
 Technologie-Peripheriegeräte
KI
Die Vereinigten Staaten haben 2,6 Milliarden US-Dollar für künstliche Intelligenz ausgegeben ... Es wird erwartet, dass der Bau von NAIRR innerhalb von 6 Jahren abgeschlossen wird
Technologie-Peripheriegeräte
KI
Die Vereinigten Staaten haben 2,6 Milliarden US-Dollar für künstliche Intelligenz ausgegeben ... Es wird erwartet, dass der Bau von NAIRR innerhalb von 6 Jahren abgeschlossen wird
Die Vereinigten Staaten haben 2,6 Milliarden US-Dollar für künstliche Intelligenz ausgegeben ... Es wird erwartet, dass der Bau von NAIRR innerhalb von 6 Jahren abgeschlossen wird

Künstliche Intelligenz ist eine strategische Technologie, die eine neue Runde der technologischen Revolution und des industriellen Wandels anführt. Mehrere Forschungsergebnisse und Daten zeigen, dass die Vereinigten Staaten weltweit führend in der wissenschaftlichen Grundlagenforschung, der technologischen Innovation und den industriellen Anwendungen künstlicher Intelligenz sind. Indikatoren wie hochrangige wissenschaftliche Arbeiten zur künstlichen Intelligenz, Anzahl der Spitzenwissenschaftler, Anzahl der Unternehmen der künstlichen Intelligenz usw Der Investitionsumfang ist allen anderen Ländern voraus.
Die US-Regierung legt großen Wert auf die Innovation und Entwicklung der Technologie der künstlichen Intelligenz. Gemäß dem National AI Initiative Act von 2020 verlangt der Kongress, dass die National Science Foundation (NSF) und das Büro für Wissenschafts- und Technologiepolitik des Weißen Hauses (OSTP) im Januar 2023 eine Arbeitsgruppe bilden, um die Vereinigten Staaten zu untersuchen und zu formulieren Der Fahrplan für den Aufbau der Infrastruktur der Artificial Intelligence Research Resource (NAIRR) festigt den Wettbewerbsvorteil der Vereinigten Staaten im Bereich der künstlichen Intelligenz, erweitert die Möglichkeiten für alle Parteien in den Vereinigten Staaten, wichtige künstliche Intelligenz und Bildungsressourcen zu erhalten, und treibt die Innovation und Innovation im Bereich der künstlichen Intelligenz in den USA weiter voran wirtschaftlicher Wohlstand.
Der Hintergrund und die Bedeutung des Baus von NAIRR in den Vereinigten Staaten
Bauhintergrund
Die US-Regierung ist der Ansicht, dass ihre Führungsposition im Bereich der künstlichen Intelligenz in Frage gestellt wird und ihr Wettbewerbsvorteil Gefahr läuft, geschwächt zu werden. Es gibt zwei Hauptprobleme: Erstens sind die Investitionen in Forschung und Entwicklung im Bereich der künstlichen Intelligenz sowie in Bildungsressourcen ungleich verteilt. Forschungsdaten zeigen, dass sich aus Investitionssicht die Höhe der Investitionen in künstliche Intelligenz aus dem privaten Sektor in den Vereinigten Staaten von 2020 bis 2021 mehr als verdoppelt hat, die Zahl neuer Unternehmen für künstliche Intelligenz jedoch zurückgeht; und Rasse der US-amerikanischen Doktoranden im Bereich der künstlichen Intelligenz. Die Verteilung, die Geschlechterverteilung und der tatsächliche Anteil der Bevölkerung sind sehr unterschiedlich, was die Innovation und Entwicklung der künstlichen Intelligenz einschränken wird. Zweitens verfügen wissenschaftliche Forschungseinrichtungen über unzureichende Rechenressourcen und Datenressourcen. Aus Sicht der Rechenleistung befinden sich die fortschrittlichsten Rechenleistungsplattformen im Besitz branchenführender privater Institutionen, und wissenschaftlichen Forschungseinrichtungen fehlen Rechenleistungsplattformen, um die Forschung und Entwicklung im Bereich der künstlichen Intelligenz zu unterstützen Die Ausbildung von Modellen für künstliche Intelligenz ist im Besitz privater Institutionen und großer Internet-Plattformen. Obwohl die US-Regierung weiterhin Daten offenlegt, reichen diese für die Forschung im Bereich der künstlichen Intelligenz immer noch nicht aus.
Die Arbeitsgruppe wies darauf hin, dass der Mangel an ausreichenden Forschungsressourcen für künstliche Intelligenz das Innovationsökosystem für künstliche Intelligenz in den USA einschränken wird, was dazu führen wird, dass sich Top-Talente von akademischen Forschungseinrichtungen auf eine kleine Anzahl ressourcenreicher Unternehmen konzentrieren Wenn sich dieser Trend langfristig durchsetzt, wird er die Wettbewerbsfähigkeit und Innovationsfähigkeit der Vereinigten Staaten beeinträchtigen. Im Januar 2023, nach 18 Monaten öffentlicher Meinungseinholung und Diskussion, schlug die Arbeitsgruppe offiziell einen Bauplan vor und plante die Beantragung von Bau-, Betriebs- und Wartungsmitteln in Höhe von 2,6 Milliarden US-Dollar. Sie plant, die NAIRR-Bauarbeiten in vier Phasen abzuschließen innerhalb von 6 Jahren, wobei der Schwerpunkt auf der Erreichung von vier Hauptzielen liegt: Sammeln von Ressourcen zur Förderung von Forschungsinnovationen, zur Verbesserung der Talentvielfalt, zur Verbesserung grundlegender Ressourcenkapazitäten und zur Förderung der Entwicklung vertrauenswürdiger künstlicher Intelligenz.
Wichtigkeit
NAIRR ist eine Forschungsinfrastruktur für künstliche Intelligenz und steht amerikanischen Forschungsschulen, Studenten und gemeinnützigen Organisationen offen. Es stellt grundlegende Forschungsressourcen wie Computerressourcen, hochwertige Daten und Bildungstools bereit Es wird erwartet, dass es die führende Forschungsplattform für künstliche Intelligenz in den Vereinigten Staaten wird. Ein wichtiger Knotenpunkt für die Zusammenarbeit, um seinen internationalen Wettbewerbsvorteil zu festigen.
Im Hinblick auf den ökologischen Aufbau wird sich die US-Regierung auf NAIRR verlassen, um relevante interne Regierungsabteilungen und wissenschaftliche Forschungseinrichtungen zu vereinen, um gemeinsam kooperative Forschung und Ressourcenaufbau im Bereich der künstlichen Intelligenz durchzuführen und so ein breites kooperatives Ökosystem zu bilden. NAIRR-Dienste und -Funktionen sind in Abbildung 1 dargestellt.
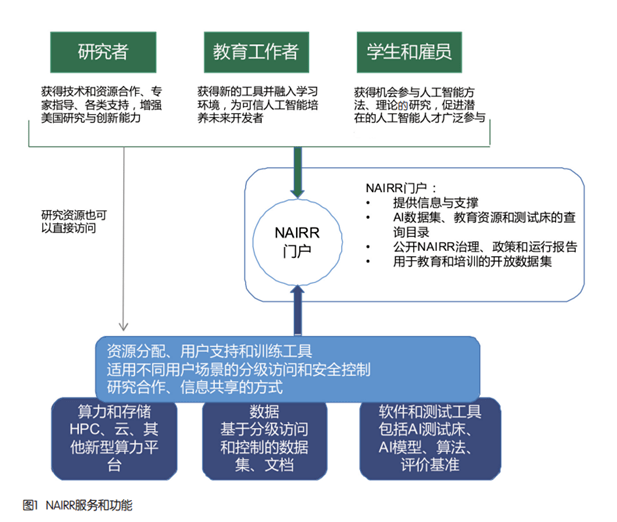
In Bezug auf Daten wird NAIRR Daten von Bundesbehörden aggregieren und Datendienstkooperationen mit verschiedenen Institutionen der Branche durchführen. Die erste besteht darin, die Aggregation, Entwicklung und Nutzung umfangreicher Datenressourcen für künstliche Intelligenz zu fördern. Dabei werden die umfangreichen Datenressourcen gesammelt und verbunden, die von US-Bundesbehörden, akademischen Forschungseinrichtungen und Technologiegiganten als Open-Source-Lösungen bereitgestellt wurden größte Datenressourcendienstplattform für künstliche Intelligenz in den Vereinigten Staaten. Beispielsweise haben die National Institutes of Health in den Vereinigten Staaten mehr als 36 PB an Gensequenzierungsdaten veröffentlicht, und die National Oceanic and Atmospheric Administration hat mehr als 10 PB an Wetter- und Umweltdaten veröffentlicht. Die zweite besteht darin, die Verbesserung der Datenverwaltungs- und Governance-Fähigkeiten künstlicher Intelligenz zu fördern. Datensätze für künstliche Intelligenz sind stark fragmentiert. Jeder Datensatz unterstützt spezielle Aufgaben und Forschungsbereiche. Es mangelt an einheitlichen Standards für Datenannotation und Datenverwaltung, was die Datenverwaltung erschwert. NAIRR wird die Einrichtung einheitlicher Standards für die Datenaggregation fördern, Datenbeschreibungsformate standardisieren und die Aggregation von Datenressourcen mehrerer Parteien fördern. Die dritte besteht darin, die Entwicklung und Nutzung von Datenressourcen durch die Zusammenarbeit mehrerer Parteien zu fördern. Die Betreibergesellschaft wird die Community für künstliche Intelligenz-Datensätze betreiben und die Community dazu ermutigen, aktiv wertvolle Datenressourcen für die Nutzung durch NAIRR zu entwickeln und aufzubauen. Betriebseinheiten werden auch Datensuchdienste bereitstellen, um die Abfrage offener Daten und Datenressourcen von Bundesbehörden von Drittanbietern zu erleichtern.
In Bezug auf die Rechenleistung wird NAIRR mit großen US-amerikanischen Cloud-Plattformunternehmen für künstliche Intelligenz zusammenarbeiten, um eine Rechenleistungsplattform aufzubauen, und plant, sich mit den Cloud-Plattformen von Technologiegiganten wie Google, Microsoft und Amazon zu verbinden sowie die U.S. Natural Science Foundation und die U.S. National Institutes of Health und andere Cloud-Plattformen für Bundesbehörden. Die Plattform bietet unterschiedliche Servicemodelle und Inhalte für Universitäten, Forschungseinrichtungen, Studenten und Start-ups, darunter eine Vielzahl von Diensten und Ressourcen wie Daten, Rechenleistung, Prüfstände und Softwaretools. Nach der Fertigstellung werden die Rechenressourcen von NAIRR Supercomputer umfassen, die das Training von Modellen für maschinelles Lernen im Parametermaßstab von mindestens einer Billion unterstützen, sowie Cloud-Computing-Ressourcen, CPUs, GPUs und Hochgeschwindigkeitsnetzwerke.
Nachdem die NAIRR-Infrastruktur etabliert und stabil betrieben ist, wird sie einerseits die Kooperationsbeziehungen mit Regierungsstellen und privaten Institutionen weiter ausbauen, den Umfang der Plattformdienste und Benutzer erweitern und andererseits erfolgreiche Erfahrungen bekannt machen Andererseits wird die Plattform die Formulierung relevanter Standards und Standardisierungen fördern, am internationalen Austausch und an der Zusammenarbeit teilnehmen und als grundlegende Plattform für die Vereinigten Staaten und ihre Verbündeten und Partner dienen, um kooperative Forschung und Datenaustausch zu fördern.
Amerikanischer NAIRR-Bauplan
Die Vereinigten Staaten planen, mit einem systematischen Ansatz die Bundesregierung und private Institutionen zu mobilisieren, um gemeinsam eine Forschungsressourceninfrastruktur für künstliche Intelligenz für die akademische Forschung aufzubauen.
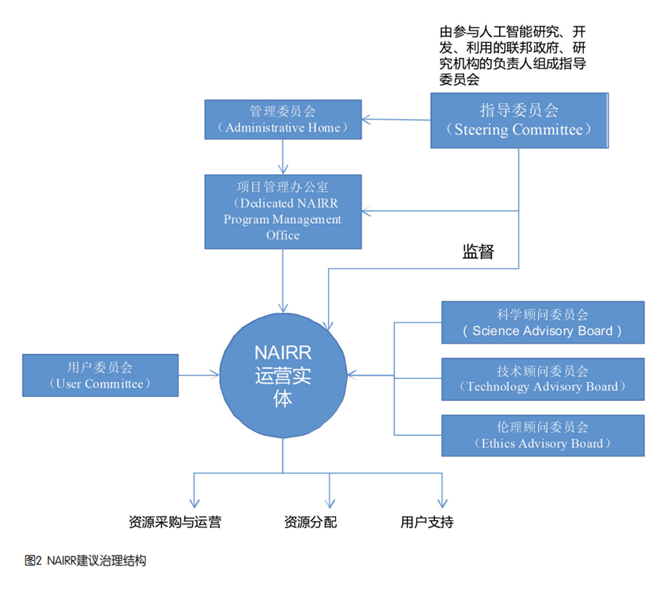
Die erste besteht darin, ein Plattform-Governance-System mit Mehrparteienbeteiligung zu planen und aufzubauen. Die von NAIRR vorgeschlagene Governance-Struktur ist in Abbildung 2 dargestellt. Der Plan empfiehlt die Einrichtung eines Governance-Systems mit Beteiligung mehrerer Regierungsstellen und die Einrichtung einer Reihe verantwortlicher Organisationen wie eines Lenkungsausschusses, eines Verwaltungsausschusses, eines Projektmanagementbüros, einer Betriebseinheit und eines Beratungsausschusses für die Zusammenarbeit. Richten Sie einen Lenkungsausschuss ein, der sich aus Vertretern verschiedener Bundesministerien und -behörden zusammensetzt. Er ist das höchste Entscheidungsgremium auf nationaler Ebene für die Gesamtplanung und die strategischen Ziele von NAIRR. Er vertritt verschiedene Abteilungen zur Förderung nationaler Ressourceninvestitionen im Bereich künstliche Intelligenz. Es wird ein Verwaltungsausschuss eingerichtet, der die Betreiber der Plattform leitet und verwaltet sowie Mittel und zugehörige Ressourcen bereitstellt. Der Plan sieht vor, dass NSF die Aufgaben des Verwaltungsausschusses übernimmt. Richten Sie ein Projektmanagementbüro ein, um mit dem Lenkungsausschuss bei der täglichen Verwaltung und Bewertung der operativen Einheiten zusammenzuarbeiten. Der US-Kongress genehmigte die Finanzierung des Project Management Office zur Unterstützung des damit verbundenen Projektmanagements, der Portalentwicklung und -bereitstellung, des gemeinsamen Supports, der Schulung und der Benutzerunterstützung. Richten Sie eine Betriebseinheit ein, die unabhängig von Regierungsabteilungen ist und für die Formulierung spezifischer Entwicklungsziele für NAIRR, die Organisation des Plattformbaus und des täglichen Betriebsmanagements sowie die Formulierung eines transparenten, fairen und angemessenen Ressourcenzuweisungssystems verantwortlich ist, um den Anforderungen verschiedener Forschungseinrichtungen für künstliche Intelligenz gerecht zu werden und Benutzer. Zur Unterstützung der Entscheidungsfindung beim Bau von NAIRR wurden ein wissenschaftlicher Ausschuss, ein technischer Ausschuss, ein Ethikausschuss und ein Benutzerausschuss eingerichtet, die sich aus Experten verschiedener Fachgebiete zusammensetzen.
Die zweite besteht darin, zweckgebundene Mittel für den Betrieb und Bau der NAIRR-Infrastruktur bereitzustellen. Der Bauplan sieht vor, über einen Zeitraum von sechs Jahren Fördermittel in Höhe von 2,6 Milliarden US-Dollar zu beantragen, wovon 2,25 Milliarden US-Dollar für den Kauf von Plattform-Rechenleistung, Software-Tools und Datenressourcen von Dienstleistern verwendet werden sollen. Die täglichen Kosten der Betriebsorganisation betragen 370 US-Dollar Millionen, und weitere 30 Millionen US-Dollar werden für die Lagebeurteilung der Infrastruktur verwendet. Alle an der Forschung und Entwicklung im Bereich der künstlichen Intelligenz beteiligten Bundesbehörden sollten am Projektmanagement von NAIRR beteiligt sein. F&E-Investitionen von Bundesbehörden im Bereich der künstlichen Intelligenz können weiterhin von jeder Behörde einzeln oder kooperativ erworben und entwickelt werden, sie sollten jedoch über die NAIRR-Infrastruktur verwaltet und bereitgestellt werden.
Die dritte besteht darin, die NAIRR-Infrastruktur schrittweise aufzubauen, die Rechenressourcen nach Bedarf zu erweitern und die Aggregation von Datenressourcen zu fördern. Der Plattformbau gliedert sich in vier Phasen: Projektinitiierung, Bau, Probebetrieb und Dauerbetrieb. In der Testbetriebsphase können 50.000 Benutzer unterstützt werden und vorhandene Daten von Bundesbehörden und privaten Behörden aggregiert und genutzt werden. Nach einem stabilen Betrieb wird es 150.000 Benutzer unterstützen und eine breitere Community für die Zusammenarbeit im Bereich Datenressourcen aufbauen. NAIRR wird Datenressourcen entwickeln, um die Datennutzung durch die Formulierung von Datenaggregationsstandards, die Entwicklung von Datenkooperationen und die Bereitstellung von Datensuchdiensten zu erleichtern.
Unter der neuen Situation ist die Bedeutung des Aufbaus von Grundlagenforschungsressourcen für künstliche Intelligenz immer wichtiger geworden
Derzeit entstehen ständig neue Technologien und neue Anwendungen künstlicher Intelligenz. Die Erforschung und Ausbildung einer neuen Generation großer künstlicher Intelligenzmodelle, die durch das große Sprachmodell ChatGPT repräsentiert werden, erfordert die Unterstützung größerer Rechenressourcen und Datenressourcen , und allein die Investitionen in Forschung und Entwicklung stiegen deutlich an. Der Schwellenwert der Rechenleistungsplattform für das Training großer Modelle künstlicher Intelligenz ist extrem hoch, und normale Institutionen können sich große Forschungs- und Entwicklungskosten sowie Betriebskosten nicht leisten. OpenAI-Forschung zeigt, dass die für das Training von KI-Modellen erforderliche Rechenleistung exponentiell gestiegen ist. Von 2012 bis 2018 ist die für das Training von KI-Modellen verbrauchte Rechenleistung um das 300.000-fache gestiegen. Die für das Training von GPT3 erforderliche Rechenleistung beträgt 3640 Pfs pro Tag (d. h. eine Effizienz von 1 PetaFLOP/s läuft über 3640 Tage), und die Schulungskosten werden auf 1,4 Millionen US-Dollar pro Zeit geschätzt. Einige Organisationen schätzen, dass die anfänglichen Investitionskosten für ChatGPT etwa 1 US-Dollar betragen 800 Millionen Dollar.
In Bezug auf Datensätze für künstliche Intelligenz ist die Größe der für das Training erforderlichen Datensätze durch die Forschung und Entwicklung großer vorab trainierter Modelle weiter gestiegen. Die Datengröße ist von Millionen oder mehreren zehn Millionen in der Vergangenheit auf gestiegen Hunderte Millionen. Die aktuellen Datensätze, die beim Training großer Modelle verwendet werden, stammen hauptsächlich aus dem Internet, einschließlich Datenbanken wie Wikipedia, sozialen Netzwerken, öffentlichen Zeitschriften, Büchern, Artikeln und Codes. Einige Studien haben darauf hingewiesen, dass „Trainingsdaten zu einem der größten Hindernisse für die Industrialisierung großer Modelle werden“. Aus einer tieferen Perspektive weisen große Modelle immer noch verschiedene Governance-Probleme in Bezug auf Trainingsdaten auf, wie z - aufwändig, mühsam und kostspielig, und die Datenqualität ist schwierig. Es gibt nicht genügend Garantien und Datendiversifizierung, um die „Long Tail“- und Randfälle abzudecken, und es gibt Probleme wie Datenschutz und Datenverzerrung bei der Erfassung, Nutzung und Weitergabe spezifischer Daten „Ausländische Wissenschaftler gehen davon aus, dass der Gesamtumfang der Sprachdaten um 7 % wächst. Das Wachstum hochwertiger Sprachdaten hängt von Faktoren wie der Bevölkerungsgröße und der wirtschaftlichen Entwicklung ab und wächst um 4 %. bis 5 %. Hochwertige Daten zum Training großer Sprachmodelle werden bis 2027 „erschöpft“ sein.
Zusammenfassung
Rechenleistung und Datenressourcen sind die grundlegenden unterstützenden Elemente für die Technologieforschung im Bereich der künstlichen Intelligenz. Mit dem Eintritt der künstlichen Intelligenz in die Ära der „großen Modelle“ sind Rechenleistung und Datenkapazität zu limitierenden Faktoren für die Forschung und Schulung von Algorithmenmodellen geworden. Die in den Vereinigten Staaten aufgebaute NAIRR-Infrastruktur trägt zur Lösung der neuen Herausforderungen bei, denen sich die aktuelle Innovation und Entwicklung der Technologie der künstlichen Intelligenz gegenübersieht, und hat für mein Land eine gewisse Referenzbedeutung. Mein Land sollte die Gesamtplanung und -koordinierung stärken und den Aufbau beschleunigen Recheninfrastruktur und grundlegende Datenressourcen sowie Entwicklung des Datenelementmarktes, Förderung der Sammlung und Verbreitung von Datenressourcen sowie Förderung der Grundlagenforschung und Anwendungsinnovation der künstlichen Intelligenz.
ENDE
Autor: Lu Yapeng, Wang Weiguo, Datenforschungszentrum, China Academy of Information and Communications Technology
Herausgeber/Formatierer: Gai Beibei
Rezensiert von: Shu Wenqiong
Produzent: Liu Qicheng
Likes und Views gibt es hier
Das obige ist der detaillierte Inhalt vonDie Vereinigten Staaten haben 2,6 Milliarden US-Dollar für künstliche Intelligenz ausgegeben ... Es wird erwartet, dass der Bau von NAIRR innerhalb von 6 Jahren abgeschlossen wird. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Bytedance Cutting führt SVIP-Supermitgliedschaft ein: 499 Yuan für ein fortlaufendes Jahresabonnement, das eine Vielzahl von KI-Funktionen bietet
Jun 28, 2024 am 03:51 AM
Bytedance Cutting führt SVIP-Supermitgliedschaft ein: 499 Yuan für ein fortlaufendes Jahresabonnement, das eine Vielzahl von KI-Funktionen bietet
Jun 28, 2024 am 03:51 AM
Diese Seite berichtete am 27. Juni, dass Jianying eine von FaceMeng Technology, einer Tochtergesellschaft von ByteDance, entwickelte Videobearbeitungssoftware ist, die auf der Douyin-Plattform basiert und grundsätzlich kurze Videoinhalte für Benutzer der Plattform produziert Windows, MacOS und andere Betriebssysteme. Jianying kündigte offiziell die Aktualisierung seines Mitgliedschaftssystems an und führte ein neues SVIP ein, das eine Vielzahl von KI-Schwarztechnologien umfasst, wie z. B. intelligente Übersetzung, intelligente Hervorhebung, intelligente Verpackung, digitale menschliche Synthese usw. Preislich beträgt die monatliche Gebühr für das Clipping von SVIP 79 Yuan, die Jahresgebühr 599 Yuan (Hinweis auf dieser Website: entspricht 49,9 Yuan pro Monat), das fortlaufende Monatsabonnement beträgt 59 Yuan pro Monat und das fortlaufende Jahresabonnement beträgt 499 Yuan pro Jahr (entspricht 41,6 Yuan pro Monat). Darüber hinaus erklärte der Cut-Beamte auch, dass diejenigen, die den ursprünglichen VIP abonniert haben, das Benutzererlebnis verbessern sollen
 Kontexterweiterter KI-Codierungsassistent mit Rag und Sem-Rag
Jun 10, 2024 am 11:08 AM
Kontexterweiterter KI-Codierungsassistent mit Rag und Sem-Rag
Jun 10, 2024 am 11:08 AM
Verbessern Sie die Produktivität, Effizienz und Genauigkeit der Entwickler, indem Sie eine abrufgestützte Generierung und ein semantisches Gedächtnis in KI-Codierungsassistenten integrieren. Übersetzt aus EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG, Autor JanakiramMSV. Obwohl grundlegende KI-Programmierassistenten natürlich hilfreich sind, können sie oft nicht die relevantesten und korrektesten Codevorschläge liefern, da sie auf einem allgemeinen Verständnis der Softwaresprache und den gängigsten Mustern beim Schreiben von Software basieren. Der von diesen Coding-Assistenten generierte Code eignet sich zur Lösung der von ihnen zu lösenden Probleme, entspricht jedoch häufig nicht den Coding-Standards, -Konventionen und -Stilen der einzelnen Teams. Dabei entstehen häufig Vorschläge, die geändert oder verfeinert werden müssen, damit der Code in die Anwendung übernommen wird
 Sieben coole technische Interviewfragen für GenAI und LLM
Jun 07, 2024 am 10:06 AM
Sieben coole technische Interviewfragen für GenAI und LLM
Jun 07, 2024 am 10:06 AM
Um mehr über AIGC zu erfahren, besuchen Sie bitte: 51CTOAI.x Community https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou unterscheidet sich von der traditionellen Fragendatenbank, die überall im Internet zu sehen ist erfordert einen Blick über den Tellerrand hinaus. Large Language Models (LLMs) gewinnen in den Bereichen Datenwissenschaft, generative künstliche Intelligenz (GenAI) und künstliche Intelligenz zunehmend an Bedeutung. Diese komplexen Algorithmen verbessern die menschlichen Fähigkeiten, treiben Effizienz und Innovation in vielen Branchen voran und werden zum Schlüssel für Unternehmen, um wettbewerbsfähig zu bleiben. LLM hat ein breites Anwendungsspektrum und kann in Bereichen wie der Verarbeitung natürlicher Sprache, der Textgenerierung, der Spracherkennung und Empfehlungssystemen eingesetzt werden. Durch das Lernen aus großen Datenmengen ist LLM in der Lage, Text zu generieren
 Kann LLM durch Feinabstimmung wirklich neue Dinge lernen: Die Einführung neuen Wissens kann dazu führen, dass das Modell mehr Halluzinationen hervorruft
Jun 11, 2024 pm 03:57 PM
Kann LLM durch Feinabstimmung wirklich neue Dinge lernen: Die Einführung neuen Wissens kann dazu führen, dass das Modell mehr Halluzinationen hervorruft
Jun 11, 2024 pm 03:57 PM
Large Language Models (LLMs) werden auf riesigen Textdatenbanken trainiert und erwerben dort große Mengen an realem Wissen. Dieses Wissen wird in ihre Parameter eingebettet und kann dann bei Bedarf genutzt werden. Das Wissen über diese Modelle wird am Ende der Ausbildung „verdinglicht“. Am Ende des Vortrainings hört das Modell tatsächlich auf zu lernen. Richten Sie das Modell aus oder verfeinern Sie es, um zu erfahren, wie Sie dieses Wissen nutzen und natürlicher auf Benutzerfragen reagieren können. Aber manchmal reicht Modellwissen nicht aus, und obwohl das Modell über RAG auf externe Inhalte zugreifen kann, wird es als vorteilhaft angesehen, das Modell durch Feinabstimmung an neue Domänen anzupassen. Diese Feinabstimmung erfolgt mithilfe von Eingaben menschlicher Annotatoren oder anderer LLM-Kreationen, wobei das Modell auf zusätzliches Wissen aus der realen Welt trifft und dieses integriert
 Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Herausgeber | Der Frage-Antwort-Datensatz (QA) von ScienceAI spielt eine entscheidende Rolle bei der Förderung der Forschung zur Verarbeitung natürlicher Sprache (NLP). Hochwertige QS-Datensätze können nicht nur zur Feinabstimmung von Modellen verwendet werden, sondern auch effektiv die Fähigkeiten großer Sprachmodelle (LLMs) bewerten, insbesondere die Fähigkeit, wissenschaftliche Erkenntnisse zu verstehen und zu begründen. Obwohl es derzeit viele wissenschaftliche QS-Datensätze aus den Bereichen Medizin, Chemie, Biologie und anderen Bereichen gibt, weisen diese Datensätze immer noch einige Mängel auf. Erstens ist das Datenformular relativ einfach, die meisten davon sind Multiple-Choice-Fragen. Sie sind leicht auszuwerten, schränken jedoch den Antwortauswahlbereich des Modells ein und können die Fähigkeit des Modells zur Beantwortung wissenschaftlicher Fragen nicht vollständig testen. Im Gegensatz dazu offene Fragen und Antworten
 Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Maschinelles Lernen ist ein wichtiger Zweig der künstlichen Intelligenz, der Computern die Möglichkeit gibt, aus Daten zu lernen und ihre Fähigkeiten zu verbessern, ohne explizit programmiert zu werden. Maschinelles Lernen hat ein breites Anwendungsspektrum in verschiedenen Bereichen, von der Bilderkennung und der Verarbeitung natürlicher Sprache bis hin zu Empfehlungssystemen und Betrugserkennung, und es verändert unsere Lebensweise. Im Bereich des maschinellen Lernens gibt es viele verschiedene Methoden und Theorien, von denen die fünf einflussreichsten Methoden als „Fünf Schulen des maschinellen Lernens“ bezeichnet werden. Die fünf Hauptschulen sind die symbolische Schule, die konnektionistische Schule, die evolutionäre Schule, die Bayes'sche Schule und die Analogieschule. 1. Der Symbolismus, auch Symbolismus genannt, betont die Verwendung von Symbolen zum logischen Denken und zum Ausdruck von Wissen. Diese Denkrichtung glaubt, dass Lernen ein Prozess der umgekehrten Schlussfolgerung durch das Vorhandene ist
 SOTA Performance, eine multimodale KI-Methode zur Vorhersage der Protein-Ligand-Affinität in Xiamen, kombiniert erstmals molekulare Oberflächeninformationen
Jul 17, 2024 pm 06:37 PM
SOTA Performance, eine multimodale KI-Methode zur Vorhersage der Protein-Ligand-Affinität in Xiamen, kombiniert erstmals molekulare Oberflächeninformationen
Jul 17, 2024 pm 06:37 PM
Herausgeber |. KX Im Bereich der Arzneimittelforschung und -entwicklung ist die genaue und effektive Vorhersage der Bindungsaffinität von Proteinen und Liganden für das Arzneimittelscreening und die Arzneimitteloptimierung von entscheidender Bedeutung. Aktuelle Studien berücksichtigen jedoch nicht die wichtige Rolle molekularer Oberflächeninformationen bei Protein-Ligand-Wechselwirkungen. Auf dieser Grundlage schlugen Forscher der Universität Xiamen ein neuartiges Framework zur multimodalen Merkmalsextraktion (MFE) vor, das erstmals Informationen über Proteinoberfläche, 3D-Struktur und -Sequenz kombiniert und einen Kreuzaufmerksamkeitsmechanismus verwendet, um verschiedene Modalitäten zu vergleichen Ausrichtung. Experimentelle Ergebnisse zeigen, dass diese Methode bei der Vorhersage von Protein-Ligand-Bindungsaffinitäten Spitzenleistungen erbringt. Darüber hinaus belegen Ablationsstudien die Wirksamkeit und Notwendigkeit der Proteinoberflächeninformation und der multimodalen Merkmalsausrichtung innerhalb dieses Rahmens. Verwandte Forschungen beginnen mit „S
 GlobalFoundries erschließt Märkte wie KI und erwirbt die Galliumnitrid-Technologie von Tagore Technology und zugehörige Teams
Jul 15, 2024 pm 12:21 PM
GlobalFoundries erschließt Märkte wie KI und erwirbt die Galliumnitrid-Technologie von Tagore Technology und zugehörige Teams
Jul 15, 2024 pm 12:21 PM
Laut Nachrichten dieser Website vom 5. Juli veröffentlichte GlobalFoundries am 1. Juli dieses Jahres eine Pressemitteilung, in der die Übernahme der Power-Galliumnitrid (GaN)-Technologie und des Portfolios an geistigem Eigentum von Tagore Technology angekündigt wurde, in der Hoffnung, seinen Marktanteil in den Bereichen Automobile und Internet auszubauen Anwendungsbereiche für Rechenzentren mit künstlicher Intelligenz, um höhere Effizienz und bessere Leistung zu erforschen. Da sich Technologien wie generative künstliche Intelligenz (GenerativeAI) in der digitalen Welt weiterentwickeln, ist Galliumnitrid (GaN) zu einer Schlüssellösung für nachhaltiges und effizientes Energiemanagement, insbesondere in Rechenzentren, geworden. Auf dieser Website wurde die offizielle Ankündigung zitiert, dass sich das Ingenieurteam von Tagore Technology im Rahmen dieser Übernahme mit GF zusammenschließen wird, um die Galliumnitrid-Technologie weiterzuentwickeln. G
