

Was ist der interne Implementierungsmechanismus der MySQL-Sperre?

Überblick
Obwohl moderne relationale Datenbanken immer ähnlicher werden, können hinter ihrer Implementierung völlig unterschiedliche Mechanismen stecken. Im Hinblick auf die tatsächliche Verwendung ist es für uns aufgrund der vorhandenen SQL-Syntaxspezifikationen nicht schwierig, mit mehreren relationalen Datenbanken vertraut zu sein, aber es kann so viele Sperrimplementierungsmethoden wie Datenbanken geben.
Microsoft Sql Server stellte vor 2005 nur Seitensperren zur Verfügung. Erst in der Version 2005 wurden im optimistischen Modus Sperren auf Zeilenebene unterstützt Sql Server, Sperren sind eine knappe Ressource. Je größer die Anzahl der Sperren, desto größer der Overhead. Um einen klippenartigen Leistungsabfall aufgrund der schnellen Zunahme der Sperren zu vermeiden, wird ein Mechanismus namens Sperre unterstützt Upgrade Sobald die Zeilensperre auf eine Seitensperre aktualisiert wird, kehrt die Parallelitätsleistung zum Ursprung zurück.
Tatsächlich gibt es in derselben Datenbank immer noch viele Streitigkeiten über die Interpretation der Sperrfunktion durch verschiedene Ausführungs-Engines. MyISAM unterstützt nur Sperren auf Tabellenebene, was für gleichzeitiges Lesen in Ordnung ist, bei gleichzeitiger Änderung jedoch bestimmte Einschränkungen aufweist. Innodb ist Oracle sehr ähnlich und bietet nicht sperrende, konsistente Lese- und Zeilensperrunterstützung. Der offensichtliche Unterschied zu SQL Server besteht darin, dass Innodb nur einen geringen Preis zahlen muss, wenn die Gesamtzahl der Sperren steigt.
Zeilensperrenstruktur
Innodb unterstützt Zeilensperren, und es gibt keinen besonders großen Aufwand bei der Beschreibung der Sperren. Daher besteht kein Bedarf für einen Sperraktualisierungsmechanismus als Rettungsmaßnahme, nachdem eine große Anzahl von Sperren zu Leistungseinbußen führt.
Aus der Datei lock0priv.h extrahiert, definiert Innodb Zeilensperren wie folgt:
/** Record lock for a page */
struct lock_rec_t {
/* space id */
ulint space;
/* page number */
ulint page_no;
/**
* number of bits in the lock bitmap;
* NOTE: the lock bitmap is placed immediately after the lock struct
*/
ulint n_bits;
};Obwohl die Parallelitätskontrolle auf Zeilenebene verfeinert werden kann, basiert die Sperrverwaltungsmethode auf Seite Für Einheiten organisiert. Im Design von Innodb kann die einzige Datenseite durch die beiden erforderlichen Bedingungen Space-ID und Seitennummer bestimmt werden. n_bits gibt an, wie viele Bits erforderlich sind, um die Zeilensperrinformationen der Seite zu beschreiben.
Jedem Datensatz auf derselben Datenseite wird eine eindeutige fortlaufend steigende Sequenznummer zugewiesen: heap_no Wenn Sie wissen möchten, ob eine bestimmte Datensatzzeile gesperrt ist, müssen Sie nur feststellen, ob die Nummer an der heap_no Position der Bitmap ist eins. Da die Sperrbitmap Speicherplatz basierend auf der Anzahl der Datensätze auf der Datenseite zuweist, ist sie nicht explizit definiert und die Seitendatensätze können weiter zunehmen, sodass ein Speicherplatz der Größe LOCK_PAGE_BITMAP_MARGIN reserviert wird.
/** * Safety margin when creating a new record lock: this many extra records * can be inserted to the page without need to create a lock with * a bigger bitmap */ #define LOCK_PAGE_BITMAP_MARGIN 64
Angenommen, die Datenseite mit der Leerzeichen-ID = 20 und der Seitennummer = 100 enthält derzeit 160 Datensätze und die Datensätze mit der Heap_Nr. 2, 3 und 4 wurden gesperrt, dann die entsprechende lock_rec_t-Struktur und die Datenseite sollten wie folgt dargestellt werden:
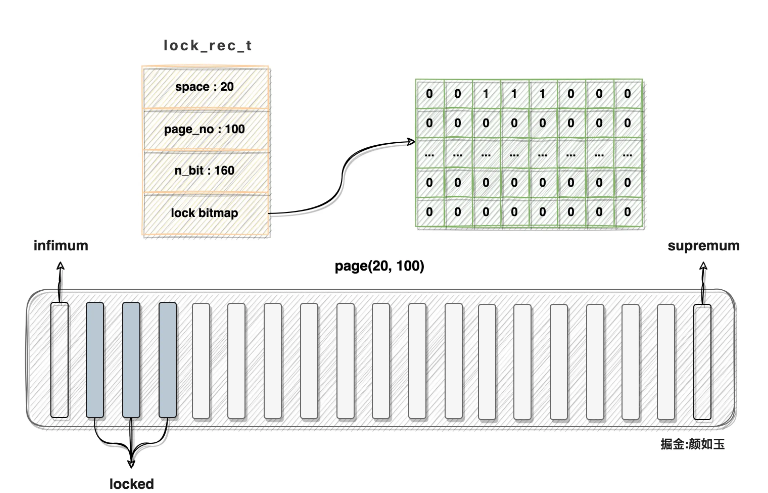
Hinweis:
Die Sperrbitmap in Der Speicher sollte linear verteilt sein. Die im Bild gezeigte zweidimensionale Struktur dient der Vereinfachung der Beschreibung im Bild ist auch zum Zeichnen erforderlich
Sie können sehen, dass die zweite, dritte und vierte Position der Bitmap, die der Seite entspricht, alle auf 1 gesetzt sind. Die Der Speicher, der durch die Zeilensperre zur Beschreibung einer Datenseite verbraucht wird, ist aus Sicht der Wahrnehmung recht begrenzt. Wie viel belegt sie konkret? Wir können berechnen:
160 / 8 + 8 + 1 = 29 Byte.
160 Datensätze entsprechen 160 Bit
+8 liegt daran, dass 64 Bit reserviert werden muss
+1 liegt daran, dass 1 Byte im Quellcode reserviert ist
Um das Problem kleiner Ergebniswerte zu vermeiden , Extra +1 hier hinzugefügt. Dadurch können Fehler vermieden werden, die durch eine Ganzzahldivision verursacht werden. Bei 161 Datensätzen, wenn nicht +1, reichen die berechneten 20 Bytes nicht aus, um die Sperrinformationen aller Datensätze zu beschreiben (ohne Verwendung reservierter Bits).
Aus der Datei lock0priv.h extrahiert:
/* lock_rec_create函数代码片段 */
n_bits = page_dir_get_n_heap(page) + LOCK_PAGE_BITMAP_MARGIN;
n_bytes = 1 + n_bits / 8;
/* 注意这里是分配的连续内存 */
lock = static_cast<lock_t*>(
mem_heap_alloc(trx->lock.lock_heap, sizeof(lock_t) + n_bytes)
);
/**
* Gets the number of records in the heap.
* @return number of user records
*/
UNIV_INLINE ulint page_dir_get_n_heap(const page_t* page)
{
return(page_header_get_field(page, PAGE_N_HEAP) & 0x7fff);
}Tabellensperrstruktur
Innodb unterstützt auch Tabellensperren, die in zwei Kategorien unterteilt werden können: Intention Lock, die Datenstruktur der selbsterhöhenden Sperre ist wie folgt definiert:
Aus der lock0priv.h-Datei extrahiert
struct lock_table_t {
/* database table in dictionary cache */
dict_table_t* table;
/* list of locks on the same table */
UT_LIST_NODE_T(lock_t) locks;
};Auszug aus der ut0lst.h-Datei #🎜 🎜#
struct ut_list_node {
/* pointer to the previous node, NULL if start of list */
TYPE* prev;
/* pointer to next node, NULL if end of list */
TYPE* next;
};
#define UT_LIST_NODE_T(TYPE) ut_list_node<TYPE>/** Lock struct; protected by lock_sys->mutex */
struct lock_t {
/* transaction owning the lock */
trx_t* trx;
/* list of the locks of the transaction */
UT_LIST_NODE_T(lock_t) trx_locks;
/**
* lock type, mode, LOCK_GAP or LOCK_REC_NOT_GAP,
* LOCK_INSERT_INTENTION, wait flag, ORed
*/
ulint type_mode;
/* hash chain node for a record lock */
hash_node_t hash;
/*!< index for a record lock */
dict_index_t* index;
/* lock details */
union {
/* table lock */
lock_table_t tab_lock;
/* record lock */
lock_rec_t rec_lock;
} un_member;
};Nach dem Login kopieren
lock_t wird basierend auf jeder Seite (oder Tabelle) jeder Transaktion definiert, aber a Transaktionen umfassen oft mehrere Seiten. Daher wird die verknüpfte Liste trx_locks benötigt, um alle Sperrinformationen im Zusammenhang mit einer Transaktion zu verketten. Neben der Abfrage aller Sperrinformationen basierend auf Transaktionen erfordert das tatsächliche Szenario auch, dass das System schnell und effizient erkennen kann, ob ein Zeilendatensatz gesperrt wurde. Daher muss eine globale Variable vorhanden sein, um die Abfrage von Sperrinformationen für Zeilendatensätze zu unterstützen. Innodb hat die Hash-Tabelle ausgewählt, die wie folgt definiert ist: Aus der lock0lock.h-Datei extrahiert /** Lock struct; protected by lock_sys->mutex */
struct lock_t {
/* transaction owning the lock */
trx_t* trx;
/* list of the locks of the transaction */
UT_LIST_NODE_T(lock_t) trx_locks;
/**
* lock type, mode, LOCK_GAP or LOCK_REC_NOT_GAP,
* LOCK_INSERT_INTENTION, wait flag, ORed
*/
ulint type_mode;
/* hash chain node for a record lock */
hash_node_t hash;
/*!< index for a record lock */
dict_index_t* index;
/* lock details */
union {
/* table lock */
lock_table_t tab_lock;
/* record lock */
lock_rec_t rec_lock;
} un_member;
};/** The lock system struct */
struct lock_sys_t {
/* Mutex protecting the locks */
ib_mutex_t mutex;
/* 就是这里: hash table of the record locks */
hash_table_t* rec_hash;
/* Mutex protecting the next two fields */
ib_mutex_t wait_mutex;
/**
* Array of user threads suspended while waiting forlocks within InnoDB,
* protected by the lock_sys->wait_mutex
*/
srv_slot_t* waiting_threads;
/*
* highest slot ever used in the waiting_threads array,
* protected by lock_sys->wait_mutex
*/
srv_slot_t* last_slot;
/**
* TRUE if rollback of all recovered transactions is complete.
* Protected by lock_sys->mutex
*/
ibool rollback_complete;
/* Max wait time */
ulint n_lock_max_wait_time;
/**
* Set to the event that is created in the lock wait monitor thread.
* A value of 0 means the thread is not active
*/
os_event_t timeout_event;
/* True if the timeout thread is running */
bool timeout_thread_active;
};/**
* Calculates the fold value of a page file address: used in inserting or
* searching for a lock in the hash table.
*
* @return folded value
*/
UNIV_INLINE ulint lock_rec_fold(ulint space, ulint page_no)
{
return(ut_fold_ulint_pair(space, page_no));
}
/**
* Folds a pair of ulints.
*
* @return folded value
*/
UNIV_INLINE ulint ut_fold_ulint_pair(ulint n1, ulint n2)
{
return (
(
(((n1 ^ n2 ^ UT_HASH_RANDOM_MASK2) << 8) + n1)
^ UT_HASH_RANDOM_MASK
)
+ n2
);
}这里返回的其实是lock_t对象,摘自lock0lock.cc文件
/**
* Gets the first explicit lock request on a record.
*
* @param block : block containing the record
* @param heap_no : heap number of the record
*
* @return first lock, NULL if none exists
*/
UNIV_INLINE lock_t* lock_rec_get_first(const buf_block_t* block, ulint heap_no)
{
lock_t* lock;
ut_ad(lock_mutex_own());
for (lock = lock_rec_get_first_on_page(block); lock;
lock = lock_rec_get_next_on_page(lock)
) {
if (lock_rec_get_nth_bit(lock, heap_no)) {
break;
}
}
return(lock);
}以页面为粒度进行锁维护并非最直接有效的方式,它明显是时间换空间,不过这种设计使得锁开销很小。某一事务对任一行上锁的开销都是一样的,锁数量的上升也不会带来额外的内存消耗。
对应每个事务的内存对象trx_t中,包含了该事务的锁信息链表和等待的锁信息。因此存在如下两种途径对锁进行查询:
根据事务: 通过trx_t对象的trx_locks链表,再通过lock_t对象中的trx_locks遍历可得某事务持有、等待的所有锁信息。
根据记录: 根据记录所在的页,通过space id、page number在lock_sys_t结构中定位到lock_t对象,扫描bitmap找到heap_no对应的bit位。
上述各种数据结构,对其整理关系如下图所示:
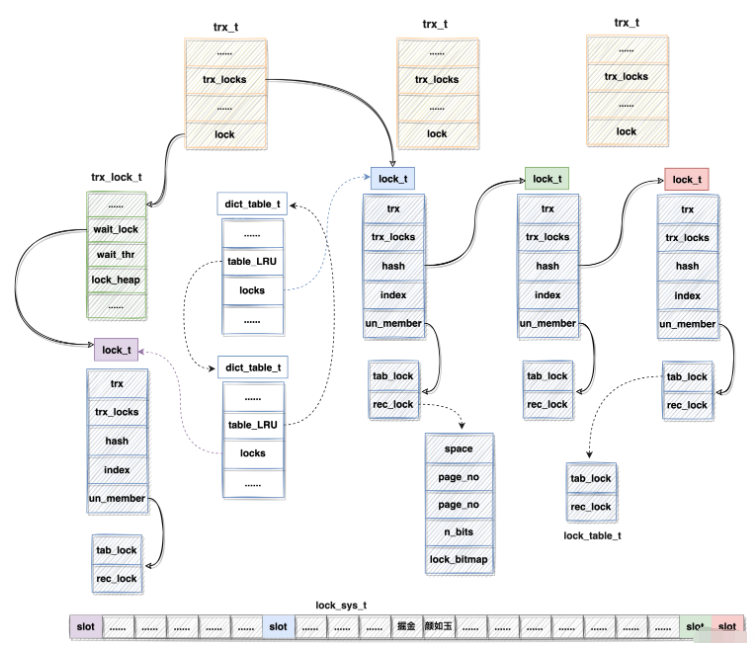
注:
lock_sys_t中的slot颜色与lock_t颜色相同则表明lock_sys_t slot持有lock_t 指针信息,实在是没法连线,不然图很混乱
Das obige ist der detaillierte Inhalt vonWas ist der interne Implementierungsmechanismus der MySQL-Sperre?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1392
1392
 52
52

 Wie man phpmyadmin öffnet
Apr 10, 2025 pm 10:51 PM
Wie man phpmyadmin öffnet
Apr 10, 2025 pm 10:51 PM
Sie können PhpMyAdmin in den folgenden Schritten öffnen: 1. Melden Sie sich beim Website -Bedienfeld an; 2. Finden und klicken Sie auf das Symbol phpmyadmin. 3. Geben Sie MySQL -Anmeldeinformationen ein; 4. Klicken Sie auf "Login".
 MySQL: Eine Einführung in die beliebteste Datenbank der Welt
Apr 12, 2025 am 12:18 AM
MySQL: Eine Einführung in die beliebteste Datenbank der Welt
Apr 12, 2025 am 12:18 AM
MySQL ist ein Open Source Relational Database Management -System, das hauptsächlich zum schnellen und zuverlässigen Speicher und Abrufen von Daten verwendet wird. Sein Arbeitsprinzip umfasst Kundenanfragen, Abfragebedingungen, Ausführung von Abfragen und Rückgabergebnissen. Beispiele für die Nutzung sind das Erstellen von Tabellen, das Einsetzen und Abfragen von Daten sowie erweiterte Funktionen wie Join -Operationen. Häufige Fehler umfassen SQL -Syntax, Datentypen und Berechtigungen sowie Optimierungsvorschläge umfassen die Verwendung von Indizes, optimierte Abfragen und die Partitionierung von Tabellen.
 So verwenden Sie ein einzelnes Gewinde -Redis
Apr 10, 2025 pm 07:12 PM
So verwenden Sie ein einzelnes Gewinde -Redis
Apr 10, 2025 pm 07:12 PM
Redis verwendet eine einzelne Gewindearchitektur, um hohe Leistung, Einfachheit und Konsistenz zu bieten. Es wird E/A-Multiplexing, Ereignisschleifen, nicht blockierende E/A und gemeinsame Speicher verwendet, um die Parallelität zu verbessern, jedoch mit Einschränkungen von Gleichzeitbeschränkungen, einem einzelnen Ausfallpunkt und ungeeigneter Schreib-intensiver Workloads.
 Mysqls Platz: Datenbanken und Programmierung
Apr 13, 2025 am 12:18 AM
Mysqls Platz: Datenbanken und Programmierung
Apr 13, 2025 am 12:18 AM
Die Position von MySQL in Datenbanken und Programmierung ist sehr wichtig. Es handelt sich um ein Open -Source -Verwaltungssystem für relationale Datenbankverwaltung, das in verschiedenen Anwendungsszenarien häufig verwendet wird. 1) MySQL bietet effiziente Datenspeicher-, Organisations- und Abruffunktionen und unterstützt Systeme für Web-, Mobil- und Unternehmensebene. 2) Es verwendet eine Client-Server-Architektur, unterstützt mehrere Speichermotoren und Indexoptimierung. 3) Zu den grundlegenden Verwendungen gehören das Erstellen von Tabellen und das Einfügen von Daten, und erweiterte Verwendungen beinhalten Multi-Table-Verknüpfungen und komplexe Abfragen. 4) Häufig gestellte Fragen wie SQL -Syntaxfehler und Leistungsprobleme können durch den Befehl erklären und langsam abfragen. 5) Die Leistungsoptimierungsmethoden umfassen die rationale Verwendung von Indizes, eine optimierte Abfrage und die Verwendung von Caches. Zu den Best Practices gehört die Verwendung von Transaktionen und vorbereiteten Staten
 Warum MySQL verwenden? Vorteile und Vorteile
Apr 12, 2025 am 12:17 AM
Warum MySQL verwenden? Vorteile und Vorteile
Apr 12, 2025 am 12:17 AM
MySQL wird für seine Leistung, Zuverlässigkeit, Benutzerfreundlichkeit und Unterstützung der Gemeinschaft ausgewählt. 1.MYSQL bietet effiziente Datenspeicher- und Abruffunktionen, die mehrere Datentypen und erweiterte Abfragevorgänge unterstützen. 2. Übernehmen Sie die Architektur der Client-Server und mehrere Speichermotoren, um die Transaktion und die Abfrageoptimierung zu unterstützen. 3. Einfach zu bedienend unterstützt eine Vielzahl von Betriebssystemen und Programmiersprachen. V.
 So stellen Sie eine Verbindung zur Datenbank von Apache her
Apr 13, 2025 pm 01:03 PM
So stellen Sie eine Verbindung zur Datenbank von Apache her
Apr 13, 2025 pm 01:03 PM
Apache verbindet eine Verbindung zu einer Datenbank erfordert die folgenden Schritte: Installieren Sie den Datenbanktreiber. Konfigurieren Sie die Datei web.xml, um einen Verbindungspool zu erstellen. Erstellen Sie eine JDBC -Datenquelle und geben Sie die Verbindungseinstellungen an. Verwenden Sie die JDBC -API, um über den Java -Code auf die Datenbank zuzugreifen, einschließlich Verbindungen, Erstellen von Anweisungen, Bindungsparametern, Ausführung von Abfragen oder Aktualisierungen und Verarbeitungsergebnissen.
 Überwachen Sie Redis Tröpfchen mit Redis Exporteur Service
Apr 10, 2025 pm 01:36 PM
Überwachen Sie Redis Tröpfchen mit Redis Exporteur Service
Apr 10, 2025 pm 01:36 PM
Eine effektive Überwachung von Redis -Datenbanken ist entscheidend für die Aufrechterhaltung einer optimalen Leistung, die Identifizierung potenzieller Engpässe und die Gewährleistung der Zuverlässigkeit des Gesamtsystems. Redis Exporteur Service ist ein leistungsstarkes Dienstprogramm zur Überwachung von Redis -Datenbanken mithilfe von Prometheus. In diesem Tutorial führt Sie die vollständige Setup und Konfiguration des Redis -Exporteur -Dienstes, um sicherzustellen, dass Sie nahtlos Überwachungslösungen erstellen. Durch das Studium dieses Tutorials erhalten Sie voll funktionsfähige Überwachungseinstellungen
 So starten Sie MySQL von Docker
Apr 15, 2025 pm 12:09 PM
So starten Sie MySQL von Docker
Apr 15, 2025 pm 12:09 PM
Der Prozess des Startens von MySQL in Docker besteht aus den folgenden Schritten: Ziehen Sie das MySQL -Image zum Erstellen und Starten des Containers an, setzen
