
 Technologie-Peripheriegeräte
KI
Der ChatGPT-Kurs von Andrew Ng ging viral: Die KI verzichtete darauf, Wörter rückwärts zu schreiben, verstand aber die ganze Welt
Technologie-Peripheriegeräte
KI
Der ChatGPT-Kurs von Andrew Ng ging viral: Die KI verzichtete darauf, Wörter rückwärts zu schreiben, verstand aber die ganze Welt
Der ChatGPT-Kurs von Andrew Ng ging viral: Die KI verzichtete darauf, Wörter rückwärts zu schreiben, verstand aber die ganze Welt

Ich hätte nicht erwartet, dass ChatGPT bis heute noch dumme Fehler machen würde?
Meister Andrew Ng hat in der letzten Klasse darauf hingewiesen:
ChatGPT kehrt Wörter nicht um!
Wenn Sie beispielsweise das Wort „Lollipop“ umkehren, lautet die Ausgabe „pilollol“, was völlig verwirrend ist.

Oh, das ist tatsächlich ein bisschen schockierend.
So sehr, dass, nachdem ein Internetnutzer den auf Reddit geposteten Kurs angehört hatte, dieser sofort eine große Anzahl von Zuschauern anzog und der Beitrag schnell 6.000 Aufrufe erreichte.
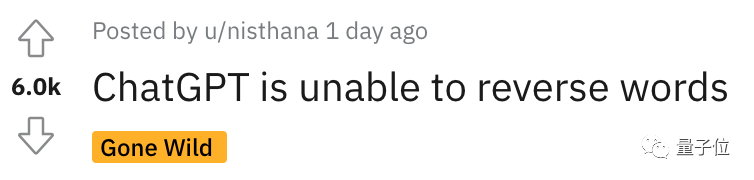
Und das ist kein zufälliger Fehler. Netizens haben festgestellt, dass ChatGPT diese Aufgabe tatsächlich nicht abschließen kann, und auch unsere persönlichen Testergebnisse sind dieselben.

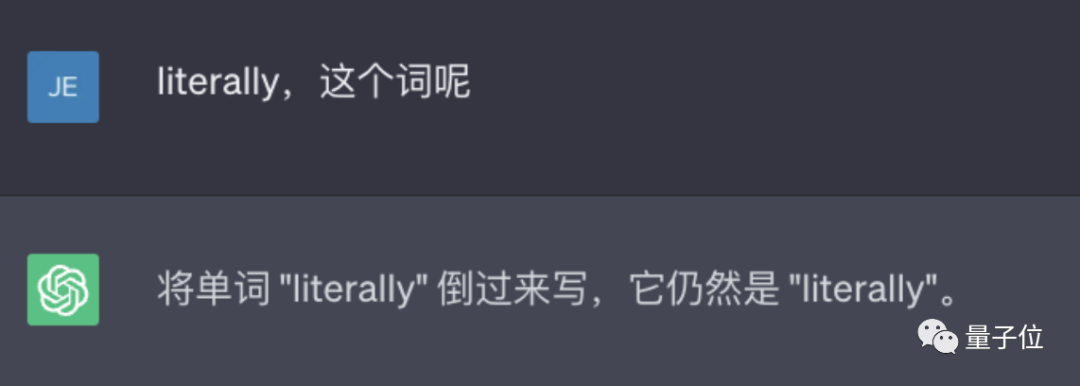
△Eigentlicher Test ChatGPT (GPT-3.5)
Auch viele Produkte, darunter Bard, Bing, Wen Xinyiyan usw., funktionieren nicht.
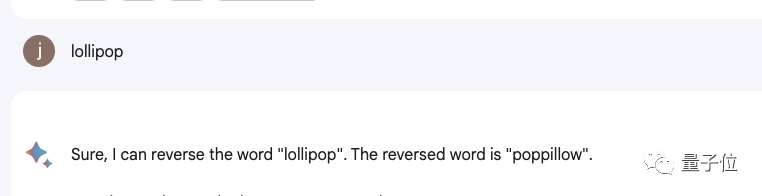
△Tatsächlicher Test Bard

△Tatsächlicher Test Wen
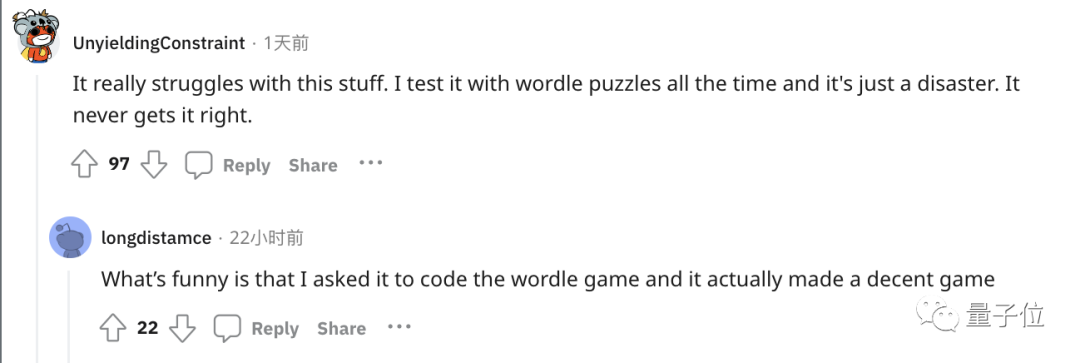
Zum Beispiel war das Spielen des beliebten Wortspiels Wordle eine Katastrophe und hat nie alles richtig gemacht.
Der Schlüssel liegt im Token
Der Schlüssel zu diesem Phänomen liegt im Token. Große Modelle verwenden häufig Token zur Textverarbeitung, da Token die häufigsten Zeichenfolgen in Texten sind.
Es kann ein ganzes Wort oder ein Fragment eines Wortes sein. Große Modelle kennen die statistischen Beziehungen zwischen diesen Token und können geschickt den nächsten Token generieren.
Wenn es also um die kleine Aufgabe der Wortumkehr geht, könnte es sein, dass man einfach jedes Plättchen umdreht und nicht den Buchstaben.


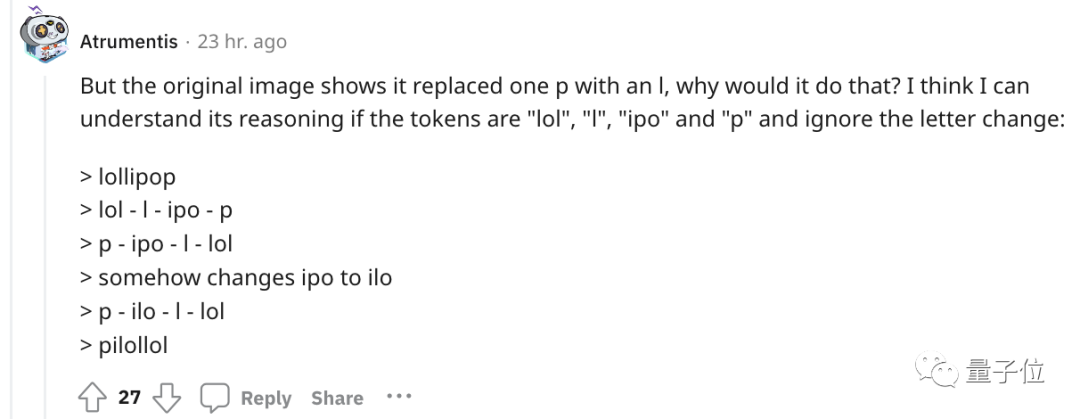
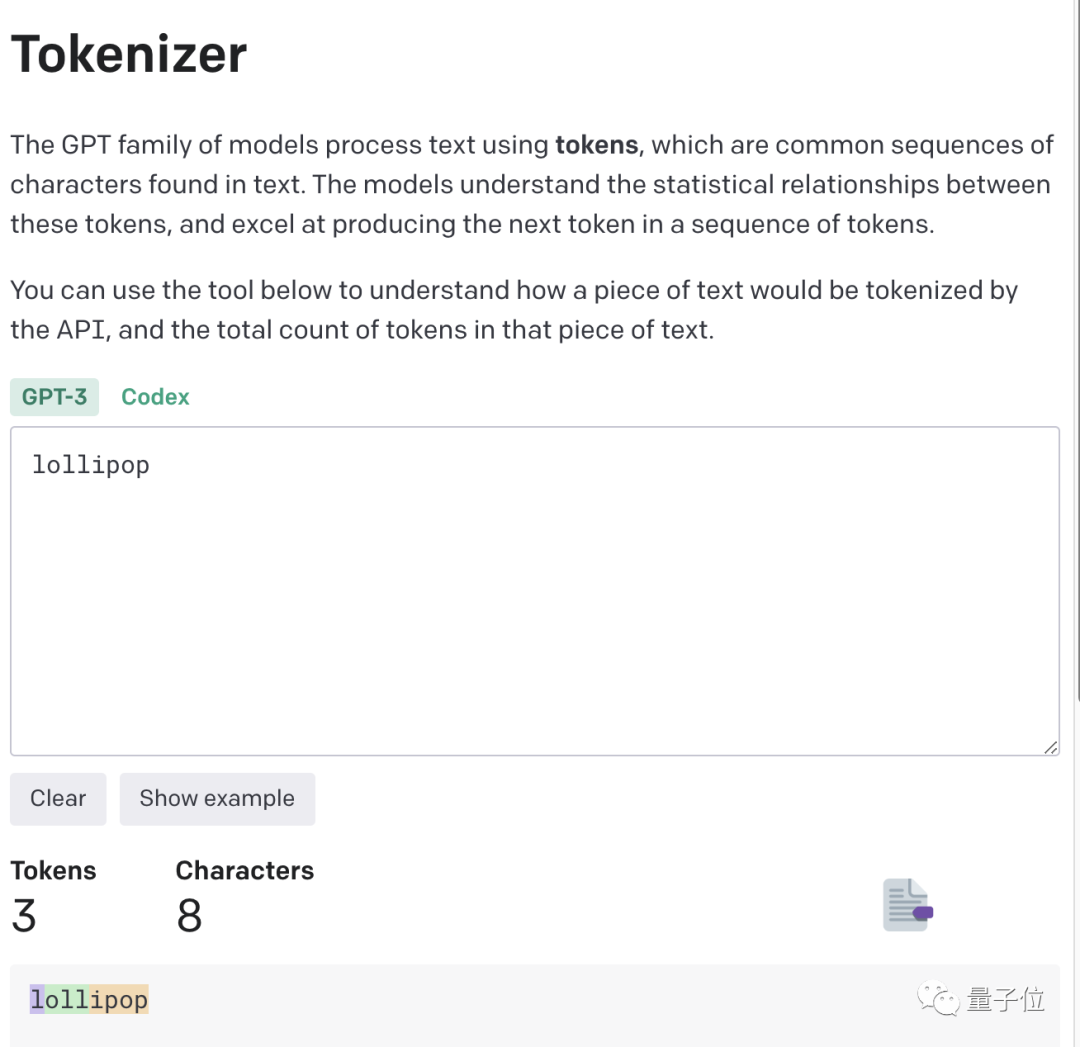
Aufgrund der Erfahrung wurden einige ungeschriebene Regeln geboren.
1 Token≈4 englische Zeichen≈dreiviertel eines Wortes;- 100 Token≈75 Wörter;
- ein Absatz≈100 Token, 1500 Wörter ≈ 2048 Token;
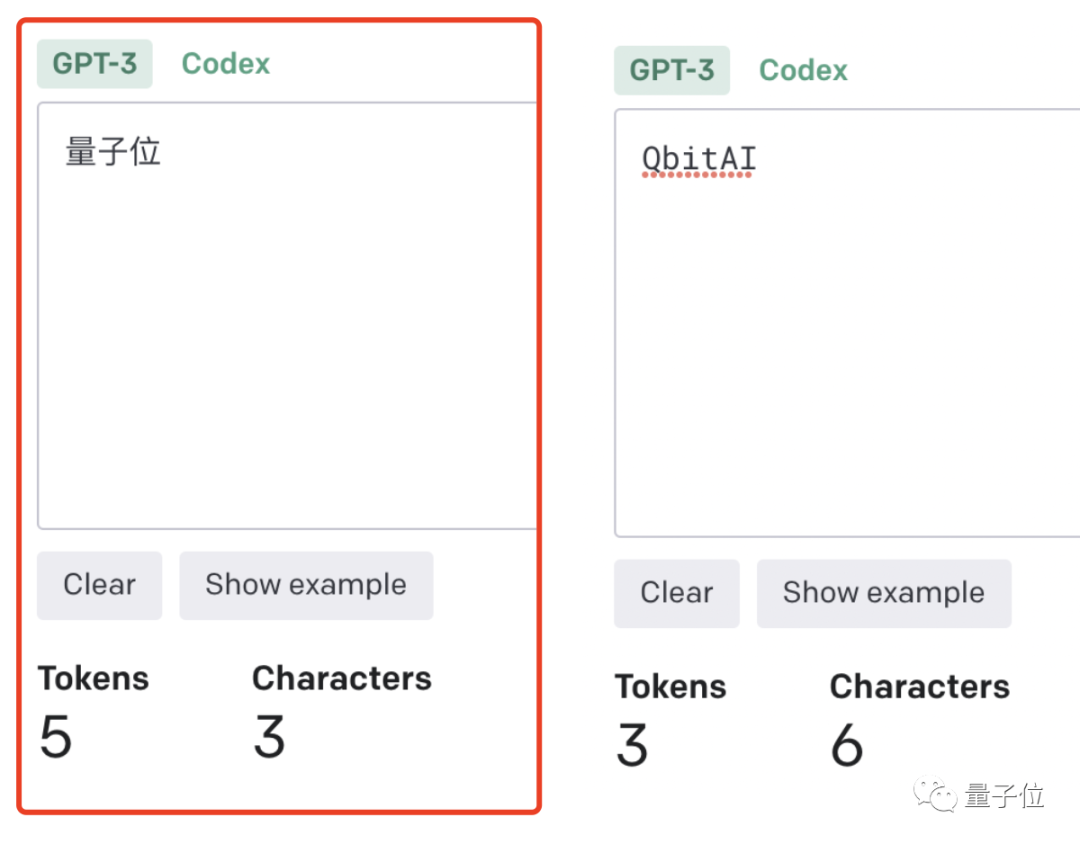
- Wie Wörter aufgeteilt werden, hängt auch von der Sprache ab. Jemand hat zuvor berechnet, dass die Anzahl der auf Chinesisch verwendeten Token 1,2- bis 2,7-mal höher ist als auf Englisch.
-

Je höher das Verhältnis von Token zu Zeichen (Token zu Wort), desto höher sind die Verarbeitungskosten. Daher ist die Verarbeitung von chinesischen Tokenisierungen teurer als die von englischen.
Sie können es so verstehen: Token ist eine Möglichkeit für große Modelle, die reale Welt der Menschen zu verstehen. Es ist sehr einfach und reduziert den Speicher- und Zeitaufwand erheblich.
Aber es gibt ein Problem mit der Tokenisierung von Wörtern, was es für das Modell schwierig macht, sinnvolle Eingabedarstellungen zu lernen. Die intuitivste Darstellung besteht darin, dass es die Bedeutung der Wörter nicht verstehen kann.
Transformers wurden damals entsprechend optimiert. Beispielsweise wurde ein komplexes und ungewöhnliches Wort in einen bedeutungsvollen Token und einen unabhängigen Token unterteilt.
So wie „nervigly“ in zwei Teile unterteilt ist: „nervig“ und „ly“, behält ersteres seine eigene Bedeutung, während letzteres häufiger vorkommt.
Dies hat heute auch zu den erstaunlichen Effekten von ChatGPT und anderen großen Modellprodukten geführt, die die menschliche Sprache sehr gut verstehen können.
Für die Unfähigkeit, eine so kleine Aufgabe wie die Wortumkehr zu bewältigen, gibt es natürlich eine Lösung.
Der einfachste und direkteste Weg besteht darin, die Wörter zuerst selbst zu trennen~
Oder Sie können ChatGPT dies Schritt für Schritt erledigen lassen und jeden Buchstaben zuerst tokenisieren.
Oder lassen Sie es ein Programm schreiben, um Buchstaben umzukehren, und dann wird das Ergebnis des Programms korrekt sein. (Hundekopf)
GPT-4 kann jedoch auch verwendet werden, und bei tatsächlichen Tests gibt es kein solches Problem.
△ Gemessen GPT-4
Kurz gesagt, Token sind der Grundstein für das Verständnis natürlicher Sprache durch KI.
Als Brücke für die KI zum Verständnis der menschlichen natürlichen Sprache wird die Bedeutung von Token immer deutlicher.
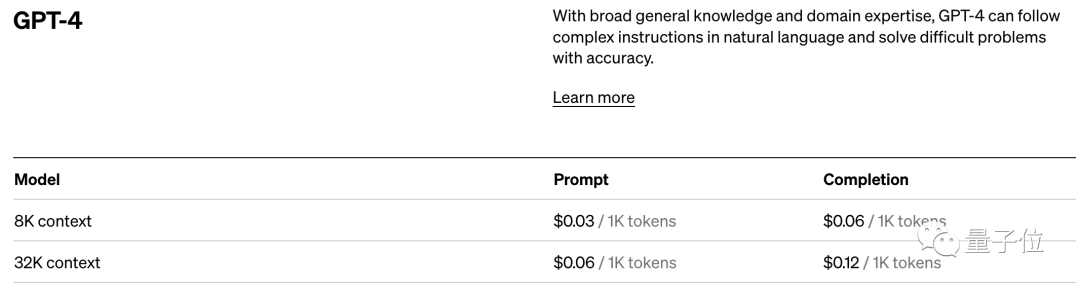
Es ist zu einem entscheidenden Faktor für die Leistung von KI-Modellen und den Abrechnungsstandard für große Modelle geworden.
Es gibt sogar Token-Literatur
Wie oben erwähnt, können Token dem Modell die Erfassung feinkörnigerer semantischer Informationen wie Wortbedeutung, Wortreihenfolge, grammatikalische Struktur usw. erleichtern. Bei Sequenzmodellierungsaufgaben (z. B. Sprachmodellierung, maschinelle Übersetzung, Textgenerierung usw.) sind Position und Reihenfolge für die Modellbildung sehr wichtig.
Nur wenn das Modell die Position und den Kontext jedes Tokens in der Sequenz genau versteht, kann es den Inhalt besser vorhersagen und eine vernünftige Ausgabe liefern.
Daher haben Qualität und Quantität der Token einen direkten Einfluss auf den Modelleffekt.
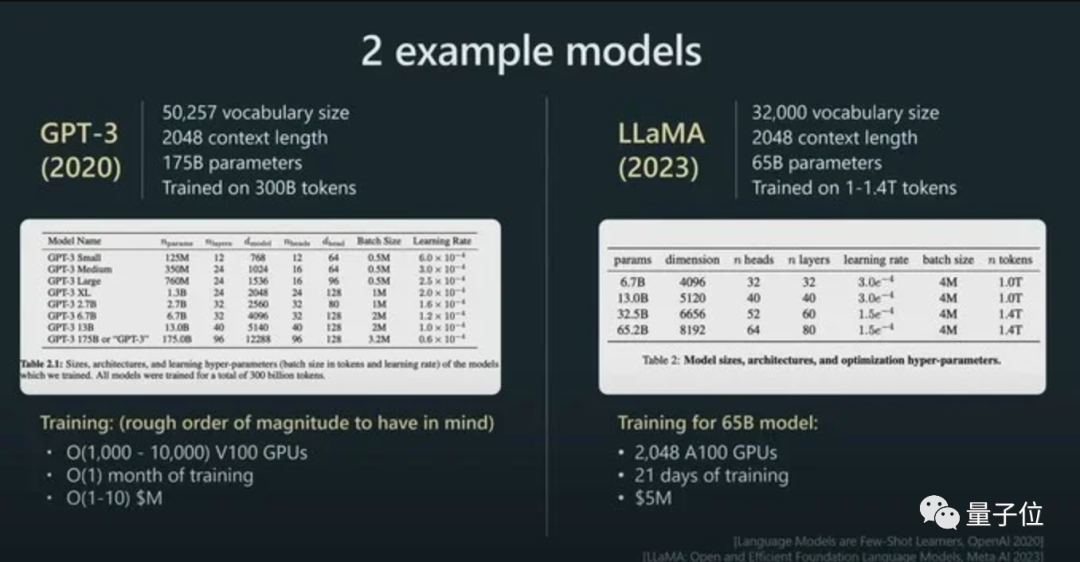
Ab diesem Jahr, wenn immer mehr große Modelle veröffentlicht werden, wird der Schwerpunkt auf der Anzahl der Token liegen. In den Details der Veröffentlichung von Google PaLM 2 wurde beispielsweise erwähnt, dass 3,6 Billionen Token für das Training verwendet wurden.
Und viele große Namen der Branche haben auch gesagt, dass Token wirklich entscheidend sind!
Andrej Karpathy, ein KI-Wissenschaftler, der dieses Jahr von Tesla zu OpenAI wechselte, sagte in seiner Rede:
Mehr Token können das Modell besser denken lassen.
Und er betonte, dass die Leistung des Modells nicht nur durch die Parametergröße bestimmt wird.
Zum Beispiel ist die Parametergröße von LLaMA viel kleiner als die von GPT-3 (65B vs. 175B), aber da mehr Token für das Training verwendet werden (1,4T vs. 300B), ist LLaMA leistungsfähiger.
Und mit seinem direkten Einfluss auf die Modellleistung ist Token auch der Abrechnungsstandard für KI-Modelle.
Nehmen Sie den Preisstandard von OpenAI. Sie berechnen in Einheiten von 1K-Tokens. Verschiedene Modelle und verschiedene Arten von Tokens haben unterschiedliche Preise.
Kurz gesagt: Sobald Sie den Bereich der großen KI-Modelle betreten, werden Sie feststellen, dass Token ein unvermeidlicher Wissenspunkt sind.
Nun, es wurde sogar Token-Literatur abgeleitet...
Es ist jedoch erwähnenswert, dass die Übersetzung von Token in der chinesischen Welt noch nicht vollständig geklärt ist.
Die wörtliche Übersetzung von „Token“ ist immer etwas seltsam.
GPT-4 meint, es sei besser, es „Wortelement“ oder „Tag“ zu nennen, was denken Sie?
Referenzlink:
[1]https://www.reddit.com/r/ChatGPT/comments/13xxehx/chatgpt_is_unable_to_reverse_words/
[2]https://help.openai.com/en/ Articles/4936856-what-are-tokens-and-how-to-count-them
[3]https://openai.com/pricing






Das obige ist der detaillierte Inhalt vonDer ChatGPT-Kurs von Andrew Ng ging viral: Die KI verzichtete darauf, Wörter rückwärts zu schreiben, verstand aber die ganze Welt. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 So implementieren Sie die Dateisortierung nach Debian Readdir
Apr 13, 2025 am 09:06 AM
So implementieren Sie die Dateisortierung nach Debian Readdir
Apr 13, 2025 am 09:06 AM
In Debian -Systemen wird die Readdir -Funktion zum Lesen des Verzeichnisinhalts verwendet, aber die Reihenfolge, in der sie zurückgibt, ist nicht vordefiniert. Um Dateien in einem Verzeichnis zu sortieren, müssen Sie zuerst alle Dateien lesen und dann mit der QSORT -Funktion sortieren. Der folgende Code zeigt, wie Verzeichnisdateien mithilfe von Readdir und QSORT in Debian System sortiert werden:#include#include#include#include // benutzerdefinierte Vergleichsfunktion, verwendet für QSortIntCompare (constvoid*a, constvoid*b) {rettrcmp (*(*(*(
 So optimieren Sie die Leistung von Debian Readdir
Apr 13, 2025 am 08:48 AM
So optimieren Sie die Leistung von Debian Readdir
Apr 13, 2025 am 08:48 AM
In Debian -Systemen werden Readdir -Systemaufrufe zum Lesen des Verzeichnisinhalts verwendet. Wenn seine Leistung nicht gut ist, probieren Sie die folgende Optimierungsstrategie aus: Vereinfachen Sie die Anzahl der Verzeichnisdateien: Teilen Sie große Verzeichnisse so weit wie möglich in mehrere kleine Verzeichnisse auf und reduzieren Sie die Anzahl der gemäß Readdir -Anrufe verarbeiteten Elemente. Aktivieren Sie den Verzeichnis -Inhalt Caching: Erstellen Sie einen Cache -Mechanismus, aktualisieren Sie den Cache regelmäßig oder bei Änderungen des Verzeichnisinhalts und reduzieren Sie häufige Aufrufe an Readdir. Speicher -Caches (wie Memcached oder Redis) oder lokale Caches (wie Dateien oder Datenbanken) können berücksichtigt werden. Nehmen Sie eine effiziente Datenstruktur an: Wenn Sie das Verzeichnis -Traversal selbst implementieren, wählen Sie effizientere Datenstrukturen (z.
 So setzen Sie die Debian Apache -Protokollebene fest
Apr 13, 2025 am 08:33 AM
So setzen Sie die Debian Apache -Protokollebene fest
Apr 13, 2025 am 08:33 AM
In diesem Artikel wird beschrieben, wie Sie die Protokollierungsstufe des Apacheweb -Servers im Debian -System anpassen. Durch Ändern der Konfigurationsdatei können Sie die ausführliche Ebene der von Apache aufgezeichneten Protokollinformationen steuern. Methode 1: Ändern Sie die Hauptkonfigurationsdatei, um die Konfigurationsdatei zu finden: Die Konfigurationsdatei von Apache2.x befindet sich normalerweise im Verzeichnis/etc/apache2/. Der Dateiname kann je nach Installationsmethode Apache2.conf oder httpd.conf sein. Konfigurationsdatei bearbeiten: Öffnen Sie die Konfigurationsdatei mit Stammberechtigungen mit einem Texteditor (z. B. Nano): Sudonano/etc/apache2/apache2.conf
 Wie Debian OpenSSL verhindert, dass Mann-in-the-Middle-Angriffe
Apr 13, 2025 am 10:30 AM
Wie Debian OpenSSL verhindert, dass Mann-in-the-Middle-Angriffe
Apr 13, 2025 am 10:30 AM
In Debian Systems ist OpenSSL eine wichtige Bibliothek für Verschlüsselung, Entschlüsselung und Zertifikatverwaltung. Um einen Mann-in-the-Middle-Angriff (MITM) zu verhindern, können folgende Maßnahmen ergriffen werden: Verwenden Sie HTTPS: Stellen Sie sicher, dass alle Netzwerkanforderungen das HTTPS-Protokoll anstelle von HTTP verwenden. HTTPS verwendet TLS (Transport Layer Security Protocol), um Kommunikationsdaten zu verschlüsseln, um sicherzustellen, dass die Daten während der Übertragung nicht gestohlen oder manipuliert werden. Überprüfen Sie das Serverzertifikat: Überprüfen Sie das Serverzertifikat im Client manuell, um sicherzustellen, dass es vertrauenswürdig ist. Der Server kann manuell durch die Delegate -Methode der URLSession überprüft werden
 Debian Mail Server SSL -Zertifikat -Installationsmethode
Apr 13, 2025 am 11:39 AM
Debian Mail Server SSL -Zertifikat -Installationsmethode
Apr 13, 2025 am 11:39 AM
Die Schritte zur Installation eines SSL -Zertifikats auf dem Debian Mail -Server sind wie folgt: 1. Installieren Sie zuerst das OpenSSL -Toolkit und stellen Sie sicher, dass das OpenSSL -Toolkit bereits in Ihrem System installiert ist. Wenn nicht installiert, können Sie den folgenden Befehl installieren: sudoapt-getupdatesudoapt-getinstallopenssl2. Generieren Sie den privaten Schlüssel und die Zertifikatanforderung als nächst
 Wie Debian Readdir sich in andere Tools integriert
Apr 13, 2025 am 09:42 AM
Wie Debian Readdir sich in andere Tools integriert
Apr 13, 2025 am 09:42 AM
Die Readdir -Funktion im Debian -System ist ein Systemaufruf, der zum Lesen des Verzeichnisgehalts verwendet wird und häufig in der C -Programmierung verwendet wird. In diesem Artikel wird erläutert, wie Readdir in andere Tools integriert wird, um seine Funktionalität zu verbessern. Methode 1: Kombinieren Sie C -Sprachprogramm und Pipeline zuerst ein C -Programm, um die Funktion der Readdir aufzurufen und das Ergebnis auszugeben:#include#include#includeIntmain (intargc, char*argv []) {Dir*Dir; structDirent*Eintrag; if (argc! = 2) {{
 Debian Mail Server Firewall -Konfigurationstipps
Apr 13, 2025 am 11:42 AM
Debian Mail Server Firewall -Konfigurationstipps
Apr 13, 2025 am 11:42 AM
Das Konfigurieren der Firewall eines Debian -Mailservers ist ein wichtiger Schritt zur Gewährleistung der Serversicherheit. Im Folgenden sind mehrere häufig verwendete Firewall -Konfigurationsmethoden, einschließlich der Verwendung von Iptables und Firewalld. Verwenden Sie Iptables, um Firewall so zu konfigurieren, dass Iptables (falls bereits installiert) installiert werden:
 Wie man Debian Syslog lernt
Apr 13, 2025 am 11:51 AM
Wie man Debian Syslog lernt
Apr 13, 2025 am 11:51 AM
In diesem Leitfaden werden Sie erfahren, wie Sie Syslog in Debian -Systemen verwenden. Syslog ist ein Schlüsseldienst in Linux -Systemen für Protokollierungssysteme und Anwendungsprotokollnachrichten. Es hilft den Administratoren, die Systemaktivitäten zu überwachen und zu analysieren, um Probleme schnell zu identifizieren und zu lösen. 1. Grundkenntnisse über syslog Die Kernfunktionen von Syslog umfassen: zentrales Sammeln und Verwalten von Protokollnachrichten; Unterstützung mehrerer Protokoll -Ausgabesformate und Zielorte (z. B. Dateien oder Netzwerke); Bereitstellung von Echtzeit-Protokoll- und Filterfunktionen. 2. Installieren und Konfigurieren von Syslog (mit Rsyslog) Das Debian -System verwendet standardmäßig Rsyslog. Sie können es mit dem folgenden Befehl installieren: sudoaptupdatesud
