

Der vorherige Artikel hat Ihnen einige grundlegende Kenntnisse über LangChain vermittelt. Freunde, die es noch nicht gesehen haben, können hier einen Blick darauf werfen. Heute stellen wir Ihnen das erste sehr wichtige Komponentenmodell von LangChain vor: Model.
Beachten Sie, dass sich das hier erwähnte Modell auf die Modellkomponente von LangChain bezieht, nicht auf das Sprachmodell ähnlich wie OpenAI. Der Grund, warum LangChain über Modellkomponenten verfügt, liegt darin, dass es in der Branche zu viele Sprachmodelle gibt, mit Ausnahme des Sprachmodells von Unternehmen OpenAI Darüber hinaus gibt es viele andere Orte.
LangChain verfügt über drei Arten von Modellkomponenten, nämlich LLM Large Language Model, Chat Model und Text Embedding Models.
LLM ist die grundlegendste Modellkomponente. Sowohl die Eingabe als auch die Ausgabe unterstützen nur Zeichenfolgen, die unsere Anforderungen in den meisten Szenarien erfüllen können. Wir können Python-Code direkt auf Colab schreiben ([https://colab.research.google.com)
Das Folgende ist ein Fall: Installieren Sie zuerst die Abhängigkeiten und führen Sie dann den folgenden Code aus.
pip install openaipip install langchain
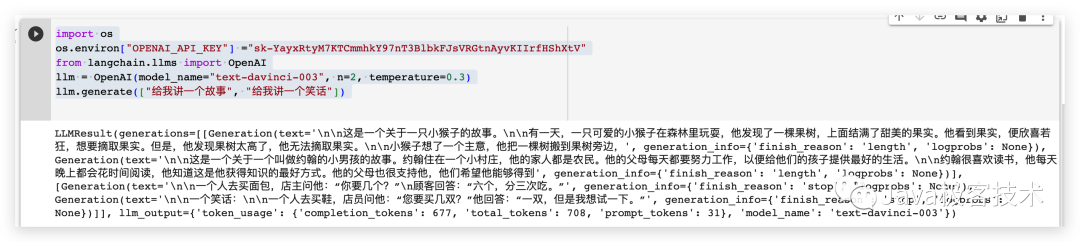
import os# 配置OpenAI 的 API KEYos.environ["OPENAI_API_KEY"] ="sk-xxx"# 从 LangChain 中导入 OpenAI 的模型from langchain.llms import OpenAI# 三个参数分别代表OpenAI 的模型名称,执行的次数和随机性,数值越大越发散llm = OpenAI(model_name="text-davinci-003", n=2, temperature=0.3)llm.generate(["给我讲一个故事", "给我讲一个笑话"])
Die Ergebnisse der Operation sind wie folgt
Chat-Modell basiert auf dem LLM-Modell, aber das Chat-Modell ist strukturierter als die Eingabe und Ausgabe zwischen dem LLM-Modell Komponenten und die Eingabe- und Ausgabeparameter sind alle Typen Chat-Modell, keine einfachen Zeichenfolgen. Zu den häufig verwendeten Chat-Modelltypen gehören die folgenden
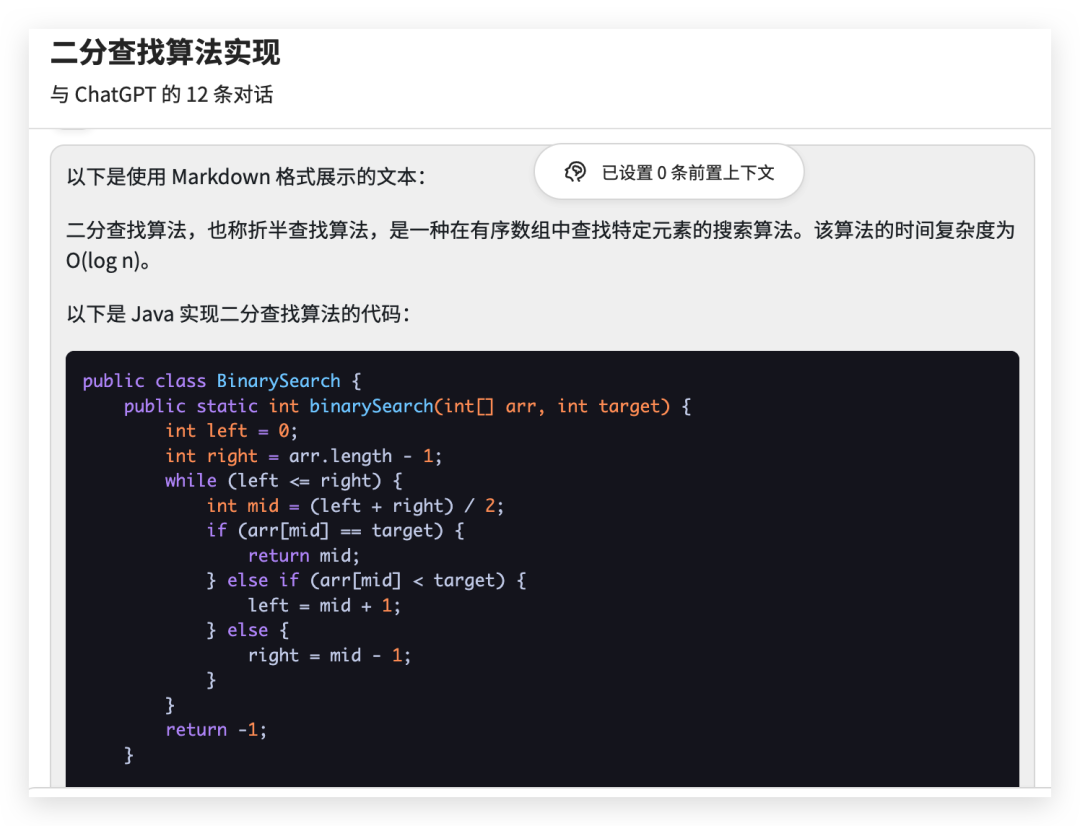
from langchain.chat_models import ChatOpenAIfrom langchain.schema import (AIMessage,HumanMessage,SystemMessage)chat = ChatOpenAI(temperature=0)messages = [SystemMessage(cnotallow="返回的数据markdown 语法进行展示,代码使用代码块包裹"),HumanMessage(cnotallow="用 Java 实现一个二分查找算法")]print(chat(messages))
Die Form der generierten Inhaltszeichenfolge lautet wie folgt:
Der binäre Suchalgorithmus ist ein Suchalgorithmus, der verwendet wird, um bestimmte Elemente in einem geordneten Array zu finden, der auch als binärer Suchalgorithmus bezeichnet wird. Die zeitliche Komplexität dieses Algorithmus beträgt O(log n). nnDas Folgende ist der Code zum Implementieren des binären Suchalgorithmus in Java: nnjavanpublic class BinarySearch {n public static int BinarySearch(int[] arr, int target) {n int left = 0;n int right = arr.length - 1;n while (left <= right) {n int mid = (left + right) / 2;n if (arr[mid] == target) {n return mid;n } else if (arr[mid] < target) {n left = mid + 1;n } else {n right = mid - 1;n }n }n return -1;n }nn public static void main(String[] args) {n int[] arr = {1 , 3, 5, 7, 9};n int target = 5;n int index = BinarySearch(arr, target);n if (index != -1) {n System.out.println("target element" + target + " in Der Index im Array ist " + index n } else {n System.out.println("target element" + target + " is not in the array"); Im obigen Code empfängt die Methode „binarySearch“ ein sortiertes Array und ein Zielelement und gibt den Index des Zielelements im Array zurück oder -1, wenn sich das Zielelement nicht im Array befindet. nnIn der Methode „binarySearch“ verwenden Sie zwei Zeiger links und rechts, um auf das linke bzw. rechte Ende des Arrays zu zeigen, und grenzen dann den Suchbereich in einer While-Schleife kontinuierlich ein, bis das Zielelement gefunden wird oder der Suchbereich leer ist. In jeder Schleife wird die mittlere Position berechnet und dann das Zielelement mit dem Element in der mittleren Position verglichen. Wenn sie gleich sind, wird der Index der mittleren Position zurückgegeben In der mittleren Position wird der linke Zeiger nach rechts von der mittleren Position bewegt. Wenn das Zielelement kleiner als das mittlere Positionselement ist, bewegen Sie den rechten Zeiger nach links von der mittleren Position. ' Additional_kwargs={} example=False
Extrahieren Sie den Inhalt und zeigen Sie ihn mit einer Markdown-Syntax wie dieser an
Mit dieser Modellkomponente können Sie einige Rollen voreinstellen und diese dann anpassen.
from langchain.chat_models import ChatOpenAIfrom langchain.prompts import (ChatPromptTemplate,PromptTemplate,SystemMessagePromptTemplate,AIMessagePromptTemplate,HumanMessagePromptTemplate,)from langchain.schema import (AIMessage,HumanMessage,SystemMessage)system_template="你是一个把{input_language}翻译成{output_language}的助手"system_message_prompt = SystemMessagePromptTemplate.from_template(system_template)human_template="{text}"human_message_prompt = HumanMessagePromptTemplate.from_template(human_template)chat_prompt = ChatPromptTemplate.from_messages([system_message_prompt, human_message_prompt])messages = chat_prompt.format_prompt(input_language="英语", output_language="汉语", text="I love programming.")print(messages)chat = ChatOpenAI(temperature=0)print(chat(messages.to_messages()))Ausgabe
messages=[SystemMessage(cnotallow='Sie sind ein Assistent, der Englisch ins Chinesische übersetzt', Additional_kwargs={}), HumanMessage(cnotallow='Ich liebe Programmieren.', Additional_kwargs = {}, example=False)] cnotallow='Ich programmiere gern. Beispiel = Falsch, zusätzliche_kwargs = {}
文本嵌入模型组件相对比较难理解,这个组件接收的是一个字符串,返回的是一个浮点数的列表。在 NLP 领域中 Embedding 是一个很常用的技术,Embedding 是将高维特征压缩成低维特征的一种方法,常用于自然语言处理任务中,如文本分类、机器翻译、推荐系统等。它将文本中的离散数据如单词、短语、句子等,映射为实数向量,以更好地进行神经网络处理和学习。通过 Embedding,文本数据可以被更好地表示和理解,提高了模型的表现力和泛化能力。
from langchain.embeddings import OpenAIEmbeddingsembeddings = OpenAIEmbeddings()text = "hello world"query_result = embeddings.embed_query(text)doc_result = embeddings.embed_documents([text])print(query_result)print(doc_result)
output
[-0.01491016335785389, 0.0013780705630779266, -0.018519161269068718, -0.031111136078834534, -0.02430146001279354, 0.007488010451197624,0.011340680532157421, 此处省略 .......
今天给大家介绍了一下 LangChain 的模型组件,有了模型组件我们就可以更加方便的跟各种 LLMs 进行交互了。
官方文档:https://python.langchain.com/en/latest/modules/models.html
Das obige ist der detaillierte Inhalt vonJava-Programmierer lernen LangChain von Grund auf – Modellkomponenten. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So beheben Sie den HTTP-Fehler 503
So beheben Sie den HTTP-Fehler 503
 Der Unterschied zwischen Java und Java
Der Unterschied zwischen Java und Java
 Wie viel entspricht Dimensity 6020 Snapdragon?
Wie viel entspricht Dimensity 6020 Snapdragon?
 MySQL-Backup-Datenmethode
MySQL-Backup-Datenmethode
 Lösung für die Meldung „Schwarzer Bildschirm' des Computers, fehlendes Betriebssystem
Lösung für die Meldung „Schwarzer Bildschirm' des Computers, fehlendes Betriebssystem
 Der Unterschied zwischen großer Funktion und max
Der Unterschied zwischen großer Funktion und max
 Was ist mit dem roten Licht am Lichtsignal los?
Was ist mit dem roten Licht am Lichtsignal los?
 Was soll ich tun, wenn beim Einschalten des Computers englische Buchstaben angezeigt werden und der Computer nicht eingeschaltet werden kann?
Was soll ich tun, wenn beim Einschalten des Computers englische Buchstaben angezeigt werden und der Computer nicht eingeschaltet werden kann?
 esd zu iso
esd zu iso








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



