

Was sind die Wissenspunkte zum Lesen des Seitenpufferpools in MySQL?

Pufferpool
Wir alle wissen, dass wir beim Lesen einer Seite zuerst die Seite von der Festplatte in den Speicher lesen und dann warten müssen, bis die CPU die Daten verarbeitet. Das Lesen von Daten von der Festplatte in den Speicher ist sehr langsam, daher müssen die von uns gelesenen Seiten zwischengespeichert werden, sodass MySQL über diesen Pufferpool zum Zwischenspeichern der Seiten verfügt.
Zunächst beantragt MySQL beim Start einen kontinuierlichen Speicherplatz vom Betriebssystem. Dieser Speicherplatz wird als Pufferpool verwendet. Legen Sie die zwischengespeicherten Seiten in den Pufferpool und verwalten Sie sie.
mysql> show variables like 'innodb_buffer_pool_size'; +-------------------------+-----------+ | Variable_name | Value | +-------------------------+-----------+ | innodb_buffer_pool_size | 134217728 | +-------------------------+-----------+ 1 row in set, 1 warning (0.00 sec)
Wir können sehen, dass der Standardwert 134217728 Bytes ist, was 128 MB entspricht. Wenn die von uns beantragte Cache-Größe ein Vielfaches von 16 KB ist, entsteht kein Fragmentierungsproblem, da jede Seite 16 KB groß ist.
Zusammensetzung des Pufferpools
Jede Seite enthält die entsprechenden Steuerblockinformationen, die im Pufferpool gespeichert werden. Jeder Steuerblock verwaltet jede Seite (wir verwenden die Adresse, um auf jede Seite zu verweisen). Der Steuerblock wird zum Speichern einiger Informationen über die Seite verwendet. Die belegte Größe des Steuerblocks ist nicht in innodb_buffer_pool_size enthalten. MySQL beantragt beim Start zusätzlichen Speicherplatz.
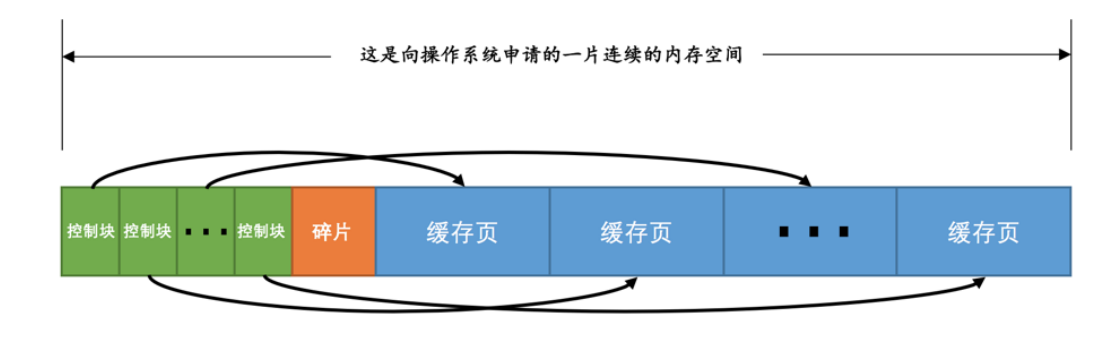
Da der Speicherplatz nicht vollständig genutzt werden kann, kommt es zu einer unregelmäßigen Fragmentierung zwischen dem Steuerblock und der Cache-Seite. Da der Speicherplatz, den MySQL auf das Betriebssystem anwendet, eine bestimmte Größe des Steuerblockraums erfordert und die spezifische Größe nicht bestimmt werden kann, ist es unvermeidlich, dass nicht nutzbarer Speicherplatz vorhanden ist.
kostenlose verknüpfte Liste
kostenlose verknüpfte Liste ist, wie der Name schon sagt, eine verknüpfte Liste, die kostenlose Cache-Seiten verwaltet. Wenn die Cache-Seite nicht verwendet wird, wird ihr Steuerblock mit der kostenlosen verknüpften Liste verbunden.
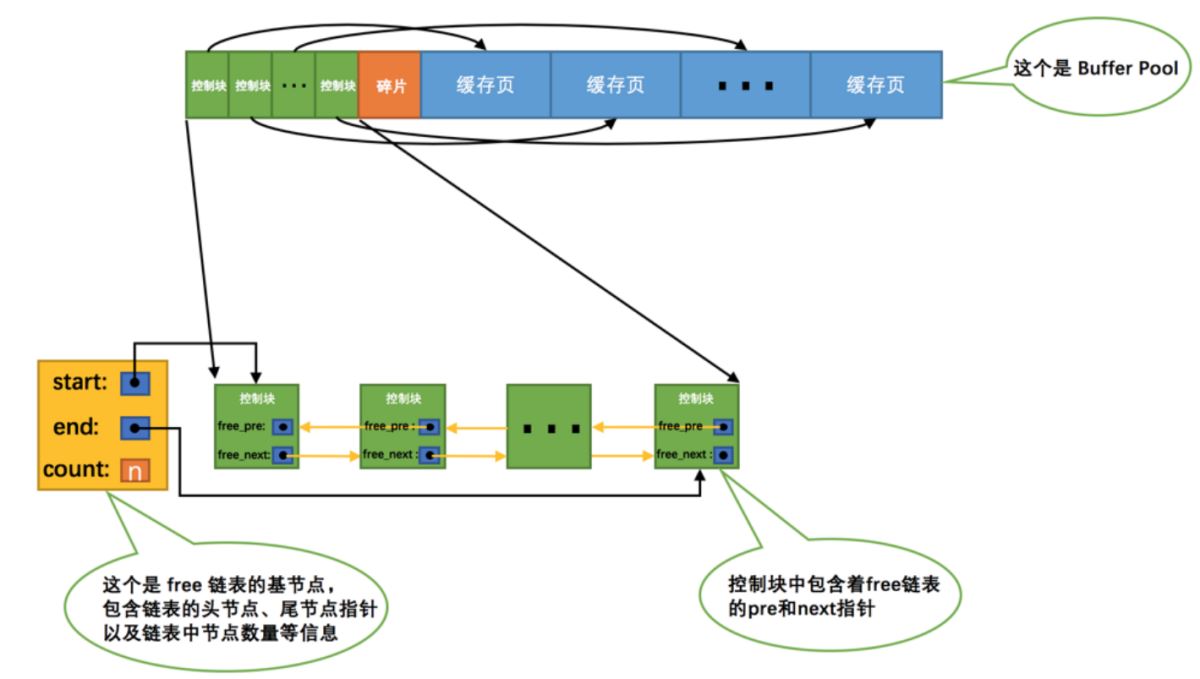
Verbinden Sie den Steuerblock über einen Basisknoten, um eine freie verknüpfte Liste zu bilden, und speichern Sie grundlegende Informationen wie die Anzahl der freien Seiten.
Wenn wir eine Seite von der Festplatte in den Pufferpool lesen, nehmen wir einen freien Steuerblock und geben die Grundinformationen der entsprechenden Cache-Seite ein.
Hash-Verarbeitung zwischengespeicherter Seiten
Wie greift MySQL schnell auf eine Seite im Pufferpool zu und prüft, ob die entsprechende Seite im Pufferpool zwischengespeichert wurde?
Hierbei wird eine Hash-Tabelle verwendet, bei der es sich um eine Hashmap in Java handelt. Sie verarbeitet den Tabellenbereich + die Seitennummer, um einen Hash-Schlüsselwert zu bilden, und der Wertwert ist dann die Adresse der Cache-Seite im Pufferpool.
Verwaltung von Flush-Linked-Listen
Ich war schockiert, als ich dieses Kapitel erfuhr, und das spätere MVCC öffnete mir wirklich die Augen. Ich werde es später zusammenfassen, damit es prägnanter und auf den Punkt kommt.
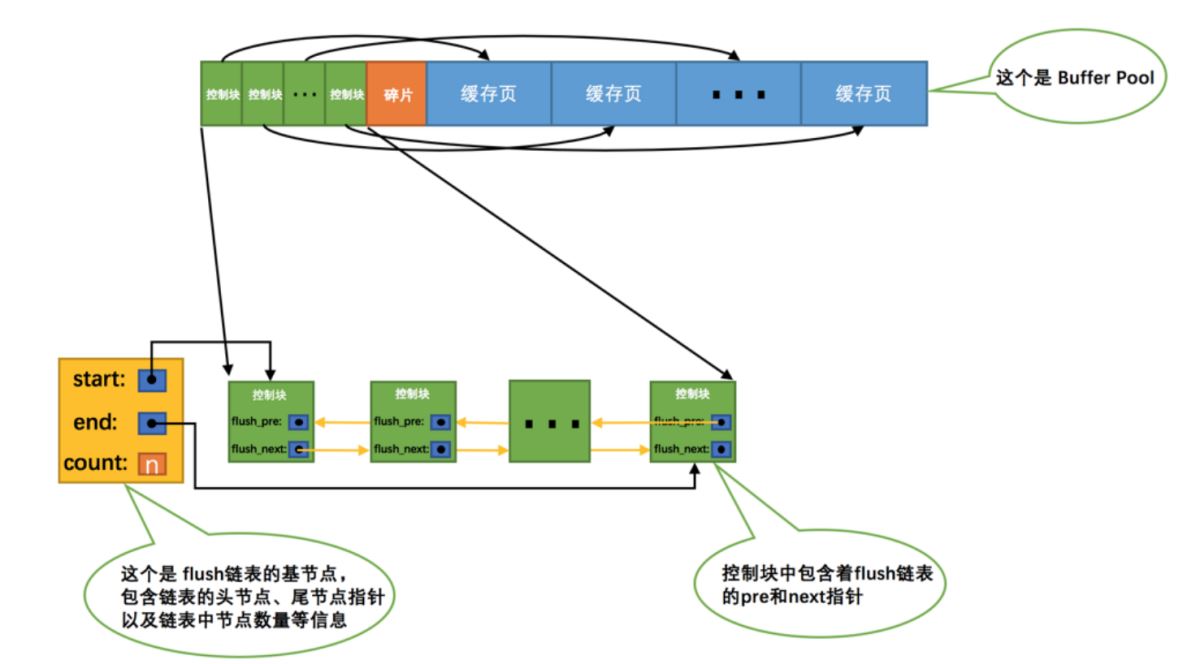
Wenn wir SQL-Anweisungen verwenden, um einen bestimmten Datensatz zu ändern, ändern wir eine bestimmte Seite oder mehrere Seiten. Wenn wir die Seite ändern, nehmen wir keine entsprechenden Änderungen an der Festplatte vor, da die Festplatten-E/A sehr schwierig ist zu langsam. Wir werden zuerst die geänderten Seiten (kurz: schmutzige Seiten) verknüpfen, was der freien verknüpften Liste ähnelt. Es handelt sich um einen Basisknoten, der die den schmutzigen Seiten entsprechenden Steuerblöcke miteinander verbindet.
Diese leere verknüpfte Liste stellt die verknüpfte Liste dar, bei der wir die Seite noch nicht auf der Festplatte aktualisiert haben.
LRU-verknüpfte Liste
Da die Größe des Pufferpools begrenzt ist, ist auch die Größe unserer Cache-Seiten begrenzt, sodass wir nicht verwendete Seiten entfernen müssen. MySQL verwendet zur Eliminierung die LRU-Methode.
LRU ist die längste ungenutzte Eliminierungsstrategie. Wir verwenden eine verknüpfte Liste, um die zuletzt aufgerufenen Seiten zu verknüpfen, und die am wenigsten aufgerufenen Seiten befinden sich am Ende der verknüpften Liste , neue Seiten kommen hinzu und haben die Möglichkeit, die Seiten am Ende der verknüpften Liste zu entfernen.
Wir verwenden LRU direkt, wenn MySQL ein Vorlesen oder einen vollständigen Tabellenscan durchführt, wird eine große Anzahl von Seiten mit niedriger Häufigkeit in die LRU-verknüpfte Liste eingelesen, was dazu führt, dass Seiten mit hoher Häufigkeit direkt entfernt und selten durch einige ersetzt werden verwendete Seiten.
Der MySQL-Optimierer lädt Seiten, auf die voraussichtlich durch Abfragen zugegriffen wird, vorab in den Speicherpufferpool, um die Abfrageleistung zu verbessern. Es kann in zwei Typen unterteilt werden:
Lineares Vorauslesen
Wenn das Lesen von Seiten in einer Zone den Wert der Systemvariablen innodb_read_ahead_threshold überschreitet, ist der Standardwert 56, dh wenn wir Seiten lesen in einer Zone mehr als 56 Seiten, MySQL Alle Seiten im nächsten Bereich werden asynchron in den Speicher gelesen.
Zufälliges Vorauslesen
Wenn der Pufferpool 13 Seiten in einem bestimmten Bereich zwischengespeichert hat, unabhängig davon, ob sie sequentiell sind oder nicht, wird MySQL veranlasst, alle Seiten zu lesen, solange 13 Seiten zwischengespeichert sind Seiten in diesem Bereich asynchron in MySQL importieren. Die Systemvariable innodb_random_read_ahead kann so eingestellt werden, dass das zufällige Vorauslesen deaktiviert wird. Die Standardeinstellung ist AUS.
Es gibt also eine verbesserte partitionsbasierte LRU-verknüpfte Liste, die die verknüpfte Liste in zwei Teile unterteilt.
Das eine ist der junge Bereich, der sehr häufig genutzt wird, und das andere ist der alte Bereich, der nicht sehr häufig genutzt wird.
正常来说old区占比是37%,所以young区就占63%,我们可以通过innodb_old_blocks_pct来修改,默认就是37。
我们来讲讲这个基于分区的LRU链表。
首先buffer pool初始化,会将读取的页面直接放进old区。
但是如果我们对于同一个页面的多条记录进行访问的话,我们就会多次访问同一页多次。但是如果我们是全表扫描的话,是可能会将所有页面缓存进缓存池中的,所以MySQL对于其进行优化。
所以MySQL对于当页面第一次读入old区并在一定时间间隔(innodb_old_blocks_pct)内的多次访问来说是不会将其放入young区进行缓存的。innodb_old_blocks_pct的值默认为1000,就是刚来的来一秒内的多次访问是不会将其转移到young区的。
如果多次访问就会将old区的页升级到young区。当young区的页面被访问,只有young链表后1/4的页面被访问时才会将其转置到young区链表头,不然就不会改动,减少一些调整链表的性能损失。
刷新脏页
MySQL会启动后台线程进行脏页,也就是修改的页面进行刷新到磁盘。
以下有两种方式刷新脏页:
从LRU的尾部扫描一些页面,刷新其中的脏页到磁盘中。
在LRU链表的old区域尾部,即不经常使用的页面中,后台线程会查找是否存在脏页,如果有,则将其更新至磁盘。控制扫描区域尾部数量的方法是更改系统变量innodb_lru_scan_depth。
从flush链表中更新到磁盘。
我们上面说了flush连接这脏页的控制块,我们就可以将连接这flush链表的脏页进行更新。
疑问:为什么要两种方式更新呢?我刚开始不懂这是我回过头来看的时候就懂了
首先我们脏页是缓存在buffer pool中的,但是我们buffer pool空间是有限的,又因为我们使用的是LRU的方式,又因为从flush链表将脏页同步到磁盘效率实在不高,所以不会很经常去更新脏页。如果我们不更新直接将其从LRU的链表抛弃也就是从缓存池中直接扔了,但是它是脏页就无法同步到磁盘了,同时flush链表链接的也会出现问题。
所以在LRU淘汰很久未使用的页有个前提就是它不是一个脏页。为了淘汰这些页面,我们需要检查LRU链表的末尾是否存在脏页并进行更新。
flush链表更新那就是它的本职工作了,它存这个也是干这个的,应该没有什么问题。
当系统十分繁忙,buffer pool使用量不足的时候,因为磁盘IO太慢了,所以会出现一种情况,就是大量的用户线程也在进行这个同步脏页的活。如果未进行脏页同步并淘汰缓冲池的页面,则无法读取该页面。
多个buffer pool实例
我们可以设置多个buffer pool来实现多实例提高性能。
mysql> show variables like 'innodb_buffer_pool_instances'; +------------------------------+-------+ | Variable_name | Value | +------------------------------+-------+ | innodb_buffer_pool_instances | 1 | +------------------------------+-------+ 1 row in set, 1 warning (0.00 sec)
我们可以设置innodb_buffer_pool_instances系统变量来控制实例变量。
但是当buffer pool的大小小于1G的时候,设置2个实例也是没有用的(会被恢复成1个),多实例的情况是建立在大内存的情况下的。
动态调整buffer pool大小
在MySQL5.7.5后,MySQL中的buffer pool的大小是以chunk来分配了,如下图。
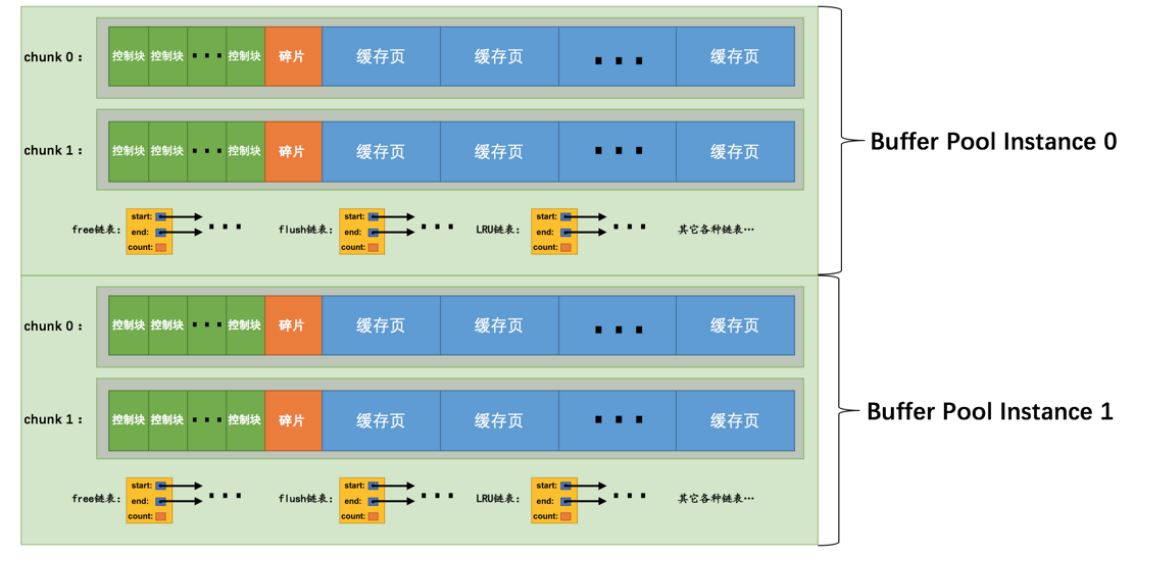
一个buffer pool是由多个chunk组成的,所以MySQL向操作系统申请连续的内存空间,就是以chunk的方式来申请的,这样我们可以在MySQL运行时调整buffer pool的大小。在运行时更改chunk大小不可行,并且会造成性能浪费。?
innodb_buffer_pool_size / innodb_buffer_pool_instances = 每个实例buffer pool的大小。
每个实例的大小 / innodb_buffer_pool_chunk_size = 每个实例由多少个chunk构成。
不是弄很明白,怎么动态调整大小,我调整了但是mysqld占用内存大小还是只能重启才能生效,我不会。
查看buffer pool具体的信息
show engine innodb status;
Das obige ist der detaillierte Inhalt vonWas sind die Wissenspunkte zum Lesen des Seitenpufferpools in MySQL?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1382
1382
 52
52

 MySQL: Einfache Konzepte für einfaches Lernen
Apr 10, 2025 am 09:29 AM
MySQL: Einfache Konzepte für einfaches Lernen
Apr 10, 2025 am 09:29 AM
MySQL ist ein Open Source Relational Database Management System. 1) Datenbank und Tabellen erstellen: Verwenden Sie die Befehle erstellte und creatEtable. 2) Grundlegende Vorgänge: Einfügen, aktualisieren, löschen und auswählen. 3) Fortgeschrittene Operationen: Join-, Unterabfrage- und Transaktionsverarbeitung. 4) Debugging -Fähigkeiten: Syntax, Datentyp und Berechtigungen überprüfen. 5) Optimierungsvorschläge: Verwenden Sie Indizes, vermeiden Sie ausgewählt* und verwenden Sie Transaktionen.
 Wie man phpmyadmin öffnet
Apr 10, 2025 pm 10:51 PM
Wie man phpmyadmin öffnet
Apr 10, 2025 pm 10:51 PM
Sie können PhpMyAdmin in den folgenden Schritten öffnen: 1. Melden Sie sich beim Website -Bedienfeld an; 2. Finden und klicken Sie auf das Symbol phpmyadmin. 3. Geben Sie MySQL -Anmeldeinformationen ein; 4. Klicken Sie auf "Login".
 MySQL: Eine Einführung in die beliebteste Datenbank der Welt
Apr 12, 2025 am 12:18 AM
MySQL: Eine Einführung in die beliebteste Datenbank der Welt
Apr 12, 2025 am 12:18 AM
MySQL ist ein Open Source Relational Database Management -System, das hauptsächlich zum schnellen und zuverlässigen Speicher und Abrufen von Daten verwendet wird. Sein Arbeitsprinzip umfasst Kundenanfragen, Abfragebedingungen, Ausführung von Abfragen und Rückgabergebnissen. Beispiele für die Nutzung sind das Erstellen von Tabellen, das Einsetzen und Abfragen von Daten sowie erweiterte Funktionen wie Join -Operationen. Häufige Fehler umfassen SQL -Syntax, Datentypen und Berechtigungen sowie Optimierungsvorschläge umfassen die Verwendung von Indizes, optimierte Abfragen und die Partitionierung von Tabellen.
 Warum MySQL verwenden? Vorteile und Vorteile
Apr 12, 2025 am 12:17 AM
Warum MySQL verwenden? Vorteile und Vorteile
Apr 12, 2025 am 12:17 AM
MySQL wird für seine Leistung, Zuverlässigkeit, Benutzerfreundlichkeit und Unterstützung der Gemeinschaft ausgewählt. 1.MYSQL bietet effiziente Datenspeicher- und Abruffunktionen, die mehrere Datentypen und erweiterte Abfragevorgänge unterstützen. 2. Übernehmen Sie die Architektur der Client-Server und mehrere Speichermotoren, um die Transaktion und die Abfrageoptimierung zu unterstützen. 3. Einfach zu bedienend unterstützt eine Vielzahl von Betriebssystemen und Programmiersprachen. V.
 So verwenden Sie ein einzelnes Gewinde -Redis
Apr 10, 2025 pm 07:12 PM
So verwenden Sie ein einzelnes Gewinde -Redis
Apr 10, 2025 pm 07:12 PM
Redis verwendet eine einzelne Gewindearchitektur, um hohe Leistung, Einfachheit und Konsistenz zu bieten. Es wird E/A-Multiplexing, Ereignisschleifen, nicht blockierende E/A und gemeinsame Speicher verwendet, um die Parallelität zu verbessern, jedoch mit Einschränkungen von Gleichzeitbeschränkungen, einem einzelnen Ausfallpunkt und ungeeigneter Schreib-intensiver Workloads.
 MySQL und SQL: Wesentliche Fähigkeiten für Entwickler
Apr 10, 2025 am 09:30 AM
MySQL und SQL: Wesentliche Fähigkeiten für Entwickler
Apr 10, 2025 am 09:30 AM
MySQL und SQL sind wesentliche Fähigkeiten für Entwickler. 1.MYSQL ist ein Open -Source -Relational Database Management -System, und SQL ist die Standardsprache, die zum Verwalten und Betrieb von Datenbanken verwendet wird. 2.MYSQL unterstützt mehrere Speichermotoren durch effiziente Datenspeicher- und Abruffunktionen, und SQL vervollständigt komplexe Datenoperationen durch einfache Aussagen. 3. Beispiele für die Nutzung sind grundlegende Abfragen und fortgeschrittene Abfragen wie Filterung und Sortierung nach Zustand. 4. Häufige Fehler umfassen Syntaxfehler und Leistungsprobleme, die durch Überprüfung von SQL -Anweisungen und Verwendung von Erklärungsbefehlen optimiert werden können. 5. Leistungsoptimierungstechniken umfassen die Verwendung von Indizes, die Vermeidung vollständiger Tabellenscanning, Optimierung von Join -Operationen und Verbesserung der Code -Lesbarkeit.
 Mysqls Platz: Datenbanken und Programmierung
Apr 13, 2025 am 12:18 AM
Mysqls Platz: Datenbanken und Programmierung
Apr 13, 2025 am 12:18 AM
Die Position von MySQL in Datenbanken und Programmierung ist sehr wichtig. Es handelt sich um ein Open -Source -Verwaltungssystem für relationale Datenbankverwaltung, das in verschiedenen Anwendungsszenarien häufig verwendet wird. 1) MySQL bietet effiziente Datenspeicher-, Organisations- und Abruffunktionen und unterstützt Systeme für Web-, Mobil- und Unternehmensebene. 2) Es verwendet eine Client-Server-Architektur, unterstützt mehrere Speichermotoren und Indexoptimierung. 3) Zu den grundlegenden Verwendungen gehören das Erstellen von Tabellen und das Einfügen von Daten, und erweiterte Verwendungen beinhalten Multi-Table-Verknüpfungen und komplexe Abfragen. 4) Häufig gestellte Fragen wie SQL -Syntaxfehler und Leistungsprobleme können durch den Befehl erklären und langsam abfragen. 5) Die Leistungsoptimierungsmethoden umfassen die rationale Verwendung von Indizes, eine optimierte Abfrage und die Verwendung von Caches. Zu den Best Practices gehört die Verwendung von Transaktionen und vorbereiteten Staten
 So wiederherstellen Sie Daten nach dem Löschen von SQL Zeilen
Apr 09, 2025 pm 12:21 PM
So wiederherstellen Sie Daten nach dem Löschen von SQL Zeilen
Apr 09, 2025 pm 12:21 PM
Das Wiederherstellen von gelöschten Zeilen direkt aus der Datenbank ist normalerweise unmöglich, es sei denn, es gibt einen Backup- oder Transaktions -Rollback -Mechanismus. Schlüsselpunkt: Transaktionsrollback: Führen Sie einen Rollback aus, bevor die Transaktion Daten wiederherstellt. Sicherung: Regelmäßige Sicherung der Datenbank kann verwendet werden, um Daten schnell wiederherzustellen. Datenbank-Snapshot: Sie können eine schreibgeschützte Kopie der Datenbank erstellen und die Daten wiederherstellen, nachdem die Daten versehentlich gelöscht wurden. Verwenden Sie eine Löschanweisung mit Vorsicht: Überprüfen Sie die Bedingungen sorgfältig, um das Verhandlich von Daten zu vermeiden. Verwenden Sie die WHERE -Klausel: Geben Sie die zu löschenden Daten explizit an. Verwenden Sie die Testumgebung: Testen Sie, bevor Sie einen Löschvorgang ausführen.
