoten durch eine verknüpfte Liste aneinandergereiht sind, werden sie standardmäßig sortiert, wenn sie nach der Indexspalte sortiert werden, sodass die Effizienz sehr hoch ist.
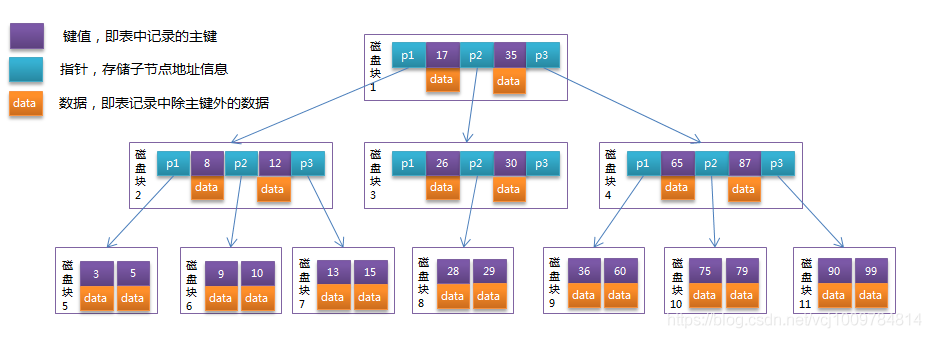 MyISAM-Index
MyISAM-Index
-
InnoDB Index#🎜 🎜#InnoDB-Daten und -Indizes werden zusammen gespeichert, auch Clustered-Index genannt. Daten werden durch den Primärschlüssel indiziert und auf den Blattknoten des Primärschlüsselindex-B+-Baums gespeichert. InnoDB-Primärschlüsselindex, die Daten sind bereits in den Blattknoten enthalten, dh der Index und die Daten werden zusammen gespeichert, was einen Clustered-Index darstellt.
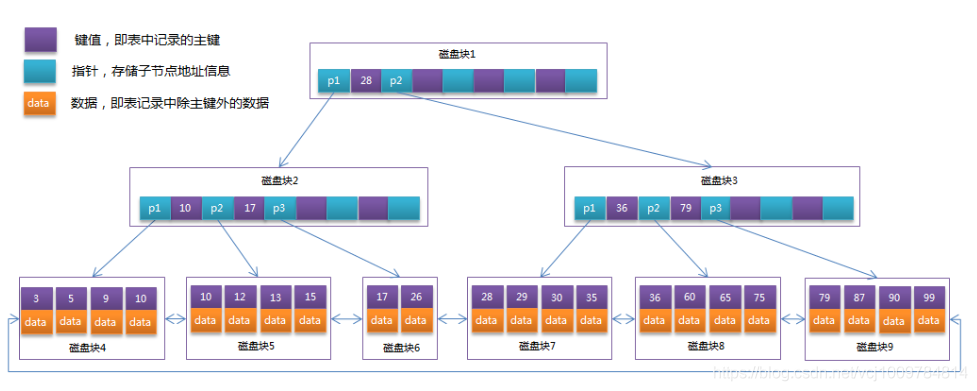
InnoDBs Hilfsindex, der Blattknoten speichert den Primärschlüsselwert, nicht die Adresse. Die Verwendung des Hilfsindex erfordert zwei Suchvorgänge.
Der Unterschied zwischen InnoDB- und MyISAM-Indizes:
InnoDB verwendet einen Clustered-Index, Seine Primärschlüsseldaten werden direkt in den Indexblattknoten gespeichert, während die Blattknoten in seinem Hilfsindex den Wert des Primärschlüssels speichern 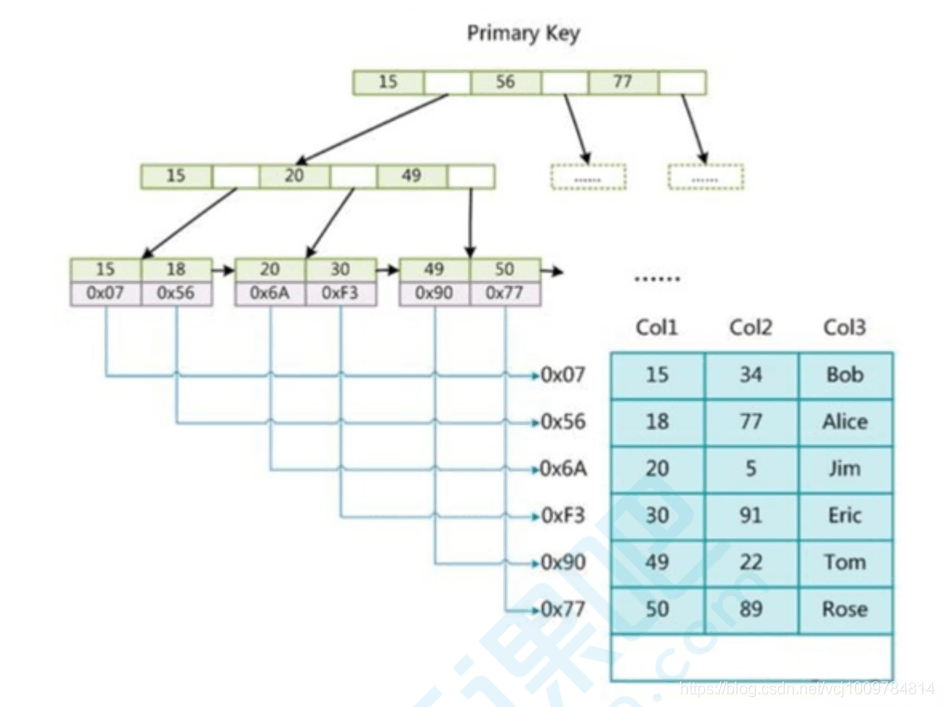
- Ein zu langer Primärschlüssel führt dazu, dass der Hilfsindex viel Platz einnimmt.
-
Warum wird empfohlen, dass InnoDB Auto verwendet? -Erhöhen der Primärschlüssel#🎜🎜 #? Wenn ein automatisch ansteigender Primärschlüssel verwendet wird, wird der neue Datensatz jedes Mal, wenn ein neuer Datensatz eingefügt wird, sequentiell an der nachfolgenden Position des aktuellen Indexknotens hinzugefügt. Wenn eine Seite voll ist, wird eine neue Seite hinzugefügt geöffnet, also Die Indexstruktur ist sehr kompakt und es ist nicht erforderlich, vorhandene Daten bei jedem Einfügen zu verschieben, was sehr effizient ist. Wenn Sie keinen automatisch inkrementierenden Primärschlüssel verwenden, müssen Sie jedes Mal, wenn Sie einen neuen Datensatz einfügen, eine Einfügeposition auswählen und die Daten müssen möglicherweise verschoben werden, was die Effizienz ineffizient macht und die Indexstruktur nicht kompakt macht#🎜🎜 #
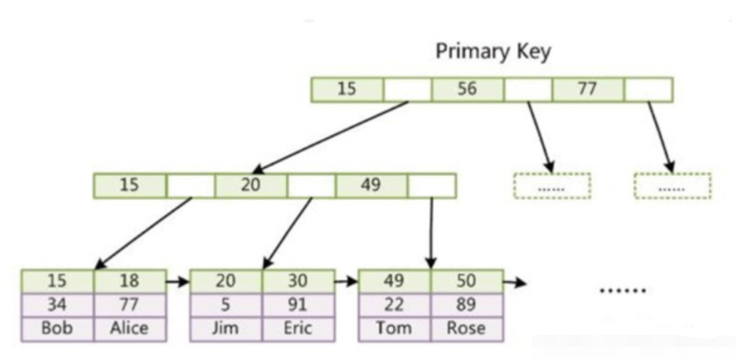 Warum B+-Baum anstelle von B-Baum verwenden? ?
Warum B+-Baum anstelle von B-Baum verwenden? ?
Der Index selbst ist ebenfalls relativ groß und wird im Allgemeinen auf der Festplatte gespeichert. Der Index und die Daten können separat gespeichert werden (nicht gruppierter Index von MyISAM). zusammen gespeichert werden (InnoDB Clustered Index)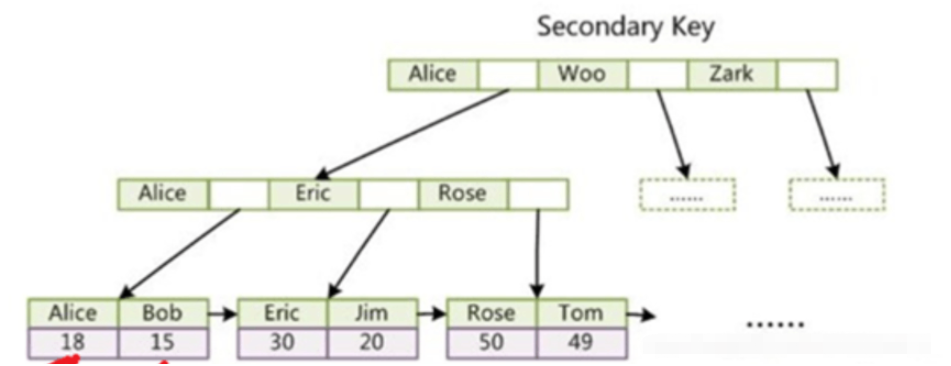
- Vorteile# 🎜🎜## ## automatisch sortiert werden, die Verwendung von „Ordnung nach“ verbessert die Effizienz erheblich.)
Der Index belegt zusätzlichen Speicherplatz.
-
Der Index verringert die Effizienz der Aktualisierung von Tabellendaten. Beim Hinzufügen, Löschen oder Ändern von Vorgängen müssen Sie nicht nur die Daten speichern, sondern auch den entsprechenden Index aktualisieren #
#🎜 🎜# Einspaltiger Index
- Primärschlüsselindex
-
#🎜🎜 #
Einzigartiger Index#🎜 🎜# - Normaler Index
Kombinierter Index#🎜🎜 #
- Index mit
-
#🎜 🎜#
CREATE INDEX index_name ON table_name(col_name); -- 或者 ALTER TABLE table_name ADD INDEX index_name(col_name)
Nach dem Login kopieren
- Szenarien, die eine Indizierung erfordern #🎜🎜 ## 🎜🎜#
DROP INDEX index_name ON table_name;
- In Beziehungen mit mehreren Tabellen müssen die zugehörigen Felder indiziert werden indiziert werden
- # 🎜🎜#Die in der Abfrage sortierten Felder müssen indiziert werden
- # 🎜🎜# Tabellen mit vielen Schreibvorgängen und wenigen Lesevorgängen sind nicht für die Indizierung geeignet #
- explainexecution Plan
- Es gibt eine Benutzertabelle, deren Index wie folgt lautet #🎜🎜 #
Sie können EXPLAIN verwenden, um eine Leistungsanalyse für eine bestimmte SQL-Anweisung durchzuführen
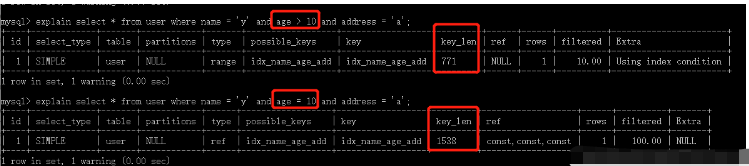
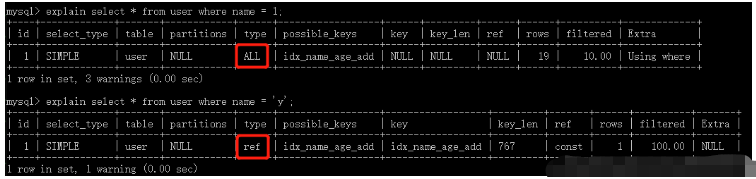
explain select * from user where name = 'am';
Nach dem Login kopieren- SOLY_KEYS#🎜🎜 ## 🎜🎜#Möglicherweise verwendet Index#🎜🎜 ## 🎜🎜###🎜🎜 ## 🎜🎜#tatsächlich verwendet Index#🎜 🎜 ## 🎜🎜##key_len#🎜🎜 ## 🎜🎜#die Länge des Index, der für die Abfrage verwendet wird
- refWenn es sich um eine äquivalente Abfrage handelt, wird sie hier konstant sein
- Szenarien wo Indizierung ist nicht anwendbar
Zusätzliche Informationen, wie z. B. 
using where
stellt die von der Speicher-Engine zurückgegebenen Ergebnisse dar und muss auf der SQL-Layer-Ebene gefiltert werden #🎜🎜 #using index#🎜 🎜# bedeutet, dass keine Rückabfrage der Tabelle erforderlich ist. Im Allgemeinen wird dieser Wert verwendet, wenn ein abdeckender Index verwendet wird. Der abdeckende Index bedeutet, dass die Spalten in der Auswahl alle Indexspalten sind. Die Abfrage, die nicht an die Tabelle zurückgegeben werden muss, bedeutet, dass Sie den Wert der Indexspalte direkt abrufen können, indem Sie zum Hilfsindex gehen. Es ist nicht erforderlich, Datensätze aus dem Primärschlüsselindex abzurufen 🎜#
MySQL 5.6.x und höher unterstützt die ICP-Funktion (Index Condition Pushdown), mit der die Prüfbedingung auf die Speicher-Engine-Ebene verschoben werden kann Erfüllen Sie die Bedingungen, werden sie nicht direkt gelesen, sondern wie zuvor. Nehmen Sie sie heraus und filtern Sie sie auf der SQL-Ebene, wodurch die Anzahl der von der Speicher-Engine-Ebene gescannten Zeilen reduziert wird. 🎜🎜#Der Index kann beim Sortieren nicht verwendet werden #system: Es gibt nur eine Datenzeile in der Tabelle oder die Tabelle ist leer
const: Verwenden Sie einen eindeutigen Index oder Primärschlüsselindex und verwenden Sie where, usw. Wertabfrage, der zurückgegebene Datensatz ist 1 Zeile, auch eindeutiger Indexscan genannt 🎜🎜# ref: Für nicht eindeutige Indizes Abfragen mit äquivalenten Where-Bedingungen oder Präfixregeln ganz links.
Das Folgende ist die Präfixregel ganz links, die erfüllt ist, dh für idx_name_age_add ist das Präfix ganz links erfüllt und der erste Index ist name#🎜🎜 ##🎜🎜 #
Bereich: Indexbereichsscan, häufig in >, <, zwischen, in, wie und anderen Abfragen #🎜🎜 #
Beachten Sie, dass bei „like“ das Platzhalterzeichen % nicht platziert werden kann am Anfang, andernfalls wird ein vollständiger Tabellenscan durchgeführt. Es besteht jedoch keine Notwendigkeit, zur Tabelle zurückzufragen #
alle: Vollständiger Tabellenscan und dann in SQL Layer Layer-Filterdatensätze, die die Anforderungen erfüllen
索引使用规范(索引失效分析)
全值匹配
在索引列上使用等值查询
explain select * from user where name = 'y' and age = 15;

2. 最左前缀
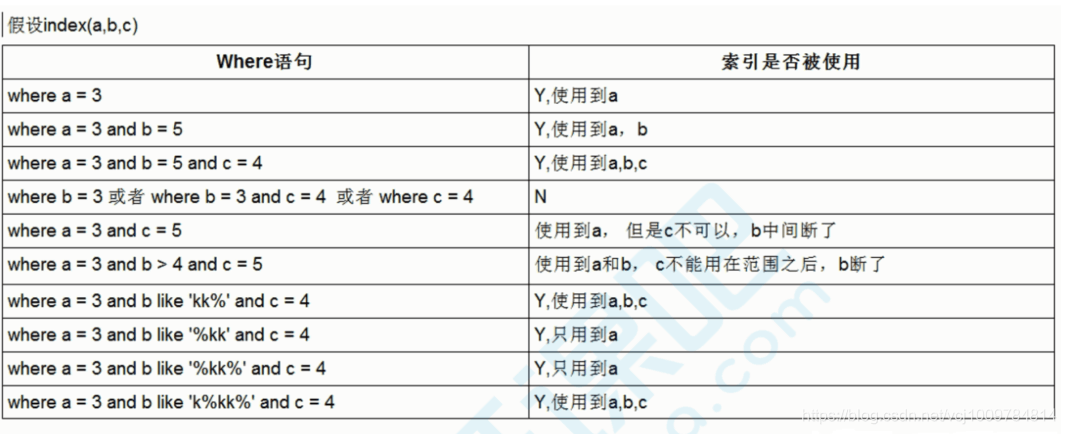
组合索引中,查询条件要从组合索引的最左列开始,如上述example中组合索引idx_name_age_add,是建立在三个列name,age,address的,若跳过name,直接用age查询,则会变为全表扫描
explain select * from user where age = 15;

3. 不要在索引列上做计算
4. 范围条件右侧的索引列会失效
看到第一个SQL语句,没有用上addresss索引
5. 尽量使用覆盖索引
explain select name,age from user where name = 'y' and age = 1;
可以避免回表查询
6. 索引字段不要使用不等(!= 或 ),不要判断null(is null/ is not null)
会导致索引失效,转为全表扫描


7. 索引字段上使用like时,不要以%开头

8. 索引字段如果是字符串,记得加单引号
9. 索引字段不要用or

例子总结:
Das obige ist der detaillierte Inhalt vonWas sind die Wissenspunkte zur MySQL-Indizierung und -Optimierung?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1393
1393
 52
1205
24
52
1205
24

 Wie man phpmyadmin öffnet
Apr 10, 2025 pm 10:51 PM
Wie man phpmyadmin öffnet
Apr 10, 2025 pm 10:51 PM
Sie können PhpMyAdmin in den folgenden Schritten öffnen: 1. Melden Sie sich beim Website -Bedienfeld an; 2. Finden und klicken Sie auf das Symbol phpmyadmin. 3. Geben Sie MySQL -Anmeldeinformationen ein; 4. Klicken Sie auf "Login".
 MySQL: Eine Einführung in die beliebteste Datenbank der Welt
Apr 12, 2025 am 12:18 AM
MySQL: Eine Einführung in die beliebteste Datenbank der Welt
Apr 12, 2025 am 12:18 AM
MySQL ist ein Open Source Relational Database Management -System, das hauptsächlich zum schnellen und zuverlässigen Speicher und Abrufen von Daten verwendet wird. Sein Arbeitsprinzip umfasst Kundenanfragen, Abfragebedingungen, Ausführung von Abfragen und Rückgabergebnissen. Beispiele für die Nutzung sind das Erstellen von Tabellen, das Einsetzen und Abfragen von Daten sowie erweiterte Funktionen wie Join -Operationen. Häufige Fehler umfassen SQL -Syntax, Datentypen und Berechtigungen sowie Optimierungsvorschläge umfassen die Verwendung von Indizes, optimierte Abfragen und die Partitionierung von Tabellen.
 So verwenden Sie ein einzelnes Gewinde -Redis
Apr 10, 2025 pm 07:12 PM
So verwenden Sie ein einzelnes Gewinde -Redis
Apr 10, 2025 pm 07:12 PM
Redis verwendet eine einzelne Gewindearchitektur, um hohe Leistung, Einfachheit und Konsistenz zu bieten. Es wird E/A-Multiplexing, Ereignisschleifen, nicht blockierende E/A und gemeinsame Speicher verwendet, um die Parallelität zu verbessern, jedoch mit Einschränkungen von Gleichzeitbeschränkungen, einem einzelnen Ausfallpunkt und ungeeigneter Schreib-intensiver Workloads.
 Mysqls Platz: Datenbanken und Programmierung
Apr 13, 2025 am 12:18 AM
Mysqls Platz: Datenbanken und Programmierung
Apr 13, 2025 am 12:18 AM
Die Position von MySQL in Datenbanken und Programmierung ist sehr wichtig. Es handelt sich um ein Open -Source -Verwaltungssystem für relationale Datenbankverwaltung, das in verschiedenen Anwendungsszenarien häufig verwendet wird. 1) MySQL bietet effiziente Datenspeicher-, Organisations- und Abruffunktionen und unterstützt Systeme für Web-, Mobil- und Unternehmensebene. 2) Es verwendet eine Client-Server-Architektur, unterstützt mehrere Speichermotoren und Indexoptimierung. 3) Zu den grundlegenden Verwendungen gehören das Erstellen von Tabellen und das Einfügen von Daten, und erweiterte Verwendungen beinhalten Multi-Table-Verknüpfungen und komplexe Abfragen. 4) Häufig gestellte Fragen wie SQL -Syntaxfehler und Leistungsprobleme können durch den Befehl erklären und langsam abfragen. 5) Die Leistungsoptimierungsmethoden umfassen die rationale Verwendung von Indizes, eine optimierte Abfrage und die Verwendung von Caches. Zu den Best Practices gehört die Verwendung von Transaktionen und vorbereiteten Staten
 Warum MySQL verwenden? Vorteile und Vorteile
Apr 12, 2025 am 12:17 AM
Warum MySQL verwenden? Vorteile und Vorteile
Apr 12, 2025 am 12:17 AM
MySQL wird für seine Leistung, Zuverlässigkeit, Benutzerfreundlichkeit und Unterstützung der Gemeinschaft ausgewählt. 1.MYSQL bietet effiziente Datenspeicher- und Abruffunktionen, die mehrere Datentypen und erweiterte Abfragevorgänge unterstützen. 2. Übernehmen Sie die Architektur der Client-Server und mehrere Speichermotoren, um die Transaktion und die Abfrageoptimierung zu unterstützen. 3. Einfach zu bedienend unterstützt eine Vielzahl von Betriebssystemen und Programmiersprachen. V.
 So stellen Sie eine Verbindung zur Datenbank von Apache her
Apr 13, 2025 pm 01:03 PM
So stellen Sie eine Verbindung zur Datenbank von Apache her
Apr 13, 2025 pm 01:03 PM
Apache verbindet eine Verbindung zu einer Datenbank erfordert die folgenden Schritte: Installieren Sie den Datenbanktreiber. Konfigurieren Sie die Datei web.xml, um einen Verbindungspool zu erstellen. Erstellen Sie eine JDBC -Datenquelle und geben Sie die Verbindungseinstellungen an. Verwenden Sie die JDBC -API, um über den Java -Code auf die Datenbank zuzugreifen, einschließlich Verbindungen, Erstellen von Anweisungen, Bindungsparametern, Ausführung von Abfragen oder Aktualisierungen und Verarbeitungsergebnissen.
 So starten Sie MySQL von Docker
Apr 15, 2025 pm 12:09 PM
So starten Sie MySQL von Docker
Apr 15, 2025 pm 12:09 PM
Der Prozess des Startens von MySQL in Docker besteht aus den folgenden Schritten: Ziehen Sie das MySQL -Image zum Erstellen und Starten des Containers an, setzen
 CentOS installieren MySQL
Apr 14, 2025 pm 08:09 PM
CentOS installieren MySQL
Apr 14, 2025 pm 08:09 PM
Die Installation von MySQL auf CentOS umfasst die folgenden Schritte: Hinzufügen der entsprechenden MySQL Yum -Quelle. Führen Sie den Befehl mySQL-server aus, um den MySQL-Server zu installieren. Verwenden Sie den Befehl mySQL_SECURE_INSTALLATION, um Sicherheitseinstellungen vorzunehmen, z. B. das Festlegen des Stammbenutzerkennworts. Passen Sie die MySQL -Konfigurationsdatei nach Bedarf an. Tune MySQL -Parameter und optimieren Sie Datenbanken für die Leistung.
