
 häufiges Problem
Schnellstart: Erste Schritte mit der Verwendung von ChatGPT und GPT-4 mit Azure OpenAI Service
häufiges Problem
Schnellstart: Erste Schritte mit der Verwendung von ChatGPT und GPT-4 mit Azure OpenAI Service
Schnellstart: Erste Schritte mit der Verwendung von ChatGPT und GPT-4 mit Azure OpenAI Service

- Azure-Abonnement – Erstellen Sie kostenlos ein Abonnement.
- Gewähren Sie Zugriff auf Azure OpenAI im erforderlichen Azure-Abonnement. Derzeit kann der Zugriff auf diesen Dienst nur über die App gewährt werden. Sie können Zugriff auf Azure OpenAI anfordern, indem Sie das Formular unter https://aka.ms/oai/access ausfüllen. Öffnen Sie ein Problem in diesem Repository, um uns zu kontaktieren, wenn Sie auf Probleme stoßen.
- Haben oder
gpt-35-turbogpt-41 Modell bereitgestellt. Weitere Informationen zur Modellbereitstellung finden Sie im Ressourcenbereitstellungshandbuch.gpt-35-turbogpt-41已部署的模型。有关模型部署的更多信息,请参阅资源部署指南。
1 GPT-4 型号目前仅应要求提供。若要访问这些模型,现有 Azure OpenAI 客户可以通过填写此表单来申请访问权限。
我遇到了先决条件问题。
转到 Azure OpenAI Studio
导航到 Azure OpenAI Studio https://oai.azure.com/,并使用有权访问 OpenAI 资源的凭据登录。在登录工作流程中或后续,要选择相关的目录、Azure订阅以及Azure OpenAI资源。
在 Azure OpenAI Studio 登陆页中,选择“聊天操场”。
操场
使用无代码方法,通过 Azure OpenAI Studio 的聊天操场,开始探索 OpenAI 功能。在此页面中,可以快速迭代和试验这些功能。
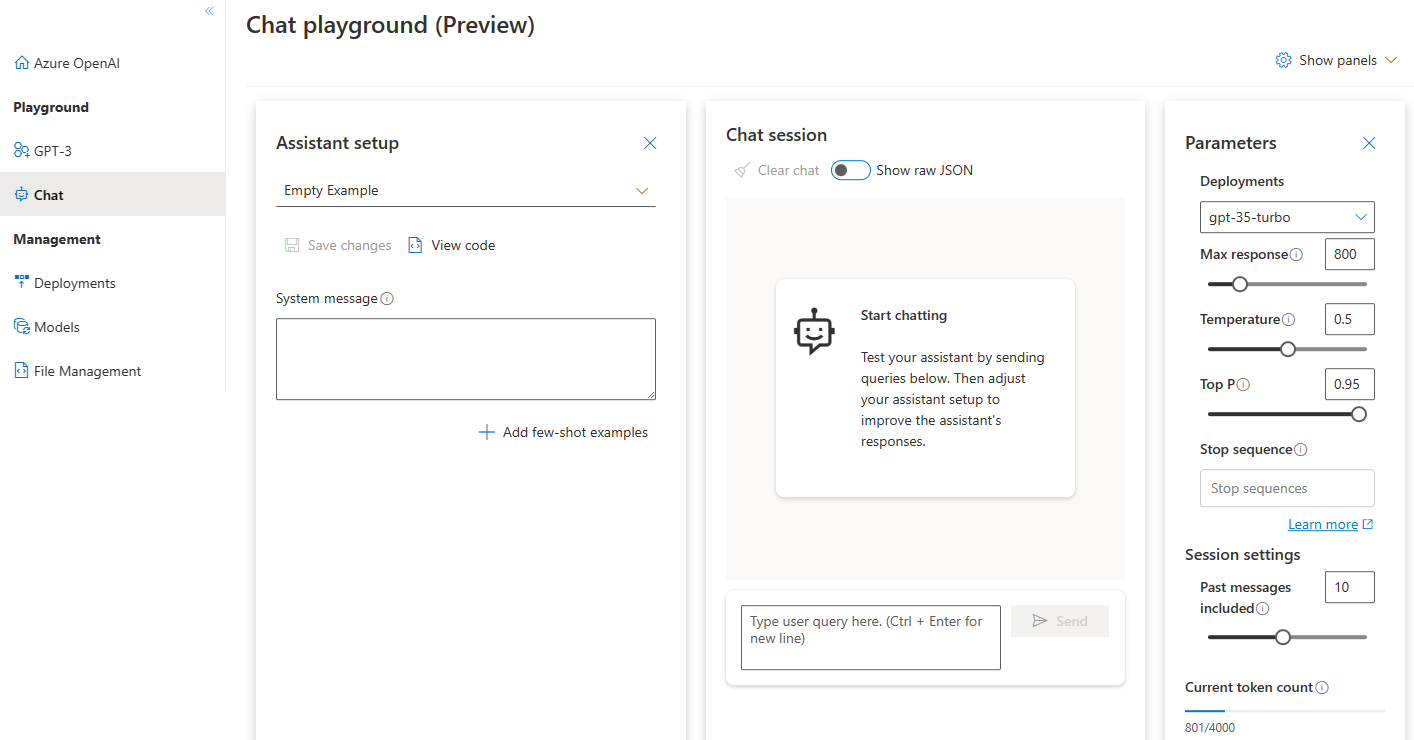
助手设置
您可以使用“助理设置”下拉列表选择一些预加载的系统消息示例以开始使用。
系统消息为模型提供有关其行为方式以及在生成响应时应引用的任何上下文的说明。你可以描述助手的个性,告诉它应该回答什么,不应该回答什么,并告诉它如何格式化回答。
添加少数镜头示例允许您提供模型用于上下文学习的对话示例。
在使用聊天操场时,您可以随时选择“查看代码”,以查看根据当前聊天会话和设置选择预填充的 Python、curl 和 json 代码示例。然后,您可以获取此代码并编写一个应用程序来完成您当前在操场上执行的相同任务。
聊天会话
选择“发送”按钮会将输入的文本发送到完成 API,结果将返回到文本框。
选择“清除聊天”按钮以删除当前对话历史记录。
设置
| 名字 | 描述 |
|---|---|
| 部署 | 与特定模型关联的部署名称。对于 ChatGPT,您需要使用该模型。gpt-35-turbo
|
| 温度 | 控制随机性。降低温度意味着模型会产生更多重复性和确定性的响应。升高温度会导致更多意想不到或创造性的反应。尝试调整温度或顶部P,但不要同时调整两者。 |
| 最大长度(令牌) | 对每个模型响应的令牌数设置限制。API 支持在提示(包括系统消息、示例、消息历史记录和用户查询)和模型响应之间共享最多 4096 个令牌。对于典型的英语文本,一个标记大约是四个字符。 |
| 最高概率 | 与温度类似,这控制随机性,但使用不同的方法。降低顶部 P 会将模型的令牌选择范围缩小到更有可能的令牌。增加顶部 P 允许模型从具有高可能性和低可能性的令牌中进行选择。尝试调整温度或顶部P,但不要同时调整两者。 |
| 多轮对话 | 选择要包含在每个新 API 请求中的过去消息数。这有助于为新用户查询提供模型上下文。将此数字设置为 10 会导致 <> 个用户查询和 <> 个系统响应。 |
| 停止序列 | 停止序列使模型在所需点结束其响应。模型响应在指定的序列之前结束,因此它不包含停止序列文本。对于 ChatGPT,使用可确保模型响应不会生成后续用户查询。最多可以包含四个停止序列。<|im_end|>1 Das GPT-4-Modell ist derzeit nur auf Anfrage erhältlich. Um auf diese Modelle zuzugreifen, können bestehende Azure OpenAI-Kunden den Zugriff anfordern, indem sie dieses Formular ausfüllen. |
#🎜🎜#
Playground
Verwenden Sie einen No-Code-Ansatz, um mit der Erkundung der OpenAI-Funktionen über den Chat-Playground von Azure OpenAI Studio zu beginnen . Auf dieser Seite können Sie diese Funktionen schnell iterieren und experimentieren. #🎜🎜#
Assistant Setup
Sie können „Assistant Setup“ verwenden. In der Dropdown-Liste werden einige vorinstallierte Systemnachrichten-Beispiele ausgewählt, um loszulegen. #🎜🎜#
Systemnachrichten geben dem Modell Anweisungen dazu, wie es sich verhalten soll und auf welchen Kontext es sich bei der Generierung von Antworten beziehen soll. Sie können die Persönlichkeit des Assistenten beschreiben, ihm sagen, was er antworten soll und was nicht, und ihm sagen, wie er Antworten formatieren soll. #🎜🎜#
Minderheitsaufnahmen hinzufügenMit Beispielen können Sie Beispiele für Gespräche bereitstellen, die das Modell für kontextbezogenes Lernen verwendet. #🎜🎜#
Während Sie den Chat Playground nutzen, können Sie jederzeit Code anzeigen auswählen, um vorab ausgefüllte Python-, Curl- und JSON-Codebeispiele basierend auf Ihrer aktuellen Chat-Sitzung und Einstellungsauswahl anzuzeigen . Anschließend können Sie diesen Code verwenden und eine Anwendung schreiben, die dieselbe Aufgabe erfüllt, die Sie derzeit auf dem Spielplatz ausführen. #🎜🎜#
Chat-Sitzung
Durch Auswahl der Schaltfläche Senden wird der eingegebene Text an die Complete API gesendet. Das Ergebnis wird in das Textfeld zurückgegeben. #🎜🎜#
Wählen Sie die Schaltfläche „Chat löschen“, um den aktuellen Konversationsverlauf zu löschen. #🎜🎜#
Einstellungen
| Beschreibung | #🎜🎜#|
|---|---|
| Deployment#🎜🎜 # | Der Bereitstellungsname, der einem bestimmten Modell zugeordnet ist. Für ChatGPT müssen Sie dieses Modell verwenden. gpt-35-turbo#🎜🎜##🎜🎜# |
| Temperatur#🎜🎜# | Zufälligkeit kontrollieren. Durch die Senkung der Temperatur erzeugt das Modell eine wiederholbarere und deterministischere Reaktion. Eine Erhöhung der Temperatur kann zu unerwarteteren oder kreativeren Reaktionen führen. Versuchen Sie, entweder die Temperatur oder den oberen P-Wert anzupassen, aber nicht beides. #🎜🎜##🎜🎜# |
| Maximale Länge (Tokens) #🎜🎜# | Legt ein Limit für die Anzahl der Token pro Modellantwort fest. Die API unterstützt die gemeinsame Nutzung von bis zu 4096 Tokens zwischen Eingabeaufforderungen (einschließlich Systemmeldungen, Beispielen, Nachrichtenverlauf und Benutzerabfragen) und Modellantworten. Für typischen englischen Text besteht ein Token aus etwa vier Zeichen. #🎜🎜##🎜🎜# |
| Höchste Wahrscheinlichkeit #🎜🎜# | Ähnlich wie die Temperatur steuert dies die Zufälligkeit, verwendet jedoch eine andere Methode. Durch Absenken des oberen P wird die Token-Auswahl des Modells auf wahrscheinlichere Token eingeschränkt. Durch Erhöhen des oberen P kann das Modell zwischen Token mit hoher und niedriger Wahrscheinlichkeit wählen. Versuchen Sie, entweder die Temperatur oder den oberen P einzustellen, aber nicht beides. #🎜🎜##🎜🎜# |
| Mehrere Gesprächsrunden #🎜🎜# | Wählen Sie die Anzahl vergangener Nachrichten aus, die in jede neue API-Anfrage einbezogen werden sollen. Dies trägt dazu bei, Modellkontext für neue Benutzerabfragen bereitzustellen. Das Festlegen dieser Zahl auf 10 führt zu <> Benutzeranfragen und <> #🎜🎜##🎜🎜# |
| Stoppsequenz #🎜🎜# | Die Stoppsequenz bewirkt, dass das Modell seine Reaktion am gewünschten Punkt beendet. Die Modellantwort endet vor der angegebenen Sequenz und enthält daher keinen Stoppsequenztext. Bei ChatGPT stellt die Verwendung sicher, dass Modellantworten keine nachfolgenden Benutzeranfragen generieren. Es können bis zu vier Stoppsequenzen enthalten sein. <|im_end|>#🎜🎜##🎜🎜##🎜🎜##🎜🎜#AnzeigebereicheStandardmäßig gibt es drei Bereiche: Assistenteneinstellungen, Chat-Sitzungen und Einstellungen. Mit Show Panels können Sie Panels hinzufügen, entfernen und neu anordnen. Wenn Sie jemals ein Panel geschlossen haben und es wiederherstellen müssen, verwenden Sie „Panel anzeigen“ , um Ihr verlorenes Panel wiederherzustellen. Starten Sie eine Chat-Sitzung
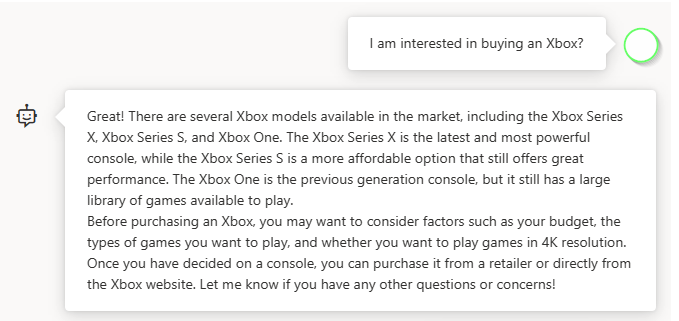
Ich bin auf ein Problem mit dem Spielplatz gestoßen. Verstehen Sie die Eingabeaufforderungsstruktur Wenn Sie Überprüfen SieBeispiel im Code anzeigen Sie werden feststellen, dass es einige eindeutige Token gibt, die nicht Teil des typischen GPT-Vervollständigungsaufrufs sind. ChatGPT ist darauf trainiert, die verschiedenen Teile des dem Modell bereitgestellten Hinweises zu beschreiben beginnt mit einer Systemnachricht. Die Nachricht kann zum Starten eines Modells verwendet werden, indem ein Kontext oder eine Beschreibung des Modells eingefügt wird. Die Eingabeaufforderung enthält dann eine Folge von Nachrichten zwischen dem Benutzer und dem Assistenten Die Antwort des Assistenten auf die Eingabeaufforderung wird dann unter dem Token zurückgegeben und endet mit einem Signal, dass der Assistent die Antwort abgeschlossen hat. Sie können sie auch über die Umschalttaste „Originalsyntax anzeigen“ im Chat-Sitzungsbereich anzeigen . 然后,助手对提示的响应将在令牌下方返回,并以表示助手已完成响应结束。您还可以使用显示原始语法切换按钮在聊天会话面板中显示这些令牌。 ChatGPT 操作指南深入介绍了新的提示结构以及如何有效地使用该模型。 清理资源完成聊天操场的测试后,如果要清理和删除 OpenAI 资源,可以删除资源或资源组。删除资源组也会删除与其关联的任何其他资源。
后续步骤
Reinigen Sie die RessourcenWeitere Beispiele finden Sie im Azure OpenAI-Beispiel-GitHub-Repository. Verwandte Artikel. Was ist Azure OpenAI Service?
|
 Geben Sie eine Folgefrage ein, z. B.: „Welche Modelle unterstützen 4K?
Geben Sie eine Folgefrage ein, z. B.: „Welche Modelle unterstützen 4K? 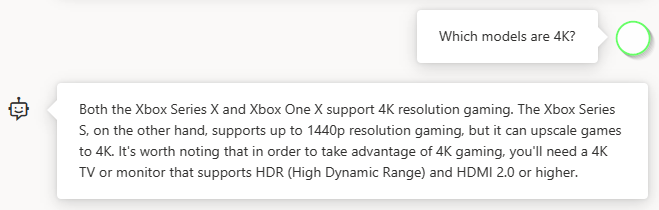 Nachdem Sie nun ein grundlegendes Gespräch geführt haben, wählen Sie
Nachdem Sie nun ein grundlegendes Gespräch geführt haben, wählen Sie 

Das obige ist der detaillierte Inhalt vonSchnellstart: Erste Schritte mit der Verwendung von ChatGPT und GPT-4 mit Azure OpenAI Service. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1371
1371
 52
52

 Eingehende Suche in Deepseek Offizieller Website Eingang
Mar 12, 2025 pm 01:33 PM
Eingehende Suche in Deepseek Offizieller Website Eingang
Mar 12, 2025 pm 01:33 PM
Zu Beginn des Jahres 2025 gab die inländische KI "Deepseek" ein atemberaubendes Debüt! Dieses kostenlose und Open-Source-KI-Modell verfügt über eine Leistung, die mit der offiziellen Version von OpenAI von O1 vergleichbar ist, und wurde vollständig auf Webseite, App und API gestartet, wobei die multi-terminale Verwendung von iOS-, Android- und Webversionen unterstützt wird. Eingehende Suche nach Deepseek Official Website und Nutzungsleitfaden: Offizielle Website-Adresse: https://www.deepseek.com/using-Schritte für Webversion: Klicken Sie auf den obigen Link, um die offizielle Website der Deepseek einzugeben. Klicken Sie auf der Homepage auf die Schaltfläche "Konversation starten". Für die erste Verwendung müssen Sie sich mit Ihrem Mobiltelefonverifizierungscode anmelden. Nach dem Anmeldung können Sie die Dialog -Schnittstelle eingeben. Deepseek ist leistungsfähig, kann Code schreiben, Datei lesen und Code erstellen
 Deepseek Web Version Offizieller Eingang
Mar 12, 2025 pm 01:42 PM
Deepseek Web Version Offizieller Eingang
Mar 12, 2025 pm 01:42 PM
Das inländische AI Dark Horse Deepseek ist stark gestiegen und schockiert die globale KI -Industrie! Dieses chinesische Unternehmen für künstliche Intelligenz, das nur seit anderthalb Jahren gegründet wurde, hat von globalen Nutzern für seine kostenlosen und Open-Source-Modelle Deepseek-V3 und Deepseek-R1 ein breites Lob erhalten. Deepseek-R1 ist jetzt vollständig gestartet, wobei die Leistung mit der offiziellen Version von Openaio1 vergleichbar ist! Sie können seine leistungsstarken Funktionen auf der Webseite, der App und der API -Schnittstelle erleben. Download -Methode: Unterstützt iOS- und Android -Systeme können Benutzer sie über den App Store herunterladen. Deepseek Web Version Offizieller Eingang: HT
 So lösen Sie das Problem vielbeschäftigter Server für Deepseek
Mar 12, 2025 pm 01:39 PM
So lösen Sie das Problem vielbeschäftigter Server für Deepseek
Mar 12, 2025 pm 01:39 PM
Deepseek: Wie kann man mit der beliebten KI umgehen, die von Servern überlastet ist? Als heiße KI im Jahr 2025 ist Deepseek frei und Open Source und hat eine Leistung, die mit der offiziellen Version von OpenAio1 vergleichbar ist, die seine Popularität zeigt. Eine hohe Parallelität bringt jedoch auch das Problem der Serververantwortung. Dieser Artikel wird die Gründe analysieren und Bewältigungsstrategien bereitstellen. Eingang der Deepseek -Webversion: https://www.deepseek.com/deepseek Server Beschäftigter Grund: Hoher Zugriff: Deepseeks kostenlose und leistungsstarke Funktionen ziehen eine große Anzahl von Benutzern an, die gleichzeitig verwendet werden können, was zu einer übermäßigen Last von Server führt. Cyber -Angriff: Es wird berichtet, dass Deepseek Auswirkungen auf die US -Finanzbranche hat.