
Double-Write-Konsistenz zwischen Redis und MySQL bezieht sich auf in dem Szenario, in dem Cache und Datenbank gleichzeitig zum Speichern von Daten verwendet werden (hauptsächlich bei hoher Parallelität), wie die Datenkonsistenz sichergestellt werden kann zwischen den beiden (der Inhalt ist derselbe oder so nah wie möglich) .
Normaler Geschäftsprozess:
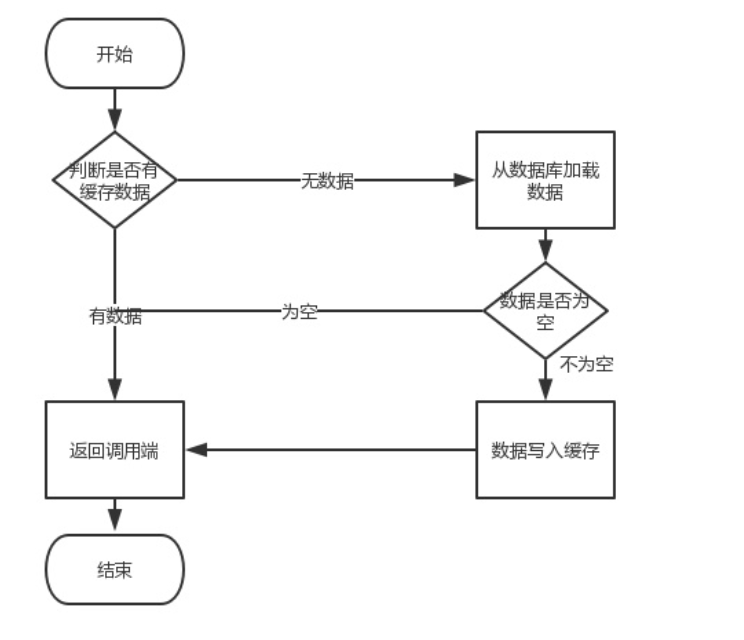
Lesen ist kein Problem, das Problem ist der Schreibvorgang (Update). Zu diesem Zeitpunkt können mehrere Probleme auftreten. Wir müssen zuerst die Datenbank aktualisieren und dann Caching-Vorgänge durchführen. Beim Umgang mit dem Cache sollten Sie überlegen, ob Sie den Cache aktualisieren oder den Cache löschen oder zuerst den Cache und dann die Datenbank aktualisieren möchten. Zusammenfassend lässt sich sagen, dass Sie zuerst den Cache und dann die Datenbank betreiben oder zuerst die Datenbank und dann der Cache?
Machen wir mit diesen Fragen weiter.
Lassen Sie uns zunächst über den Vorgangscache sprechen, der zwei Typen umfasst: Cache aktualisieren und Cache löschen. Wie wählt man aus?
Cache aktualisieren? Cache löschen?
Gehen Sie davon aus, dass die Datenbank zuerst aktualisiert wird (da es problematischer ist, zuerst den Cache und dann die Datenbank zu betreiben, was später besprochen wird). Aktualisieren Sie dann den Cache.Wenn zwei Anfragen gleichzeitig dieselben Daten ändern, sind möglicherweise alte Daten im Cache vorhanden, da ihre Reihenfolge möglicherweise umgekehrt ist. Nachfolgende Leseanforderungen lesen alte Daten, und nur wenn der Cache ungültig wird, kann der korrekte Wert aus der Datenbank abgerufen werden.
Cache löschen
Aktualisieren Sie zuerst die Datenbank und löschen Sie dann den Cache.
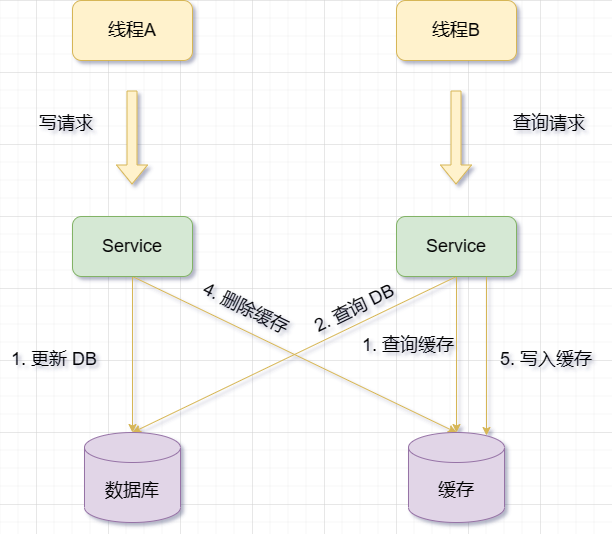
Wenn der Cache ausfällt, kann Anforderung B Daten aus der Datenbank abfragen und den alten Wert abrufen. Zu diesem Zeitpunkt wird A aufgefordert, die Datenbank zu aktualisieren, den neuen Wert in die Datenbank zu schreiben und den Cache zu löschen. Anforderung B schreibt den alten Wert in den Cache, was zu schmutzigen Daten führt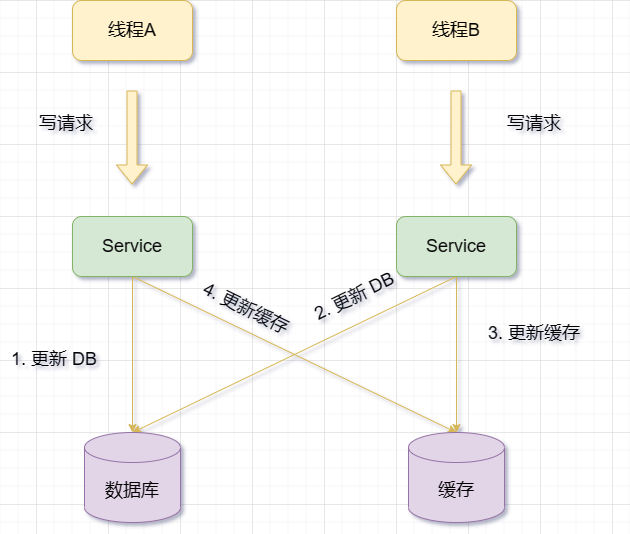
Aus dem oben Gesagten ist ersichtlich, dass die Anforderungen für schmutzige Daten höher sind als die Anforderungen für die Aktualisierung des Caches. Die folgenden Bedingungen müssen erfüllt sein:
 Leseanfrage + Schreibanfrage-Parallelität
Leseanfrage + Schreibanfrage-Parallelität
Datenbank aktualisieren + Cache löschen Zeit ist kürzer als Datenbank lesen + Schreibcache-Zeit
Die ersten beiden sind Für uns sehr zufriedenstellend. Schauen wir uns den dritten Punkt an: Wird das wirklich passieren?
Die Datenbank ist beim Aktualisieren im Allgemeinen gesperrt und die Geschwindigkeit von Lesevorgängen ist viel schneller als die von Schreibvorgängen, sodass die Wahrscheinlichkeit, dass der dritte Punkt eintritt, äußerst gering ist (natürlich kann er passieren)Hinweis: Ich habe tatsächlich Ich verstehe das einfach nicht sehr gut. Es scheint, dass die Wahrscheinlichkeit des Auftretens tatsächlich gering ist, aber wenn es zu Netzwerkverzögerungen und anderen Situationen kommt, wird es dann nicht auch passieren? Ich hoffe, dass jemand mit guten Absichten die Verwirrung beseitigen kann, aber ich verstehe es sowieso nicht. Daher müssen Sie bei der Entscheidung, den Cache zu löschen, auch andere Technologien kombinieren, um Leistung und Konsistenz zu optimieren. Zum Beispiel:
Vergleich
sofort gelesen
, was dazu führt, dass viele Daten, auf die selten zugegriffen wird, im Cache gespeichert werden . , eine Verschwendung von Cache-Ressourcen. Und in vielen Fällen stimmt der in den Cache geschriebene Wert nicht eins zu eins mit dem Wert in der Datenbank überein. Es ist sehr wahrscheinlich, dass zuerst die Datenbank abgefragt wird und dann durch eine Reihe von „Berechnungen“ ein Wert ermittelt wird. bevor der Wert in den Cache geschrieben wird.Cache-Aktualisierungsschema
nicht nur zu einer geringen Cache-Auslastung führt, sondern auch zu einer Verschwendung von Maschinenleistung führt. Daher überlegen wir im Allgemeinen:Aktualisieren Sie zuerst den Cache und dann die Datenbank.
Beim Aktualisieren von Daten: Schreiben Sie zuerst die neuen Daten in den Cache (Redis) und dann die neuen Daten in die Datenbank ( MySQL)
Aber es gibt ein Problem:
: Der Benutzer hat seinen Spitznamen geändert, das System Schreibt zuerst den neuen Spitznamen in den Cache und aktualisiert dann die Datenbank erneut. Während des Aktualisierungsprozesses der Datenbank kam es jedoch zu ungewöhnlichen Situationen wie Netzwerkausfällen oder Datenbankausfällen, was dazu führte, dass der Spitzname in der Datenbank nicht geändert wurde. Auf diese Weise stimmt der Spitzname im Cache nicht mit dem Spitznamen in der Datenbank überein.Beispiel
Das Cache-Update ist erfolgreich, aber das Datenbank-Update verzögert sich, was dazu führt, dass andere Anfragen alte Daten lesen
Beispiel: Der Benutzer gibt eine Bestellung für ein Produkt auf, in das das System zunächst den Bestellstatus schreibt den Cache und aktualisiert dann die Datenbank. Während des Aktualisierungsprozesses der Datenbank ist jedoch aufgrund großer Parallelität oder aus anderen Gründen die Schreibgeschwindigkeit der Datenbank langsamer als die Schreibgeschwindigkeit des Caches. Auf diese Weise lesen andere Anfragen den Bestellstatus als „bezahlt“ aus dem Cache, lesen jedoch den Bestellstatus als „unbezahlt“ aus der Datenbank.
Das Cache-Update ist erfolgreich, aber vor dem Datenbank-Update gibt es andere Anfragen, die den Cache und die Datenbank abfragen und die alten Daten zurück in den Cache schreiben, wodurch die neuen Daten überschrieben werden
Beispiel: Benutzer A hat seinen Avatar geändert und auf den Server hochgeladen. Das System schreibt zunächst die neue Avatar-Adresse in den Cache und gibt sie zur Anzeige an Benutzer A zurück. Aktualisieren Sie dann die neue Avatar-Adresse in der Datenbank. Während dieses Vorgangs besuchte Benutzer B jedoch die persönliche Homepage von Benutzer A und las die neue Avatar-Adresse aus dem Cache. Die Cache-Ungültigmachung kann auf die Cache-Ablaufrichtlinie oder andere Gründe zurückzuführen sein, z. B. auf Neustartvorgänge, die dazu führen, dass der Cache geleert wird oder abläuft. Zu diesem Zeitpunkt besucht Benutzer B erneut die persönliche Homepage von Benutzer A, liest die alte Avatar-Adresse aus der Datenbank und schreibt sie zurück in den Cache. Dies kann dazu führen, dass die Avatar-Adresse im Cache nicht mit der Adresse in der Datenbank übereinstimmt.
Oben wurde viel gesagt, aber die Zusammenfassung ist, dass das Cache-Update erfolgreich war, aber die Datenbank nicht aktualisiert wurde (Update fehlgeschlagen), was dazu führte, dass der Cache den neuesten Wert und das Dateninventar den alten speicherte Wert. Wenn der Cache ausfällt, wird der alte Wert in der Datenbank abgerufen.
Ich war später auch verwirrt, da das Problem durch das Scheitern der Datenbankaktualisierung verursacht wurde. Kann ich das Problem der Dateninkonsistenz einfach dadurch lösen, dass die Datenbankaktualisierung erfolgreich ist, und die Aktualisierung erneut versuchen? Datenbank, bis die Datenbankaktualisierung abgeschlossen ist.
Später stellte ich fest, dass ich zu naiv war und es viele Probleme gab, wie zum Beispiel:
Wenn der Grund für das Scheitern der Datenbankaktualisierung ein Datenbankausfall oder ein Netzwerkfehler ist, kann es sein, dass Sie ständig versuchen, die Datenbank zu aktualisieren Größerer Druck und Verzögerungen können sogar zu Schwierigkeiten bei der Datenbankwiederherstellung führen.
Wenn der Grund für das Scheitern der Datenbankaktualisierung ein Datenkonflikt oder ein Fehler in der Geschäftslogik ist, kann Ihr ständiger Versuch, die Datenbank zu aktualisieren, zu Datenverlust oder Datenverwirrung führen und sich sogar auf die Daten anderer Benutzer auswirken.
Wenn Sie immer wieder versuchen, die Datenbank zu aktualisieren, müssen Sie überlegen, wie Sie die Idempotenz und Reihenfolge der Wiederholungsversuche sicherstellen und wie Sie mit Ausnahmen umgehen, die während des Wiederholungsvorgangs auftreten.
Diese Methode ist also keine sehr gute Lösung.
Bei einem Aktualisierungsvorgang aktualisieren Sie zuerst die Datenbankdaten und dann die entsprechenden Cache-Daten.
Diese Lösung birgt jedoch auch einige Probleme und Risiken, wie z :
Wenn die Datenbank erfolgreich aktualisiert wird, die Cache-Aktualisierung jedoch fehlschlägt, bleiben die alten Daten im Cache erhalten, während die Datenbank bereits neue Daten, also schmutzige Daten, enthält.
Wenn zwischen der Aktualisierung der Datenbank und der Aktualisierung des Caches eine weitere Anfrage dieselben Daten abfragt und festgestellt wird, dass der Cache vorhanden ist, werden die alten Daten aus dem Cache gelesen. Dies führt auch zu Inkonsistenzen zwischen Cache und Datenbank.
Wenn daher der Update-Cache-Vorgang verwendet wird, egal, wer zuerst kommt, wenn in letzterem eine Ausnahme auftritt, hat dies Auswirkungen auf das Geschäft. (Standbild oben)
Wie gehe ich also mit Ausnahmen um, um die Datenkonsistenz sicherzustellen?
Die Ursache dieser Probleme liegt in der Multithread-Parallelität. Der einfachste Weg ist daher das Sperren (verteilte Sperre). . Wenn zwei Threads dieselben Daten ändern möchten, muss jeder Thread eine verteilte Sperre beantragen, bevor Änderungen vorgenommen werden. Nur der Thread, der die Sperre erhalten hat, darf die Datenbank und den Cache aktualisieren Warten Sie auf den nächsten Wiederholungsversuch. Der Grund dafür besteht darin, nur einen Thread auf Betriebsdaten und Cache zu beschränken, um Parallelitätsprobleme zu vermeiden.
Aber das Abschließen ist zeit- und arbeitsintensiv und daher definitiv nicht zu empfehlen. Darüber hinaus werden die Daten im Cache bei jeder Aktualisierung möglicherweise nicht sofort gelesen. Dies kann dazu führen, dass viele Daten, auf die selten zugegriffen wird, im Cache gespeichert werden, wodurch Cache-Ressourcen verschwendet werden. Und in vielen Fällen stimmt der in den Cache geschriebene Wert nicht eins zu eins mit dem Wert in der Datenbank überein. Es ist sehr wahrscheinlich, dass zuerst die Datenbank abgefragt wird und dann durch eine Reihe von „Berechnungen“ ein Wert ermittelt wird. bevor der Wert in den Cache geschrieben wird.
Es ist ersichtlich, dass diese Lösung aus Aktualisierung der Datenbank + Aktualisierung des Caches nicht nur eine geringe Cache-Auslastung aufweist, sondern auch eine Verschwendung von Maschinenleistung verursacht.
Zu diesem Zeitpunkt müssen wir also eine andere Option in Betracht ziehen: Cache löschen
Wenn es einen Aktualisierungsvorgang gibt, löschen Sie zuerst die entsprechenden Cache-Daten und aktualisieren Sie dann die DatenbankdatenDiese Lösung weist jedoch auch einige Probleme auf und Risiken, zum Beispiel:
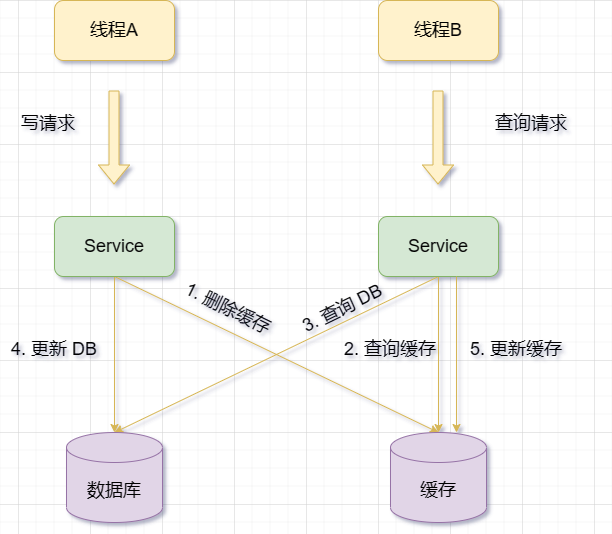
Wann Während des Aktualisierungsvorgangs werden zuerst die Datenbankdaten aktualisiert und dann der Cache gelöscht Der Cache schlägt fehl, es kann zu einer Anfrage kommen. B fragt die Daten aus der Datenbank ab und erhält den alten Wert. Zu diesem Zeitpunkt wird A aufgefordert, die Datenbank zu aktualisieren, den neuen Wert in die Datenbank zu schreiben und den Cache zu löschen. Anforderung B schreibt den alten Wert in den Cache, was zu schmutzigen Daten führt die Voraussetzungen für die Aktualisierung des Caches. Darüber hinaus müssen die folgenden Bedingungen erfüllt sein:#🎜🎜 #
Leseanfrage + Schreibanfrage-Parallelität
Datenbank aktualisieren + Cache löschen # 🎜🎜# dauert länger als #🎜 🎜#Datenbank lesen + Cache schreiben 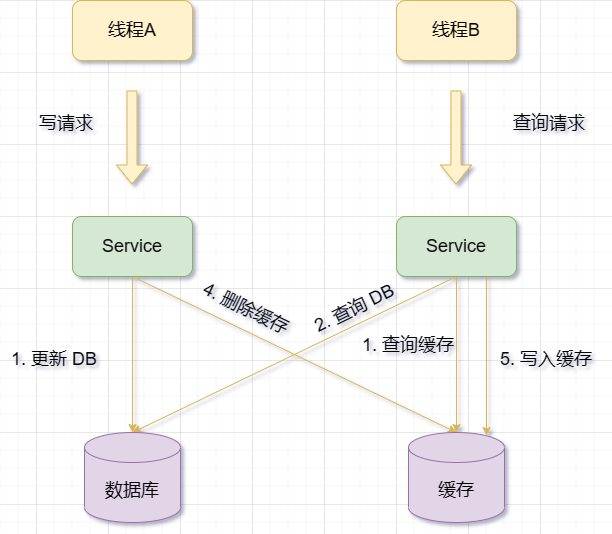 Kurz
Kurz
Die Datenbank ist beim Aktualisieren im Allgemeinen gesperrt und der Lesevorgang ist viel schneller als der Schreibvorgang, sodass die Wahrscheinlichkeit, dass der dritte Punkt auftritt, äußerst gering istFür das Doppelte -Schreibproblem. Eine geeignetere Lösung besteht darin, den Cache nach der Aktualisierung der Datenbank zu löschen. Natürlich erfordert die spezifische Situation eine spezifische Analyse und kann nicht verallgemeinert werden.
Löschen Sie zuerst den Cache, aktualisieren Sie dann die Datenbank und verwenden Sie dann einen asynchronen Thread oder eine Nachrichtenwarteschlange, um den Cache neu zu erstellen.
Aktualisieren Sie zuerst die Datenbank, löschen Sie dann den Cache und legen Sie eine angemessene Ablaufzeit fest, um die Wirksamkeit des Caches sicherzustellen. Verwenden Sie verteilte Sperren oder optimistische Sperren, um den gleichzeitigen Zugriff zu steuern und sicherzustellen, dass jeweils nur eine Anforderung den Cache und die Datenbank bedienen kann
2. Asynchroner Wiederholungsversuch
Da die Wiederholungsmethode Ressourcen beansprucht, werde ich sie asynchron durchführen. Wenn der Vorgang beim Löschen oder Aktualisieren des Caches fehlschlägt, wird nicht sofort ein Fehler zurückgegeben, sondern der Cache-Wiederholungsvorgang wird über einige Mechanismen (z. B. Nachrichtenwarteschlangen, geplante Aufgaben, Binlog-Abonnements usw.) ausgelöst. Mit dieser Methode können zwar Leistungseinbußen und Blockierungsprobleme beim synchronen Wiederholen des Caches vermieden werden, sie verlängert jedoch die Zeit, in der Cache- und Datenbankdaten inkonsistent sind.
2.1 Verwenden Sie die Nachrichtenwarteschlange, um einen Wiederholungsversuch zu implementieren gehen nicht verloren, bis sie erfolgreich verbraucht wurden (Sie müssen sich keine Gedanken über einen Neustart des Projekts machen) : Downstream ruft die Nachricht aus der Warteschlange ab und löscht sie nach erfolgreichem Verbrauch. Andernfalls wird die Nachricht weiterhin an den Verbraucher übermittelt (gemäß unseren Wiederholungsanforderungen)
# 🎜🎜##🎜 warten lassen 🎜#Wenn Sie beispielsweise eine Benutzerinformationstabelle haben, möchten Sie die Benutzerinformationen in Redis speichern. Die folgenden Schritte können ausgeführt werden, wobei als Beispiel die Lösung der Verwendung des asynchronen Wiederholungscachings in der Nachrichtenwarteschlange verwendet wird:
Wenn sich Benutzerinformationen ändern, aktualisieren Sie zuerst die Datenbank und geben Sie das erfolgreiche Ergebnis an das Frontend zurück.
Versuchen Sie, den Cache zu löschen, wird der Vorgang beendet. Wenn er fehlschlägt, wird eine Nachricht für den Vorgang zum Löschen oder Aktualisieren des Caches generiert (z. B. einschließlich des Schlüssels und des Vorgangstyps). in die Nachrichtenwarteschlange (z. B. mit Kafka oder RabbitMQ).
Darüber hinaus gibt es einen Verbraucherthread, der diese Nachrichten abonniert und aus der Nachrichtenwarteschlange abruft und die entsprechenden Informationen in Redis basierend auf dem Nachrichteninhalt löscht oder aktualisiert.
Wenn der Cache erfolgreich gelöscht oder aktualisiert wurde, wird die Nachricht aus der Nachrichtenwarteschlange entfernt (verworfen), um wiederholte Vorgänge zu vermeiden.
Wenn das Löschen oder Aktualisieren des Caches fehlschlägt, implementieren Sie eine Fehlerstrategie, z. B. das Festlegen einer Verzögerungszeit oder eines Wiederholungslimits, und senden Sie die Nachricht dann zur Wiederholung erneut an die Nachrichtenwarteschlange.
Wenn die Wiederholungsversuche nach Überschreiten einer bestimmten Anzahl immer noch fehlschlagen, wird eine Fehlermeldung an die Business-Schicht gesendet und protokolliert.
Die Grundidee der Verwendung von Binlog zur Erzielung von Konsistenz besteht darin, Binlog-Protokolle zum Aufzeichnen von Datenbankänderungsvorgängen zu verwenden und dann Daten durch Master-Slave-Replikation oder inkrementelle Sicherung zu synchronisieren oder wiederherzustellen.
Wenn wir beispielsweise eine Master-Datenbank und eine Slave-Datenbank haben, können wir Binlog für die Master-Datenbank aktivieren und die Slave-Datenbank als Replikationsknoten festlegen. Auf diese Weise wird bei jedem Änderungsvorgang in der Master-Datenbank das entsprechende Binlog-Protokoll an die Slave-Datenbank gesendet, und die Slave-Datenbank führt denselben Vorgang basierend auf dem Binlog-Protokoll aus, um die Datenkonsistenz sicherzustellen.
Wenn wir Daten vor einem bestimmten Zeitpunkt wiederherstellen müssen, können wir dazu auch Binlog-Protokolle verwenden. Zuerst müssen wir die aktuellste vollständige Sicherungsdatei vor dem entsprechenden Zeitpunkt finden und sie in der Zieldatenbank wiederherstellen. Dann müssen wir alle inkrementellen Sicherungsdateien (d. h. Binlog-Protokolldateien) vor dem entsprechenden Zeitpunkt finden und sie der Reihe nach auf die Zieldatenbank anwenden. Auf diese Weise können wir den Datenstatus vor dem Zielzeitpunkt wiederherstellen.
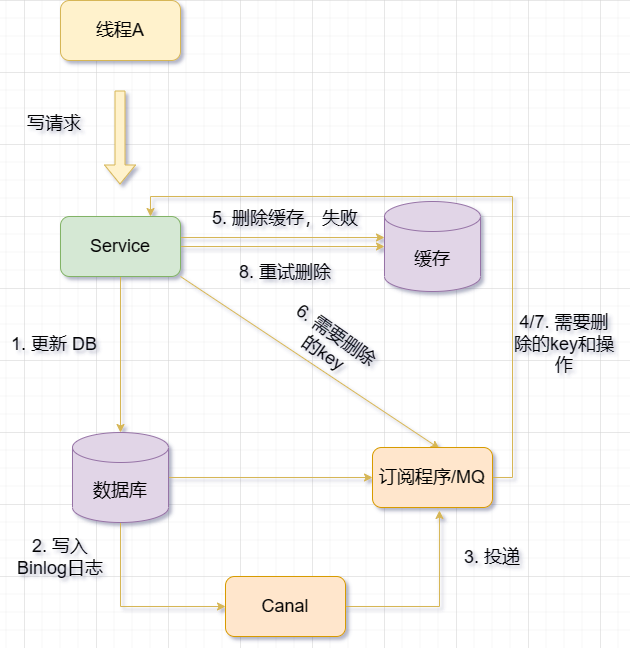
Verwenden Sie Binlog, um den Redis-Cache in Echtzeit zu aktualisieren/löschen. Mit Canal tarnt sich der für die Cache-Aktualisierung verantwortliche Dienst als MySQL-Slave-Knoten, empfängt Binlog von MySQL, analysiert das Binlog, ruft Echtzeit-Datenänderungsinformationen ab und aktualisiert/löscht dann den Redis-Cache basierend auf den Änderungsinformationen
MQ+ Canal-Strategie, übermittelt die von Canal Server empfangenen Binlog-Daten zur Entkopplung direkt an MQ und verwendet MQ, um Binlog-Protokolle für die Datensynchronisierung asynchron zu konsumieren;
MySQLs Binlog-Protokoll zeichnet Datenbankänderungsvorgänge wie Einfügungen auf. aktualisieren, löschen usw. Das Binlog-Protokoll hat zwei Hauptfunktionen: eine ist die Master-Slave-Replikation und die andere ist eine inkrementelle Sicherung.
Master-Slave-Replikation ist der Prozess der Datensynchronisierung durch Synchronisierung von Daten aus einer Master-Datenbank mit einer oder mehreren Slave-Datenbanken. Die Master-Datenbank sendet ihr eigenes Binlog-Protokoll an die Slave-Datenbank, und die Slave-Datenbank führt denselben Vorgang basierend auf dem Binlog-Protokoll aus, um die Datenkonsistenz sicherzustellen. Durch die Implementierung dieses Ansatzes können die Datenverfügbarkeit und -zuverlässigkeit verbessert sowie Lastausgleich und Fehlerwiederherstellung erreicht werden.
Inkrementelle Sicherung bezieht sich auf die regelmäßige Sicherung von Datenbankänderungen basierend auf einer vollständigen Sicherung. Unter Vollsicherung versteht man die vollständige Sicherung der gesamten Datenbankdaten in einer Datei. Der Zweck besteht darin, die neuesten Änderungen in der Datenbank mit früheren Sicherungen zusammenzuführen, um den neuesten Stand wiederherzustellen. Auf diese Weise können Sie nicht nur den für die Sicherung benötigten Platz und Zeit sparen, sondern auch die Wiederherstellung von Daten zu jedem beliebigen Zeitpunkt vereinfachen.
An diesem Punkt können wir den Schluss ziehen, dass zur Gewährleistung der Konsistenz der Datenbank und des Caches empfohlen wird, die Lösung „Zuerst die Datenbank aktualisieren und dann den Cache löschen“ zu übernehmen und mit der „Nachrichtenwarteschlange“ zusammenzuarbeiten. oder „Abonnieren Sie das Änderungsprotokoll“, um dies zu tun.
Unser Fokus liegt darauf, zuerst die Datenbank zu aktualisieren und dann den Cache zu löschen. Was ist, wenn ich zuerst den Cache löschen und dann die Datenbank aktualisieren möchte?
Erinnern Sie sich daran, was ich zuvor über das Löschen des Caches und das anschließende Aktualisieren der Datenbank gesagt habe. Das ist einfach zu handhaben. Das ist das Prinzip der Verzögerung Doppeltes Löschen. Die Grundidee ist:
Zuerst den Cache löschen
und dann die Datenbank aktualisieren
Für einen bestimmten Zeitraum in den Ruhezustand versetzen (abhängig von den Systembedingungen)
Den Cache löschen noch einmal
Um eine Aktualisierung der Datenbank zu vermeiden, wurde diese Maßnahme ergriffen, nachdem andere Threads abgelaufene zwischengespeicherte Daten gelesen und in den Cache zurückgeschrieben hatten, was zu Dateninkonsistenzen führte.
Zum Beispiel: Angenommen, es gibt eine Benutzerinformationstabelle, eine davon sind Benutzerpunkte. Jetzt arbeiten zwei Threads A und B gleichzeitig mit Benutzerpunkten:
Thread A möchte die Punkte des Benutzers um 100 Punkte erhöhen
Thread B möchte die Punkte des Benutzers um 50 Punkte verringern
Wenn die verzögerte Doppellöschstrategie verwendet wird, kann der Ausführungsprozess der Threads A und B wie folgt aussehen:
Thread A löscht zuerst die Benutzerinformationen im Cache.
Thread A liest dann die Benutzerinformationen Aus der Datenbank wird festgestellt, dass die Benutzerbewertung 1000 beträgt. Thread A addiert 100 zur Benutzerbewertung, um 1100 zu erhalten, und aktualisiert sie in der Datenbank genug, damit die Datenbank synchronisiert werden kann)
Thread A löscht die Benutzerinformationen im Cache erneut
Thread B löscht zuerst die Benutzerinformationen im Cache
Thread B liest dann die Benutzerinformationen aus der Datenbank und stellt fest, dass die Benutzerpunkte 1100 sind (weil Thread A aktualisiert wurde)
Thread B subtrahiert 50 von den Benutzerpunkten auf 1050 und aktualisiert sie in der Datenbank
Thread B schläft 5 Sekunden lang (vorausgesetzt, diese Zeit reicht aus). damit die Datenbank synchronisiert werden kann)
Thread B löscht den Cache erneut Benutzerinformationen
Das Endergebnis ist: Die Benutzerpunkte in der Datenbank sind 1050 und es befinden sich keine Benutzerinformationen im Cache. Wenn die Benutzerinformationen das nächste Mal abgefragt werden, werden sie zuerst aus dem Cache gelesen, anstatt sie aus der Datenbank abzurufen und in den Cache zu schreiben. Dadurch wird die Datenkonsistenz gewährleistet.
Das obige ist der detaillierte Inhalt vonSo lösen Sie das Problem der Doppelschreibkonsistenz zwischen Redis und MySQL. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 MySQL ändert den Namen der Datentabelle
MySQL ändert den Namen der Datentabelle
 MySQL erstellt eine gespeicherte Prozedur
MySQL erstellt eine gespeicherte Prozedur
 Der Unterschied zwischen Mongodb und MySQL
Der Unterschied zwischen Mongodb und MySQL
 So überprüfen Sie, ob das MySQL-Passwort vergessen wurde
So überprüfen Sie, ob das MySQL-Passwort vergessen wurde
 MySQL-Datenbank erstellen
MySQL-Datenbank erstellen
 MySQL-Standard-Transaktionsisolationsstufe
MySQL-Standard-Transaktionsisolationsstufe
 Der Unterschied zwischen SQL Server und MySQL
Der Unterschied zwischen SQL Server und MySQL
 mysqlPasswort vergessen
mysqlPasswort vergessen









![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



