
 Backend-Entwicklung
Python-Tutorial
So implementieren Sie Suchalgorithmen für die Breite und Tiefe von Graphen in Python
Backend-Entwicklung
Python-Tutorial
So implementieren Sie Suchalgorithmen für die Breite und Tiefe von Graphen in Python
So implementieren Sie Suchalgorithmen für die Breite und Tiefe von Graphen in Python

Vorwort
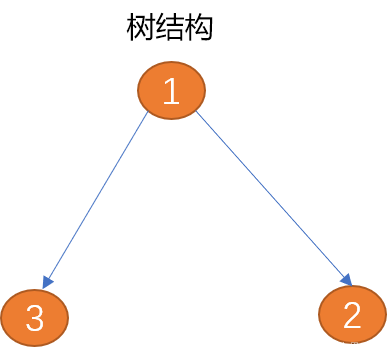
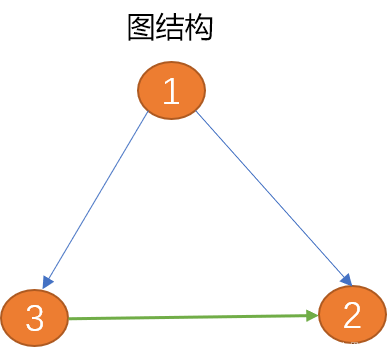
Graph ist eine abstrakte Datenstruktur, die im Wesentlichen einer Baumstruktur entspricht.
Im Vergleich zu Bäumen sind Diagramme geschlossen. Die Baumstruktur kann als Vorgänger der Diagrammstruktur angesehen werden. Wenn Sie horizontale Verbindungen zwischen Geschwisterknoten oder untergeordneten Knoten auf eine Baumstruktur anwenden, können Sie eine Diagrammstruktur erstellen.
Tree eignet sich zur Beschreibung einer Eins-zu-Viele-Datenstruktur von oben nach unten, beispielsweise der Organisationsstruktur eines Unternehmens.
Grafiken eignen sich zur Beschreibung komplexerer Viele-zu-Viele-Datenstrukturen, wie beispielsweise komplexer sozialer Gruppenbeziehungen.
1. Graphentheorie
Wenn Sie Computer zur Lösung von Problemen in der realen Welt verwenden, müssen Sie nicht nur Informationen in der realen Welt speichern, sondern auch die Beziehung zwischen den Informationen korrekt beschreiben.
Zum Beispiel ist es bei der Entwicklung eines Kartenprogramms notwendig, die Beziehungen zwischen Städten oder Straßen in der Stadt am Computer korrekt zu simulieren. Nur auf dieser Grundlage können Algorithmen den besten Weg von einer Stadt zur anderen oder von einem vorgegebenen Startpunkt zu einem Zielpunkt berechnen.
Ähnlich gibt es Flugroutenkarten, Zugroutenkarten und Karten für soziale Kommunikation.
Graphstrukturen können die oben beschriebenen komplexen Beziehungen zwischen Informationen in der realen Welt effektiv widerspiegeln. Mit diesem Algorithmus lässt sich ganz einfach der kürzeste Weg auf einer Flugstrecke, der beste Umsteigeplan auf einer Zugstrecke, wer mit wem im sozialen Umfeld die beste Beziehung hat und wer mit wem im Ehenetzwerk am besten verträglich ist. ..
1.1 Das Konzept des Graphen
Vertex: Vertex wird auch Knoten genannt, und ein Graph kann als eine Sammlung von Scheitelpunkten betrachtet werden. Die Scheitelpunkte selbst haben eine Datenbedeutung, daher tragen die Scheitelpunkte zusätzliche Informationen, die als „Nutzlast“ bezeichnet werden.
Scheitelpunkte können Städte, Ortsnamen, Stationsnamen, Menschen in der realen Welt sein ... Kanten können eine Richtung oder keine Richtung haben. Richtungskanten können in unidirektionale Kanten und bidirektionale Kanten unterteilt werden.
Wie in der Abbildung unten gezeigt, hat die Kante zwischen (Element 1) und (Scheitelpunkt 2) nur eine Richtung (der Pfeil zeigt die Richtung), 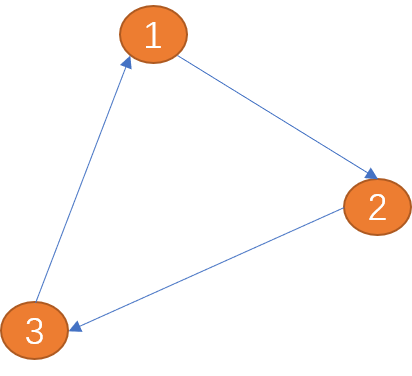 wird als Einwegkante
wird als Einwegkante
(Scheitelpunkt 1) und (Scheitelpunkt 2) hat zwei Richtungen (bidirektionale Pfeile), wird als bidirektionale Kante bezeichnet.
Die Beziehung zwischen Städten ist wechselseitig.
Gewicht: Wertinformationen können am Rand hinzugefügt werden, und der Mehrwert wird
Gewicht genannt. Gewichtete Kanten beschreiben die Stärke einer Verbindung von einem Scheitelpunkt zum anderen. 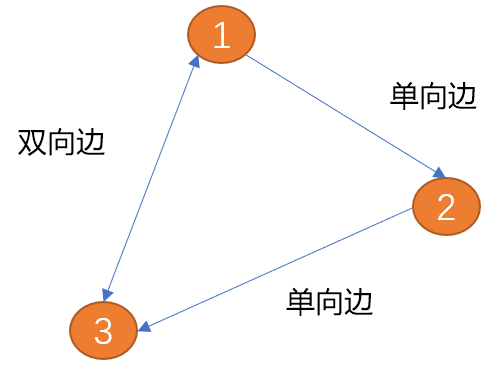
Kanten beschreiben die Beziehung zwischen Eckpunkten und Gewichte beschreiben den Unterschied in den Verbindungen.
Pfad: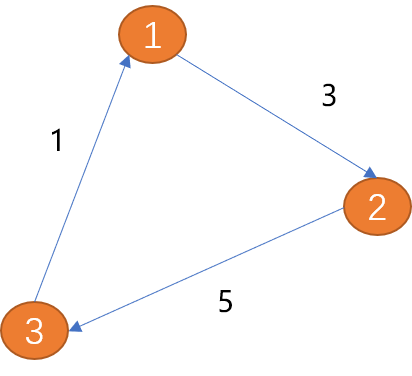 Verstehen Sie zunächst das Konzept des Pfads in der realen Welt.
Verstehen Sie zunächst das Konzept des Pfads in der realen Welt.
Zum Beispiel: Wenn Sie von einer Stadt in eine andere fahren, müssen Sie zuerst den Pfad bestimmen. Das heißt: Welche Städte müssen Sie vom Abfahrtsort bis zum Zielort durchqueren? Wie viele Meilen wird es dauern?
Wir können sagen, dass ein Pfad eine Folge von Eckpunkten ist, die durch Kanten verbunden sind. Da es mehr als einen Pfad gibt, bezieht sich die Pfadbeschreibung von einem Elementpunkt zu einem anderen Elementpunkt nicht auf einen Typ.
Wie berechnet man Pfade in Diagrammstrukturen?
Die Länge eines ungewichteten Pfades ist die Anzahl der Kanten auf dem Pfad.Die Länge eines gewichteten Pfades ist die Summe der Gewichte der Kanten auf dem Pfad.
- Wie in der obigen Abbildung gezeigt, beträgt die Pfadlänge von (Scheitelpunkt 1) bis (Scheitelpunkt 3) 8.
-
Schleife:
Vom Startpunkt aus und schließlich zurück zum Ausgangspunkt (der Endpunkt ist auch der Ausgangspunkt) bildet eine Schleife einen besonderen Weg. Wie oben ist ein Ring.
Zusammenfassend können Diagramme in die folgenden Kategorien unterteilt werden: (V1, V2, V3, V1)
Gerichtete Diagramme:
Ein Diagramm mit gerichteten Kanten wird als gerichtetes Diagramm bezeichnet.Ungerichteter Graph: Ein Graph, dessen Kanten keine Richtung haben, wird als ungerichteter Graph bezeichnet.
Gewichteter Graph: Ein Graph mit Gewichtsinformationen an den Kanten wird als gewichteter Graph bezeichnet.
Azyklischer Graph: Ein Graph ohne Zyklen wird als azyklischer Graph bezeichnet.
Gerichteter azyklischer Graph: Ein gerichteter Graph ohne Zyklus, der als DAG bezeichnet wird.
- 1.2 Diagramm definieren
Entsprechend den Eigenschaften des Diagramms muss die Diagrammdatenstruktur mindestens zwei Arten von Informationen enthalten:
Alle Eckpunkte bilden einen Satz von Informationen, hier dargestellt durch V (in einem Kartenprogramm werden beispielsweise alle Städte in einem Eckpunktsatz gebildet).
Alle Kanten stellen Mengeninformationen dar, hier dargestellt durch E (Beschreibung der Beziehung zwischen Städten).
Wie beschreibt man Kanten?
Kanten werden verwendet, um die Beziehung zwischen Objektpunkten darzustellen. Eine Kante kann also 3 Metadaten enthalten (Startpunkt, Endpunkt, Gewicht). Natürlich können die Gewichte weggelassen werden, aber im Allgemeinen beziehen sie sich beim Studium von Diagrammen auf gewichtete Diagramme.
Wenn
Gzur Darstellung des Diagramms verwendet wird, dann istG = (V, E). Jede Kante kann durch ein Tupel(fv, ev)oder ein Triplett(fv, ev, w)beschrieben werden.G表示图,则G = (V, E)。每一条边可以用二元组(fv, ev)也可以使用 三元组(fv,ev,w)描述。fv表示起点,ev表示终点。且fv,ev数据必须引用于V集合。
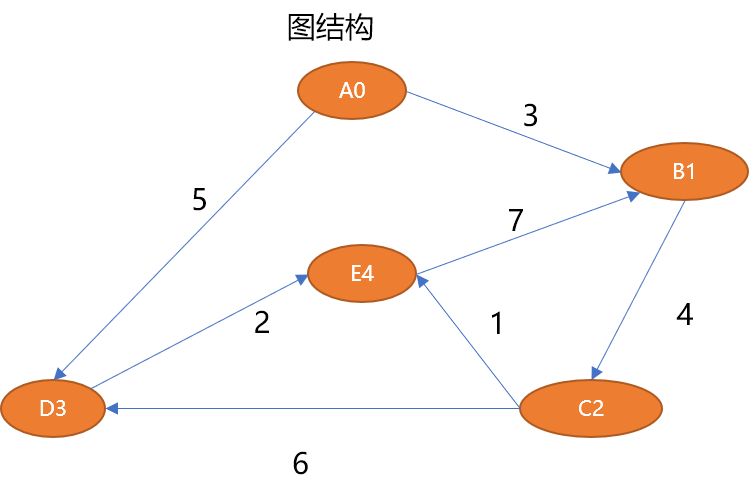
如上的图结构可以描述如下:
# 5 个顶点 V={A0,B1,C2,D3,E4} # 7 条边 E={ (A0,B1,3),(B1,C2,4),(C2,D3,6),(C2,E4,1),(D3,E4,2),(A0,D3,5),(E4,B1,7)}Nach dem Login kopieren1.3 图的抽象数据结构
图的抽象数据描述中至少要有的方法:
Graph ( ): 用来创建一个新图。add_vertex( vert ):向图中添加一个新节点,参数应该是一个节点类型的对象。add_edge(fv,tv ):在 2 个项点之间建立起边关系。add_edge(fv,tv,w ):在 2 个项点之间建立起一条边并指定连接权重。find_vertex( key ): 根据关键字 key 在图中查找顶点。find_vertexs( ):查询所有顶点信息。find_path( fv,tv):查找.从一个顶点到另一个顶点之间的路径。
2. 图的存储实现
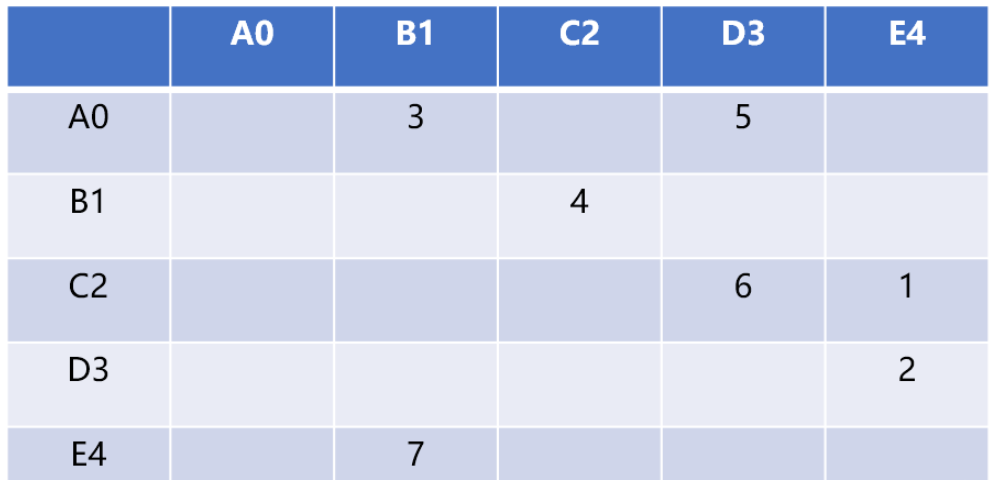
图的存储实现主流有 2 种:邻接矩阵和链接表,本文主要介绍邻接矩阵。
2.1 邻接矩阵
使用二维矩阵(数组)存储顶点之间的关系。
如
graph[5][5]可以存储 5 个顶点的关系数据,行号和列号表示顶点,第 v 行的第 w 列交叉的单元格中的值表示从顶点 v 到顶点 w 的边的权重,如grap[2][3]=6表示 C2 顶点和 D3 顶点的有连接(相邻),权重为 6相邻矩阵的优点就是简单,可以清晰表示那些顶点是相连的。由于并非每对顶点之间都存在连接,因此矩阵中存在许多未被利用的空间,通常被称为“稀疏矩阵”。
只有当每一个顶点和其它顶点都有关系时,矩阵才会填满。如果图结构的关系不是太复杂,使用这种结构存储图数据会浪费大量的空间。
邻接矩阵适合表示关系复杂的图结构,如互联网上网页之间的链接、社交圈中人与人之间的社会关系……
2.2 编码实现邻接矩阵
因顶点本身有数据含义,需要先定义顶点类型。
顶点类:
""" 节(顶)点类 """ class Vertex: def __init__(self, name, v_id=0): # 顶点的编号 self.v_id = v_id # 顶点的名称 self.v_name = name # 是否被访问过:False 没有 True:有 self.visited = False # 自我显示 def __str__(self): return '[编号为 {0},名称为 {1} ] 的顶点'.format(self.v_id, self.v_name)Nach dem Login kopieren顶点类中
v_id和v_name很好理解。为什么要添加一个visited?这个变量用来记录顶点在路径搜索过程中是否已经被搜索过,避免重复搜索计算。
图类:图类的方法较多,这里逐方法介绍。
初始化方法
class Graph: """ nums:相邻矩阵的大小 """ def __init__(self, nums): # 一维列表,保存节点,最多只能有 nums 个节点 self.vert_list = [] # 二维列表,存储顶点及顶点间的关系(权重) # 初始权重为 0 ,表示节点与节点之间还没有建立起关系 self.matrix = [[0] * nums for _ in range(nums)] # 顶点个数 self.v_nums = 0 # 使用队列模拟队列或栈,用于广度、深度优先搜索算法 self.queue_stack = [] # 保存搜索到的路径 self.searchPath = [] # 暂省略……Nach dem Login kopieren初始化方法用来初始化图中的数据类型:
一维列表
vert_list保存所有顶点数据。二维列表
matrix保存顶点与顶点之间的关系数据。queue_stack使用列表模拟队列或栈,用于后续的广度搜索和深度搜索。怎么使用列表模拟队列或栈?
列表有
append()、pop()2 个很价值的方法。append()用来向列表中添加数据,且每次都是从列表最后面添加。pop()默认从列表最后面删除且弹出数据,pop(参数)可以提供索引值用来从指定位置删除且弹出数据。使用 append() 和 pop() 方法就能模拟栈,从同一个地方进出数据。
使用 append() 和 pop(0) 方法就能模拟队列,从后面添加数据,从最前面获取数据
searchPathfvstellt den Startpunkt dar undevstellt den Endpunkt dar. Undfv-,ev-Daten müssen in derV-Sammlung referenziert werden.
Die obige Diagrammstruktur kann wie folgt beschrieben werden: 🎜 """ 添加新顶点 """ def add_vertex(self, vert): if vert in self.vert_list: # 已经存在 return if self.v_nums >= len(self.matrix): # 超过相邻矩阵所能存储的节点上限 return # 顶点的编号内部生成 vert.v_id = self.v_nums self.vert_list.append(vert) # 数量增一 self.v_nums += 1Nach dem Login kopierenNach dem Login kopieren1.3 Abstrakte Datenstruktur des Diagramms
🎜Zumindest die Methode, die in der abstrakten Datenbeschreibung des Diagramms enthalten sein muss: 🎜- 🎜
Graph ( ): Wird zum Erstellen eines neuen Diagramms verwendet. 🎜 - 🎜
add_vertex( vert ): Fügen Sie dem Diagramm einen neuen Knoten hinzu. Der Parameter sollte ein Objekt vom Knotentyp sein. 🎜 - 🎜
add_edge(fv, tv): Stellen Sie eine Kantenbeziehung zwischen 2 Elementpunkten her. 🎜 - 🎜
add_edge(fv,tv,w): Legen Sie eine Kante zwischen 2 Elementpunkten fest und geben Sie das Verbindungsgewicht an. 🎜 - 🎜
find_vertex( key): Scheitelpunkte im Diagramm basierend auf dem Schlüsselwort key finden. 🎜 - 🎜
find_vertexs( ): Alle Scheitelpunktinformationen abfragen. 🎜 - 🎜
find_path(fv,tv): Finden Sie den Pfad von einem Scheitelpunkt zu einem anderen Scheitelpunkt. 🎜
2. Diagrammspeicherimplementierung
🎜Es gibt zwei Haupttypen der Diagrammspeicherimplementierung: Adjazenzmatrix und Linkliste. In diesem Artikel wird hauptsächlich die Adjazenzmatrix vorgestellt. 🎜2.1 Adjazenzmatrix
🎜Verwenden Sie eine zweidimensionale Matrix (Array), um die Beziehung zwischen Eckpunkten zu speichern. 🎜🎜Zum Beispiel kanngraph[5][5]die relationalen Daten von 5 Scheitelpunkten speichern. Die Zeilennummer und die Spaltennummer stellen den Wert in der Zelle dar, die die v-te Zeile und das wth schneidet Die Spalte stellt den Startpunkt dar. Das Gewicht der Kante vom Scheitelpunkt v zum Scheitelpunkt w, z. B.grap[2][3]=6bedeutet, dass der Scheitelpunkt C2 und der Scheitelpunkt D3 verbunden (angrenzend) sind. , und das Gewicht beträgt 6🎜🎜2.2 Codierung zur Implementierung der Adjazenzmatrix 🎜 Da der Scheitelpunkt selbst eine Datenbedeutung hat, muss zuerst der Scheitelpunkttyp definiert werden. 🎜🎜🎜Vertex-Klasse: 🎜🎜🎜In der Vertex-Klasse sind''' 添加节点与节点之间的边, 如果是无权重图,统一设定为 1 ''' def add_edge(self, from_v, to_v): # 如果节点不存在 if from_v not in self.vert_list: self.add_vertex(from_v) if to_v not in self.vert_list: self.add_vertex(to_v) # from_v 节点的编号为行号,to_v 节点的编号为列号 self.matrix[from_v.v_id][to_v.v_id] = 1 ''' 添加有权重的边 ''' def add_edge(self, from_v, to_v, weight): # 如果节点不存在 if from_v not in self.vert_list: self.add_vertex(from_v) if to_v not in self.vert_list: self.add_vertex(to_v) # from_v 节点的编号为行号,to_v 节点的编号为列号 self.matrix[from_v.v_id][to_v.v_id] = weightNach dem Login kopierenNach dem Login kopierenv_idundv_nameleicht zu verstehen. Warum einenbesuchthinzufügen? 🎜🎜Diese Variable wird verwendet, um aufzuzeichnen, ob der Scheitelpunkt während des Pfadsuchvorgangs durchsucht wurde, um wiederholte Suchberechnungen zu vermeiden. 🎜🎜🎜Graph-Klasse: 🎜Die Graph-Klasse verfügt über viele Methoden. Hier werden wir sie einzeln vorstellen. 🎜🎜🎜Initialisierungsmethode🎜🎜🎜Die Initialisierungsmethode wird verwendet, um den Datentyp im Diagramm zu initialisieren: 🎜🎜Eindimensionale Liste''' 根据节点编号返回节点 ''' def find_vertex(self, v_id): if v_id >= 0 or v_id <= self.v_nums: # 节点编号必须存在 return [tmp_v for tmp_v in self.vert_list if tmp_v.v_id == v_id][0]Nach dem Login kopierenNach dem Login kopierenvert_listspeichert alle Scheitelpunktdaten. 🎜🎜Zweidimensionale Listematrixspeichert die Beziehungsdaten zwischen Scheitelpunkten. 🎜🎜queue_stackVerwenden Sie eine Liste, um eine Warteschlange oder einen Stapel für nachfolgende Breiten- und Tiefensuchen zu simulieren. 🎜🎜🎜Wie verwende ich eine Liste, um eine Warteschlange oder einen Stapel zu simulieren? 🎜🎜🎜Die Liste enthält zwei wertvolle Methoden:append()undpop(). 🎜🎜append()wird verwendet, um Daten zur Liste hinzuzufügen, und zwar jedes Mal, wenn sie vom Ende der Liste hinzugefügt werden. 🎜🎜pop()löscht und fügt Daten standardmäßig am Ende der Liste hinzu.pop(parameter)kann einen Indexwert zum Löschen und Einfügen von Daten an der angegebenen Position bereitstellen . 🎜🎜Verwenden Sie die Methoden append() und pop(), um einen Stapel zu simulieren und Daten an derselben Stelle einzugeben und zu verlassen. 🎜🎜Verwenden Sie die Methoden append() und pop(0), um eine Warteschlange zu simulieren, Daten von hinten hinzuzufügen und Daten von vorne abzurufen🎜🎜searchPath: Wird zum Speichern der in Breite oder Breite verwendeten Daten verwendet Suchergebnis für den Tiefenpfad. 🎜🎜🎜So fügen Sie einen neuen Abschnittspunkt (oben) hinzu: 🎜🎜""" 添加新顶点 """ def add_vertex(self, vert): if vert in self.vert_list: # 已经存在 return if self.v_nums >= len(self.matrix): # 超过相邻矩阵所能存储的节点上限 return # 顶点的编号内部生成 vert.v_id = self.v_nums self.vert_list.append(vert) # 数量增一 self.v_nums += 1Nach dem Login kopierenNach dem Login kopieren上述方法注意一点,节点的编号由图内部逻辑提供,便于节点编号顺序的统一。
添加边方法
此方法是邻接矩阵表示法的核心逻辑。
''' 添加节点与节点之间的边, 如果是无权重图,统一设定为 1 ''' def add_edge(self, from_v, to_v): # 如果节点不存在 if from_v not in self.vert_list: self.add_vertex(from_v) if to_v not in self.vert_list: self.add_vertex(to_v) # from_v 节点的编号为行号,to_v 节点的编号为列号 self.matrix[from_v.v_id][to_v.v_id] = 1 ''' 添加有权重的边 ''' def add_edge(self, from_v, to_v, weight): # 如果节点不存在 if from_v not in self.vert_list: self.add_vertex(from_v) if to_v not in self.vert_list: self.add_vertex(to_v) # from_v 节点的编号为行号,to_v 节点的编号为列号 self.matrix[from_v.v_id][to_v.v_id] = weightNach dem Login kopierenNach dem Login kopieren添加边信息的方法有 2 个,一个用来添加无权重边,一个用来添加有权重的边。
查找某节点
使用线性查找法从节点集合中查找某一个节点。
''' 根据节点编号返回节点 ''' def find_vertex(self, v_id): if v_id >= 0 or v_id <= self.v_nums: # 节点编号必须存在 return [tmp_v for tmp_v in self.vert_list if tmp_v.v_id == v_id][0]Nach dem Login kopierenNach dem Login kopieren查询所有节点
''' 输出所有顶点信息 ''' def find_only_vertexes(self): for tmp_v in self.vert_list: print(tmp_v)Nach dem Login kopieren此方法仅为了查询方便。
查询节点之间的关系
''' 迭代节点与节点之间的关系(边) ''' def find_vertexes(self): for tmp_v in self.vert_list: edges = self.matrix[tmp_v.v_id] for col in range(len(edges)): w = edges[col] if w != 0: print(tmp_v, '和', self.vert_list[col], '的权重为:', w)Nach dem Login kopieren测试代码:
if __name__ == "__main__": # 初始化图对象 g = Graph(5) # 添加顶点 for _ in range(len(g.matrix)): v_name = input("顶点的名称( q 为退出):") if v_name == 'q': break v = Vertex(v_name) g.add_vertex(v) # 节点之间的关系 infos = [(0, 1, 3), (0, 3, 5), (1, 2, 4), (2, 3, 6), (2, 4, 1), (3, 4, 2), (4, 1, 7)] for i in infos: v = g.find_vertex(i[0]) v1 = g.find_vertex(i[1]) g.add_edge(v, v1, i[2]) # 输出顶点及边a print("-----------顶点与顶点关系--------------") g.find_vertexes() ''' 输出结果: 顶点的名称( q 为退出):A 顶点的名称( q 为退出):B 顶点的名称( q 为退出):C 顶点的名称( q 为退出):D 顶点的名称( q 为退出):E [编号为 0,名称为 A ] 的顶点 和 [编号为 1,名称为 B ] 的顶点 的权重为: 3 [编号为 0,名称为 A ] 的顶点 和 [编号为 3,名称为 D ] 的顶点 的权重为: 5 [编号为 1,名称为 B ] 的顶点 和 [编号为 2,名称为 C ] 的顶点 的权重为: 4 [编号为 2,名称为 C ] 的顶点 和 [编号为 3,名称为 D ] 的顶点 的权重为: 6 [编号为 2,名称为 C ] 的顶点 和 [编号为 4,名称为 E ] 的顶点 的权重为: 1 [编号为 3,名称为 D ] 的顶点 和 [编号为 4,名称为 E ] 的顶点 的权重为: 2 [编号为 4,名称为 E ] 的顶点 和 [编号为 1,名称为 B ] 的顶点 的权重为: 7 '''Nach dem Login kopieren3. 搜索路径
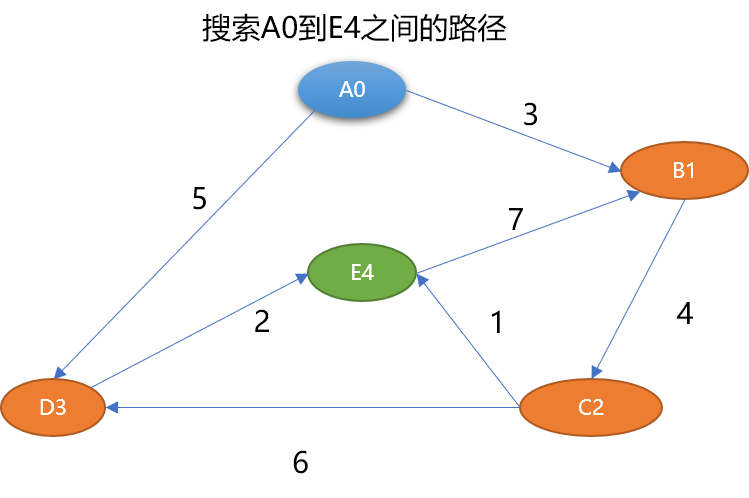
在图中经常做的操作,就是查找从一个顶点到另一个顶点的路径。如怎么查找到 A0 到 E4 之间的路径长度:
从人的直观思维角度查找一下,可以找到如下路径:
{A0,B1,C2,E4}路径长度为 8。{A0,D3,E4}路径长度为 7。{A0,B1,C2,D3,E4}路径长度为 15。
在路径查找时,人的思维具有知识性和直观性特点,因此不存在所谓的尝试或碰壁问题。而计算机是试探性思维,就会出现这条路不通,再找另一条路的现象。
所以路径算法中常常会以错误为代价,在查找过程中会走一些弯路。常用的路径搜索算法有 2 种:
广度优先搜索
深度优先搜索
3.1 广度优先搜索
先看一下广度优先搜索的示意图:
广度优先搜索的基本思路:
确定出发点,本案例是 A0 顶点。
以出发点相邻的顶点为候选点,并存储至队列。
从队列中每拿出一个顶点后,再把与此顶点相邻的其它顶点做为候选点存储于队列。
不停重复上述过程,至到找到目标顶点或队列为空。
使用广度搜索到的路径与候选节点进入队列的先后顺序有关系。如第 1 步确定候选节点时
B1和D3谁先进入队列,对于后面的查找也会有影响。上图使用广度搜索可找到
A0~E4路径是:{A0,B1,D3,C2,E4}其实
{A0,B1,C2,E4}也是一条有效路径,有可能搜索不出来,这里因为搜索到B1后不会马上搜索C2,因为B3先于C2进入,广度优先搜索算法只能保证找到路径,而不能保存找到最佳路径。编码实现广度优先搜索:
广度优先搜索需要借助队列临时存储选节点,本文使用列表模拟队列。
在图类中实现广度优先搜索算法的方法:
class Graph(): # 省略其它代码 ''' 广度优先搜索算法 ''' def bfs(self, from_v, to_v): # 查找与 fv 相邻的节点 self.find_neighbor(from_v) # 临时路径 lst_path = [from_v] # 重复条件:队列不为空 while len(self.queue_stack) != 0: # 从队列中一个节点(模拟队列) tmp_v = self.queue_stack.pop(0) # 添加到列表中 lst_path.append(tmp_v) # 是不是目标节点 if tmp_v.v_id == to_v.v_id: self.searchPath.append(lst_path) print('找到一条路径', [v_.v_id for v_ in lst_path]) lst_path.pop() else: self.find_neighbor(tmp_v) ''' 查找某一节点的相邻节点,并添加到队列(栈)中 ''' def find_neighbor(self, find_v): if find_v.visited: return find_v.visited = True # 找到保存 find_v 节点相邻节点的列表 lst = self.matrix[find_v.v_id] for idx in range(len(lst)): if lst[idx] != 0: # 权重不为 0 ,可判断相邻 self.queue_stack.append(self.vert_list[idx])Nach dem Login kopieren广度优先搜索过程中,需要随时获取与当前节点相邻的节点,
find_neighbor()方法的作用就是用来把当前节点的相邻节点压入队列中。测试广度优先搜索算法:
if __name__ == "__main__": # 初始化图对象 g = Graph(5) # 添加顶点 for _ in range(len(g.matrix)): v_name = input("顶点的名称( q 为退出):") if v_name == 'q': break v = Vertex(v_name) g.add_vertex(v) # 节点之间的关系 infos = [(0, 1, 3), (0, 3, 5), (1, 2, 4), (2, 3, 6), (2, 4, 1), (3, 4, 2), (4, 1, 7)] for i in infos: v = g.find_vertex(i[0]) v1 = g.find_vertex(i[1]) g.add_edge(v, v1, i[2]) print("----------- 广度优先路径搜索--------------") f_v = g.find_vertex(0) t_v = g.find_vertex(4) g.bfs(f_v,t_v) ''' 输出结果 顶点的名称( q 为退出):A 顶点的名称( q 为退出):B 顶点的名称( q 为退出):C 顶点的名称( q 为退出):D 顶点的名称( q 为退出):E ----------- 广度优先路径搜索-------------- 找到一条路径 [0, 1, 3, 2, 4] 找到一条路径 [0, 1, 3, 2, 3, 4] '''Nach dem Login kopieren使用递归实现广度优先搜索算法:
''' 递归方式实现广度搜索 ''' def bfs_dg(self, from_v, to_v): self.searchPath.append(from_v) if from_v.v_id != to_v.v_id: self.find_neighbor(from_v) if len(self.queue_stack) != 0: self.bfs_dg(self.queue_stack.pop(0), to_v)Nach dem Login kopieren3.2 深度优先搜索算法
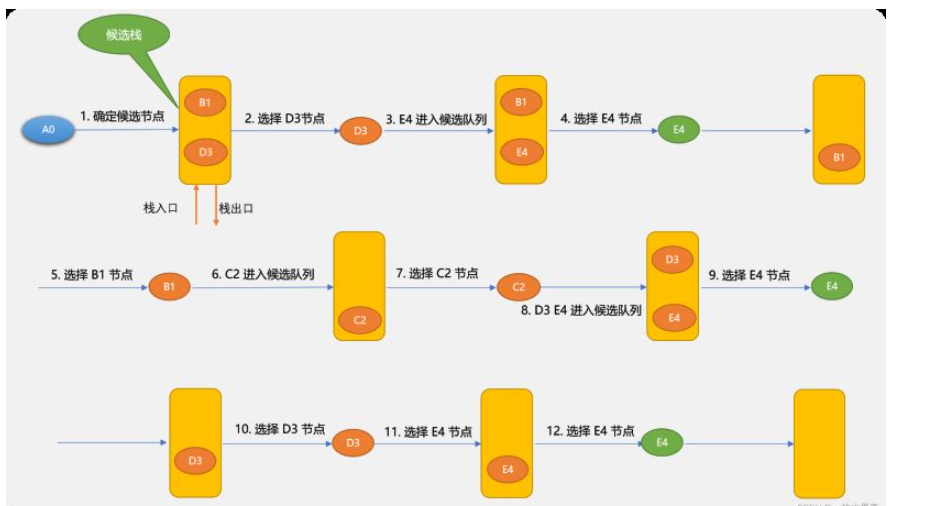
先看一下深度优先算法的示意图。
深度优先搜索算法和广度优先搜索算法不同的地方在于:深度优先搜索算法将候选节点放在堆栈中。因栈是先进后出,所以,搜索到的节点顺序不一样。
使用循环实现深度优先搜索算法:
深度优先搜索算法需要用到栈,本文使用列表模拟。
''' 深度优先搜索算法 使用栈存储下一个需要查找的节点 ''' def dfs(self, from_v, to_v): # 查找与 from_v 相邻的节点 self.find_neighbor(from_v) # 临时路径 lst_path = [from_v] # 重复条件:栈不为空 while len(self.queue_stack) != 0: # 从栈中取一个节点(模拟栈) tmp_v = self.queue_stack.pop() # 添加到列表中 lst_path.append(tmp_v) # 是不是目标节点 if tmp_v.v_id == to_v.v_id: self.searchPath.append(lst_path) print('找到一条路径:', [v_.v_id for v_ in lst_path]) lst_path.pop() else: self.find_neighbor(tmp_v)Nach dem Login kopieren测试:
if __name__ == "__main__": # 初始化图对象 g = Graph(5) # 添加顶点 for _ in range(len(g.matrix)): v_name = input("顶点的名称( q 为退出):") if v_name == 'q': break v = Vertex(v_name) g.add_vertex(v) # 节点之间的关系 infos = [(0, 1, 3), (0, 3, 5), (1, 2, 4), (2, 3, 6), (2, 4, 1), (3, 4, 2), (4, 1, 7)] for i in infos: v = g.find_vertex(i[0]) v1 = g.find_vertex(i[1]) g.add_edge(v, v1, i[2]) # 输出顶点及边a print("-----------顶点与顶点关系--------------") g.find_vertexes() print("----------- 深度优先路径搜索--------------") f_v = g.find_vertex(0) t_v = g.find_vertex(4) g.dfs(f_v, t_v) ''' 输出结果 顶点的名称( q 为退出):A 顶点的名称( q 为退出):B 顶点的名称( q 为退出):C 顶点的名称( q 为退出):D 顶点的名称( q 为退出):E -----------顶点与顶点关系-------------- [编号为 0,名称为 A ] 的顶点 和 [编号为 1,名称为 B ] 的顶点 的权重为: 3 [编号为 0,名称为 A ] 的顶点 和 [编号为 3,名称为 D ] 的顶点 的权重为: 5 [编号为 1,名称为 B ] 的顶点 和 [编号为 2,名称为 C ] 的顶点 的权重为: 4 [编号为 2,名称为 C ] 的顶点 和 [编号为 3,名称为 D ] 的顶点 的权重为: 6 [编号为 2,名称为 C ] 的顶点 和 [编号为 4,名称为 E ] 的顶点 的权重为: 1 [编号为 3,名称为 D ] 的顶点 和 [编号为 4,名称为 E ] 的顶点 的权重为: 2 [编号为 4,名称为 E ] 的顶点 和 [编号为 1,名称为 B ] 的顶点 的权重为: 7 ----------- 深度优先路径搜索-------------- 找到一条路径: [0, 3, 4] 找到一条路径: [0, 3, 1, 2, 4] '''Nach dem Login kopieren使用递归实现深度优先搜索算法:
''' 递归实现深度搜索算法 ''' def def_dg(self, from_v, to_v): self.searchPath.append(from_v) if from_v.v_id != to_v.v_id: # 查找与 from_v 节点相连的子节点 lst = self.find_neighbor_(from_v) if lst is not None: for tmp_v in lst[::-1]: self.def_dg(tmp_v, to_v) """ 查找某一节点的相邻节点,以列表方式返回 """ def find_neighbor_(self, find_v): if find_v.visited: return find_v.visited = True # 查找与 find_v 节点相邻的节点 lst = self.matrix[find_v.v_id] return [self.vert_list[idx] for idx in range(len(lst)) if lst[idx] != 0]Nach dem Login kopieren递归实现时,不需要使用全局栈,只需要获到当前节点的相邻节点便可。
 2.2 Codierung zur Implementierung der Adjazenzmatrix 🎜 Da der Scheitelpunkt selbst eine Datenbedeutung hat, muss zuerst der Scheitelpunkttyp definiert werden. 🎜🎜🎜Vertex-Klasse: 🎜🎜
2.2 Codierung zur Implementierung der Adjazenzmatrix 🎜 Da der Scheitelpunkt selbst eine Datenbedeutung hat, muss zuerst der Scheitelpunkttyp definiert werden. 🎜🎜🎜Vertex-Klasse: 🎜🎜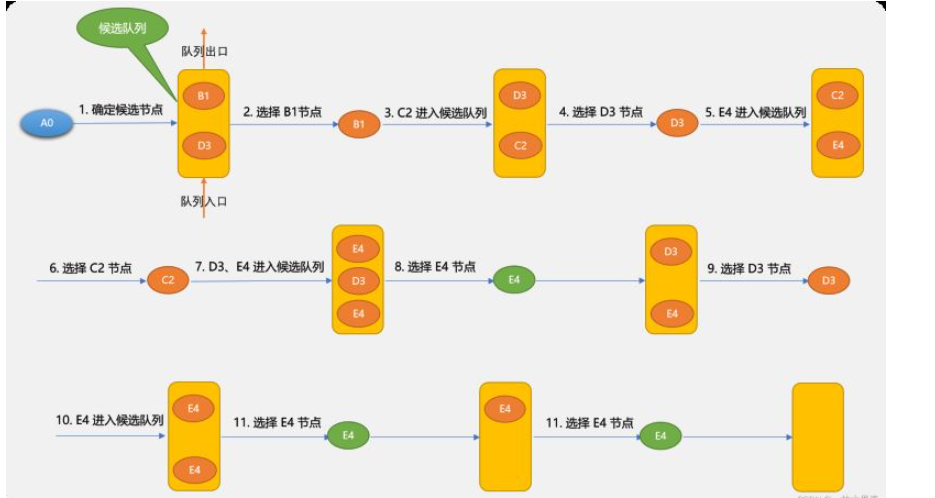
Das obige ist der detaillierte Inhalt vonSo implementieren Sie Suchalgorithmen für die Breite und Tiefe von Graphen in Python. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1393
1393
 52
1205
24
52
1205
24

 PHP und Python: Verschiedene Paradigmen erklärt
Apr 18, 2025 am 12:26 AM
PHP und Python: Verschiedene Paradigmen erklärt
Apr 18, 2025 am 12:26 AM
PHP ist hauptsächlich prozedurale Programmierung, unterstützt aber auch die objektorientierte Programmierung (OOP). Python unterstützt eine Vielzahl von Paradigmen, einschließlich OOP, funktionaler und prozeduraler Programmierung. PHP ist für die Webentwicklung geeignet, und Python eignet sich für eine Vielzahl von Anwendungen wie Datenanalyse und maschinelles Lernen.
 Wählen Sie zwischen PHP und Python: Ein Leitfaden
Apr 18, 2025 am 12:24 AM
Wählen Sie zwischen PHP und Python: Ein Leitfaden
Apr 18, 2025 am 12:24 AM
PHP eignet sich für Webentwicklung und schnelles Prototyping, und Python eignet sich für Datenwissenschaft und maschinelles Lernen. 1.PHP wird für die dynamische Webentwicklung verwendet, mit einfacher Syntax und für schnelle Entwicklung geeignet. 2. Python hat eine kurze Syntax, ist für mehrere Felder geeignet und ein starkes Bibliotheksökosystem.
 Kann Visual Studio -Code in Python verwendet werden
Apr 15, 2025 pm 08:18 PM
Kann Visual Studio -Code in Python verwendet werden
Apr 15, 2025 pm 08:18 PM
VS -Code kann zum Schreiben von Python verwendet werden und bietet viele Funktionen, die es zu einem idealen Werkzeug für die Entwicklung von Python -Anwendungen machen. Sie ermöglichen es Benutzern: Installation von Python -Erweiterungen, um Funktionen wie Code -Abschluss, Syntax -Hervorhebung und Debugging zu erhalten. Verwenden Sie den Debugger, um Code Schritt für Schritt zu verfolgen, Fehler zu finden und zu beheben. Integrieren Sie Git für die Versionskontrolle. Verwenden Sie Tools für die Codeformatierung, um die Codekonsistenz aufrechtzuerhalten. Verwenden Sie das Lining -Tool, um potenzielle Probleme im Voraus zu erkennen.
 Kann gegen Code in Windows 8 ausgeführt werden
Apr 15, 2025 pm 07:24 PM
Kann gegen Code in Windows 8 ausgeführt werden
Apr 15, 2025 pm 07:24 PM
VS -Code kann unter Windows 8 ausgeführt werden, aber die Erfahrung ist möglicherweise nicht großartig. Stellen Sie zunächst sicher, dass das System auf den neuesten Patch aktualisiert wurde, und laden Sie dann das VS -Code -Installationspaket herunter, das der Systemarchitektur entspricht und sie wie aufgefordert installiert. Beachten Sie nach der Installation, dass einige Erweiterungen möglicherweise mit Windows 8 nicht kompatibel sind und nach alternativen Erweiterungen suchen oder neuere Windows -Systeme in einer virtuellen Maschine verwenden müssen. Installieren Sie die erforderlichen Erweiterungen, um zu überprüfen, ob sie ordnungsgemäß funktionieren. Obwohl VS -Code unter Windows 8 möglich ist, wird empfohlen, auf ein neueres Windows -System zu upgraden, um eine bessere Entwicklungserfahrung und Sicherheit zu erzielen.
 Ist die VSCODE -Erweiterung bösartig?
Apr 15, 2025 pm 07:57 PM
Ist die VSCODE -Erweiterung bösartig?
Apr 15, 2025 pm 07:57 PM
VS -Code -Erweiterungen stellen böswillige Risiken dar, wie das Verstecken von böswilligem Code, das Ausbeutetieren von Schwachstellen und das Masturbieren als legitime Erweiterungen. Zu den Methoden zur Identifizierung böswilliger Erweiterungen gehören: Überprüfung von Verlegern, Lesen von Kommentaren, Überprüfung von Code und Installation mit Vorsicht. Zu den Sicherheitsmaßnahmen gehören auch: Sicherheitsbewusstsein, gute Gewohnheiten, regelmäßige Updates und Antivirensoftware.
 Python vs. JavaScript: Die Lernkurve und Benutzerfreundlichkeit
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript: Die Lernkurve und Benutzerfreundlichkeit
Apr 16, 2025 am 12:12 AM
Python eignet sich besser für Anfänger mit einer reibungslosen Lernkurve und einer kurzen Syntax. JavaScript ist für die Front-End-Entwicklung mit einer steilen Lernkurve und einer flexiblen Syntax geeignet. 1. Python-Syntax ist intuitiv und für die Entwicklung von Datenwissenschaften und Back-End-Entwicklung geeignet. 2. JavaScript ist flexibel und in Front-End- und serverseitiger Programmierung weit verbreitet.
 PHP und Python: Ein tiefes Eintauchen in ihre Geschichte
Apr 18, 2025 am 12:25 AM
PHP und Python: Ein tiefes Eintauchen in ihre Geschichte
Apr 18, 2025 am 12:25 AM
PHP entstand 1994 und wurde von Rasmuslerdorf entwickelt. Es wurde ursprünglich verwendet, um Website-Besucher zu verfolgen und sich nach und nach zu einer serverseitigen Skriptsprache entwickelt und in der Webentwicklung häufig verwendet. Python wurde Ende der 1980er Jahre von Guidovan Rossum entwickelt und erstmals 1991 veröffentlicht. Es betont die Lesbarkeit und Einfachheit der Code und ist für wissenschaftliche Computer, Datenanalysen und andere Bereiche geeignet.
 So führen Sie Programme in der terminalen VSCODE aus
Apr 15, 2025 pm 06:42 PM
So führen Sie Programme in der terminalen VSCODE aus
Apr 15, 2025 pm 06:42 PM
Im VS -Code können Sie das Programm im Terminal in den folgenden Schritten ausführen: Erstellen Sie den Code und öffnen Sie das integrierte Terminal, um sicherzustellen, dass das Codeverzeichnis mit dem Terminal Working -Verzeichnis übereinstimmt. Wählen Sie den Befehl aus, den Befehl ausführen, gemäß der Programmiersprache (z. B. Pythons Python your_file_name.py), um zu überprüfen, ob er erfolgreich ausgeführt wird, und Fehler auflösen. Verwenden Sie den Debugger, um die Debugging -Effizienz zu verbessern.
