

So beheben Sie den Redis-Pufferüberlauf

Puffer ist ein Teil des Speicherplatzes. Mit anderen Worten: Im Speicher ist eine bestimmte Menge Speicherplatz reserviert. Diese Speicherplätze werden zum Puffern von Eingabe- oder Ausgabedaten verwendet. Dieser reservierte Speicherplatz wird als Puffer bezeichnet.
1. Auswirkungen des Redis-Pufferüberlaufs
In Redis gibt es drei Hauptszenarien, in denen das Konzept des Puffers verwendet wird.
Bei der Kommunikation zwischen dem Client und dem Server werden die vom Client gesendeten Befehlsdaten oder die vom Server an den Client zurückgegebenen Datenergebnisse vorübergehend gespeichert. Bei der Datensynchronisierung zwischen Master- und Slave-Knoten verwendet Redis Puffer Um die vom Masterknoten empfangenen Schreibbefehle und Daten vorübergehend zu speichern, verwendet Redis bei der AOF-Persistenz auch das Konzept von Puffern, um häufige Schreibvorgänge auf der Festplatte zu vermeiden
Das Pufferkonzept wurde ursprünglich vom Betriebssystem verwendet, um die Inkonsistenz zwischen zu verringern CPU- und E/A-Gerätegeschwindigkeiten werden angepasst, um die Parallelität von CPUs und E/A-Geräten zu verbessern.
Die Diskrepanz zwischen Hochgeschwindigkeitsgeräten und Geräten mit niedriger Geschwindigkeit führt unweigerlich dazu, dass Hochgeschwindigkeitsgeräte Zeit damit verbringen, auf Geräte mit niedriger Geschwindigkeit zu warten. Das Konzept des Puffers kann dieses Problem sehr gut lösen. Der Puffer ist auch eine wichtige Verkörperung des Producer-Consumer-Modells.
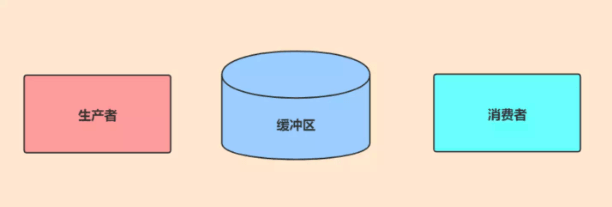
1. Ein Pufferüberlauf führt dazu, dass die Netzwerkverbindung geschlossen wird. Wenn qubf-free erschöpft ist, führt dies zu einem Überlauf des Client-Eingabepuffers. Das Ergebnis ist ein Geschäftsprogramm Zugriff auf Daten nicht möglich.
2. Pufferüberlauf führt zu Befehlsdatenverlust oder -absturz.
Normalerweise gibt es viele Client-Verbindungen, die die maximale Speicherkonfiguration von Redis überschreiten. Die Datenveralterung wirkt sich auf den Zugriff aus Durchführung von Geschäftsprogrammen.
Selbst mehrere Clients führen dazu, dass Redis zu viel Speicher beansprucht, und es kann auch zu Speicherüberlaufproblemen kommen, die zum Absturz von Redis führen können.
2. Client-Puffer
Es gibt zwei weitere Client-Puffer, den Eingabepuffer und den Ausgabepuffer, die beide eingerichtet sind, um die Diskrepanz bei der Anforderungssende- und Verarbeitungsgeschwindigkeit zwischen dem Client und dem Server zu beheben.
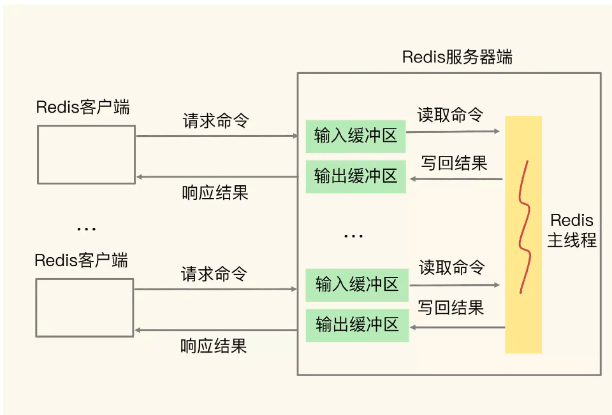 Der Eingabepuffer speichert vorübergehend vom Client gesendete Befehle. Es gibt zwei häufige Gründe für einen Überlauf:
Der Eingabepuffer speichert vorübergehend vom Client gesendete Befehle. Es gibt zwei häufige Gründe für einen Überlauf:
Das Schreiben von BigKey, z. B. das gleichzeitige Schreiben von Millionen von Hashes oder das Festlegen von Daten, überschreitet die Größe des Puffers, des Servers Verarbeitet die Anfrage zu langsam, was zu Blockaden führt und die Anfrage nicht rechtzeitig verarbeiten kann, wodurch sich immer mehr vom Client gesendete Anfragen im Puffer ansammeln.
Der Ausgabepuffer speichert vorübergehend die Daten, die vom Redis-Hauptthread an den Client zurückgegeben werden sollen.
Zu diesen Daten gehören einfache und feste OK-Antworten (z. B. die Ausführung des SET-Befehls) oder Fehlermeldungen sowie Ausführungsergebnisse mit variabler Größe und spezifischen Daten (z. B. die Ausführung des HGET-Befehls)
Gemeinsame Ausgabe Puffer Es gibt drei Gründe für einen Überlauf:
Eine große Anzahl von BigKey-Ergebnissen zurückgeben. Einige unangemessene Befehle ausführen. Unangemessene Puffergrößeneinstellung.
Gemessen an den häufigen Ursachen für einen Überlauf in Eingabe- und Ausgabepuffern ist BigKey die wahrscheinlichste Ursache für einen Überlauf Daher sollten wir versuchen, die Verwendung von BigKey zu vermeiden.
Da es für den Eingabepuffer keine Möglichkeit gibt, seine Größe zu ändern (Standard 1G pro Client), können wir nur die Sende- und Verarbeitungsgeschwindigkeit von Befehlen steuern, um Blockierungen so weit wie möglich zu vermeiden.
Vermeiden Sie für den Ausgabepuffer die Verwendung einiger Befehle, die eine große Anzahl von Ergebnissen zurückgeben, wie z. B. KEYS, MONITOR usw. Gleichzeitig können Sie einen Überlauf vermeiden, indem Sie die Größe des Ausgabepuffers anpassen.
3. Kopierpuffer
Der Kopierpuffer wird zum Kopieren zwischen Redis-Master- und Slave-Knoten verwendet. Denn die Datenreplikation zwischen Master- und Slave-Knoten umfasst die vollständige Replikation und die inkrementelle Replikation. Daher ist der Kopierpuffer auch in zwei Typen unterteilt: Kopierpuffer und Kopierrückstandspuffer.
1. Puffer kopieren
Während des vollständigen Replikationsprozesses empfängt der Master-Knoten weiterhin vom Client gesendete Schreibbefehlsanfragen, während er RDB-Dateien an den Slave-Knoten überträgt. Diese Schreibbefehle werden zunächst im Replikationspuffer gespeichert und nach Abschluss der RDB-Dateiübertragung an den Slave-Knoten gesendet und ausgeführt. Um die Datensynchronisation zwischen Master- und Slave-Knoten sicherzustellen, unterhält jeder Slave-Knoten einen Replikationspuffer auf dem Master-Knoten.
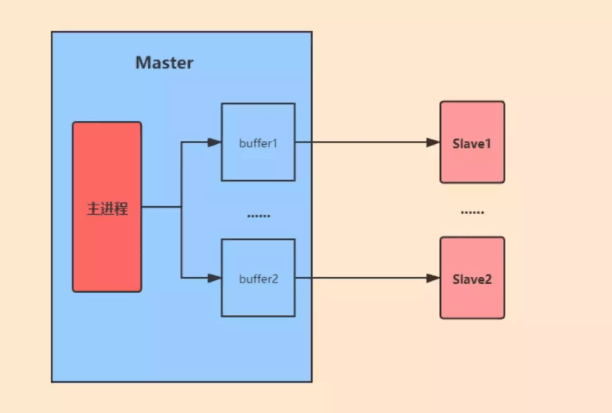 Wenn es für den Kopierpuffer lange dauert, bis die Hauptbibliothek RDB-Dateien überträgt und RDB-Dateien von der Slave-Bibliothek lädt, und gleichzeitig die Hauptbibliothek viele Schreibbefehlsvorgänge empfängt, Dies führt dazu, dass der Kopierpuffer voll wird und überläuft.
Wenn es für den Kopierpuffer lange dauert, bis die Hauptbibliothek RDB-Dateien überträgt und RDB-Dateien von der Slave-Bibliothek lädt, und gleichzeitig die Hauptbibliothek viele Schreibbefehlsvorgänge empfängt, Dies führt dazu, dass der Kopierpuffer voll wird und überläuft.
Um einen Überlauf des Replikationspuffers zu vermeiden, können wir einerseits die vom Masterknoten gespeicherte Datenmenge steuern, was die Übertragung von RDB-Dateien und die Ladezeit von Slave-Bibliotheken beschleunigen kann, um die Ansammlung zu vieler Befehle zu vermeiden im Replikationspuffer.
Sie können die Größe des Replikationspuffers auch angemessener festlegen, um einen Überlauf zu vermeiden, basierend auf dem Datenvolumen des Masterknotens, dem Schreiblastdruck des Masterknotens und der Speichergröße des Masterknotens selbst, um einen Überlauf zu vermeiden. Da der Master-Knoten außerdem einen Replikationspuffer auf dem Slave-Knoten einrichtet, ist der Speicheraufwand des Master-Knotens sehr groß. Daher sollten wir versuchen, einen Master-Knoten zu vermeiden zu viele Slave-Knoten haben.
2. Replikations-Backlog-Puffer
Während des inkrementellen Replikationsprozesses werden Schreibbefehle vorübergehend im Replikationspuffer gespeichert, wenn der Master-Knoten eine regelmäßige Synchronisierung mit dem Slave-Knoten durchführt. Wenn eine Netzwerkunterbrechung zwischen dem Slave-Knoten und dem Master-Knoten auftritt, können Befehlsoperationen, die noch nicht repliziert wurden, aus dem Replikations-Backlog-Puffer synchronisiert werden, nachdem der Slave-Knoten erneut verbunden wurde.
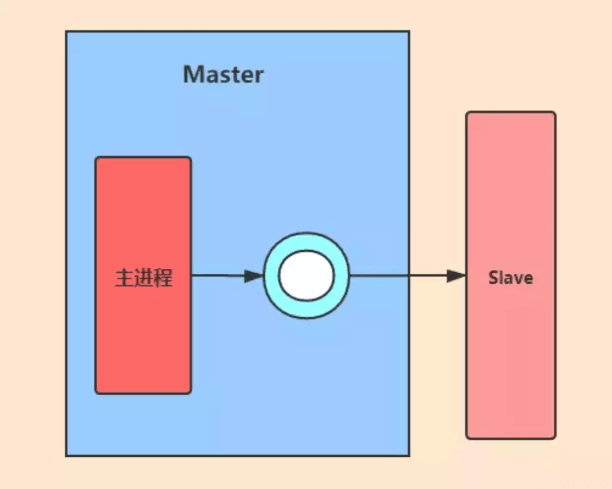
Es ist zu beachten, dass der Kopierrückstandspuffer ein Ringpuffer mit begrenzter Größe ist.
Wenn der Masterknoten den Replikations-Backlog-Puffer füllt, überschreibt er die alten Befehlsdaten im Puffer. Zu diesem Zeitpunkt sind die Daten der Master- und Slave-Knoten inkonsistent.
Als Reaktion auf dieses Problem besteht die allgemeine Möglichkeit, dieses Problem zu lösen, darin, die Größe des Kopierrückstandspuffers zu erhöhen. Die Berechnungsmethode dieser Größe kann im Allgemeinen verwendet werden
缓冲区大小=(主库写入命令速度 * 操作大小 - 主从库间网络传输命令速度 * 操作大小)* 2
Der Überlauf des AOF-Puffers hängt möglicherweise mit der Schreibgeschwindigkeit der Festplatte oder der AOF-Writeback-Strategie zusammen AOF Wenn der Puffer seinen festgelegten Schwellenwert überschreitet, kommt es zu einem Pufferüberlauf. Um dieses Problem zu vermeiden, können wir es lösen, indem wir die Rückschreibstrategie oder die AOF-Puffergröße anpassen.
2. AOF-Rewrite-Puffer 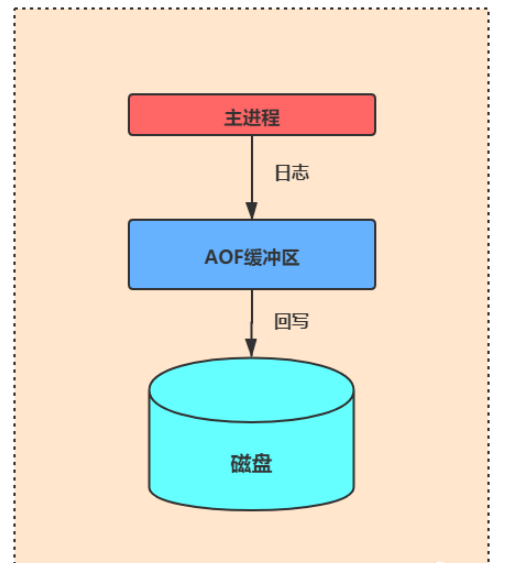
Der Überlauf des AOF-Rewrite-Puffers hängt mit der Anzahl der Befehle zusammen, die vom Hauptprozess während des AOF-Rewrites verarbeitet werden AOF-Umschreibung Eine große Anzahl von Befehlen wird verarbeitet und diese Befehle werden in den AOF-Umschreibungspuffer geschrieben. Wenn der festgelegte Schwellenwert überschritten wird, kommt es zu einem Überlauf.
Um den Überlauf des AOF-Rewrite-Puffers zu vermeiden, können wir ihn auch lösen, indem wir die Größe des AOF-Rewrite-Puffers anpassen. 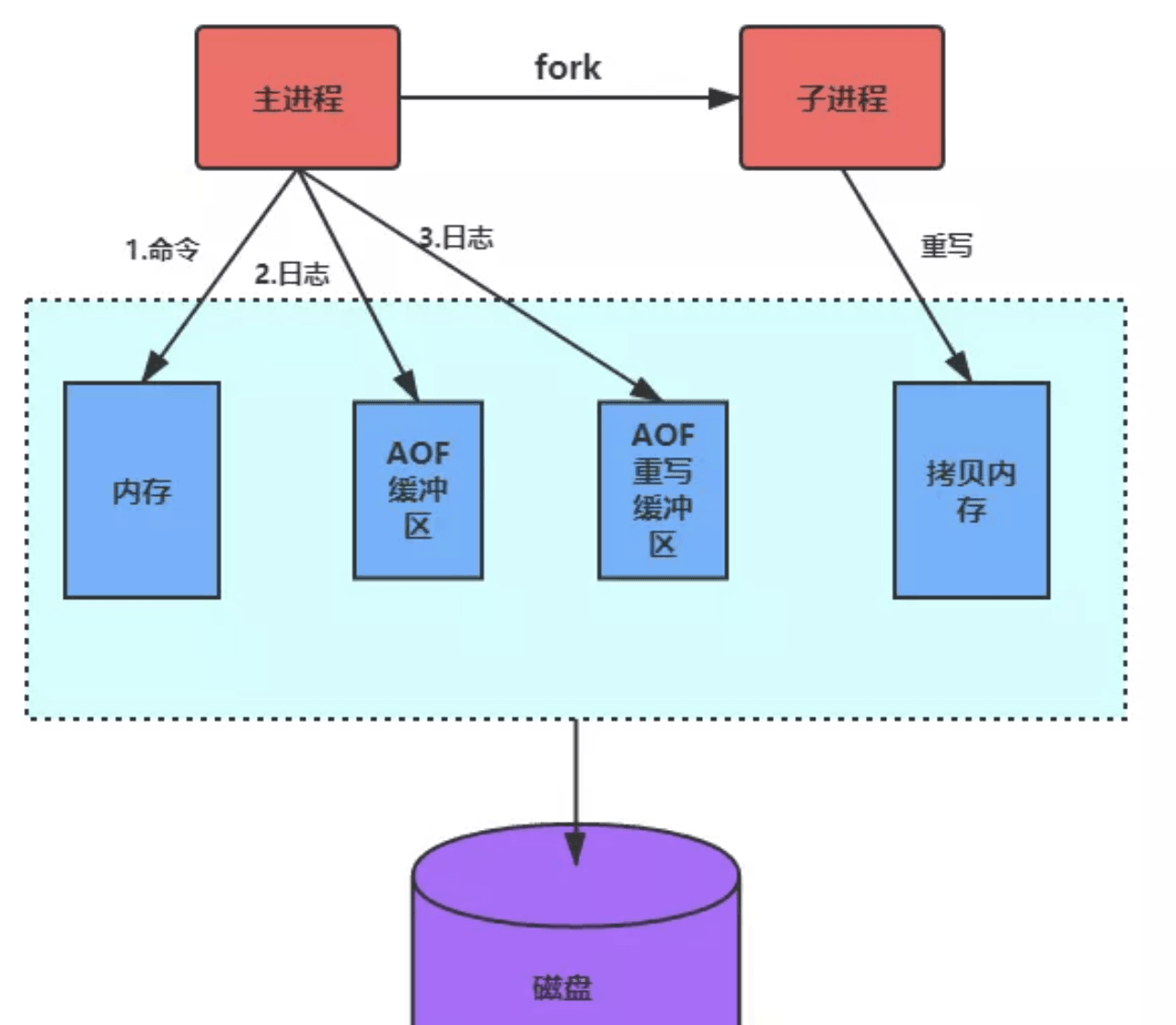
Das obige ist der detaillierte Inhalt vonSo beheben Sie den Redis-Pufferüberlauf. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1392
1392
 52
52

 So erstellen Sie den Redis -Clustermodus
Apr 10, 2025 pm 10:15 PM
So erstellen Sie den Redis -Clustermodus
Apr 10, 2025 pm 10:15 PM
Der Redis -Cluster -Modus bietet Redis -Instanzen durch Sharding, die Skalierbarkeit und Verfügbarkeit verbessert. Die Bauschritte sind wie folgt: Erstellen Sie ungerade Redis -Instanzen mit verschiedenen Ports; Erstellen Sie 3 Sentinel -Instanzen, Monitor -Redis -Instanzen und Failover; Konfigurieren von Sentinel -Konfigurationsdateien, Informationen zur Überwachung von Redis -Instanzinformationen und Failover -Einstellungen hinzufügen. Konfigurieren von Redis -Instanzkonfigurationsdateien, aktivieren Sie den Cluster -Modus und geben Sie den Cluster -Informationsdateipfad an. Erstellen Sie die Datei nodes.conf, die Informationen zu jeder Redis -Instanz enthält. Starten Sie den Cluster, führen Sie den Befehl erstellen aus, um einen Cluster zu erstellen und die Anzahl der Replikate anzugeben. Melden Sie sich im Cluster an, um den Befehl cluster info auszuführen, um den Clusterstatus zu überprüfen. machen
 So löschen Sie Redis -Daten
Apr 10, 2025 pm 10:06 PM
So löschen Sie Redis -Daten
Apr 10, 2025 pm 10:06 PM
So löschen Sie Redis -Daten: Verwenden Sie den Befehl Flushall, um alle Schlüsselwerte zu löschen. Verwenden Sie den Befehl flushdb, um den Schlüsselwert der aktuell ausgewählten Datenbank zu löschen. Verwenden Sie SELECT, um Datenbanken zu wechseln, und löschen Sie dann FlushDB, um mehrere Datenbanken zu löschen. Verwenden Sie den Befehl del, um einen bestimmten Schlüssel zu löschen. Verwenden Sie das Redis-Cli-Tool, um die Daten zu löschen.
 So lesen Sie Redis -Warteschlange
Apr 10, 2025 pm 10:12 PM
So lesen Sie Redis -Warteschlange
Apr 10, 2025 pm 10:12 PM
Um eine Warteschlange aus Redis zu lesen, müssen Sie den Warteschlangenname erhalten, die Elemente mit dem Befehl LPOP lesen und die leere Warteschlange verarbeiten. Die spezifischen Schritte sind wie folgt: Holen Sie sich den Warteschlangenname: Nennen Sie ihn mit dem Präfix von "Warteschlange:" wie "Warteschlangen: My-Queue". Verwenden Sie den Befehl LPOP: Wischen Sie das Element aus dem Kopf der Warteschlange aus und geben Sie seinen Wert zurück, z. B. die LPOP-Warteschlange: my-queue. Verarbeitung leerer Warteschlangen: Wenn die Warteschlange leer ist, gibt LPOP NIL zurück, und Sie können überprüfen, ob die Warteschlange existiert, bevor Sie das Element lesen.
 So verwenden Sie den Befehl Redis
Apr 10, 2025 pm 08:45 PM
So verwenden Sie den Befehl Redis
Apr 10, 2025 pm 08:45 PM
Die Verwendung der REDIS -Anweisung erfordert die folgenden Schritte: Öffnen Sie den Redis -Client. Geben Sie den Befehl ein (Verbschlüsselwert). Bietet die erforderlichen Parameter (variiert von der Anweisung bis zur Anweisung). Drücken Sie die Eingabetaste, um den Befehl auszuführen. Redis gibt eine Antwort zurück, die das Ergebnis der Operation anzeigt (normalerweise in Ordnung oder -err).
 So verwenden Sie Redis Lock
Apr 10, 2025 pm 08:39 PM
So verwenden Sie Redis Lock
Apr 10, 2025 pm 08:39 PM
Um die Operationen zu sperren, muss die Sperre durch den Befehl setNX erfasst werden und dann den Befehl Ablauf verwenden, um die Ablaufzeit festzulegen. Die spezifischen Schritte sind: (1) Verwenden Sie den Befehl setNX, um zu versuchen, ein Schlüsselwertpaar festzulegen; (2) Verwenden Sie den Befehl Ablauf, um die Ablaufzeit für die Sperre festzulegen. (3) Verwenden Sie den Befehl Del, um die Sperre zu löschen, wenn die Sperre nicht mehr benötigt wird.
 So lesen Sie den Quellcode von Redis
Apr 10, 2025 pm 08:27 PM
So lesen Sie den Quellcode von Redis
Apr 10, 2025 pm 08:27 PM
Der beste Weg, um Redis -Quellcode zu verstehen, besteht darin, Schritt für Schritt zu gehen: Machen Sie sich mit den Grundlagen von Redis vertraut. Wählen Sie ein bestimmtes Modul oder eine bestimmte Funktion als Ausgangspunkt. Beginnen Sie mit dem Einstiegspunkt des Moduls oder der Funktion und sehen Sie sich die Codezeile nach Zeile an. Zeigen Sie den Code über die Funktionsaufrufkette an. Kennen Sie die von Redis verwendeten Datenstrukturen. Identifizieren Sie den von Redis verwendeten Algorithmus.
 So verwenden Sie die Befehlszeile der Redis
Apr 10, 2025 pm 10:18 PM
So verwenden Sie die Befehlszeile der Redis
Apr 10, 2025 pm 10:18 PM
Verwenden Sie das Redis-Befehlszeilen-Tool (REDIS-CLI), um Redis in folgenden Schritten zu verwalten und zu betreiben: Stellen Sie die Adresse und den Port an, um die Adresse und den Port zu stellen. Senden Sie Befehle mit dem Befehlsnamen und den Parametern an den Server. Verwenden Sie den Befehl Hilfe, um Hilfeinformationen für einen bestimmten Befehl anzuzeigen. Verwenden Sie den Befehl zum Beenden, um das Befehlszeilenwerkzeug zu beenden.
 So lösen Sie Datenverlust mit Redis
Apr 10, 2025 pm 08:24 PM
So lösen Sie Datenverlust mit Redis
Apr 10, 2025 pm 08:24 PM
Zu den Ursachen für Datenverluste gehören Speicherausfälle, Stromausfälle, menschliche Fehler und Hardwarefehler. Die Lösungen sind: 1. Speichern Sie Daten auf Festplatten mit RDB oder AOF Persistenz; 2. Kopieren Sie auf mehrere Server, um eine hohe Verfügbarkeit zu erhalten. 3. Ha mit Redis Sentinel oder Redis Cluster; 4. Erstellen Sie Schnappschüsse, um Daten zu sichern. 5. Implementieren Sie Best Practices wie Persistenz, Replikation, Schnappschüsse, Überwachung und Sicherheitsmaßnahmen.
