
 Backend-Entwicklung
Python-Tutorial
Was ist die Kommunikationsmethode zwischen Python-Prozessen?
Backend-Entwicklung
Python-Tutorial
Was ist die Kommunikationsmethode zwischen Python-Prozessen?
Was ist die Kommunikationsmethode zwischen Python-Prozessen?

Was ist Prozesskommunikation
Hier ein Beispiel für einen Kommunikationsmechanismus: Wir alle kennen das Wort Kommunikation, zum Beispiel möchte eine Person ihre Freundin anrufen. Sobald der Anruf hergestellt ist, wird eine implizite Warteschlange (beachten Sie diese Terminologie) gebildet. Zu diesem Zeitpunkt wird diese Person ihrer Freundin weiterhin Informationen im Dialog mitteilen, und die Freundin dieser Person hört ebenfalls zu. Ich denke, in den meisten Fällen ist es wahrscheinlich umgekehrt.
Die beiden können mit zwei Prozessen verglichen werden. Der Prozess „Diese Person“ muss Informationen an den Prozess „Freundin“ senden und benötigt daher die Hilfe einer Warteschlange. Da die Freundin jederzeit Informationen in der Warteschlange erhalten muss, kann sie gleichzeitig andere Dinge tun, was bedeutet, dass die Kommunikation zwischen den beiden Prozessen hauptsächlich von der Warteschlange abhängt.
Diese Warteschlange kann das Senden und Empfangen von Nachrichten unterstützen. „Diese Person“ ist für das Senden von Nachrichten verantwortlich, während „Freundin“ für den Empfang von Nachrichten verantwortlich ist.
Da die Warteschlange im Mittelpunkt steht, schauen wir uns an, wie man die Warteschlange erstellt.
Erstellung einer Warteschlange – Multiprocessing
verwendet weiterhin das Multiprocessing-Modul und ruft die Queue-Funktion dieses Moduls auf, um die Warteschlange zu erstellen.
| Funktionsname | Einführung | Parameter | Rückgabewert |
|---|---|---|---|
| Warteschlange | Erstellung der Warteschlange | mac_count | Queue.object |
Einführung in die Warteschlangenfunktion: Durch den Aufruf von Queue kann eine Warteschlange erstellt werden ; Es gibt einen Parameter mac_count, der die maximale Anzahl von Nachrichten angibt, die in der Warteschlange erstellt werden können. Wenn er nicht übergeben wird, ist die Standardlänge unbegrenzt. Nachdem Sie ein Warteschlangenobjekt instanziiert haben, müssen Sie das Warteschlangenobjekt bedienen, um Daten einzugeben und herauszunehmen.
Methode der Kommunikation zwischen Prozessen
| Funktionsname | Einführung | Parameter | Rückgabewert |
|---|---|---|---|
| put | Stellen Sie die Nachricht in die Warteschlange | get | |
| None | str |
Einführung in die Put-Funktion: Daten übergeben. Es verfügt über eine Parameternachricht, bei der es sich um einen Zeichenfolgentyp handelt. Einführung in die Get-Funktion: Wird zum Empfangen von Daten in der Warteschlange verwendet. (Eigentlich handelt es sich hierbei um ein häufiges JSON-Szenario. Ein großer Teil der Datenübertragung erfolgt in Zeichenfolgen. Das Einfügen und Abrufen von Warteschlangen erfolgt mithilfe von Zeichenfolgen, sodass JSON für dieses Szenario sehr gut geeignet ist.) Als Nächstes üben wir die Verwendung von Warteschlangen. Interprozesskommunikation – Warteschlangen-DemonstrationsfallDas Codebeispiel lautet wie folgt: # coding:utf-8
import json
import multiprocessing
class Work(object): # 定义一个 Work 类
def __init__(self, queue): # 构造函数传入一个 '队列对象' --> queue
self.queue = queue
def send(self, message): # 定义一个 send(发送) 函数,传入 message
# [这里有个隐藏的bug,就是只判断了传入的是否字符串类型;如果传入的是函数、类、集合等依然会报错]
if not isinstance(message, str): # 判断传入的 message 是否为字符串,若不是,则进行 json 序列化
message = json.dumps(message)
self.queue.put(message) # 利用 queue 的队列实例化对象将 message 发送出去
def receive(self): # 定义一个 receive(接收) 函数,不需传入参数,但是因为接收是一个源源不断的过程,所以需要使用 while 循环
while 1:
result = self.queue.get() # 获取 '队列对象' --> queue 传入的message
# 由于我们接收的 message 可能不是一个字符串,所以要进程异常的捕获
try: # 如果传入的 message 符合 JSON 格式将赋值给 res ;若不符合,则直接使用 result 赋值 res
res = json.loads(result)
except:
res = result
print('接收到的信息为:{}'.format(res))
if __name__ == '__main__':
queue = multiprocessing.Queue()
work = Work(queue)
send = multiprocessing.Process(target=work.send, args=({'message': '这是一条测试的消息'},))
receive = multiprocessing.Process(target=work.receive)
send.start()
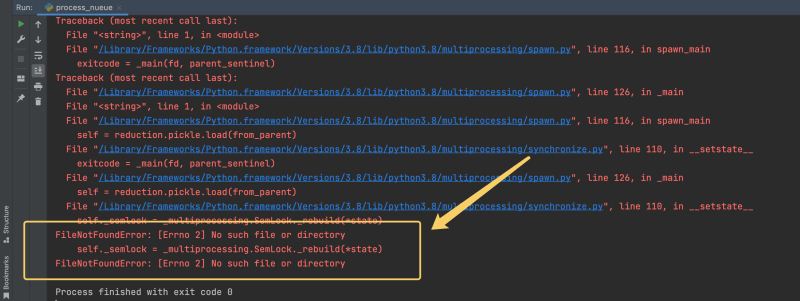
receive.start()Nach dem Login kopieren Bei Verwendung der Warteschlange zum Einrichten der Interprozesskommunikation ist eine Ausnahme aufgetreten Hier wird jedoch ein Fehler angezeigt, wie unten gezeigt: Ein Beispiel Der Fehler-Screenshot lautet wie folgt: Die Fehlermeldung hier bedeutet, dass die Datei nicht gefunden wurde. Wenn wir die Warteschlange zum Ausführen von put() und get() verwenden, wird tatsächlich eine unsichtbare Sperre hinzugefügt, nämlich die .SemLock im Kreis im Bild oben. Wir müssen uns nicht um die konkrete Ursache dieses Fehlers kümmern. Die Lösung dieses Problems ist eigentlich sehr einfach. FileNotFoundError: [Errno 2] Keine solche Datei- oder Verzeichnisausnahmelösung Was den Prozess blockieren muss, ist nur einer der Sende- oder Empfangsunterprozesse. Blockieren Sie einfach einen davon. Aber unser Empfangsunterprozess ist eine While-Schleife, die immer ausgeführt wird, sodass wir nur einen Join zum Sendeunterprozess hinzufügen müssen. Das Lösungsdiagramm sieht wie folgt aus:
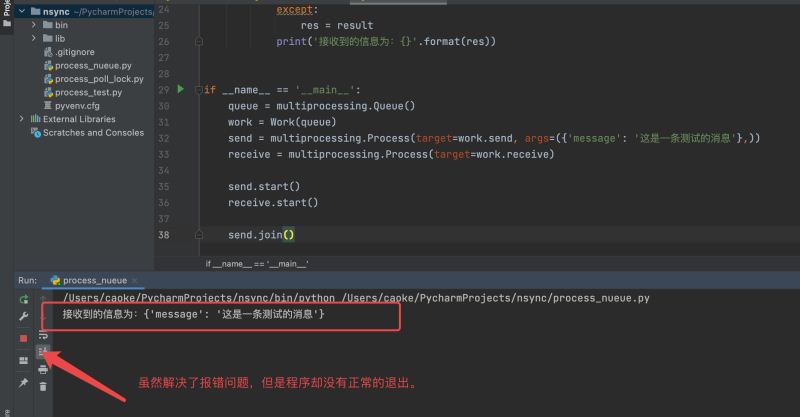
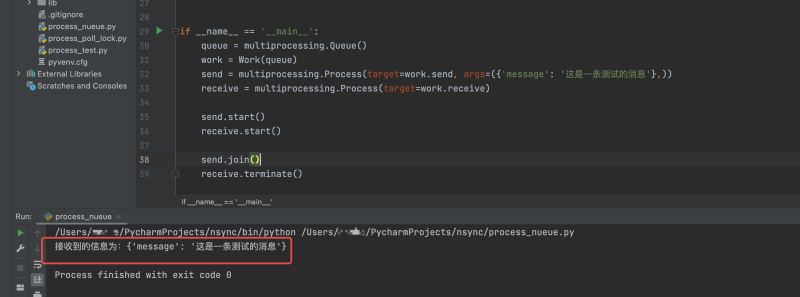
PS: Obwohl das Fehlerproblem behoben wurde, wurde das Programm nicht normal beendet. Da es sich bei unserem Empfangsprozess tatsächlich um eine While-Schleife handelt, wissen wir nicht, wann er verarbeitet wird, und es gibt keine Möglichkeit, ihn sofort zu beenden. Daher müssen wir im Empfangsprozess die Funktion „terminate()“ verwenden, um das empfangende Ende zu beenden. Die laufenden Ergebnisse sind wie folgt:
Fügen Sie Daten stapelweise zur Sendefunktion hinzuErstellen Sie eine neue Funktion und schreiben Sie sie in eine for-Schleife, um das Hinzufügen von Nachrichten zu simulieren, die stapelweise gesendet werden sollen Dann fügen Sie einen Thread hinzu zu dieser Funktion, die das Senden von Daten in Stapeln simuliert. Der Beispielcode lautet wie folgt: # coding:utf-8
import json
import time
import multiprocessing
class Work(object): # 定义一个 Work 类
def __init__(self, queue): # 构造函数传入一个 '队列对象' --> queue
self.queue = queue
def send(self, message): # 定义一个 send(发送) 函数,传入 message
# [这里有个隐藏的bug,就是只判断了传入的是否字符串类型;如果传入的是函数、类、集合等依然会报错]
if not isinstance(message, str): # 判断传入的 message 是否为字符串,若不是,则进行 json 序列化
message = json.dumps(message)
self.queue.put(message) # 利用 queue 的队列实例化对象将 message 发送出去
def send_all(self): # 定义一个 send_all(发送)函数,然后通过for循环模拟批量发送的 message
for i in range(20):
self.queue.put('第 {} 次循环,发送的消息为:{}'.format(i, i))
time.sleep(1)
def receive(self): # 定义一个 receive(接收) 函数,不需传入参数,但是因为接收是一个源源不断的过程,所以需要使用 while 循环
while 1:
result = self.queue.get() # 获取 '队列对象' --> queue 传入的message
# 由于我们接收的 message 可能不是一个字符串,所以要进程异常的捕获
try: # 如果传入的 message 符合 JSON 格式将赋值给 res ;若不符合,则直接使用 result 赋值 res
res = json.loads(result)
except:
res = result
print('接收到的信息为:{}'.format(res))
if __name__ == '__main__':
queue = multiprocessing.Queue()
work = Work(queue)
send = multiprocessing.Process(target=work.send, args=({'message': '这是一条测试的消息'},))
receive = multiprocessing.Process(target=work.receive)
send_all = multiprocessing.Process(target=work.send_all,)
send_all.start() # 这里因为 send 只执行了1次,然后就结束了。而 send_all 却要循环20次,它的执行时间是最长的,信息也是发送的最多的
send.start()
receive.start()
# send.join() # 使用 send 的阻塞会造成 send_all 循环还未结束 ,receive.terminate() 函数接收端就会终结。
send_all.join() # 所以我们只需要阻塞最长使用率的进程就可以了
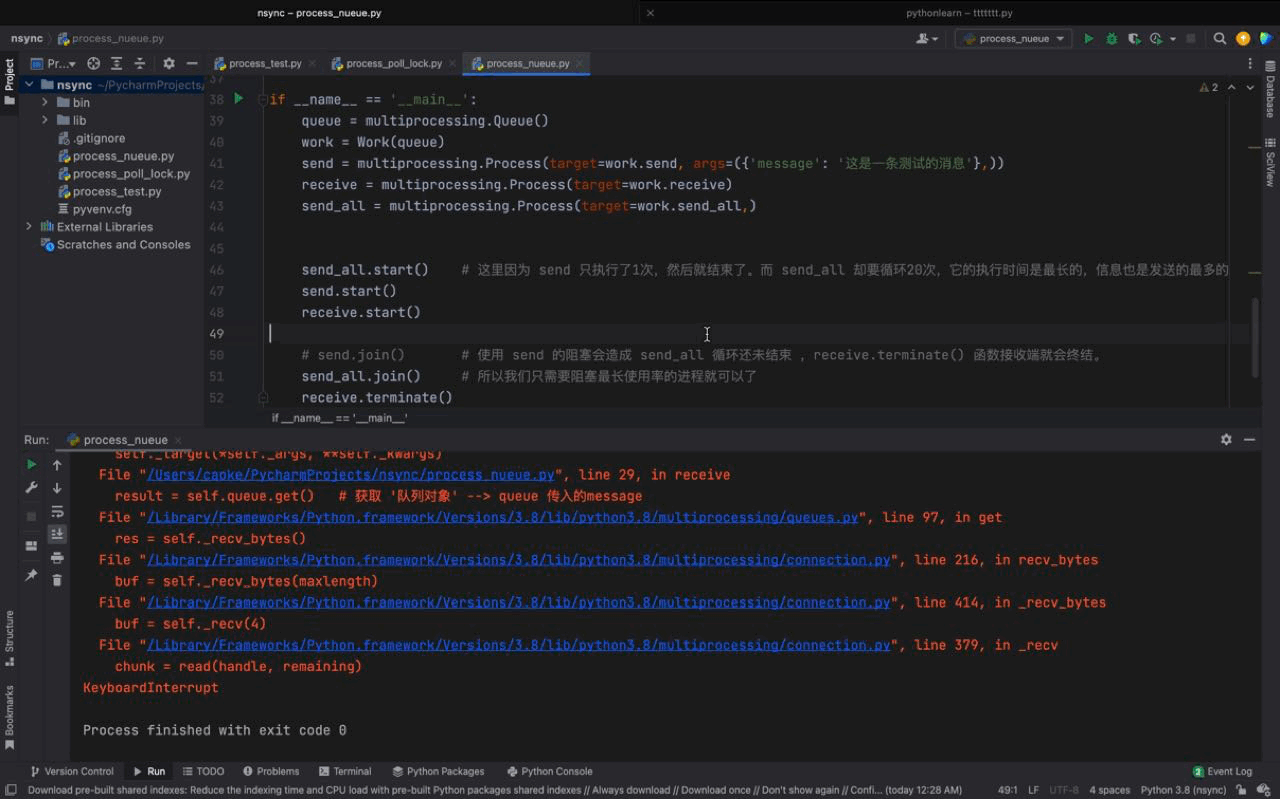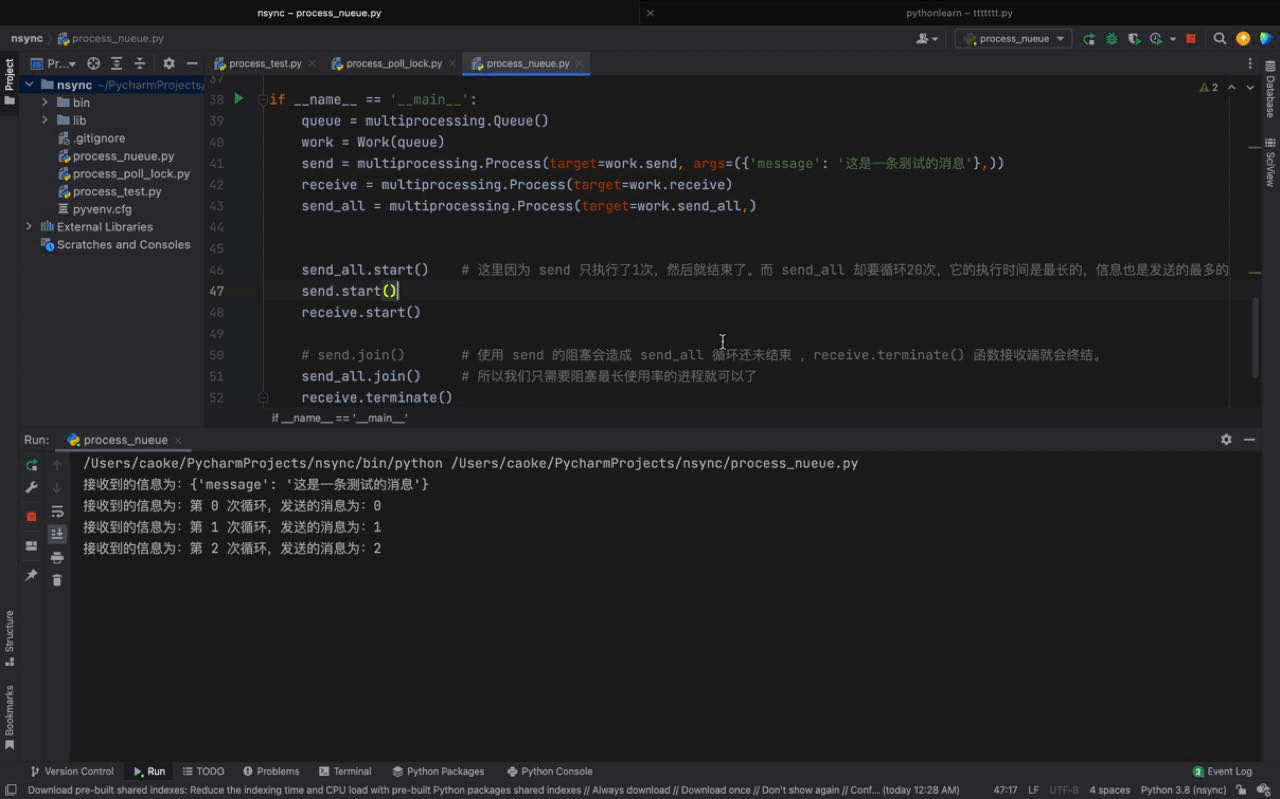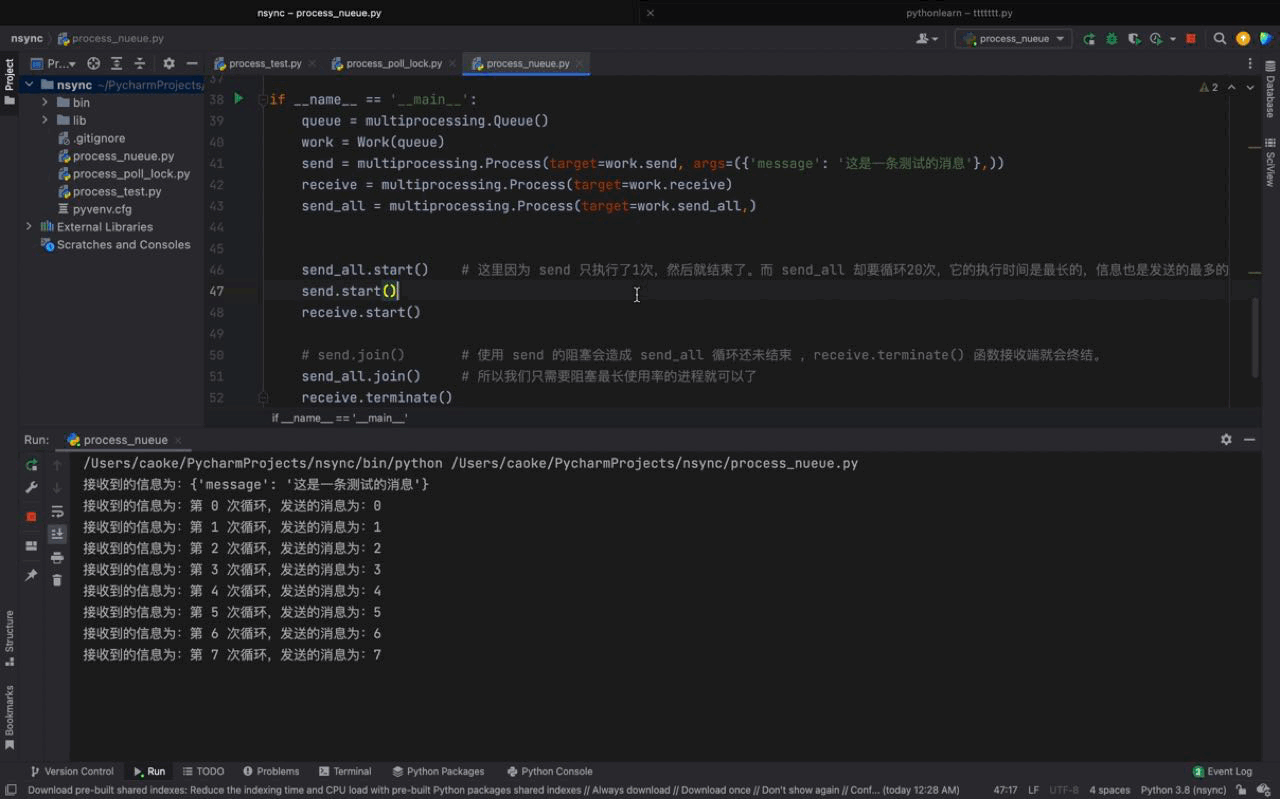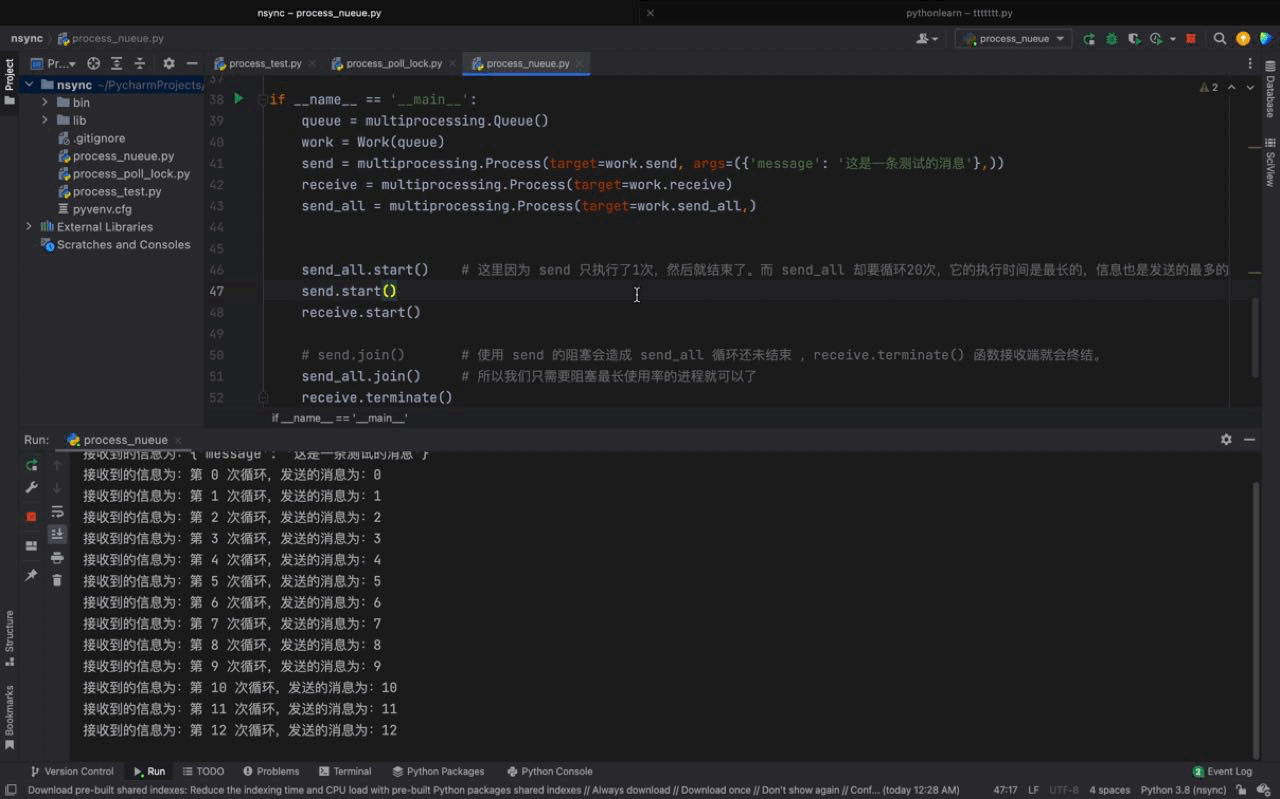
receive.terminate()Nach dem Login kopieren Die laufenden Ergebnisse lauten wie folgt:
Aus der obigen Abbildung können wir sehen, dass sowohl send- als auch send_all-Prozesse Nachrichten über das von der Warteschlange instanziierte Warteschlangenobjekt senden können gleiche Empfangsfunktion Die von den beiden Prozessen übergebenen Nachrichten werden ebenfalls ausgedruckt. AbschnittIn diesem Kapitel haben wir Warteschlangen erfolgreich eingesetzt, um eine prozessübergreifende Kommunikation zu erreichen, und auch die Betriebsfähigkeiten von Warteschlangen gemeistert. In einer Warteschlange fügt ein Ende (hier demonstrieren wir das Sendeende) relevante Informationen über die Put-Methode hinzu, und das andere Ende verwendet die Get-Methode, um relevante Informationen abzurufen, um die Wirkung eines Prozesses zu erzielen Kommunikation. Zusätzlich zu Warteschlangen können Prozesse auch über Pipes, Semaphoren und Shared Memory kommunizieren. Wenn Sie interessiert sind, können Sie sich über diese Methoden informieren. Sie können es selbst erweitern. Andere Möglichkeiten der Kommunikation zwischen Prozessen – ErgänzungPython bietet eine Vielzahl von Möglichkeiten der Prozesskommunikation, einschließlich Signale, Pipes, Nachrichtenwarteschlangen, Semaphoren, gemeinsam genutzter Speicher, Sockets usw. Die beiden wichtigsten Methoden sind Warteschlange und Pipe . Warteschlange Wird zur Implementierung der Kommunikation zwischen mehreren Prozessen verwendet. Pipe ist die Kommunikation zwischen zwei Prozessen. 1. Pipes: unterteilt in anonyme Pipes und benannte Pipes Anonyme Pipes: Beantragen Sie einen Puffer mit fester Größe im Kernel. Im Allgemeinen wird die Fock-Funktion verwendet, um die Kommunikation zwischen ihnen zu realisieren Übergeordnete und untergeordnete Prozesse Benannte Pipe: Beantragen Sie einen Puffer mit fester Größe im Speicher. Das Programm hat das Recht, auch zwischen Prozessen zu kommunizieren, die nicht miteinander verbunden sind. Eigenschaften: Orientiert an Byte-Streams. Der Lebenszyklus folgt dem Kernel und ist mit einem synchronen gegenseitigen Ausschlussmechanismus ausgestattet. Zwei Pipes realisieren eine bidirektionale Kommunikation. Eine Möglichkeit zum Umschreiben besteht darin, eine Warteschlange im Betriebssystemkern einzurichten, die die Warteschlange enthält Mehrere Datagrammelemente und mehrere Prozesse können über ein bestimmtes Handle auf die Warteschlange zugreifen. Nachrichtenwarteschlangen können verwendet werden, um Daten von einem Prozess an einen anderen zu senden. Es wird davon ausgegangen, dass jeder Datenblock einen Typ hat, und die vom Empfängerprozess empfangenen Datenblöcke können unterschiedliche Typen haben. Nachrichtenwarteschlangen weisen auch die gleichen Mängel wie Pipes auf, dh es gibt eine Obergrenze für die maximale Länge jeder Nachricht, eine Obergrenze für die Gesamtzahl der Bytes in jeder Nachrichtenwarteschlange und auch eine Obergrenze für die Gesamtzahl der Nachrichtenwarteschlangen im System Merkmale: Nachrichtenwarteschlange Es kann als globale verknüpfte Liste betrachtet werden. Der Typ und der Inhalt des Datagramms werden in den Knoten der verknüpften Liste gespeichert, die mit der Kennung der Nachrichtenwarteschlange gekennzeichnet sind ; Die Nachrichtenwarteschlange ermöglicht es einem oder mehreren Prozessen, Nachrichten zu schreiben oder zu lesen. Der Zyklus folgt dem Kernel und kann eine bidirektionale Kommunikation erreichen 3. Semaphor: Erstellen Sie eine Semaphorsammlung (im Wesentlichen ein Array) im Kernel. Die Elemente des Arrays (Semaphore) sind alle 1. Verwenden Sie die P-Operation, um -1 auszuführen, und verwenden Sie die V-Operation, um +1 P auszuführen (sv): Wenn der Wert von sv größer als Null ist, dekrementieren Sie ihn um 1; wenn sein Wert Null ist, unterbrechen Sie die Ausführung des Programms Wenn kein Prozess aufgrund des Wartens auf sv hängen bleibt, fügen Sie 1 hinzu. Der PV-Vorgang wird für denselben Prozess verwendet, um einen gegenseitigen Ausschluss zu erreichen. Funktion: Schützen Sie kritische Ressourcen 4. Gemeinsam genutzter Speicher: Ordnen Sie denselben Teil des physischen Speichers dem virtuellen Adressraum verschiedener Prozesse zu, um die gemeinsame Nutzung derselben Ressource zwischen verschiedenen Prozessen zu erreichen. Wenn es um Kommunikationsmethoden zwischen Prozessen geht, kann Shared Memory als die nützlichste und schnellste Form von IPC bezeichnet werden. Eigenschaften: Im Gegensatz zum häufigen Wechseln und Kopieren von Daten vom Benutzermodus in den Kernelmodus können Sie sie einfach direkt aus dem Speicher lesen ; gemeinsame Nutzung Der Speicher ist eine kritische Ressource, daher muss die Atomizität gewährleistet sein, wenn Vorgänge erforderlich sind. Sie können ein Semaphor oder einen Mutex verwenden. |
Das obige ist der detaillierte Inhalt vonWas ist die Kommunikationsmethode zwischen Python-Prozessen?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Muss MySQL bezahlen?
Apr 08, 2025 pm 05:36 PM
Muss MySQL bezahlen?
Apr 08, 2025 pm 05:36 PM
MySQL hat eine kostenlose Community -Version und eine kostenpflichtige Enterprise -Version. Die Community -Version kann kostenlos verwendet und geändert werden, die Unterstützung ist jedoch begrenzt und für Anwendungen mit geringen Stabilitätsanforderungen und starken technischen Funktionen geeignet. Die Enterprise Edition bietet umfassende kommerzielle Unterstützung für Anwendungen, die eine stabile, zuverlässige Hochleistungsdatenbank erfordern und bereit sind, Unterstützung zu bezahlen. Zu den Faktoren, die bei der Auswahl einer Version berücksichtigt werden, gehören Kritikalität, Budgetierung und technische Fähigkeiten von Anwendungen. Es gibt keine perfekte Option, nur die am besten geeignete Option, und Sie müssen die spezifische Situation sorgfältig auswählen.
 So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
Der Artikel führt den Betrieb der MySQL -Datenbank vor. Zunächst müssen Sie einen MySQL -Client wie MySQLworkBench oder Befehlszeilen -Client installieren. 1. Verwenden Sie den Befehl mySQL-uroot-P, um eine Verbindung zum Server herzustellen und sich mit dem Stammkonto-Passwort anzumelden. 2. Verwenden Sie die Erstellung von Createdatabase, um eine Datenbank zu erstellen, und verwenden Sie eine Datenbank aus. 3.. Verwenden Sie CreateTable, um eine Tabelle zu erstellen, Felder und Datentypen zu definieren. 4. Verwenden Sie InsertInto, um Daten einzulegen, Daten abzufragen, Daten nach Aktualisierung zu aktualisieren und Daten nach Löschen zu löschen. Nur indem Sie diese Schritte beherrschen, lernen, mit gemeinsamen Problemen umzugehen und die Datenbankleistung zu optimieren, können Sie MySQL effizient verwenden.
 Die MySQL -Download -Datei ist beschädigt und kann nicht installiert werden. Reparaturlösung
Apr 08, 2025 am 11:21 AM
Die MySQL -Download -Datei ist beschädigt und kann nicht installiert werden. Reparaturlösung
Apr 08, 2025 am 11:21 AM
Die MySQL -Download -Datei ist beschädigt. Was soll ich tun? Wenn Sie MySQL herunterladen, können Sie die Korruption der Datei begegnen. Es ist heutzutage wirklich nicht einfach! In diesem Artikel wird darüber gesprochen, wie dieses Problem gelöst werden kann, damit jeder Umwege vermeiden kann. Nach dem Lesen können Sie nicht nur das beschädigte MySQL -Installationspaket reparieren, sondern auch ein tieferes Verständnis des Download- und Installationsprozesses haben, um zu vermeiden, dass Sie in Zukunft stecken bleiben. Lassen Sie uns zunächst darüber sprechen, warum das Herunterladen von Dateien beschädigt wird. Dafür gibt es viele Gründe. Netzwerkprobleme sind der Schuldige. Unterbrechung des Download -Prozesses und der Instabilität im Netzwerk kann zu einer Korruption von Dateien führen. Es gibt auch das Problem mit der Download -Quelle selbst. Die Serverdatei selbst ist gebrochen und natürlich auch unterbrochen, wenn Sie sie herunterladen. Darüber hinaus kann das übermäßige "leidenschaftliche" Scannen einer Antiviren -Software auch zu einer Beschädigung von Dateien führen. Diagnoseproblem: Stellen Sie fest, ob die Datei wirklich beschädigt ist
 MySQL kann nach dem Herunterladen nicht installiert werden
Apr 08, 2025 am 11:24 AM
MySQL kann nach dem Herunterladen nicht installiert werden
Apr 08, 2025 am 11:24 AM
Die Hauptgründe für den Fehler bei MySQL -Installationsfehlern sind: 1. Erlaubnisprobleme, Sie müssen als Administrator ausgeführt oder den Sudo -Befehl verwenden. 2. Die Abhängigkeiten fehlen, und Sie müssen relevante Entwicklungspakete installieren. 3. Portkonflikte müssen Sie das Programm schließen, das Port 3306 einnimmt, oder die Konfigurationsdatei ändern. 4. Das Installationspaket ist beschädigt. Sie müssen die Integrität herunterladen und überprüfen. 5. Die Umgebungsvariable ist falsch konfiguriert und die Umgebungsvariablen müssen korrekt entsprechend dem Betriebssystem konfiguriert werden. Lösen Sie diese Probleme und überprüfen Sie jeden Schritt sorgfältig, um MySQL erfolgreich zu installieren.
 Lösungen für den Dienst, der nach der MySQL -Installation nicht gestartet werden kann
Apr 08, 2025 am 11:18 AM
Lösungen für den Dienst, der nach der MySQL -Installation nicht gestartet werden kann
Apr 08, 2025 am 11:18 AM
MySQL hat sich geweigert, anzufangen? Nicht in Panik, lass es uns ausprobieren! Viele Freunde stellten fest, dass der Service nach der Installation von MySQL nicht begonnen werden konnte, und sie waren so ängstlich! Mach dir keine Sorgen, dieser Artikel wird dich dazu bringen, ruhig damit umzugehen und den Mastermind dahinter herauszufinden! Nachdem Sie es gelesen haben, können Sie dieses Problem nicht nur lösen, sondern auch Ihr Verständnis von MySQL -Diensten und Ihren Ideen zur Fehlerbehebungsproblemen verbessern und zu einem leistungsstärkeren Datenbankadministrator werden! Der MySQL -Dienst startete nicht und es gibt viele Gründe, von einfachen Konfigurationsfehlern bis hin zu komplexen Systemproblemen. Beginnen wir mit den häufigsten Aspekten. Grundkenntnisse: Eine kurze Beschreibung des Service -Startup -Prozesses MySQL Service Startup. Einfach ausgedrückt, lädt das Betriebssystem MySQL-bezogene Dateien und startet dann den MySQL-Daemon. Dies beinhaltet die Konfiguration
 Wie optimieren Sie die MySQL-Leistung für Hochlastanwendungen?
Apr 08, 2025 pm 06:03 PM
Wie optimieren Sie die MySQL-Leistung für Hochlastanwendungen?
Apr 08, 2025 pm 06:03 PM
Die MySQL-Datenbankleistung Optimierungshandbuch In ressourcenintensiven Anwendungen spielt die MySQL-Datenbank eine entscheidende Rolle und ist für die Verwaltung massiver Transaktionen verantwortlich. Mit der Erweiterung der Anwendung werden jedoch die Datenbankleistung Engpässe häufig zu einer Einschränkung. In diesem Artikel werden eine Reihe effektiver Strategien zur Leistungsoptimierung von MySQL -Leistung untersucht, um sicherzustellen, dass Ihre Anwendung unter hohen Lasten effizient und reaktionsschnell bleibt. Wir werden tatsächliche Fälle kombinieren, um eingehende Schlüsseltechnologien wie Indexierung, Abfrageoptimierung, Datenbankdesign und Caching zu erklären. 1. Das Design der Datenbankarchitektur und die optimierte Datenbankarchitektur sind der Eckpfeiler der MySQL -Leistungsoptimierung. Hier sind einige Kernprinzipien: Die Auswahl des richtigen Datentyps und die Auswahl des kleinsten Datentyps, der den Anforderungen entspricht, kann nicht nur Speicherplatz speichern, sondern auch die Datenverarbeitungsgeschwindigkeit verbessern.
 So optimieren Sie die Datenbankleistung nach der MySQL -Installation
Apr 08, 2025 am 11:36 AM
So optimieren Sie die Datenbankleistung nach der MySQL -Installation
Apr 08, 2025 am 11:36 AM
Die MySQL -Leistungsoptimierung muss von drei Aspekten beginnen: Installationskonfiguration, Indexierung und Abfrageoptimierung, Überwachung und Abstimmung. 1. Nach der Installation müssen Sie die my.cnf -Datei entsprechend der Serverkonfiguration anpassen, z. 2. Erstellen Sie einen geeigneten Index, um übermäßige Indizes zu vermeiden und Abfrageanweisungen zu optimieren, z. B. den Befehl Erklärung zur Analyse des Ausführungsplans; 3. Verwenden Sie das eigene Überwachungstool von MySQL (ShowProcessList, Showstatus), um die Datenbankgesundheit zu überwachen und die Datenbank regelmäßig zu sichern und zu organisieren. Nur durch kontinuierliche Optimierung dieser Schritte kann die Leistung der MySQL -Datenbank verbessert werden.
 Braucht MySQL das Internet?
Apr 08, 2025 pm 02:18 PM
Braucht MySQL das Internet?
Apr 08, 2025 pm 02:18 PM
MySQL kann ohne Netzwerkverbindungen für die grundlegende Datenspeicherung und -verwaltung ausgeführt werden. Für die Interaktion mit anderen Systemen, Remotezugriff oder Verwendung erweiterte Funktionen wie Replikation und Clustering ist jedoch eine Netzwerkverbindung erforderlich. Darüber hinaus sind Sicherheitsmaßnahmen (wie Firewalls), Leistungsoptimierung (Wählen Sie die richtige Netzwerkverbindung) und die Datensicherung für die Verbindung zum Internet von entscheidender Bedeutung.
