
 Datenbank
MySQL-Tutorial
Beispielanalyse von Indizes und Algorithmen der Mysql Innodb-Speicher-Engine
Datenbank
MySQL-Tutorial
Beispielanalyse von Indizes und Algorithmen der Mysql Innodb-Speicher-Engine
Beispielanalyse von Indizes und Algorithmen der Mysql Innodb-Speicher-Engine

1. Übersicht
Zu wenige Indizes führen zu einer geringen Abfrageeffizienz; zu viele Indizes beeinträchtigen die Programmleistung, und die Verwendung von Indizes sollte mit der tatsächlichen Situation übereinstimmen.
Innodb unterstützt Indizes einschließlich:
Volltextsuche mit invertiertem Index
ha Hash Der Index ist anpassungsfähig und kann nicht von Menschen eingegriffen werden. Er wird auf der Grundlage der Clustered-Index-Seite im Pufferpool erstellt und hasht nicht die gesamte Tabelle, sodass die Indexerstellung sehr schnell erfolgt.
Der B+-Baumindex, ein Index im herkömmlichen Sinne, ist derzeit der effektivste und am häufigsten verwendete Index in relationalen Datenbanken.
Der B+-Baum kann den spezifischen Zeilendatensatz in der Tabelle nicht finden, gibt aber schließlich die Seite zurück, auf der sich der Zeilendatensatz befindet, basierend auf den Slot-Informationen und der Zeile Satz im Speicher Die nächsten Satzinformationen im Satzkopf dienen der genauen Positionierung.
2. Datenstruktur und Algorithmus
1. Binäre Suche
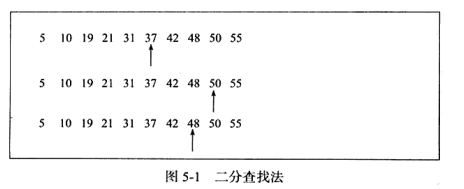
Die binäre Suche kann nur zum Durchsuchen eines Satzes geordneter linearer Daten verwendet werden jedes Mal der Medianwert, wobei man sich bei kleinen Werten vorwärts und bei großen Werten rückwärts bewegt. Die Zeitkomplexität zum Finden der Zahl 48 in einem geordneten Array beträgt log N, wie in der folgenden Abbildung dargestellt.
2. Binärer Suchbaum und ausgeglichener Binärbaum
1) Binärer Suchbaum
#🎜🎜 # Der binäre Suchbaum bezieht sich auf einen Binärbaum, der die folgenden Bedingungen erfüllt: Der linke untergeordnete Knoten eines beliebigen Knotens ist kleiner als er selbst und der rechte untergeordnete Knoten eines beliebigen Knotens ist größer als er selbst. Dies ist ein binärer Suchbaum. Gewöhnliche Binärbäume können keine O(logN)-Zugriffszeit garantieren, da sie im Extremfall sogar zu einer verknüpften Liste ausarten können. Wenn ein Satz geordneter Daten erstellt wird, um einen Binärbaum zu erstellen, wird eine verknüpfte Liste erhalten. Zu diesem Zeitpunkt beträgt die Zeitkomplexität: O(N)#🎜 🎜## 🎜🎜#
2) Ausgeglichener Binärbaum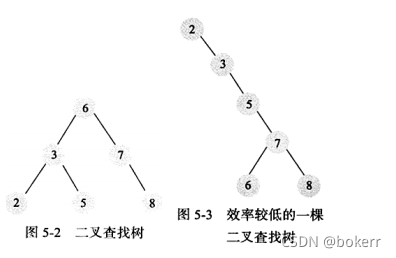
Obwohl er O(logN) garantieren kann Zugriffszeit, ist aber nicht für die Datenbankindizierung geeignet: 
[Baumhöhe ist der aufgerundete logarithmische Wert, zum Beispiel: log3 = 1,58, Baumhöhe ist 2;] #🎜🎜 # 3. B+-Baum
#🎜🎜 # 3. B+-Baum
Aufgrund der Einschränkungen ausgeglichener Binärbäume müssen B+-Bäume eingeführt werden.
Der B+-Baum ist ein ausgewogener Suchbaum, der für Festplatten oder andere Hilfsgeräte mit Direktzugriff entwickelt wurde. Im B+-Baum haben alle Datensatzknoten die Schlüsselwertgröße und werden in derselben Reihenfolge gespeichert. Die Blattknoten der Ebene werden durch jeden Blattknotenzeiger verknüpft.1. Vollständige Definition des B+-Baums Ein B+-Baum der Ordnung M muss die folgenden Eigenschaften erfüllen:
Alle Folgende Definitionen: Wenn zwei Zahlen nicht teilbar sind, runden Sie sie auf, anstatt die Dezimalstellen wegzulassen. (Außer der Ableitung von Ungleichungen in diesem Fall)
1) Datenelemente müssen auf Blattknoten gespeichert werden.
2) Nicht-Blattknoten speichern M-1-Schlüsselwörter, um die Suche anzuzeigen Richtung; Schlüsselwort i stellt das kleinste Schlüsselwort im i + 1. Teilbaum des Nicht-Blattknotens dar, unter der Annahme eines B+-Baums 5. Ordnung, dann hat es 5 - 1 = 4 Schlüsselwörter.
3) Der B+-Baum hat entweder nur einen Blattknoten als Wurzelknoten (ohne untergeordnete Knoten); wenn er untergeordnete Knoten hat, muss seine Anzahl an Knoten zur Menge gehören: {2~M} ; #🎜🎜 #
4) Mit Ausnahme der Wurzel muss die Anzahl der untergeordneten Knoten aller Nicht-Blattknoten die folgende Menge erfüllen: { 5) Alle Blätter haben die gleiche Tiefe und die Anzahl der Datenelemente der Blattknoten muss zur Menge gehören: {L/2, L};2. Ausgewählte Fälle über M und L#🎜🎜 #Angenommen, die Gesamtlänge aller Felder beträgt nicht mehr als 500 Bytes. Nehmen Sie den 50-Byte-Primärschlüssel als Beispiel, um die Ableitung des B+-Baums zu simulieren, einschließlich des vom Zeilendatensatz selbst belegten Speicherplatzes#🎜 🎜#
Es ist bekannt, dass alle Zeilendatensätze einige Bytes verbrauchen, um Zeileninformationen aufzuzeichnen: z. B. Felder variabler Länge, Zeilendatensatzheader, Transaktions-IDs, Rollback-Zeiger usw.
create table context( id varchar(50) primary key, name varchar(50) not null, description varchar(360) );
Ein Blattknoten stellt eine Datenseite dar, und die Auswahl der M- und L-Werte hängt eng damit zusammen. Angenommen, die Datenseitengröße beträgt: P/Byte (am Beispiel des in diesem Artikel besprochenen MySQL). Die Größe einer Datenseite beträgt 16 KB, also 16384 Bytes.
Auf Nicht-Blattknoten: Der Schlüssel des B+-Baums ist der Primärschlüssel Die Schlüssel des M-Ordnungs-B+-Baums sind M -1 und belegen: 50 * (M - 1) Bytes Speicherplatz
plus seine Verzweigungszeiger, die auf M untergeordnete Knoten zeigen, vorausgesetzt, dass jeder Verzweigungszeiger 4 Bytes Speicher belegt; Dann beträgt in einem Nicht-Blattknoten der gesamte Speicherplatzverbrauch: 50 * (M - 1) + 4 * M = 54M - 50 Bytes.
Bei Verwendung von MySQL und unter der Annahme, dass der Primärschlüssel 50 Bytes beträgt, ergibt sich die Ungleichung: 54M - 50 <= P, wobei P = 16384, dann lautet die Lösung für M: M <= 302, der maximale optionale Wert der Ordnung M Ungefähr: 302; hier können wir maximal 302 Bäume der Ordnung B+ auswählen.
Auf dem Blattknoten beträgt die maximale Kapazität jeder in der bekannten Tabelle definierten Zeile: 500 Byte. Zu diesem Zeitpunkt wird der folgende Ausdruck erstellt: L * 500 <= 16384. Die Lösungsmenge von L ist: L < = 32; Der maximale L, den wir wählen können, ist: 32.
Wie im Bild unten gezeigt, liegen zu diesem Zeitpunkt 5000-W-Daten vor und die Baumhöhe ist größer als 3, was bedeutet, dass wir nur bis zu 4 Festplatten-E/A benötigen, um die Daten zu finden.
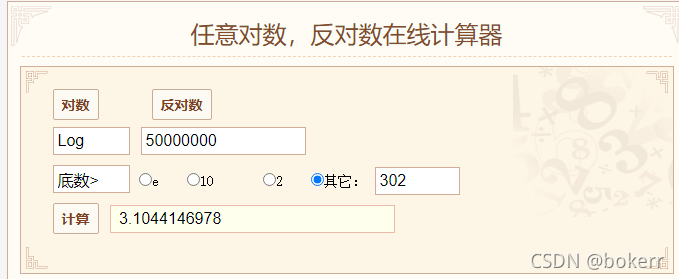
Siehe die Abbildung unten: 1,44 * logN = 25,58 * 1,44 = 36,83; das heißt, wenn 5000-W-Daten einen ausgeglichenen Binärbaum verwenden, wird der Baum überschritten 36 Festplatten-IOs im schlimmsten Fall. Mindestens 26 Festplatten-IO-Zeiten.
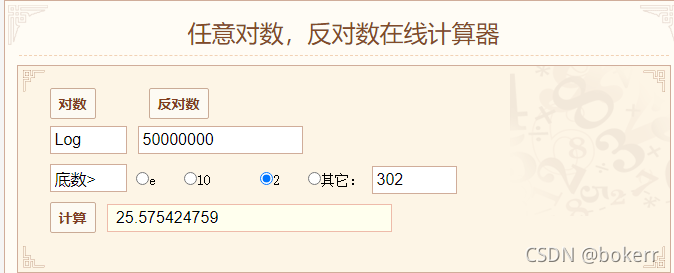
Das Bild zeigt einen gewöhnlichen B+-Baum 5. Ordnung (M = 5), wobei jeder Knoten bis zu 5 Werte hat (M und L sind nicht unbedingt gleich, wie oben gezeigt). Analyse: M und L unterliegen den tatsächlichen Bedingungen.
Hahaha, es ist zu mühsam, Bilder zu zeichnen. Ich habe die Fotos aus diesem Buch über Datenstrukturen und Algorithmen analysiert und sie sind genauso schlau wie ich.
Hier sprechen wir nur über die B+-Baumdefinition und die Parameterauswahldetails. Das Einfügen des B+-Baums und das Löschen des B+-Baums werden nicht im Detail besprochen.
4. B+-Baumindex
Im Allgemeinen beträgt die B+-Baumhöhe 2 bis 4 Ebenen, d gelegen. Unabhängig vom Clustered-Index oder dem Nicht-Clustered-Index ist das Innere sehr ausgewogen und die Indexdaten werden in Blattknoten gespeichert. Der Unterschied besteht darin, dass die Blattknoten des Clustered-Index die gesamten Zeilendatensatzdaten speichern.
1. Clustered-Index
Die Blattknoten des Clustered-Index speichern die gesamte Datenzeile, und jede Tabelle kann nur einen Clustered-Index haben.
2. Hilfsindex
Der Blattknoten des Hilfsindex speichert den Schlüsselwert und ein Lesezeichen, das der Innodb-Speicher-Engine mitteilt, wo die vollständigen Daten des entsprechenden Zeilendatensatzes im Index zu finden sind.
Jede Tabelle kann mehrere Hilfsindizes haben
Ein Nachteil von Hilfsindizes besteht darin, dass vollständige Zeilendaten abgerufen werden müssen Diskrete Clustered-Indizes, auch wenn das im Sekundärindex gespeicherte Lesezeichen gefunden wurde.
5. Über den Kardinalitätswert
Die Diskussion der Kardinalität basiert auf nicht gruppierten Indizes, und jeder nicht gruppierte Index hat einen Kardinalitätswert.
1. Kardinalitätsdefinition
Beachten Sie, dass nicht alle Spalten in den Abfragebedingungen indiziert werden müssen. Wörterbücher mit kleinen Wertebereichen und einer dichten Verteilung wie Geschlecht, Alter und Themen müssen beispielsweise nicht indiziert werden.
Kardinalität stellt die geschätzte Anzahl eindeutiger Datensätze im Index dar. Im Allgemeinen sollte die Kardinalität / Anzahl der Datensatzzeilen in der Tabelle so nahe wie möglich bei 1 liegen. Wenn sie sehr klein ist, müssen Sie überlegen, ob der Index entfernt werden soll. (Dieser Wert muss in einem Clustered-Index nahe bei 1 liegen und es gibt keinen Diskussionswert.)
2. Kardinalitätsaktualisierung
Da in MySQL jede Speicher-Engine B+-Baumindizes unterschiedlich implementiert, werden Kardinalitätsstatistiken auf der Ebene der Speicher-Engine implementiert.
Wenn die Datenmenge in der Tabelle sehr groß ist, ist die Erstellung von Kardinalitätsstatistiken sehr zeitaufwändig, und die Statistiken werden im Allgemeinen mithilfe der Stichprobenmethode erstellt.
Die Existenz der Kardinalität kann uns helfen zu analysieren, ob der Index irgendeine Bedeutung hat.
6. Verwendung des B+-Baumindex
[Die in diesem Abschnitt besprochenen Indizes beziehen sich hauptsächlich auf Hilfsindizes, und Abfragen zu Clustered-Indizes werden im Allgemeinen als vollständige Tabellenscans bezeichnet. 】
1. Gemeinsamer Index
Ein gemeinsamer Index ist ein Index, der auf mehreren Spalten in der Tabelle basiert. Es handelt sich ebenfalls um eine B+-Baumstruktur. Der einzige Unterschied zu einem einzelnen Index besteht.
create table t ( a int, b int, primary key (a), key idx_ab (a, b) )engine=innodb;
Legen Sie in der obigen Tabelle den gemeinsamen Primärschlüssel idx_ab fest. Seine Speicherstruktur lautet wie folgt:
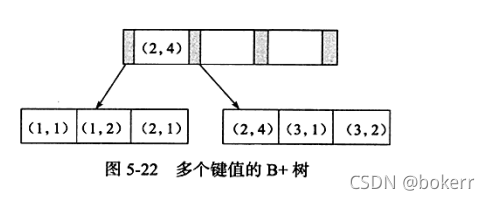
如上图所述,键值有序,需要注意的是,如下SQL可以使用该索引:
select * from t where a = ? and b = ? select * from t where a = ?
如下sql 不能使用该索引;查看示例图中联合索引叶子节点存放的数据我们可以发现:两个叶子节点上,关于字段b的存放显然不是有序的。
select * from t where b = ?
联合索引本身还有一个好处,辅助索引本身已经对第二个键值进行了排序,如下语句可以避免多一次的排序。
select b from t where a = ? order by b desc
辅助索引中已经对 b 列进行了排序,所以此时使用辅助索引更高效。
2、覆盖索引
Innodb 支持覆盖索引(covering index,或称为索引覆盖),即从辅助索引中就可以得到结果,而不需要查询聚集索引中的记录。由于辅助索引不包含完整的行记录,从而比聚集索引小很多,可以极大地减少IO操作。
再形如:select count(*) from table name where b <= ? and b >= ? 的sql,如果有满足条件的辅助索引,它会优先使用辅助索引因为辅助索引体积远远小于聚集索引。
3、优化器选择不使用索引的情况
某些情况下,通过EXPLAIN指令会发现一些SQL,并没有选择使用满足条件的辅助索引去查数据,而是直接选择了全表扫描(聚集索引),这种情况一般发生于 范围查找、join链接操作等情况下。
当发生此类查找时,一般是查找一个较大范围内的数据,当范围较大时同样意味着大量的数据需要再进行一次书签访问去获取完整数据,已知顺序读取速度大于离散读取速度,所以此时不会使用辅助索引,而是直接查聚集索引(整表扫描)。一般情况下,当访问数据超过表中数据总数的20%时,索引覆盖不再适用,而需要进行全表扫描。)
create table t ( a int, b int, primary key (a,b), key idx_a (a) )engine=innodb;
如上定义表,a和b两列构成联合索引,列a上有独立的辅助索引,对于语句:
select * from t where a >= 3 and a<= 1000000;
按理说,该语句是可以选择使用辅助索引 idx_a 进行查找的,但是通过执行 explain 发现该语句发生了全表扫描(聚集索引),而不是使用辅助索引: idx_a。
4、索引提示
索引提示指MySQL支持在SQL中显式的告诉优化器使用哪个索引。
当优化器选择索引错误,可以手动指定索引。[极小概率事件]
当索引太多时,优化器选择索引的操作时间开销大,此时可以手动指定索引。
使用索引提示的前提是我们自己要对sql的执行非常了解,非常明确该操作能带来更好的效率。
5、Multi-Range Read 优化 (MRR)
MySQL5.6版本开始支持Multi-Range Read (MRR) 优化,它的目的是减少磁盘的离散读,将离散的访问优化为相对有序的访问,它使用于 range ref eq_ref 类型的查询。
1).MRR优化有如下好处:
它使得数据访问变得较为顺序,当根据辅助索引查询时,会将查询结果按照主键排序后,再去聚集索引进行书签查询。
减少缓冲池中页被替换的次数;
批量处理对键值的查询操作;
2).对于 JOIN 和 范围查询,Innodb 中MRR的工作方式为:
将通过辅助索引查询到的数据放到一个缓存中,此时这些数据是按照辅助索引键值排序的;
将缓存中的数据按照主键顺序排序;
根据主键顺序访问实际数据文件;
想象一下,在缓冲池不够大的情况下进行大范围数据查询,会导致数据页频繁被从LRU列表中移除。如果被查询的辅助索引不是按主键排序的,可能会多次发生如下的情况:一个页在同一次查询中被剔出LRU列表后又再次被加载出来。
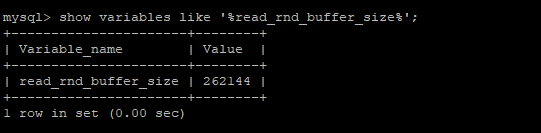
配置项:read_rnd_buffer_size 用来配置上述描述的键值缓冲区大小,默认为256K;当发生溢出时,执行器只对已经缓存的数据进行排序。
3).对于范围查询:MMR还支持对键值的拆分,将范围查询拆分为键值对进行批量的数据查询.
create table t ( a integer, b integer, primary key (a), key idx_ab (a, b) )engine=innodb;
select * from t where a = 50 and b>= 100 and b<= 20000
由于存在辅助索引 idx_ab,上述sql语句的条件可以拆分为键值对集合:{( 50 , 100 ),( 50 , 101 ),......,( 50 , 20000 )},这样就将范围查询优化为对键值对的查询;否则会进行范围查询,将 b ∈ {100,20000} 的所有数据都取出。
Multi-Range Read 是否启用,由如下参数中的,mrr 和 mrr_cost_based 标记进行控制,mrr标记是 MRR优化的开关。若前者设置为on,后者设置为off表示当满足条件时总是使用MRR优化;若前者设置为 on,后者也设置 on 表示通过 cost base 方式判断是否需要 MRR优化。

6. Index Condition Pushdown Optimization (ICP)
ICP-Optimierung wird ab MySQL 5.6 ebenfalls unterstützt. Es handelt sich um eine Optimierungsmethode für Abfragen basierend auf dem Index. Sie unterstützt Abfragen vom Typ „range“, „ref“, „eq_ref“, „ref_or_null“. Optimieren.
Wenn ICP deaktiviert ist, durchläuft die Speicher-Engine-Schicht den Index, um den vollständigen Zeilendatensatz zu finden, und gibt ihn dann an die Datenbankschicht (Serverschicht) zurück und filtert dann die Wo-Bedingungen für diese Datenzeilen.
Wenn ICP aktiviert ist und die Where-Bedingung den Index verwenden kann, legt MySQL diesen Teil des Filtervorgangs in der Speicher-Engine-Ebene ab. Die Speicher-Engine filtert durch den Index und entnimmt die gesamte Datenzeile, die erfüllt die Where-Bedingung und gibt sie zurück. Die Verwendung von ICP kann die Häufigkeit reduzieren, mit der die Speicher-Engine-Schicht auf Zeilendatensätze zugreift, und gleichzeitig die Häufigkeit reduzieren, mit der die Datenbankschicht (Server-Schicht) auf die Speicher-Engine zugreifen muss.
[Voraussetzung für die Verwendung dieses Filters ist: Die Filterbedingung muss der Bereich sein, den der Index abdecken kann]
Index Condition Pushdown funktioniert wie folgt:
1) Wenn ICP nicht verwendet wird
( 1) Wenn die Speicher-Engine die nächste Zeile liest, liest sie den relevanten Zeilendatensatz vom Blattknoten des Hilfsindex und verwendet dann die Primärschlüsselreferenz im Lesezeichen des Datensatzes, um den vollständigen Zeilendatensatz abzufragen und an ihn zurückzugeben die Datenbankschicht (Serverschicht).
(2) Die Datenbankschicht führt eine Where-Bedingungsfilterung für die gesamten Zeilendatensätze durch. Wenn die Zeilendaten die Where-Bedingung erfüllen, werden sie verwendet, andernfalls werden sie verworfen.
(3) Führen Sie Schritt 1 aus, bis alle Daten gelesen sind, die die Bedingungen erfüllen.
2) So führen Sie einen Index-Scan durch, wenn Sie ICP verwenden
(1) Die Speicher-Engine liest Daten einzeln aus dem Index...
(2) Wenn die Speicher-Engine Daten aus dem Index liest, laut Schlüssel des Index Verwenden Sie zum Filtern die Where-Bedingung. Wenn der Zeilendatensatz die Bedingung nicht erfüllt, verarbeitet die Speicher-Engine das nächste Datenelement (kehrt zum vorherigen Schritt zurück). Erst wenn die Abfragebedingungen erfüllt sind, werden die vollständigen Daten aus dem Clustered-Index gelesen.
(3) Schließlich gibt die Speicher-Engine-Schicht alle vollständigen Zeilendatensätze, die die Abfragebedingungen erfüllen, an die Datenbankschicht zurück.
(4) Wenn die Datenbankschicht weiterhin verwendet wird, werden die Abfragebedingungen danach gefiltert, die nicht vom Index abgedeckt werden.
Das obige ist der detaillierte Inhalt vonBeispielanalyse von Indizes und Algorithmen der Mysql Innodb-Speicher-Engine. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1369
1369
 52
52

 Ich kann mich nicht als Stamm bei MySQL anmelden
Apr 08, 2025 pm 04:54 PM
Ich kann mich nicht als Stamm bei MySQL anmelden
Apr 08, 2025 pm 04:54 PM
Die Hauptgründe, warum Sie sich bei MySQL nicht als Root anmelden können, sind Berechtigungsprobleme, Konfigurationsdateifehler, Kennwort inkonsistent, Socket -Dateiprobleme oder Firewall -Interception. Die Lösung umfasst: Überprüfen Sie, ob der Parameter Bind-Address in der Konfigurationsdatei korrekt konfiguriert ist. Überprüfen Sie, ob die Root -Benutzerberechtigungen geändert oder gelöscht und zurückgesetzt wurden. Stellen Sie sicher, dass das Passwort korrekt ist, einschließlich Fall- und Sonderzeichen. Überprüfen Sie die Einstellungen und Pfade der Socket -Dateiberechtigte. Überprüfen Sie, ob die Firewall Verbindungen zum MySQL -Server blockiert.
 MySQL, ob die Tabellenverriegelungstabelle geändert werden soll
Apr 08, 2025 pm 05:06 PM
MySQL, ob die Tabellenverriegelungstabelle geändert werden soll
Apr 08, 2025 pm 05:06 PM
Wenn MySQL -Modifys -Tabellenstruktur verwendet werden, werden normalerweise Metadatenverriegelungen verwendet, wodurch die Tabelle gesperrt wird. Um die Auswirkungen von Schlösser zu verringern, können die folgenden Maßnahmen ergriffen werden: 1. Halten Sie Tabellen mit Online -DDL verfügbar; 2. Führen Sie komplexe Modifikationen in Chargen durch; 3.. Arbeiten während kleiner oder absendlicher Perioden; 4. Verwenden Sie PT-OSC-Tools, um eine feinere Kontrolle zu erreichen.
 RDS MySQL -Integration mit RedShift Zero ETL
Apr 08, 2025 pm 07:06 PM
RDS MySQL -Integration mit RedShift Zero ETL
Apr 08, 2025 pm 07:06 PM
Vereinfachung der Datenintegration: AmazonRDSMYSQL und Redshifts Null ETL-Integration Die effiziente Datenintegration steht im Mittelpunkt einer datengesteuerten Organisation. Herkömmliche ETL-Prozesse (Extrakt, Konvertierung, Last) sind komplex und zeitaufwändig, insbesondere bei der Integration von Datenbanken (wie AmazonRDSMysQL) in Data Warehouses (wie Rotverschiebung). AWS bietet jedoch keine ETL-Integrationslösungen, die diese Situation vollständig verändert haben und eine vereinfachte Lösung für die Datenmigration von RDSMysQL zu Rotverschiebung bietet. Dieser Artikel wird in die Integration von RDSMYSQL Null ETL mit RedShift eintauchen und erklärt, wie es funktioniert und welche Vorteile es Dateningenieuren und Entwicklern bringt.
 Kann MySQL mehrere Verbindungen umgehen?
Apr 08, 2025 pm 03:51 PM
Kann MySQL mehrere Verbindungen umgehen?
Apr 08, 2025 pm 03:51 PM
MySQL kann mehrere gleichzeitige Verbindungen verarbeiten und Multi-Threading-/Multi-Processings verwenden, um jeder Client-Anfrage unabhängige Ausführungsumgebungen zuzuweisen, um sicherzustellen, dass sie nicht gestört werden. Die Anzahl der gleichzeitigen Verbindungen wird jedoch von Systemressourcen, MySQL -Konfiguration, Abfrageleistung, Speicher -Engine und Netzwerkumgebung beeinflusst. Die Optimierung erfordert die Berücksichtigung vieler Faktoren wie Codeebene (Schreiben effizienter SQL), Konfigurationsstufe (Anpassung von max_connections), Hardwareebene (Verbesserung der Serverkonfiguration).
 Die Abfrageoptimierung in MySQL ist für die Verbesserung der Datenbankleistung von wesentlicher Bedeutung, insbesondere im Umgang mit großen Datensätzen
Apr 08, 2025 pm 07:12 PM
Die Abfrageoptimierung in MySQL ist für die Verbesserung der Datenbankleistung von wesentlicher Bedeutung, insbesondere im Umgang mit großen Datensätzen
Apr 08, 2025 pm 07:12 PM
1. Verwenden Sie den richtigen Index, um das Abrufen von Daten zu beschleunigen, indem die Menge der skanierten Datenmenge ausgewählt wird. Wenn Sie mehrmals eine Spalte einer Tabelle nachschlagen, erstellen Sie einen Index für diese Spalte. Wenn Sie oder Ihre App Daten aus mehreren Spalten gemäß den Kriterien benötigen, erstellen Sie einen zusammengesetzten Index 2. Vermeiden Sie aus. Auswählen * Nur die erforderlichen Spalten. Wenn Sie alle unerwünschten Spalten auswählen, konsumiert dies nur mehr Serverspeicher und veranlasst den Server bei hoher Last oder Frequenzzeiten, beispielsweise die Auswahl Ihrer Tabelle, wie beispielsweise die Spalten wie innovata und updated_at und Zeitsteuer und dann zu entfernen.
 Die Beziehung zwischen MySQL -Benutzer und Datenbank
Apr 08, 2025 pm 07:15 PM
Die Beziehung zwischen MySQL -Benutzer und Datenbank
Apr 08, 2025 pm 07:15 PM
In der MySQL -Datenbank wird die Beziehung zwischen dem Benutzer und der Datenbank durch Berechtigungen und Tabellen definiert. Der Benutzer verfügt über einen Benutzernamen und ein Passwort, um auf die Datenbank zuzugreifen. Die Berechtigungen werden über den Zuschussbefehl erteilt, während die Tabelle durch den Befehl create table erstellt wird. Um eine Beziehung zwischen einem Benutzer und einer Datenbank herzustellen, müssen Sie eine Datenbank erstellen, einen Benutzer erstellen und dann Berechtigungen erfüllen.
 Kann MySQL auf Android laufen?
Apr 08, 2025 pm 05:03 PM
Kann MySQL auf Android laufen?
Apr 08, 2025 pm 05:03 PM
MySQL kann nicht direkt auf Android ausgeführt werden, kann jedoch indirekt mit den folgenden Methoden implementiert werden: Die Verwendung der Leichtgewichtsdatenbank SQLite, die auf dem Android -System basiert, benötigt keinen separaten Server und verfügt über eine kleine Ressourcennutzung, die für Anwendungen für Mobilgeräte sehr geeignet ist. Stellen Sie sich remote eine Verbindung zum MySQL -Server her und stellen Sie über das Netzwerk zum Lesen und Schreiben von Daten über das Netzwerk eine Verbindung zur MySQL -Datenbank auf dem Remote -Server her. Es gibt jedoch Nachteile wie starke Netzwerkabhängigkeiten, Sicherheitsprobleme und Serverkosten.
 Muss MySQL bezahlen?
Apr 08, 2025 pm 05:36 PM
Muss MySQL bezahlen?
Apr 08, 2025 pm 05:36 PM
MySQL hat eine kostenlose Community -Version und eine kostenpflichtige Enterprise -Version. Die Community -Version kann kostenlos verwendet und geändert werden, die Unterstützung ist jedoch begrenzt und für Anwendungen mit geringen Stabilitätsanforderungen und starken technischen Funktionen geeignet. Die Enterprise Edition bietet umfassende kommerzielle Unterstützung für Anwendungen, die eine stabile, zuverlässige Hochleistungsdatenbank erfordern und bereit sind, Unterstützung zu bezahlen. Zu den Faktoren, die bei der Auswahl einer Version berücksichtigt werden, gehören Kritikalität, Budgetierung und technische Fähigkeiten von Anwendungen. Es gibt keine perfekte Option, nur die am besten geeignete Option, und Sie müssen die spezifische Situation sorgfältig auswählen.
