

So optimieren Sie die Join-Anweisung in MySQL

Einfacher Nested-Loop-Join
Werfen wir einen Blick darauf, wie MySQL bei der Durchführung einer Join-Operation funktioniert. Was sind die gängigen Join-Methoden?
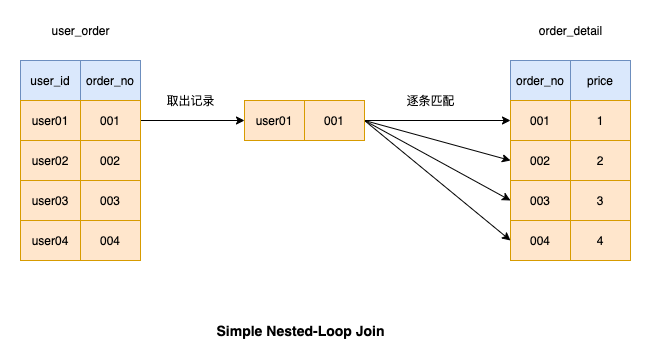
Wie im Bild gezeigt, ist die Tabelle auf der linken Seite, wenn wir den Verbindungsvorgang ausführen Angesteuerte Tabelle , und die Tabelle auf der rechten Seite ist # 🎜🎜#driven table
Einfacher Nested-Loop-Join Bei dieser Join-Operation wird ein Datensatz aus der Treibertabelle entnommen und dann mit den Datensätzen der getriebenen Tabelle abgeglichen Wenn die Bedingungen übereinstimmen, wird das Ergebnis zurückgegeben. Fahren Sie dann mit dem Abgleichen des nächsten Datensatzes in der Treibertabelle fort, bis alle Daten in der Treibertabelle abgeglichen wurden.Weil es zeitaufwändig ist, jedes Mal Daten aus der Treibertabelle abzurufen , MySQL verwendet diesen Algorithmus nicht, um Verbindungsvorgänge auszuführen
Nested-Loop-Join blockieren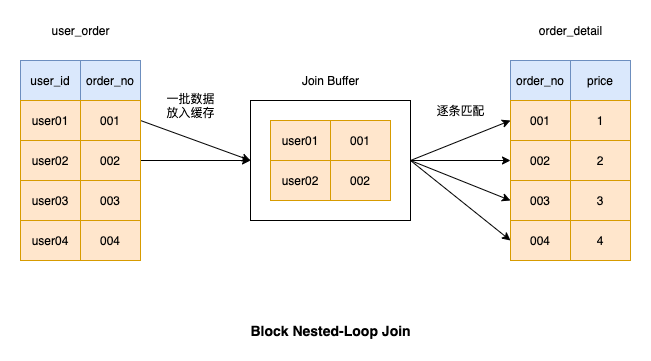
show variables like '%join_buffer%'
CREATE TABLE single_table (
id INT NOT NULL AUTO_INCREMENT,
key1 VARCHAR(100),
key2 INT,
key3 VARCHAR(100),
key_part1 VARCHAR(100),
key_part2 VARCHAR(100),
key_part3 VARCHAR(100),
common_field VARCHAR(100),
PRIMARY KEY (id),
KEY idx_key1 (key1),
UNIQUE KEY idx_key2 (key2),
KEY idx_key3 (key3),
KEY idx_key_part(key_part1, key_part2, key_part3)
) Engine=InnoDB CHARSET=utf8;
create table t1 like single_table;
create table t2 like single_table;
select * from t1 straight_join t2 on (t1.common_field = t2.common_field)
Der Ausführungsplan ist wie folgt

Block Nested-Loop Join basiert# 🎜🎜# Algorithmus
Index Nested-Loop Join # 🎜🎜#Nachdem Sie den
# 🎜🎜#Nachdem Sie den
Algorithmus verstanden haben, können Sie sehen, dass jeder Datensatz in Die Treibertabelle gleicht alle Datensätze in der gesteuerten Tabelle ab. Kann die Effizienz des gesteuerten Tabellenabgleichs verbessert werden? Ich denke, Sie haben auch an diesen Algorithmus gedacht, der darin besteht, Indizes zu den durch die gesteuerte Tabelle verbundenen Spalten hinzuzufügen, sodass der Abgleichsprozess sehr schnell ist, wie im Bild gezeigt
# 🎜🎜#
Werfen wir einen Blick darauf, wie schnell es ist, Abfragen basierend auf Verknüpfungen basierend auf Indexspalten durchzuführen. # 🎜🎜# Der Ausführungsplan lautet wie folgt Nachdem wir nun die spezifische Implementierung von Join kennen, sprechen wir über eine häufig gestellte Frage, nämlich: Wie wählt man die Treibertabelle aus? Wenn der Join-Puffer groß genug ist, Wer macht das? Die Treibertabelle hat keinen Einfluss weniger Daten und die Häufigkeit, mit der sie in den Join-Puffer gestellt werden, ist gering, was die Anzahl der Scans der Tabelle verringert ein Index Nested-Loop Join-Algorithmus #🎜🎜; #Jede Datenzeile in der treibenden Tabelle muss einmal in der getriebenen Tabelle durchsucht werden. Die ungefähre Komplexität des gesamten Ausführungsprozesses beträgt M + M &lowast 2 ∗ 2∗log2N Kurz gesagt, wir können die kleine Tabelle als Treibertabelle verwenden. Wenn die Join-Anweisung langsam ausgeführt wird, können wir sie mit den folgenden Methoden optimieren: Beim Ausführen der Join-Operation kann die gesteuerte Tabelle dies tun verwendet werden Index Verwenden Sie eine kleine Tabelle als Treibertabelle Erhöhen Sie die Größe des Join-Puffers Verwenden Sie * nicht als Abfrageliste, sondern geben Sie nur die erforderlichen Spalten zurück Das obige ist der detaillierte Inhalt vonSo optimieren Sie die Join-Anweisung in MySQL. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!select * from t1 straight_join t2 on (t1.id = t2.id)
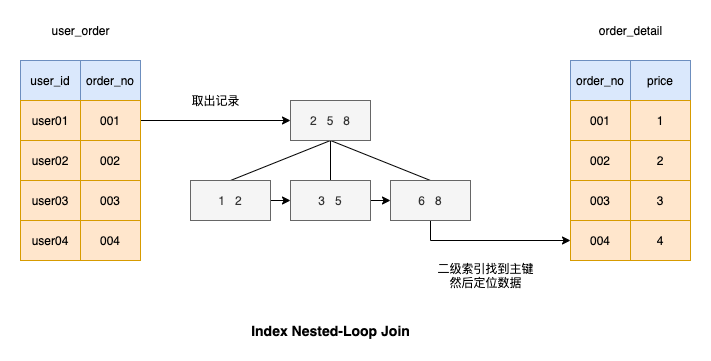
 Wie wähle ich die Treibertabelle aus?
Wie wähle ich die Treibertabelle aus?  Angenommen, die Anzahl der Zeilen der Treibertabelle ist M, daher müssen M Zeilen der Treibertabelle gescannt werden
Angenommen, die Anzahl der Zeilen der Treibertabelle ist M, daher müssen M Zeilen der Treibertabelle gescannt werden

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 MySQL: Die einfache Datenverwaltung für Anfänger
Apr 09, 2025 am 12:07 AM
MySQL: Die einfache Datenverwaltung für Anfänger
Apr 09, 2025 am 12:07 AM
MySQL ist für Anfänger geeignet, da es einfach zu installieren, leistungsfähig und einfach zu verwalten ist. 1. Einfache Installation und Konfiguration, geeignet für eine Vielzahl von Betriebssystemen. 2. Unterstützung grundlegender Vorgänge wie Erstellen von Datenbanken und Tabellen, Einfügen, Abfragen, Aktualisieren und Löschen von Daten. 3. Bereitstellung fortgeschrittener Funktionen wie Join Operations und Unterabfragen. 4. Die Leistung kann durch Indexierung, Abfrageoptimierung und Tabellenpartitionierung verbessert werden. 5. Backup-, Wiederherstellungs- und Sicherheitsmaßnahmen unterstützen, um die Datensicherheit und -konsistenz zu gewährleisten.
 Wie man phpmyadmin öffnet
Apr 10, 2025 pm 10:51 PM
Wie man phpmyadmin öffnet
Apr 10, 2025 pm 10:51 PM
Sie können PhpMyAdmin in den folgenden Schritten öffnen: 1. Melden Sie sich beim Website -Bedienfeld an; 2. Finden und klicken Sie auf das Symbol phpmyadmin. 3. Geben Sie MySQL -Anmeldeinformationen ein; 4. Klicken Sie auf "Login".
 MySQL und SQL: Wesentliche Fähigkeiten für Entwickler
Apr 10, 2025 am 09:30 AM
MySQL und SQL: Wesentliche Fähigkeiten für Entwickler
Apr 10, 2025 am 09:30 AM
MySQL und SQL sind wesentliche Fähigkeiten für Entwickler. 1.MYSQL ist ein Open -Source -Relational Database Management -System, und SQL ist die Standardsprache, die zum Verwalten und Betrieb von Datenbanken verwendet wird. 2.MYSQL unterstützt mehrere Speichermotoren durch effiziente Datenspeicher- und Abruffunktionen, und SQL vervollständigt komplexe Datenoperationen durch einfache Aussagen. 3. Beispiele für die Nutzung sind grundlegende Abfragen und fortgeschrittene Abfragen wie Filterung und Sortierung nach Zustand. 4. Häufige Fehler umfassen Syntaxfehler und Leistungsprobleme, die durch Überprüfung von SQL -Anweisungen und Verwendung von Erklärungsbefehlen optimiert werden können. 5. Leistungsoptimierungstechniken umfassen die Verwendung von Indizes, die Vermeidung vollständiger Tabellenscanning, Optimierung von Join -Operationen und Verbesserung der Code -Lesbarkeit.
 So erstellen Sie Navicat Premium
Apr 09, 2025 am 07:09 AM
So erstellen Sie Navicat Premium
Apr 09, 2025 am 07:09 AM
Erstellen Sie eine Datenbank mit Navicat Premium: Stellen Sie eine Verbindung zum Datenbankserver her und geben Sie die Verbindungsparameter ein. Klicken Sie mit der rechten Maustaste auf den Server und wählen Sie Datenbank erstellen. Geben Sie den Namen der neuen Datenbank und den angegebenen Zeichensatz und die angegebene Kollektion ein. Stellen Sie eine Verbindung zur neuen Datenbank her und erstellen Sie die Tabelle im Objektbrowser. Klicken Sie mit der rechten Maustaste auf die Tabelle und wählen Sie Daten einfügen, um die Daten einzufügen.
 MySQL: Einfache Konzepte für einfaches Lernen
Apr 10, 2025 am 09:29 AM
MySQL: Einfache Konzepte für einfaches Lernen
Apr 10, 2025 am 09:29 AM
MySQL ist ein Open Source Relational Database Management System. 1) Datenbank und Tabellen erstellen: Verwenden Sie die Befehle erstellte und creatEtable. 2) Grundlegende Vorgänge: Einfügen, aktualisieren, löschen und auswählen. 3) Fortgeschrittene Operationen: Join-, Unterabfrage- und Transaktionsverarbeitung. 4) Debugging -Fähigkeiten: Syntax, Datentyp und Berechtigungen überprüfen. 5) Optimierungsvorschläge: Verwenden Sie Indizes, vermeiden Sie ausgewählt* und verwenden Sie Transaktionen.
 So erstellen Sie eine neue Verbindung zu MySQL in Navicat
Apr 09, 2025 am 07:21 AM
So erstellen Sie eine neue Verbindung zu MySQL in Navicat
Apr 09, 2025 am 07:21 AM
Sie können eine neue MySQL -Verbindung in Navicat erstellen, indem Sie den Schritten folgen: Öffnen Sie die Anwendung und wählen Sie eine neue Verbindung (Strg N). Wählen Sie "MySQL" als Verbindungstyp. Geben Sie die Hostname/IP -Adresse, den Port, den Benutzernamen und das Passwort ein. (Optional) Konfigurieren Sie erweiterte Optionen. Speichern Sie die Verbindung und geben Sie den Verbindungsnamen ein.
 So führen Sie SQL in Navicat aus
Apr 08, 2025 pm 11:42 PM
So führen Sie SQL in Navicat aus
Apr 08, 2025 pm 11:42 PM
Schritte zur Durchführung von SQL in Navicat: Verbindung zur Datenbank herstellen. Erstellen Sie ein SQL -Editorfenster. Schreiben Sie SQL -Abfragen oder Skripte. Klicken Sie auf die Schaltfläche Ausführen, um eine Abfrage oder ein Skript auszuführen. Zeigen Sie die Ergebnisse an (wenn die Abfrage ausgeführt wird).
 Navicat stellt eine Verbindung zu Datenbankfehlercode und Lösung her
Apr 08, 2025 pm 11:06 PM
Navicat stellt eine Verbindung zu Datenbankfehlercode und Lösung her
Apr 08, 2025 pm 11:06 PM
Häufige Fehler und Lösungen beim Anschließen mit Datenbanken: Benutzername oder Kennwort (Fehler 1045) Firewall -Blocks -Verbindungsverbindung (Fehler 2003) Timeout (Fehler 10060) Die Verwendung von Socket -Verbindung kann nicht verwendet werden (Fehler 1042).
