

Was sind die technischen Punkte von Redis?

1. Warum Redis verwenden
Bei der Verwendung von Redis in einem Projekt ist der Autor der Ansicht, dass Leistung und Parallelität berücksichtigt werden müssen. Natürlich verfügt Redis auch über andere Funktionen, die verteilte Sperren und andere Funktionen ausführen können. Wenn es sich jedoch nur um andere Funktionen wie verteilte Sperren handelt, kann stattdessen auch andere Middleware (z. B. Zookpeer usw.) verwendet werden ist nicht erforderlich, um Redis zu verwenden.
Daher wird diese Frage hauptsächlich aus den beiden Perspektiven Leistung und Parallelität beantwortet:
1. Leistung
Wie in der Abbildung unten gezeigt, dauert es, bis wir auf die Notwendigkeit einer Ausführung stoßen eine besonders lange Zeit und das Ergebnis Wenn sich die SQL nicht häufig ändert, ist es besonders geeignet, die laufenden Ergebnisse in den Cache zu legen. Auf diese Weise werden nachfolgende Anfragen aus dem Cache gelesen, sodass schnell auf Anfragen reagiert werden kann.
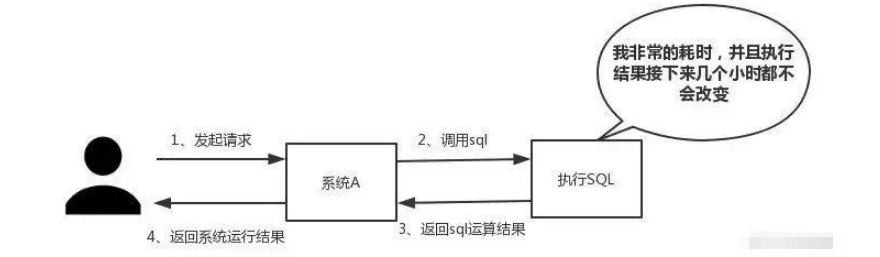
Exkurs: Ich möchte plötzlich über den Standard für schnelle Reaktion sprechen – tatsächlich gibt es keinen festen Standard für diese Reaktionszeit in Abhängigkeit vom Interaktionseffekt. Jemand hat mir gegenüber einmal gesagt: „Im Idealfall sollten unsere Seitensprünge sofort abgeschlossen sein, und In-Page-Vorgänge müssen sofort abgeschlossen sein.“ Darüber hinaus sollten zeitaufwändige Vorgänge, die mehr als einen Fingerschnippen erfordern, über Fortschrittsmeldungen verfügen und jederzeit unterbrochen oder abgebrochen werden können, um den Benutzern das bestmögliche Erlebnis zu bieten. „
Wie viel Zeit ist also ein Augenblick, ein Augenblick oder eine Fingerbewegung?
Laut den „Maha Sangha Vinaya“-Aufzeichnungen: Ein Moment ist ein Gedanke, zwanzig Gedanken sind ein Augenblick, zwanzig Augenblicke sind eine Bewegung des Fingers sind zwanzig Fingerbewegungen Ein Luo ist ein Moment, zwanzig Luo sind ein Moment und ein Tag und eine Nacht sind dreißig Momente
Nach sorgfältiger Berechnung ist ein Moment also 0,36 Sekunden, ein Moment ist 0,018 Sekunden und ein Finger ist 7,2 Sekunden lang Vermeiden Sie den direkten Zugriff auf die Datenbank. In diesem Fall können wir Redis zum Puffern verwenden. Lassen Sie die Anforderung zuerst auf Redis zugreifen. 2. Welche Nachteile hat die Verwendung von Redis?
Jeder verwendet Redis schon so lange. Grundsätzlich muss man bei der Verwendung von Redis auf einige Probleme stoßen, die häufigsten sind hauptsächlich vier Aspekte:
1 2. Cache-Lawinenproblem
3. Warum ist Single-Threaded Redis so schnell? Diese Frage ist eigentlich eine Untersuchung des internen Mechanismus von Redis. Viele Leute wissen tatsächlich nicht, dass Redis a Daher sollte diese Frage hauptsächlich anhand der folgenden drei Punkte überprüft werden: 1. Reiner Speicherbetrieb, Vermeidung häufiger Kontextwechsel I/O-Multiplex-Mechanismus Lassen Sie uns den I/O-Multiplex-Mechanismus genauer besprechen, da dieser Begriff zu populär ist, als dass normale Menschen seine Bedeutung verstehen könnten. Xiaoqu eröffnete beispielsweise einen Kurierladen in der S-Stadt und war für Intra- verantwortlich. Aus finanziellen Gründen stellte Xiaoqu zunächst viele Kuriere ein, stellte jedoch später fest, dass man nur durch den Kauf eines Autos über genügend Geld verfügen kann, um eine Expresszustellung durchzuführen:
Lassen Sie uns den I/O-Multiplex-Mechanismus genauer besprechen, da dieser Begriff zu populär ist, als dass normale Menschen seine Bedeutung verstehen könnten. Xiaoqu eröffnete beispielsweise einen Kurierladen in der S-Stadt und war für Intra- verantwortlich. Aus finanziellen Gründen stellte Xiaoqu zunächst viele Kuriere ein, stellte jedoch später fest, dass man nur durch den Kauf eines Autos über genügend Geld verfügen kann, um eine Expresszustellung durchzuführen:
Jedes Mal, wenn ein Kunde liefert Bei der Expresslieferung wird Xiaoqu einen Kurier damit beauftragen, die Expresslieferung zuzustellen. Langsam stellte Xiaoqu fest, dass es bei dieser Geschäftsmethode viele Probleme gab der Kuriere waren untätig. Wer sich das Auto schnappte, konnte es per Express liefern lassen Die Koordination zwischen den Kurieren ist sehr zeitaufwändig. Aufgrund der oben genannten Mängel hat Xiaoqu die folgende Geschäftsmethode vorgeschlagen:
Xiaoqu hat nur einen Kurier beauftragt und die Expresszustellung vom Kunden nach dem Bestimmungsort sortiert, ordentlich an einem Ort platziert. Schließlich holt der Kurier die Kuriere der Reihe nach ab, nimmt sie einzeln entgegen und fährt den Kurier hinaus. und kehrt dann zurück, um den nächsten Kurier zu holen.
Wenn man die beiden oben genannten Geschäftsmethoden vergleicht, ist es offensichtlich, dass die zweite Methode effizienter und besser ist? In der obigen Metapher: 1. Jeder Kurier → jeder Thread
2. Jeder Express → jeder Socket (E/A-Stream) 3. Der Lieferort des Express → verschiedene Zustände des SocketsExpress-Lieferanfrage → Anfrage vom Kunden
5. Xiaoqus Geschäftsmethode → Code läuft auf dem Server
6. Ein Auto → CPU-Kernanzahl
Wir haben also die folgenden Schlussfolgerungen:
1. Betrieb Die erste Methode ist das traditionelle Parallelitätsmodell. Jeder E/A-Stream (Express) wird von einem neuen Thread (Courier) verwaltet.
2. Die zweite Verwaltungsmethode ist I/O-Multiplexing. Ein Kurier verwaltet mehrere E/A-Flüsse, indem er den Status jedes E/A-Flusses verfolgt. Dies ähnelt einem Kurier, der nur eine Person hat, die jedes Paket ausliefert und den Lieferstatus jedes Pakets kennen muss.
Das Folgende ist eine Analogie zum echten Redis-Thread-Modell, wie in der Abbildung gezeigt:
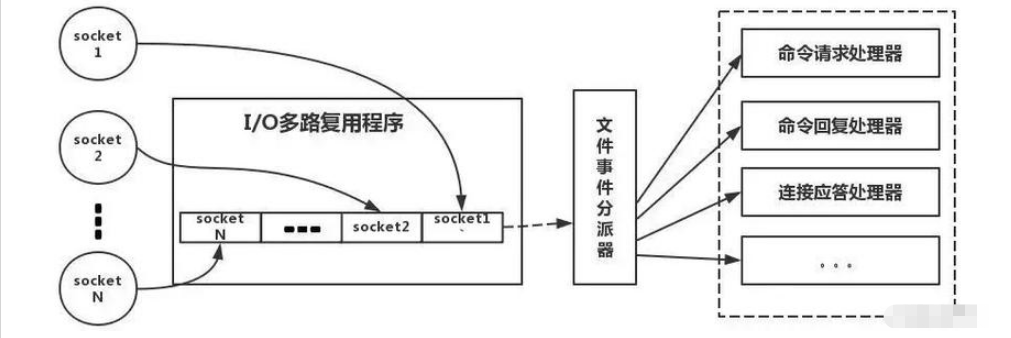
Unter Bezugnahme auf die Abbildung oben generiert unser Redis-Client vereinfacht gesagt Sockets mit unterschiedlichen Ereignissen, wenn er ausgeführt wird Typen. Auf der Serverseite gibt es ein I/O-Multiplexing-Programm, das es in eine Warteschlange stellt. Anschließend entnimmt der Dateiereignis-Dispatcher die Datei der Reihe nach aus der Warteschlange und leitet sie an verschiedene Ereignisprozessoren weiter.
Es ist zu beachten, dass Redis für diesen E/A-Multiplexing-Mechanismus auch Multiplexing-Funktionsbibliotheken wie Select, Epoll, Evport und Kqueue bereitstellt. Sie können sich selbst darüber informieren.
4. Redis-Datentypen und ihre jeweiligen Verwendungsszenarien
Wenn Sie diese Frage sehen, denken Sie, dass sie sehr einfach ist? Tatsächlich glaube ich das auch. Laut Interviewerfahrung können jedoch mindestens 80 % der Menschen diese Frage nicht beantworten. Es wird empfohlen, dass Sie es nach der Verwendung im Projekt analog auswendig lernen können, um eine tiefere Erfahrung zu sammeln, anstatt es auswendig zu lernen. Grundsätzlich verwendet ein qualifizierter Programmierer fünf Typen:
1, String
Dazu gibt es eigentlich nichts zu sagen. Für die konventionellste Set/Get-Operation kann Value entweder String oder eine Zahl sein. Führen Sie im Allgemeinen eine Zwischenspeicherung komplexer Zählfunktionen durch.
2. Hash
Der Wert ist hier eine Variable, die ein strukturiertes Objekt enthält, das eine bequeme Manipulation bestimmter darin enthaltener Felder ermöglicht. Wenn der Autor eine einmalige Anmeldung durchführt, verwende ich diese Datenstruktur zum Speichern von Benutzerinformationen, verwende CookieId als Schlüssel und stelle 30 Minuten als Cache-Ablaufzeit ein, was einen sitzungsähnlichen Effekt sehr gut simulieren kann.
3. List
Mit der Datenstruktur von List können Sie einfache Nachrichtenwarteschlangenfunktionen ausführen. Darüber hinaus können Sie auch den Lrange-Befehl von Redis verwenden, um die Paging-Funktion zu implementieren, die eine hervorragende Leistung aufweist und eine gute Benutzererfahrung bieten kann.
4. Set
Da Set eine Reihe von Sätzen eindeutiger Werte stapelt, kann eine globale Deduplizierung durchgeführt werden.
Warum nicht das mit der JVM gelieferte Set für die Deduplizierung verwenden? Da unsere Systeme im Allgemeinen in Clustern bereitgestellt werden, ist die Verwendung des mit der JVM gelieferten Sets mühsam. Ist es notwendig, einen öffentlichen Dienst zu erstellen, um eine globale Deduplizierung durchzuführen? Es ist zu viel Mühe.
Darüber hinaus können Sie durch die Verwendung von Operationen wie Schnittmenge, Vereinigung und Differenz allgemeine Präferenzen, alle Präferenzen und Ihre eigenen einzigartigen Präferenzen berechnen.
5. Sortierter Satz
Durch Zuweisen des Score-Parameters zu den Elementen im Satz kann der sortierte Satz die Elemente nach dem Score sortieren. Sie können einen Ranking-Antrag stellen und TOP N-Operationen durchführen. Darüber hinaus kann Sorted Set auch zur Ausführung verzögerter Aufgaben verwendet werden. Die letzte Anwendung besteht darin, Bereichssuchen durchzuführen. 5. Die Ablaufstrategie von Redis und der Speicherbeseitigungsmechanismus Wenn Ihr Redis beispielsweise nur 5G Daten speichern kann und Sie 10G schreiben, werden 5G Daten gelöscht. Wie wurde es gelöscht? Haben Sie über dieses Problem nachgedacht? Außerdem ist für Ihre Daten eine Ablaufzeit festgelegt, aber wenn die Zeit abgelaufen ist, ist die Speichernutzung immer noch relativ hoch. Haben Sie über den Grund nachgedacht?
Redis verwendet eine Strategie für regelmäßiges Löschen und verzögertes Löschen.
Warum nicht eine geplante Löschstrategie verwenden?
Regelmäßiges Löschen, Verwenden Sie einen Timer, um den Schlüssel zu überwachen, und er wird automatisch gelöscht, wenn er abläuft. Obwohl der Speicher rechtzeitig freigegeben wird, verbraucht er viele CPU-Ressourcen. Bei großen gleichzeitigen Anforderungen sollte die CPU Zeit für die Verarbeitung der Anforderung verwenden, anstatt den Schlüssel zu löschen. Daher wird diese Strategie nicht übernommen. Wie funktioniert das periodische Löschen + das verzögerte Löschen? Regelmäßiges Löschen:
Redis prüft standardmäßig alle 100 ms, ob abgelaufene Schlüssel vorhanden sind. Wenn abgelaufene Schlüssel vorhanden sind, werden diese gelöscht. Es ist zu beachten, dass Redis nicht alle 100 ms alle Schlüssel überprüft, sondern sie zufällig auswählt und überprüft (wenn alle Schlüssel alle 100 ms überprüft werden, bleibt Redis nicht hängen). Wenn Sie daher nur eine reguläre Löschstrategie anwenden, werden viele Schlüssel am Ende der Zeit nicht gelöscht. Daher ist das verzögerte Löschen praktisch. Das heißt, wenn Sie einen Schlüssel erhalten, prüft Redis, ob die Ablaufzeit für diesen Schlüssel festgelegt ist. Wenn es abläuft, wird es zu diesem Zeitpunkt gelöscht.
Gibt es keine anderen Probleme, wenn wir das reguläre Löschen + das verzögerte Löschen übernehmen?
Nein, sofern der Schlüssel nicht durch reguläres Löschen gelöscht wird. Dann haben Sie den Schlüssel nicht rechtzeitig angefordert, was bedeutet, dass die verzögerte Löschung nicht wirksam wurde. Um zu verhindern, dass der Speicher von Redis kontinuierlich zunimmt, muss der Speichereliminierungsmechanismus aktiviert werden. In Redis.conf gibt es eine Konfigurationszeile:
# maxmemory-policy volatile-lru
Diese Konfiguration ist mit der Speichereliminierungsstrategie ausgestattet:
Noeviction: Wenn der Speicher nicht ausreicht, um Platz zu schaffen Bei neu geschriebenen Daten wird bei neuen Schreibvorgängen ein Fehler gemeldet. Niemand sollte es benutzen;
Allkeys-lru: Wenn der Speicher nicht ausreicht, um die neu geschriebenen Daten aufzunehmen, entfernen Sie im Schlüsselbereich den zuletzt verwendeten Schlüssel. Empfohlen, derzeit verwendet das Projekt dies;
Allkeys-random: Wenn der Speicher nicht ausreicht, um die neu geschriebenen Daten aufzunehmen, wird ein Schlüssel zufällig aus dem Schlüsselbereich entfernt und niemand sollte ihn verwenden
Volatile-lru: Wenn der Speicher nicht ausreicht, um neu geschriebene Daten aufzunehmen, entfernen Sie im Schlüsselbereich mit festgelegter Ablaufzeit den zuletzt verwendeten Schlüssel. Diese Situation kommt im Allgemeinen vor, wenn Redis sowohl als Cache als auch als persistenter Speicher verwendet wird. Nicht empfohlen;
Volatil-zufällig: Wenn der Speicher nicht ausreicht, um neu geschriebene Daten aufzunehmen, wird ein Schlüssel zufällig mit einer festgelegten Ablaufzeit aus dem Schlüsselraum entfernt. Immer noch nicht empfohlen;
Volatile-ttl: Wenn der Speicher nicht ausreicht, um neu geschriebene Daten aufzunehmen, wird im Schlüsselbereich mit einer festgelegten Ablaufzeit zuerst der Schlüssel mit einer früheren Ablaufzeit entfernt. Nicht empfohlen.
PS: Wenn der Expire Key nicht gesetzt ist und die Voraussetzungen nicht erfüllt sind, dann ist das Verhalten der Strategien Volatile-lru, Volatile-random und Volatile-ttl im Grunde dasselbe wie Noeviction (keine Löschung).
6. Doppelschreibkonsistenzproblem zwischen Redis und Datenbank
Konsistenzproblem ist ein häufiges verteiltes Problem, das weiter in endgültige Konsistenz und starke Konsistenz unterteilt werden kann. Wenn die Datenbank und der Cache doppelt geschrieben werden, kommt es zwangsläufig zu Inkonsistenzen. Wenn Sie diese Frage beantworten möchten, müssen Sie zunächst eine Prämisse verstehen: Wenn strenge Konsistenzanforderungen für die Daten bestehen, können diese nicht zwischengespeichert werden. Alles, was wir tun, kann nur letztendliche Konsistenz garantieren.
Die von uns vorgeschlagene Lösung kann die Möglichkeit von Inkonsistenzen nur verringern, aber nicht vollständig beseitigen. Daher können Daten mit hohen Konsistenzanforderungen nicht zwischengespeichert werden.
„Distributed Database and Cache Double-Write Consistency Solution“
gibt eine detaillierte Analyse. Hier eine kurze Erklärung: Erstens, übernehmen Sie die richtige Aktualisierungsstrategie, aktualisieren Sie zuerst die Datenbank und löschen Sie dann den Cache Es kann sein, dass das Löschen des Caches fehlschlägt. Stellen Sie einfach eine Kompensationsmaßnahme bereit, z. B. die Verwendung einer Nachrichtenwarteschlange.
7. Umgang mit Cache-Penetrations- und Cache-Lawinenproblemen
Im Allgemeinen stoßen kleine und mittlere traditionelle Softwareunternehmen selten auf Cache-Penetrations- und Cache-Lawinenprobleme. Wenn Sie Millionen von Datenverkehr bewältigen möchten, müssen diese beiden Probleme sorgfältig berücksichtigt werden:
1. Umgang mit Cache-Penetration
Cache-Penetration, das heißt, Hacker fordern absichtlich Inhalte an, die nicht vorhanden sind Die Cache-Daten führen dazu, dass alle Anforderungen an die Datenbank gesendet werden, was zu einer abnormalen Datenbankverbindung führt.
Lösung:
Verwenden Sie eine Mutex-Sperre. Wenn Sie die Sperre erhalten, fordern Sie die Datenbank für eine Weile an Versuchen Sie es erneut.
1. Verwenden Sie die asynchrone Aktualisierungsstrategie. Unabhängig davon, ob der Schlüssel den Wert erhält, wird er direkt zurückgegeben. Im Wert Wert wird eine Cache-Ablaufzeit beibehalten. Wenn der Cache abläuft, wird ein Thread asynchron gestartet, um die Datenbank zu lesen und den Cache zu aktualisieren. Es ist ein Cache-Aufwärmvorgang erforderlich
2. Stellen Sie eine Methode bereit, mit der Sie schnell feststellen können, ob es einen wirksamen Abfangmechanismus gibt, z. B. die Verwendung eines Bloom-Filters, um eine Reihe legaler und gültiger Schlüssel intern zu verwalten, und schnell feststellen kann, ob der in der Anfrage enthaltene Schlüssel legal ist Wenn es nicht legal ist, wird es direkt zurückgegeben.2. Umgang mit Cache-Lawine
Cache-Lawine, d Alle Anfragen werden an die Datenbank gesendet, was zu Ausnahmen bei der Datenbankverbindung führt. Lösung: 1. Fügen Sie einen zufälligen Wert zur Cache-Ablaufzeit hinzu 2. Verwenden Sie eine Mutex-Sperre, aber der Durchsatz ist erheblich gesunken 3. Wir haben zwei Caches, Cache A und Cache B. Die Ablaufzeit von Cache A beträgt 20 Minuten, für Cache B gibt es keine Ablaufzeit. Der Cache-Vorwärmvorgang erfolgt von selbst. Dann schlüsseln Sie die folgenden Punkte auf: a Lesen Sie die Datenbank aus Cache A und kehren Sie direkt zurück, falls vorhanden.8. So lösen Sie das Problem der Redis-Parallelität, die um Schlüssel konkurriert
Dieses Problem besteht ungefähr darin, dass mehrere Subsysteme gleichzeitig einen Schlüssel festlegen. In diesem Fall sollte darauf geachtet werden, den Redis-Transaktionsmechanismus zu verwenden. Laut meinen Suchergebnissen auf Baidu im Vorfeld empfehlen die meisten Leute diese Methode. Ich empfehle jedoch nicht, den Transaktionsmechanismus von Redis zu verwenden. Wir verwenden hauptsächlich Redis-Cluster in der Produktionsumgebung und führen Daten-Sharding durch. Wenn Sie mehrere Schlüsseloperationen in eine Transaktion einbeziehen, werden diese Schlüssel nicht unbedingt auf demselben Redis-Server gespeichert. Daher ist der Transaktionsmechanismus von Redis sehr nutzlos. Die Lösung lautet wie folgt:Wenn die Reihenfolge dieser Schlüsseloperation nicht erforderlich ist
In diesem Fall bereiten Sie ein verteiltes Schloss vor, jeder greift nach dem Schloss und führt nach dem Ergreifen des Schlosses einfach die Set-Operation aus. Es ist relativ einfach.Wenn die Sequenz für diesen Tastenvorgang erforderlich ist
Angenommen, es gibt einen Schlüssel1. System A muss Schlüssel1 auf WertA setzen, System B muss Schlüssel1 auf WertB setzen und System C muss Schlüssel1 auf WertC setzen. Es besteht die Hoffnung, dass sich der Wert von Schlüssel1 in der Reihenfolge WertA→WertB→WertC ändert. Zu diesem Zeitpunkt müssen wir beim Schreiben von Daten in die Datenbank einen Zeitstempel speichern. Gehen Sie davon aus, dass der Zeitstempel wie folgt lautet:
1. System A-Taste 1 {WertA 3:00}
2. System B-Taste 1 {WertB 3:05}
3.
Angenommen, System B greift zuerst nach dem Schloss und setzt Key1 auf {ValueB 3:05}. Wenn System A die Sperre ergreift und feststellt, dass der Zeitstempel von ValueA früher ist als der Zeitstempel im Cache, wird die Set-Operation nicht ausgeführt. Und so weiter.
Das obige ist der detaillierte Inhalt vonWas sind die technischen Punkte von Redis?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 So erstellen Sie den Redis -Clustermodus
Apr 10, 2025 pm 10:15 PM
So erstellen Sie den Redis -Clustermodus
Apr 10, 2025 pm 10:15 PM
Der Redis -Cluster -Modus bietet Redis -Instanzen durch Sharding, die Skalierbarkeit und Verfügbarkeit verbessert. Die Bauschritte sind wie folgt: Erstellen Sie ungerade Redis -Instanzen mit verschiedenen Ports; Erstellen Sie 3 Sentinel -Instanzen, Monitor -Redis -Instanzen und Failover; Konfigurieren von Sentinel -Konfigurationsdateien, Informationen zur Überwachung von Redis -Instanzinformationen und Failover -Einstellungen hinzufügen. Konfigurieren von Redis -Instanzkonfigurationsdateien, aktivieren Sie den Cluster -Modus und geben Sie den Cluster -Informationsdateipfad an. Erstellen Sie die Datei nodes.conf, die Informationen zu jeder Redis -Instanz enthält. Starten Sie den Cluster, führen Sie den Befehl erstellen aus, um einen Cluster zu erstellen und die Anzahl der Replikate anzugeben. Melden Sie sich im Cluster an, um den Befehl cluster info auszuführen, um den Clusterstatus zu überprüfen. machen
 So sehen Sie alle Schlüssel in Redis
Apr 10, 2025 pm 07:15 PM
So sehen Sie alle Schlüssel in Redis
Apr 10, 2025 pm 07:15 PM
Um alle Schlüssel in Redis anzuzeigen, gibt es drei Möglichkeiten: Verwenden Sie den Befehl keys, um alle Schlüssel zurückzugeben, die dem angegebenen Muster übereinstimmen. Verwenden Sie den Befehl scan, um über die Schlüssel zu iterieren und eine Reihe von Schlüssel zurückzugeben. Verwenden Sie den Befehl Info, um die Gesamtzahl der Schlüssel zu erhalten.
 So implementieren Sie die zugrunde liegenden Redis
Apr 10, 2025 pm 07:21 PM
So implementieren Sie die zugrunde liegenden Redis
Apr 10, 2025 pm 07:21 PM
Redis verwendet Hash -Tabellen, um Daten zu speichern und unterstützt Datenstrukturen wie Zeichenfolgen, Listen, Hash -Tabellen, Sammlungen und geordnete Sammlungen. Ernähren sich weiterhin über Daten über Snapshots (RDB) und appendiert Mechanismen nur Schreibmechanismen. Redis verwendet die Master-Slave-Replikation, um die Datenverfügbarkeit zu verbessern. Redis verwendet eine Ereignisschleife mit einer Thread, um Verbindungen und Befehle zu verarbeiten, um die Datenatomizität und Konsistenz zu gewährleisten. Redis legt die Ablaufzeit für den Schlüssel fest und verwendet den faulen Löschmechanismus, um den Ablaufschlüssel zu löschen.
 So verwenden Sie den Befehl Redis
Apr 10, 2025 pm 08:45 PM
So verwenden Sie den Befehl Redis
Apr 10, 2025 pm 08:45 PM
Die Verwendung der REDIS -Anweisung erfordert die folgenden Schritte: Öffnen Sie den Redis -Client. Geben Sie den Befehl ein (Verbschlüsselwert). Bietet die erforderlichen Parameter (variiert von der Anweisung bis zur Anweisung). Drücken Sie die Eingabetaste, um den Befehl auszuführen. Redis gibt eine Antwort zurück, die das Ergebnis der Operation anzeigt (normalerweise in Ordnung oder -err).
 So lesen Sie Redis -Warteschlange
Apr 10, 2025 pm 10:12 PM
So lesen Sie Redis -Warteschlange
Apr 10, 2025 pm 10:12 PM
Um eine Warteschlange aus Redis zu lesen, müssen Sie den Warteschlangenname erhalten, die Elemente mit dem Befehl LPOP lesen und die leere Warteschlange verarbeiten. Die spezifischen Schritte sind wie folgt: Holen Sie sich den Warteschlangenname: Nennen Sie ihn mit dem Präfix von "Warteschlange:" wie "Warteschlangen: My-Queue". Verwenden Sie den Befehl LPOP: Wischen Sie das Element aus dem Kopf der Warteschlange aus und geben Sie seinen Wert zurück, z. B. die LPOP-Warteschlange: my-queue. Verarbeitung leerer Warteschlangen: Wenn die Warteschlange leer ist, gibt LPOP NIL zurück, und Sie können überprüfen, ob die Warteschlange existiert, bevor Sie das Element lesen.
 So implementieren Sie Redis -Zähler
Apr 10, 2025 pm 10:21 PM
So implementieren Sie Redis -Zähler
Apr 10, 2025 pm 10:21 PM
Der Redis-Zähler ist ein Mechanismus, der die Speicherung von Redis-Schlüsselwertpaaren verwendet, um Zählvorgänge zu implementieren, einschließlich der folgenden Schritte: Erstellen von Zählerschlüssel, Erhöhung der Zählungen, Verringerung der Anzahl, Zurücksetzen der Zählungen und Erhalt von Zählungen. Die Vorteile von Redis -Zählern umfassen schnelle Geschwindigkeit, hohe Parallelität, Haltbarkeit und Einfachheit und Benutzerfreundlichkeit. Es kann in Szenarien wie Benutzerzugriffszählungen, Echtzeit-Metrikverfolgung, Spielergebnissen und Ranglisten sowie Auftragsverarbeitungszählung verwendet werden.
 So lesen Sie den Quellcode von Redis
Apr 10, 2025 pm 08:27 PM
So lesen Sie den Quellcode von Redis
Apr 10, 2025 pm 08:27 PM
Der beste Weg, um Redis -Quellcode zu verstehen, besteht darin, Schritt für Schritt zu gehen: Machen Sie sich mit den Grundlagen von Redis vertraut. Wählen Sie ein bestimmtes Modul oder eine bestimmte Funktion als Ausgangspunkt. Beginnen Sie mit dem Einstiegspunkt des Moduls oder der Funktion und sehen Sie sich die Codezeile nach Zeile an. Zeigen Sie den Code über die Funktionsaufrufkette an. Kennen Sie die von Redis verwendeten Datenstrukturen. Identifizieren Sie den von Redis verwendeten Algorithmus.
 So verwenden Sie Redis Lock
Apr 10, 2025 pm 08:39 PM
So verwenden Sie Redis Lock
Apr 10, 2025 pm 08:39 PM
Um die Operationen zu sperren, muss die Sperre durch den Befehl setNX erfasst werden und dann den Befehl Ablauf verwenden, um die Ablaufzeit festzulegen. Die spezifischen Schritte sind: (1) Verwenden Sie den Befehl setNX, um zu versuchen, ein Schlüsselwertpaar festzulegen; (2) Verwenden Sie den Befehl Ablauf, um die Ablaufzeit für die Sperre festzulegen. (3) Verwenden Sie den Befehl Del, um die Sperre zu löschen, wenn die Sperre nicht mehr benötigt wird.
